@gyyin
2019-03-20T13:00:06.000000Z
字数 3427
阅读 729
如何写好业务代码?
javascript
前言
原本只是想简单群发一下,但预览之后看到格式不友好,还是简单写一篇文章吧。
分层
对于业务代码来说,大部分的前端应用都还是以展示数据为主,无非是从接口拿到数据,进行一系列数据格式化后,显示在页面当中。
首先,应当尽可能的进行分层,传统的mvc分层很适用于前端开发,但对于复杂页面来说,随着业务逻辑增加,往往会造成controller臃肿的问题。因此,在此之上,可以将controller其分成formatter、service等等。
下面这是一些分层后简单的目录结构。
+ pages+ hotelList+ components+ Header.jsx+ formatter+ index.js+ share+ constants.js+ utils.js+ view.js+ controller.js+ model.js
Service
统一管理所有请求路径,并且将页面中涉及到的网络请求封装为class。
// api.jsexport default {HOTELLIST: '/hotelList',HOTELDETAIL: '/hotelDetail'}// Service.jsclass Service {fetchHotelList = (params) => {return fetch(HOTELLIST, params);}fetchHotelDetail = (params) => {return fetch(HOTELLIST, params);}}export default new Service
这样带来的好处就是,很清楚的知道页面中涉及了哪些请求,如果使用了TypeScript,后续某个请求方法名修改了后,在所有调用的地方也会提示错误,非常方便。
formatter
formatter层储存一些格式化数据的方法,这些方法接收数据,返回新的数据,不应该在涉及到其他的逻辑,便于单元测试。单个format函数也不应该格式化过多数据,函数应该根据功能进行适当拆分,有利于复用。
mvc
顾名思义,controller就是mvc中的c,controller应该是处理各种副作用操作(网络请求、缓存等等)的地方。处理一个请求的时候,它会调用service里面的方法,拿到数据后再调用formatter的方法,将这些需要展示的数据存入store中。
react只负责渲染view,有了hooks之后,react也可以变得更加纯粹(实际上有状态组件也可以看做一个mvc的结构,state是model,render是view,各种handler方法是controller)。
对于react来说,容器组件里面的一些逻辑可以剥离出来放到controller中(react-imvc就是这种做法),给controller赋予生命周期。
我们将容器组件的生命周期放到wrapper组件中,并在里面调用controller里面封装的生命周期,这样我们可以编写更加纯粹的view,例如:
// wrapper.js(伪代码)const Wrapper = (components) => {return class extends Component {constructor(props) {super(props)this.isFirstMount = true;}componentWillMount() {this.props.pageWillMount && this.props.pageWillMount()}componentDidMount() {if (this.isFirstMount) {this.props.pageWillMount && this.props.pageDidFirstMount()this.isFirstMount = false} else {this.props.pageWillMount && this.props.pageDidMount()}}componentWillUnmount() {this.props.pageWillLeave && this.props.pageWillLeave()}render() {const {store: state,actions} = this.propsreturn view({store, actions})}}}// view.jsfunction view({state,actions}) {return (<><Headertitle={state.title}handleBack={actions.goBackPage}/><Body /><Footer /></>)}export default Wrapper(view)// controller.jsclass Controller {pageDidFirstMount() {this.bindScrollEvent('on')console.log('page did first mount')}pageDidMount() {console.log('page did mount')}pageWillLeave() {this.bindScrollEvent('off')console.log('page will leave')}bindScrollEvent(status) {if (status === 'on) {this.bindScrollEvent('off');window.addEventListener('scroll', this.handleScroll);} else if (status === 'off') {window.removeEventListener('scroll', this.handleScroll);}}// 滚动事件handleScroll() {}}
其他
对于埋点来说,原本也应该放到controller中,但也是可以独立出来一个tracelog层,至于tracelog层如何实现和调用,还是看个人爱好,我比较喜欢用发布订阅的形式。
如果还涉及到缓存,那我们也可以再分出来一个storage层,这里存放对缓存进行增删查改的各种操作。
对于一些常用的固定不变的值,也可以放到constants.js,通过引入constants来获取值,这样便于后续维护。
// constants.jsexport const cityMapping = {'1': '北京','2': '上海'}export const traceKey = {'loading': 'PAGE_LOADING'}// tracelog.jsclass TraceLog {traceLoading = (params) => {tracelog(traceKey.loading, params);}}export default new TraceLog// storage.jsexport default class Storage {static get instance() {//}setName(name) {//}getName() {//}}
数据与交互
不过也不代表着这样写就够了,分层只能够保证代码结构上的清晰,真正想写出好的业务代码,最重要的还是你对业务逻辑足够清晰,页面上的数据流动是怎样的?数据结构怎么设计更加合理?页面上有哪些交互?这些交互会带来哪些影响?
以如下酒店列表页为例,这个页面看似简单,实际上包含了很多复杂的交互。上方的是四个筛选项菜单,点开后里面包含了很多子类筛选项。比如筛选里面包括了双床、大床、三床,价格/星级里面包含了高档/豪华、¥150-¥300等等。
下方是快捷筛选项,对应了部分筛选项菜单里面的子类筛选项。
当我们选中筛选里面的双床后,下方的双床也会被默认选中,反之当我们选中下方的双床后,筛选类别里面的双床也会被选中,名称还会回显到原来的筛选上。
除此之外,我们点击搜索框后,输入'双床',联想词会出现双床,并表示这是个筛选项,如果用户选中了这个双床,我们依然需要筛选项和快捷筛选项默认选中。
这三个地方都涉及到了筛选项,并且修改一个,其他两个地方就要跟着改变,更何况三者的数据来自于三个不同的接口数据,这是多么蛋疼的一件事情!
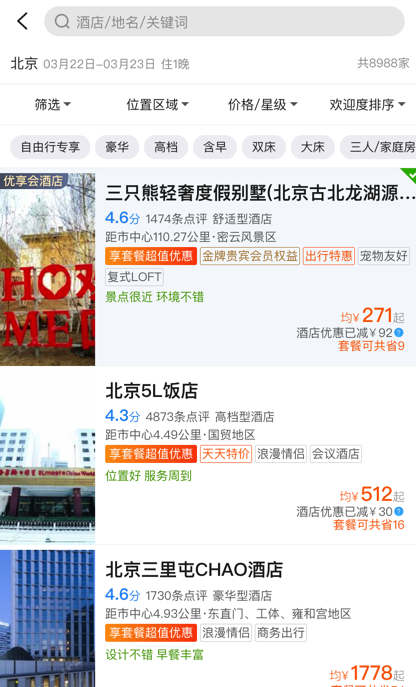
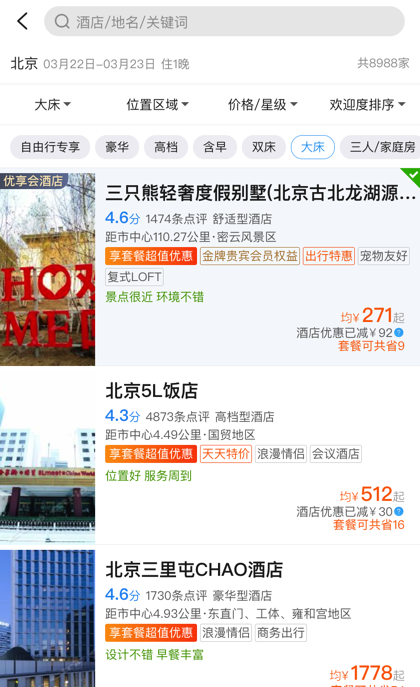
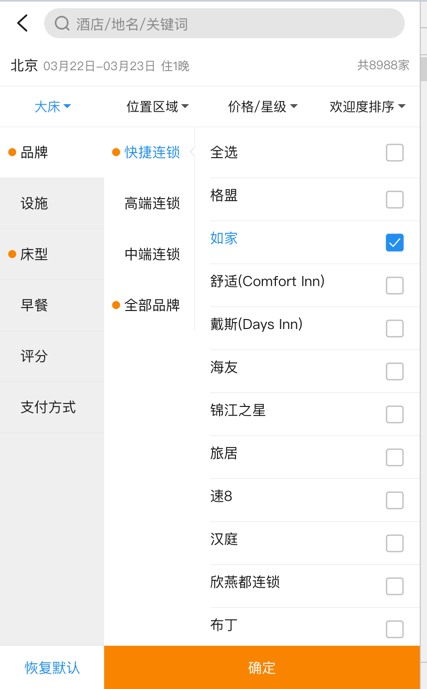
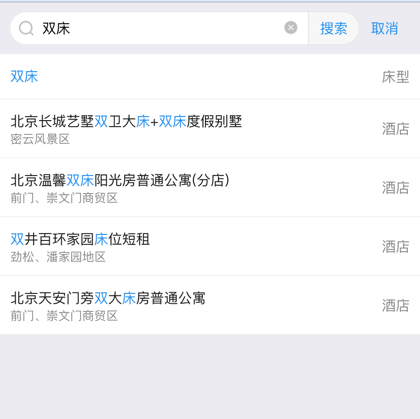
我借助这个例子来说明,在开始写页面之前,一定要对页面中的隐藏交互和数据流动很熟悉,也需要去设计更加合理的数据结构。
对于深层次的列表结构,键值对会比数组查询速度更快,但是却不能保证顺序,这个时候就需要牺牲空间来换时间。
