@ltlovezh
2019-12-22T08:57:05.000000Z
字数 11008
阅读 3787
Android图形系统系统篇之Gralloc
图形系统
gralloc是Android中负责申请和释放GraphicBuffer的HAL层模块,由硬件驱动提供实现,为BufferQueue机制提供了基础。gralloc分配的图形Buffer是进程间共享的,且根据其Flag支持不同硬件设备的读写。
从系统层级来看,gralloc属于最底层的HAL层模块,为上层的libui库提供服务,整个层级结构如下所示:
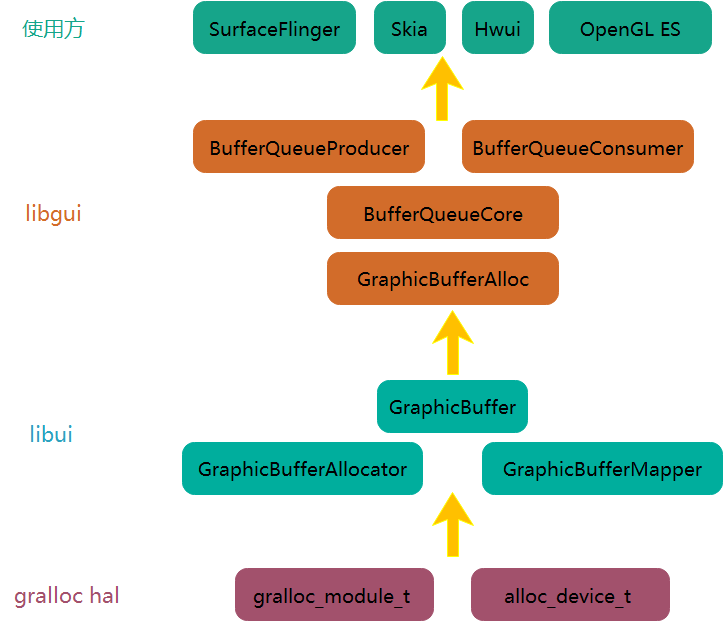
- 最底层是
grallocHAL模块。 - 向上是
libui库,主要功能是封装对grallocHAL层的调用。代码目录是frameworks/native/include/ui和frameworks/native/libs/ui。 - 再向上是
libgui库,主要功能是封装连接SF客户端和服务端的BufferQueue,向下依赖于于libui。代码目录是frameworks/native/include/gui和frameworks/native/libs/gui。 - 最上面是使用方,
Skia、Hwui和OpenGL ES是BufferQueue的生产方,SurfaceFlinger是BufferQueue的消费方。
本篇文章主要关注gralloc和libui层。
gralloc
grallocHAL模块结构体定义在gralloc.h:
// gralloc的模块ID#define GRALLOC_HARDWARE_MODULE_ID "gralloc"// gralloc的设备ID#define GRALLOC_HARDWARE_GPU0 "gpu0"// gralloc扩展的HAL层模块结构体typedef struct gralloc_module_t {// hw_module_t表示一个通用的硬件模块,是HAL层的灵魂,相当于继承了hw_module_tstruct hw_module_t common;// 当其他进程分配的GraphicBuffer传递到当前进程后,需要通过该方法映射到当前进程,为后续的lock做好准备int (*registerBuffer)(struct gralloc_module_t const* module,buffer_handle_t handle);// 取消GraphicBuffer在当前进程的映射,后续不能调用lock了int (*unregisterBuffer)(struct gralloc_module_t const* module,buffer_handle_t handle);// 调用lock后,才能访问图形Buffer,假如usage指定了GRALLOC_USAGE_SW_* flag,vaddr将被填充成图形Buffer在虚拟内存中的地址,使用方可以直接向该地址写入像素数据int (*lock)(struct gralloc_module_t const* module,buffer_handle_t handle, int usage,int l, int t, int w, int h,void** vaddr);// 对图形Buffer写之后,需要unlock提交数据int (*unlock)(struct gralloc_module_t const* module,buffer_handle_t handle);//其他函数......} gralloc_module_t;// gralloc扩展的HAL层设备结构体typedef struct alloc_device_t {// hw_device_t表示一个通用的硬件设备,相当于继承了hw_device_t结构体struct hw_device_t common;// 申请一块graphic buffer,并通过buffer_handle_t标识该graphic bufferint (*alloc)(struct alloc_device_t* dev,int w, int h, int format, int usage,buffer_handle_t* handle, int* stride);// 释放buffer_handle_t标识的一块graphic bufferint (*free)(struct alloc_device_t* dev,buffer_handle_t handle);//其他函数......}
之前介绍HWC模块时有提到:每个HAL层模块实现都要定义一个HAL_MODULE_INFO_SYM数据结构,并且该结构的第一个字段必须是hw_module_t。gralloc.cpp提供了gralloc的默认实现,对应的共享库是gralloc.default.so。高通MSM8994也提供了实现,对应的共享库是gralloc.msm8994.so,下面是default定义:
struct private_module_t HAL_MODULE_INFO_SYM = {// base表示gralloc_module_t结构体.base = {// common表示hw_module_t结构体.common = {.tag = HARDWARE_MODULE_TAG,.version_major = 1,.version_minor = 0,.id = GRALLOC_HARDWARE_MODULE_ID,.name = "Graphics Memory Allocator Module",.author = "The Android Open Source Project",// 打开gralloc设备alloc_device_t的函数.methods = &gralloc_module_methods},// gralloc_module_t的扩展字段.registerBuffer = gralloc_register_buffer,.unregisterBuffer = gralloc_unregister_buffer,.lock = gralloc_lock,.unlock = gralloc_unlock,},.framebuffer = 0,.flags = 0,.numBuffers = 0,.bufferMask = 0,.lock = PTHREAD_MUTEX_INITIALIZER,.currentBuffer = 0,};
libui
libui库主要封装了对grallocHAL模块的调用,管理GraphicBuffer的分配释放以及在不同进程间的映射,主要包含3个核心类,类图如下所示:
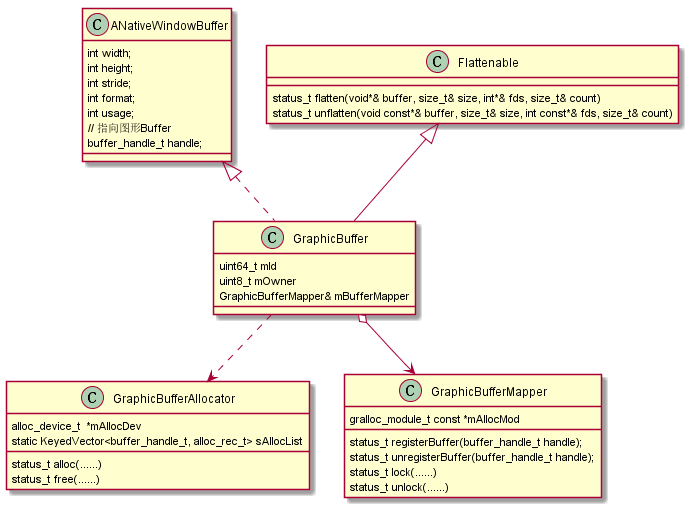
GraphicBuffer:对应gralloc分配的图形Buffer(也可能是普通内存,具体要看gralloc实现),继承ANativeWindowBuffer结构体,核心是指向图形显存的指针(buffer_handle_t),并且图形Buffer本身是多进程共享的,跨进程传输的是GraphicBuffer的关键属性,这样在使用进程可以重建GraphicBuffer,同时指向同一块图形Buffer。GraphicBufferAllocator:向下对接grallocHAL模块的alloc_device_t设备,是进程内单例,负责分配进程间共享的图形Buffer,对外即GraphicBuffer。GraphicBufferMapper:向下对接grallocHAL模块的gralloc_module_t模块,是进程内单例,负责把GraphicBufferAllocator分配的GraphicBuffer映射到当前进程空间。
接下来,我们看下在当前进程申请和释放GraphicBuffer的时序逻辑:
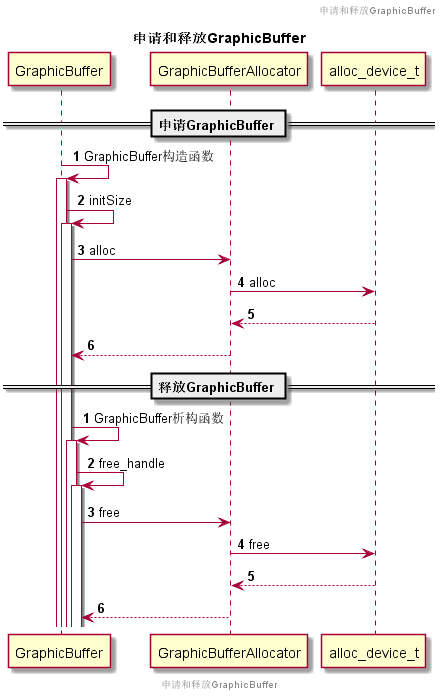
申请成功的图形Buffer的属性会保存在GraphicBuffer父类ANativeWindowBuffer对应字段中:
// 图形Buffer的Size = stride * height * 每像素字节数typedef struct ANativeWindowBuffer {// 图形Buffer的宽度int width;// 图形Buffer的高度int height;// 图形Buffer的步长,为了处理对齐问题,与height可能不同int stride;// 图形Buffer的像素格式int format;// 图形Buffer的使用规则(gralloc会分配不同属性的图形Buffer)int usage;// 指向一块图形Bufferbuffer_handle_t handle;} ANativeWindowBuffer_t;
图形Buffer的Size = stride * height * 每像素字节数
除了直接申请一块图形Buffer外,还可以基于已有图形Buffer的不同形式来创建GraphicBuffer:
ANativeWindowBuffernative_handle_t(即buffer_handle_t)
逻辑比较简单,可直接参考GraphicBuffer重载的构造函数,此处不再赘述。
上图中,最终通过GraphicBufferAllocator.mAllocDev(alloc_device_t)分配图形Buffer,mAllocDev是在GraphicBufferAllocator构造函数中初始化的:
// GraphicBufferAllocator是进程内单例GraphicBufferAllocator::GraphicBufferAllocator(): mAllocDev(0){hw_module_t const* module;// 跟HWC一样,打开gralloc模块int err = hw_get_module(GRALLOC_HARDWARE_MODULE_ID, &module);if (err == 0) {// 打开gralloc设备,保存在mAllocDevgralloc_open(module, &mAllocDev);}}
与打开HWC设备一样,先打开gralloc模块,再打开gralloc设备,这是操作HAL模块的通用流程。
申请图形Buffer时,除了宽、高、像素格式,还有一个usage参数,它表示申请方使用GraphicBuffer的行为,gralloc可以根据usage做对应优化,gralloc.h定义了usage枚举值:
- GRALLOC_USAGE_SW_READ_NEVER:CPU不会读GraphicBuffer
- GRALLOC_USAGE_SW_READ_RARELY:CPU很少读GraphicBuffer
- GRALLOC_USAGE_SW_READ_OFTEN:CPU经常读GraphicBuffer
- GRALLOC_USAGE_SW_WRITE_NEVER:CPU不会写GraphicBuffer
- GRALLOC_USAGE_SW_WRITE_RARELY:CPU很少写GraphicBuffer
- GRALLOC_USAGE_SW_WRITE_OFTEN:CPU经常写GraphicBuffer
- GRALLOC_USAGE_HW_TEXTURE:GraphicBuffer可以被上传为OpenGL ES texture,相当于GPU读GraphicBuffer
- GRALLOC_USAGE_HW_RENDER:GraphicBuffer可以被当做OpenGL ES的渲染目标,相当于GPU写GraphicBuffer
- GRALLOC_USAGE_HW_2D:GraphicBuffer will be used by the 2D hardware blitter
- GRALLOC_USAGE_HW_COMPOSER:HWC可以直接使用GraphicBuffer进行合成
- GRALLOC_USAGE_HW_VIDEO_ENCODER:GraphicBuffer可以作为Video硬编码器的输入对象
- GRALLOC_USAGE_HW_CAMERA_WRITE:GraphicBuffer可以被当做camera的渲染目标,相当于camera写GraphicBuffer
- GRALLOC_USAGE_HW_CAMERA_READ:camera可以读GraphicBuffer
图形Buffer的申请方可以根据场景,使用不同的usage组合。
上述分析了在同一个进程分配和释放图形Buffer的场景,那么GraphicBuffer怎么在进程间共享那?可以通过一个流程图概括:
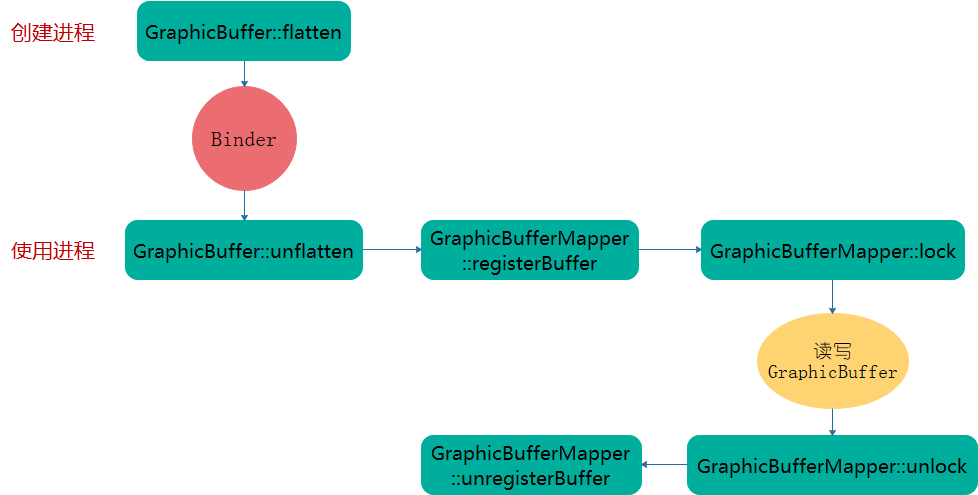
- 首先,创建进程通过
GraphicBuffer::flatten把ANativeWindowBuffer关键属性保存在两个数组中:buffer和fds。 - 其次,跨进程传输
buffer和fds。 - 然后,使用进程通过
GraphicBuffer::unflatten在自己进程重建ANativeWindowBuffer,关键是重建ANativeWindowBuffer.handle结构,相当于把创建进程的GraphicBuffer映射到了使用进程。 - 最后,遵循registerBuffer->lock->读写
GraphicBuffer->unlock->unregisterBuffer的基本流程操作GraphicBuffer就行了。
Binder只是传输
ANativeWindowBuffer属性,真正的底层图形显存(内存)是进程间共享的。
从上下文可以看出,GraphicBufferAllocator负责在创建进程申请和释放GraphicBuffer,GraphicBufferMapper负责在使用进程操作GraphicBuffer。
GraphicBufferMapper对GraphicBuffer的所有操作最后都是通过grallocHAL模块实现的,具体一点就是通过gralloc_module_t实现,感兴趣的可以参考GraphicBufferMapper.cpp,这里仅看一下gralloc模块的初始化逻辑:
GraphicBufferMapper::GraphicBufferMapper(): mAllocMod(0) {hw_module_t const* module;// 跟HWC一样,打开gralloc模块int err = hw_get_module(GRALLOC_HARDWARE_MODULE_ID, &module);if (err == 0) {mAllocMod = reinterpret_cast<gralloc_module_t const*>(module);}}
最后,结合上述流程图我们看下GraphicBuffer跨进程传输的关键代码:
// 计算传输GraphicBuffer需要的Sizesize_t GraphicBuffer::getFlattenedSize() const {return static_cast<size_t>(11 + (handle ? handle->numInts : 0)) * sizeof(int);}// 获取文件描述符数量size_t GraphicBuffer::getFdCount() const {return static_cast<size_t>(handle ? handle->numFds : 0);}// 把GraphicBuffer关键属性保存在buffer和fds中,以进行Binder传输// size表示buffer数组可用长度,count表示fds数组可用长度status_t GraphicBuffer::flatten(void*& buffer, size_t& size, int*& fds, size_t& count) const {// 判断buffer可用长度是否足够size_t sizeNeeded = GraphicBuffer::getFlattenedSize();if (size < sizeNeeded) return NO_MEMORY;// 判断fds数组长度是否足够size_t fdCountNeeded = GraphicBuffer::getFdCount();if (count < fdCountNeeded) return NO_MEMORY;// 把当前GraphicBuffer的关键属性存储在buffer中int32_t* buf = static_cast<int32_t*>(buffer);// 存储标识符buf[0] = 'GBFR';buf[1] = width;buf[2] = height;buf[3] = stride;buf[4] = format;buf[5] = usage;buf[6] = static_cast<int32_t>(mId >> 32);buf[7] = static_cast<int32_t>(mId & 0xFFFFFFFFull);buf[8] = static_cast<int32_t>(mGenerationNumber);buf[9] = 0;buf[10] = 0;if (handle) {// 存储文件描述符数量buf[9] = handle->numFds;// 存储int数组长度buf[10] = handle->numInts;// copy文件描述符数组到fdsmemcpy(fds, handle->data,static_cast<size_t>(handle->numFds) * sizeof(int));// copy int数组到buffermemcpy(&buf[11], handle->data + handle->numFds,static_cast<size_t>(handle->numInts) * sizeof(int));}// 修改buffer地址和可用长度buffer = static_cast<void*>(static_cast<uint8_t*>(buffer) + sizeNeeded);size -= sizeNeeded;if (handle) {// 修改fds地址和可用长度fds += handle->numFds;count -= static_cast<size_t>(handle->numFds);}return NO_ERROR;}// 根据Binder传输的buffer和fds中,把创建进程的GraphicBuffer映射到使用进程status_t GraphicBuffer::unflatten(void const*& buffer, size_t& size, int const*& fds, size_t& count) {// 判断buffer的正确性if (size < 11 * sizeof(int)) return NO_MEMORY;int const* buf = static_cast<int const*>(buffer);if (buf[0] != 'GBFR') return BAD_TYPE;// 取出文件描述符和int数组的长度const size_t numFds = static_cast<size_t>(buf[9]);const size_t numInts = static_cast<size_t>(buf[10]);// 判断buffer长度是否正确const size_t sizeNeeded = (11 + numInts) * sizeof(int);if (size < sizeNeeded) return NO_MEMORY;// 判断fds长度是否正确size_t fdCountNeeded = numFds;if (count < fdCountNeeded) return NO_MEMORY;if (handle) {// 如果有,先释放之前的ANativeWindowBuffer.handlefree_handle();}if (numFds || numInts) {width = buf[1];height = buf[2];stride = buf[3];format = buf[4];usage = buf[5];// 创建ANativeWindowBuffer.handle,native_handle_create定义在native_handle.cnative_handle* h = native_handle_create(static_cast<int>(numFds), static_cast<int>(numInts));if (!h) {width = height = stride = format = usage = 0;handle = NULL;ALOGE("unflatten: native_handle_create failed");return NO_MEMORY;}// 从fds和buffer中copy文件描述符和int数组到ANativeWindowBuffer.handle结构体memcpy(h->data, fds, numFds * sizeof(int));memcpy(h->data + numFds, &buf[11], numInts * sizeof(int));handle = h;} else {width = height = stride = format = usage = 0;handle = NULL;}// 从buffer中恢复其他字段mId = static_cast<uint64_t>(buf[6]) << 32;mId |= static_cast<uint32_t>(buf[7]);mGenerationNumber = static_cast<uint32_t>(buf[8]);// 表示GraphicBuffer是从其他创建进程映射过来的,决定了释放GraphicBuffer的逻辑mOwner = ownHandle;if (handle != 0) {// register到当前线程status_t err = mBufferMapper.registerBuffer(handle);}// 调整buffer和fds数组的地址和可用长度buffer = static_cast<void const*>(static_cast<uint8_t const*>(buffer) + sizeNeeded);size -= sizeNeeded;fds += numFds;count -= numFds;return NO_ERROR;}// ANativeWindowBuffer.handle结构体typedef struct native_handle{/* sizeof(native_handle_t) */int version;/* number of file-descriptors at &data[0] */int numFds;/* number of ints at &data[numFds] */int numInts;/* numFds + numInts ints */int data[0];} native_handle_t;typedef const native_handle_t* buffer_handle_t
上述代码虽然很长,但都是关键代码,感兴趣的可以参考注释阅读。ANativeWindowBuffer.handle是GraphicBuffer的核心字段,定义在handle.h中。native_handle.c则定义了create、close和delete native_handle的方法,感兴趣的可自行查看。
前面我们看了GraphicBuffer申请和释放的时序图,可知在创建进程GraphicBuffer是通过GraphicBufferAllocator进行申请和释放的,那么在使用进程那?很明显,是通过unflatten在使用进程重建了GraphicBuffer,那么使用进程是如何释放GraphicBuffer的?毕竟真正的图形Buffer并不是在当前进程创建的。我们可以直接看下GraphicBuffer的释放代码:
// GraphicBuffer析构函数会调用到这里void GraphicBuffer::free_handle(){if (mOwner == ownHandle) { // 表示图形Buffer不是自己创建的,而是从创建进程映射过来的,即处于使用进程mBufferMapper.unregisterBuffer(handle);// 关闭删除ANativeWindowBuffer.handle,具体方法实现可参见native_handle.cnative_handle_close(handle);native_handle_delete(const_cast<native_handle*>(handle));} else if (mOwner == ownData) { //表示图形Buffer是自己创建的,需要自己释放,即处于创建进程GraphicBufferAllocator& allocator(GraphicBufferAllocator::get());allocator.free(handle);}handle = NULL;mWrappedBuffer = 0;}
指向同一块图形Buffer的GraphicBuffer可以存在多个实例,但是底层的图形Buffer是同一个。
此外,GraphicBufferAllocator会记录所有分配的GraphicBuffer,通过adb shell dumpsys SurfaceFlinger查看:
// GraphicBufferAllocator的dump信息Allocated buffers:// 分别表示buffer_handle_t地址,图形Buffer的大小,宽(stride)*高、像素格式,usage等0x76fd25a070: 1546.00 KiB | 459 ( 512) x 773 | 1 | 1 | 0x10000900 | PopupWindow:e2334a2#00x76fd25a7e0: 9945.00 KiB | 1080 (1088) x 2340 | 1 | 1 | 0x10000900 | StatusBar#00x76fd837220: 9945.00 KiB | 1080 (1088) x 2340 | 1 | 1 | 0x10001a00 | FramebufferSurface// 表示分配的图形Buffer的总大小Total allocated (estimate): 112834.50 KB
这里再提出一个疑问:GraphicBuffer是在哪个进程分配的?
要解释这个问题,需要了解BufferQueue逻辑,这里不做深入介绍,后面会单独文章分析。直接给出结论:BufferQueueProducer通过BufferQueueCore持有的IGraphicBufferAlloc创建GraphicBuffer,而IGraphicBufferAlloc的实现类GraphicBufferAlloc则运行在SurfaceFlinger进程。也就是说,真正分配GraphicBuffer的只有Surfaceflinger进程,其他进程只不过是映射操作。
总结
本篇文章分析了grallocHAL模块,以及libui库主要逻辑。下一篇文章继续向上看下libgui库主要逻辑。
