@zakexu
2020-12-30T15:04:00.000000Z
字数 22456
阅读 10505
大规模预训练语言模型总结:ELMo、GPT、BERT、XLNet
自然语言处理
首发时间:2019.8.25
作者:zakexu(个人主页)
目录
前言
前段时间一直在忙产品上线的事情,对于NLP领域的新宠“Pretrain+Finetune”范式以及BERT、XLNet等模型都是零零散散的了解,很多细节一知半解,趁着这几天有些时间,索性把相关的paper都从头看一遍,加深理解。大规模Pretrain加小规模Finetune其实并不是最近才有的Pipeline,几年前在CV领域已被提出并证实其在Transfer方面的效果。但CV领域的Pretrain是基于大规模的监督数据,而在NLP领域,标注数据是非常稀缺的,因此才一直不愠不火。直到BERT的推出,基于非监督语言模型的Pretrain才逐渐火爆(毕竟无监督的语料数据太容易获得了),因此笔者就从LM开始,把最近一些前沿的重点工作做下简单的总结,也算是做下笔记加深印象。
一、LM
语言模型(Language Model,LM)是一个非常基础的概念,在自然语言处理的各项任务中起到极其重要的作用。同时对于后续知识点的掌握是一个不可或缺的储备,因而文章的开头还是先简单熟悉一下LM。
1、定义:对于长度为 的语言序列,其语言模型指的就是该语言序列的共现概率,也就是联合概率分布 。
2、概率计算:根据贝叶斯链式法则,语言模型的联合概率分布可以拆解为:
(1)计算量大:假设训练语料中字典大小为 ,语言序列长度最长为 ,语言序列中的 都来自字典,那么模型参数量级为 ,也就是意味着模型参数量会随着语言序列长度的增长而指数级暴增。
(2)数据稀疏:由于整个模型的参数量级为 ,根据似然估计的计算方式,一般的训练语料中,会出现大量的参数为0的情况(一般的训练语料很难覆盖到所有的 )。
3、N-gram模型:为了解决上述参数量大而带来的计算问题,引入了马尔科夫假设,也就是任意一个当前词 出现的概率,只跟其上文的前 个词有关,这样的模型就称为N-gram模型。一般 的取值为1、2、3,分别对应unigram、bigram、trigram模型;以bigram为例,其概率模型可以表示为:
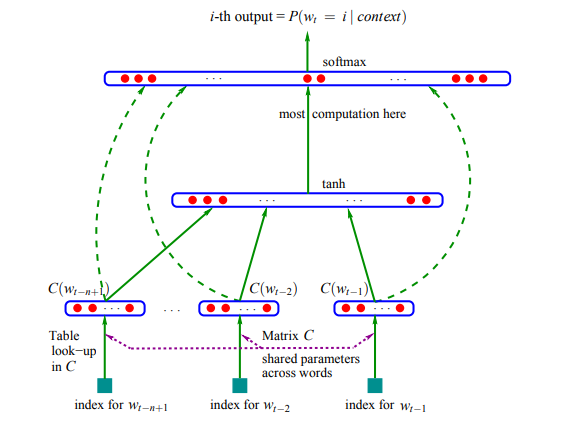
4、基于神经网络的语言模型(Neural Network Language Model,NNLM):上述的N-gram本质上是基于统计频次的模型,缺乏泛化能力。而基于神经网络的语言模型赋予每个词向量化的能力,丰富其表征能力,从而提高模型泛化的能力以及避免OOV带来的影响。如图1所示就是基于前向神经网络的语言模型。
5、语言模型的评价指标:perplexity(困惑度)
(1)在信息论中,一般采用相对熵来衡量两个分布之间的相似度。对于随机变量 ,其熵、交叉熵以及相对熵的定义如下:
(2)对于语言模型而言,计算相对熵评测其模型效果时, 是一个固定不变的值(真实分布唯一),因此可以用 来衡量两个分布之间的相似度。对于样本的真实分布可以表示为:
二、RNN vs LSTM
(一)RNN
1、自然语言处理本质上属于序列问题,循环神经网络(Recurrent Neural Network,RNN)就是为了解决序列问题而被提出的。相比传统的DNN或者CNN网络,它的优势在于:
(1)可以更加便捷地学习到足够长的上文信息;在语言模型的学习过程中,N-gram模型随着 的变大会带来模型参数量级的指数增长,而RNN可以很好地解决这个问题,理论上可以获得上文所有序列的信息。
(2)可以适应序列数据不定长输入的特点;在自然语言处理的任务中,输入的序列通常都是不定长的,而传统的DNN跟CNN输入输出都是固定维度的。
2、定义:给定一个长度为 的输入样本 ,其在 时刻对应的模型输入是 (注意: 是一个向量),该时刻的隐层状态 是由当前时刻模型的输入 跟上一时刻模型的隐层状态 所决定的。对于每个时刻的模型输出 则由当前时刻的隐藏状态 所决定。具体如图2所示。其中 代表单个时刻的网络模型,每个时刻的网络模型参数是共享的。从图中可以看出,对于不定长的输入,RNN可以通过横向扩展网络结构来训练,而由于横向的网络模型参数是共享的,所以这种结构天然适合不定长的序列任务,也是RNN的核心思想。
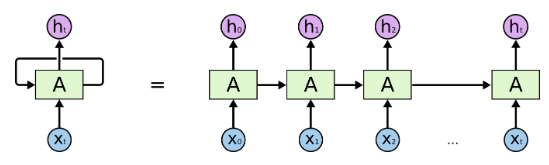
3、RNN的前向传播
对于 时刻,假设输入为 ,那么隐层状态为:
4、RNN的反向传播
RNN的损失函数一般采用交叉熵,对于时刻 ,交叉熵定义如下:
(二)LSTM
1、定义:LSTM即Long Short Memory Network,是为了克服RNN在长期依赖问题上的缺陷而被提出,属于RNN的一种变种,通过一堆门控单元来对历史信息进行选择性地传递或者遗忘,从而有效地捕捉上文信息。
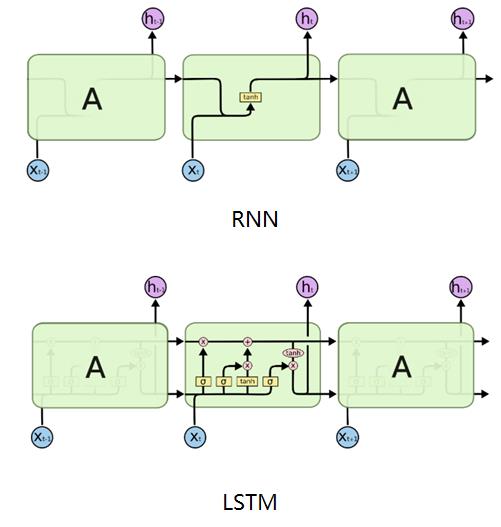
2、LSTM的前向传播
(1)单元状态流
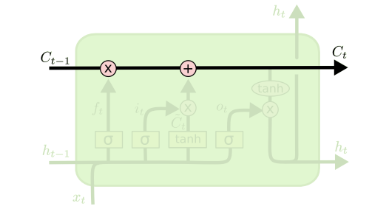
单元状态流可以理解为LSTM的记忆流水线,上面存储着LSTM对上文信息的提取记忆。主要是通过遗忘门、输入门以及输出门来管控。
(2)遗忘门
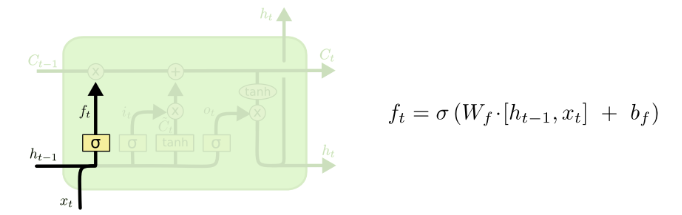
如图所示, 表示上一个时刻的隐层状态, 表示 时刻的输入(注意: 是一个向量), 表示遗忘门权重参数(该权重参数可以拆分为两个权重参数矩阵,分别对应输入状态跟上一个时刻隐层状态), 表示遗忘门偏置参数, 表示sigmoid激活函数,这样子可以确保遗忘门输出 是一个0到1之间的数值,这个数值决定有多少历史信息需要遗忘。1表示完全保留,0表示完全舍弃。
(3)输入门

如图所示, 表示输入门权重参数, 表示输入门偏置参数, 表示sigmoid激活函数,这样子可以确保输入门输出 是一个0到1之间的数值,这个数值决定有多少输入信息需要记忆。1表示完全保留,0表示完全舍弃。 表示权重参数, 表示偏置参数, 表示激活函数,输出值 表示当前时刻流向单元状态的值。输入门控制的就是有多少 流入单元状态。
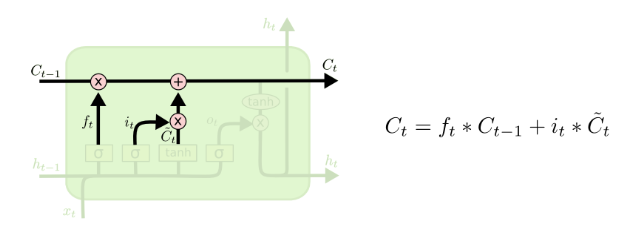
根据图7可以看出,最终单元状态保存的信息就是通过对上一个时刻的状态信息 进行选择性遗忘,对当前时刻的输入单元状态信息 进行选择性保留,从而组成当前时刻的最终的单元状态信息 。
(4)输出门
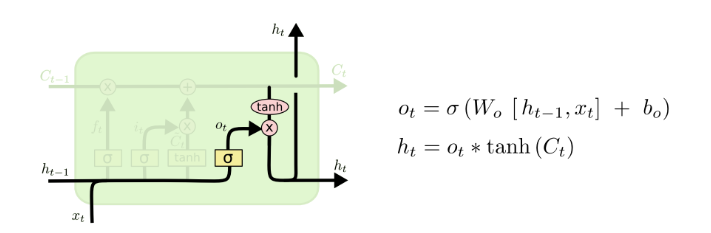
如图所示, 表示输出门权重参数, 表示输出门偏置参数, 表示sigmoid激活函数,这样子可以确保输出门输出 是一个0到1之间的数值,这个数值决定有多少输出信息需要记忆。1表示完全保留,0表示完全舍弃。
(三)GRU
GRU(Gated Recurrent Unit)是LSTM的变种,LSTM具有3个门(输入门、输出门、遗忘门),而GRU只有2个门(更新门、重置门),并且GRU也抛弃了单元状态的概念,由于GRU的模型参数变少,所以训练时候更好收敛。
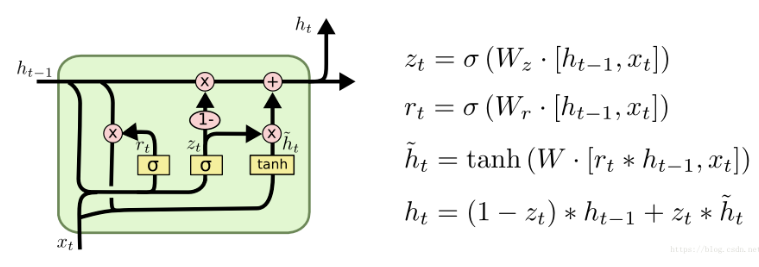
如图所示, 表示重置门, 表示更新门。
(四)RNN网络的基本应用
1、N vs N
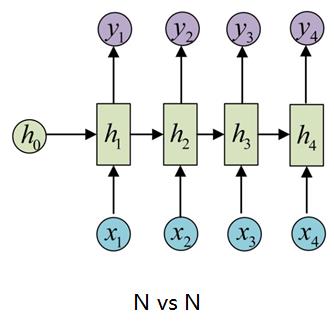
如图所示,输入输出等长。典型的应用场景有:序列标注、语言建模(输入一般是 ,输出则是 ,这就是典型的char RNN)等。
2、N vs 1
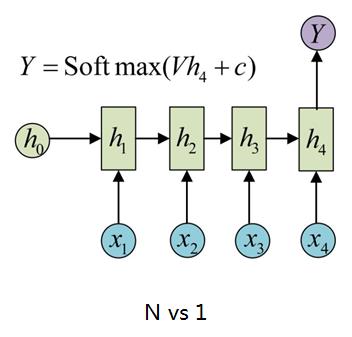
如图所示,输入是一个序列,输出则是单个时刻的向量,后面再接个softmax分类器。典型的应用场景有:文本分类、情感分析等。
3、1 vs N
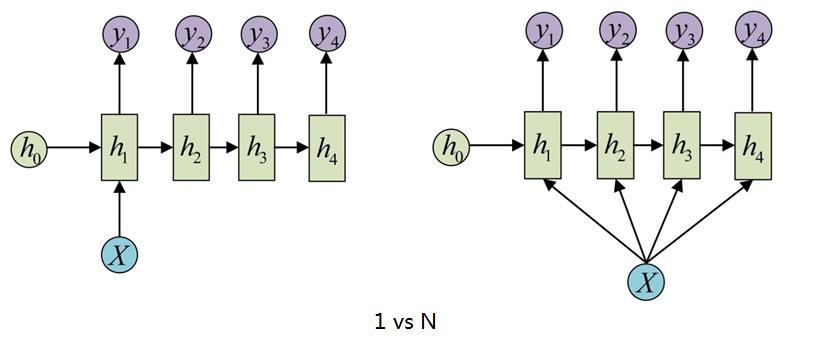
如图所示,输入是单个时刻的向量,输出则是一个序列。典型的应用场景有:图像生成文字等。
4、N vs M
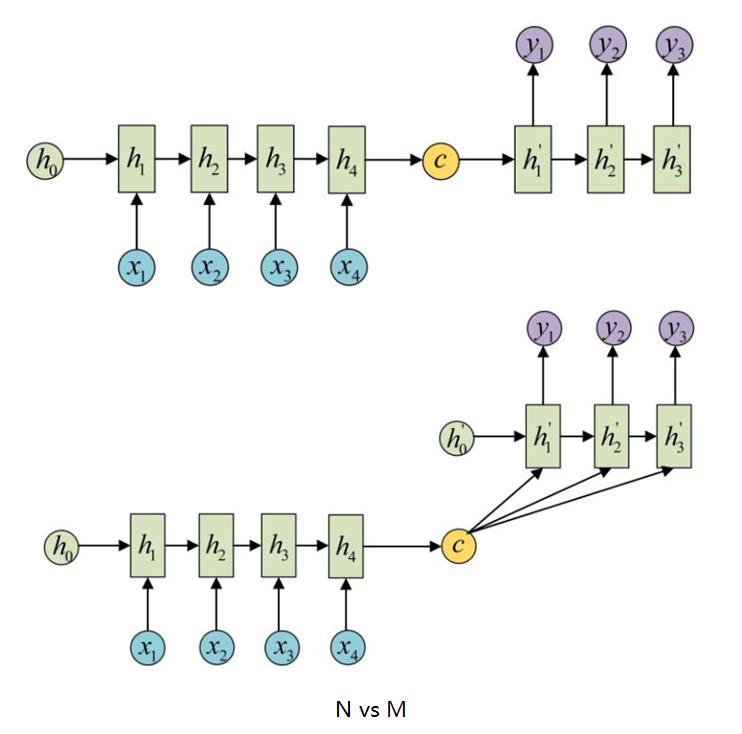
如图所示,输入输出可以是不等长序列,该模型先是将输入序列编码成一个上下文向量,然后根据上下文向量解码成一个不等长的输出序列,因此该结构也叫encoder-decoder结构,也叫seq2seq模型。典型的应用场景有:
机器翻译、文本摘要、语音识别、阅读理解(输入是文章内容以及问题,输出是问题对应的回答)。
三、Attention Mechanism
上文已经介绍了seq2seq的模型结构,该网络结构在处理序列到序列的任务中应用非常广泛。但其存在2个明显不足的问题:
1、encoder将所有的输入序列信息压缩到固定维度的上下文向量中,很显然是存在信息的有损压缩的,尤其是当输入序列长度过长的情况下。
2、decoder在解码的时候,每一个时刻的上下文向量是固定不变的,但在实际情况中,decoder端某个时刻往往只对应encoder端的某几个时刻的序列值,而不是所有时刻。举个例子,在机器翻译中,对于样本对“我爱中国——I Love China”,输出序列的“China”其实只跟输入序列的“中国”有关。
因此,为了解决上述存在的问题,Attention Mechanism(AM)被提出。
1、Attention机制

如图所示,对于decoder,定义条件概率如下:
2、Self-Attention
传统的Attention机制是根据encoder端跟decoder端的隐层状态来计算Attention Score的,得到的结果是源端跟目标端之间词与词的依赖关系。但Self-Attention是分别在encoder跟decoder端计算Attention Score的,先是在encoder端计算Attention Score捕捉源端自身词与词之间的依赖关系,然后将encoder端得到的Attention Score加入到decoder端,捕捉目标端自身词与词之间的依赖关系以及目标端跟源端词与词之间的依赖关系。相对比传统的Attention机制,Self-Attention的优势在于不仅可以捕捉目标端跟源端之间词与词的依赖关系,还可以捕捉源端或者目标端自身词与词的依赖关系。
3、Scaled Dot-Product Attention
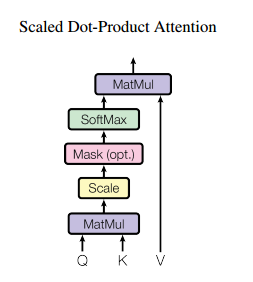
之所以提Scaled Dot-Product Attention是因为一般Self-Attention都是结合Scaled Dot-Product Attention实现的。假设输入为 ,其中 是维度为 的向量。首先将输入 经过线性变化得到 (Self-Attention的体现),分别表示Query、Key、Value。如图所示, 做一个矩阵相乘的操作,得到输入端自身词与词之间的依赖关系,然后依次经过尺寸变换(防止输入维度过大导致梯度落在softmax函数的边缘区域,从而训练难收敛)、掩码(可选操作,主要用于对时间先后关系的表示)、SoftMax操作,得到最终的Self-Attention矩阵。将Self-Attention矩阵跟做矩阵相乘,就可以得到最后的输出结果。
注: 在实际应用中,attention掩码的实现是在进softmax函数之前加上一个非常大的负数;之所以这么做的原因是如果在softmax函数出来之后再乘以01掩码的话,会导致和不为1;如果是在进softmax函数前乘以01掩码的话,根据softmax函数曲线,0值附近的输出是最大的。
4、Multi-Head Attention
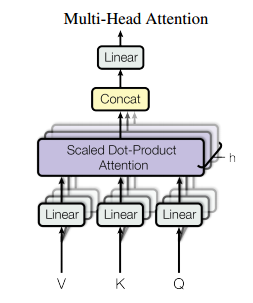
上述的Attention都是只有一套 ,而Multi-Head Attention是在一套 的基础上线性变化得到 套 ,分别得到输出矩阵之后再进行拼接。之所以采用多套 一方面是可以加速Attention的计算,一方面是可以获取不同空间维度的依赖信息。个人理解这应该是一个工程上的trick。
四、Transformer
传统seq2seq的encoder跟decoder都是基于RNN等序列模型进行设计的,比如为了改善RNN的长期依赖问题,引入LSTM;为了获取目标端跟源端的对齐属性,引入了Attention机制。但是由于基础模型都是RNN等序列模型,在前向预测或者训练过程中,都是必须沿着序列方向依次进行计算(along the symbol positions),无法并行,因此计算效率是其面临的一个问题。为了改善这个问题,Google设计了Transformer特征抽取器。Transformer完全抛弃了RNN等序列模型,encoder跟decoder都是完全基于Attention机制设计的。
具体的模型结构如图17所示。整个网络结构还是沿用传统的两段式的encoder-decoder结构。
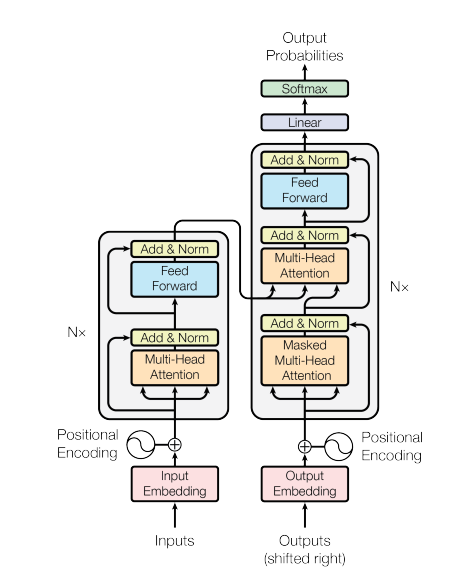
1、encoder跟decoder都是 层网络结构。对于encoder,每一层网络是由2个子层组成,分别是Multi-Head Attention跟Feed Forward Network。对于decoder,每一层网络则是由3个子层组成,分别是Masked Multi-Head Attention、Multi-Head Attention跟Feed Forward Network。除此之外,整个模型所有的子层都会引入残差连接以及layer normalization,因此每个子层的输出可以表示为 ,其中 表示每一个子层的输入。由于引入了残差连接,因此每一个子层网络的输出向量的维度都必须保持在 。
2、Transformer网络除了encoder跟decoder之外,还包含embedding层跟softmax层。embedding层将输入或者输出的token转换成维度 的向量。softmax层将decoder输出的向量做一个线性变换然后经过softmax函数,预测下一个token的概率值。这儿需要注意的是embding层跟softmax层共享权重参数,只不过embedding层会在共享权重参数的基础上乘以一个缩放因子 。
3、为了充分利用序列的位置信息,Transformer在 embedding层引入了positional encoding。每一个token对应的positional encoding是一个 维的向量,表示如下:
4、Transformer总共有3种不同结构的Attention。在encoder中的Multi-Head Attention指的是典型的Attention,主要是为了捕捉源端词与词之间的依赖关系。Decoder有2种Attention。其中的Multi-Head Attention也是典型的Attention,只不过 是来自encoder,来自上一层decoder,主要是为了捕捉源端跟目标端词与词之间的依赖关系。Masked Multi-Head Attention是为了捕捉目标端词与词之间的依赖关系,加了Masked是为了防止信息泄露,也就是对下文序列的token做了一个掩码不可见的操作。
5、Transformer中的FFN是一个两层的全连接网络,而且是针对每一个position都是共享的。其计算公式如下:
6、关于并行,从上面的描述中可以看出,encoder始终是可并行的,也就是每个position之间的encoder计算可以说都是独立的。而对于decoder而言,训练时候,每个position可以看成是独立的,但在预测的时候,就依然还是不可并行计算的,当前position的计算还是得依赖上一个position的计算结果。
五、TransformerXL
虽然Transformer在各项任务表现突出,但是其有一个比较明显的不足之处,也就是对长文本的长期依赖问题处理不好。首先Transformer的输入是固定长度的token序列,这就导致在训练的时候,经常需要对长文本进行固定片段的划分,分批进入网络训练,一方面是无法捕捉超长文本的依赖关系,另一方面也导致上下文碎片化,忽略了句子边界,也就是原文中提到的context fragmentation。因此,google在Transformer的基础上提出了TransformerXL(extra long的意思),目的就是为了解决Transformer在超长文本的不足之处,其改进点主要有两个:segment-level recurrence mechanism跟positional encoding scheme。
1、segment-level recurrence mechanism(片段级递归机制)
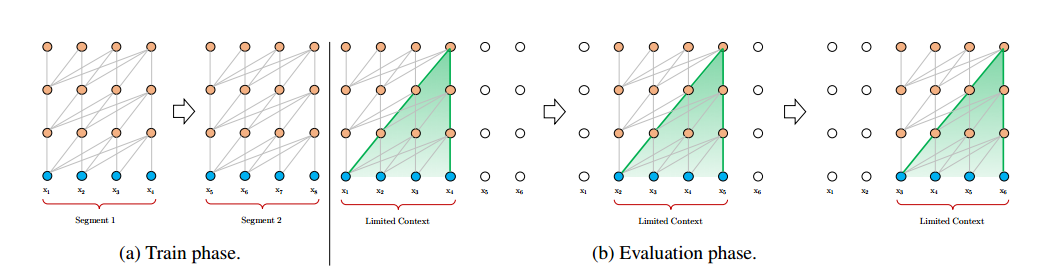
注:训练的时候,按窗口长度做步长,切分文本,进入训练;预测的时候,每次窗口往后移动一个token,预测最后一个token,这样子做的好处就是保证每预测一个token的时候,都能考虑窗口长度内上文的信息。
如图所示,Transformer在处理长文本时,都是通过设置滑动窗口来计算的,每一个窗口对应一个segment。虽然每一个窗口对每一个segment能够很好地处理上文依赖关系,但是窗口之间,也就是上下文segment之间的长期依赖信息并没能往后传递,而且每个窗口也可能会存在着依赖信息重复计算的情况(窗口重叠)。参考RNN获取长期依赖关系的方式,也就是通过同层间的隐状态进行传递,自然而然可以想到的方案就是给segment之间加入这种类似的机制。

假设相邻的两个长度为 的segment分别是 、,每个segment在第 层的隐层状态是 ,其中 表示隐层状态的向量维度,那么TransformerXL的片段级递归机制可以表示为:
2、Relative Positional Encodings(相对位置编码)
Transformer采用一个固定的绝对位置向量矩阵 来表示位置信息。但对于片段递归机制而言,同一个position会出现在相邻的两个segment中,这是有问题的,因此作者提出了相对位置编码的概念。先看看Transformer是怎么结合position coding做Attention score的计算,考虑绝对位置编码情况下,第 个query跟第 个key的score可以表示如下:
因此,最后(a)(b)(c)(d)分别对应的就是content-based addressing、content-dependent positional bias、global content bias、global positional bias。
六、Pretrain + Finetune Pipeline
(一)ELMo
通过预训练得到高质量的词向量一直是具有挑战性的问题,主要有两方面的难点,一个是词本身具有的语法语义复杂属性,另一个是这些语法语义的复杂属性如何随着上下文语境产生变化,也就是一词多义性问题。传统的词向量方法例如word2vec、GloVe等都是训练完之后,每个词向量就固定下来,这样就无法解决一词多义的问题。为了解决这个问题,AI2提出了ELMo(Embeddings from Language Models),其通过在大型语料上预训练一个深度BiLSTM语言模型网络来获取词向量,也就是每次输入一句话,可以根据这句话的上下文语境获得每个词的向量,这样子就可以解决一词多义问题。总结来说,word2vec、GloVe等模型是得到一个大型的词向量矩阵,每个词的向量都是固定的,而ELMo是得到一个预训练的语言模型,每次需要获取一个词的向量时,需要实时输入词的上下文序列,从而得到该语境下的词向量。
除此之外,ELMo是一个多层的网络结构,最终得到的词向量可以是每一层网络输出向量的线性组合,而不仅仅只是顶层输出的向量。通过评估可以发现,底层网络的输出向量主要获取语法层面的信息,因此在词性标注等任务表现突出;而顶层网络的输出向量主要获取上下文相关的语义信息,因此在词义消岐等任务表现突出。
1、双向LSTM语言模型
(1)前向LSTM语言模型表达式如下:
其中 表示第 个token,在输入层,会转换成与上下文无关的词向量 (原文作者用的是CNN-BIG-LSTM);前向LSTM模型一共有 层隐层,第 个token在第 层的状态值为:,而第 个token在第 层的状态值 ,后面一般会接一个softmax,用来预测 。
(2)后向LSTM语言模型表达式如下:
(3)双向LSTM语言模型:其实就是对前向LSTM语言模型跟后向LSTM语言模型做一个联合训练。损失函数定义如下:
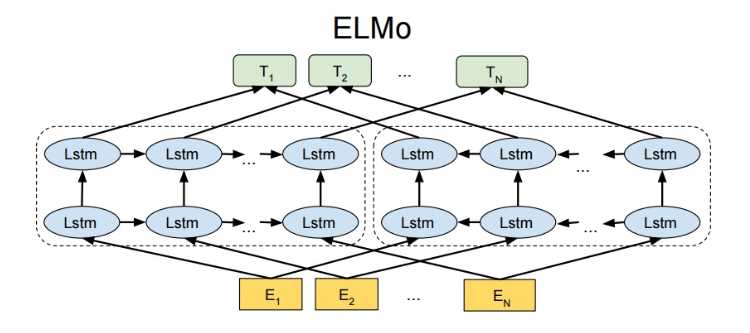
2、ELMo向量
对于一个token ,在一个 层的双向LSTM模型中,其有一套 的向量表示组合:
3、ELMo向量在下游监督任务的应用
基于一个预训练好的BiLSTM语言模型,我们可以得到一套 的向量表示组合(一般取 ,那么就可以得到3层向量特征,可以理解为输入层捕捉的是单词特征,第一层LSTM捕捉的是句法信息,第二层LSTM捕捉的是语义信息),那么只需要结合下游任务,学习获得权重因子 、 即可得到最终的词向量 。
ELMo的作者提供了几种应用的思路:(1)固定权重因子 、,从而得到 向量,然后跟原始词向量进行拼接,,再输入到下游任务中,重新训练权重因子。(2)在前者的基础上,对隐层的输出也引入ELMo向量,,只不过是采用不同的权重因子。
(二)GPT
ELMo虽然解决了一词多义的问题,但还有没有改善的空间呢?肯定是有的,最简单的想法就是用新秀特征抽取器Transformer替换LSTM,因此,openAI就提出了GPT(Generative Pre-Training)。基于Pretrain + Finetune范式,用Transformer decoder替换ELMo的LSTM,而且GPT只采取了单向的网络,这儿也就埋下了伏笔,给了Bert有机可乘(Bert后面再介绍)。
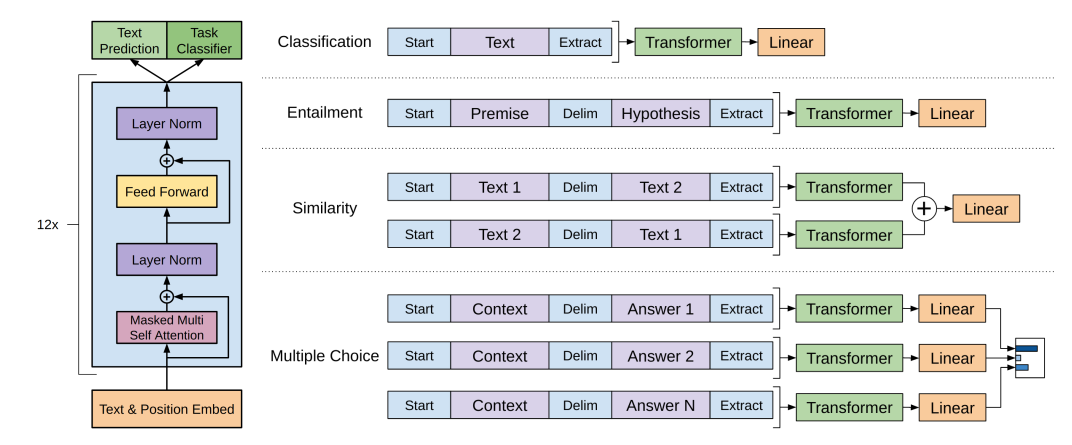
1、前向计算:对于输入的第 个token,其上文长度为 的token序列可以表示为 ,因此GPT的前向计算可以表示如下:
2、Pretrain:GPT的预训练是基于以下的损失函数进行梯度下降训练(单向语言模型):
3、Finetune:假设现有数据集 ,下游任务是一个分类任务,那么其预测函数为:
(三)BERT
前面提到的GPT是基于单向语言模型来做预训练的,在sentence级别的NLP任务表现良好,但是在token级别的NLP任务并不是最佳选择,毕竟token的含义不仅取决于上文信息,同时也跟下文信息有着密切关系,因此,Google提出了BERT(Bidirectional Encoder Representations from Transformers)模型,用双向语言模型替换单向语言模型。
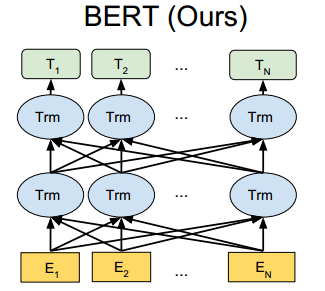
1、前向计算:如图可以看出,BERT的前向跟GPT的前向区别主要有两点:(1)GPT的特征抽取器采用的是Transformer的decoder(单向语言模型),而BERT采用的是Transformer的encoder(双向语言模型);(2)输入表示的区别:如图23所示,所有输入序列开头添加[CLS]token(对于N vs 1的NLP下游任务,取[CLS]token的最后一层向量进入下游任务),句子结尾添加[SEP]token;输入层由3个embedding向量组成,分别是token embedding、segment embedding、position embedding;输入token不超过512个。
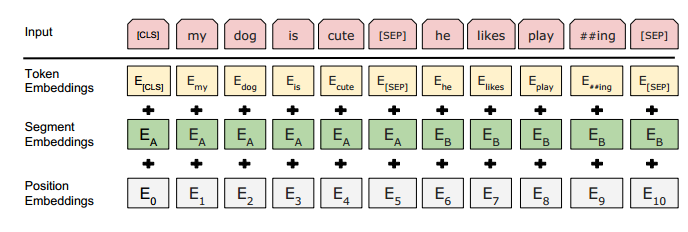
2、Pretrain:区别于GPT的单向语言模型训练,BERT是一个双向语言模型,作者采用两个无监督任务进行预训练,一个是token级别的,一个是sentence级别。token级别的预训练任务采用的是Masked Language Model(MLM);具体做法是取每个输入序列15%的token进行预测,其中80%替换成[mask],10%替换成随机token,10%保持不变;训练过程中,在这15%的token的最后一层向量后面接一层softmax进行预测。sentence级别的预训练任务采用的是Next Sentence Predict(NSP);具体做法就是构造句子对训练样本 ,50%的样本label为1,表示句子B是句子A的下一句,50%的样本label为0,表示句子B不是句子A的下一句;训练过程中,取[CLS]token的最后一层向量进行预测。因此,BERT就是联合上述两个任务进行预训练的,既可以捕捉token级别的信息,又可以捕捉sentence级别的信息。
3、Finetune:BERT的Finetune就很好理解了,跟GPT的Finetue没有太大区别,都是采用少量的NLP下游任务的监督样本,对BERT以及下游任务的参数进行微调。
(四)GPT2.0
前文提到的ELMo、GPT、BERT本质上都是基于大量无监督样本的预训练以及少量指定任务的有监督样本进行Finetune,最终衡量各个预训练模型的效果都是通过在各种下游任务的benchmark刷SOA来验证。而GPT2.0则不是一味地刷benchmark的SOA来指导工作,其更关注的是预训练模型的通用性。原文作者提出,现有的机器学习系统更多的像是一个narrow experts,在指定领域,拥有数量足够大的标注数据集、容量足够大的模型结构,在有监督的学习方法下,就可以获得特定领域下足够好的效果;但这些模型对数据的分布比较敏感而且现实世界中,很多特定领域的任务都没有足够多的标注样本;所以作者把研究的重心放在了competent generalists,也就是通过无监督的方法获取更加通用的模型上,通用到不需要有监督的Finetune就可以直接应用到下游任务中。论文作者也提出了,现有模型缺乏的泛化能力主要是因为训练过程中的单任务单领域数据所导致。因此,GPT2.0更加关注的是通过多领域的数据集来获取更加通用的预训练模型(multi-task learning),从而在zero-shot(无需任务参数以及网络结构的调整)的设定下,可以在下游任务中表现良好。
相比GPT,GPT2.0的改进在于:
1、对GPT的模型参数进行扩容:比如扩充到48层的Transformer Layer;将Layer Normalization放到每一层的外面;将输入token序列长度由512的限制扩充到1024等。
2、更丰富、更高质量的数据集:通过爬取网页,人工筛选,最终构建了800万篇、40GB大小的网页数据集WebText。
3、单向语言模型+多任务的训练方法:GPT的单向语言模型可以表示为 ,而GPT2.0则是在单向语言模型的基础上,加入了多任务的因素,。具体是通过构造训练样本而实现的,在输入的token序列添加具体的任务标识(下游任务通过任务标识来做预测),比如对于翻译任务,输入token序列可以表示为:,对于阅读理解任务,输入token序列可以表示为:。
4、基于Byte Pair Encoding的输入表示。
(五)XLNet
前面提到的GPT跟BERT这两个语言模型,分别属于AutoRegressive(AR)自回归模型跟denoising AutoEncoder(AE)自编码模型。其中AR模型属于单向语言模型,可以表示为:;而AE模型没有明确的density estimation,其通过对输入token序列随机做[MASK](denoising的体现),然后再进行重建,从而训练得到整个语言模型,属于双向语言模型,可以获得上下文信息。分别看一下AR模型跟AE模型的似然函数,对于AR模型,其最大似然函数表示为:
基于AR的GPT模型缺点在于只能学到上文信息;而基于AE的BERT模型虽然可以学到上下文信息,但由于训练时对输入token序列随机做了[MASK],导致了Pretrain跟Finetune两个阶段输入不一致,而且随机替换token,会破坏[MASK] token之间的相关性(例如对“因为”、“所以”这样一些具有上下文关系的[MASK] token),对于某些特定任务,效果不佳。而为了综合AE跟AR的优点,google提出了XLNet。XLNet本质上是一个AR模型,但其通过优化联合概率分布函数的所有可分解排列组合的期望似然(排列语言模型)引入上下文信息,解决了BERT中[MASK]的问题,也集成了TransformerXL(当前效果最好的AR模型)的优点segment-level recurrence mechanism跟positional encoding scheme,解决长文本依赖问题,从而完虐BERT。
1、Permutation Language Modeling(排列语言模型)
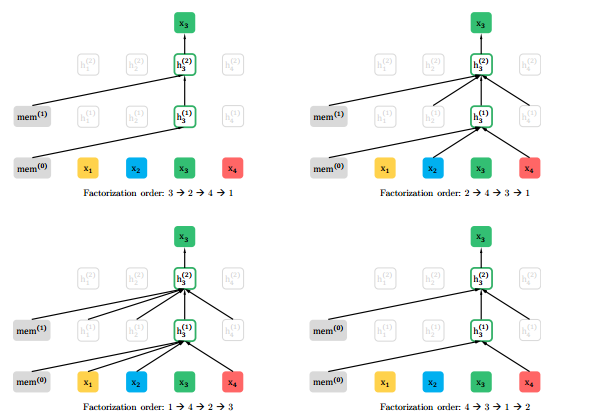
对于AR模型的表达 ,其通过将联合概率分布拆解成多个条件概率的累积,默认是前向的分解方式,也就是 。但其实是可以有 种分解方式,如图24,对于输入序列 ,列举了4种分解的方式(例如对于分解顺序2-4-3-1,)。假设 表示所有分解方式的集合, 表示具体的分解方式,那么排列语言模型的最大化期望似然可以表示为:
如式子所示,所有分解方式都共享一套模型参数,最终的优化目标就是所有分解方式的期望似然。这儿需要注意的是:(1)排列语言模型并没有改变输入token序列的顺序,而是改变分解的顺序(通过Transformer内部Attention的掩码来实现),这点很重要,因为在Finetune阶段,模型的输入是有序的。(2)不一定需要采集所有的分解方式,可以用采样的方式。
基于排列语言模型来引入上下文信息,可以解决BERT的[MASK]问题,比如一个sentence中有两个[MASK],在预测第一个[MASK]时,就无法用到第二个[MASK]的token信息,但是基于排列语言模型,则没有这个问题。
基于Transformer来实现排列语言模型,其概率函数可以表示如下:
其中 表示某种分解的顺序, 表示 时刻之前的上文信息;根据式子可以看出,预测函数跟token所在位置无关,导致训练得到的representation没有多大意义(假设输入token序列是 ,对于分解顺序1-2-3-4跟1-2-4-3,在位置3跟4看到的都是位置1跟2,由于没有位置信息 ,大家看到的都是位置1跟2,所以就会给训练带来不确定性,这个不确定性是排列语言模型带来的)。为了避免这个问题,原文作者对预测函数做了re-parameterize,表示如下:
注:在BERT中,根据上下文预测[MASK]位置的token,是根据[MASK]位置的内容向量(由于使用了[MASK]占位符,所以并无实际意义)跟位置向量可得,是包含了所有上下文以及当前的[MASK]token(因为内容并无实际意义,因此不存在数据穿越的问题)。而在XLNet中,由于排列语言模型的设定以及不存在[MASK]占位符,所以只包含了上文信息,不包含下文信息以及当前token信息,那么剩下的问题就是如何设计,该首先肯定不包含当前token的内容信息,其次就是需要包含该token的位置信息。可以回头看TransformerXL的attention score计算,在XLNet这边,第一、二项是不存在的,因为是不带内容信息的,那么可以理解为就是第三、四项,其实是一样的,都是用一个全局向量来表示位置向量,看原文的初始化是用了。
2、Two-Stream Self-Attention(双流自注意模型)
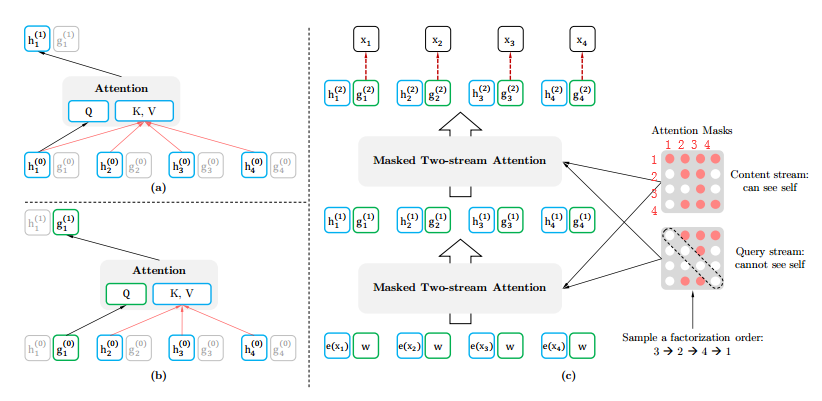
如图25所示,双流指的分别是query stream跟content stream。(1)内容流注意力跟传统Transformer的Attention机制一样,所有的都来自向量,并且对于每个,都可以看得到自身,比如图中的可以看得到,这跟BERT是一致的,只不过BERT自身会是一个[MASK],而XLNet并没有做mask。(2)query流注意力是XLNet的创新点,其来自向量(该向量用初始化,参考TransformerXL,虽然初始化时候每个位置用的都是同一个向量,但因为排列语言模型的存在,后面每一层每个位置的向量都会有差异性),代表的就是位置信息,来自向量(代表的是内容信息),而且其不会看得到自身,比如图中的可以看得到。
双流的计算可以表示如下:
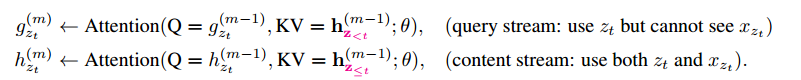
其中 表示第 层的 ;而 则表示第 层的 。最终output层是基于向量计算。
总结
本文主要是对Pretain+Finetune范式下的若干主流模型进行一个学习总结,基本都是抱着论文一步一步啃下来的,至于在实际业务中的落地效果,下来笔者再持续关注。
参考文献
- Understanding LSTM Networks
- 完全图解RNN、RNN变体、Seq2Seq、Attention机制
- 模型汇总24 - 深度学习中Attention Mechanism详细介绍:原理、分类及应用
- Attention Is All You Need
- Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context
- Deep contextualized word representations
- Improving Language Understanding by Generative Pre-Training
- BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
- Language Models are Unsupervised Multitask Learners
- XLNet: Generalized Autoregressive Pretraining for Language Understanding
