@zhangyu756897669
2017-09-22T15:34:58.000000Z
字数 5060
阅读 914
下载来自Web的请求模块的文件
python官方文档
request模块允许您轻松地从Web下载文件,而无需担心网络错误,连接问题和数据压缩等复杂问题。请求模块不附带Python,因此您必须先安装它。如果您需要从Web下载东西,只需使用request模块。
接下来,做一个简单的测试,以确保请求模块本身正确安装。
import requests
如果没有显示错误消息,则请求模块已成功安装。
使用request.get()函数下载Web页面
requests.get()函数接收要下载的URL的字符串。通过在request.get()的返回值上调用type(),可以看到它返回一个Response对象,其中包含Web服务器为您的请求提供的响应。
import requestsres = requests.get('https://automatetheboringstuff.com/files/rj.txt')type(res)
requests.models.Response
res.status_code == requests.codes.ok #❶
True
len(res.text)
174130
print(res.text[:250])
The Project Gutenberg EBook of Romeo and Juliet, by William Shakespeare
This eBook is for the use of anyone anywhere at no cost and with
almost no restrictions whatsoever. You may copy it, give it away or
re-use it under the terms of the Project
该URL转到罗密欧与朱丽叶的整个游戏的文本网页。您可以通过检查Response对象的status_code属性来告知对此网页的请求成功。如果它等于requests.codes.ok的值,那么一切都很好❶。 (顺便说一下,HTTP协议中的“OK”状态代码是200.你可能已经熟悉了“未找到”的404状态代码。)
如果请求成功,下载的网页将作为一个字符串存储在Response对象的文本变量中。这个变量持有整个游戏的大字符串;对len(res.text)的调用显示,它的长度超过178,000个字符。最后,调用print(res.text [:250])只显示前250个字符。
检查错误
如你所见,Response对象有一个status_code属性,可以根据request.codes.ok进行检查,看看下载是否成功。检查成功的一个更简单的方法是在Response对象上调用raise_for_status()方法。如果下载文件时出错,将会引发异常,如果下载成功,将不会执行任何操作。
res = requests.get('http://inventwithpython.com/page_that_does_not_exist')
res.raise_for_status()
Traceback (most recent call last):
File "", line 1, in
res.raise_for_status()
File "C:\Python34\lib\site-packages\requests\models.py", line 773, in raise_for_status
raise HTTPError(http_error_msg, response=self)
requests.exceptions.HTTPError: 404 Client Error: Not Found
raise_for_status()方法是确保如果发生不良下载时程序停止的好方法。这是一件好事:一旦出现意外的错误,您希望程序停止。如果失败的下载不是您的程序的交易破坏者,则可以使用try和except语句来包装raise_for_status()行,以处理此错误情况而不会崩溃。
import requestsres = requests.get('http://inventwithpython.com/page_that_does_not_exist')try:res.raise_for_status()except Exception as exc:print('There was a problem: %s' % (exc))
There was a problem: 404 Client Error: Not Found for url: http://inventwithpython.com/page_that_does_not_exist
此raise_for_status()方法调用导致程序输出以下内容:
There was a problem: 404 Client Error: Not Found
调用request.get()后,始终调用raise_for_status()。您希望在程序继续之前确保下载实际工作。
将下载的文件保存到硬盘驱动器
从这里,您可以使用标准的open()函数和write()方法将网页保存到硬盘驱动器上的文件中。但有一些微小的差异。首先,必须通过将字符串'wb'作为第二个参数传递给open()来以写入二进制模式打开文件。即使该页面是纯文本(例如您之前下载的罗密欧与朱丽叶文本),您需要编写二进制数据而不是文本数据,以便维护文本的Unicode编码。
Unicode编码
Unicode编码超出了本书的范围,但您可以从这些网页了解更多信息:
Joel on Software:每个软件开发人员绝对必须了解Unicode和字符集(No Excuses!):
http://www.joelonsoftware.com/articles/Unicode.html务实的Unicode: http://nedbatchelder.com/text/unipain.html
要将网页写入文件,可以使用带有Response对象的iter_content()方法的for循环。
import requestsres = requests.get('https://automatetheboringstuff.com/files/rj.txt')res.raise_for_status()playFile = open('RomeoAndJuliet.txt', 'wb')for chunk in res.iter_content(100000):playFile.write(chunk)
playFile.close()
iter_content()方法通过循环在每次迭代中返回内容的“块”。每个块都是字节数据类型,您可以指定每个块将包含多少个字节。十万个字节通常是一个很好的大小,所以通过100000作为参数到iter_content()。
文件RomeoAndJuliet.txt现在将存在于当前工作目录中。请注意,虽然网站上的文件名是rj.txt,但硬盘驱动器上的文件具有不同的文件名。请求模块简单地处理下载网页的内容。页面下载完成后,它只是程序中的数据。即使您在下载网页后失去了互联网连接,所有的页面数据仍然在您的计算机上。
write()方法返回写入文件的字节数。在前面的例子中,第一个块中有100,000个字节,文件的剩余部分只有78,981个字节。
要查看,以下是完整的下载和保存文件的过程:
- 调用request.get()来下载文件。
- 用'wb'调用open()以写入二进制模式创建一个新文件。
- 循环响应对象的iter_content()方法。
- 在每次迭代时调用write()将内容写入文件。
- 调用close()关闭文件。
您可以从http://requests.readthedocs.org/中了解请求模块的其他功能。
HTML
在下载网页之前,您将学习一些HTML基础知识。您还将看到如何访问您的Web浏览器的强大的开发人员工具,这将使从Web轻松获取信息。
HTML的学习资源
超文本标记语言(HTML)是网页编写的格式。本章假设您有一些HTML的基础经验,但如果您需要初学者教程,我建议以下网站之一:
- http://htmldog.com/guides/html/beginner/
- http://www.codecademy.com/tracks/web/
- https://developer.mozilla.org/en-US/learn/html/
快速复习
如果您已经看过任何HTML,这是一个简短的概述。 HTML文件是带.html文件扩展名的纯文本文件。这些文件中的文本被标记包围,这些标签是用尖括号括起来的单词。标签告诉浏览器如何格式化网页。起始标签和结束标签可以包含一些文本形成一个元素。文本(或内部HTML)是起始和结束标签之间的内容。例如,以下HTML将显示Hello world!在浏览器中,以粗体显示:
<strong>Hello</strong> world!
Hello world
<strong>标签的意思是,所附文本将以粗体显示。</strong>标签告诉浏览器粗体文本结束
HTML中有许多不同的标签。这些标签中的某些标签具有在尖括号内的属性形式的额外属性。 tag encloses text that should be a link." onmouseover="this.style.backgroundColor='#ebeff9'" onmouseout="this.style.backgroundColor='#fff'">例如,标签包含应该是链接的文本。文本链接到的URL由href属性确定。这里有一个例子:
HTML中有许多不同的标签。这些标签中的某些标签具有在尖括号内的属性形式的额外属性。 例如, <a> 标签包含应该是链接的文本。 链接到的URL是由href属性决定的 这里有一个例子:
( )
Al's free <a href="http://inventwithpython.com">Python books</a>.
Al's free Python books
某些元素具有id属性,用于唯一标识页面中的元素。您将经常指示您的程序通过其id属性来查找元素,因此使用浏览器的开发人员工具找出元素的id属性是编写Web抓取程序的常见任务。
查看网页的源代码
您将需要查看您的程序将使用的网页的HTML源代码。为此,请右键单击(或在操作系统X上单击)Web浏览器中的任何网页,然后选择“查看源”或“查看”页面来查看页面的HTML文本(参见图)。这是您的浏览器实际收到的文字。浏览器知道如何从此HTML中显示或呈现网页。

我强烈建议您查看一些您最喜欢的网站的源HTML。如果您不完全了解您在查看源代码时看到的内容,那很好。您不需要HTML掌握来编写简单的Web抓取程序,毕竟您不会自己编写自己的网站。您只需要足够的知识从现有网站中挑选数据。
打开浏览器的开发工具
除了查看网页的源之外,您还可以使用浏览器的开发人员工具查看页面的HTML。在Chrome和Internet Explorer for Windows中,开发人员工具已经安装,您可以按F12使其出现(参见图)。再次按F12会使开发人员工具消失。在Chrome中,您还可以通过选择“查看▸开发人员▸开发人员工具”来开启开发人员工具。在OS X中,按“OPTION-I”将打开Chrome的开发工具。
在Firefox中,您可以通过在Windows和Linux上按CTRL-SHIFT-C或者在OS X上按⌘-OPTION-C来启动Web Developer Tools检查器。布局与Chrome的开发人员工具几乎相同。
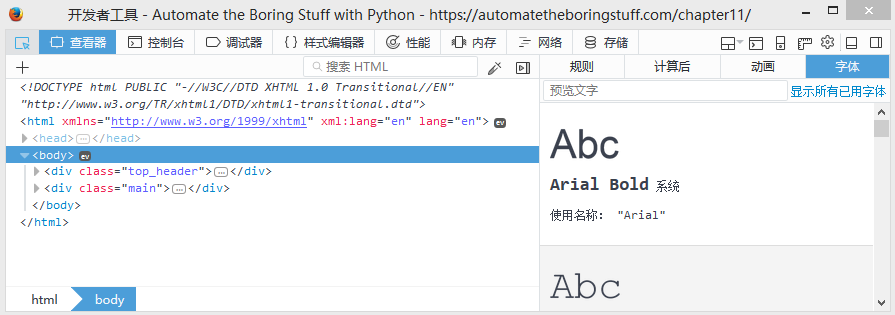
在浏览器中启用或安装开发人员工具后,您可以右键单击网页的任何部分,然后从上下文菜单中选择“检查元素”,以调出该页面的该部分的HTML。当您开始解析您的网页抓取程序的HTML时,这将非常有用。
不要使用正则表达式来解析HTML
在字符串中查找特定的HTML片段似乎是正则表达式的完美情况。不过,我建议你不要这么做。 HTML有许多不同的方式被格式化,仍然被认为是有效的HTML,但尝试捕获正则表达式中的所有这些可能的变体可能是乏味且容易出错的。专门用于解析HTML的模块,如 Beautiful Soup,将不太可能导致错误。
您可以找到一个扩展参数,为什么不应该使用正则表达式来解析HTML http://stackoverflow.com/a/1732454/1893164/.
