@zakexu
2020-12-13T06:13:24.000000Z
字数 7373
阅读 3714
AutoNLP-DeepTagging:基于对抗式多任务联合训练的实体抽取框架
项目总结
首发时间:2019.12.2
作者:zakexu(个人主页)
目录
前言
DeepTagging项目已在公司内部开源,并获得腾讯【新代码文化奖-AI算法评选】金奖,后续也会逐步面向外部开源。
1、简介
AutoNLP是由腾讯云知文团队推出的一站式低门槛的自然语言处理服务定制平台,以可视化的操作支持各种NLP任务的训练以及服务的自动化部署,包括文本分类、序列标注、文本纠错等,旨在为NLP算法研究人员以及合作伙伴提供高效的自动化平台。本项目DeepTagging属于序列标注部分,重点关注命名实体抽取(Named Entity Recognition,NER)。NER任务本质上属于Tagging任务,在政务、金融以及法务领域有着广泛的应用场景,同时又面临小样本量、实体边界模糊等难点。结合客户场景,在业界主流方案BERT+CRF的基础上,本项目提出了4种不同的模型架构,在客户场景中都获得不错的效果提升:
(1) Segment-Based BERT+CRF:基于字词结合的BERT+CRF模型,引入词的边界信息以及词的向量信息;适用于样本量充足、实体边界清晰、对训练性能要求不高的场景。
(2) MRC-Based BERT+CRF:基于机器阅读理解(Machine Reading Comprehension,MRC)的BERT+CRF模型,将传统的Tagging序列输入形式转换成QA的输入形式,从而引入实体的先验信息,提升识别效果;适用于实体先验信息明确的场景。
(3) Multi-Task Bert+CRF:基于多任务联合训练的BERT+CRF模型,既可以引入out-of-domain的NER数据集来进行Cross-Domain学习,解决小样本量问题,也可以支持NER跟中文分词(Chinese Word Segment,CWS)多任务联合训练,解决实体的边界问题;适用于小样本量且具有多个相邻domain样本集的场景。
注: 多任务既包含了不同nlp任务的联合训练,比如NER跟CWS的联合训练;也包含了同一个任务用不同domain数据的联合训练,因此下文会拆成2个子类来分别分析。
(4) Adversarial Multi-Task Bert+CRF:基于对抗式多任务联合训练的BERT+CRF模型,在多任务的基础上,引入对抗训练机制,从而可以获取task-shared的信息而去除task-special的影响,提升多任务学习的效果;适用于小样本量且具有多个source domain样本集的场景。

2、模型介绍
2.1 Segment-Based BERT+CRF

基于BERT+CRF的Tagging方法,主要是字级别的模型,但在汉语中,词才是最小的语义单元,因此引入词级别的特征表达很有必要。除此之外,实体识别的任务可以细分为实体边界确定以及实体类别划分,引入词的边界信息可以提升实体识别的效果。
本项目以BERF+CRF为基础,在embedding层以及output层引入词的表达:
(1)embedding层除了字向量、片段向量以及位置向量之外,设计了词边界向量,每个词采用BIO的标注体系进行标注。
(2)output层基于char-level的输出,利用词的边界信息做pooling,得到word-level的特征,最终将char-level以及word-level的特征拼接输入到CRF层。
实验过程中会发现Segment-Based的模型虽然引入了词的边界信息以及向量信息,但是也存在若干问题:
(1)最终的效果依赖于分词器的选择,不同的分词粒度以及标准对实体抽取的效果影响比较大,举个简单例子:在NER任务中,“广东省广州市XX小区XX号楼XX的房间”是一个LOC的实体,但是一般的CWS任务中可能会将这一个实体词进行拆分,因此反而带来边界的干扰信息。
(2)老生常谈的新词发现问题,实体词本身就是分词任务中的一个结果补充,因此这方面可能也是一个问题。
(3)输出层word-level信息的pooling时,由于窗口是不定长的,性能上也不好做优化,所以训练测试性能较差。
(4)另外还有一些需要进一步探索的点,比如字词向量的融合方式(拼接?加权?)、词向量的pooling(max?mean?bilstm)。
2.2 Multi-Task Bert+CRF

为了解决Segment-Based模型所遗留的问题,可以采用多任务的方法,这么做的好处有:
(1)更多多任务联合:通过对Tagging任务跟CWS任务的联合学习,可以更有效地获取词界信息,避免特定分词器的干扰。
(2)标签样本:CWS任务的引入,相当于引入更多的监督信息,可以更有效提升训练效果。
(3)更快的推理性能:主任务NER的推理跟BERT+CRF一致,差异主要体现在训练阶段。
实验过程中这儿也有一些想法要share一下:由于不同的任务可能样本数量差别较大,比方说我的主任务NER可能才1万甚至几千的样本量,这个在toB客户的场景中其实是很常见的(借助标注平台我也自己标注了一些样本,体验了一把肉眼标注的苦),而辅助任务比如分词,可能样本量大几万甚至更多,这样子直接联合训练的话可能会直接被带偏了,效果也不好,因此这儿有一些trick需要注意,比如说做一下简单的随机采样?或者是不同的任务要用不同的batch_size?同时,不同任务loss之间的权重也是一个影响,所以其实这儿也是有一些超参需要处理的!
2.3 Adversarial Multi-Task Bert+CRF模型

进一步思考,多任务的联合学习是否就只有正向的收益而不会有反向的折损? 其实通过一些case可以发现确实是有负收益的存在的,本质原因是因为NER任务跟CWS任务的词粒度标准可能不一致,比方说在NER任务中,“重庆市渝北区xxx小区”是一个实体词,而在CWS任务中,“重庆市”是一个词,“渝北区”是一个词,“xxx小区”也是一个独立的词,这样的联合任务,反而会给主任务带来噪声。因此总结来看,对于联合训练的任务,是既存在task-sahred的信息,也存在task-privated的信息,前者是起正收益作用,后者是起负收益作用,那么是否可以只利用task-shared的信息而去除task-privated的干扰呢?
为了获取干净的task-shared信息,本项目引入了对抗的机制,通过对抗训练,将task-shared跟task-privated的信息区分,从而提升最终的识别效果。
(1)首先先解释一下为啥要引入highway network这么一个东西,其实想想也不难理解,bert做为一个share的model,出来之后如果就进入crf,那么无论是NER还是CWS或者是share那一路,大家发挥的空间其实就不大了,而加入highway的一个初衷就是为了让bert出来的向量可以映射到不同的语义空间上去,从而各自去学习specific部分的信息;那为啥不是BiLSTM之类的呢?主要是因为效果不好,可能bert本身网络就已经比较深,这个时候再搞一个BiLSTM估计也不好收敛,而highway network这东西就跟残差网络类似,通过门控制可以避免这种高层过拟合的问题,撸完实验也发现确实还不错。
注: highway可以表示为:,其中表示对输入的非线性变化,就是门控制函数。
(2)关于中间对抗网络部分,其实也不难理解,本来对于NER跟CWS的样本,经过bert跟shared highway之后,应该是会分到不同的特征空间中去,可以理解这是生成部分,那这个时候就需要一个Discriminator来做对抗,让分类器最终区分不了NER跟CWS的样本,而梯度反转层主要是实现上的一种方式,一般的对抗生成loss都是 的形式,通过梯度反转层就可以用一个来做优化。
注: 对抗损失可以表示为:,其中表示highway,表示Discriminator,是为了让两个任务的样本经过bert跟shared highway之后,特征空间尽量一致(NER跟CWS样本不可分);是为了让NER跟CWS的样本尽量可分,也就是两者的特征空间尽量不一致,可以看出前后两个目标是对抗的。
2.4 MRC-Based BERT+CRF模型
基于BERT+CRF的实体识别任务是采用Tagging的方法来解决,也就是对于输入 ,给出 的标注结果(本项目统一采用BIO标注体系),但这种方式会有一个不足之处,每一类实体在训练的过程中都是一个“冷冰冰”的数字标签(B-PER,I-PER等),为了引入实体本身的一些先验信息,本项目借鉴机器阅读理解任务的处理方式来做实体识别任务,将Tagging的任务形式转换成QA的任务形式,也就是为每一类实体设计一个question,如下:
| 实体 | 问题 |
|---|---|
| 人名 | 请找出文中的人名,包括姓跟名字,例如刘德华,张学友,也可以是指代词,比如刘某、许某 |
| 机构 | 请找出文中的组织,主要是指法院、检察院等机构 |
| 位置 | 请找出文中的地理位置,包括小区位置、地级市、省份或者是具体位置信息的名词 |
| 时间 | 请找出文中的时间,可以是某年某月某日,也可以是具体到某个小时或者分钟,当然也可以是模糊指代,比如说3月的某一天 |
那么最终模型的输入将转换成: ,其中表示query的第个token 。除此之外,在MRC任务中,一般是需要预测一个start position跟end position,但在Tagging任务中,可能存在多个start position跟end position,而且start position跟end position存在上下文依赖关系,因此这儿依然采用的是CRF等标注模型。

在实验过程中这儿发现了一些有意思的现象:
(1)输入样本的构造过程中,需要将query跟context的token序列进行颠倒拼接,也就是,不然效果会急剧下降,这儿初步猜测是因为pred_mask的连续性问题。
(2)构造不同的query对实验结果影响比较大,这儿业界一般的做法基本都是用标注语料时的指导信息作为query。
(3)MRC-Based的方法可以跟Segment-Based的方法进一步融合,对最终的效果也是有正向提升作用的,当然这儿需要注意的是只对context做segment,对query保持不动。
(4)在Multi-Task的基础上也是可以加入MRC机制的,但是要注意的是需要所有任务都加MRC,效果才有保障,那么问题来了,对于分词任务的话,怎么设计query也是一个问题,但我理解这儿的query应该更多是一个数据一致性上的问题,在我的实验中我是通过一个简单的query来保证数据一致性的,比如“请找出文中的词语,一般是2个字或者2个字以上”。
2.5 Cross-Domain Bert+CRF模型
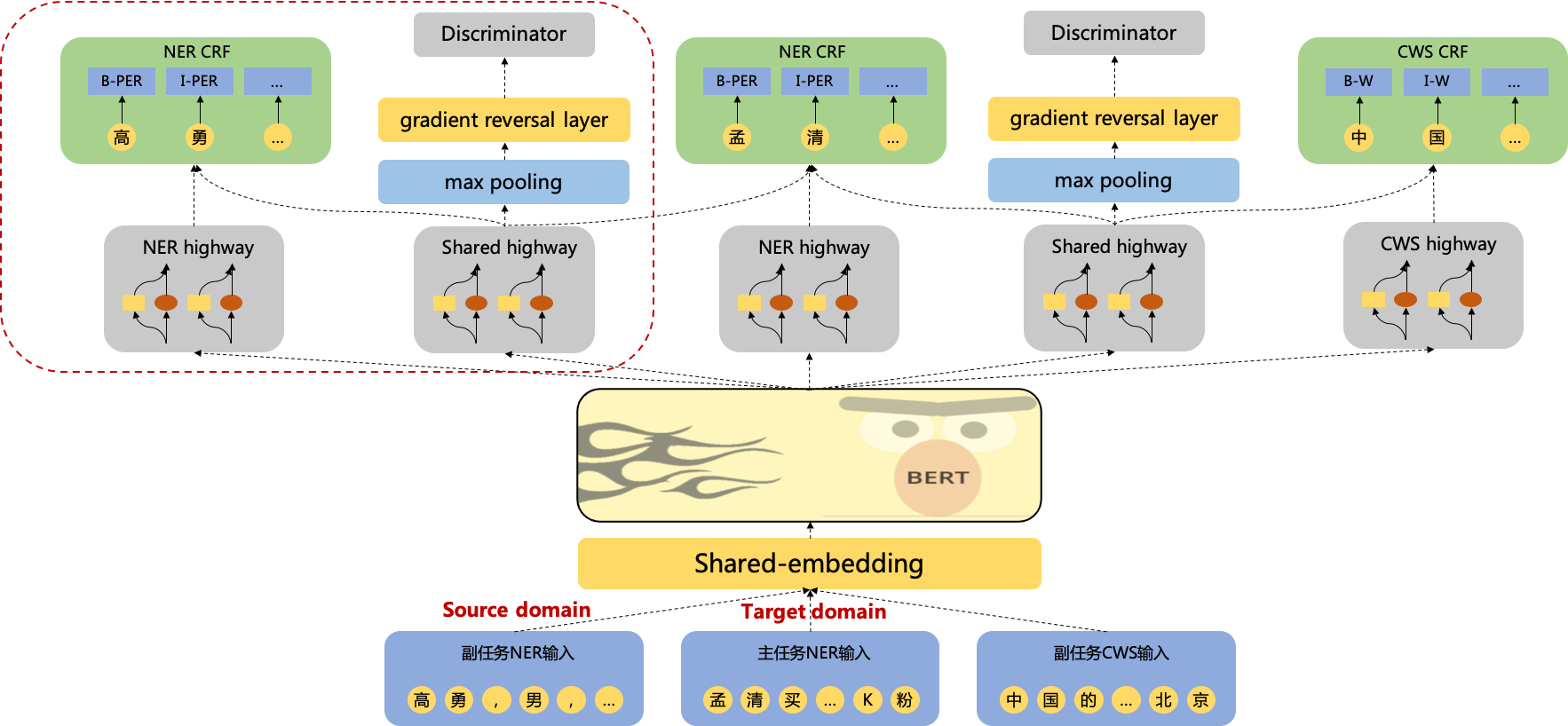
在中文实体识别任务中,各个领域的实体标注数据非常稀缺而且标注成本高。通过联合多个out-of-domain的实体数据集,可以缓解target domain样本量不足的问题。
在挑辅助任务数据集的时候,domain similarity很重要,不然效果不升反降,这个其实也很好理解,毕竟大家的数据分布不那么一致的话,肯定是越学越差,这儿也看了一些有意思的方法,比如在联合训练的过程中,通过domain similarity的一些计算方法,来决定让哪些辅助任务的样本可以进入到联合训练中,或者通过动态调整learning rate的手段,domain distance比较大的情况下,learning rate就小一点?
3、应用以及评测结果
3.1、业务数据集效果
该项目提出的几种模型结构目前主要应用于裁判文书的结构化信息抽取,基于裁判文书的结构化信息抽取,有助于文书的进一步精细化分析以及检索。针对毒品犯罪领域的裁判文书数据集NER-DRUG-AWARD,几种算法模型的实验数据如下:
- 单任务对比实验
| 模型 | 数据集 | F1 score |
|---|---|---|
| BERT+CRF | NER-DRUG-AWARD | 0.8678 |
| Segment-Based BERT+CRF | NER-DRUG-AWARD | 0.8879 |
| MRC-Based BERT+CRF | NER-DRUG-AWARD | 0.9099 |
| Segment-MRC-Based BERT+CRF | NER-DRUG-AWARD | 0.9142 |
结论:对比BERT+CRF的baseline方法
(1)字词信息的融合,F1值提升2.3%。
(2)将输入转成QA形式的输入,引入实体的先验信息,F1值提升4.9%。
(3)Segment方法跟MRC方法的同时引入,F1值可以提升5.3%。
- Multi-Task对比实验
| 模型 | 主任务 | 副任务 | F1 score |
|---|---|---|---|
| BERT+CRF | NER-DRUG-AWARD | —— | 0.8678 |
| Multi-Task Bert+CRF | NER-DRUG-AWARD | CWS-MSRA2005 | 0.8937 |
| MRC-Based Multi-Task Bert+CRF | NER-DRUG-AWARD | CWS-MSRA2005 | 0.9048 |
| Adversarial MRC-Based Multi-Task Bert+CRF | NER-DRUG-AWARD | CWS-MSRA2005 | 0.9188 |
结论:对比BERT+CRF的baseline方法
(1)NER任务跟CWS任务的联合训练,F1值提升3.0%。
(2)联合训练的过程中,引入实体的先验信息,F1值提升4.3%。
(3)联合训练的过程中,同时引入实体先验以及对抗机制,F1值提升5.9%。
- Cross-Domain对比实验
| 模型 | 主任务 | 副任务 | F1 score |
|---|---|---|---|
| BERT+CRF | NER-DRUG-AWARD | —— | 0.8678 |
| Multi-Task Bert+CRF | NER-DRUG-AWARD | NER-Weibo2018 | 0.9076 |
| MRC-Based Multi-Task Bert+CRF | NER-DRUG-AWARD | NER-Weibo2018 | 0.9103 |
| Adversarial MRC-Based Multi-Task Bert+CRF | NER-DRUG-AWARD | NER-Weibo2018; | 0.9123 |
结论:对比BERT+CRF的baseline方法
(1)引入新的source domain数据后,通过联合训练,F1值可以提升4.6%。
(2)在Cross-Domain联合训练的基础上,加入实体先验信息,F1值可以提升4.9%。
(3)在Cross-Domain联合训练的基础上,加入实体先验信息以及对抗机制,F1值可以提升5.1%。
3.2、公开数据集效果
为了验证本项目方法的普适性,也在公开数据集上面做了实验。
| 模型 | 主任务 | 副任务 | F1 score |
|---|---|---|---|
| BERT+CRF | NER-Weibo2015 | —— | 0.6447 |
| Segment-MRC-Based BERT+CRF | NER-Weibo2015 | —— | 0.7176 |
| Adversarial MRC-Based Multi-Task Bert+CRF | NER-Weibo2015 | CWS-PKU2005 | 0.7267 |
结论:对比BERT+CRF的baseline方法
(1)单任务模型引入Segment-Based跟MRC机制,F1值可以提升11.3%。
(2)NER任务跟CWS任务联合训练,F1值可以提升12.7%%。
总结
本项目提出的4种模型改进,相比baseline方法,不仅在业务数据集NER-DRUG-AWARD上F1值最高提升5.9%,在公开数据集NER-Weibo2015上F1值最高也可以提升12.7%。
参考文献
- 开源项目:transformer2.0
- 《Chinese NER Using Lattice LSTM》
- 《A Unified Model for Cross-Domain and Semi-Supervised Named Entity Recognition in Chinese Social Media》
- 《A Survey on Deep Learning for Named Entity Recognition》
- 《Multi-Task Deep Neural Networks for Natural Language Understanding》
- 《Character-Based LSTM-CRF with Radical-Level Features for Chinese Named Entity 》
- 《Neural Adaptation Layers for Cross-domain Named Entity Recognition》
- 《Neural Chinese Named Entity Recognition via CNN-LSTM-CRF and Joint Training with Word Segmentation》
- 《Adversarial Transfer Learning for Chinese Named Entity Recognition with Self-Attention Mechanism》
- 《A Unified MRC Framework for Named Entity Recognition》
