@rianusr
2019-08-13T02:15:30.000000Z
字数 6086
阅读 2429
机器学习02:监督学习01:构建第一个分类模型
06-机器学习
0 本章概况
0.1 本章学习目标
- 快速构建你的第一个简单分类模型
- 简单了解分类模型的优化方向
0.2 课程安排

1 构建第一个分类模型
1.1 分类问题

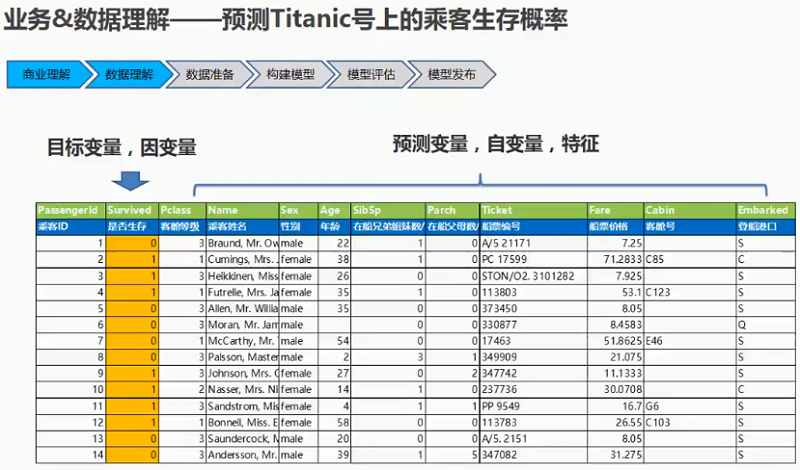
1.2 kaggle竞赛经典案例--预测Titanic号上的乘客生存概率
1.2.1 业务和数据理解
1.2.2 数据准备
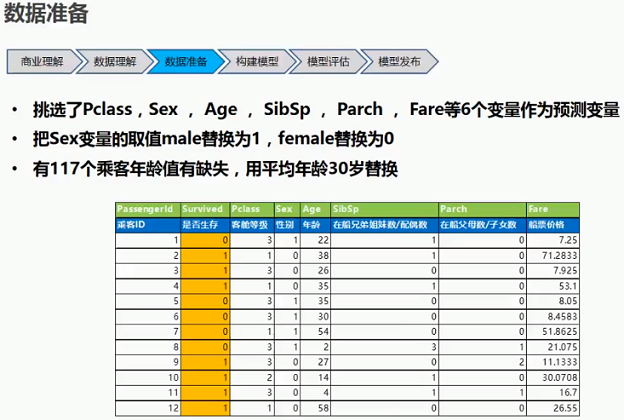
(1):挑选特征变量
(2):特征变量变换
(3):缺失值处理
1.2.3 构建模型-逻辑回归模型

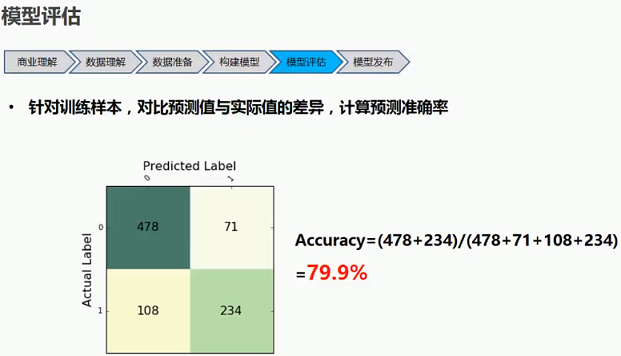
1.2.4 模型评估
1.2.5 模型发布
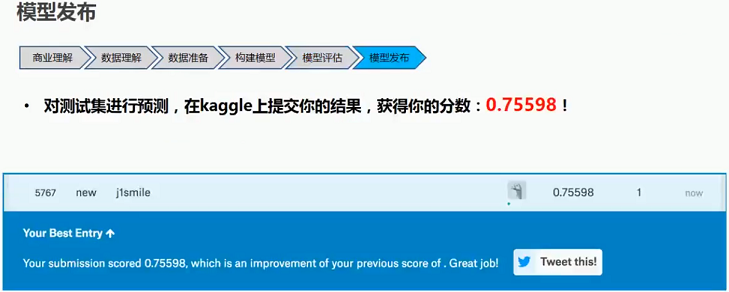
2 代码实现 -- 基于Numpy和pandas
import numpy as npimport pandas as pdfrom sklearn.linear_model import LogisticRegressionfrom sklearn import metricsimport matplotlib.pyplot as plt%matplotlib inlinefrom IPython.core.interactiveshell import InteractiveShellInteractiveShell.ast_node_interactivity = "all"import warningswarnings.filterwarnings("ignore")train_src=pd.read_csv("./../data/titanic_data/train.csv")train_src.info()train_src.head()# Age分布train_src.hist(column="Age",bins=50)# 性别分布train_src["Sex"].value_counts().plot(kind="bar")# Sex与目标(是否生存)的相关性pd.crosstab(train_src["Sex"],train_src["Survived"]).plot(kind="bar")# Pclass与目标(是否生存)的相关性pd.crosstab(train_src["Pclass"],train_src["Survived"]).plot(kind="bar")# Age与目标(是否生存)的相关性train_src.age=pd.cut(train_src.Age,[0,5,15,20,35,50,60,100])pd.crosstab(train_src.age,train_src.Survived).plot(kind="bar")# 筛选Plcass,Sex,Age,SibSp,Parch,Fare六个变量作为预测变量(特征)train=train_src[["Survived","Pclass","Sex","Age","SibSp","Parch","Fare"]]# 把Sex变量的取值male替换为1,female替换为0train["Sex"]=train["Sex"].replace({"male":1,"female":0})#有117和乘客Age有缺失,用平均年龄替换age_mean=train["Age"].mean()train["Age"]=train["Age"].fillna(age_mean)# 查看一下准备好的数据集train.head(10)train.describe()# 拆分出自变量X,目标变量ytrain_X = train.ix[:,1:] # 训练集自变量train_y = train["Survived"] #训练集因变量# 使用逻辑回归算法训练模型lr = LogisticRegression() #使用默认参数lr.fit(train_X,train_y) #训练# 查看lr模型的系数print (lr.coef_)print(train_X.columns)pd.DataFrame(list(zip(np.transpose(lr.coef_),train_X.columns)),columns=["coef","columns"])train_y_pred=lr.predict(train_X) #对训练集进行预测,输出标签train_y_pred_prob=lr.predict_proba(train_X) # 对训练集进行预测,输出概率print(train_y_pred)print(train_y_pred_prob)# 误分类矩阵cnf_matrix=metrics.confusion_matrix(train_y,train_y_pred)print(cnf_matrix)# 准确率precision = metrics.accuracy_score(train_y,train_y_pred)print(precision)# 更直观一点的展现误分类矩阵def show_confusion_matrix(cnf_matrix,class_labels):plt.matshow(cnf_matrix,cmap=plt.cm.YlGn,alpha=0.7)ax=plt.gca()ax.set_xlabel("Predicted Label",fontsize=16)ax.set_xticks(range(0,len(class_labels)))ax.set_xticklabels(class_labels,rotation=45)ax.set_ylabel("Actual Label",fontsize=16,rotation=90)ax.set_yticks(range(0,len(class_labels)))ax.set_yticklabels(class_labels)ax.xaxis.set_label_position("top")ax.xaxis.tick_top()for row in range(len(cnf_matrix)):for col in range(len(cnf_matrix[row])):ax.text(col,row,cnf_matrix[row][col],va="center",ha="center",fontsize=16)class_labels=[0,1]show_confusion_matrix(cnf_matrix,class_labels)# 测试数据准备,与训练集的准备完全一致test_src=pd.read_csv("./../data/titanic_data/test.csv")test=test_src[["PassengerId","Pclass","Sex","Age","SibSp","Parch","Fare"]]test["Sex"].replace({"male":1,"female":0},inplace=True)test["Age"].fillna(age_mean,inplace=True)# Fare船票价格在测试集中出现了控制,用训练集的平均值替换test["Fare"].fillna(round(train["Fare"].mean()),inplace=True)# 对测试数据预测test_X=test.ix[:,1:]test_y_pred = lr.predict(test_X) #对测试集进行预测test_pred = pd.DataFrame({"PassengerId":test["PassengerId"],"Survived":test_y_pred.astype(int)})test_pred.to_csv("./../data/titanic_data/test_pred_0601.csv",index=False)# 查看预测结果test_pred.head()
3 用测试集对模型进行交叉验证
3.1 课程目标

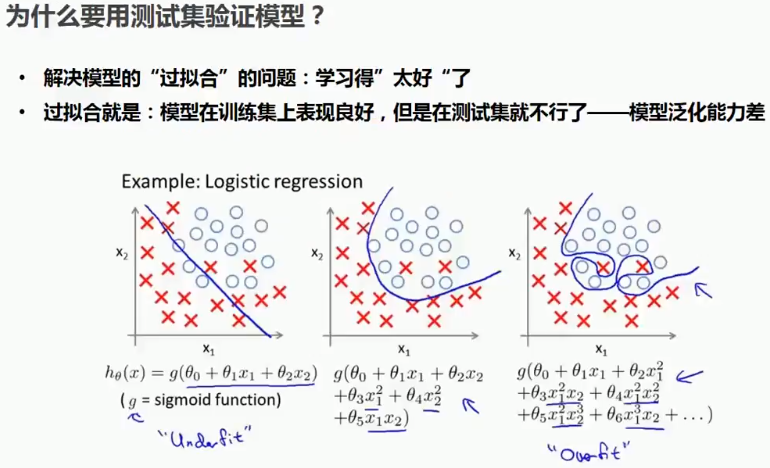
3.2 为什么要用测试集验证模型?
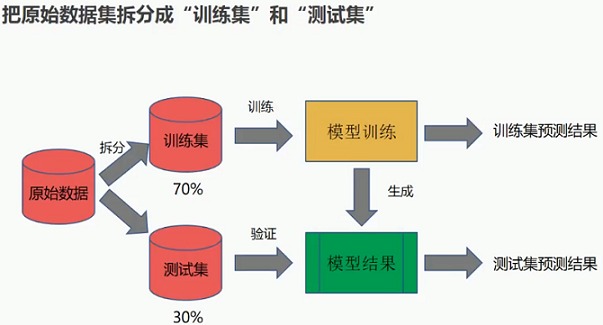
3.3 数据拆分
3.4 代码层面
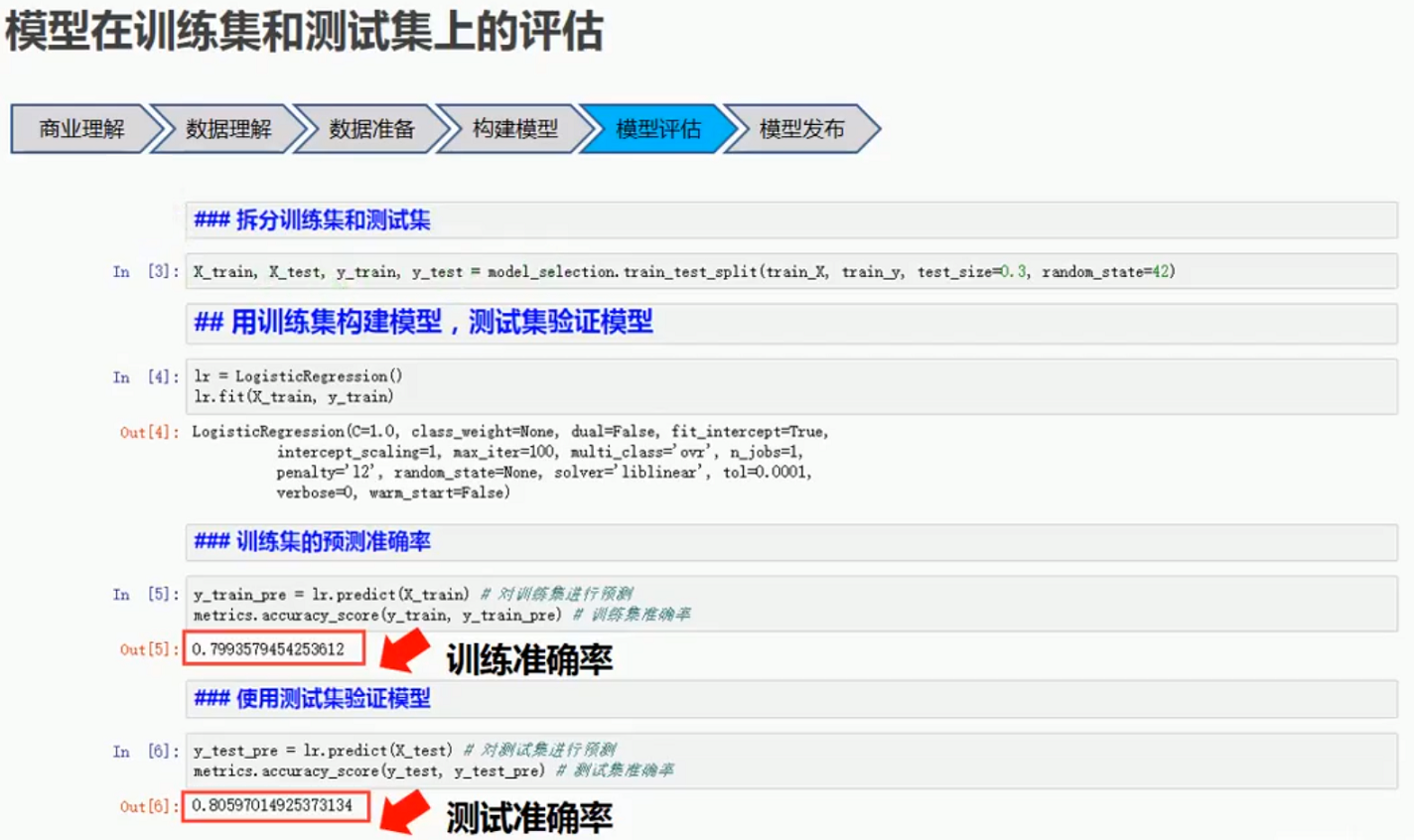
3.5 代码演示:拆分数据集,训练集进行训练,测试集进行预测
import numpy as npimport pandas as pdfrom sklearn.linear_model import LogisticRegressionfrom sklearn import metricsfrom sklearn import model_selectiomimport matplotlib.pyplot as plt%matplotlib inlinefrom IPython.core.interactiveshell import InteractiveShellInteractiveShell.ast_node_interactivity = "all"import warningswarnings.filterwarnings("ignore")train_src=pd.read_csv("./../data/titanic_data/train.csv")train_src.info()train_src.head()# Age分布train_src.hist(column="Age",bins=50)# 性别分布train_src["Sex"].value_counts().plot(kind="bar")# Sex与目标(是否生存)的相关性pd.crosstab(train_src["Sex"],train_src["Survived"]).plot(kind="bar")# Pclass与目标(是否生存)的相关性pd.crosstab(train_src["Pclass"],train_src["Survived"]).plot(kind="bar")# Age与目标(是否生存)的相关性train_src.age=pd.cut(train_src.Age,[0,5,15,20,35,50,60,100])pd.crosstab(train_src.age,train_src.Survived).plot(kind="bar")# 筛选Plcass,Sex,Age,SibSp,Parch,Fare六个变量作为预测变量(特征)train=train_src[["Survived","Pclass","Sex","Age","SibSp","Parch","Fare"]]# 把Sex变量的取值male替换为1,female替换为0train["Sex"]=train["Sex"].replace({"male":1,"female":0})#有117和乘客Age有缺失,用平均年龄替换age_mean=train["Age"].mean()train["Age"]=train["Age"].fillna(age_mean)# 查看一下准备好的数据集train.head(10)train.describe()# 拆分出自变量X,目标变量ytrain_X = train.ix[:,1:] # 训练集自变量train_y = train["Survived"] #训练集因变量X_train,X_test,y_train,y_test=model_selection.train_test_split(train_X,train_y,test_size=0.3,random_state=42)# 使用逻辑回归算法训练模型lr = LogisticRegression() #使用默认参数lr.fit(X_train,y_train) #训练y_train_pre=lr.predict(X_train) # 对训练集进行预测metrics.accuracy_score(y_train,y_train_pre) # 训练集准确率y_test_pre=lr.predict(X_test) # 对测试集进行预测metrics.accuracy_score(y_test,y_test_pre)
4 尝试其他的分类算法
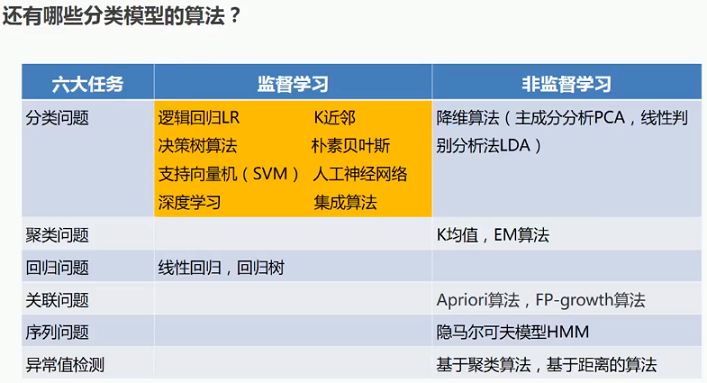
from sklearn.linear_model import LogisticRegressionfrom sklearn.svm import SVC,LinearSVCfrom sklearn.neighbors import KNeighborsClassifierfrom sklearn.tree import DecisionTreeClassifierfrom sklearn.ensemble import RandomForestClassifier
4.1 SVM
svc=SVC()svc.fit(X_train,y_train)print("train accurary:",svc.score(X_train,y_train))print("test accurary:",svc.score(X_test,y_test))
4.2 决策树
dtree=DecisionTreeClassifier()dtree.fit(X_train,y_train)print("train accurary:",dtree.score(X_train,y_train))print("test accurary:",dtree.score(X_test,y_test))
4.3 随机森林
random_forest=RandomForestClassifier(n_estimators=10)random_forest.fit(X_train,y_train)print("train accurary:",random_forest.score(X_train,y_train))print("test accurary:",random_forest.score(X_test,y_test))
4.4 K近邻
knn=KNeighborsClassifier(n_neighbors=3)knn.fit(X_train,y_train)print("train accurary:",knn.score(X_train,y_train))print("test accurary:",knn.score(X_test,y_test))
4.5 各个算法预测结果对比
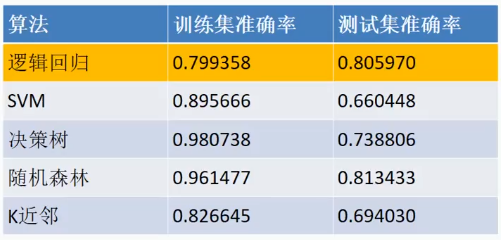
5 准备一个更好的训练集
5.1 准备更好的训练集

5.2 提取有价值的特征

5.3 缺失值处理
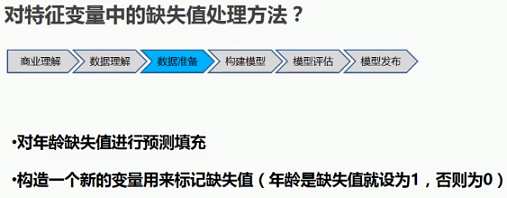
5.4 特征变量转化处理

5.5 特征变量汇总
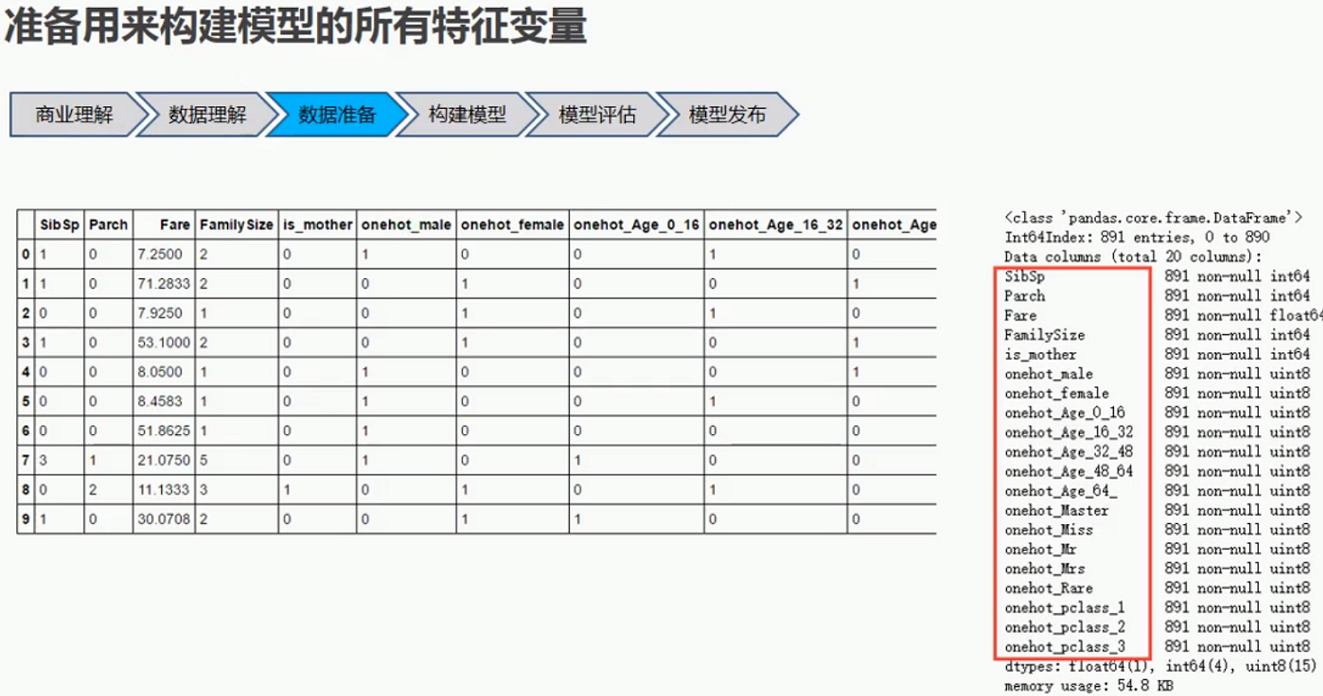
5.6 新模型的变量权重
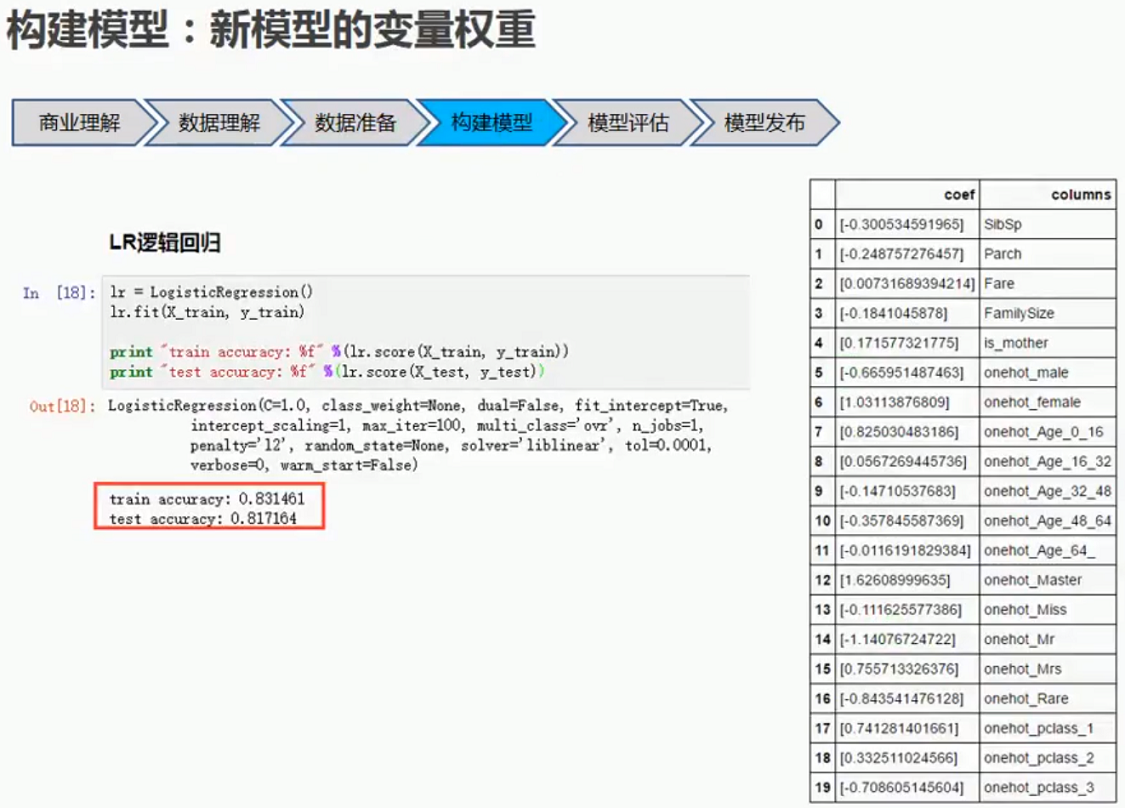
5.7 新模型评估
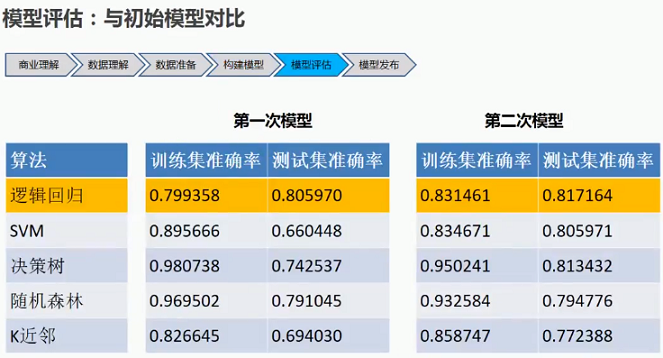
5.8 新模型发布
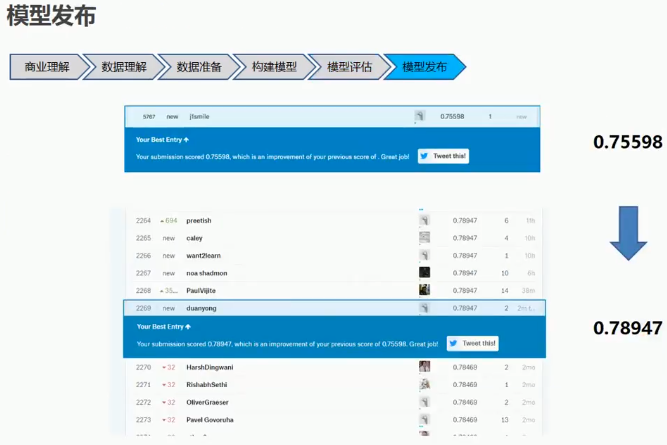
5.9 代码演示
#E:\Jupyter_workspace\Scikit-learn video learning\监督学习\准备一个更好的训练集.ipynb
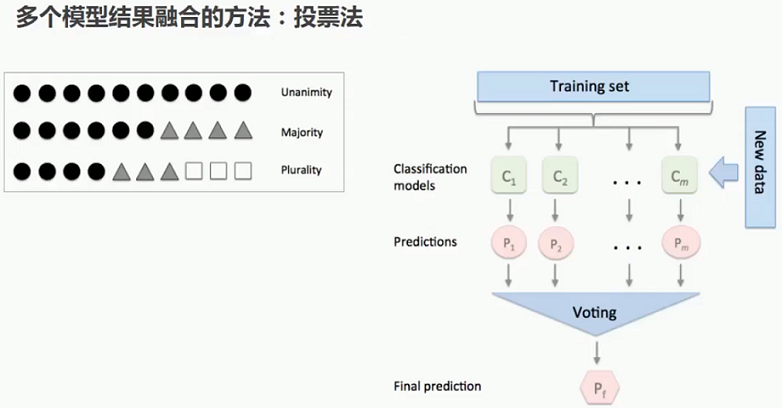
5 将多个模型的结果融合起来
5.1 多个模型的融合方法1:投票法(Voting)
5.2 模型融合后的结果对比
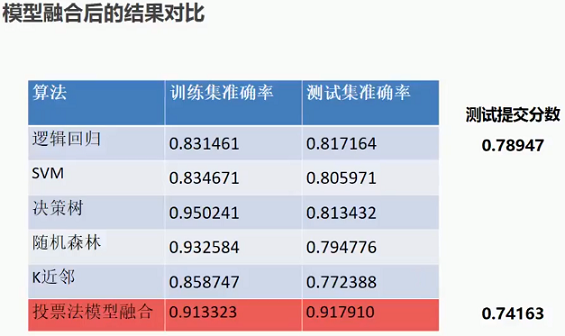
模型融合存在过拟合的现象
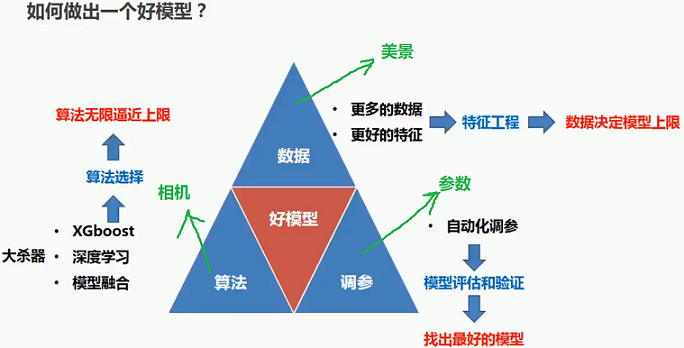
6 模型优化的三个要素