@wrlqwe
2016-02-28T16:08:29.000000Z
字数 1297
阅读 1281
一行命令查摇号(天津版)
开发 一个悲伤的故事
引言
去年刚下的车本,在天津试着抽签摇号,官网查询起来比较麻烦,于是写了个脚本查摇号,每月26号以后运行查看摇号结果,它运行起来是这样的:

如果你想了解它如何工作,可以Follow me,来制作这样一个脚本~
制作步骤
1. 准备
要完成这个工作,要用到4个工具:
1. Chrome 使用开发者工具分析网络请求
2. PostMan 发送模拟请求
3. BeyondCompare 对比文本
4. Shell命令行 脚本最后运行在这里
2. 官网查询请求分析
在天津小汽车调控管理系统中找到摇号结果查询的页面: http://apply.tjjttk.gov.cn/apply/norm/personQuery.html
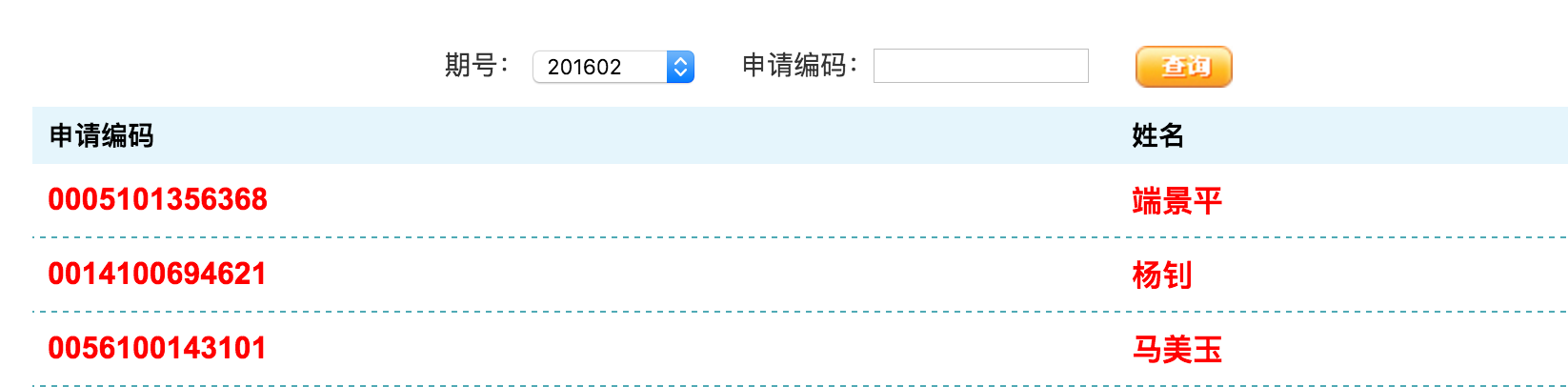
展开网页查看源码
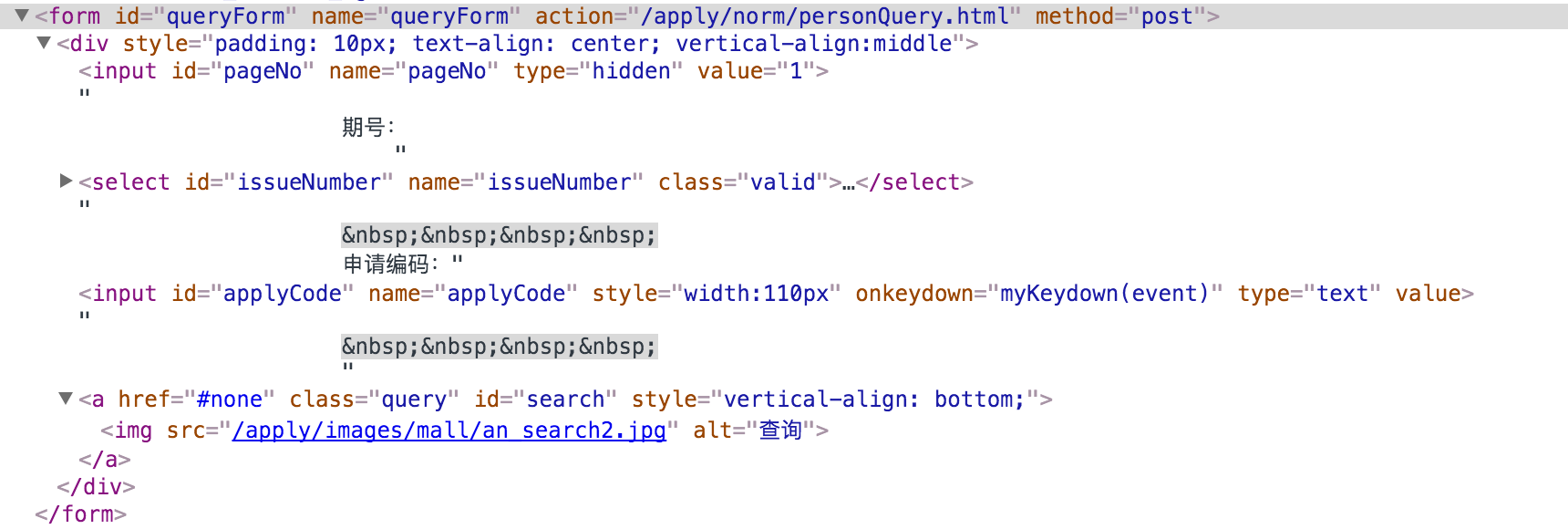
可以看到要想查询摇号结果,需要构建一个表单,参数分别为一个页码,一个申请编码和一个期号,以POST方法向服务器请求,其中页码默认是1,申请编码可以在个人的摇号申请页面查到,而期号遵循如下的规则:

可选的很多,不过选择第一个期号000000是最方便的。
这三个参数都齐活了,使用PostMan测试一下:
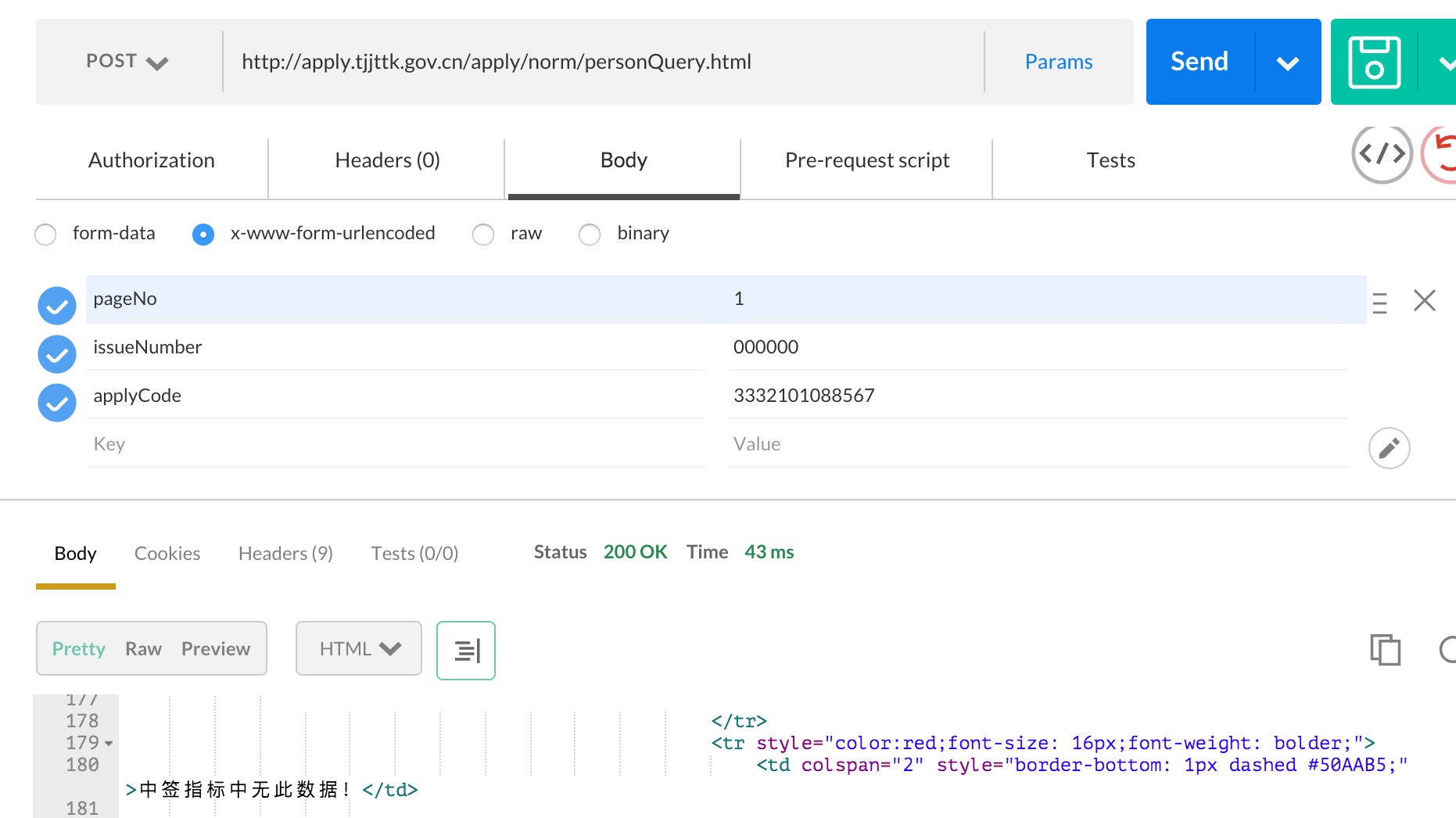
开发者工具Network里的请求,也证明请求没错:
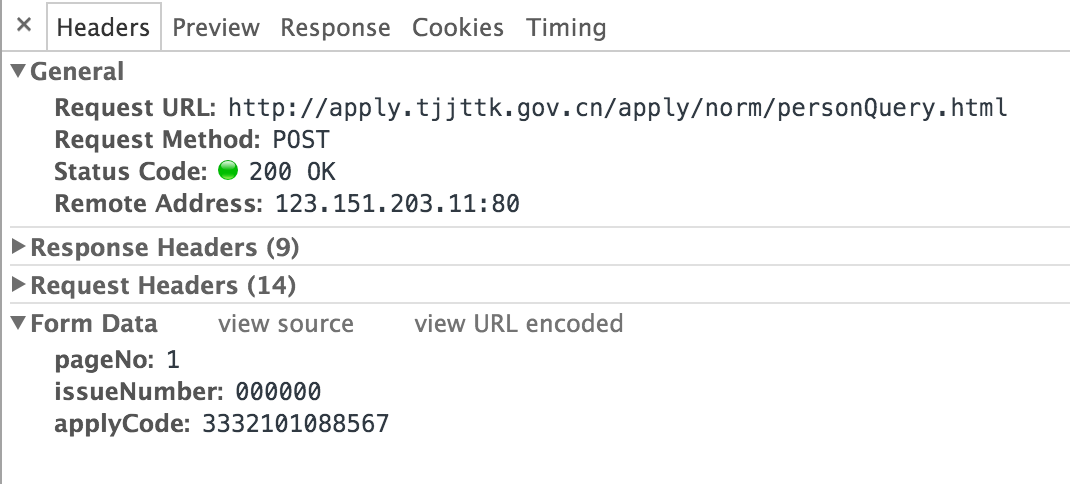
接下来要分析这个请求的结果。
我需要一个能查询摇号成功的编码和一个失败的编码,失败的用我本人的,成功的选择结果查询页面第一个人的,分析它们的异同,使用BeyondCompare对比发现,两个网页区别很小,有一处比较明显的差异:

这一行可以当作查询成功的标记。
3. 编写Shell脚本
首先要在命令行里模拟网络请求,要用到curl命令:
curl -X POST -d "pageNo=1&issueNumber=000000&applyCode=3332101088567" -ss http://apply.tjjttk.gov.cn//apply/norm/personQuery.html
其中-X指定方法, -d指定body, -ss控制不要输出进度。
执行这个命令,打印出了原始的html,接下来要对文本进行过滤,按照刚才发现的不同之处,筛选结果:
grep '中签指标中无此数据!'
如果没有中签,则会筛选出包含这个字符串的一行。
接下来查行数:
wc -l
根据行数,使用awk命令输出结果
awk '{if($1~/1/){ print "哇喔, 没有抽中,再接再厉哦"} else {print "恭喜!中奖了!"}}'
所有命令连起来是这样的:
curl -X POST -d "pageNo=1&issueNumber=000000&applyCode=3332101088567" -ss http://apply.tjjttk.gov.cn//apply/norm/personQuery.html | grep '中签指标中无此数据!' | wc -l | awk '{if($1~/1/){ print "哇喔, 没有抽中,再接再厉哦"} else {print "恭喜!中奖了!"}}'
done~
4. 改善
这一大坨命令直接生敲并不现实,所以我们把它保存到一个脚本文件里,文件内容如下:

为它添加可执行权限
chmod +X ~/bin/lottery
最后视情况把脚本添加到PATH环境下,done~
