@lightless
2021-03-16T07:29:49.000000Z
字数 1321
阅读 843
从零开始的炼丹之旅:P1-线性回归
炼丹
0x00 模型构建
线性回归应该算是机器学习的入门的经典算法了,主要原因是它非常简单并且易于理解。这里主要是记录一下学习过程中的笔记,对于一些基础概念就不再额外阐述了。
首先,我们从经典的预测房价问题开始切入,现在收集了某地区的一批房价和房子的关系数据,需要你根据这些数据,预测出指定房子的价格,数据大概是这个样子:
| 大小 | 房价数量 | 价格(k) |
|---|---|---|
| 2104 | 3 | 460 |
| 1416 | 1 | 232 |
| 1534 | 2 | 315 |
| 852 | 1 | 232 |
现在我们的任务就是根据这些已有的数据,设计一个算法使其可以很好的预测给定房屋信息的价格,当然这里为了简化问题,只选取了两个维度来统计数据,实际真实情况中,问题会比这数据维度复杂的多的多,不过现在的数据已经足够我们学习使用了。
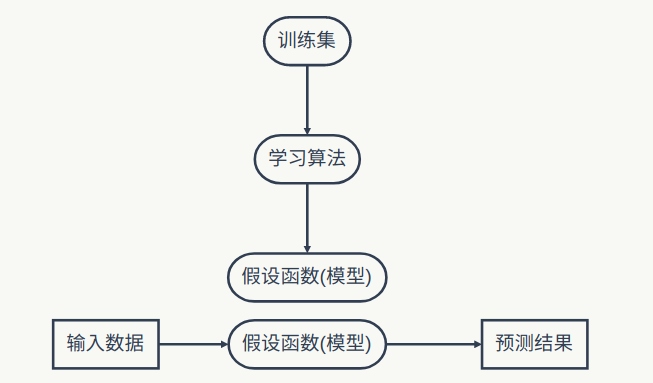
那么现在的问题就是,如何构建我们的预测模型,或者说如何定义我们的假设函数 呢?为了简化问题,我们先舍弃掉一个特征,只保留房屋大小与价格的关系,即只有一个输入特征,只考虑单变量的线性回归情况,我们先将数据画出来看下是什么样的。
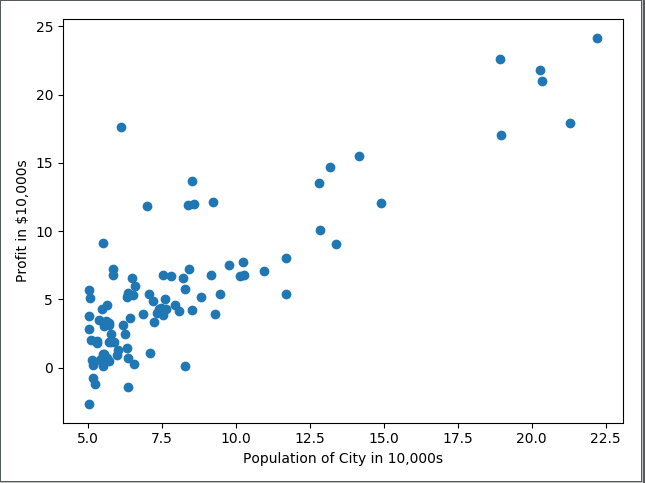
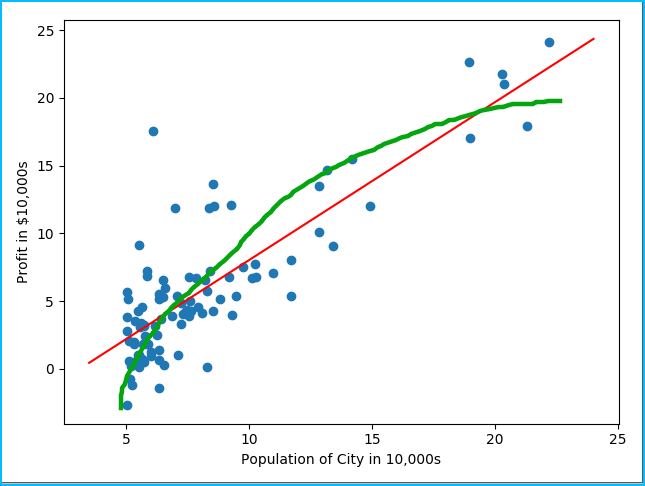
很明显,数据的分布是符合线性函数的,用一条直线或者一个二次函数曲线都可以大概的拟合上这些数据,实际上感觉二次函数更符合一点,因为随着(房屋面积)的增加,价格的上升速度很有可能会变慢,这里我将两条线都画了出来。
这里我们选择使用一次函数来拟合我们的数据,先从简单的模型入手,将假设函数表示出来就是:
我们前面简化了变量个数,所以这里只有一个输入特征,和是这个一次函数的两个参数。
0x01 代价函数
现在我们已经有了假设函数,我们就假设这些数据可以被 这个函数拟合。那么现在有了新的问题,我们如何选取 参数呢?很明显我们有无数个选取组合,都可以画出一条直线,那么如何让这条直线和数据最接近呢?这里我们引入一个新的概念,叫做代价函数,又叫损失函数。简单的讲,这个函数就是用来度量模型拟合程度的。一般情况下,损失函数越小,就代表我们的模型(这里就是)拟合的越好。
针对现在的这个情况,我们需要构造一个损失函数,代表这个模型的拟合程度,由于这是个一次函数,我们可以使用最小二乘来构造损失函数:
如果你明白最小二乘,那么应该很容易看明白这个公式,其实很简单,对于每一个输入变量,我们用预测值减掉标准值,并且平方求和,然后求平均值,再乘以 仅仅是为了便于后续的计算。
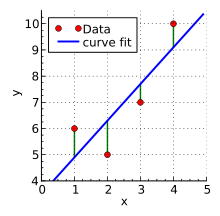
在这个图中,红点就是数据的实际值,蓝线是预测值,绿线就是部分。
前面说过,我们的目标就是使损失函数最小,而我们写出的损失函数是关于 和 两个变量的函数,如果画出图的话,应该是一个曲面,和下图类似
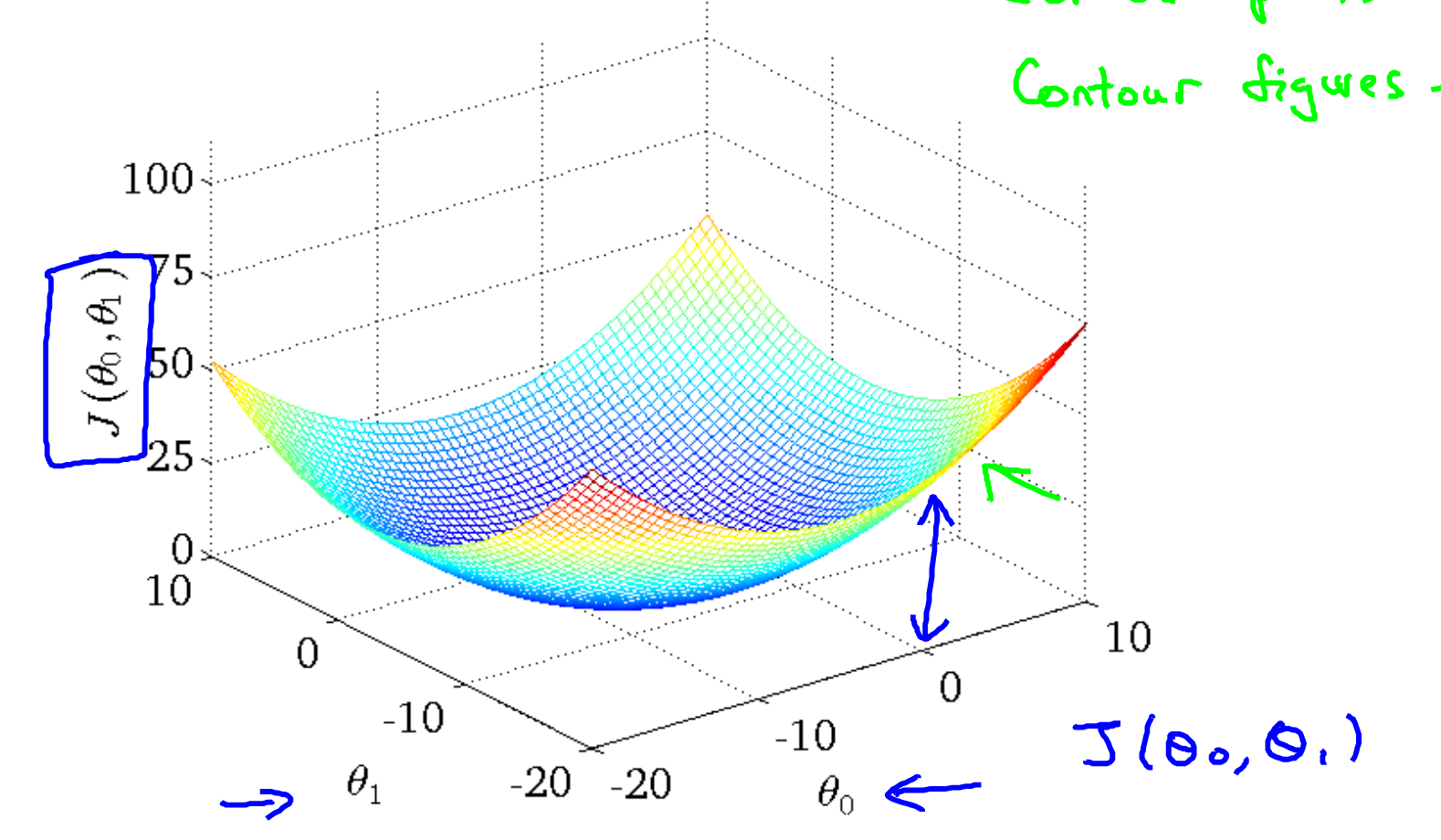
所以我们的目标就变成了在上面这个函数上求最小值。
