@nemos
2017-05-09T09:18:40.000000Z
字数 3318
阅读 1455
sklearn
ml
参考
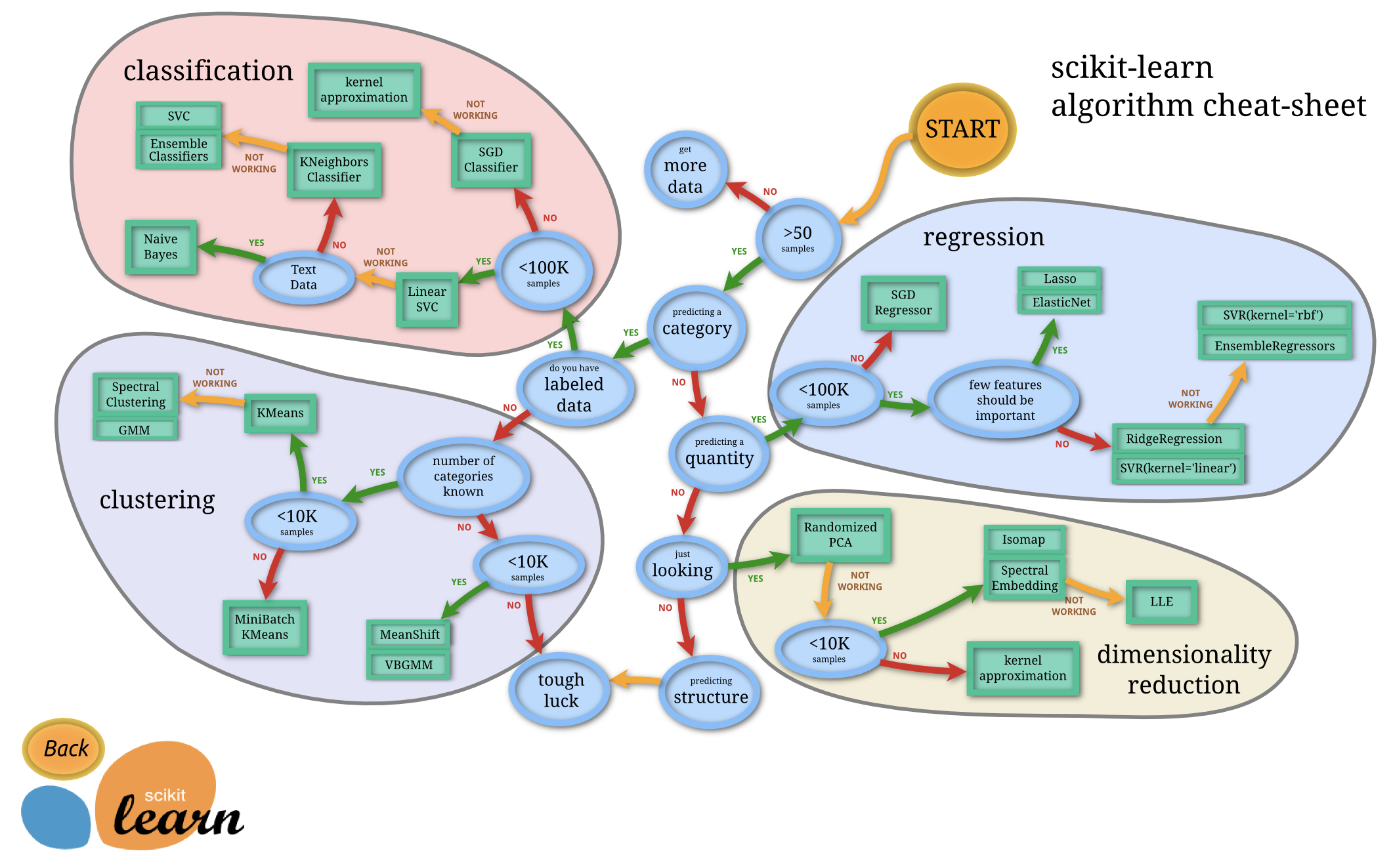
快速入门
from sklearn import datasetsfrom sklearn.cross_validation import train_test_splitfrom sklearn.neighbors import KNeighborsClassifier# 数据载入iris = datasets.load_iris()iris_X = iris.datairis_Label = iris.target# 训练集和测试集的分割X_train, X_test, label_train, label_test = train_test_split(iris_X, iris_Label,test_size=0.3) # 测试集比例# 初始化模型knn = KNeighborsClassifier()# 模型训练knn.fit(X_train, label_train)# 模型预测y_test = knn.predict(X_test)# 模型评估knn.score(x_test, y_test)
详细说明
特征工程
预处理
sklearn.preprcessing
规范化:
MinMaxScaler:最大最小值规范化Normalizer:使每条数据各特征值的和为1StandardScaler:为使各特征的均值为0,方差为1
编码:
LabelEncoder:把字符串类型的数据转化为整型OneHotEncoder:特征用一个二进制数字来表示Binarizer:为将数值型特征的二值化MultiLabelBinarizer:多标签二值化
抽取
sklearn.feature_extraction
dictvectorizer: 将dict类型的list数据,转换成numpy arrayfeaturehasher: 特征哈希,相当于一种降维技巧image:图像相关的特征抽取text: 文本相关的特征抽取text.countvectorizer:将文本转换为每个词出现的个数的向量text.tfidfvectorizer:将文本转换为tfidf值的向量text.hashingvectorizer:文本的特征哈希
选择
sklearn.feature_selection
VarianceThreshold: 删除特征值的方差达不到最低标准的特征SelectKBest: 返回k个最佳特征SelectPercentile: 返回表现最佳的前r%个特征
降维
sklearn.decomposition
集成
sklearn.ensemble
BaggingClassifier: Bagging分类器组合BaggingRegressor: Bagging回归器组合AdaBoostClassifier: AdaBoost分类器组合AdaBoostRegressor: AdaBoost回归器组合GradientBoostingClassifier:GradientBoosting分类器组合GradientBoostingRegressor: GradientBoosting回归器组合ExtraTreeClassifier:ExtraTree分类器组合ExtraTreeRegressor: ExtraTree回归器组合RandomTreeClassifier:随机森林分类器组合RandomTreeRegressor: 随机森林回归器组合
评估
sklearn.metrics
分数
分类
accuracy_score:分类准确度condusion_matrix:分类混淆矩阵classification_report:分类报告precision_recall_fscore_support:计算精确度、召回率、f、支持率jaccard_similarity_score:计算jcaard相似度hamming_loss:计算汉明损失zero_one_loss:0-1损失hinge_loss:计算hinge损失log_loss:计算log损失
回归
explained_varicance_score:可解释方差的回归评分函数mean_absolute_error:平均绝对误差mean_squared_error:平均平方误差
多标签
coverage_error:涵盖误差label_ranking_average_precision_score:计算基于排名的平均误差Label ranking average precision (LRAP)
聚类
adjusted_mutual_info_score:调整的互信息评分silhouette_score:所有样本的轮廓系数的平均值silhouette_sample:所有样本的轮廓系数
曲线
学习曲线,样本集由小变大时模型的评估。
from sklearn.learning_curve import learning_curvetrain_sizes, train_loss, test_loss = learning_curve(model, X, label,cv=10, scoring='mean_squared_error',train_sizes=[0.1, 0.25, 0.5, 0.75, 1]) # 每一轮样本占总样本的百分比。
模型曲线
from sklearn.learning_curve import validation_curve# 参数测试集param_range = np.logspace(-6, -2.3, 5)train_loss, test_loss = validation_curve(Model(), X, y,param_name='gamma', # 指定参数名param_range=param_range, # 指定参数取值范围个步长cv=10, scoring='mean_squared_error')
交叉验证
sklearn.cross_validation
模型训练
KFold:K-Fold交叉验证迭代器。接收元素个数、fold数、是否清洗LeaveOneOut:LeaveOneOut交叉验证迭代器LeavePOut:LeavePOut交叉验证迭代器LeaveOneLableOut:LeaveOneLableOut交叉验证迭代器LeavePLabelOut:LeavePLabelOut交叉验证迭代器
其他
train_test_split:分离训练集和测试集(不是K-Fold)cross_val_score:交叉验证评分,可以指认cv为上面的类的实例cross_val_predict:交叉验证的预测。
参数搜索
sklearn.grid_search
GridSearchCV:搜索指定参数网格中的最佳参数ParameterGrid:参数网格ParameterSampler:用给定分布生成参数的生成器RandomizedSearchCV:超参的随机搜索
通过best_estimator_.get_params()方法,获取最佳参数。
数据集
# 数据导入loaded_data = datasets.load_boston()data_X = loaded_data.datadata_label = loaded_data.target# 数据生成X, label = datasets.make_regression(n_samples=100, # 样本数n_features=1, # 特征数n_targets=1, # label数noise=10)
生产配置
from sklearn import svmfrom sklearn import datasetsclf = svm.SVC()iris = datasets.load_iris()X, y = iris.data, iris.targetclf.fit(X,y)from sklearn.externals import joblib #jbolib模块#保存Model(注:save文件夹要预先建立,否则会报错)joblib.dump(clf, 'save/clf.pkl')#读取Modelclf3 = joblib.load('save/clf.pkl')
