@ghimi
2018-05-28T12:45:25.000000Z
字数 28950
阅读 1433
大数据面试总结
大数据 面试
MapReduce 设计模式
- 概要模式
2.1:关于Combiner和paritioner
combiner:reducer之前调用reducer函数,对数据进行聚合,在某些业务需求下可以极大的减少通过网络传输到reducer端的key/value数量,适用的条件是你可以任意的改变值的顺序,并且可以随意的将计算进行分组,同时需要注意的是一个combiner函数只对一个map函数有作用
partitioner:许多概要模式通过定制partitioner函数实现更优的将键值对分发到n个reducer中,着这样的需求场景会比较少,但如果任务的执行时间要求很高,数据量非常大,且存在数据倾斜的情况,定制partitioner将是非常有效的解决方案
Scala隐式转换
使用隐含转换将变量转换成预期的类型是编译器最先使用 implicit 的地方。这个规则非常简单,当编译器看到类型X而却需要类型Y,它就在当前作用域查找是否定义了从类型X到类型Y的隐式定义.
// For implicit conversions like converting RDDs to DataFrames
在 Spark 中会将 RDD 隐式转换为DataFrame
// Encoders for most common types are automatically provided by importing spark.implicits._
一些可能会问到的脚本代码
- flume
# flume 分为三个阶段的配置 source channel sink# flume 可以做一些简单的数据清洗工作flume-ng -c conf -f conf1.conf
- kafka
- sqoop
- hive
之前公司可能用到的资料
关键词:精细化管理系统,医院绩效管理系统,医院信息管理系统,成本核算系统,电子病历系统
管理精细化
“细节决定成败”。医院绩效管理系统的一大功能便是采集HIS系统、PACS系统、LIS系统等中的有关数据,并对这些数据进行分类、归集、汇总、复合计算等。通过医院绩效管理系统,我们可以把每一位医护人员的工作责任具体化、明确化,实时采集他们的工作情况,并对他们的工作成果进行评价,发现问题及时纠正,及时处理。绩效管理系统的应用使得医院实现管理精细化成为可能。
HIS医疗管理系统分为门诊管理、住院管理、医生站、护士站、药房管理、药库管理、物资管理、医技管理、院长财务、和系统管理等模块。具有挂号、门诊收费、住院登记、住院收费、医生处方、患者病历、药房发药、患者退药、请领单、药房退库、药库入库、销售出库、调拨出库和采购退货等管理功能,报表丰富,收费员日报、医生工作量报表、药房出库汇总表、入库汇总报表、药库结存表等等。
监听者模式
享元模式
装饰器模式
工厂模式
单例模式
集群配置
我们使用的平常使用的是测试集群进行代码的编写与测试,
测试集群有5台,8每台8核64G内存每天的数据量大概有80G左右10个字段每个字段大概100Byte 80*1000*1000*1000/100 每天数据量大概6亿条以上通过在浏览器
我对自己的评价
我热衷于新知识,新技术,用于挑战自我,对于新的技术上手能力强。我喜欢浏览开源社区如国外的StackOverflow,github以及国内的码云,开源中国等社区;当我遇到问题时,我比较喜欢上Google,StackOverflow上面搜索相似的问题并且寻求解决方案,或者通过阅读源码,用户手册等了解问题的原因,在解决了问题后,我能够及时的对遇到的问题做归纳总结并且反馈到网上。
关于机器学习
我们之前的项目上面老板说可能要用所以了解了一些相关的知识但实际没有用到
我了解knn,kmeans,逻辑回归算法,线性回归算法,
需要做的事情
对项目流程整个模拟一遍,有一些可能用到的东西必须模拟出来
* 集群有多少台
* hbase中创建了什么表,都有哪些字段,rowKey是怎么设计的
* hive 分区,都写过哪些udf函数
数据脱敏函数
* 有没有遇到过数据倾斜问题,是怎么解决的?
Spark 数据倾斜调优
关于项目部分还需要再重新编写一遍
将事情的时候使用总分总的格式
pv uv 订单量 日活跃量
推荐系统
大数据开发方面的技能:
* 熟练使用Linux 常用的操作命令,熟悉shell脚本编程
修改用户权限: chmod [guo][+rwx] 脚本名称
shell 变量
声明变量:var1
问题
- 你知道哪些常用的linux操作命令:
答:linux操作命令可以分为很多类别,常见的类别有
对系统设备的操作命令如:shutdown,service,ifconfig,netstat,mount,init等
对用户的操作命令如:chmod,chown,useradd,password,sudo,su等
在shell脚本变成中最常用的就是对文件的操作命令了如:sed,grep,awk,test,source,sort,uniq等
#!/bin/bash
flume channel中的数据会不会发生丢失情况?
答: flume是一个日志收集系统,能够将不同源头的数据统一存储到同一个位置去.flume软件架构主要分为3个部分:source,channel以及sink,当source读取数据的能力远远大于sink导出数据的能力,并且channel容量不足时,会停止接收数据.
答: flume是一个分布式,高可靠,高可用性的海量日志采集/聚合和传输的系统.flume可以定制各类数据发送方,用于收集数据;同时flume提供对数据进行简单处理LinkedList与ArrayList的概念,联系与区别,他们是线程安全的吗?
答:LinkedList与ArrayList是List数据类型的两种实现方式。其中LinkedList是List基于链表的数据结构的实现,而ArrayList是实现了基于动态数组的数据结构。他们都不是线程安全的
LinkedList对List的数据类型是使用链表的方式实现的,因此不存在扩容的问题,而ArrayList对List数据类型的实现方式是使用数组的当时实现的,因此当容量不足时,需要对ArrayList进行动态扩容,因此当ArrayList在写入操作比较多的时候,发生的自动扩容操作会影响ArrayList的性能写性能,相对的LinkedList在写操作方面就比较占优势了,而在读操作方面,由于LinkedList的每次读操作需要进行遍历,所以在读操作方面ArrayList比较占优势。
注:more /proc/cpuinfo |grep "physical id"|uniq|wc -l 先查看一下Linux内核数量。
自我介绍
个人信息+需求分析+匹配岗位的特征+逻辑/事例论证+礼貌自信+反复练习=offer
面试官您好,我叫高皓,我毕业于内蒙古大学。之前从事数据清洗和数据分析相关方面的工作。擅长Hive,Spark
很荣幸来到贵公司,希望能够和贵公司共同进步。
面试官您好,我叫高皓,来自内蒙古
毕业于内蒙古大学.现在住在海淀区
今天面试的岗位是大数据开发工程师
之前工作与阿西诺文化科技公司,
最初是从事web开发,后来因为公司业务需求,开始进行数据清洗和数据分析方面的工作
擅长Spark,Hive等框架,之前在项目中主要从事数据清洗和数据分析方面的工作,
很荣幸来到贵公司,非常感谢有机会参加这次面试。
我喜欢去接触新的技术,回去尝试了解并应用这些
大学期间曾今尝试自己做过校园博客,后来因为学习比较紧张所以没有做成功。
平常爱好跑步,打乒乓球,看动漫等- 男生而言,讲话可以稍微低沉一些,语速可以降低,这样显得自信。
- 不做害羞的动作,例如不自觉的玩手指,不敢与面试官眼神交流,眼睛四眼无神等
- 抬头挺胸,目光直视HR
- 轮到自己发言时,眼光顺序:最左-中间-最右-中间 ,时间大概2-3秒,然后再大声的开始自我介绍。这样子的话全场的目光都会聚集在你身上。
进程与线程的概念,和区别
- 基本概念
进程是正在运行的程序的实例(an instanc of a computer program that is being executed) - 组成
- 进程是一个实体,每一个进程都有它自己的地址空间,一般情况下,包括
- 文本区域(text region),文本区域存储处理器执行的代码;
- 数据域(data region) 数据区域存储变量和进程执行期间使用的动态分配的内存;
- 堆栈(stack region).堆栈区域存储着活动过程调用的指令和本地变量
# 文本区域(text region):文本区域存储处理器执行的代码;# 数据域(data region):数据区域存储变量和进程执行期间使用的动态分配的内存;# 堆栈(stack region):堆栈区域存储着活动过程调用的指令和本地变量
- 结构特征:进程有程序,数据和进程控制块三部分组成.
- 状态: 阻塞态,运行态,和就绪态
- 线程的基本概念:一个标准的线程由线程ID,当前指令指针(PC),寄存器集合和堆栈组成。
进程与线程的区别:
进程是正在运行这的程序实例,而线程是进程的一个实体,是被系统独立调度和分派的基本单位,线程自己不拥有系统资源,只拥有一点在运行期间比不可少的资源,但它可与同属一个进程的其他线程共享其所属进程所拥有的全部资源. - 一个线程可以创建和撤销另一个线程,同一个进程的多个线程之间可以并发执行.由于线程之间的相互制约,致使线程在运行中呈现出间断性.线程也有就绪,
进程和线程的区别
(1)地址空间:进程内的一个执行单元;进程至少有一个线程;它们共享进程的地址空间;而进程有自己独立的地址空间;
(2)资源拥有:进程是资源分配和拥有的单位,同一个进程内的线程共享进程的资源
(3)线程是处理器调度的基本单位,但进程不是.
(4)二者均可并发执行.
你在之前的项目中都用到了哪些设计模式?
单例模式,用于生成唯一id
工厂模式
装饰器模式
代理模式
我看你的专业并不是计算机相关专业,怎么的大数据?
是这样的,我在之前的公司一开始是做WEB开发,后来因为公司业务需求,然后跟着项目组开始做大数据.
你们项目组有多少人?
7个人
说说你在你们的项目中主要负责哪些工作?
利用sqoop 将数据导入到hadoop当中
设计将nginx 中的日志通过flume 导入到hadoop 当中
通过hive对hadoop当中的 数据进行清洗,数据仓库的搭建
spark 程序设计
利用 spark mllib 参数调优
HashMap的底层
hashMap是Map的数据类型基于Hash算法的实现形式,它内部的数据构造是数组+链表的方式,在写入数据时,会先计算记录的key的hash值,然后根据当前hashMap的数组大小进行取模,最后根据对应的模值将记录添加到对应数组的链表当中去。
TreeMap的底层
TreeeMap 的实现了NavigatableMap 接口,基于红黑二叉树实现,相对于HashMap,TreeMap实现了基于key的顺序排序,没有实现线程安全,在线程安全的情况下可以使用
Map map = Collections.synchronizedMap(new TreeMap());
实现线程同步或者使用synchronized关键字实现线程安全
jvm的内存模型与垃圾回收机制
jvm的内存模型最大的一块就是运行时数据区,包括方法区,虚拟机栈,本地方法栈和堆和程序计数器。
其中方法区用来保存一些静态的数据和代码,如类加载信息,常量和一些静态变量等,虚拟机栈主要保存局部变量表,操作栈,动态链接等,本地方法栈,堆主要用来保存类的实例对象等。除了运行数据区以外内存模型还包括执行引擎和本地库接口。
jvm的垃圾回收机制
有两种方式,一种是引用计数(但是无法解决循环引用的问题);另一种就是可达性分析。
判断对象可以回收的情况:
显示的把某个引用置位NULL或者指向别的对象
局部引用指向的对象
弱引用关联的对象
栈是运行时的单位,而堆是存储的单位。
java中的引用类型有四种:
强引用类型Strong Reference
软引用类型Soft Reference
弱引用类型Weak Reference WeakHashMap
虚引用类型
jvm垃圾回收的方法:
标记-清除算法;优点是减少停顿时间,缺点是会造成内存碎片
标记-整理算法;可以解决内存碎片的问题,但是会增加停顿时间
复制算法;不涉及到对象的删除,
只是把可用的对象移动到另一个地方,
因此适合大量对象回收的场景,比如新生代的回收
分代收集算法;是前面几种方法的合体,是jvm主要使用的一种垃圾回收的方法;
新生代(Young Generation):用于存放新创建的对象,采用复制回收方法,如果在s0和s1之间复制一定次数后,转移到年老代中。这里的垃圾回收叫做minor GC;
年老代(Old Generation):这些对象垃圾回收的频率较低,采用的标记整理方法,这里的垃圾回收叫做 major GC。
永久代(Permanent Generation):存放Java本身的一些数据,当类不再使用时,也会被回收。
在新生代中,分为三个区:Eden, from survivor, to survior。
当触发minor GC时,会先把Eden中存活的对象复制到to Survivor中;
然后再看from survivor,如果次数达到年老代的标准,就复制到年老代中;如果没有达到则复制到to survivor中,如果to survivor满了,则复制到年老代中。
然后调换from survivor 和 to survivor的名字,保证每次to survivor都是空的等待对象复制到那里的。
jvm垃圾回收器:
Serial 收集器
ParalOld收集器
串行收集器;以单线程的方式收集,垃圾回收的时候其他线程也不能工作
并行收集器;以多线程的方式进行收集
并发标记-清除收集器;大致的流程为:初始标记--并发标记--重新标记--并发清除
G1收集器;初始标记--并发标记--最终标记--筛选回收
RowKey怎么创建比较好?
Rowkey可以实现的功能:
Rowkey的检索方式是字典序Ascii升序排序:可以
保证记录的唯一性:使用hashCode(不能完全保证唯一并且hashCode有可能为负数),md5,uuid,timestamp
通过记录分类有序性实现记录的简单分类:
记录的排序:默认的记录是升序排序,如果需要降序的话可以使用一个足够大的数减去升序排序的rowkey
timestamp即可以在很大程度上保证记录的唯一性,并且可以保证记录按照时间有序,还可以通过年,月,日等方式获取某一个分类确定年月日的数据
具体根据业务场景不同进行设计:
比如在在涉及到用户信息的记录时可以使用用户id作为rowKey实现记录的唯一性,如果需要根据用户的注册时间对用户进行检索的话还可以在用户id前面添加timestamp实现对用户按照时间检索。如果需要检索的数据为降序的话,需要用一个大数减去rowkey
String s = "hello";s = s + "World";//这两行代码执行后,原始的String 对象中的内容到底变了没有,为什么?
答:改变了,String是一种引用的数据类型,
创建的String对象s中保存的是指向"Hello"字符串的指针,当发生赋值后
jvm会将String对象s重新指向生成的常量"Hello World"中。然后就将“Hello”和“ World”这两个常量对象进行回收。
有看过
写过hive的udf,udtf,udaf类函数吗?
创建函数流程:
1. 自定义一个Java类
2. 继承UDF类
3. 重写evaluate方法
4. 打成jar包
5. 在hive中执行add jar方法
6. 在hive中执行创建模板函数
7. hql中使用
我们使用的hive版本为1.2.1,如果不记得了就说软件框架是由我们的大数据架构师选的,具体版本记不太清楚了
将hive启动起来,对hiveudf进行测试
## COUNT、SUM、MIN、MAX、AVGselectuser_id,user_type,sales,--默认为从起点到当前行sum(sales) OVER(PARTITION BY user_type ORDER BY sales asc) AS sales_1,--从起点到当前行,结果与sales_1不同。sum(sales) OVER(PARTITION BY user_type ORDER BY sales asc ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) AS sales_2,--当前行+往前3行sum(sales) OVER(PARTITION BY user_type ORDER BY sales asc ROWS BETWEEN 3 PRECEDING AND CURRENT ROW) AS sales_3,--当前行+往前3行+往后1行sum(sales) OVER(PARTITION BY user_type ORDER BY sales asc ROWS BETWEEN 3 PRECEDING AND 1 FOLLOWING) AS sales_4,--当前行+往后所有行sum(sales) OVER(PARTITION BY user_type ORDER BY sales asc ROWS BETWEEN CURRENT ROW AND UNBOUNDED FOLLOWING) AS sales_5,--分组内所有行SUM(sales) OVER(PARTITION BY user_type) AS sales_6fromorder_detailorder byuser_type,sales,user_id;注意:结果和ORDER BY相关,默认为升序如果不指定ROWS BETWEEN,默认为从起点到当前行;如果不指定ORDER BY,则将分组内所有值累加;关键是理解ROWS BETWEEN含义,也叫做WINDOW子句:PRECEDING:往前FOLLOWING:往后CURRENT ROW:当前行UNBOUNDED:无界限(起点或终点)UNBOUNDED PRECEDING:表示从前面的起点UNBOUNDED FOLLOWING:表示到后面的终点其他COUNT、AVG,MIN,MAX,和SUM用法一样。
hive 中 使用beeline添加udf的方法
create function bigthan as "top.HiveUDF" USING JAR "hdfs://node03:9000/hiveUDF.jar";
java中多用并发集合少用同步集合
并发集合:CocurrentHashMap
同步集合:Collections.synchronizedMap(new HashMap());
集合排序:Collections.sort(arrayList);
截止目前依赖,我们用大数据做的数据分析:
单词统计:WordCount
求天气的最高值,平均值等:Temperature
好友推荐:Friend of Friend
基于物品的协同过滤算法:itemcf,(商品同现矩阵)
页面重要程度统计:tf-idf
pv值uv值统计
交通状况预测:逻辑回归算法
商品的推荐:逻辑回归算法推荐系统
hadoop项目:根据不同维度统计页面的信息
我看到你的项目中用到了推荐系统,你们的推荐系统是怎么设计的?
答:项目中用到的推荐系统是基于协同过滤算法实现的,协同过滤算法的实现方式有两种,一种是基于用户的协同过滤算法,是根据不同用户之间对于物品的偏好程度的相似性来计算用户之间的相似度,另一种是基于物品的协同过滤算法,是根据物品与物品之间的同现次数为基础来计算物品之间的相似程度的。虽然这两种算法各有利弊,但是算法之间可以互补,所以我们的系统以基于物品的协同过滤算法为主兼顾了基于用户的协同过滤算法,当用户没有登录或者无法获取到用户肖像时,我们一基于物品的协同过滤为主;当用户发生登录行为或者说我们可以获得用户肖像时,我们以基于用户的协同过滤为主
实现协同过滤算法,需要以下几个步骤:
* 收集用户偏好
* 找到相似的用户或物品
* 计算推荐
根据用户对网页的操作行为计算用户偏好
对不同的用户行为进行分组,根据不同的用户行为反映用户的喜好程度将它们进行加权,得到用户对物品的总的喜好。一般来说,显示的用户行为比隐式地用户行为权值大,但比较稀疏,
对用户行为数据进行降噪,和归一化
相似度的计算:
欧几里得距离算度
余弦距离算度
皮尔逊相关系数
相似邻居的计算:
基于固定数量的邻居的相似邻居计算:计算得到的邻居个数确定,但是容易受到孤立点的影响
基于相似度门槛的邻居计算:计算得到的邻居个数不确定,但是相似度不会出现较大的误差
基于物品的协同过滤算法要比基于用户的协同过滤算法更优主要是由于数据的特征,对于一个在线网站,用户的数量往往大于物品的数量,同时物品的数据也比较稳定,因此计算物品的相似度不但计算量较小,同时也不必频繁更新。
对于新闻,博客或者微内容的推荐系统,情况往往是相反的,物品的数量是海量的,同时也是更新频繁的,所以但从复杂度的角度,这两个算法在不同的系统中各有优势,推荐系统引擎的设计者需要根据自己应用的特点选择更加适合的算法
基于物品的协同过滤算法
- 学习java类加载机制
- 学习几种gc垃圾回收器
Hadoop与Spark的输入输出
Java 基础知识
- String,StringBuilder,StringBuffer区别 String 是否可变 StringBuilder,StringBuffer哪个线程安全,哪个线程不安全
答:String 是字符串常量,StringBuilder 和StringBuffer 是字符串变量,String因为是常量所以不可变StringBuilder是不是线程安全的,StringBuffer是线程安全的。简要的说,String 类型和StringBuffer 类型的主要性能区别其实在于String 是不可变对象,因此在每次对String 类型 进行改变的时候其实都等于生成了一个新的String 对象,然后将指针指向新的String对象,所以经常改变内容的字符串最好不要使用String 类型,因为每次生成对象都会对系统的性能产生影响,特别当内存中无引用对象多了以后,JVM的GC就会开始工作,那速度一定会相当慢的。
而如果是使用StringBuffer类则结果就不一样了,每次都会对StringBuffer对象本身进行操作,而不是生成新的对象,再改变对象引用。所以在一般情况下我们推荐使用StringBuffer,特别是字符串对象经常改变的情况下。而在某些特别情况下, String 对象的字符串拼接其实是被 JVM 解释成了 StringBuffer 对象的拼接,所以这些时候 String 对象的速度并不会比 StringBuffer 对象慢,而特别是以下的字符串对象生成中, String 效率是远要比 StringBuffer 快的;
StringBuffer
Java.lang.StringBuffer线程安全的可变字符序列。一个类似于 String 的字符串缓冲区,但不能修改。虽然在任意时间点上它都包含某种特定的字符序列,但通过某些方法调用可以改变该序列的长度和内容。将字符串缓冲区安全地用于多个线程。可以在必要时对这些方法进行同步,因此任意特定实例上的所有操作就好像是以串行顺序发生的,该顺序与所涉及的每个线程进行的方法调用顺序一致。
StringBuffer 上的主要操作是 append 和 insert 方法,可重载这些方法,以接受任意类型的数据。每个方法都能有效地将给定的数据转换成字符串,然后将该字符串的字符追加或插入到字符串缓冲区中。append 方法始终将这些字符添加到缓冲区的末端;而 insert 方法则在指定的点添加字符。
运行速度 StringBuilder > StringBuffer > String
线程安全 StringBuilder是线程不安全的,而StringBuffer是线程安全的
string不可变
HashMap 和 HashTable 有什么区别?
(1) Hashtable继承自Dictionary类,而HashMap继承自AbstractMap类。但二者都实现了Map接口。
(2)线程安全性不同,HashTable使用了Synchronize。
(3)HashMap把Hashtable的contains方法去掉了,改成containsValue和containsKey (4)Hashtable中,key和value都不允许出现null值
(5)Hashtable、HashMap都使用了 Iterator。而由于历史原因,Hashtable还使用了Enumeration的方式
(6)哈希值的使用不同,HashTable直接使用对象的hashCode。而HashMap重新计算hash值。
(7)HashTable在不指定容量的情况下的默认容量为11,而HashMap为16,Hashtable不要求底层数组的容量一定要为2的整数次幂,而HashMap则要求一定为2的整数次幂。Hashtable扩容时,将容量变为原来的2倍加1,而HashMap扩容时,将容量变为原来的2倍。
网络分层结构:

基于TCP/IP协议族的网络,被分为四层,分别为应用层,传输层,网际层以及网络接口层,每一层都设计了相应的协议,我们常用的一些协议(如HTTP,FTP等),都是属于应用层协议,他们大多是基于传输层的TCP,UDP设计出来的。
我们的主角Socket,它是应用层之下,传输层之上的一个接口层,也就是操作系统提供给用户访问网络的系统接口,我们可以借助于Socket接口层,对传输层,网际层以及网络接口层进行操作,来实现我们不同的应用层协议,举几个例子,如HTTP是基于TCP实现的,ping和tracerouter是基于ICMP实现的,libpcap(用wireshare做过网络抓包的可能更熟悉)则是直接读取了网络接口层的数据,但是他们的实现,都是借助于Socket完成的。可见,对于应用层,我们想实现网络功能,归根究底都是要通过Socket来实现的,否则,我们无法访问处于操作系统的传输层,网际层以及网络接口层。考虑的本文以及本文之后的其他文章,我们暂时只关注Socket访问传输层的流程,其他的方面可以参看相关书籍,这里推荐《TCP/IP详解 卷一》以及《UNIX网络编程》(UNP),虽然是Linux C语言开发的书,但是对网络编程讲解的很透彻。这里也向这位大家致敬,虽英年早逝,留给大家的财富不可估量。
再来了解一下TCP和UDP,两者最大的区别在于,TCP是可靠的,也就是说,我们通过TCP发送的数据,网络协议栈会保证数据可靠的传输到对端,而UDP是不可靠的,如果出现丢包,协议栈不会做任何处理,可靠性的保证交由应用层处理。因此,TCP的性能会比UDP低,但是可靠性会比UDP好很多。除此之外,两者在传输数据时,也有形式上的不同,TCP的数据是流,大家可以类比文件流,而UDP则是基于数据包,也就是说数据会被打成包发送,可能大家会有疑问,这个有什么差别吗?当然有,一个最大的问题就是,TCP没有数据边界,每次接收数据以字节为单位,如果想区分两次发送的数据,除非在数据中加入分割字符(如http的\r\n\r\n),否则,TCP无法区分数据边界,而UDP每次发送的数据都被打为一个独立的数据包,因此几次发送的数据边界很清晰,我们每次接收也是按照数据包为单位进行接收。对于不同的编程语言或平台,虽然Socket的接口可能不同,但是都提供了基于TCP发送数据的接口以及基于UDP发送数据的接口。另外,还有一个概念,对于一个Socket以客户端的IP及端口号<=>服务器端的IP以及端口号唯一标识。由于后面几篇文章基本上都是基于TCP的,所以这里为了让大家知道Socket是个什么东西,先以UDP为例,后面再详细了解基于TCP的Socket编程。我们使用Java Socket,基于UDP协议,实现字母的大写转换,整个流程是客户端发送字符串给服务器,服务器将字符串转换为全部大写后,发送回客户端,客户端进行显示。
单例模式
需要编写一个类,确保这个类只会产生一个对象实例
默认构造器为私有,当构造器为私有时,
就不能够使用new 方法去创建实例对象了,否则会报构造器不可见异常
The constructor Singleton() is not visible
时候在这个类中声明方法确保该方法只能够创建一个唯一可用的实例对象:
非线程安全的方式有:
* 懒汉模式(非线程安全)
public class Singleton {private static Singleton instance;private Singleton (){}public static Singleton getInstance() {if (instance == null) {instance = new Singleton();}return instance;}}
- 懒汉模式(通过同步方法来保证线程安全)
public class Singleton {private static Singleton instance;private Singleton (){}public static synchronized Singleton getInstance() {if (instance == null) {instance = new Singleton();}return instance;}}
- 饿汉模式,通过classloader的方式解决了线程安全问题
public class Singleton {private static Singleton instance = new Singleton();private Singleton (){}public static Singleton getInstance() {return instance;}}
单例模式 dcl(double checked lock)
class Singleton{private volatile static Singleton instance;private Singleton(){}public static Singleton getInstance() {if(instance == null) {synchronized(Singleton.class) {if(instance == null)instance = new Singleton();}}return instance;}}
单例模式 同步方法
class Singleton{private static Singleton instance;private Singleton() {}public static synchronized Singleton getInstance() {if(instance == null) {instance = new Singleton();}return instance;}}
单例模式 静态内部类
class Singleton{private static class SINGLETONHolder{private static final Singleton INSTANCE = new Singleton();}private Singleton() {}public static final Singleton getInstance() {return SINGLETONHOLDER.INSTANCE;}}
什么是java静态同步
所有的非静态同步方法用的都是同一把锁——实例对象本身,也就是说如果一个实例对象的非静态同步方法获取锁后,该实例对象的其他非静态同步方法必须等待获取锁的方法释放锁后才能获取锁,可是别的实例对象的非静态同步方法因为跟该实例对象的非静态同步方法用的是不同的锁,所以毋须等待该实例对象已获取锁的非静态同步方法释放锁就可以获取他们自己的锁。
而所有的静态同步方法用的也是同一把锁——类对象本身,这两把锁是两个不同的对象,所以静态同步方法与非静态同步方法之间是不会有竞态条件的。但是一旦一个静态同步方法获取锁后,其他的静态同步方法都必须等待该方法释放锁后才能获取锁,而不管是同一个实例对象的静态同步方法之间,还是不同的实例对象的静态同步方法之间,只要它们同一个类的实例对象!
HBase 读写优化
递归的方式实现二分查找
传入参数:
* 整个数组
* 要查找的数
* 开始查找的位置
* 结束查找的位置
查找异常的情况:
* 当查找的数小于有序数组的最小值
* 当查找的数大于有序数组的最大值
* 开始查找的位置大于结束查找的位置(整个数组查找完毕)
public static int binarySearch(int[] dataset,int data,int beginIndex,int endIndex) {int middle = (beginIndex+endIndex)/2;if(data < dataset[beginIndex] || data > dataset[endIndex] || beginIndex > endIndex)return -1;//查找异常的情况,返回-1if(data < dataset[middle])return binarySearch(dataset,data,beginIndex,middle-1);//向左半部分查找else if (data > dataset[middle])return binarySearch(dataset, data, middle+1, endIndex);//向右半部分查找else return middle;}
1.synchronized与static synchronized 的区别
synchronized是对类的当前实例进行加锁,防止其他线程同时访问该类的该实例的所有synchronized块,注意这里是“类的当前实例”, 类的两个不同实例就没有这种约束了。那么static synchronized恰好就是要控制类的所有实例的访问了,static synchronized是限制线程同时访问jvm中该类的所有实例同时访问对应的代码快。实际上,在类中某方法或某代码块中有synchronized,那么在生成一个该类实例后,改类也就有一个监视快,放置线程并发访问改实例synchronized保护快,而static synchronized则是所有该类的实例公用一个监视快了,也也就是两个的区别了,也就是synchronized相当于 this.synchronized,而static synchronized相当于Something.synchronized.
一个日本作者-结成浩的《java多线程设计模式》有这样的一个列子:
pulbic class Something(){public synchronized void isSyncA(){}public synchronized void isSyncB(){}public static synchronized void cSyncA(){}public static synchronized void cSyncB(){}}
那么,加入有Something类的两个实例a与b,那么下列组方法何以被1个以上线程同时访问呢
a. x.isSyncA()与x.isSyncB()
b. x.isSyncA()与y.isSyncA()
c. x.cSyncA()与y.cSyncB()
d. x.isSyncA()与Something.cSyncA()
这里,很清楚的可以判断:
a,都是对同一个实例的synchronized域访问,因此不能被同时访问
b,是针对不同实例的,因此可以同时被访问
c,因为是static synchronized,所以不同实例之间仍然会被限制,相当于Something.isSyncA()与 Something.isSyncB()了,因此不能被同时访问。
那么,第d呢?,书上的 答案是可以被同时访问的,答案理由是synchronzied的是实例方法与synchronzied的类方法由于锁定(lock)不同的原因。
个人分析也就是synchronized 与static synchronized 相当于两帮派,各自管各自,相互之间就无约束了,可以被同时访问。目前还不是分清楚java内部设计synchronzied是怎么样实现的。
结论:A: synchronized static是某个类的范围,synchronized static cSync{}防止多个线程同时访问这个 类中的synchronized static 方法。它可以对类的所有对象实例起作用。
B: synchronized 是某实例的范围,synchronized isSync(){}防止多个线程同时访问这个实例中的synchronized 方法。
2.synchronized方法与synchronized代码快的区别
synchronized methods(){} 与synchronized(this){}之间没有什么区别,只是 synchronized methods(){} 便于阅读理解,而synchronized(this){}可以更精确的控制冲突限制访问区域,有时候表现更高效率。
3.synchronized关键字是不能继承的
我想这一点也是很值得注意的,继承时子类的覆盖方法必须显示定义成synchronized
java 中类加载过程
- 加载
加载class字节码到内存,并且提供对应的入口 - 链接
- 校验格式和数据结构
- 默认初始化
- 加载框架入口
- 显式初始化
java 中创建一个变量的过程
Student s = new Student();
- 在栈中创建s变量(开辟空间)
- 在对中创建Student()对象(开辟空间)
- 默认初始化Student对象(对象初始化)
- 显示初始化Student对象(对象初始化)
- 通过构造方法对Student的对象的成员变量赋值
- 将Student对象赋值给s
java中反射的实现方式
Foo foo = new Foo();//第一种:通过Object类的getClass方法Class cla = foo.getClass();//第二种:通过对象实例方法获取对象Class cla = foo.class;//第三种:通过Class.forName方式Class cla = Class.forName("xx.xx.Foo");//对于有空构造器函数的类,可以直接用字节码文件获取实例:Object o = clazz.newInstznce(); //会调用空参构造器 如果没有则会报错//对于没有空的构造函数的类则需要先获取到他的构造对象 再通过该构造方法获取实例Consutructor constroctor =clazz.getConxtruxtor(String.class,int.class);//先获取构造函数Object obj = constroctor.newInstance("jack",18);//通过构造器对象的newInstance 方法进行对象的初试化
HashMap实现put方法
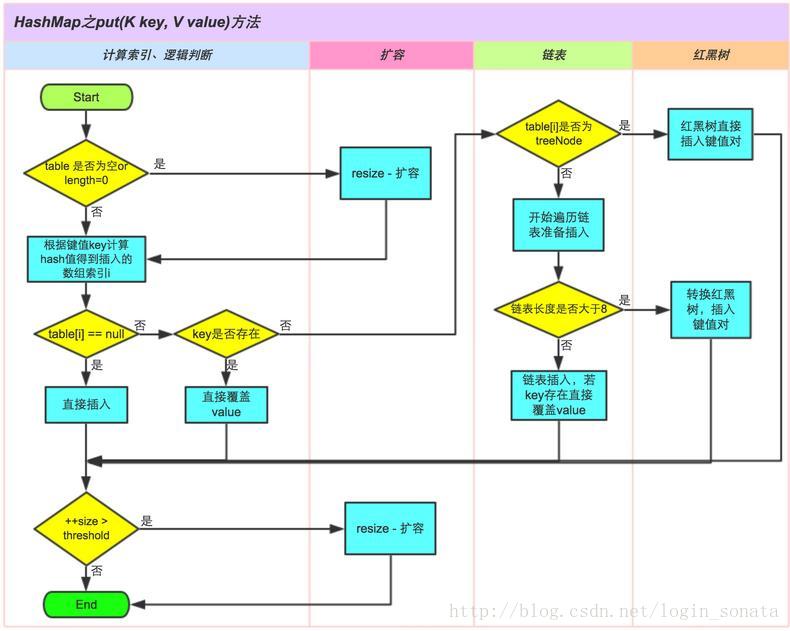
HashMap是通过"拉链法"实现的哈希表。它包括几个重要的成员变量:table, size, threshold, loadFactor, modCount。
- table是一个Entry[]数组类型,而Entry实际上就是一个单向链表。哈希表的"key-value键值对"都是存储在Entry数组中的。
- size是HashMap的大小,它是HashMap保存的键值对的数量。
- threshold是HashMap的阈值,用于判断是否需要调整HashMap的容量。threshold的值="容量*加载因子",当HashMap中存储数据的数量达到threshold时,就需要将HashMap的容量加倍。
- loadFactor就是加载因子。
- modCount是用来实现fail-fast机制的。
你们的kafka是怎么分区的?
在创建Topic时候可以使用–partitions <numPartitions>指定分区数。也可以在server.properties配置文件中配置参数num.partitions来指定默认的分区数。
但有一点需要注意,为Topic创建分区时,分区数最好是broker数量的整数倍,这样才能是一个Topic的分区均匀的分布在整个Kafka集群中,假设我的Kafka集群由4个broker组成
1. 跟kafka的集群数量相关;
2. 跟producer 生产者生产数据的速度有关
3. 跟comsumer 消费者消费数据的速度有关
当分区数量过多的时候,consumer 段需要维护的offset的数量也会相应增多
kafka消息分区内有序,分区间无序
当需要topic的消费的数据有序的时候,需要将分区数量设置为一个默认的分区数量为一个,因为软件无法直接判断集群数量.而分区的数量跟集群的数量有很大关系
CAST函数用于将某种数据类型的表达式显式转换为另一种数据类型
SparkStreaming 编程
Redis持久化
RDB 持久化可以在指定的时间间隔内生成数据集的时间点快照(point-in-time snapshot)。
AOF 持久化记录服务器执行的所有写操作命令,并在服务器启动时,通过重新执行这些命令来还原数据集。
相对于 AOF 持久化方式,RDB 持久化,恢复的速度比AOF方式恢复速度快,但RDB持久化方式可能会出现时间段内的数据丢失的问题.
AOF 在数据丢失的情况下丢失数据量要远远小于RDB持久化方式.但AOF持久化产生的文件要比RDB 持久化产生的文件要大.append only log
hive order by;sort by;cluster by;distributed by之间的区别
- order by
order by 会对输入做全局排序,因此只有一个reducer(多个reducer无法保证全局有序)只有一个reducer,会导致当输入规模较大时,需要较长的计算时间。
set hive.mapred.mode=nonstrict; (default value / 默认值)
set hive.mapred.mode=strict;
order by 和数据库中的Order by 功能一致,按照某一项 & 几项 排序输出。
与数据库中 order by 的区别在于在hive.mapred.mode = strict 模式下 必须指定 limit 否则执行会报错。
hive> select * from test order by id;FAILED: Error in semantic analysis: 1:28 In strict mode, if ORDER BY is specified, LIMIT must also be specified. Error encountered near token 'id'
原因: 在order by 状态下所有数据会到一台服务器进行reduce操作也即只有一个reduce,如果在数据量大的情况下会出现无法输出结果的情况,如果进行 limit n ,那只有 n * map number 条记录而已。只有一个reduce也可以处理过来。
sort by
sort by不是全局排序,其在数据进入reducer前完成排序.
因此,如果用sort by进行排序,并且设置mapred.reduce.tasks=1, 则sort by只保证每个reducer的输出有序,不保证全局有序。
sort by 不受 hive.mapred.mode 是否为strict ,nostrict 的影响
sort by 的数据只能保证在同一reduce中的数据可以按指定字段排序。
使用sort by 你可以指定执行的reduce 个数(set mapred.reduce.tasks=<number>),对输出的数据再执行归并排序,即可以得到全部结果。
注意:可以用limit子句大大减少数据量.使用limit n后,传输到reduce端(单机)的数据记录数就减少到n*(map个数)。否则由于数据过大可能出不了结果。distribute by
按照指定的字段对数据进行划分到不同的输出reduce / 文件中。
insert overwrite local directory '/home/hadoop/out' select * from test order by name distribute by length(name);
此方法会根据name的长度划分到不同的reduce中,最终输出到不同的文件中.length 是内建函数,也可以指定其他的函数或这使用自定义函数- Cluster By
cluster by 除了具有distribute by的功能外还兼具sort by的功能.但是排序只能是倒序排序,不能指定排序规则为asc 或者desc。
flume 的source源
org.apache.flume.source.SpoolDirectorySource是flume的一个常用的source,这个源支持从磁盘中某文件夹获取文件数据。不同于其他异步源,这个源能够避免重启或者发送失败后数据丢失。flume可以监控文件夹,当出现新文件时会读取该文件并获取数据。当一个给定的文件被全部读入到通道中时,该文件会被重命名以标志已经完成。同时,该源需要一个清理进程来定期移除完成的文件。
exec source源使用tail -f 去读取nginx 上面的日志
Spark Core 与Spark Streaming的区别
Spark Core 的工作,解析RDD 调度RDD 容错 Shuffle
Spark Streaming 的工作
Spark 宽窄依赖是什么
Spark 本身一个流式计算框架,依托DAG有向无环图将 Job 切分为一个个的 Stage,而将 Job 切分为 Stage 的依据就是前后RDD之间的宽窄依赖关系,当 RDD 之间的依赖为宽依赖时,会出现 Shffle 的过程;而RDD 之间的窄依赖关系不会出现 Shuffle 过程。一个Stage中的RDD之间的关系都是窄依赖关系,Stage之间的前后RDD都是宽依赖关系。在Spark的编程有一个原则是尽量避免计算过程中出现shuffle的过程,依旧是避免RDD之间出现宽依赖关系从而增加计算时间。
数据来源
网站访问日志js jdk,app sdk
客户行为数据
订单信息,需要多做副本
网站日访问量:
如果是200万PV,那么每天的独立访客,大概是15万左右;
算不错吧,京东之类的,都是上千万、上亿的。
1M 数据 大概 10 个字段 为 1万条记录
80G 数据
数据仓库分层
. 数据来源层→ ODS层
这里其实就是我们现在大数据技术发挥作用的一个主要战场。 我们的数据主要会有两个大的来源:
业务库,这里经常会使用 Sqoop 来抽取,比如我们每天定时抽取一次。在实时方面,可以考虑用 Canal 监听 Mysql 的 Binlog,实时接入即可。
埋点日志,线上系统会打入各种日志,这些日志一般以文件的形式保存,我们可以选择用 Flume 定时抽取,也可以用用 Spark Streaming 或者 Storm 来实时接入,当然,Kafka 也会是一个关键的角色。
Hive 的一些hql语句
- hive查表并将结果导入到不同的文件当中
按照指定的字段对数据进行划分到不同的输出reduce / 文件中。
当设定的reducer的个数只有1个的时候,只输出1个文件,会按照指定的字段进行分类排序,然后所有的key输出到一个文件当中。
当设定的reducer的个数为多个的时,指定的字段中的key会均匀的(一个文件中会有多个key,不同文件中不可能出现相同的key)分布在这些reducer输出的文件当中。当reducer的个数大于key的个数的时候,不同的key的记录会以相同的key为一组每个key置于一个reducer中,并且每一个key对应一个文件,多出来的reducer 不进行任何操作并且输出一个空的文件。
可以通过命令set mepred.reduce.tasks=10来设置reducer的个数,当前输出了10个
如果想要均匀的每个key对应一个文件的话,可以先用命令去获取对应字段具有多少个key,然后按照key的个数去设置reducer的个数,如果不同的key的记录的个数差异很大的话,就有可能会产生数据倾斜问题。
insert overwrite local directory '/home/hadoop/out'select * from test order by name distribute by length(name);
此方法会根据name的长度划分到不同的reduce中,最终输出到不同的文件中。
length 是内建函数,也可以指定其他的函数或这使用自定义函数。
Hive 做子查询的时候需要将子查询放在最前面,并且重新定义一个表名
from (select count(*) from table_name1) as tempselect * from temp
from (select * from table_name2) as tempinsert overwrite into table table_name3select field1,field2,field3,field4where field1 is not null;
插入方式有两种,一种是overwrite,另一种是append
插入的位置目前遇到的有两种,一种是插入一张表当中,另外一种是导出到文件中,可以导出的本地文件当中,还可以导出到hdfs当中
###示例
操作的表名称:ghimi_stu_info_detail
字段:
+---------------+------------+----------+--+
| col_name | data_type | comment |
+---------------+------------+----------+--+
| id | string | |
| area_id | string | |
| name | string | |
| chinese | smallint | |
| arts_math | smallint | |
| science_math | smallint | |
| english | smallint | |
| arts | smallint | |
| science | smallint | |
| oral | smallint | |
| listening | smallint | |
| total | int | |
| test_time | string | |
| create_time | string | |
| update_time | string | |
| delete_time | string | |
| meng | smallint | |
| meng_chinese | smallint | |
| meng_english | smallint | |
| japanese | smallint | |
| meng_yi | int | |
| russian | smallint | |
| eng_chi | smallint | |
+---------------+------------+----------+--+
查询不同length(name)名字长度的key的个数
from (select count(*)from ghimi_stu_info_detailgroup by length(name)) as tempselect count(*);
Hive 动态分区
Hive分区是在创建表的时候用Partitioned by关键字定义的,但要注意,Partitioned by子句中定义的列是表中正式的列,但是Hive下的数据文件中并不包含这些列,因为它们是目录名。
但是在查询的过程中会将分区的列显示出来。
启动动态分区功能:
set hive.exec.dynamic.partition=true;
# 静态导入分区数据 本地load data local inpath '/root/data/par_tab.txt' into table par_tab partition(sex='woman');# 查询分区数据select * from par_tab where sex='woman';# 创建包含多个分区的表create table par_tab_muilt (name string, nation string) partitioned by (sex string,dt string) row format delimited fields terminated by ',' ;#将数据导入这张表中load data local inpath '/home/hadoop/files/par_tab.txt' into table par_tab_muilt partition (sex='man',dt='2017-03-29');
可见,新建表的时候定义的分区顺序,决定了文件目录顺序(谁是父目录谁是子目录),正因为有了这个层级关系,当我们查询所有man的时候,man以下的所有日期下的数据都会被查出来。如果只查询日期分区,但父目录sex=man和sex=woman都有该日期的数据,那么Hive会对输入路径进行修剪,从而只扫描日期分区,性别分区不作过滤(即查询结果包含了所有性别)。
Dynamic partition strict mode requires at least one static partition column.
To turn this off set hive.exec.dynamic.partition.mode=nonstrict (state=42000,code=10096)
要想关闭严格模式使用set hive.exec.dynamic.partition.mode=nostrict;
分区列并不包含在文件中,它们以文件目录的形式显示出来,当查询的时候也能够在对应的列中显示出来,分区可以定义多个列,这些列在前后定义时候的顺序会影响目录的结构层次,具体表现为最先声明的分区列位于一级目录,依次往下,分区列不断延伸成多级目录。
注意,动态分区不允许主分区采用动态列而副分区采用静态列,这样将导致所有的主分区都要创建副分区静态列所定义的分区。
动态分区可以允许所有的分区列都是动态分区列,但是要首先设置一个参数hive.exec.dynamic.partition.mode :
删除分区
ALTER TABLE table_Name DROP PARTITION (Datekey='2016-05-05');
一些动态分区的参数:
set hive.exec.dynamic.partition=true;(可通过这个语句查看:set hive.exec.dynamic.partition;)set hive.exec.dynamic.partition.mode=nonstrict;SET hive.exec.max.dynamic.partitions=100000;(如果自动分区数大于这个参数,将会报错)SET hive.exec.max.dynamic.partitions.pernode=100000;
为什么离职
家里有事,回家处理了一些事情,在家里呆了一段时间.然后来到寻求工作机会.
为什么要来北京
觉得北京在大数据技术方面的发展空间比较大,未来希望能够在北京有所成就.
能够手写单链表反转
单链表的定义
class ListNode{int val;ListNode next;ListNode(int x){val = x;}}
思路:
1. 定义两个临时列表节点为前临时节点prev与后临时节点curr
2. 最初的prev为null
3. 保存curr的下一个节点为temp
4. 将curr指向prev
5. 将prev等于curr
6. 将curr等于temp
7. 从第3步开始重复操作,直到curr的指向为null为止
8. 返回前临时节点
//单链表翻转的循环迭代代码public static ListNode reverseListNode(ListNode head) {ListNode prev = null;while(head != null) {ListNode temp = head.next;head.next = prev;prev = head;head = temp.next;}return head;}
垃圾回收算法
类加载机制
思路:
- 创建临时变量 curr
- 判断curr是否为空链表,或者是链表的尾部,如果是的话,返回curr
递归调用结束的出口,这里要判断当前curr 节点是否能够执行下面的代码,
比如curr.next 不能为null 否则的话curr.next.next就会报错
还有curr 如果为null 的话,不仅 curr.next.next 会报错,
而且下一条代码 curr.next 也会报错 - 递归调用本身,传入参数为 curr.next
- curr 的下一个节点指向curr
- curr 指向空
- 返回 递归调用的结果,这个结果只用来递归下一个节点,除此之外没有其他作用
//单链表反转的递归实现代码public ListNode reverseList(ListNode head) {//递归调用的出口if(head == null || head.next == null)return head;//递归调用的入口,prev 不做判断只用来递归ListNode prev = reverseList(head.next);//递归的head.next.next = head;head.next = null;return prev;}
插入排序
将排序数组分为已经排好序的数组的部分和没有排好序的部分,然后依次将没有排序的元素在排好序的部分中迭代比较,找到其对应的有序的位置,并且插入.
* 链表数组的话直接插入即可
* 有序数组的话可以在比较的过程中进程中交换节点位置
public static void insertSort(int[] array) {for (int i = 1; i < array.length; i++) {for (int j = i; j > 0; j--) {if(array[j-1] > array[j]) {int temp = array[j-1];array[j-1] = array[j];array[j] = temp;}}}}
能够说出web 开发过程中用到的几种框架的优劣
WordCount 天气排序 好友推荐 Friend of Friend
Spark中有没有遇到过oom的情况,你是怎么解决的?
Spark 的oom 问题?? shuffle 的时候
说说你在工作当中遇到的设计模式?
在web 开发当中用的最常用的设计模式就是 mvc 设计模式了,MVC 设计模式用一种业务逻辑、数据、界面显示分离的方法组织代码,将业务逻辑、数据、界面显示分离的方法组织代码,将业务逻辑聚集到一个部件里面,在改进和个性化定制界面及用户交互的同时,不需要重新编写业务逻辑.在我们之前的医院信息管理系统当中,我们需要根据不同的医院具体的需求去定制我们的系统,通过mvc设计模式使得我们在修改需求的时候结构更为清晰.比如不同医院之间的门诊流程不同,但底层的调用数据的行为大致一致,这时候我们只需修改对应的业务逻辑层和界面就可以实现医院的门诊流程定制了.
单例模式,包括线程安全的类型和非线程安全的类型.
工厂模式.
装饰器模式.
什么是面向对象?
是一种编程思想.相对于面向过程的编程而言,面向对象的编程更适合于软件工程中软件的软件的设计.面向对象的编程主要的特征有:封装,多态和继承.
- 封装,即隐藏对象的属性和实现细节,仅对外公开接口,控制在程序中属性的读和修改的访问级别;将抽象得到的数据和行为(或功能)相结合,形成一个有机的整体,也就是将数据与操作数据的源代码进行有机的结合,形成“类”,其中数据和函数都是类的成员。
- 继承是指一个对象直接使用另一对象的属性和方法。
- 在面向对象语言中,接口的多种不同的实现方式即为多态
hibernate mybatis
关于Java的面试题:
- HashMap的底层:
HashMap是基于哈希表的Map接口的非同步实现(HashTable跟HashMap很像,唯一的区别是HashTable是线程安全的,也就是同步的)。 此实现提供所有可选的映射操作,并允许使用null值和null键。此类不保证映射的顺序,特别是它不保证该顺序恒久不变.
在Java编程语言中,最基本的结构就是两种,一种是数组,另外一种是模拟指针(引用),所有的数据结构都可以用这两种基本结构来构造的,HashMap也不例外.HashMap实际上是一个"链表的数组"的数据结构,每个元素存放链表头结点的数组,及数组和链表的结合体.
kafka 创建分区的默认分区数量是多少?
答:默认为1个分区数量,也即默认的kafka创建的topic的读写顺序是有序的.
我自己的经历
2015年7月份开始实习之后一直在那家公司工作到18年4月份底,因为家里有点事辞职回家呆了一段时间,觉得北京的大数据行业发展前景比较好所以来到了北京.
在之前的公司一开始是在做web开发,后来公司项目要整合大数据,所以跟着开始借助进行hive数据清洗,然后开始做spark的数据分析,开始写spark程序.我现在比较擅长的有Hive和HBase的系统架构,能使用Hive进行海量数据的统计分析,精通Spark体系架构,熟悉SparkCore,SparkSQL,SparkStreaming,读过Spark的部分核心源代码
2016年毕业但由于挂科,所以2017年才拿到毕业证
最初的web 项目为医院信息管理系统
设计项目
2017.7-2018.4
* 智慧社区项目
智慧社区通过建立线上社区,涉及智慧物业管理,电子商务服务,智慧养老服务等模块,旨在为用户提供一个安全,舒适,遍历的现代化,智慧化生活环境,从而形成基于信息化、智能化社会管理与服务的一种新的管理形态的社区。
我这个项目主要负责了数据清洗,推荐系统设计
2017.2-2017.7
* 阿西诺大数据分析平台
公司运行时间过程中会产生大量的日志数据,现在有需求将这些数据进行汇总,统计并进行分析,并且以报表的形式展现出来.
这个项目特点是离线数据和历史数据比较多,需要对大量的数据通过定时任务进行清洗和统计分析,所以主要用到的软件有hadoop mapreduce 和hive,通过sqoop将关系型数据库的数据导入到hadoop当中,通过flume 收集服务器产生的日志数据,然后通过mapreduce 对数据进行清洗,然后使用hive对清洗后的数据进行分析,最后将结果导入到mysql中通过前端进行展示
埋点日志,线上系统会打入各种日志
2016.7-2017.2
* 医院信息管理系统
HIS医疗管理系统分为门诊管理、住院管理、医生站、护士站、药房管理、药库管理、物资管理、医技管理、院长财务、和系统管理等模块。
这个项目我主要参与了业务逻辑的设计,并参与后端业务逻辑开发等工作.
基于物品的协同过滤和基于内容的协同过滤有什么区别?
你的问题是否是:基于物品的协同过滤和内容过滤有什么区别?基于物品的协同过滤,首先从数据库里获取他之前喜欢的东西,然后从剩下的物品中找到和他历史兴趣近似的物品推荐给他。核心是要计算两个物品的相似度。内容过滤的基本思想是,给用户推荐和他们之前喜欢的物品在内容上相似的其他物品。核心任务就是计算物品的内容相似度。可以注意到两者的相同点都是要计算两个物品的相似度,但不同点是前者是根据两个物品被越多的人同时喜欢,这两个物品就越相似,而后者要根据物品的内容相似度来做推荐,给物品内容建模的方法很多,最著名的是向量空间模型,要计算两个向量的相似度。由此可以看到两种方法的不同点在于计算两个物品的相似度方法不同,一个根据外界环境计算,一个根据内容计算。
将各个软件的流程存在手机上面一份,然后笔试的时候可能会用的到.
hbase rowkey的设计思路
1.将查询条件中的可选字段转换成数字能节省存储空间,如交通工具中的飞机,高铁,火车,轮船,汽车分别转换成5,4,3,2,1
2.将汉字转换成拼音才能保证数据按HBase的排序规则排序
3.如果数据量在百万级别以下可使用Phoenix(HBase的SQL查询引擎)模糊查询功能减少索引行键的设计
Hbase 的热点问题
由于检索Hbase 的记录是通过Rowkey来定位记录的,当大量的client 访问hbase集群的一个或者少数几个节点的时候,造成少数的region server 的读写请求过多,负载过大,而其他的region server 的负载却很小,就造成了热点现象.
热点产生的原因:当有大量连续编号的Rowkey 导致大量相近的记录集中在个别region,client 检索记录是,对个别region 访问过多,造成此 region 所在的主机过载从而产生热点.
连续编号的rowkey 比如 直接使用timestamp 作为rowkey 的时候就容易产生热点现象,或者使用升序的userID作为rowkey也会容易产生热点现象.所以避免热点问题的关键在于rowkey的设计,rowkey设计的基本原则有唯一性原则确保rowkey唯一,长度原则确保rowkey的设计不能过长和哈希散列原则确保rowkey能够避免连续的rowkey同时写入一个region 当中.对rowkey的处理方式有加盐(也即添加噪声避免rowkey呈线性的格式展现)翻转时间戳的方式,和减少行和列的大小.
hadoop kill 命令
hadoop job -kill job_id
Spark有四种运行模式
Local Standalone yarn mesos
用 linux shell script 将/data 目录及其子目录下所有一扩展名.txt 结尾的文件中包含grip 的字符串全部替换为 boy.
# grep -r 递归查找\# -l 列出文件内容符合指定的范本样式的文件名称。sed -i "s/grip/boy/g" `grep *.txt -rl /data`find /data -exec sed -i 's/grip/boy/g' {} \;find ./ -exec sed -i 's/grip/boy/' {} \;#有点问题 需要将目录剔除# 将当前目录下以及其子目录下文件名匹配为"*.txt"的文件中的boy替换为gripfind ./ -name "*.txt" -exec sed -i "s/boy/grip/g" {} \;
flume 宕机怎么处理
flume channel 本质上是事务性的
Flume采用基于Transactions的方式保证数据传输的可靠性,当数据从一个Agent流向另外一个Agent时,两个Transactions已经开始生效。发送Agent的Sink首先从Channel取出一条消息,并且将该消息发送给另外一个Agent。
如果接受消息的Agent成功地接受并处理消息,那么发送Agent将会提交Transactions,标识一次数据传输成功可靠地完成。当接收Agent接受到发送Agent发送的消息时,开始一个新的Transactions,当该数据被成功处理(写入Channel中),那么接收Agent提交该Transactions,并向发送Agent发送成功响应。
如果在某次提交(commit)之前,数据传输出现了失败,将会再次开始上一次Transcriptions,并将上次发送失败的数据重新传输。因为commit操作已经将Transcriptions写入了磁盘,那么在进程故障退出并恢复业务之后,仍然可以继续上次的Transcriptions。
flume 丢失数据的情况:如果channel 的存储位置是在内存上,在flume宕机后,该部分数据就会丢失,解决方案是将memory channel 修改为file channel
kafka 宕机怎么处理
kafka 宕机后生产者在生产数据的时候发现无法连接kakfa 则会尝试着连接zookeeper去寻找还存活着的broker 去生产数据.
hbase 宕机怎么处理
flume 丢失数据怎么办
kafka 丢失数据怎么办
sqoop 怎么用?
sqoop 是一款数据迁移工具,依赖于hadoop的mapreduce进行工作,将关系型数据上的数据迁移到hadoop上或者将hadoop上的数据迁移到mapreduce上面去.
关于kafka 数据丢失与速度优化
kafka 重复消费与丢失数据的情况
2、如何保证接着offset消费的数据正确性
为了确保consumer消费的数据一定是接着上一次consumer消费的数据,
consumer消费时,记录第一次取出的数据,将其offset和上次consumer最后消费的offset进行对比,如果相同则继续消费。如果不同,则停止消费,检查原因。
你们的 hive 是怎么进行动态分区的?
如何实现 PB 级别的数据的实时查询
答:这个需要根据要处理的数据结构了,大致方法是建立索引和增加缓存,如果是需要对文本数据的查询的话,可以使用ElasticSearch建立倒排索引表.(ElasticSearch是一个实时的分布式搜索和分析引擎.它可以帮助你实现快速梳理数据,它可以用于全文搜索,结构化搜索以及分析.它不但包括了全文搜索功能,还可以进行1. 分布式实时文件存储,并且将每一个字段都编入索引,使其可以被搜索,实时分析的分布式搜索引擎,可以扩展到上百台服务器,处理PB 级别的结构化或非结构或数据.
Bugzilla 概念
Bugzilla 是一个开源的缺陷跟踪系统(Bug-Tracking System),它可以管理软件开发中缺陷的提交(new),修复(resolve),关闭(close)等整个生命周期。
外排序算法
外部排序指的是大文件的排序,当待排序的文件很大时,无法将整个文件的所有记录同时调入内存进行排序,只能将文件存放在外存,这种排称为外部排序。外部排序的过程主要是依据数据的内外存交换和“内部归并”两者结合起来实现的。
一般提到排序都是指内排序,比如快速排序,堆排序,归并排序等,所谓内排序就是可以在内存中完成的排序。RAM的访问速度大约是磁盘的25万倍,我们当然希望如果可以的话都是内排来完成。但对于大数据集来说,内存是远远不够的,这时候就涉及到外排序的知识了.
外部排序最常用的算法是多路归并排序,即将原文件分解成多个能够一次性装入内存的部分分别把每一部分调入内存完成排序。然后,对已经排序的子文件进行归并排序。
将源文件分解成多个能够一次性装入内存的部分分别把每一部分调入内存完成排序.然后对已经排序的子文件进行归并排序.
软件版本号
| 软件名称 | 软件中文名称 | 软件版本号 |
|---|---|---|
| kafka | 分布式发布订阅消息系统 | 0.9.1 |
sql 问到的问题
sql 行转列,列转行
sql 行转列 列转行
sql 开窗函数 over
over(order by salary range between 5 preceding and 5 following)#窗口范围为当前行数据幅度减5加5后的范围内的。
over(order by salary rows between 5 preceding and 5 following):窗口范围为当前行前后各移动5行。
sql case when
SELECT CASE countryWHEN '中国' THEN '亚洲'WHEN '墨西哥' THEN '北美洲'ELSE '其他' END as '洲' , SUM(population) as '人口'
#这里的两个CASE WHEN都相当于一个字段,不过值得一提的是,第二个CASE WHEN 的THEN值并不用写明是什么洲,它只是用于将记录进行分组,所以THEN后面的值只有能区分这三种记录就行,GROUP BY也可以写成:GROUP BY CASE countryWHEN '中国' THEN 0WHEN '日本' THEN 0WHEN '美国' THEN 1WHEN '墨西哥' THEN 1ELSE 2 END;
Spark Sql
java 中有可能出现 i + 1 < i 的情况吗?为什么
这个和java中的数值表示有关系,带符号的数都有最大值,到了最大值之后就变成负数了,可以看看java中负数的表示方法。原理讲了,下面给个例子:
int i = Integer.MAX_VALUE;int j = i+1;System.out.println(j<i);
