@xlsd1996
2020-09-14T02:01:46.000000Z
字数 1567
阅读 667
路网匹配 工作记录
mapmatching 记录
8-15
预处理效果图:
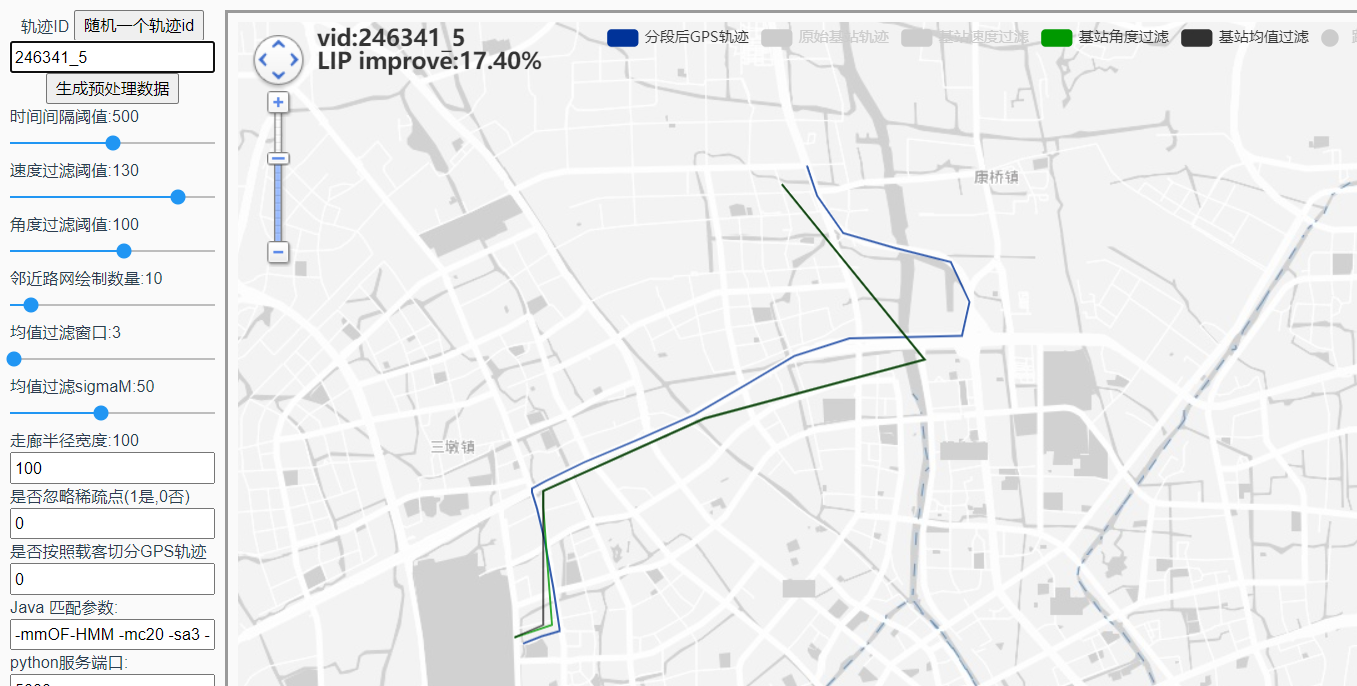
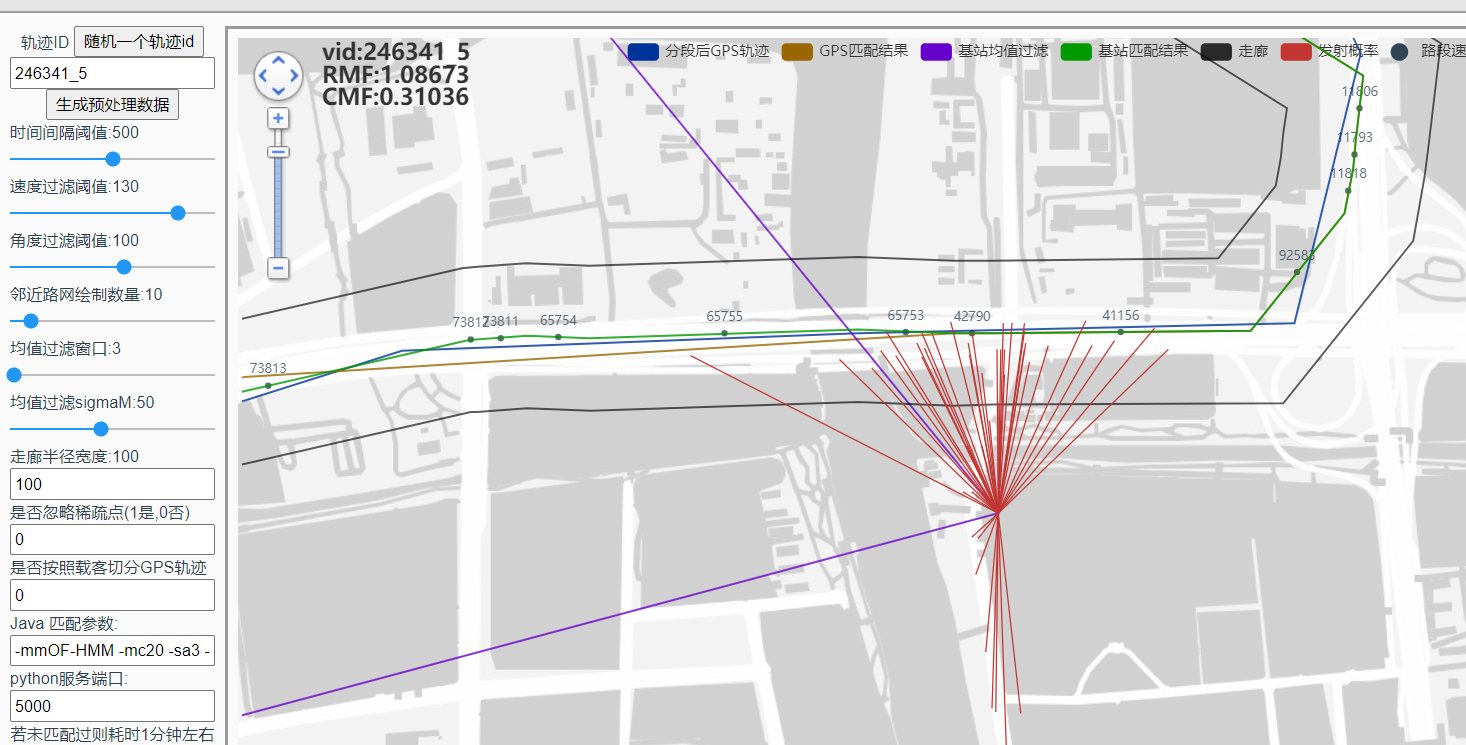
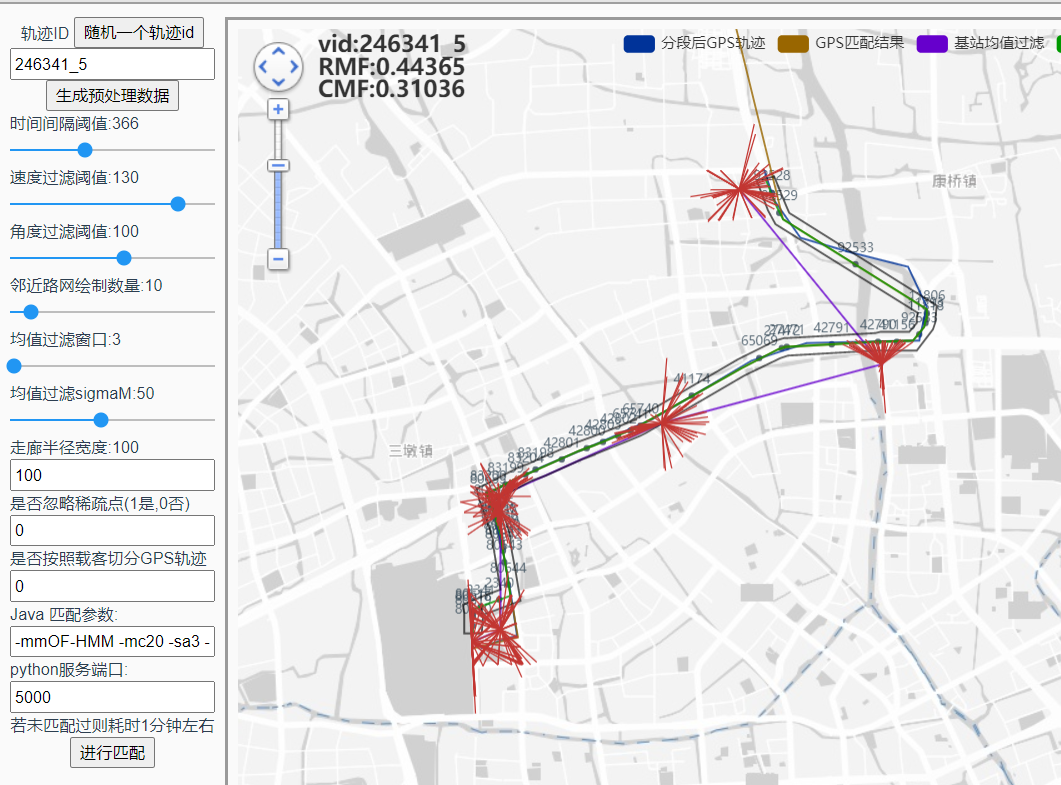
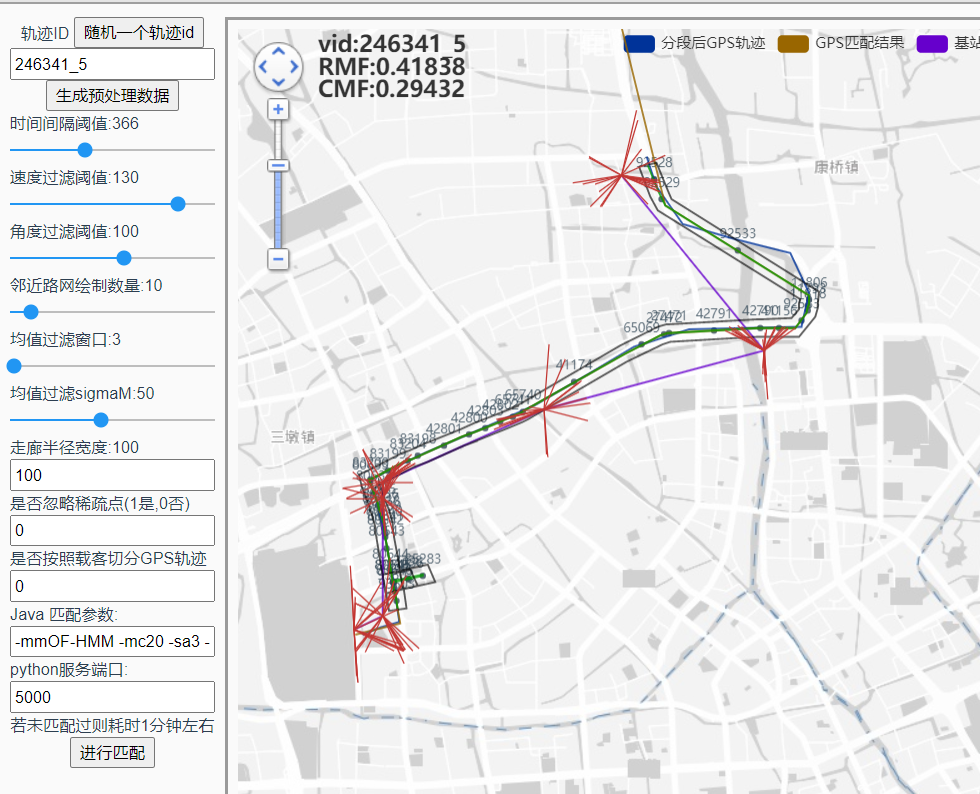
246341_5
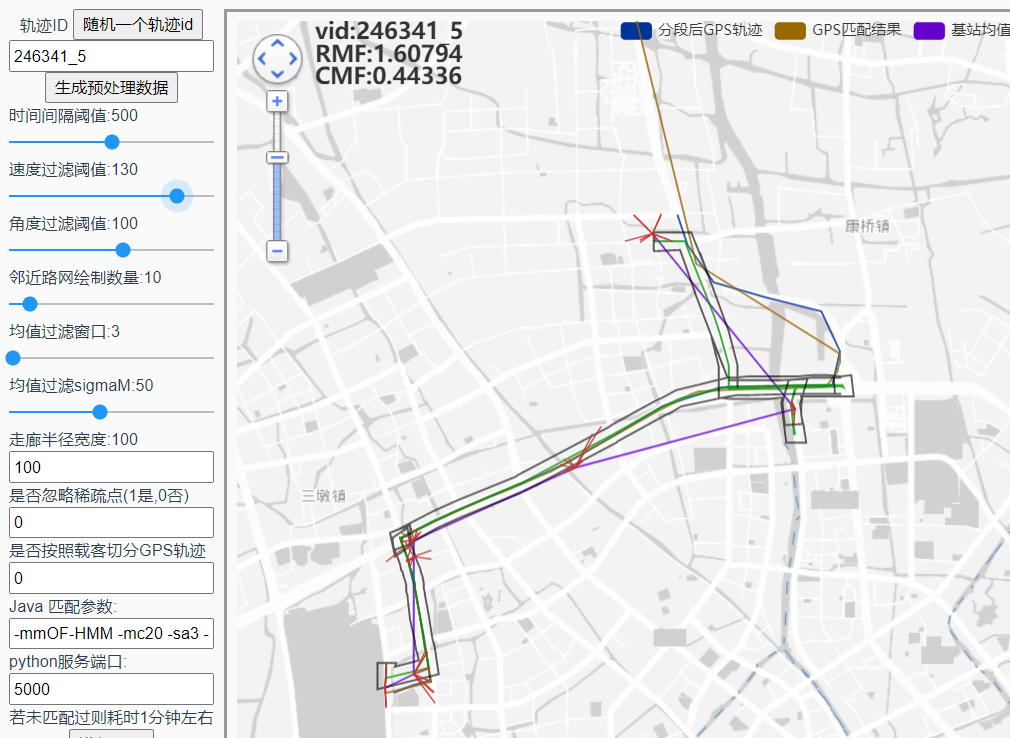
mc10 ms200 结果为 1.608 rmf:
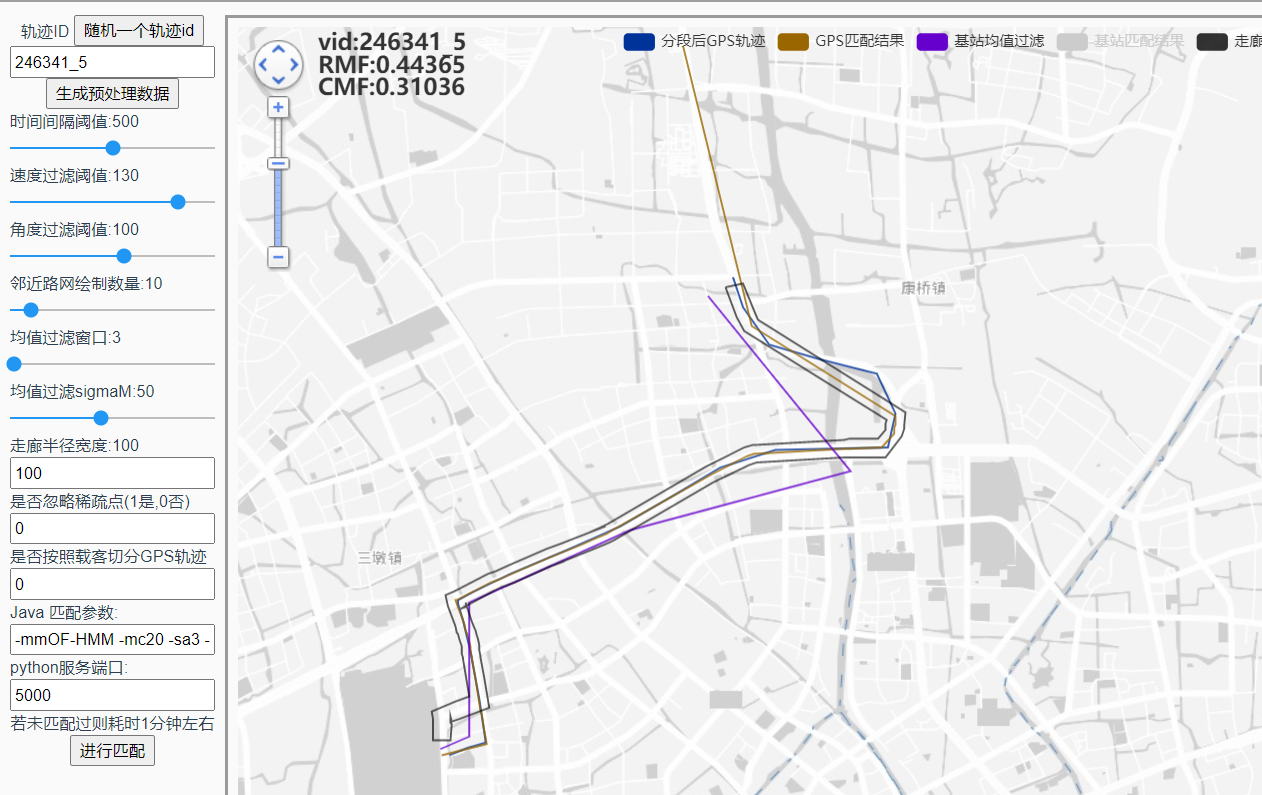
mc65 ms200 结果为 0.44rmf 0.31 cmf:
候选点数量对结果的影响
mc30:
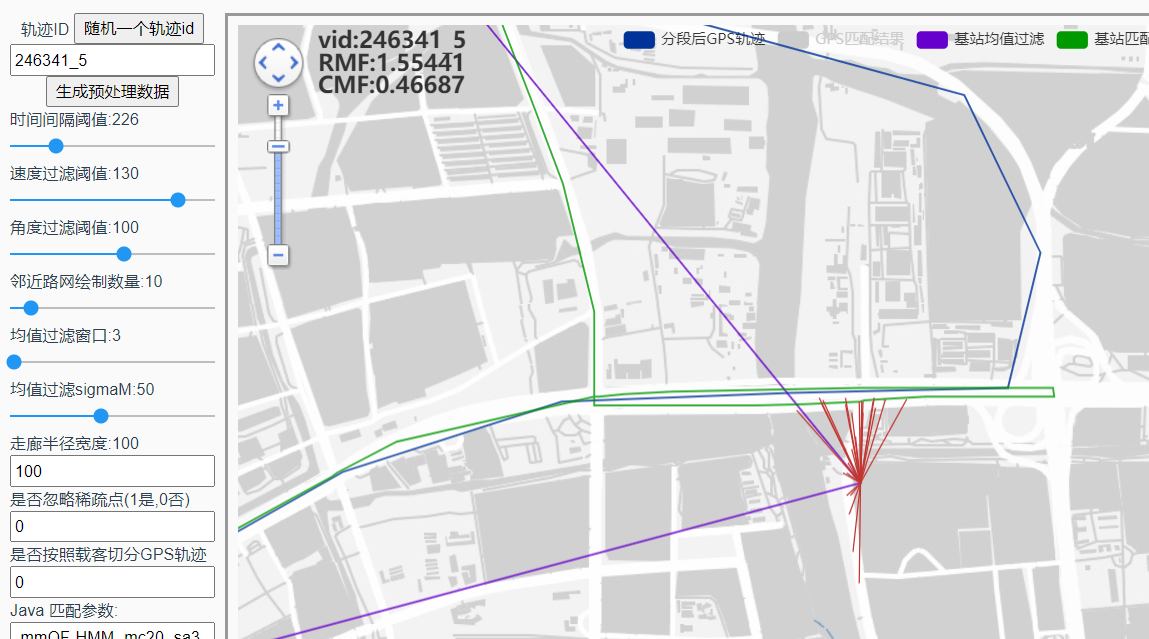
mc50:
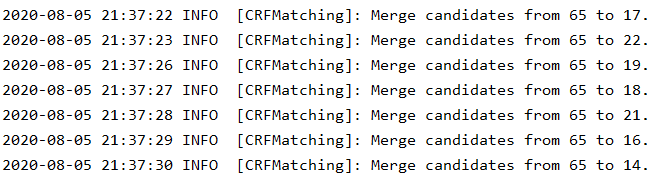
但是其实是不需要这么多候选人的,50个候选人中在同一条路上的应该有不少,想办法合并一下。
合并前mc65:
合并步数2 ,mc65:
合并能显著减少计算量,候选点数量越多,提升越大
思路:
1. 最短路径算法修改
2. 最短路径内部的转向惩罚(检查现在的转向惩罚有没有问题)
3. 合并候选人!(已完成)
6. 根据情况动态调整候选数量(重要)
- MEE点的密度
- 周围基站密度
- 轨迹长度
7. 合适的合并步长
8. 解决GPS匹配中绕路的问题
7. 外部compact 候选合并
8-13
主要问题:
- 重写路网数据读取代码
- 检查现有的数据是否为混合型路网(既不是compact也不是loose)
- 直接读取为loose型路网
- loose型路网转为compact型路网
- 利用compact型路网来做候选人合并
8-14 spark有关hostname的解析很有问题,折腾了很久
8-16 处理压缩完的路网数据,效果貌似不错
接下来动态候选数量:
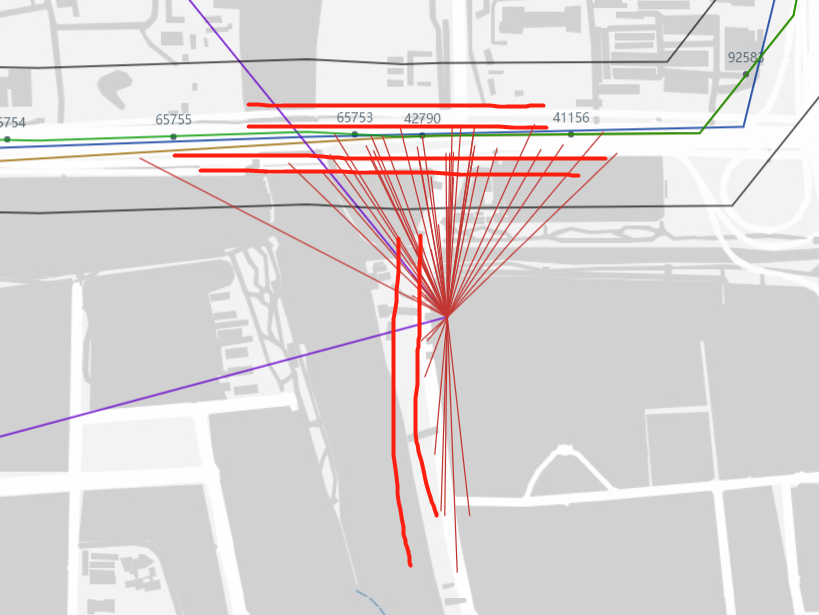
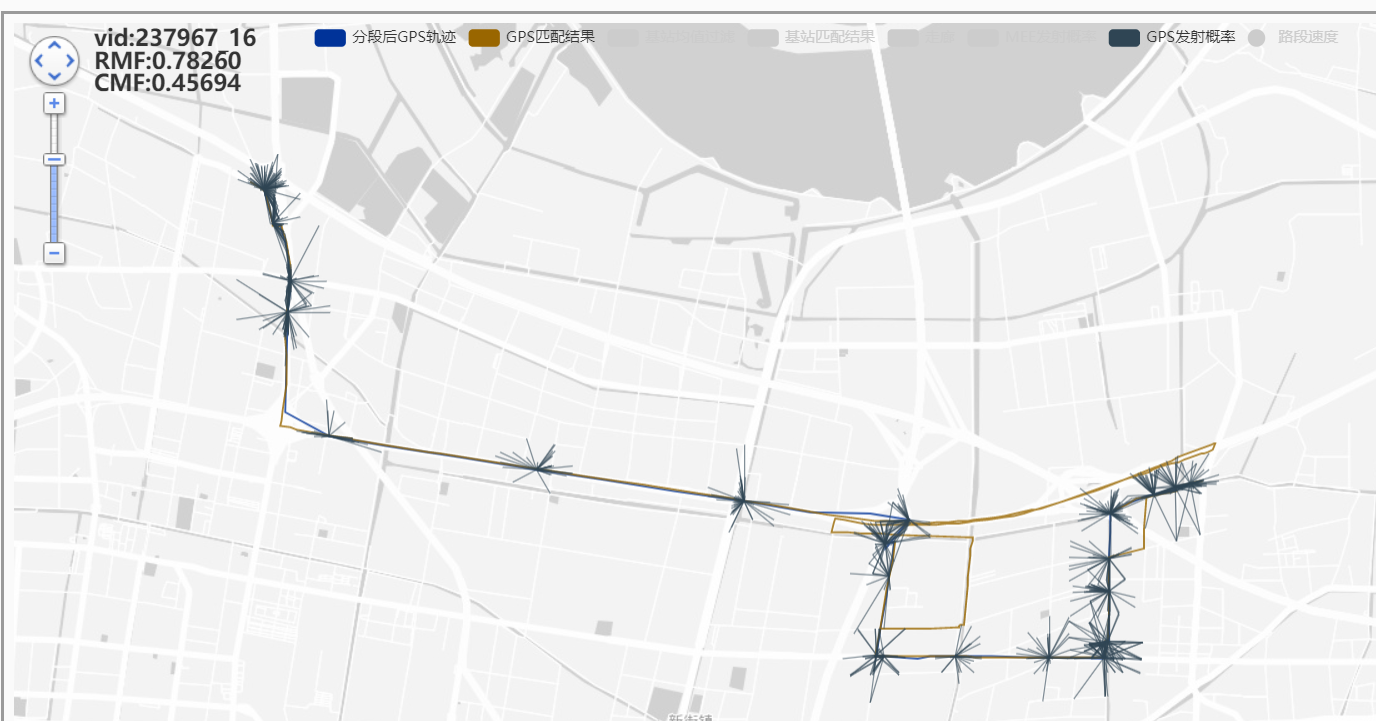
GPS离谱绕路:237967_16
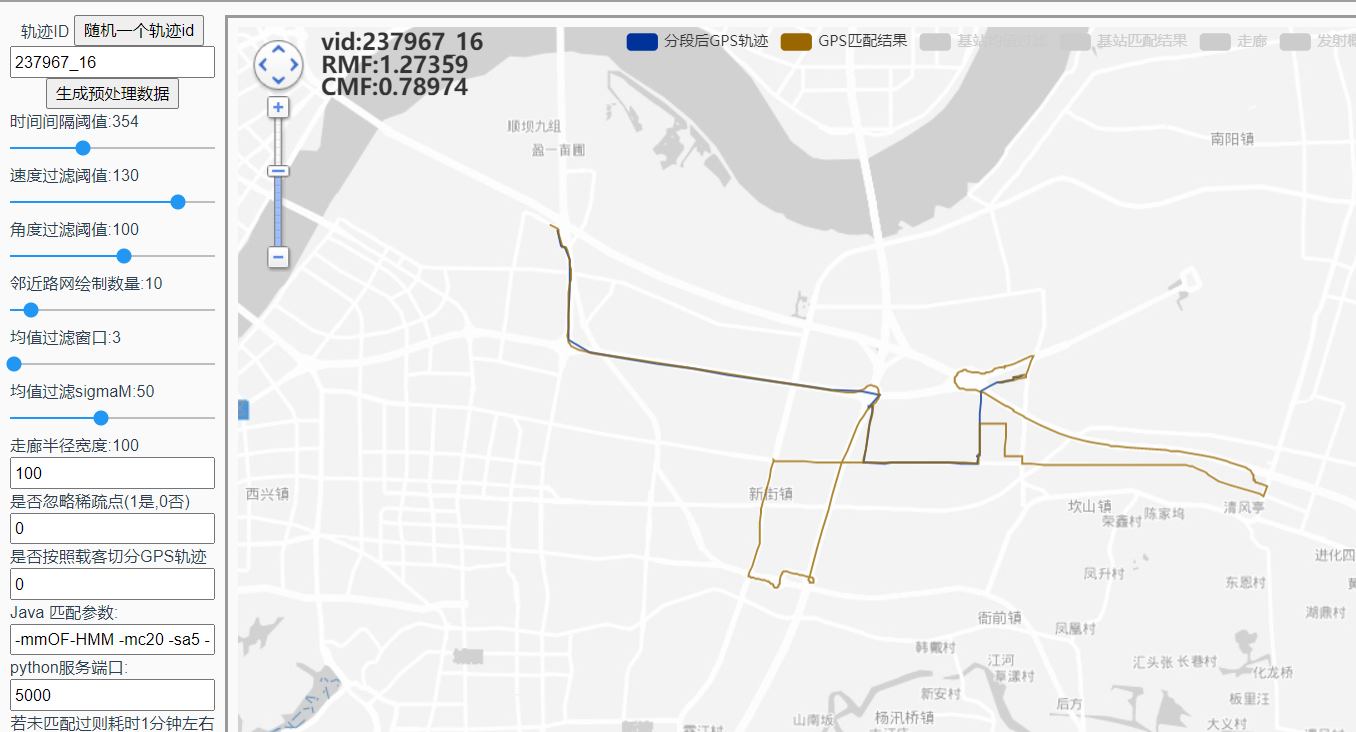
GPS拟合目标设置为0后,还是会绕路,推测可能是指数函数分布在劣质情况下趋向于0导致转移概率都接近于0,因此受发射概率影响较大;
加上softmax
感觉仔细想一下,MEE只要找个最短的路径就行了,大概率就是最优路径
检查 转移概率和发射概率 以及 维特比解码细节;
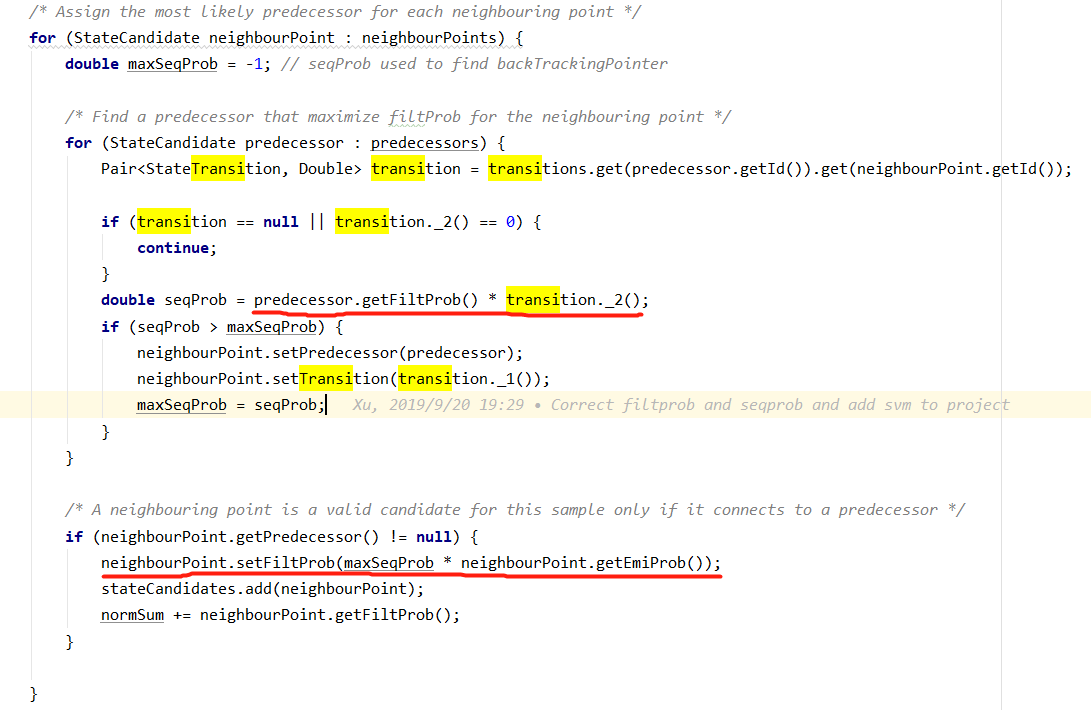
为了避免小数下溢 应该改为使用log和替代乘法
原来的做法是每层进行归一化,这样每层概率之和为1,感觉会有问题,因为有些候选的概率就直接为0了。
结果和手测不一致:
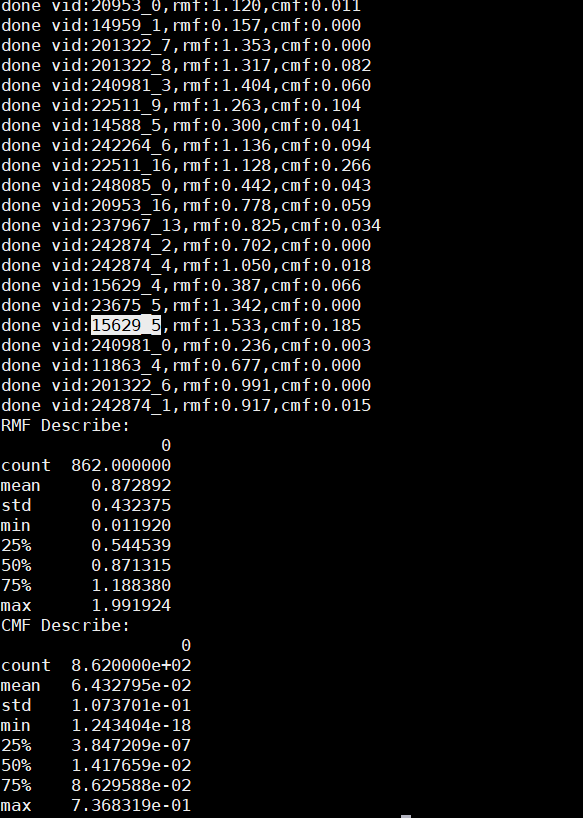
done vid:16828_8,rmf:1.566,cmf:0.135
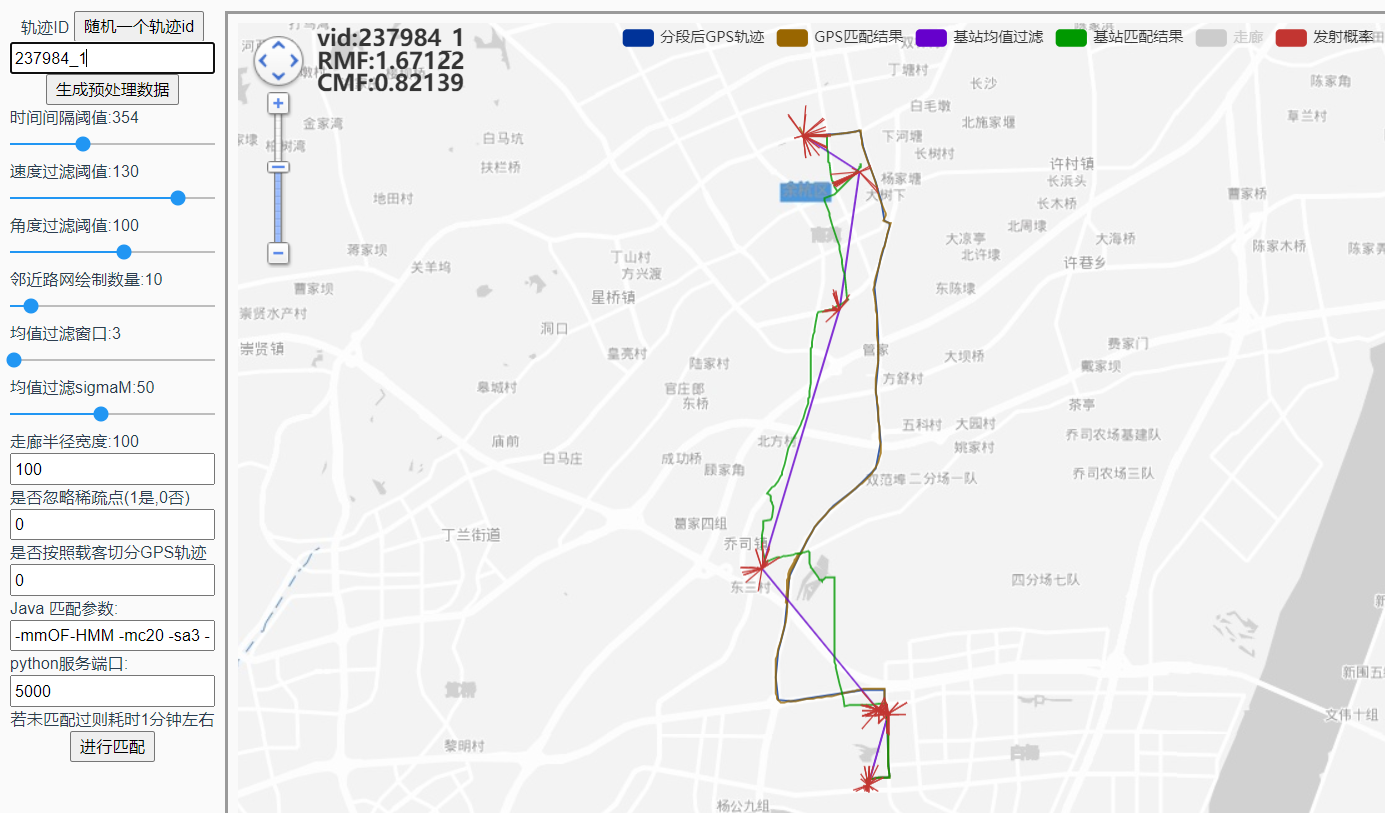
GPS候选合并:
2号观测点的候选对象在1号观测点的前面
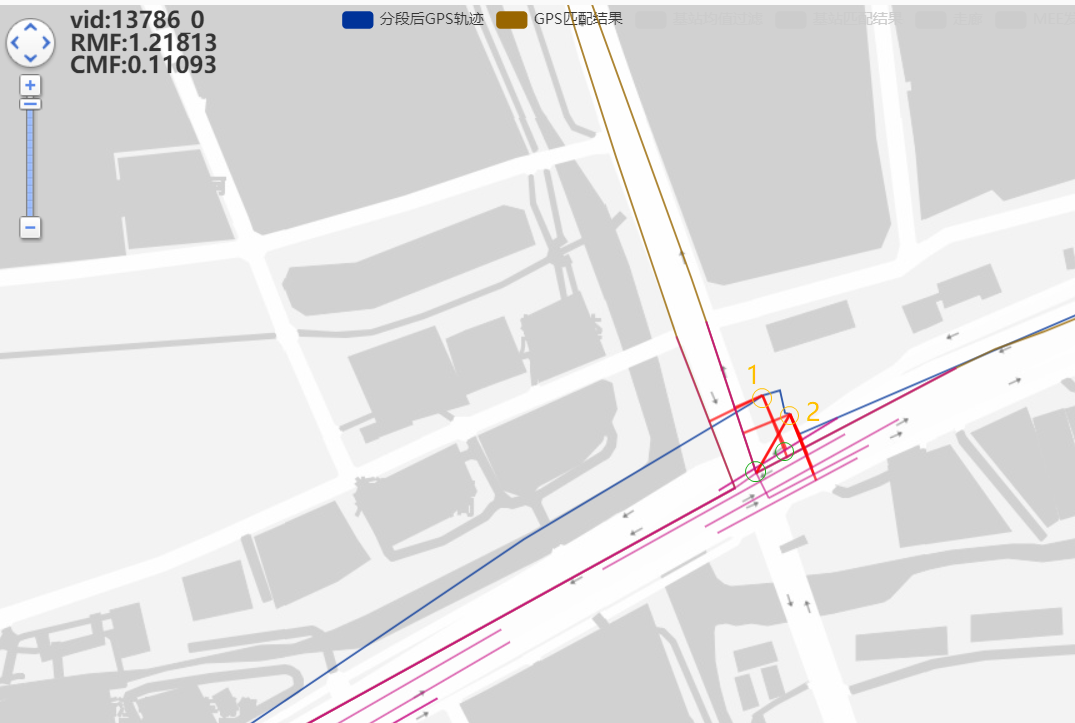
这里的绕路不合理,适合用来分析:
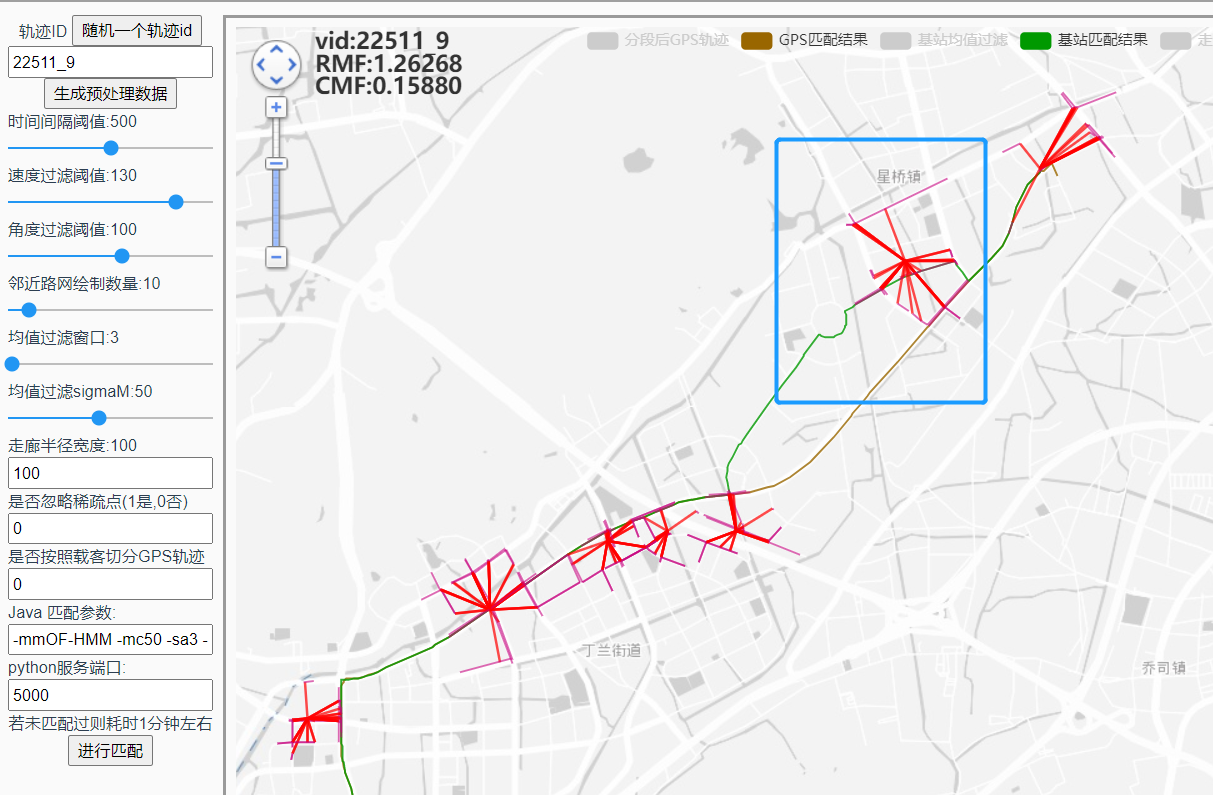
普通:
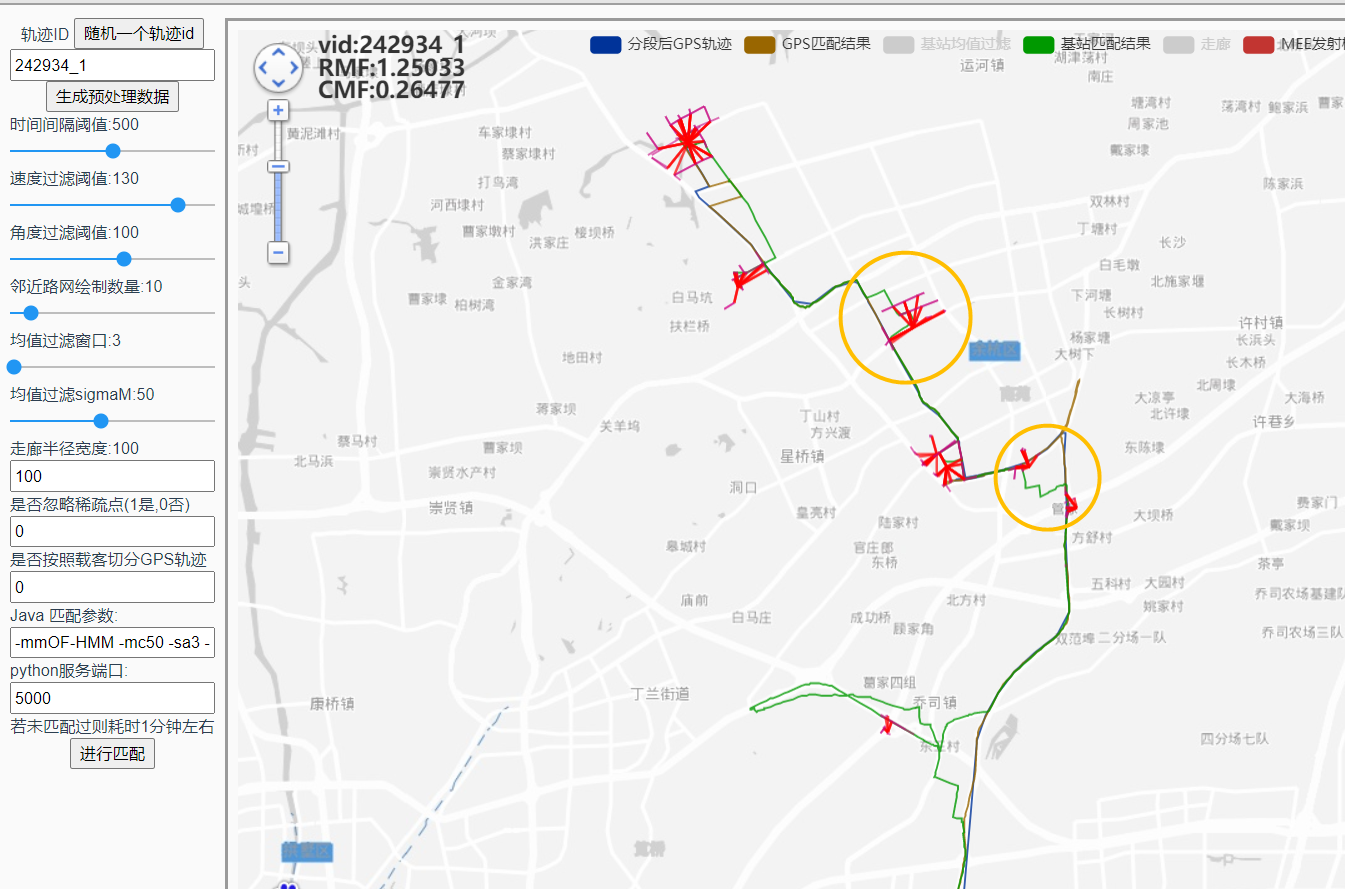
linerTarget = 0:
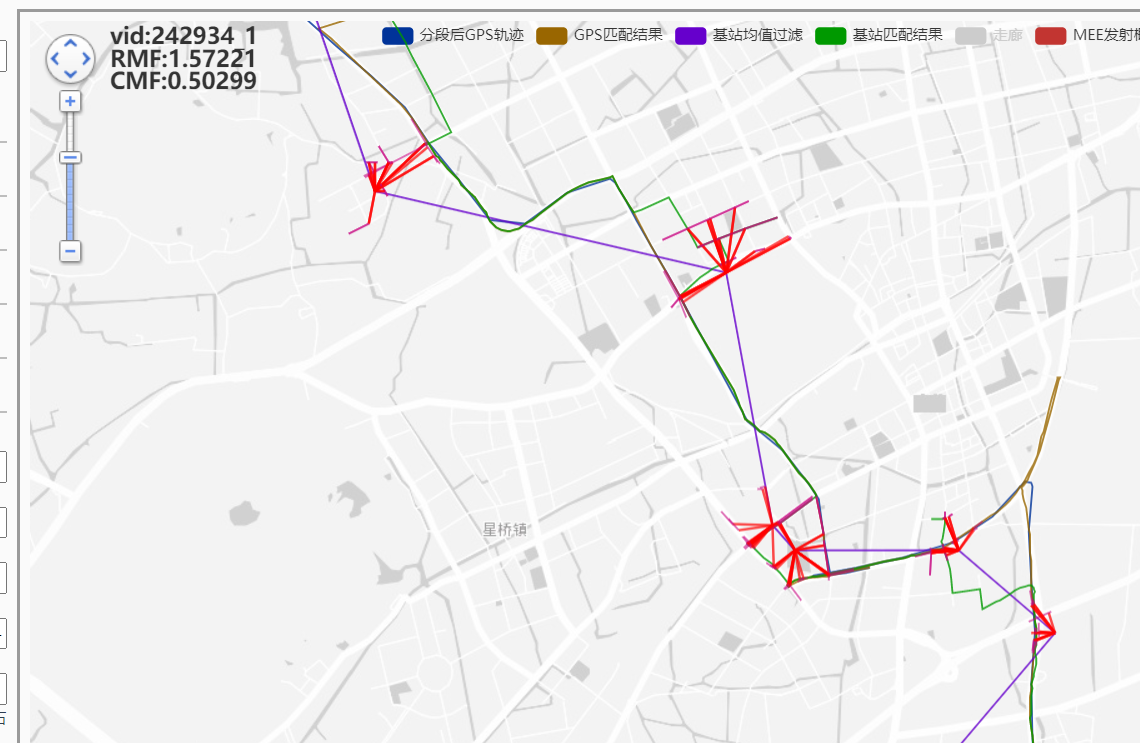
mee_tw1000:还是要绕路
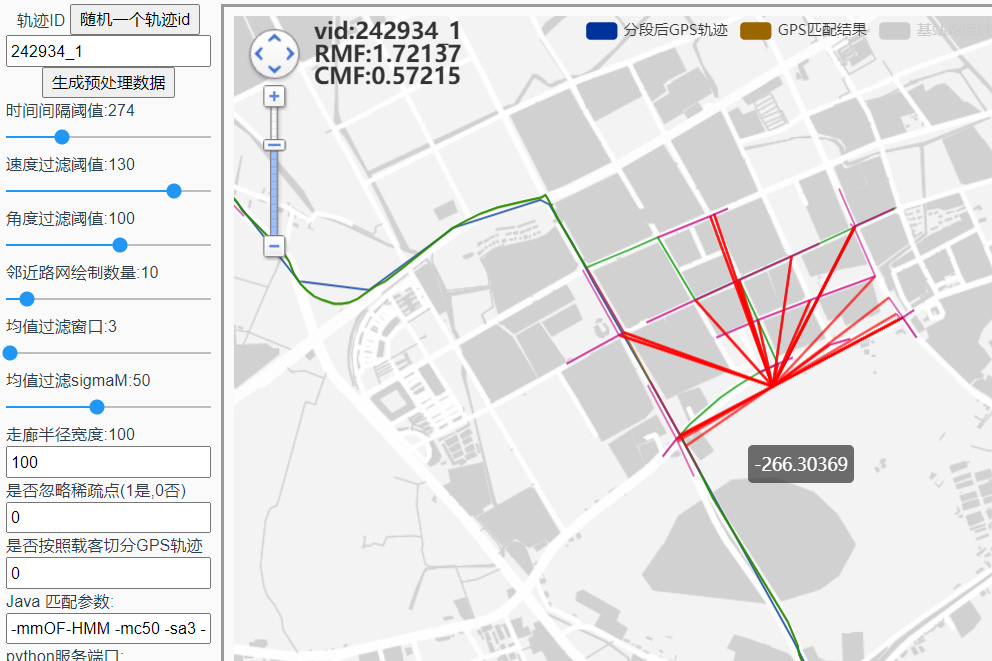 发射概率都为0时,
发射概率都为0时,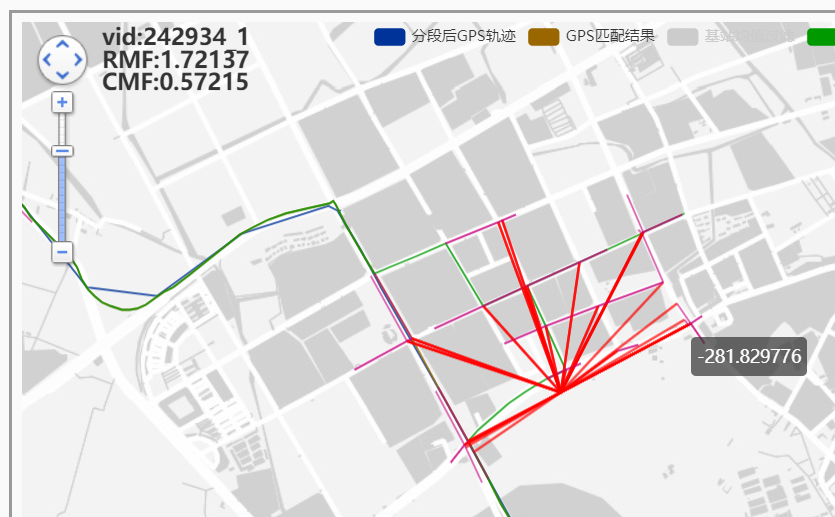 ,为什么不选近的??
,为什么不选近的??
最短寻路就不是正确的最短寻路结果!!!才会这样,修改maxDistance!
调大maxDistance后更大了!
242161_4
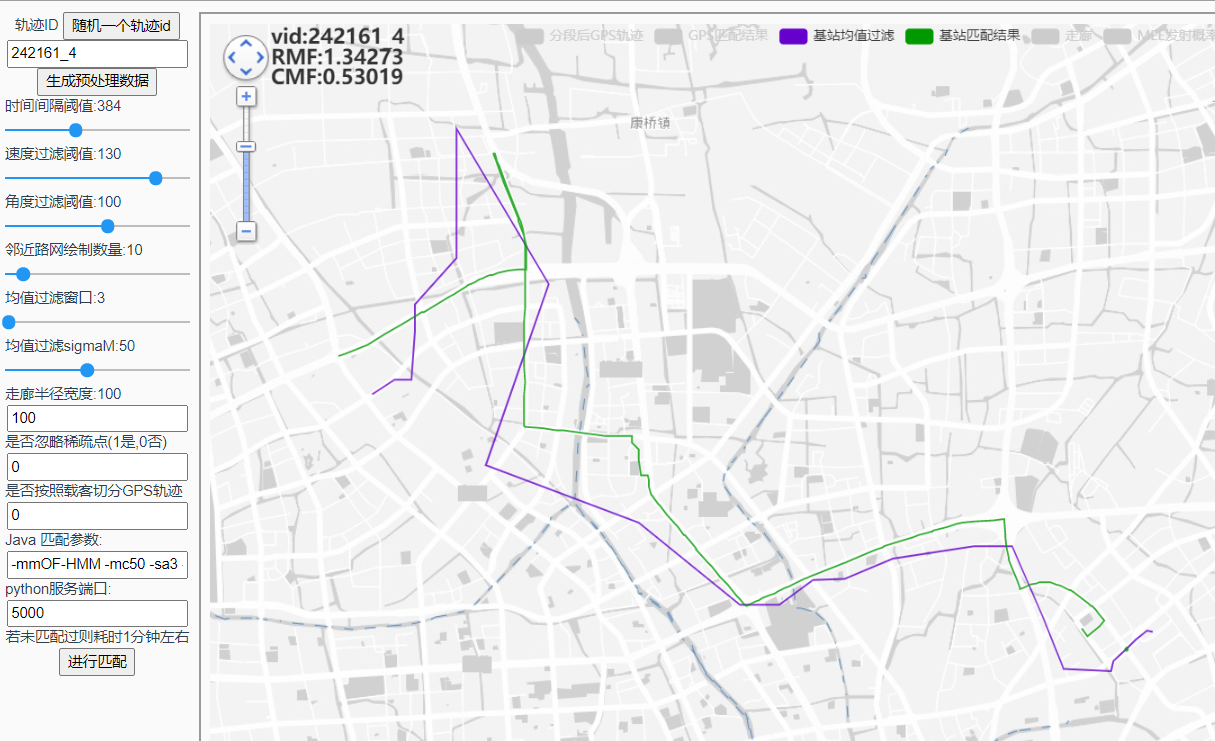
加入发射线性惩罚:

done vid:239708_3,rmf:0.958,cmf:0.315
done vid:16886_5,rmf:0.891,cmf:0.271
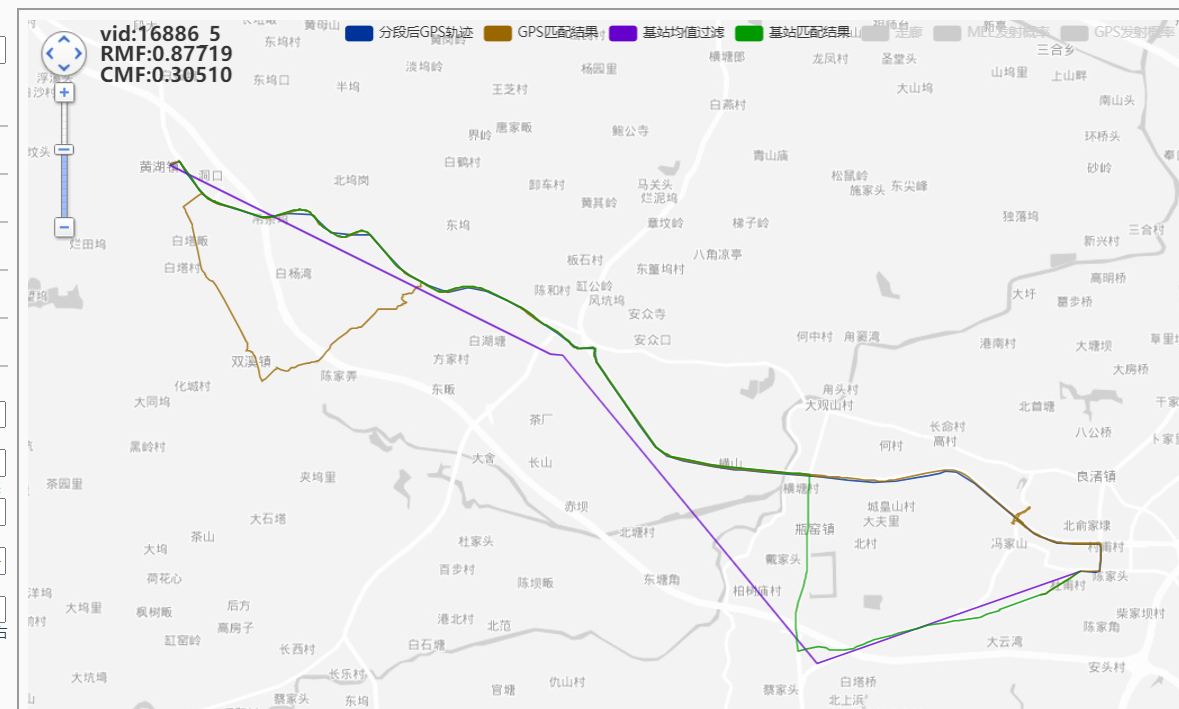
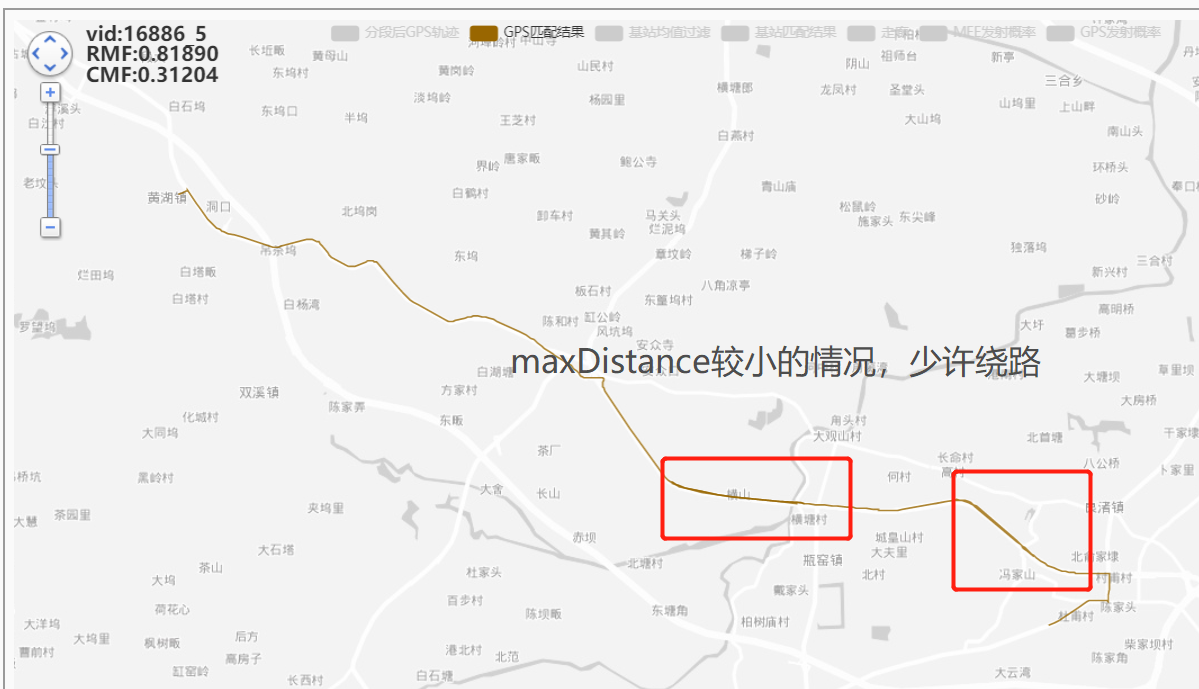
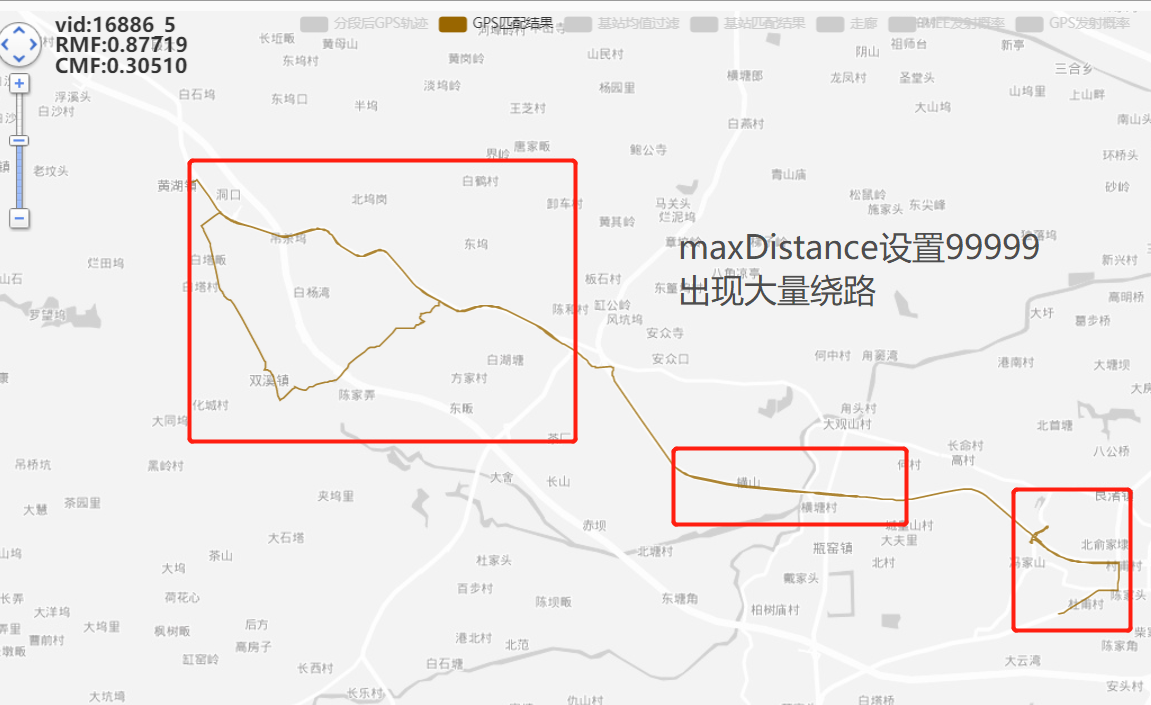
GPS加过滤器(距离时间过滤)
8-20:
最短路径
endPointLoc2EdgeIndex中key为路段端点构造的字符串
endPointLoc2EdgeIndex.put(startNode.lon() + "_" + startNode.lat() + "," + endNode.lon() + "_" + endNode.lat() + "," + way.getID(), edgeIndex);
routingEdges存的啥
每次从优先队列中取距离起点最近的一个
在比较短的轨迹上,或者基站密度很高的城区?
mee_mc:5>15>65
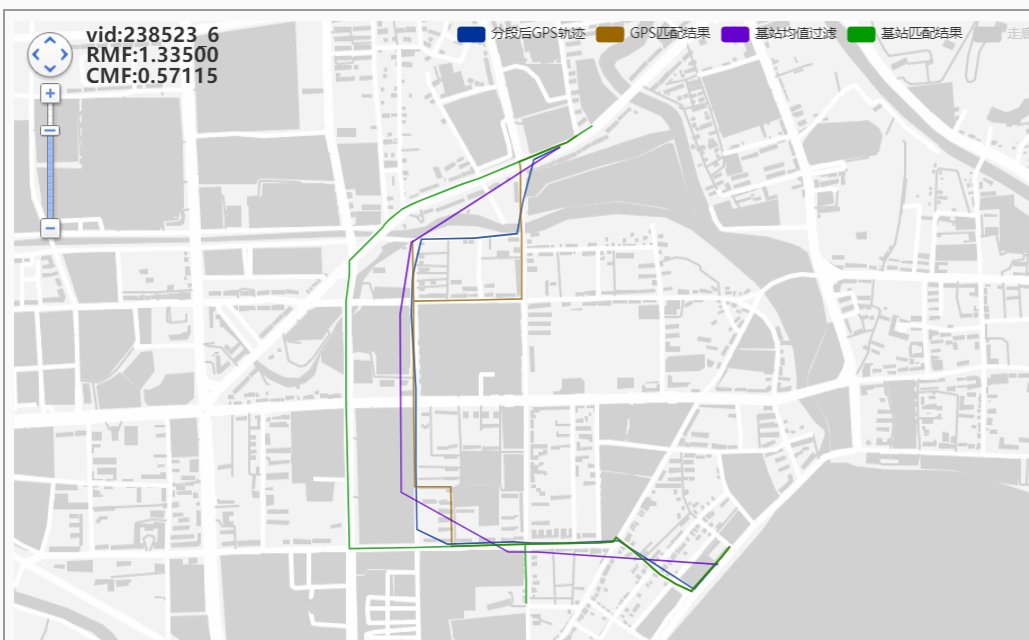
8-23
动态调整候选:
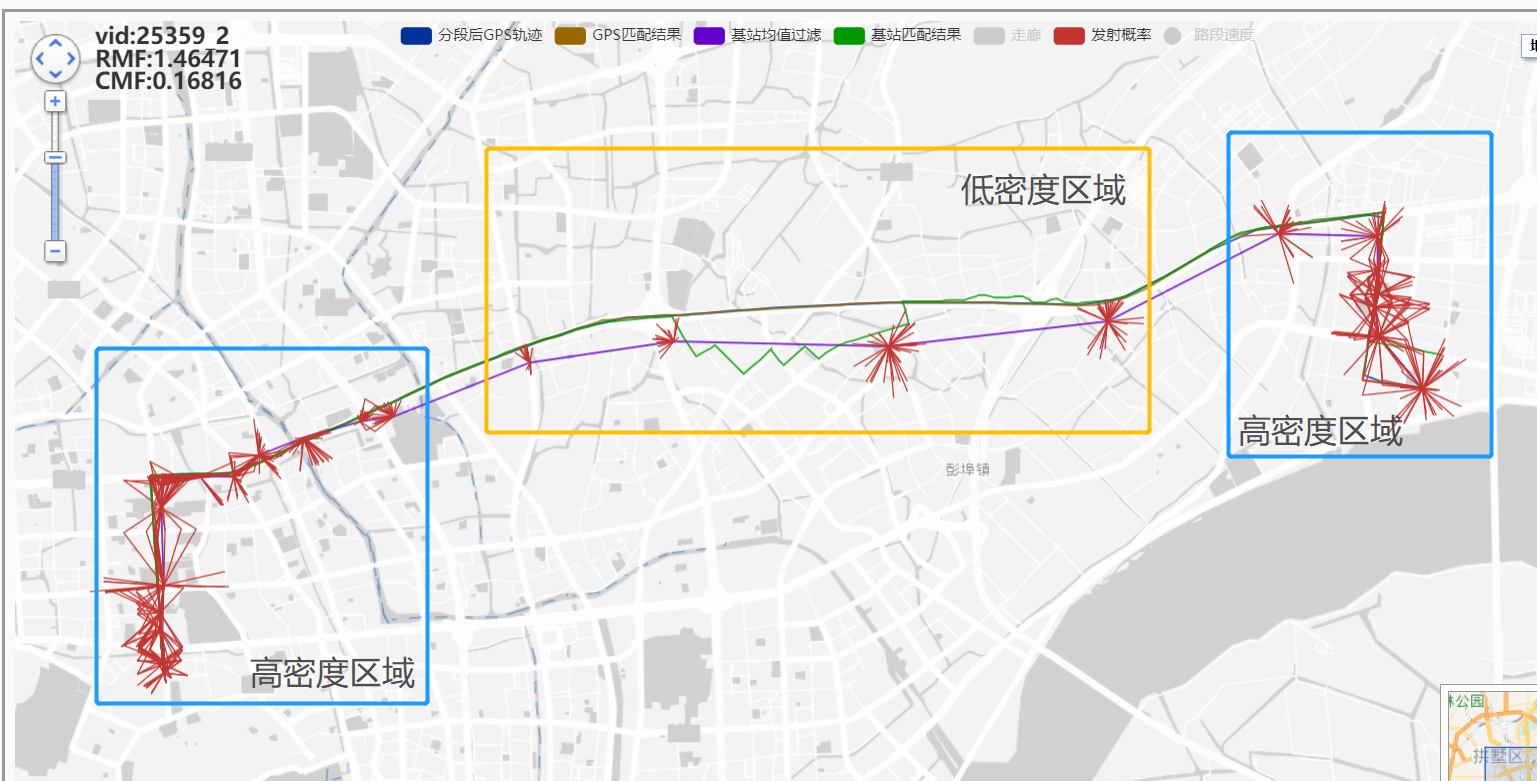
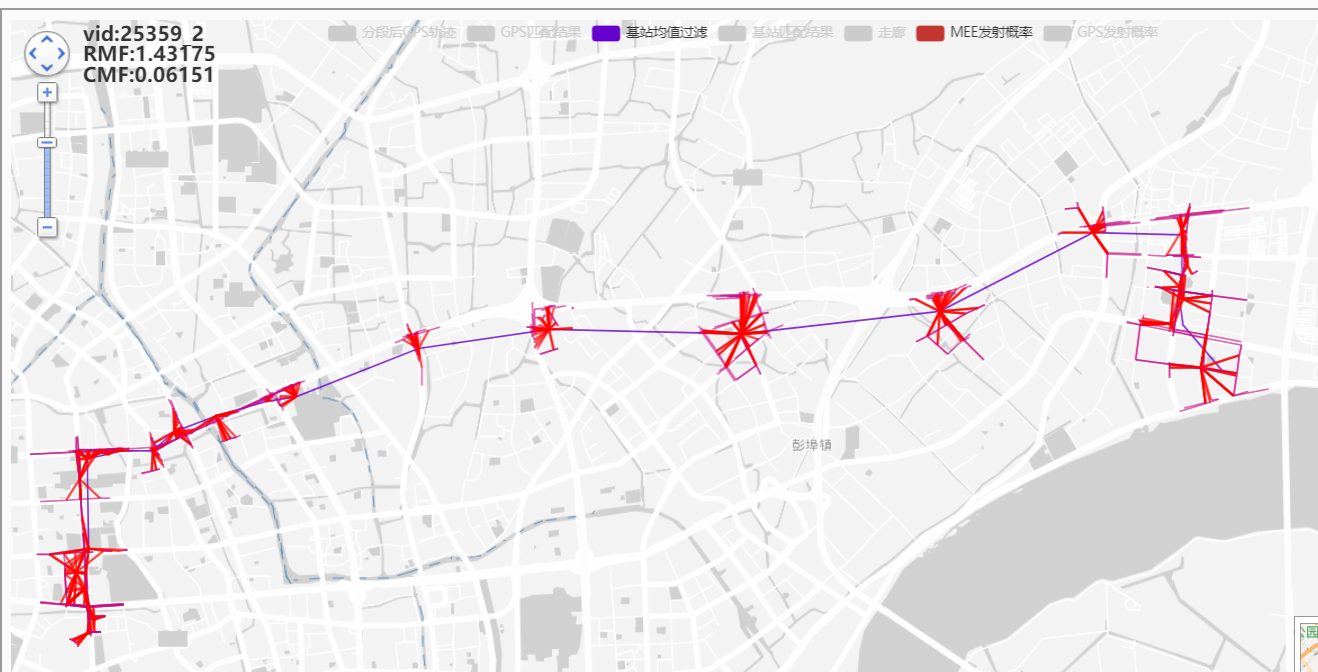
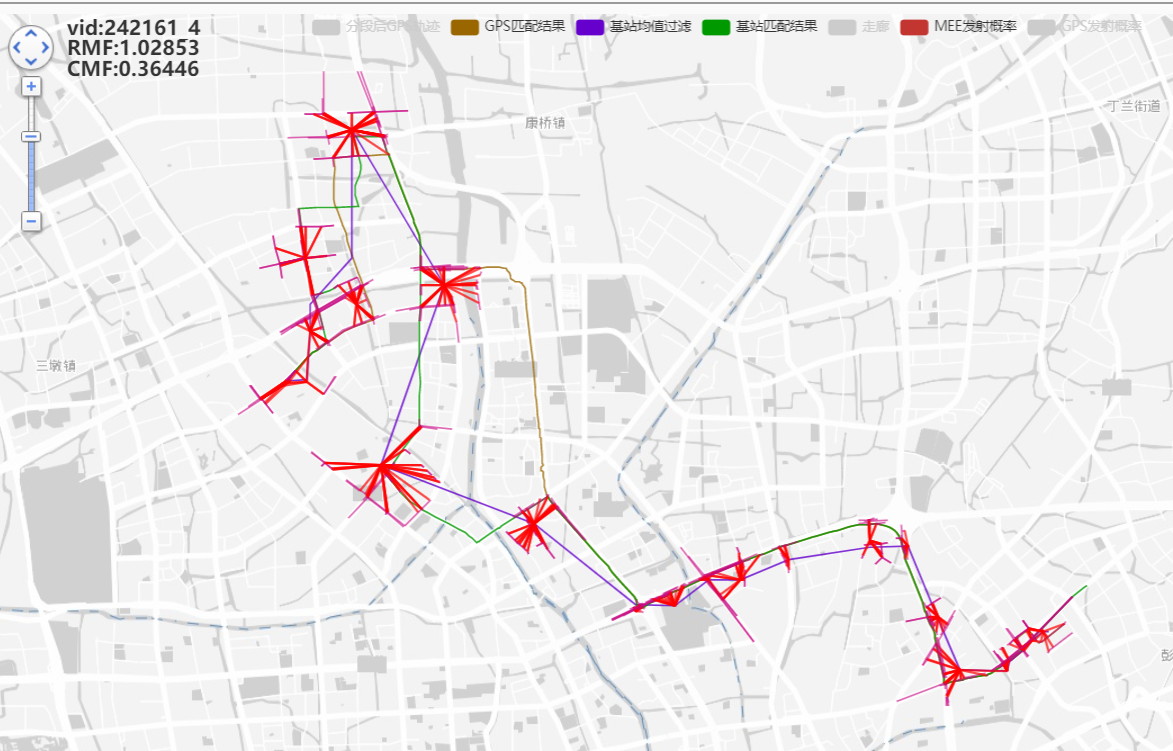 效果不错
效果不错
sparksession在配合rest时有很大困难,好像与sparksession只能全局唯一有关
8-25
发现有的劣质GPS采样间隔很高
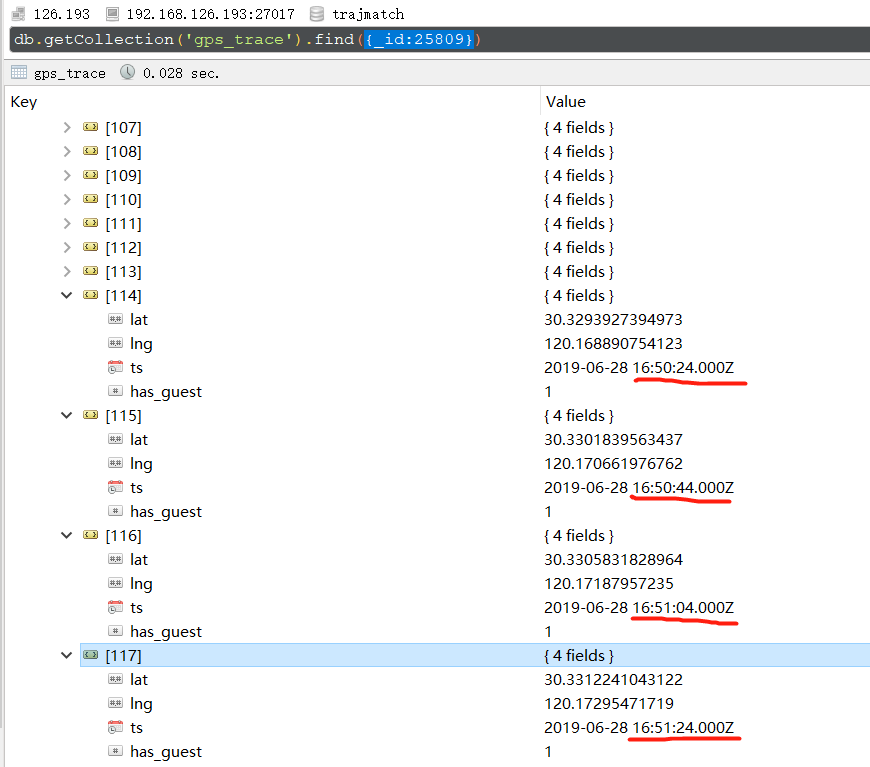
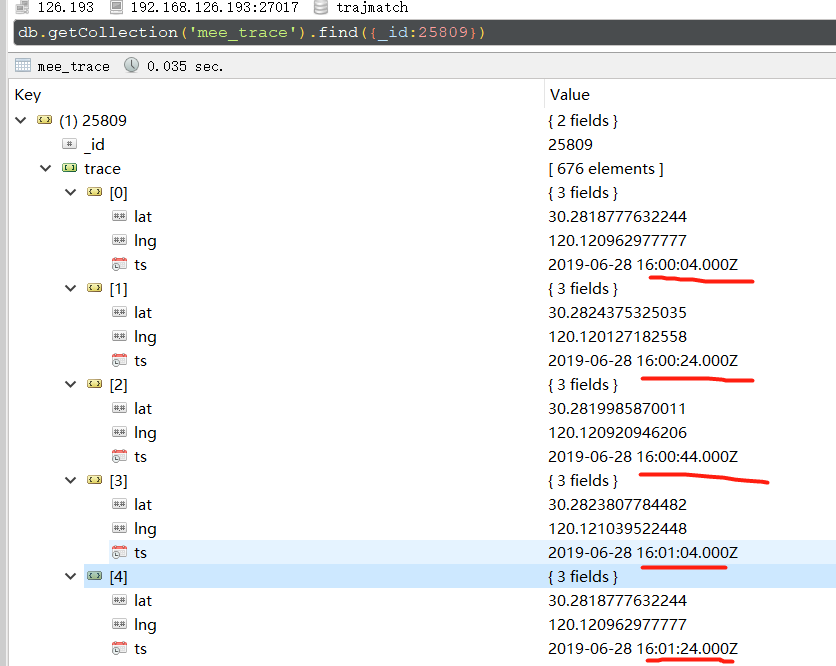
考虑到现有的各种过滤器应该考虑时间间隔,过大间隔的点不应该去除
16768_0
8-31
匹配速度可能是dijk没有加提前终止条件的原因
动态MaxDistance
9-10
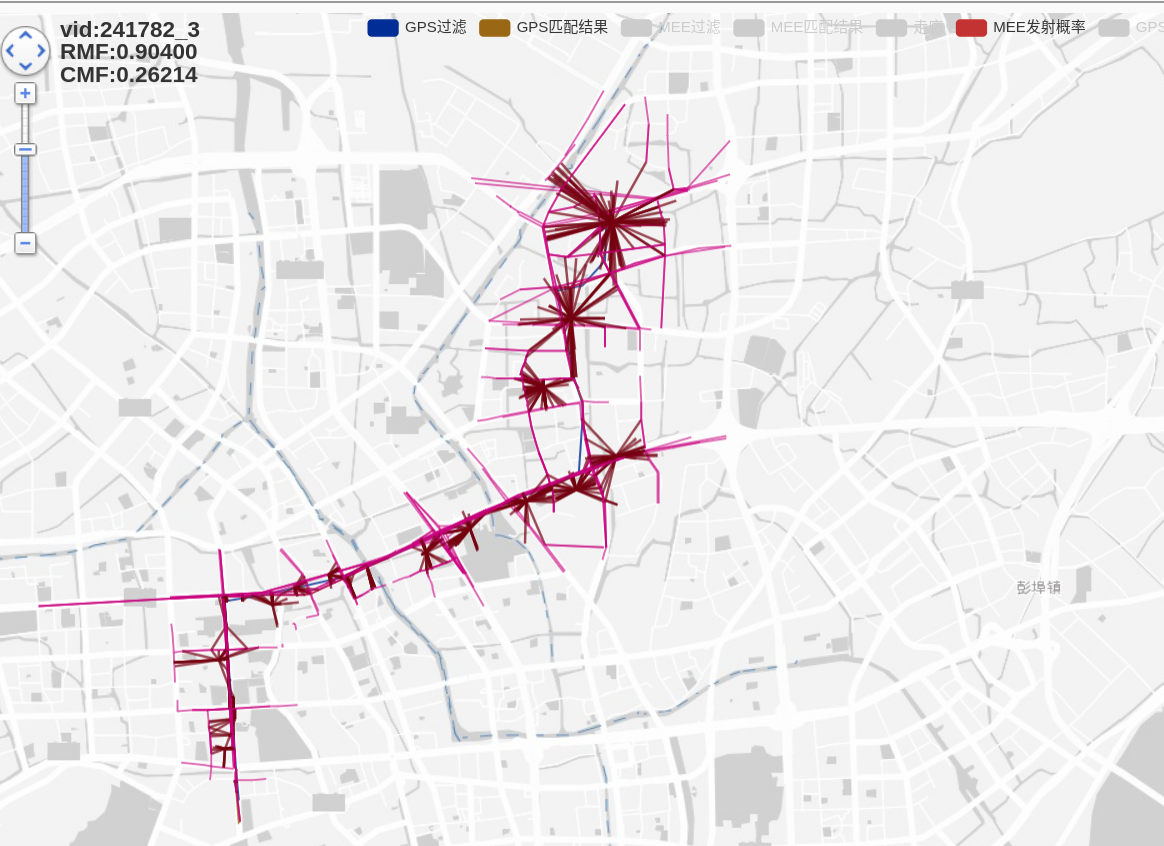
candidateRange = 30
densityCandidatePara = 0.02
resizeStandardLength = 3000
13分钟

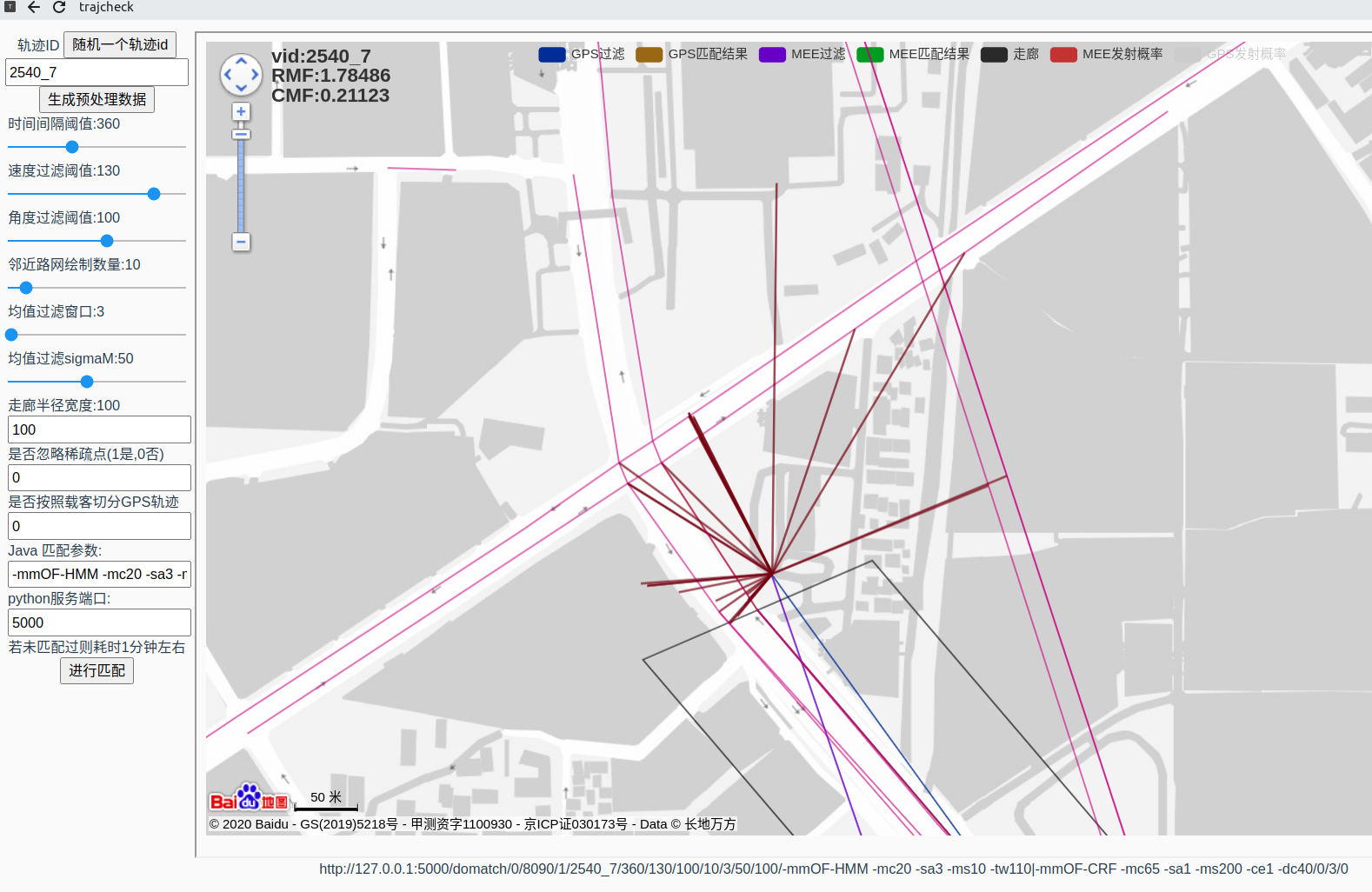
9-14
highest rmf
14976_1
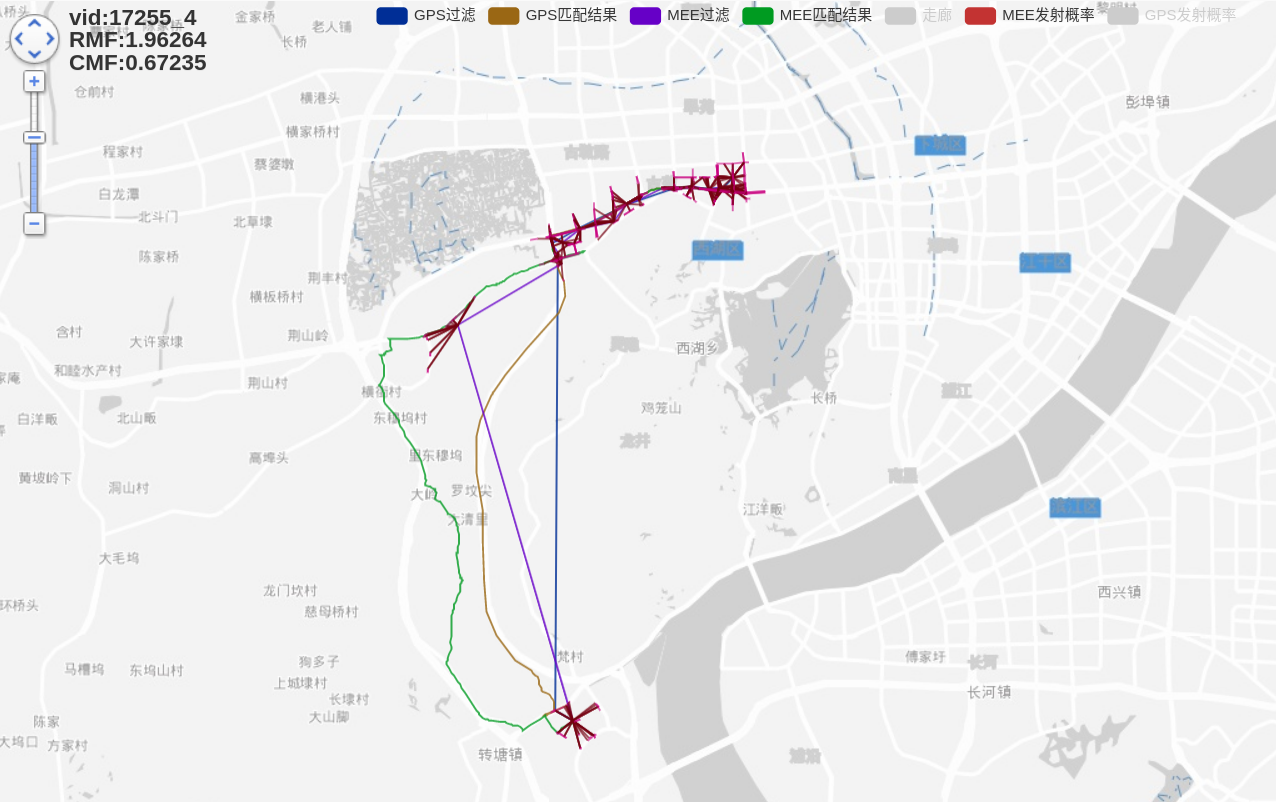
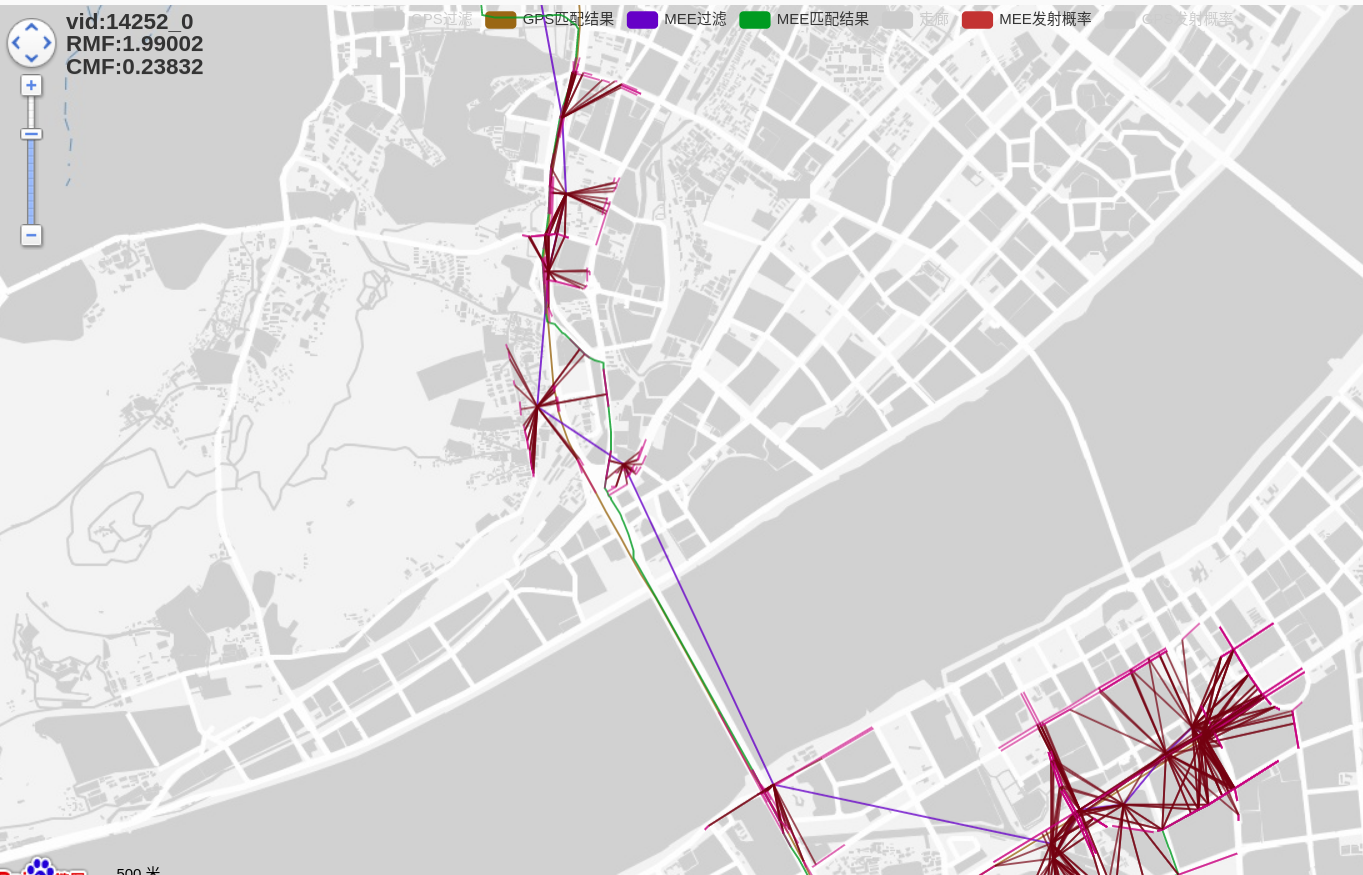
16231_1
113121_0
18400_2
18339_2
15031_2
18310_0
10583_0
走廊node 要从spark拿
