@xtccc
2015-12-09T02:37:42.000000Z
字数 12807
阅读 2765
Documents

ElasticSearch
1. 存储与搜索文档
1.1 存储文档 (indexing)
1.1.1 存储文档的本质
存储数据的过程,称为indexing。To index a document, we must tell ElasticSearch which type in the index it should go to.
WHAT HAPPENS WHEN YOU INDEX A DOCUMENT?
By default, when you index a document, it’s first sent to one of the primary shards, which is chosen based on a hash of the document’s ID. Then, the document is sent to be indexed in all of that primary shard’s replicas.
The Elasticsearch node that receives your indexing request first selects the shard to index the document to. By default, documents are distributed evenly between shards.
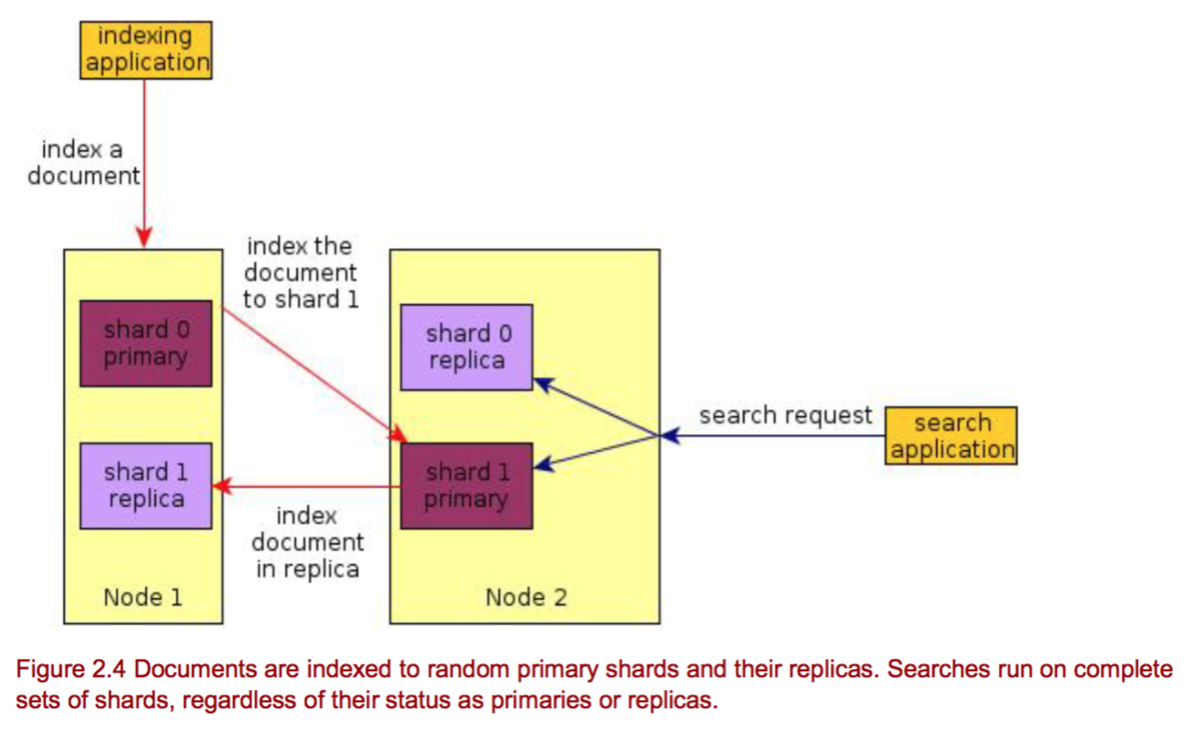
1.1.2 存储文档的例子
下面我们在megacorp这个index中创建一个文档,令其type为employee,ID为1:
[root@ecs1 elasticsearch-1.7.2]# curl -XPUT localhost:9200/megacorp/employee/1?pretty -d '> {> "firstname" : "Tao",> "lastname" : "Xiao",> "age" : 30,> "about" : "Hello, my wife is CCC",> "interests" : ["coding", "jogging"]> }'{"_index" : "megacorp","_type" : "employee","_id" : "1","_version" : 1,"created" : true}
在indexing document的过程中,尚不存在的index、type都会被自动创建。
从上面的PUT Request的返回响应来看,它的返回包含了被indexed的文档的index、type、id、version以及created,其中,version指的是该文档的版本号。每当一个document发生变化时(包括DELETE),它的metadata中的version就会自增1;而created为false,则表明这个文档是第一次被创建。
1.2 查询文档
WHAT HAPPENS WHEN YOU SEARCH AN INDEX?
When you search an index, Elasticsearch has to look in a complete set of shards for that index . Those shards can be either primary or replicas because primary and replica shards typically contain the same documents. Elasticsearch distributes the search load between the primary and replica shards of the index you’re searching, making replicas useful for both search performance and fault tolerance.
Elasticsearch uses a round-robin format to forward the request to the cluster’s nodes and shards. As shown in figure 2.9, Elasticsearch then gathers results from those shards, aggregates them into a single reply, and forwards the reply back to the client application.
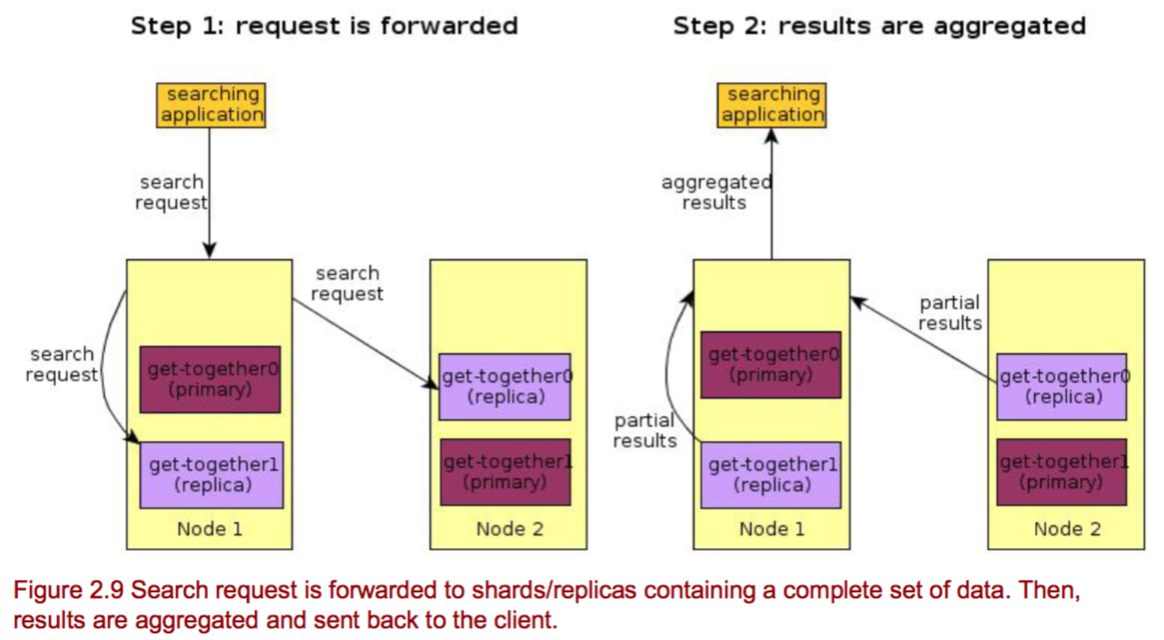
1.2.0 multi-index, multi-type
在全部的文档中查询
curl localhost:9200/_search
在gb这个index中查询
curl localhost:9200/gb/_search
在以g开头和以u开头这两个index中查询
curl localhost:9200/g*,u*/_search
在gb和us这两个index中查询
curl localhost:9200/gb,us/_search
在全局范围的user和twitter这两个index中查询
curl localhost:9200/_all/user,twitter/_search
1.2.1 查询文档的全部内容及metadata
[root@ecs1 elasticsearch-1.7.2]# curl -i localhost:9200/megacorp/employee/1?prettyHTTP/1.1 200 OKContent-Type: application/json; charset=UTF-8Content-Length: 283{"_index" : "megacorp","_type" : "employee","_id" : "1","_version" : 1,"found" : true,"_source":{"firstname" : "Tao","lastname" : "Xiao","age" : 30,"about" : "Hello, my wife is CCC","interests" : ["coding", "jogging"]}}
可以看到,response返回了该文档的metadata,并通过_source域返回了 full JSON document。
1.2.2 只查询文档全文,不返回metadata
如果希望只返回文档,而不返回关于该文档的metadata,则可以如下查询:
curl localhost:9200/megacorp/employee/1/_source?pretty
1.2.3 只查询文档的部分fields
curl localhost:9200/megacorp/employee/1?_source=firstname,interests
1.2.4 批量获取多个文档
[root@ecs1 tmp]# curl localhost:9200/_mget?pretty -d '> {> "docs" : [> {> "_index" : "megacorp",> "_type" : "employee",> "_id" : 2> },> {> "_index" : "megacorp",> "_type" : "employee",> "_id" : 3> }> ]> } '{"docs" : [ {"_index" : "megacorp","_type" : "employee","_id" : "2","_version" : 1,"found" : true,"_source": {"firstname" : "Jack","lastname" : "Chen","age" : 40,"about" : "Hello, I am Jack","interests" : ["sports", "music"]}}, {"_index" : "megacorp","_type" : "employee","_id" : "3","_version" : 1,"found" : true,"_source": {"firstname" : "Lucy","lastname" : "Liu","age" : 50,"about" : "Hello, I am Lucy","interests" : ["tv", "talking"]}} ]}
如果要获取的多个文档在同一个index和type中,则可以如下构造请求:
[root@ecs1 tmp]# curl localhost:9200/megacorp/employee/_mget -d '> {> "docs" : [> { "_id" : 2 },> { "_id" : 3 }> ]> }'
1.2.5 分页查询
在默认情况下,一次查询会返回符合条件的前10个文档,并且这10个文档是按照_score排序的。我们可以通过参数size来控制一次返回多少个文档,同时通过参数from控制返回文档时跳过前面多少个文档。
1.3 更新文档
1.3.1 文档只能整体替换,不能局部更新
ES中的文档是不可变的(immutable),因此如果要更新一个文档,只能replace it。例如,这里我们更新坐标为megacorp/employee/1的文档:
[root@ecs1 ~]# curl -XPUT localhost:9200/megacorp/employee/1?pretty -d '> {> "age" : 31,> "about" : "I amm updated"> }'{"_index" : "megacorp","_type" : "employee","_id" : "1","_version" : 2,"created" : false}
可见:
- 不能对原来的文档进行修改,只能整体替换并重新index
- 更新后,该文档的
_version增1,且created由 true变为了false
1.3.2 如果真的希望实现局部更新文档的效果
通过_update可以实现,但是本质上依然遵循了retrieve -> change -> reindex的路线。
通过 partial update,可以增加新的fields,也可以修改已有的fields,如下:
[root@ecs1 ~]# curl localhost:9200/megacorp/employee/8?pretty{"_index" : "megacorp","_type" : "employee","_id" : "8","_version" : 20,"found" : true,"_source": {"name" : "Tao","city" : "NJ"}}[root@ecs1 ~]# curl localhost:9200/megacorp/employee/8/_update?pretty -d '> {> "doc" : {> "tags" : ["A", "B"],> "gender" : "male",> "city" : "Taixing"> }> }'{"_index" : "megacorp","_type" : "employee","_id" : "8","_version" : 21}[root@ecs1 ~]# curl localhost:9200/megacorp/employee/8?pretty{"_index" : "megacorp","_type" : "employee","_id" : "8","_version" : 21,"found" : true,"_source":{"name":"Tao","city":"Taixing","tags":["A","B"],"gender":"male"}}
1.4 防止覆盖已有文档
如果在index document时,希望做到:只有当该文档尚未存在(即同样的 index/type/id)时,才能index新的文档;如果已存在,就不能将旧的文档覆盖。
方法1:增加_create
[root@ecs1 ~]# curl -i -XPUT localhost:9200/megacorp/employee/1/_create -d '> {> "age" : 31,> "about" : "I amm updated"> }'HTTP/1.1 409 ConflictContent-Type: application/json; charset=UTF-8Content-Length: 109{"error":"DocumentAlreadyExistsException[[megacorp][4] [employee][5]: document already exists]","status":409}
方法2:增加op_type=create
[root@ecs1 ~]# curl -i -XPUT localhost:9200/megacorp/employee/1?op_type=create -d '> {> "age" : 31,> "about" : "I amm updated"> }'HTTP/1.1 409 ConflictContent-Type: application/json; charset=UTF-8Content-Length: 109{"error":"DocumentAlreadyExistsException[[megacorp][6] [employee][7]: document already exists]","status":409}
1.5 删除文档
用动词DELETE来删除一个指定的文档
[root@ecs1 elasticsearch-1.7.2]# curl -i -XDELETE localhost:9200/megacorp/employee/1?prettyHTTP/1.1 200 OKContent-Type: application/json; charset=UTF-8Content-Length: 103{"found" : true,"_index" : "megacorp","_type" : "employee","_id" : "1","_version" : 2}[root@ecs1 elasticsearch-1.7.2]# curl -i -XHEAD localhost:9200/megacorp/employee/1?prettyHTTP/1.1 404 Not FoundContent-Type: text/plain; charset=UTF-8Content-Length: 0
注意这里:删除后该文档的_version加1了,即使要删除的文档不存在,_version还是会加1。
1.6 测试文档是否存在
用动词HEAD来检测指定的文档是否存在
[root@ecs1 elasticsearch-1.7.2]# curl -i -XHEAD localhost:9200/megacorp/employee/1?prettyHTTP/1.1 200 OKContent-Type: text/plain; charset=UTF-8Content-Length: 0
HEAD Request不返回body,只返回HTTP header
1.7 随机生成文档ID
上面,我们指定了ID,也可以不指定ID,而是让ES随机生成一个ID,如下:
[root@ecs1 elasticsearch-1.7.2]# curl -XPOST localhost:9200/megacorp/employee?pretty -d '> {> "firstname" : "Tao",> "lastname" : "Xiao",> "age" : 30,> "about" : "Hello, my wife is CCC",> "interests" : ["coding", "jogging"]> }'{"_index" : "megacorp","_type" : "employee","_id" : "AVCE4xivMv8zm4P4wh-e","_version" : 1,"created" : true}
注意,此时的 -XPUT 要换成 -XPOST。ES生成的随机ID是一个: 22-character long, URL-safe, Base64-encoded string universally unique identifier, or UUID。
1.8 解决读写不一致的冲突
In the database world, two approaches are commonly used to ensure that changes are not lost when making concurrent updates:
Pessimistic concurrency control
Widely used by relational databases, this approach assumes that conflicting changes are likely to happen and so blocks access to a resource in order to prevent conflicts. A typical example is locking a row before reading its data, ensuring that only the thread that placed the lock is able to make changes to the data in that row.
Optimistic concurrency control
Used by Elasticsearch, this approach assumes that conflicts are unlikely to happen and doesn’t block operations from being attempted. However, if the underlying data has been modified between reading and writing, the update will fail. It is then up to the application to decide how it should resolve the conflict. For instance, it could reattempt the update, using the fresh data, or it could report the situation to the user.
参考 Optimistic Concurrency Control
1.9 通过version参数实现乐观锁
1.9.1 Internal Version Number
UPDATE和DELETE类的API都可以通过version参数来实现乐观锁。假设我们新增了一个文档:
[root@ecs1 ~]# curl -XPUT localhost:9200/megacorp/employee/7?pretty -d '> {> "name" : "Tao",> "city" : "NJ"> }'{"_index" : "megacorp","_type" : "employee","_id" : "7","_version" : 1,"created" : true}
可见这个文档的version为1。
下面我们去更新这个文档,为了防止在更新该文档时,它已经被另外一个用户更新了,我们在更新时指定文档的version为1,如下:
[root@ecs1 ~]# curl -XPUT localhost:9200/megacorp/employee/7?version=1 -d '> {> "name" : "Tao",> "city" : "SH"> }'{"_index":"megacorp","_type":"employee","_id":"7","_version":2,"created":false}
更新成功!且文档的version现在变为了2。
如果现在我们仍然指定version=1去更新该文档,则会失败:
[root@ecs1 ~]# curl -XPUT localhost:9200/megacorp/employee/7?version=1 -d '> {> "name" : "Tao",> "city" : "BJ"> }'{"error":"VersionConflictEngineException[[megacorp][3] [employee][7]: version conflict, current [2], provided [1]]","status":409}
1.9.2 External Version
有时候,我们会将外部存储系统(例如MySQL)的数据导入到ES中,那我们就可以将这些数据的一些属性(例如时间戳)作为ES中文档的Version Number。此时,我们可以通过参数version_type=external来声明,如下:
[root@ecs1 ~]# curl -XPUT "localhost:9200/megacorp/employee/8?version=10&version_type=external" -d '> {> "name" : "Tao",> "city" : "BJ"> }'{"_index":"megacorp","_type":"employee","_id":"8","_version":10,"created":true}
对于external version number,在更新同一个文档时,指定的version number必须大于该文档原来的version number(不必严格等于),且在范围(0, 9.2e+18)内。下面验证:
[root@ecs1 ~]# curl -XPUT "localhost:9200/megacorp/employee/8?version=20&version_type=external" -d '> {> "name" : "Tao",> "city" : "NJ"> }'{"_index":"megacorp","_type":"employee","_id":"8","_version":20,"created":false}
1.9.3 冲突重试
如果通过在API中指定version的方式,在更新文档时发现读写不一致,则更新操作会失败。我们可以指定其失败后重试的次数,来实现自动地重试。
这个参数是retry_on_conflict,其默认值为0。
[root@ecs1 ~]# curl -XPOST localhost:9200/megacorp/employee/7/_update?retry_on_conflict=6 -d '{"script" : "ctx._source.city=NY"}'{"_index":"megacorp","_type":"employee","_id":"7","_version":3}
1.10 Script
1.10.1 利用script实现局部更新
首先,新增一个文档:
[root@ecs1 elasticsearch-1.7.2]# curl -XPUT localhost:9200/megacorp/employee/8?pretty -d '> {> "tags" : ["A", "B"],> "gender" : "male",> "city" : "Taixing",> "age" : 30> }'{"_index" : "megacorp","_type" : "employee","_id" : "8","_version" : 32,"created" : true}
现在,更新一个整型field(age)的值,将其加1:
curl -XPOST localhost:9200/megacorp/employee/8/_update -d '> {> "script" : "ctx._source.age+=1"> }'
看看这个值变了没有:
[root@ecs1 elasticsearch-1.7.2]# curl localhost:9200/megacorp/employee/8?pretty{"_index" : "megacorp","_type" : "employee","_id" : "8","_version" : 33,"found" : true,"_source":{"tags":["A","B"],"gender":"male","city":"Taixing","age":31}}
再对一个数组field(tags)附加一个元素
[root@ecs1 elasticsearch-1.7.2]# curl -XPOST localhost:9200/megacorp/employee/8/_update -d '{"script" : "ctx._source.tags+=new_tag",> "params" : {> "new_tag" : "C"> }> }'[root@ecs1 elasticsearch-1.7.2]# curl localhost:9200/megacorp/employee/8?pretty{"_index" : "megacorp","_type" : "employee","_id" : "8","_version" : 34,"found" : true,"_source":{"tags":["A","B","C"],"gender":"male","city":"Taixing","age":31}}
1.10.2 基于内容删除一个文档
我们希望删除age为31的文档:
[root@ecs1 elasticsearch-1.7.2]# curl -XPOST localhost:9200/megacorp/employee/8/_update -d '> {> "script" : "ctx.op = ctx._source.age == target_age ? 'delete' : 'none'",> "params" : {> "target_age" : 31> }> }'
但是这样会报错:
{"error":"ElasticsearchIllegalArgumentException[failed to execute script];nested: GroovyScriptExecutionException[MissingPropertyException[No such property: delete for class: da51a7f9a0e50de83432eb2d5f50321c8bce1178]]; ","status":400}
Why?
1.10.3 更新一个尚不存在的文档
考虑这样的一个场景:将一个文档的views域加1,若这个文档还不存在,则创建该文档,并令其views域的值为1。
[root@ecs1 ~]# curl -XPOST localhost:9200/megacorp/employee/9/_update -d '> {> "script" : "ctx._source.views+=1",> "upsert" : {> "views" : 1> }> }'{"_index":"megacorp","_type":"employee","_id":"9","_version":1}[root@ecs1 ~]# curl localhost:9200/megacorp/employee/9?pretty{"_index" : "megacorp","_type" : "employee","_id" : "9","_version" : 1,"found" : true,"_source":{"views":1}}[root@ecs1 ~]# curl -XPOST localhost:9200/megacorp/employee/9/_update -d '> {> "script" : "ctx._source.views+=1",> "upsert" : {> "views" : 1> }> }'{"_index":"megacorp","_type":"employee","_id":"9","_version":2}[root@ecs1 ~]# curl localhost:9200/megacorp/employee/9?pretty{"_index" : "megacorp","_type" : "employee","_id" : "9","_version" : 2,"found" : true,"_source":{"views":2}}
1.11 Search
下面,我们要在一个type的范围内对文档进行Query,首先我们在上述的type内加入3个document:
[root@ecs1 elasticsearch-1.7.2]# curl localhost:9200/megacorp/employee/1?pretty -d '> {> "firstname" : "Tao",> "lastname" : "Xiao",> "age" : 30,> "about" : "Hello, my wife is CCC",> "interests" : ["coding", "jogging"]> }'[root@ecs1 elasticsearch-1.7.2]# curl localhost:9200/megacorp/employee/2?pretty -d '> {> "firstname" : "Jack",> "lastname" : "Chen",> "age" : 40,> "about" : "Hello, I am Jack",> "interests" : ["sports", "music"]> }'[root@ecs1 elasticsearch-1.7.2]# curl localhost:9200/megacorp/employee/3?pretty -d '> {> "firstname" : "Lucy",> "lastname" : "Liu",> "age" : 50,> "about" : "Hello, I am Lucy",> "interests" : ["tv", "talking"]> }'
在该type范围内search全部的文档:
[root@ecs1 elasticsearch-1.7.2]# curl localhost:9200/megacorp/employee/_search?pretty{"took" : 3,"timed_out" : false,"_shards" : {"total" : 5,"successful" : 5,"failed" : 0},"hits" : {"total" : 4,"max_score" : 1.0,"hits" : [ {"_index" : "megacorp","_type" : "employee","_id" : "1","_score" : 1.0,"_source":{"firstname" : "Tao","lastname" : "Xiao","age" : 30,"about" : "Hello, my wife is CCC","interests" : ["coding", "jogging"]}}, {"_index" : "megacorp","_type" : "employee","_id" : "AVCE4xivMv8zm4P4wh-e","_score" : 1.0,"_source":{"firstname" : "Tao","lastname" : "Xiao","age" : 30,"about" : "Hello, my wife is CCC","interests" : ["coding", "jogging"]}}, {"_index" : "megacorp","_type" : "employee","_id" : "2","_score" : 1.0,"_source":{"firstname" : "Jack","lastname" : "Chen","age" : 40,"about" : "Hello, I am Jack","interests" : ["sports", "music"]}}, {"_index" : "megacorp","_type" : "employee","_id" : "3","_score" : 1.0,"_source":{"firstname" : "Lucy","lastname" : "Liu","age" : 50,"about" : "Hello, I am Lucy","interests" : ["tv", "talking"]}} ]}}
可见,response通过hits域返回了满足search条件的全部3个文档,以及这些文档自身。
默认情况下,一次search会返回前10个结果。
