@zakexu
2021-04-14T08:54:25.000000Z
字数 17924
阅读 4629
推荐系统入门
推荐系统
首发时间:2020.10.10
作者:zakexu(个人主页)
目录
一、算法
(一)召回
召回模型有几个需要重点关注的:
- 如何评价召回的效果?
- 如何构造正负样本?
- 如何解决用户、物品冷启动问题?
- 如何解决长尾问题?
- 如何打压热门?
1、YouTube DNN
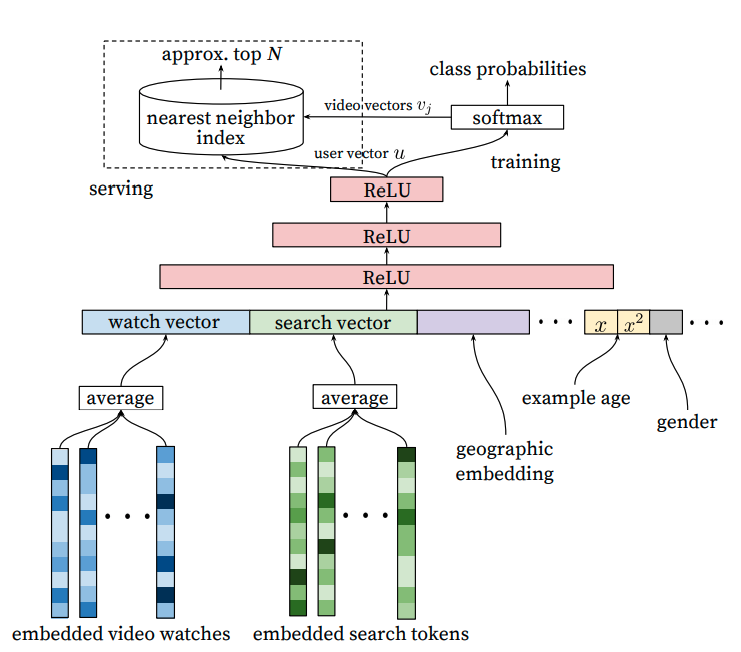
根据用户历史行为以及上下文信息,预测用户下一个观看的视频id(超大规模多分类问题)。
(1)样本:
- 虽然YouTube场景存在“用户点赞”等显式反馈,但为了避免样本稀疏,文中根据“观看时长”来选取正样本,负样本随机构造。
- 为了解决exploitation bias(避免越学越窄),会从其他场景补充正样本。
- 为了避免重度用户对loss的影响,对每个用户选择相同数量的样本。
(2)特征:user profile + user behavior + context。
- 用户人口统计学特征:用户性别、用户年龄等(解决用户冷启动问题)。
- 用户历史观看视频id序列:embeding + mean pooling。
- 用户历史搜索query列表:token切分 + embedding + mean pooling。
- 上下文特征:地理位置、用户设备、用户登陆状态等。
- 样本年龄(example age):一般训练时用来表示样本年龄,表示训练时间窗口的最大值,表示当前样本发生的时间,预测时则用0或者负值来表示样本年龄;主要是因为新内容在刚上传时会出现一个高点击率的尖峰,为了学习吸收这种bias,在训练时加入样本年龄特征。
注:只输入用户观看视频id序列特征,相当于fm模型(用户侧是用户观看视频id序列,物品侧是曝光视频id),只不过fm是分别对用户侧以及物品侧的item学习embedding,而在dnn中,可以参数共享,而且dnn只对UI做交叉,U内部或者I内部不做交叉。
注:文中并没有对全量的视频id做embedding,而是根据曝光点击选择topN个,其余的默认为0向量,一方面可以加速训练,一方面也可以避免长尾的无效学习(数据量少,训练会不充分,得到的embedding向量会导致过度泛化)。
注:对用户搜索query token做随机打乱,避免“taylor swift”现象(用户在搜索页刚搜完taylor swift的视频,下一刻立马在主页推相关的视频,不是很好的体验)。
(3)模型:“embedding + mlp” 范式。
- 输入层:既支持连续特征,也支持离散特征。
- 全连接层:3层MLP,激活函数用ReLU(“tower”范式,隐层单元数逐层减半)。
- 输出层:softmax层。
- 线上推理:最后一层MLP的输出作为user向量,softmax权重参数(可以跟item embedding做参数共享,原文没有做共享)作为item向量,通过向量内积做近邻搜索取topK;一般就是user向量通过线上计算(存在上下文特征),item向量离线计算完存储在faiss中。
(4)策略:nce loss或者neg loss。
(5)算法:梯度下降算法。
(6)评估:离线用准确率@K、召回率@K、MAP@K、ranking loss等,在线A/B。
注:对于召回的效果评估,离线一般要么肉眼看,要么就是看召回率@K等,比如说观测回流的样本中,看topK命中多少个正样本;但会有一个问题就是没有命中正样本的其他item,可能并没有曝光的机会,所以无法评估;在线的话就做分层正交的A/B看效果(召回路数并不多的前提下是ok的),但同样会有召回未曝光的问题。
2、Google DSSM
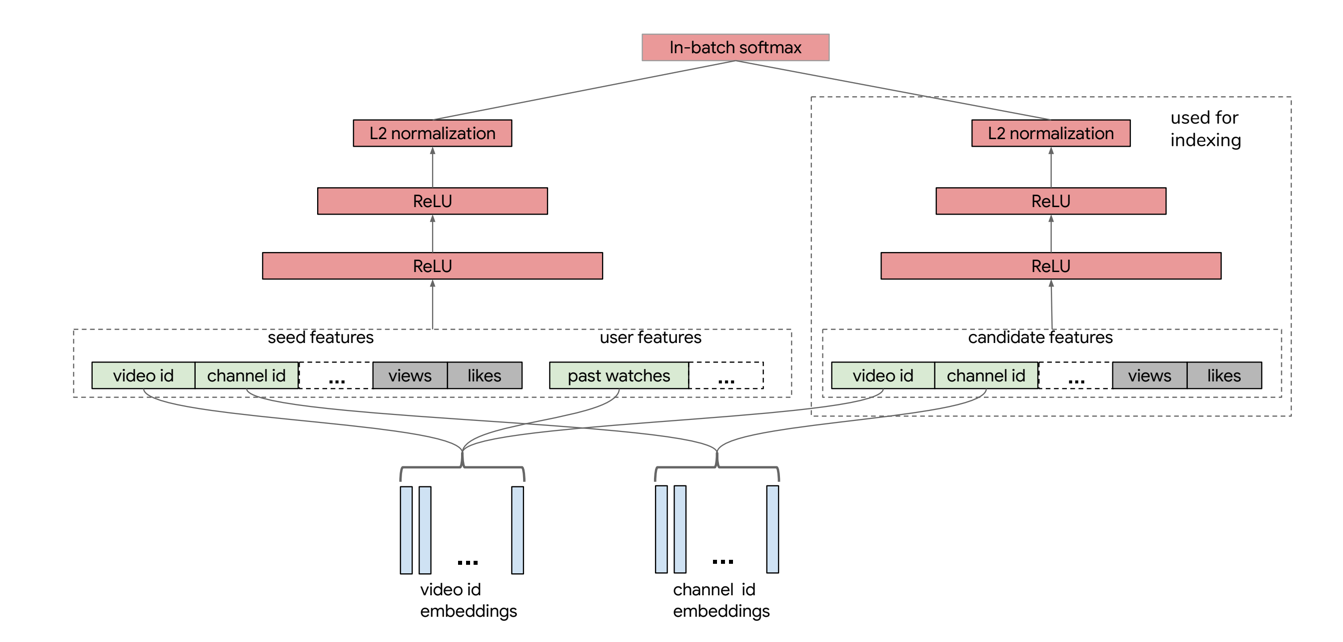
YouTube DNN召回存在一个明显的问题就是无法有效解决长尾内容以及内容冷启动的问题,而双塔结构中,左塔对用户以及上下文信息建模,右塔对视频建模,右塔可以输入更多的视频内容特征(比如视频所属类型等)从而解决泛化问题。其实YouTube DNN也可以看成双塔结构,右塔只有一层embedding,也就是只有id特征的输入。
采用YouTube DNN负采样(一般需要采较多负样本)的思路,无法有效解决双塔的训练问题,主要是因为右塔支持更多特征的输入以及参数共享机制,因此Google DSSM采用in batch softmax的思想来提升训练效果(只在batch内负采样而不是全量视频池子),但基于batch的负采样会有sample bias(全量物品池子采样的话,每个视频等概率被采,而在batch内采样,则更可能采到热门视频,毕竟batch内的视频都是正样本),需要修正,Google DSSM通过估算item频率来修正sample bias。
注:双塔结构只适用于召回场景,其对于UI的交叉学习不够充分,不太适合于精排场景。
(1)样本:假设一个batch的样本可以表示为,其中表示用户-物品正样本对(用户点击视频),表示该样本的权重(比如观看时长等),负样本就是基于batch中剩余的其他物品进行构造。
(2)特征:
- 左塔:user profile + user behavior + context(seed video表示当前正在观看的视频)。
- 右塔:item feature。
注:对于物品id采用hash bucket的方式,可以解决长尾训练不充分以及物品冷启动问题。
(3)模型:“embedding + mlp” 范式。
- 左塔(用户+上下文):输入层 + 3层MLP + L2。
- 右塔(物品):输入层 + 3层MLP + L2。
- 输出层:in-batch softmax。
(4)策略:一个batch的loss可以表示如下:
其中表示第个物品的采样频率:
注:通常会对跟做L2标准化(),也会对向量内积做缩放()。
(5)算法:梯度下降算法。
(6)评估:离线用Recall@K,在线看A/B效果。
3、Facebook EBR
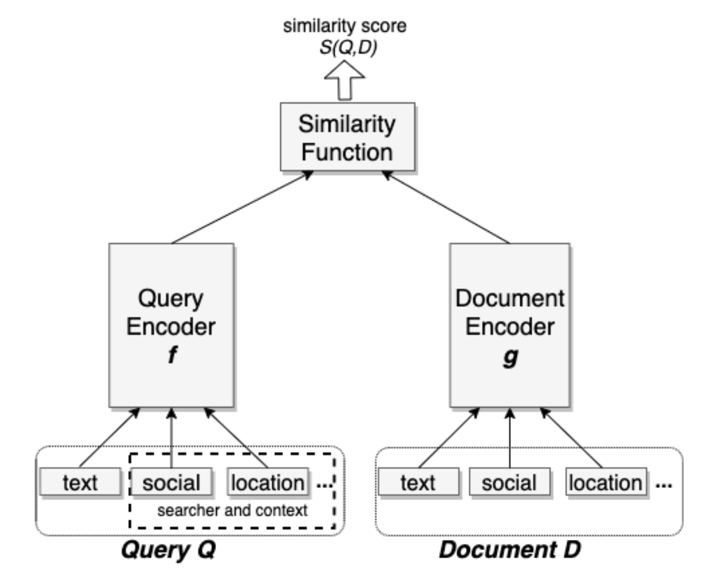
(1)样本:
- 正样本构造思路:
- 点击为正。
- 上一轮曝光为正。
- 负样本构造思路:
- 随机负采样。
- 曝光未点击。
注:点击为正跟上一轮曝光为正,在文中的实验,效果基本等价,两者叠加,效果并没有额外增益。
注:文中指出采用“曝光未点击”作为负样本,效果会很差,主要是因为这种属于hard negative(或多或少会跟query match),而实际召回时面对的大多是easy negative,因此训练测试数据分布不一致。
注:base版本就是以点击为正,随机采样为负。
注:hard negative mining:
- online hard negative:类似in-batch softmax,在每个batch中随机选取构造hard negative,只不过in-batch softmax是batch内剩下的都作为负样本,这儿一个正样本会选两个hard negative。
- offline hard negative:曝光未点击中,选取不那么hard的negative,大概就是rank在101-500的位置。
- 最终easy negative跟hard negative的比例是100:1。
注:hard positive mining:上述的easy positive都是基于请求成功并有用户反馈的数据,可以考虑的hard positive有召回成功但展示失败时所返回的样本。
注:构造样本时,需要对热门进行打压,一般就是构造正样本时,对热门做降权,构造负样本时,对热门做加权。
(2)特征:参考双塔结构。
(3)模型:参考双塔结构。
(4)策略:triplet loss可以表示如下:
其中表示向量距离,表示margin,是一个超参。
注:对于embedding based的召回模型,一般都用pairwise loss(主要是因为召回模型的样本构造带有随机噪声,所以用ctr的方式没法保序,用pair的方式更容易学到保序),常见的loss有bpr loss、nce/neg loss、in-batch softmax loss、triplet loss,其中都涉及负采样。
注:在精排中,通过预测ctr(pointwise)来做排序已经能够解决大多数场景的问题,但也可以通过直接优化排序(pairwise)的思路来做(在大多数场景,点击作为正样本,曝光未点击作为负样本,但其实点击是隐式反馈,未点击也不一定负,所以只能说明点击比不点击更“正”,比较适合用排序的思路来做),比如对于lr模型,通过构造(user、item+、item-)的样本,修改loss函数,原先pointwise的单样本(正样本)loss可以表示为:,修改后pairwise的单样本loss(也叫做Bayesian Personalized Ranking BPR loss)可以表示为(比更大,表示比更“正”):,两者的差别主要体现在训练阶段,推理阶段是一致的。除此之外,还有另外一种构造思路,原始lr的loss函数可以表示为:,输入的样本有正有负;而基于pairwise的loss可以表示为:,输入的样本只有正,但对每一个,都会随机构造若干个,这就相当于训练时,极端情况采用随机样本,每次梯度下降都会使得最小,也就是单样本的loss最小意味着比其余的更“正”,而在原始的loss函数中,单样本的loss就是,并没有排序的约束(每个样本要么就是正要么就是负)。
(5)算法:梯度下降算法。
(6)评估:离线用Recall@K,在线看A/B效果。
(二)精排
1、特征组合
1.1、LR、FM、XGBoost、XGBoost+FM
(1)lr模型是一种线性模型,可解释性强,实现简单;但是需要耗费大量的人力去做特征工程(比如构建交叉组合特征:用户下载过的app&曝光的app等)以提升非线性学习能力,通常也会通过构造一些比较粗粒度的特征交叉组合来提升泛化能力(比如用户下载过的app类型&曝光的app类型等)(过细粒度的组合特征容易过拟合,所以一般会通过正则来做稀疏约束),但是对于样本中没有出现过的组合特征,模型无法学习到对应的特征权重。
(2)fm模型适用于这种大规模稀疏离散特征,首先是fm自带二阶特征交叉,无需过多的特征工程;其次是通过特征embedding的方式,解决了稀疏特征权重的训练问题,对于样本中没有出现过的特征组合具有泛化能力(主要是利用共现传递性,ac共现,bc共现,那么ab应该有一定的相关性,也就是如果ad共现的话,可以泛化出bd共现);最后就是其具备线性的时间复杂度。
(3)虽然通过fm可以引入更高阶(三阶及以上)的特征组合,但计算较为复杂,而且二阶笛卡尔交叉可能存在无效交叉(user&user、item&item)。而xgboost模型通过对特征空间的多维切分,可以达到高阶特征组合的目的(对应树的一条路径,对于每棵树,样本落到的叶子节点置为1,其余叶子节点置为0;将所有树的向量拼接得到最终的特征向量)。但xgboost比较适合连续特征、低中维度稀疏向量特征,对于高维稀疏向量特征,一来学习效率低(树的深度有限),二来对于样本中没有出现的特征组合没有泛化能力。
(4)因此常采用xgboost+fm的方式来做模型组合。通常将一些连续值特征、值空间不大的比如类别特征都丢给xgboost模型,值空间很大的比如id特征等留在fm模型中训练,既能做高阶特征组合又可以利用处理大规模稀疏数据的优势。
1.2、Google Wide And Deep
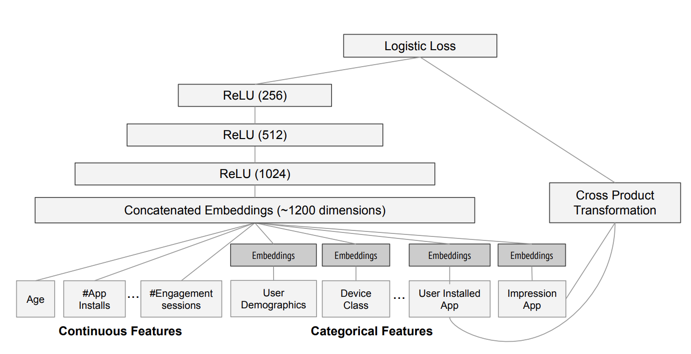
wide部分通过id特征的交叉(比如用户下载过的app&曝光的app等)提升模型的memorization,但对于样本中没有出现过的特征组合,wide没有泛化能力;deep部分通过embedding跟多层mlp提升模型的高阶特征组合能力以及generation,但对于长尾物品,由于训练数据不够,导致embeddig训练不足,从而造成过度泛化(wide部分的memorazation可以解决这个问题)。
(1)样本:下载为正,曝光未下载为负。
(2)特征:user profile + user behavior + context + item feature。
(3)模型:deep:“embedding + mlp” 范式;wide:lr。
(4)策略:ce loss。
(5)算法:使用带L1正则化项的FTRL作为wide部分的优化方法,而使用AdaGrad作为deep部分的优化方法。wide部分之所以会采用带L1正则化项的FTRL作为学习算法,主要是因为wide部分的输入特征是两个大规模id特征的交叉,在维度爆炸的同时,会让原本已经非常稀疏的multihot特征向量,变得更加稀疏。为了不把数量如此之巨的权重都搬到线上进行model serving,采用FTRL过滤掉那些稀疏特征无疑是非常好的工程经验。
(6)评估:离线看AUC、在线看A/B效果。
1.3、Huawei DeepFM
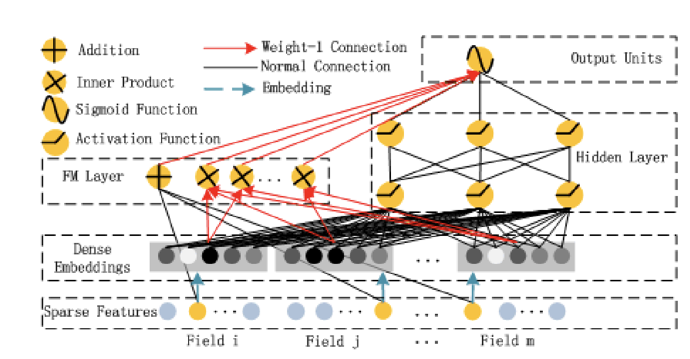
wide&deep的wide部分仍然需要人工特征,而deepfm是端到端的模型,无需人工特征,fm部分负责低阶显式特征的组合以及泛化,deep部分负责高阶隐式特征的组合以及泛化,同时deep跟fm部分共享embedding层,提高学习效率。
(1)样本:点击为正,曝光未点击为负。
(2)特征:user profile + user behavior + context + item feature。
- 离散特征:转成one-hot输入。
- 连续特征:连续值输入或者离散化后转成one-hot输入。
- 每个原始特征是一个field(也可以叫做group),。
(3)模型:deep:“embedding + mlp” 范式;wide:fm。
- 输入层:稀疏特征输入,一个field代表一个原始特征,并且都是one-hot形式。
- embedding层:fm跟deep共享。
- fm部分:一阶特征向量,有多少个filed就有多少维;二阶特征向量,维(embedding的维度)特征向量,可以参考fm中的推导,fm的输出就是将一阶向量跟二阶向量进行拼接。
- deep部分:将dense embedding按field做avg,然后进入全连接网络中。
- 输出层:将fm跟deep的输出向量拼接后进入lr做二分类。
注:deep部分,除了用mlp,常见的方案还包括cnn、rnn以及transformer,目前主流是mlp,cnn的话主要擅长局部序列的信息获取,对于远端的特征组合捕捉能力差,加上在推荐中,特征输入本身就是无序的;对于rnn也是如此,本身输入不存在序列关系,其次由于引入rnn,反而无法并行,效率慢;对于transformer而言,可能会是一个适合的方向,可以对特征做任意组合而且带入attention。
(4)策略:ce loss。
(5)算法:梯度下降算法。
(6)评估:离线看AUC跟logloss,在线看A/B效果。
2、用户侧-兴趣表达
2.1、Alibaba DIN
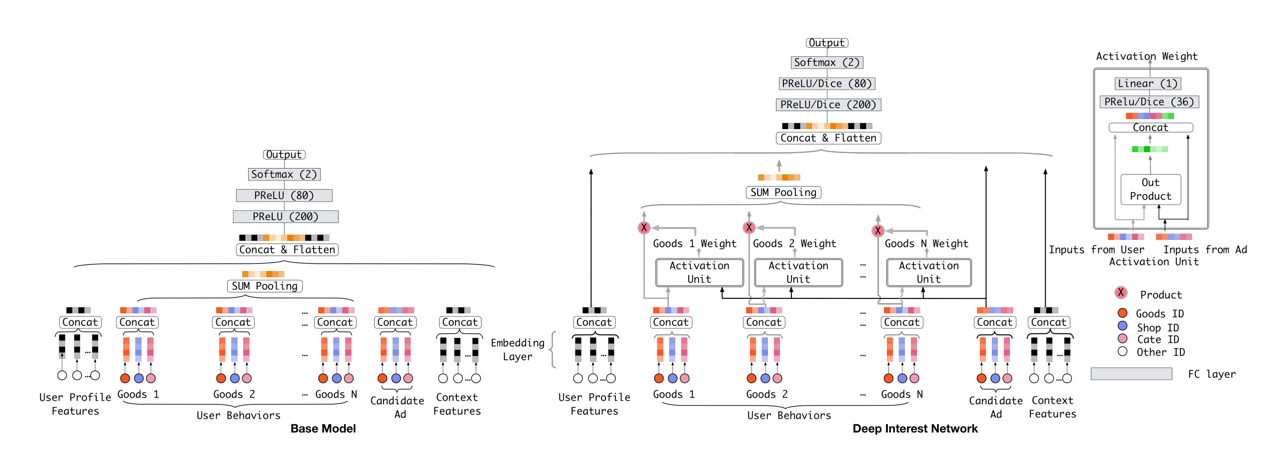
在embedding+mlp的模型范式下,通常会用用户行为序列来表示用户兴趣,一般的做法就是将对应的embedding向量做pooling,但这样做会有几个问题:一个是信息损失,即使加入时间衰减,也不够精细,另外一个就是一般用户兴趣是多峰的,针对不同的曝光,会激活不同的兴趣,简单的pooling无法体现该特点。
(1)样本:点击为正,曝光未点击为负。
(2)特征:user profile + user behavior + context + item feature。
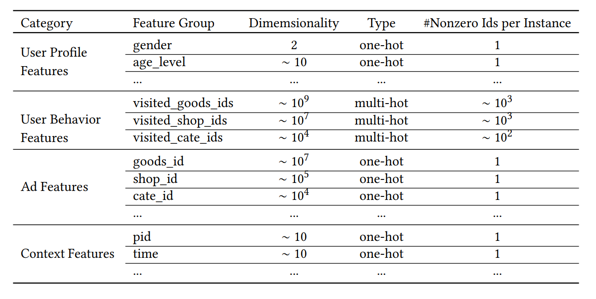
(3)模型:“embedding + mlp” 范式 + attention。
其中表示用户向量,表示候选item向量,表示历史行为item向量,表示attention score的计算,由图中可以看出,将、以及其外积拼接后进入mlp得到一个score,需要注意的是,这个score并没有进softmax做归一化,作者认为希望保留其原始的attention强度。
(4)策略:ce loss。
(5)算法:梯度下降算法。
(6)评估:离线看AUC、在线看A/B效果。
2.2、Alibaba DIEN
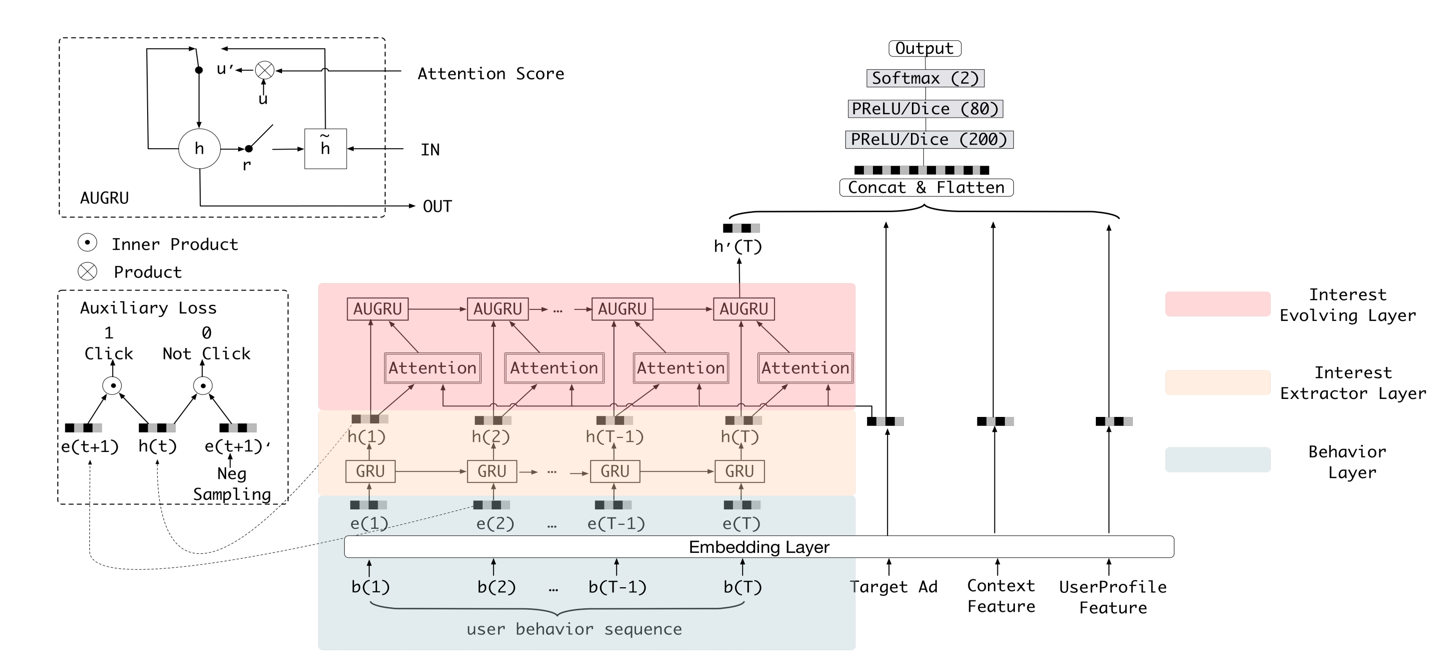
在din中,将用户的行为作为兴趣过于直接简单,而且随着序列变长,attention的作用也会变弱,除此之外,din并没有考虑序列关系。因此,dien在din的基础上,一方面加强了兴趣的精准提取,一方面对序列关系进行建模。
(1)样本:点击为正,曝光未点击为负。
(2)特征:user profile + user behavior + context + item feature。
(3)模型:“embedding + mlp” 范式 + interest extractor + interest evolving。
- interest extractor:使用gru来抽取用户每个时间点的兴趣表达,同时加入一个辅助rank loss来起到监督作用(其中表示负采样):
- interest evolving:使用augru来抽取用户兴趣的动态变化,augru对比gru就是基于attention替换更新门,这儿的attention score是基于向量内积以及softmax做归一化。
(4)策略:ce loss。
(5)算法:梯度下降算法。
(6)评估:离线看AUC、在线看A/B效果。
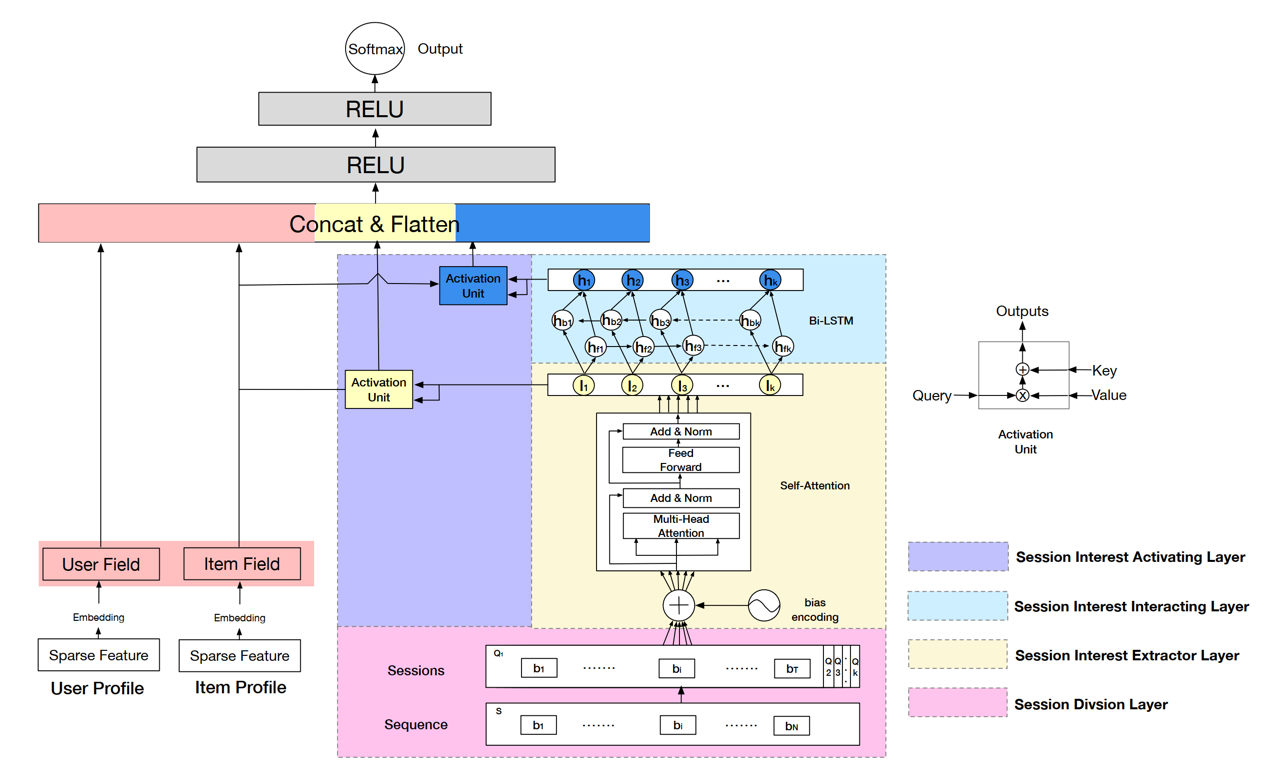
2.3、Alibaba DSIN
dsin引入了session的概念,同一个session内的行为高度同构,不同session间的行为异构。
(1)样本:点击为正,曝光未点击为负。
(2)特征:user profile + user behavior + context + item feature。
(3)模型:“embedding + mlp” 范式 + session interest extractor + session interest interacting + session interest activating。
- session interest extractor:采用transformer提取session内兴趣(类似dien中的interest extractor)。
- session interest interacting:采用双向lstm提取session间兴趣(类似dien中的interest evolving)。
- session interest activating:把前面两层的输出当做k、v,曝光物品embedding作为query,计算self-attention。
(4)策略:ce loss。
(5)算法:梯度下降算法。
(6)评估:离线看AUC、在线看A/B效果。
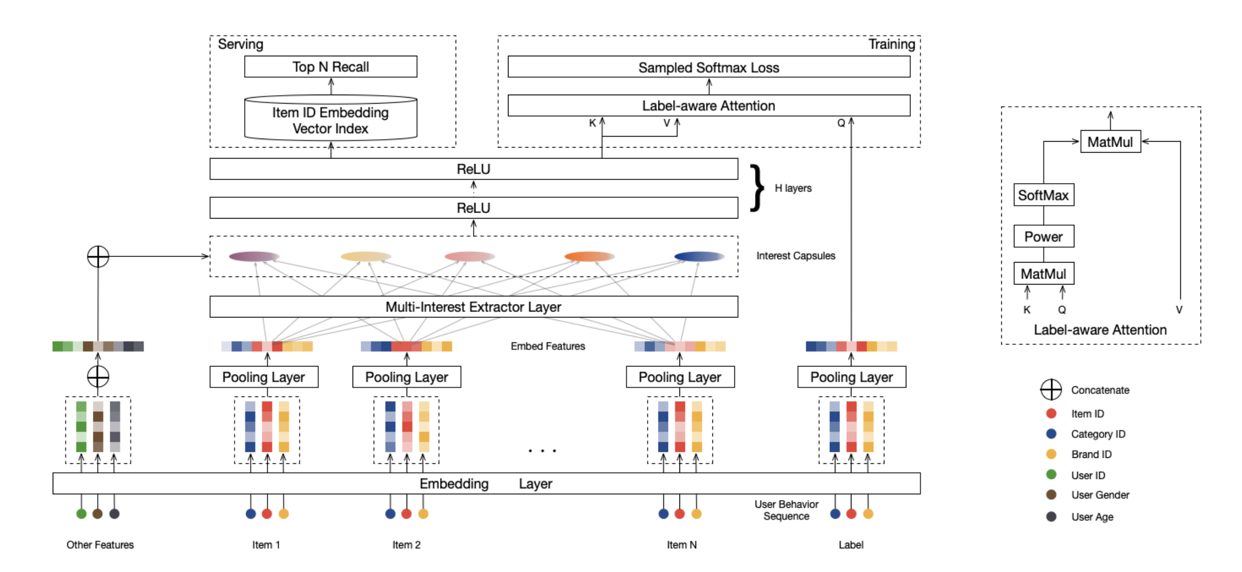
2.4、Alibaba MIND
din、dien、dsin都是基于attention机制来进行用户兴趣提取,更多适用于精排层。对于召回层,物品数量太多,不太适合用attention,那么能想到的一个insight就是将用户兴趣进行拆分,原先一个用户只用一个向量来表示兴趣,比较局限,可以拆成多个,那么可以同时召回不同兴趣下的物品。
(1)样本:参考双塔结构
(2)特征:参考双塔结构。
(3)模型:参考双塔结构。
- Multi-Interest Extractor Layer
胶囊网络是传统神经元的向量版本,传统神经元是多个标量进一个标量出,而胶囊网络是多个向量进一个向量出。假设前一层胶囊的向量组(item embedding向量)为:,后一层胶囊的向量组(user多峰兴趣向量)为:,也就是前一层有个胶囊,后一层有个胶囊,每个胶囊的向量维度假设为。那么一个胶囊的计算过程是:
其中是一个维的矩阵,在本文中,对于不同的共享一个权重参数,一方面是因为item数量太多,共享可以节省计算,一方面是为了将所有的向量映射到一个特征空间。
的计算是通过迭代计算的方式来获取,一开始随机初始化,通过算出,再更新,一般迭代2-3轮就可以收敛,这个过程叫做动态路由,有点类似k-means聚类的过程(跟越相似,对应的权重会越大,会越偏向)。
前一层胶囊代表用户的item向量,后一层胶囊代表用户的多峰兴趣,不同的用户兴趣数量不同:,其中表示最多个兴趣,表示用户的行为item数量。
- Label-aware Attention Layer
多个用户兴趣作为k,v,而右塔的输出item向量作为q,做attention。
(4)策略:nce loss或者neg loss。
(5)算法:梯度下降算法。
(6)评估:离线用召回率@K,在线A/B
3、物品侧-多模态融合
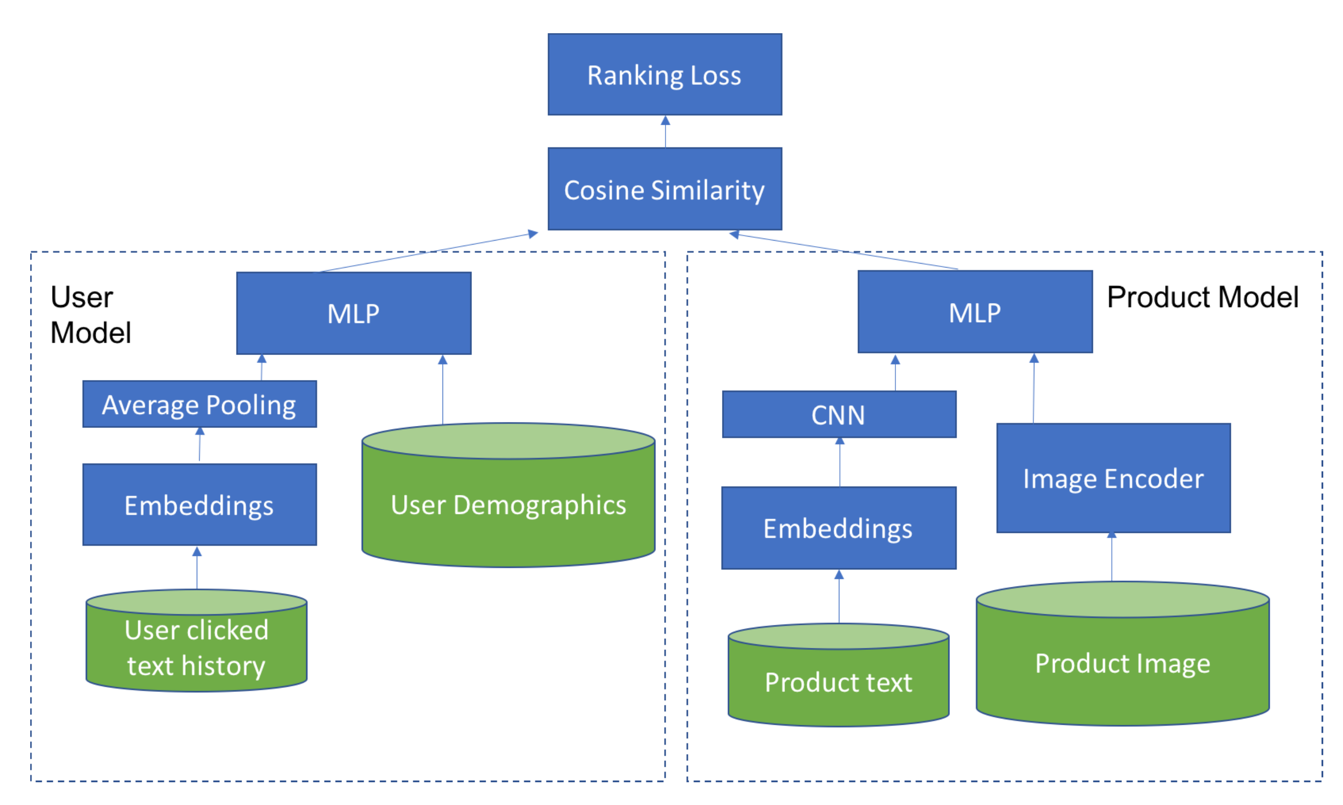
多模态机器学习(MultiModal Machine Learning)旨在融合推荐中的多源模态信息。在“embedding + mlp” 范式中,根据用户行为序列可以学到内容的embedding向量,但该向量的获取依赖于用户行为的积累,对于一些长尾item以及冷启动item,无法获得有效的embedding表示,而多模态内容理解是基于item的元数据来进行的,可以有效解决这个问题。
3.1、基于双塔的多模态融合
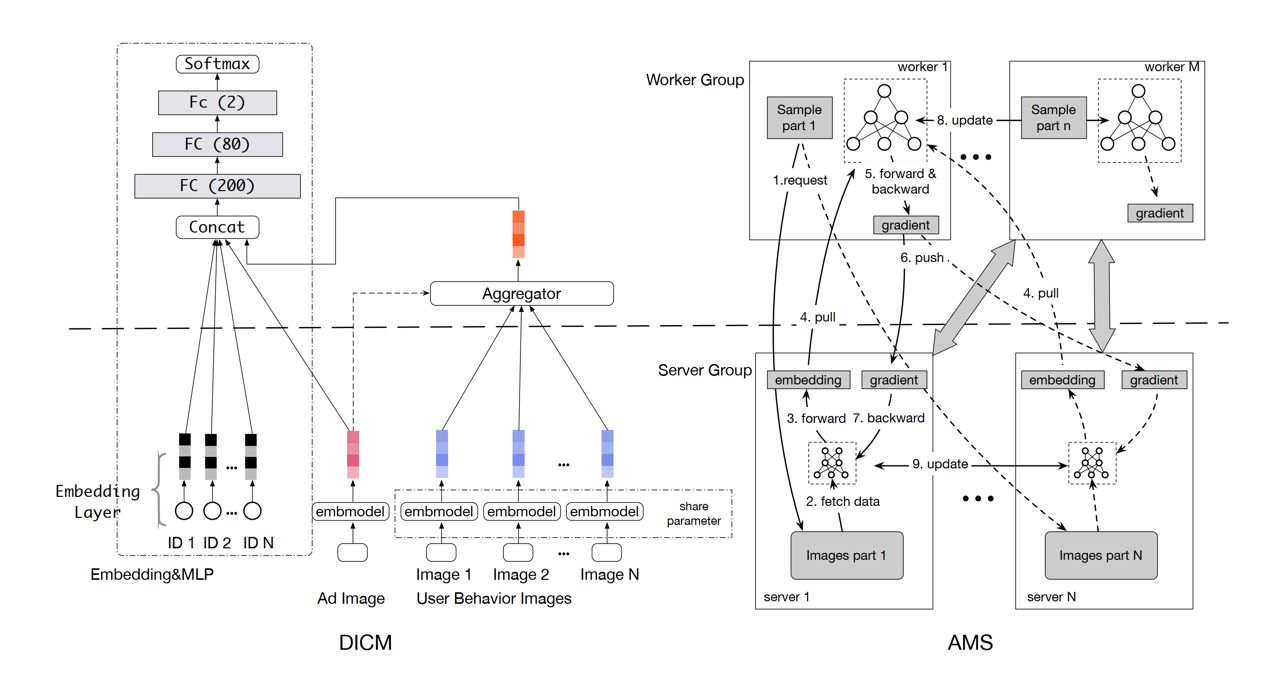
3.2、基于用户行为序列的多模态融合
3.3、基于度量学习的多模态融合
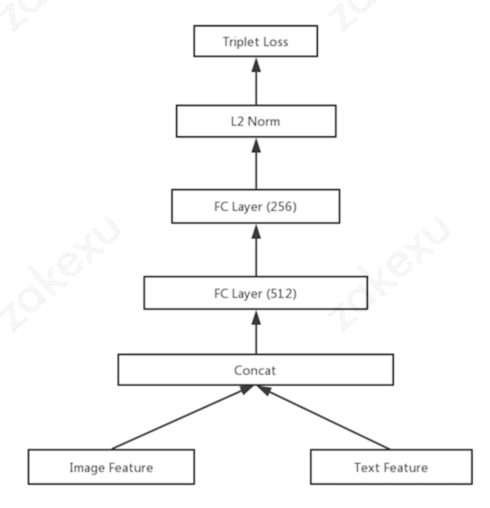
注:基于triplet loss,正样本基于itemCF的共现item来抽取,负样本随机采样。
4、多目标优化
对于多目标优化问题,一般会有几种做法:(1)通过对样本进行加权,比如点击权重为1,下载权重为2,其实就是将多目标折算成一个目标,没有额外的算法复杂度。(2)单独训练多个目标模型,比如ctr模型、cvr模型等,然后线上进行加权融合。(3)多任务联合训练,ctr、cvr联合训练。
在多任务联合训练中,经常会遇到的问题就是如何解决loss的权重,首先要看业务对该问题的定义,如果业务拍了权重,那么算法执行即可,如果业务对权重没有明确定义,那么就需要依靠数据来说话:
(1)通过线上A/B来调参。
(2)不确定性加权:在机器学习中,会面临“偶尔不确定性”,一种是数据标注或者产生过程中噪声所带来的,另外一种是所选取模型所带来的,这两种不确定性都会给任务带来预测偏差,这个偏差可以定义为,那么偏差越大的任务,也就是噪声越大,loss权重也应该越小,因此:
其中表示多任务的共享参数,起到正则作用,约束噪声取值不要太大。
(3)梯度标准化:控制多个任务之间训练的速度尽可能一致。假设多任务的loss可以表示为(权重是随着时间自适应变化的):
其中是通过训练得到的:
其中(是的平均数;越小,loss下降越快):
可以看出,对于loss ,如果子任务对于共享参数的梯度越大,会使loss 越大,对于目标loss 下降越快(也就是训练越快),也会使loss 越大,因此最小化loss ,可以让各个任务的训练速度保持一致,以及梯度量级也保持一致。
(4)动态加权平均:思路跟梯度标准化类似:
其中:
可以看出训练速度越快,loss权重越小。
(5)动态任务优先级:任务越难学,权重越大。
其中表示任务的学习难度,比如可以用准确率等来衡量。
(6)帕累托最优?
注:在多任务训练中,通常有两种输入格式,一种是,同一个输入,但是有不同的label,对应不同的tower;一种是,每一种pair对进入不同的tower,这一种一般都是随机轮流进入网络,每次只更新一个tower。
注:在多任务训练中,会经常面临不同的任务样本量级差别较大,可以对不同的任务采用不同的batch size,或者不同的学习率等,来保证学习速度一致。
4.1、Alibaba ESMM
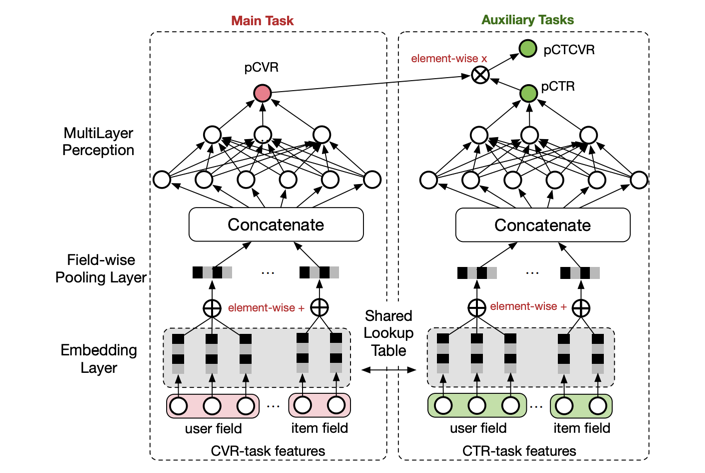
esmm的提出是为了解决cvr预估的样本选择偏差问题,传统的cvr模型,训练数据是基于曝光点击数据构造,而推理是基于全量曝光数据进行预测,存在训练测试数据分布不一致的情况。而通过ctcvr跟ctr的联合训练(多任务学习),可以缓解这个问题。首先是通过ctr * cvr的形式,利用了全量的样本数据,解决样本选择偏差问题,其次是结合ctr任务,更多地利用了标签数据,解决了样本稀疏问题。
(1)样本:,其中表示特征,表示是否点击,表示是否转化。其中ctr任务用的是全量样本数据,点击为正,ctcvr任务用的也是全量样本数据,转化为正。
(2)特征:user profile + user behavior + context + item feature。
(3)模型:“embedding + mlp” 范式 + task tower。
(4)策略:ce loss。
(5)算法:梯度下降算法。
(6)评估:离线看AUC、在线看A/B效果。
4.2、Google MMoE
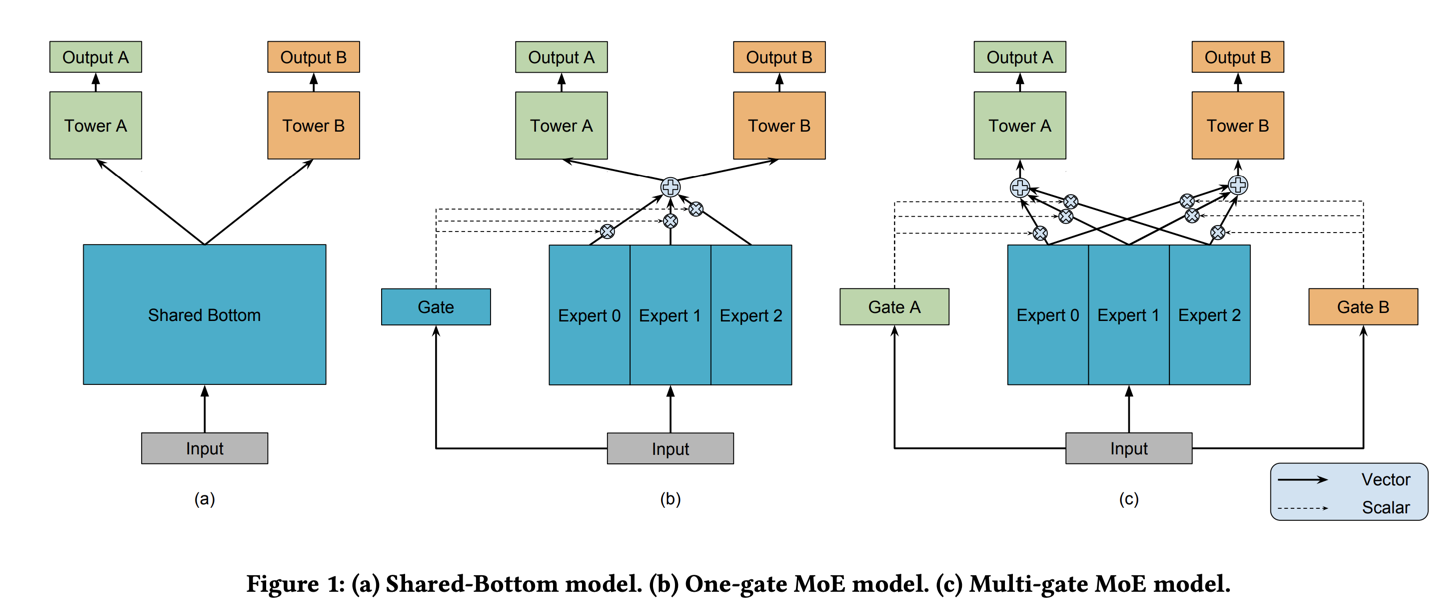
在多任务联合训练的过程中,每个task除了有shared的信息,通常也会有task privated的信息,因此需要对task privated的信息建模。通常会给各自的tower增加模型参数来试图建模,但这会带来训练困难问题,而mmoe则通过门机制的方式来建模task privated信息。
(1)样本:参考esmm。
(2)特征:参考esmm。
(3)模型:“embedding + mlp” 范式 + task tower。
其中表示第个expert,表示第个子任务tower,表示针对第个子任务第个expert的权重参数。
Expert0、Expert1、Expert2通常会是Shared Bottom的拆解,比如在esmm模型中,Shared Bottom会是一个embedding矩阵,维度为,那拆解成多个Expert的话,可以转化为,其。
(4)策略:参考esmm。
(5)算法:梯度下降算法。
(6)评估:离线看AUC、在线看A/B效果。
(三)重排
1、MAB
多臂老虎机(Multi-Armed Bandit problem, MAB)主要是用来解决E&E问题的,也就是利用(Exploit)与探索(Explore)的平衡;比如用户冷启动、新品试探、兴趣试探等问题。常见的有4种解决思路:朴素bandit策略、epsilon贪婪策略、汤普森采样(Thompson Sampling)、UCB(Upper Confidence Bound)策略。
(1)朴素bandit策略:其实就是热度算法;先随机推,然后得到每一个arm(物品)的回报(热度),最后根据回报(热度)高低来进行推荐;优点就是简单;缺点就是耗时较长,很难快速得到每个arm(物品)的回报(热度)。
注:适用于用户冷启动场景,按照热度推荐即可。
(2)epsilon贪婪策略:在0到1之间产生一个随机数,如果小于epsilon,则随机挑一个arm;如果大于epsilon,则选择当前回报最高的arm。
注:适用于新品试探或者兴趣试探场景,大于epsilon的时候则挑模型item,小于的话则随机挑试探item。
(3)汤普森采样:假设每个arm都符合beta分布(参数有跟);每次都是由每个arm产生一个随机数,看谁大就选谁(越大,产生大数的概率越高),有回报就(win)+1,没有回报就(lose)+1。
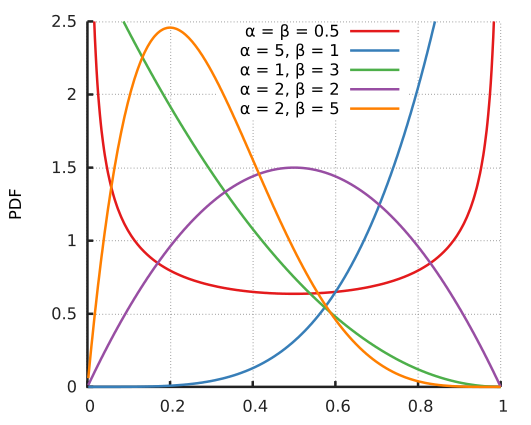
注:适用于用户冷启动场景。
(4)UCB
霍夫丁(hoeffding)不等式:
其中表示真实分布,表示预测分布,表示置信区间,表示实验次数,表示置信度,也就是说落在置信区间的置信度为。
- 假设置信区间为:,其中表示全部实验次数,表示第个arm的实验次数,那么置信度为:,可以看出总实验次数越多,置信度越大。
- 那么UCB对每个arm的得分可以表示为:
其中表示全部arm被选择的总次数,第一项表示第个arm的回报(比如ctr);第二项是兼容探索,也就是之前被选择次数少的arm,这一项得分越高。 - linUCB其实就是对上述第一项做延伸,加入特征的概念,比如用精排得分来表示。
注:适用于新品试探或者兴趣试探场景。
(四)推荐系统中的bias跟debias
1、常见的bias
1.1、选择性偏差 vs 一致性偏差
选择性偏差跟一致性偏差主要出现在显式反馈数据上(用户对物品喜好的打分比如电影评分等)。
- 选择性偏差:用户会倾向于对自己喜欢或者不喜欢的物品进行打分,因此所能获取样本并不是随机抽样,会存在部分样本分布上的缺失。
- 一致性偏差:用户对物品打分会倾向于跟随大部分人的意见,比如一部电影很受好评,用户大概率也会打高分。
1.2、曝光偏差 vs 位置偏差
曝光偏差跟位置偏差主要出现在隐式反馈数据上(用户对物品的点击、购买等)。
- 曝光偏差:曝光的物品只是全量物品的一个子集,并且不是能代表物品分布的子集,而是由模型打分筛选出来的,因此也叫“previous mode bias”。
- 位置偏差:用户倾向于对头部位置的物品有正反馈。
1.3、归纳偏差
通常会在模型中加入归纳偏差从而带来泛化能力。比如对于负样本,适当增加“hard negative”的比例。
1.4、流行度偏差 vs 不公平偏差
- 流行度偏差:热门商品的推荐频率超过了它们的受欢迎程度。可能会带来几个问题:(1)削弱个性化的作用;(2)长尾物品得不到有效曝光,热门不代表优质,长尾不代表低质;(3)马太效应,热门越来越热。
- 不公平偏差:不同人群数量不一致,比如种族、性别、年龄等,会带来数据歧视,比如在职位推荐场景,由于男女就业不平衡,女性更难被推荐高薪优质岗位。
二、系统
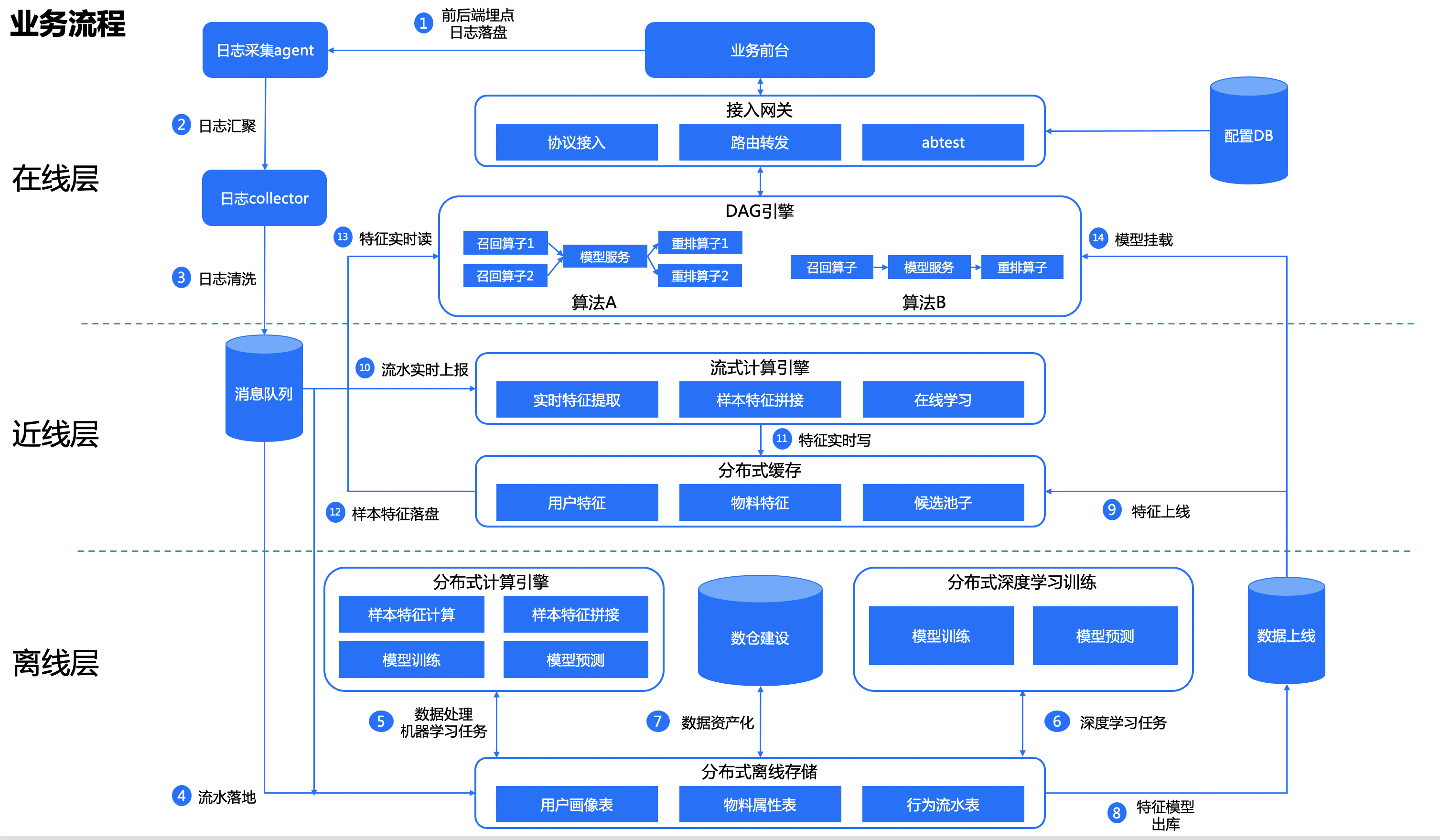
业界推荐系统都可以分为离线-近线-在线三段式的结构。系统之外还需考虑数据的接入问题。一般整体的数据链路是:业务前端日志埋点->业务后端日志接收(TCP/UDP消息、http请求等接入格式)->业务后端日志上报(前端埋点+后端埋点)(日志数据文件、数据库记录)->数据缓存(kafka等消息队列组件)。
注:这儿提供可参考的方案有filebeat+logstash+kafka。
(一)离线层offline
1、从组件的层面来看,一般会提供分布式存储引擎、分布式计算引擎、分布式训练引擎、任务调度引擎、数据上线。
(1)分布式存储引擎:通常采用HDFS;上报的流水(从kafka消费)会定期(按小时)落地到HDFS,然后入库到Hive表。
(2)分布式计算引擎:通常采用Spark+Hive;负责数据预处理、特征计算(主要是长期兴趣的计算)、样本抽取、离线样本特征拼接等,计算结果一般也是存于Hive表中,然后出库到HDFS上。
(3)分布式训练引擎:比如基于Spark的MapReduce、Parameter Server、Ring-Allreduce等,训练的模型结果通常也是出到HDFS上。目前主流深度学习框架tensorflow跟pytorch都有基于Spark、Parameter Server跟Ring-Allreduce实现的案例。
(4)任务调度引擎:通常采用洛子,主要用于周期任务的调度。
(5)数据上线:最后出库到HDFS上的特征、模型等数据,需要通过sqoop等工具同步到线上存储。
2、分布式训练
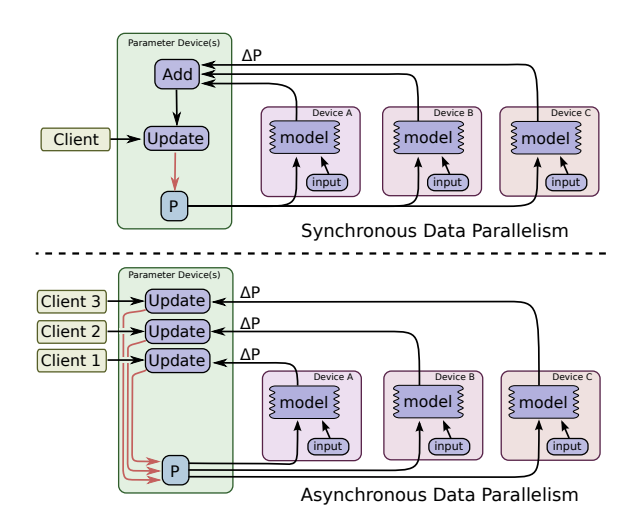
(1)数据并行 vs 模型并行
- 数据并行:不同的计算节点有同一个模型的多个副本,每个节点分配到不同的数据,然后将所有节点的计算结果按某种方式合并。合并的方式有两种,分别是同步、异步跟半同步。同步(BSP)的话就是每个节点会分配一个mini-batch的样本,等所有节点计算完之后,合并梯度取均值,然后更新一次参数(完成一个迭代),这样的话是完全模拟了真实的梯度下降,但是会有一个问题就是需要各个节点计算能力均衡不能有短板,不然训练速度会变慢。异步(ASP)的话就是每个节点计算完各自的梯度,便会更新一次参数,这样大大加快了训练速度;但是会带来梯度失效的问题,也就是当一个节点更新完参数之后,另外的节点虽然会同步得到新的参数,但是正在计算的梯度就没有意义,因为是基于更新前的模型参数来计算梯度的,梯度也就不是准确的梯度,可能会陷入局部最优。而半同步(SSP)的话就是结合两者,还是每个节点计算完各自的梯度,便会更新一次参数,但不是无限超前,会有一个阈值参数,约束最多超前多少次迭代,当为0时,其实就等同于同步,当为无穷大时,就等同于异步。
- 模型并行:分布式系统中的不同计算节点负责网络模型的不同部分,可以是不同的网络层分配给不同的计算节点,也可以是同一层内部的不同参数分配给不同的计算节点。由于每个模型内部参数依赖不一样,针对不同的模型都得设计不同的并行方案(数据并行本身其实也是存在内部依赖的,只不过数据并行是本次迭代依赖上一次迭代的全量参数,而模型并行是本次迭代内部的参数依赖),所以通常都是以数据并行为主。
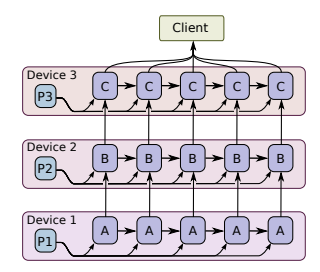
(2)MapReduce vs Parameter Server vs Ring-allreduce
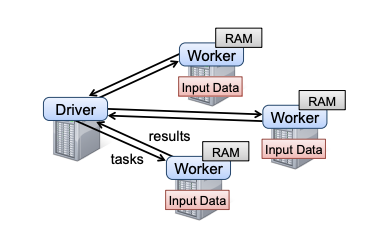
- 基于Spark的MR:Spark框架以driver为核心,任务调度和参数汇总都在driver;通常用于数据并行的情况较多,在中小规模训练场景较为常见;数据同步的方式采用BSP。其瓶颈在于driver,一般都是单点,因此当模型大到一个节点放不下之后,就无法正常训练了。
- 参数服务器PS:架构上可以分为server group跟worker group;前者存放参数分片,后者存放数据分片,其实有点相当于将Spark中的driver做了多机版。同步协议一般用SSP。参数服务器一般会有4种使用场景:第一就是参数可以单机存储并且单机更新,那么其实server group一个节点就够了,然后采用数据并行的方式,有点类似Spark的用法。第二就是参数不可单机存储,但可以单机更新(单样本的稀疏性通常远低于参数的稀疏性,一般样本的稀疏性在0.1%左右),处理方式跟第一种类似,只不过server group会有多个节点来存储参数切片。第三就是参数不可单机存储,也不可单机更新(稠密特征较多的情况下),但不使用模型并行,这种一般需要用到矩阵分块技术。第四就是参数不可单机存储,也不可单机更新,使用模型并行,除了考虑用矩阵分块技术,还需要在server group去维护参数间的依赖关系。
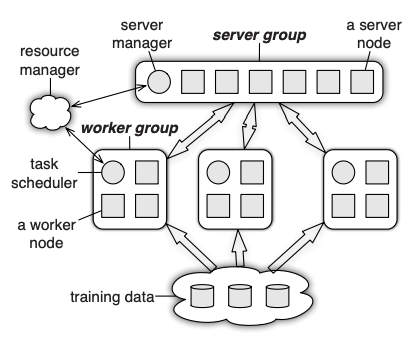
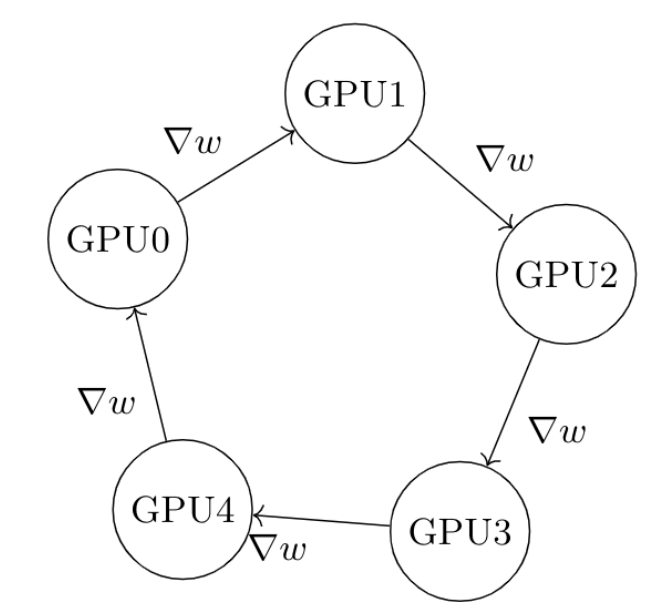
- Ring-Allreduce:PS架构中所有的worker计算节点都需要聚合给server group,这会造成一种通信瓶颈。而在Ring-Allreduce架构中,各个设备都是worker,并且形成一个环,没有中心节点来聚合所有worker计算的梯度。在一个迭代过程,每个worker完成自己的mini-batch训练,计算出梯度,并将梯度传递给环中的下一个worker,同时它也接收从上一个worker的梯度。对于一个包含N个worker的环,各个worker需要收到其它N-1个worker的梯度后就可以更新模型参数。
假设每个计算节点的带宽是,传输的数据量是,总共有个节点;对于PS来说(假设单节点存储模型参数),通信时间需要,通信时间随着节点数量线性增长,因此当worker增加时,确实会有带宽瓶颈。而对于Ring-Allreduce来说,假设可以将数据量切分为份,每次只传输一份,那么数据从节点0传输到节点的时候,需要的时间是,当远大于的时候,通信时间等价于,与计算节点不相关,因此当随意增加worker时候,不影响通信时间,可扩展性好。
(二)近线层nearline
1、分布式流式引擎:实时消费kafka的数据。
(1)实时计算引擎:业界常用的是Storm、Spark streaming、Flink。
(2)实时计算主要包括:实时特征计算(短期兴趣)、实时样本抽取、实时样本特征拼接、在线学习。
2、 分布式缓存系统:主要用于存储用户特征、item特征、推荐物料、模型数据等,通常用redis。
(三)在线层online
1、在线层涉及到的主要有几方面:
(1)接入层cgi,一般会做一些流量转发、规则配置等。
(2)实验系统,主要用于线上的abtest,根据用户id等获取对应的算法id。
(3)DAG计算框架,一般推荐引擎会包括召回(recall)-精排(rank)-重排(rerank)三层,每一层可以有多种策略比如多路召回等,那么整体流程其实就是一个DAG图。
(4)计算节点服务(可插拔),一般要包括模型服务、规则引擎、重排策略等。
(5)索引服务,一般会包括正排、倒排(根据标签召回等场景)、向量检索。
2、模型服务可以采用常见的深度学习框架,比如tensor flow serving或者TorchServe。
(四)常见的系统设计问题
1、lambda架构 vs kappa架构
(1)前者可以分为三层:batch layer、real-time layer、serving layer。
(2)后者可以分为两层:real-time layer、serving layer。
(3)后者实现了流批一体化,解决了lambda架构离线、近线各维护一套代码的问题。
2、线上线下一致性问题:
(1)特征抽取线上线下一致:目前业界做法是将特征工程等工具抽象成一个lib,然后线上线下共用一套代码逻辑。
(2)训练推理数据分布一致:一个是特征与特征之间,由于特征上线存在不同步问题,也就是可能同时存在8号的A特征以及9号的B特征;一个是模型与特征之间,通常来讲10号那天我们会选取9号的样本拼接8号的特征训练得到10号的模型,线上做预测时候理论上会用9号的特征,但由于特征上线不同步的问题,可能会读取到8号的特征,这就是模型与特征不一致问题。缓解上述问题的方法之一就是在近线层做样本特征拼接,这样子是可以把这些噪声考虑进来。
