@cww97
2017-12-11T18:20:07.000000Z
字数 2999
阅读 1240
机器学习作业9:k均值聚类
机器学习
k均值聚类,这次作业要求自动确定均值 = =
K均值聚类
K均值聚类(固定k)大致步骤:
- 随机选择k个点作为初始的簇中心
- 计算每个点到每个簇中心的距离,选择最小的作为该点属于的簇类
- 将每个簇的点取平均获得一个新的簇中心
- 重复2、3步骤直至簇中心不再变化
- 输出簇划分
伪代码表示(from书P203):

因为要确定k值,所以怕是没法直接sklearn了
自己实现的Kmeans,为了优雅,分了几个函数,fit先初始化然后产生一开始的类簇
随后的循环迭代两行便是上面口述步骤的二三步:得到新分类,每个类计算新中心,收敛时结束。其中计算新分类调用了get_dist()计算距离矩阵,
class Kmeans:data = np.array([])n, k = 0, 0def init_center(self):center = [] # center of clusterswhile len(center) < k: # 产生k个不重复的随机数cen = random.randint(0, n - 1)if cen not in center:center.append(cen)for i in range(len(center)): # 到data里面取点center[i] = data[center[i]]return centerdef get_dist(self, center):dist = np.zeros((n, k))for j in range(n):for i in range(k):dist[j][i] = np.linalg.norm(center[i] - data[j])return distdef get_clusters(self, center):dist = self.get_dist(center)label = np.argmin(dist, 1)clusters = []for i in range(k): clusters.append([])for i in range(n):clusters[label[i]].append(data[i])return label, clustersdef new_center(self, label, clusters):center = []for i in range(k):center.append(np.average(clusters[i], 0))return centerdef over(self, c0, c1):for i in range(k):print(c0[i]- c1[i])if np.linalg.norm(c0[i]-c1[i]) > eps: return Falsereturn Truedef fit(self, data, k):self.data, self.k, self.n = data, k, len(data)center0 = self.init_center()while True:label, clusters = self.get_clusters(center0)center1 = self.new_center(label, clusters)if self.over(center0, center1): breakcenter0 = center1return label
关于数据
debug的时候用的样例数据
data = np.array([[-9.38526262, 2.74797643],
[-11.8458768, 2.06863466],
[-0.84464735, -3.6778601 ],
[-9.55019081, 2.91500874],
[-0.29088953, -4.58059872],
[-0.90988716, -2.43335193],
[-9.82206029, 2.66678343],
[-0.28556052, -3.97549066],
[-1.51725199, -2.53455834],
[-10.6981788, 3.64205984]])
label = np.array([0, 0, 1, 0, 1, 1, 0, 1, 1, 0])
测试一下样例数据
if __name__ == '__main__':n, k = 10, 2data, label = get_data(n, k)cls = Kmeans()fit_label = cls.fit(data=data, k=k)print(label)print(fit_label)
结果
[ 0.87505124 -0.06011619]
[ 0. 0.]
[ 0. 0.]
[0 0 1 0 1 1 0 1 1 0]
[0 0 1 0 1 1 0 1 1 0]
与原先设置的label一模一样,当然,迭代两轮就结束了
为了写代码和调试的方便,我在这里之前都使用了样例数据
def get_data(n, k):# sample data, use in debug'''data = np.array([[-9.38526262, 2.74797643],[-11.8458768, 2.06863466],[-0.84464735, -3.6778601 ],[-9.55019081, 2.91500874],[-0.29088953, -4.58059872],[-0.90988716, -2.43335193],[-9.82206029, 2.66678343],[-0.28556052, -3.97549066],[-1.51725199, -2.53455834],[-10.6981788, 3.64205984]])label = np.array([0, 0, 1, 0, 1, 1, 0, 1, 1, 0])'''data, label = make_blobs(n_samples=n, n_features=2, centers=k)return data, label
加大数据
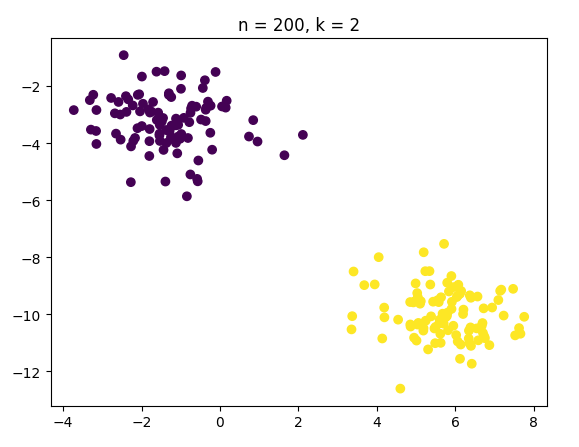
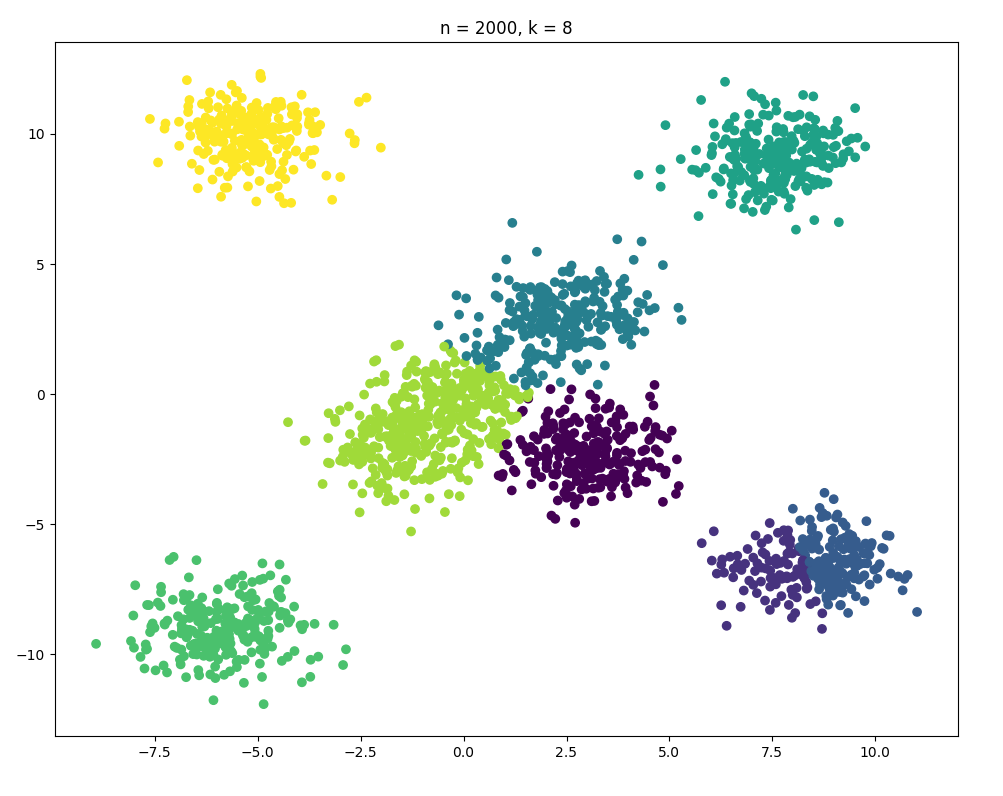
再大我有点担心机器性能了
试一下三维数据
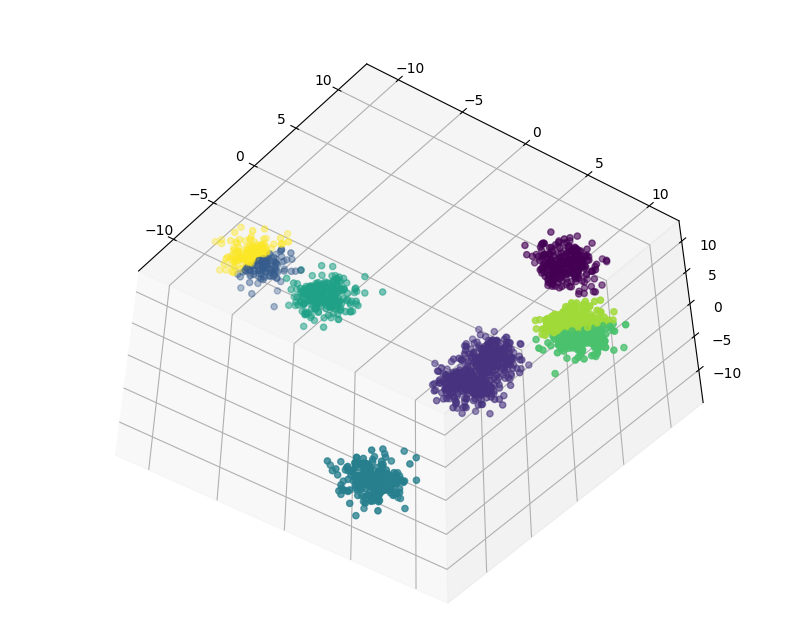
很好,我大概成功造了一个车轮
自动确定k值
不会,抄彭先生的
这里参考了彭先生的方法,其实聚类的k值很大程度上看人的喜好(也就是分几类),我们,就穷举吧= =枚举我们需要的k,然后计算每次的类簇“半径”,取半径之和下降最快的k为我们要的k,在实际应用中,其实这就是个调参的过程
def no_k_fit(self, data):central_dots, radius = [], np.zeros(self.__max_k, np.float32)# 寻找最佳的k值,k值范围在1到max_k之间for k in range(1, self.__max_k):_, distance_group, data_type = self.__fit_k_means(data, k)type_distance = np.min(distance_group, axis=0)central_dots.append(_)# 计算各个簇的半径(中心点到簇中最远的点的距离)之和for idx in range(k):type_data_idx = np.where(data_type == idx)radius[k] += np.max(type_distance[type_data_idx])# 加权求和,k用于抑制radius[k] = np.sqrt(radius[k]) * k# 交叉相减,得出半径之和下降最快的k值,并认定为最佳k值best_k = np.argmax(radius[:self.__max_k-1] - radius[1:])self.__dots = central_dots[best_k]
