@nemos
2017-05-06T02:10:38.000000Z
字数 10946
阅读 1315
scrapy
py
快速入门
$ scrapy startproject tutorial # 初始化一个项目
import scrapyclass MySpider(scrapy.Spider):name = "myspider" # 爬虫名,必须唯一start_urls = []# 初始化的url,上下选其一def start_requests(self):urls = []for url in urls:yield scrapy.Request(url=url, callback=self.parse)#必须返回一个Request对象的迭代器,显式指定开始爬取的url和解析的函数# 默认response处理函数def parse(self, response):# 消息派发,对response存储完后再取其中有用的url进行增量爬取self.process_data(response)yield scrapy.Request(response.url, callback=self.parse)def process_data(self, response):pass
命令行启动
$ scrapy crawl myspider
详细说明
目录层次
scrapy.cfg: 项目的配置文件tutorial/: 该项目的python模块, 在这里添加代码items.py: 项目中的item文件pipelines.py: 项目中的pipelines文件.settings.py: 项目全局设置文件.spiders/ 爬虫模块目录
脚本启动
from scrapy.crawler import CrawlerProcessfrom scrapy.utils.project import get_project_settingsfrom spiders.MySpider import MySpider# 获取settings.py模块的设置settings = get_project_settings()process = CrawlerProcess(settings=settings)# 指定要启动的爬虫process.crawl(MySpider)# 启动爬虫,会阻塞,直到爬取完成process.start()
Spider
class MySpider(scrapy.Spider):name #唯一名称allowed_domains #指定域名范围start_urls #指定开始爬取的链接custom_settings #重写默认设置crawler #指定爬取者,被from_crawler()指定,Crawler的实例settings #指定设置,Settings的实例logger #指定logger#######################################################from_crawler(crawler, *args, **kwargs) #指定Crawler实例,并向__init__传递参数start_requests() #必须返回Requrst对象的迭代对象make_requests_from_url(url) #接受url返回Request对象,默认回调parseparse(response) #默认的回调,解析请求内容log(message[, level, component]) #设置loggerclosed(reason) #但爬虫被关闭时被调用##########################CrawlSpider # 可以定制规则
Request
# 构造参数class scrapy.http.Request(url[,callback, # 响应的函数method='GET',headers,body,cookies,meta,encoding='utf-8',priority=0, # 优先级dont_filter=False, # 请求完是否过滤,想多次请求指定Trueerrback] # 请求失败的回调函数)# 实例属性request.urlrequest.methodrequest.headersrequest.bodyrequest.meta # 包含请求元数据的字典,当请求被复制时会被浅拷贝request.copy() # 返回一个请求的拷贝request.replace() # 返回一个替换过的请求,参数与初始化时相同
# 用于表单验证class scrapy.http.FormRequest(url[, formdata, ...])#返回一个填充好的FormRequest实例scrapy.FormRequest.from_response(response[, # 需要填充的表单formname=None,formnumber=0,formdata=None, # 需要填充的数据formxpath=None,formcss=None,clickdata=None,dont_click=False,...])# 模拟登陆示例class LoginSpider(scrapy.Spider):name = 'example'start_urls = ['http://www.example.com/users/login.php']def parse(self, response):return scrapy.FormRequest.from_response(response,formdata={'username': 'john', 'password': 'secret'},callback=self.after_login)def after_login(self, response): #执行一些登陆后的操作if "authentication failed" in response.body: #检查是否成功登陆self.logger.error("Login failed")
Response
# 构造方法class scrapy.http.Response(url[, status=200, headers=None, body=b'', flags=None, request=None])# 实例属性response.url # 请求的urlresponse.status # 响应状态码response.headers # 响应头,使用get()获得第一个,getlist()获得所有response.body # 响应体response.request # 响应的请求实例response.meta # 相当与request.metaresponse.flags # 响应的标记response.copy() # 返回响应的拷贝response.replace() # 返回替换过的响应对象response.urljoin(url) # 构造一个绝对路径
class scrapy.http.TextResponse(url[, encoding[, ...]])text_response.text # 响应体,作为unicode返回,同response.body.decode(response.encoding)text_response.encoding # 指定的编码text_response.selector # 选择器支持css和xpathtext_response.css() # 快捷方式text_response.xpath() # 快捷方式text_response.body_as_unicode() # 同text
Selector
selector相当于节点,通过选择再到子节点的集合,所有可以支持链式调用。
注意css和xpath的内部实现是相同的所以可以混合使用。
# 构造class scrapy.selector.Selector(response=None, # 从response中实例text=None, # 同上type=None)# 使用# response实例的快捷方法response.css() #返回SelectorListresponse.xpath() #选择不到对象会返回Noneresponse.css('img').xpath('@src') # 混合使用html = '<html><body><span>good</span><span>buy</span></body></html>'selector = Selector(text=html)nodes = selector.xpath('//span')for node in nodes:node.extract() # 取出内容返回listnode.extract_first() # 取得list的第一个元素
Item & Loader
用于结构化数据
使用
# item.pyfrom scrapy import Item, Fieldclass MyItem(Item):title = Field()link = Field()desc = Field()# spider.pyclass MySpider(scrapy.Spider):...def parse(self, response):for sel in response.xpath('//ul/li'):item = MyItem()item['title'] = sel.xpath('a/text()').extract()item['link'] = sel.xpath('a/@href').extract()tem['desc'] = sel.xpath('text()').extract()print dmoz_item
使用ItemLoader加载数据
from scrapy.loader import ItemLoaderfrom myproject.items import MyItemdef parse(self, response):loader = ItemLoader(item=MyItem, response=response)loader.add_xpath('name', '//div[@class="xxx"]')loader.add_css('stock', 'p#xxx]')loader.add_value('last_updated', 'today') # you can also use literal valuesreturn loader.load_item() # 填充item
定制ItemLoader
数据流动方向:
xpath或css解析 > input_processor > loader > output_processor > item
from scrapy.contrib.loader import ItemLoaderfrom scrapy.contrib.loader.processor import TakeFirst, MapCompose, Joinclass ProductLoader(ItemLoader):# 默认的输入/出处理器default_input_processor = TakeFirst()default_output_processor = TakeFirst()# in为输入时调用的处理器,out同理name_in = MapCompose(unicode.title)name_out = Join()
上下文字典,loader声明,创建,调用时都能使用到一个上下文字段用于处理上下文相关数据
# 修改实例loader = ItemLoader(product)loader.context[‘unit’] = ‘cm’# 实例化时传入loader = ItemLoader(product, unit=’cm’)# 处理器支持class ProductLoader(ItemLoader):length_out = MapCompose(parse_length, unit=’cm’)
内置处理器
class scrapy.loader.processors 模块
Identity直接返回TakeFirst返回第一个非空值Join(separator=' ')返回分割符连接后的值Compose(*functions, **default_loader_context)值流过多个函数后返回,相当于管道MapCompose(*functions, **default_loader_context)类似上一个,但是输入值被迭代处理SelectJmes(json_path)# 查询指定json路径并返回
- 需要jmes支持
Pipeline
数据深度处理
# 过滤重复的链接from scrapy.exceptions import DropItemclass DuplicatesPipeline(object):def __init__(self):self.links = set()# process_item为固定的回调函数名def process_item(self, item, spider):if item['link'] in self.links:# 跑出DropItem表示丢掉数据raise DropItem("Duplicate item found: %s" % item)else:self.links.add(item['link'])return item
# 保存数据from Database import Databaseclass DatabasePipeline(object):def __init__(self):self.db = Databasedef process_item(self, item, spider):if self.db.item_exists(item['id']):self.db.update_item(item)else:self.db.insert_item(item)
除process_item外还有
open_spider, spider_closed
配置
setting.py全局配置
ITEM_PIPELINES = {'pipelines.DuplicatesPipeline.DuplicatesPipeline': 1,'pipelines.DatabasePipelin.DatabasePipelin': 2,}
单独配置
class MySpider(Spider):# 自定义配置custom_settings = {'ITEM_PIPELINES': {'tutorial.pipelines.DatabasePipeline.DatabasePipelin': 1,},}
Rule
对连接规则的提取
from scrapy.spiders import CrawlSpider, Rulefrom scrapy.linkextractors import LinkExtractorclass LianjiaSpider(CrawlSpider):name = "lianjia"allowed_domains = ["lianjia.com"]start_urls = ["http://bj.lianjia.com/ershoufang/"]rules = [# 匹配正则表达式,处理下一页Rule(LinkExtractor(allow=(r'http://bj.lianjia.com/ershoufang/pg\s+$',)), callback='parse_item'),# 匹配正则表达式,结果加到url列表中,设置请求预处理函数# Rule(FangLinkExtractor(allow=('http://www.lianjia.com/client/', )), follow=True, process_request='add_cookie')]def parse_item(self, response):pass
class scrapy.spiders.Rule(link_extractor,callback=None, # link_ex的回调函数cb_kwargs=None, # 附加参数follow=None, # 是否对请求完的链接应用当前的规则process_links=None, # 处理所有连接的回调用于过滤process_request=None # 链接请求预处理添加headers之类的)
class scrapy.linkextractors.lxmlhtml.LxmlLinkExtractor(allow=(), # 提取满足正则的连接deny=(), # 排除满足正则的链接allow_domains=(), #deny_domains=(),deny_extensions=None, # 排除的后缀名restrict_xpaths=(), # 满足xpath的链接restrict_css=(), # 同上tags=('a', 'area'), # 提取指定标签下的连接attrs=('href', ), # 提取拥有满足属性的连接canonicalize=True, # 是否规范化unique=True, # 链接去重process_value=None # 值处理函数)
Middleware
import randomclass RandomUserAgentMiddleware(object):"""Randomly rotate user agents based on a list of predefined ones"""def __init__(self, agents):self.agents = agents# 从crawler构造,USER_AGENTS定义在crawler的配置的设置中@classmethoddef from_crawler(cls, crawler):return cls(crawler.settings.getlist('USER_AGENTS'))# 从settings构造,USER_AGENTS定义在settings.py中@classmethoddef from_settings(cls, settings):return cls(settings.getlist('USER_AGENTS'))def process_request(self, request, spider):# 设置随机的User-Agentrequest.headers.setdefault('User-Agent', random.choice(self.agents))
DownloaderMiddleware 下载中间件
注意所有函数都是惰性的
class scrapy.downloadermiddlewares.DownloaderMiddlewaredef process_request(request, spider):yield Request # 返回请求,并向下传递yield None # 忽略次中间件并传递到下一个中间件yield Response # 直接中断,返回请求raise IgnoreRequest # 调用self.process_exception(),无则调用Request.errbackdef process_response(request, reponse, spider):yield Request # 中断并传递请求到下载器yield Response # 传递到下一个中间件raise IgnoreRequest # 调用Request.errback() 无则忽略def process_exception(request, exception, spider):yield Noneyield Responseyield Request# setting.pyDOWNLOADER_MIDDLEWARES = {'myproject.middlewares.CustomDownloaderMiddleware': 543,# None 指定关闭'scrapy.contrib.downloadermiddleware.useragent.UserAgentMiddleware': None,}
内置的下载中间件
class scrapy.downloadermiddlewares.cookies.CookiesMiddleware# setting.pyCOOKIES_ENABLEDCOOKIES_DEBUGclass scrapy.downloadermiddlewares.defaultheaders.DefaultHeadersMiddleware# setting.pyDEFAULT_REQUEST_HEADERSclass scrapy.downloadermiddlewares.downloadtimeout.DownloadTimeoutMiddleware# setting.pyDOWNLOAD_TIMEOUT# 认证相关class scrapy.contrib.downloadermiddleware.httpauth.HttpAuthMiddleware# 缓存相关class scrapy.downloadermiddlewares.httpcache.HttpCacheMiddleware
单spider多cookies
# 通过meta字段传递for i, url in enumerate(urls):yield scrapy.Request("http://www.example.com", meta={'cookiejar': i},callback=self.parse_page)# 转发时需要重新指明def parse_page(self, response):# do some processingreturn scrapy.Request("http://www.example.com/otherpage",meta={'cookiejar': response.meta['cookiejar']},callback=self.parse_other_page)
Setting
Cache
# setting.py# 打开缓存HTTPCACHE_ENABLED = True# 设置缓存过期时间(单位:秒)HTTPCACHE_EXPIRATION_SECS = 0# 缓存路径(默认为:.scrapy/httpcache)HTTPCACHE_DIR = 'httpcache'# 忽略的状态码HTTPCACHE_IGNORE_HTTP_CODES = []# 缓存模式(文件缓存)HTTPCACHE_STORAGE = 'scrapy.extensions.httpcache.FilesystemCacheStorage'
多线程
# 默认Item并发数:100CONCURRENT_ITEMS = 100# 默认Request并发数:16CONCURRENT_REQUESTS = 16# 默认每个域名的并发数:8CONCURRENT_REQUESTS_PER_DOMAIN = 8# 每个IP的最大并发数:0表示忽略CONCURRENT_REQUESTS_PER_IP = 0
异常处理
from scrapy.spidermiddlewares.httperror import HttpErrorfrom twisted.internet.error import DNSLookupErrorfrom twisted.internet.error import TimeoutError, TCPTimedOutErrordef errback(self, failure): #在Request初始化时指定的回调函数if failure.check(HttpError): #检查错误类型failure.value.response #响应的实例failure.request #请求的实例
meta
传递数据
def parse_page1(self, response):item = MyItem()item['main_url'] = response.urlrequest = scrapy.Request("http://www.example.com/some_page.html",callback=self.parse_page2)request.meta['item'] = item #使用meta传递了itemreturn requestdef parse_page2(self, response):item = response.meta['item']item['other_url'] = response.urlreturn item
指定特殊键
| 键名 | 含义 |
|---|---|
dont_redirect |
|
dont_retry |
|
handle_httpstatus_list |
|
handle_httpstatus_all |
|
dont_merge_cookies (see cookies parameter of Request constructor) |
|
cookiejar |
|
dont_cache |
|
redirect_urls |
|
bindaddress |
|
dont_obey_robotstxt |
|
download_timeout |
|
download_maxsize |
|
download_latency |
|
proxy |
引用
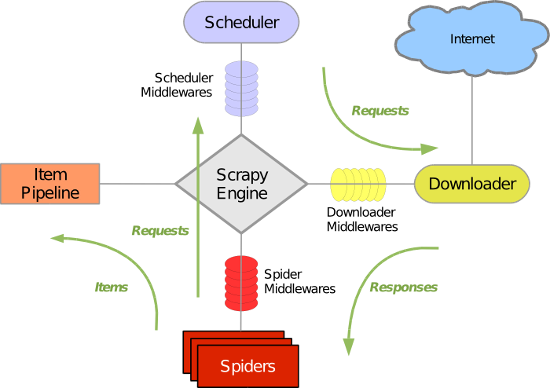
引擎(Scrapy)
用来处理整个系统的数据流处理, 触发事务(框架核心)
调度器(Scheduler)
用来接受引擎发过来的请求, 压入队列中, 并在引擎再次请求的时候返回. 可以想像成一个URL(抓取网页的网址或者说是链接)的优先队列, 由它来决定下一个要抓取的网址是什么, 同时去除重复的网址
下载器(Downloader)
用于下载网页内容, 并将网页内容返回给蜘蛛(Scrapy下载器是建立在twisted这个高效的异步模型上的)
爬虫(Spiders)
爬虫是主要干活的, 用于从特定的网页中提取自己需要的信息, 即所谓的实体(Item)。用户也可以从中提取出链接,让Scrapy继续抓取下一个页面
项目管道(Pipeline)
负责处理爬虫从网页中抽取的实体,主要的功能是持久化实体、验证实体的有效性、清除不需要的信息。当页面被爬虫解析后,将被发送到项目管道,并经过几个特定的次序处理数据。
下载器中间件(Downloader Middlewares)
位于Scrapy引擎和下载器之间的框架,主要是处理Scrapy引擎与下载器之间的请求及响应。
爬虫中间件(Spider Middlewares)
介于Scrapy引擎和爬虫之间的框架,主要工作是处理蜘蛛的响应输入和请求输出。
调度中间件(Scheduler Middewares)
介于Scrapy引擎和调度之间的中间件,从Scrapy引擎发送到调度的请求和响应。
Scrapy运行流程大概如下:
引擎从调度器中取出一个链接(URL)用于接下来的抓取
引擎把URL封装成一个请求(Request)传给下载器
下载器把资源下载下来,并封装成应答包(Response)
爬虫解析Response
解析出实体(Item),则交给实体管道进行进一步的处理
解析出的是链接(URL),则把URL交给调度器等待抓取
