@gyyin
2018-04-24T05:47:00.000000Z
字数 4603
阅读 753
underscore查找索引函数分析
underscore
这是underscore源码剖析系列第七篇文章,这篇文章主要介绍underscore中查找数组中某一项索引或者对象中某个key的函数。
find
// find函数接受三个参数,分别是集合obj、检测函数predicate和上下文context_.find = _.detect = function (obj, predicate, context) {var key;// 判断是否是类数组,如果是类数组就查找索引,是对象就查找keyif (isArrayLike(obj)) {key = _.findIndex(obj, predicate, context);} else {key = _.findKey(obj, predicate, context);}// 如果查不到,findIndex会返回-1,而findKey会什么都不返回(默认undefined)// 所以这里对没有查找到的情况做了判断if (key !== void 0 && key !== -1) return obj[key];};
findKey和findIndex方法的实现也都比较简单。
_.findKey = function (obj, predicate, context) {predicate = cb(predicate, context);var keys = _.keys(obj), key;for (var i = 0, length = keys.length; i < length; i++) {key = keys[i];// 直接return出key意味着只返回第一个通过predicate检测的值if (predicate(obj[key], key, obj)) return key;}};// 根据传入dir的正负来判断是findIndex还是findLastIndexfunction createPredicateIndexFinder(dir) {return function (array, predicate, context) {// cb中对predicate绑定作用域predicate = cb(predicate, context);var length = getLength(array);// 根据dir判断是从头遍历还是从尾遍历var index = dir > 0 ? 0 : length - 1;// 这里需要判断两个临界条件for (; index >= 0 && index < length; index += dir) {// 遍历数组,并将每一项和key都传到函数中进行运算,返回结果为true的index值if (predicate(array[index], index, array)) return index;}// 查找不到就返回-1return -1;};}// Returns the first index on an array-like that passes a predicate test_.findIndex = createPredicateIndexFinder(1);_.findLastIndex = createPredicateIndexFinder(-1);
sortedIndex二分查找
sortedIndex函数是返回一个值在数组中的位置(注意:这个值不一定在数组中)
var arr = [10, 20, 30, 40]_.sortedIndex(arr, 25) // 返回2
由于sortedIndex是二分查找的实现,所以必须保证传入的数组是升序的(或者数组对象中按某属性升序排列)。
这里是维基百科对二分查找的定义:
在计算机科学中,二分搜索(英语:binary search),也称折半搜索(英语:half-interval
search)、对数搜索(英语:logarithmicsearch),是一种在有序数组中查找某一特定元素的搜索算法。搜索过程从数组的中间元素开始,如果中间元素正好是要查找的元素,则搜索过程结束;如果某一特定元素大于或者小于中间元素,则在数组大于或小于中间元素的那一半中查找,而且跟开始一样从中间元素开始比较。如果在某一步骤数组为空,则代表找不到。这种搜索算法每一次比较都使搜索范围缩小一半。
// 二分法,可以理解为以中间元素为基准,将数组分成两个// 首先获取到数组中间的元素,比较传入的obj和中间元素的大小// 如果obj大于这个元素,那么就说明这个obj应该是在数组右半段// 反过来,就是在数组左半段_.sortedIndex = function (array, obj, iteratee, context) {// 不理解cb函数的建议去看我之前的文章iteratee = cb(iteratee, context, 1);// obj有可能是一个对象,iteratee(obj)会返回当前obj中的某个值// 如果obj是{age: 20, name: "ygy"},iteratee是age,那么这个就是根据age来获取到index的var value = iteratee(obj);var low = 0, high = getLength(array);// 通过while循环来不断重复上述过程,直到找到obj的位置while (low < high) {var mid = Math.floor((low + high) / 2);if (iteratee(array[mid]) < value) low = mid + 1; else high = mid;}return low;};
indexOf
indexOf函数接收array、value和isSorted三个参数。
indexOf返回value在该 array 中的索引值,如果value不存在 array中就返回-1。
使用原生的indexOf 函数,除非它失效。如果您正在使用一个大数组,你知道数组已经排序,传递true给isSorted将更快的用sortedIndex二分查找..,或者,传递一个数字作为第三个参数,为了在给定的索引的数组中寻找第一个匹配值。
lastIndexOf接收array、value和fromIndex三个参数。
lastIndexOf返回value在该 array 中的从最后开始的索引值,如果value不存在 array中就返回-1。如果支持原生的lastIndexOf,将使用原生的lastIndexOf函数。 传递fromIndex将从你给定的索性值开始搜索。
给下面返回值编上号,以便后面可以直接拿来讲。
var arr = [1, 2, 3, 2, 4, 5]var index1 = _.indexOf(arr, 2) // 1// 如果传了索引值为2,那就是从索引为2的地方开始搜索// 如果不传第三个参数,可以理解为默认是从0开始搜索var index2 = _.indexOf(arr, 2, 2) // 3// 从索引为-1的地方查找意思就是从length-2的索引开始查找var index3 = _.indexOf(arr, 2, -1)// lastIndexOf是从数组末尾反向查询,返回第一个查询到的索引值var index4 = _.lastIndexOf(arr, 2) // 3// 如果传了索引值(比如下面的4),意味着将截取数组里面0-4的部分// 将这部分当作新数组,从数组末尾反向查询,返回第一个查询到的索引值// 当然这个查询到的索引值还是按照原来数组来看的,以下面这个为例,传入了4// 意味着从1,2,3,2,4中反向查询2,查询到的第一个2在原arr数组中索引为3//其实个人理解类似于如果我不传第三个参数,那就默认的是6(arr的长度)var index5 = _.lastIndexOf(arr, 2, 4) // 3// 这种情况下传入-1类似于传入5,因为如果不传第三个参数,其实类似于从index为6开始反向查的,传入负值就是从fromIndex+arr.length开始搜索var index6 = _.lastIndexOf(arr, 2, -1)
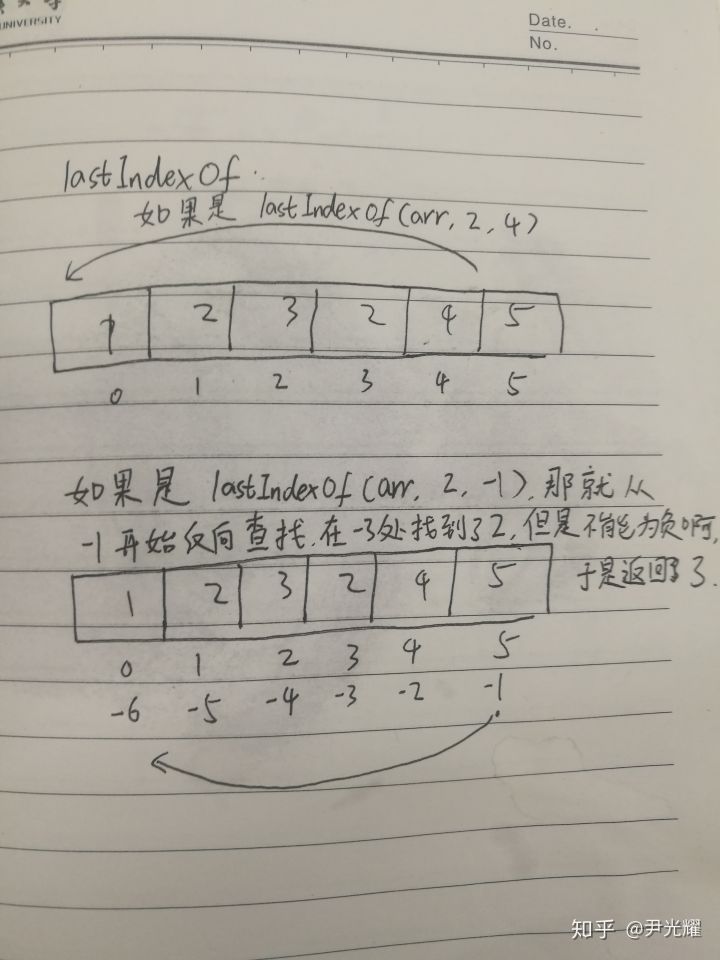
可能上面有点绕,这里我们再看一下源码:
_.indexOf = createIndexFinder(1, _.findIndex, _.sortedIndex);_.lastIndexOf = createIndexFinder(-1, _.findLastIndex);function createIndexFinder(dir, predicateFind, sortedIndex) {// idx有可能是布尔类型(isSorted)和数字类型return function (array, item, idx) {var i = 0, length = getLength(array);// 如果idx是数字类型,那就是从某个索引开始搜索if (typeof idx == 'number') {// dir大于0的时候是从左到右查询(indexOf)if (dir > 0) {// 这里对idx进行了处理,如果idx为负数,那就从加上length的索引开始算// idx为负数对应上面的index3的情况i = idx >= 0 ? idx : Math.max(idx + length, i);// dir小于0的时候是从右到左查询(lastIndexOf)} else {// 从index开始反向查找,如果idx为正,那么不能超过数组长度// 如果idx为负,那就取idx+length+1(这里之所以+1是为了兼容后面for循环里面的-1,因为如果什么都不传的情况下,循环肯定是从0到length-1)length = idx >= 0 ? Math.min(idx + 1, length) : Math.max(idx, idx + length + 1);}// 如果idx为布尔类型,那么就使用sortedIndex二分查找} else if (sortedIndex && idx && length) {// 使用二分法来查找idx = sortedIndex(array, item);return array[idx] === item ? idx : -1;}// 如果item是NaNif (item !== item) {// 数组里面有可能有NaN,因为NaN不和自身相等,所以这里传入了isNaN的方法来检测// 其实这里面对array.slice(i, length)的每一项都用isNaN来检测了idx = predicateFind(slice.call(array, i, length), _.isNaN);// 这里之所以加上i,是因为predicateFind函数里面是根据array.slice(i, length)的长度来循环最终获取到index值,// 这样其实少算了一段长度为i的数组,这个可以去看createPredicateIndexFinder函数return idx >= 0 ? idx + i : -1;}// 根据上面计算出来的i和length来进行循环// 这里不用加上i是因为一开始就是从i或者length-1开始遍历的for (idx = dir > 0 ? i : length - 1; idx >= 0 && idx < length; idx += dir) {if (array[idx] === item) return idx;}return -1;};}
原本indexOf只是个简单的方法,只不过这里面考虑到lastIndexOf可以传入负值以及indexOf使用二分查找优化才让人那么难懂。
这篇文章如果有什么错误和不足之处,希望大家可以指出,有疑惑也可以直接在评论区提出来。
