@zhangyu756897669
2017-09-23T15:42:39.000000Z
字数 2723
阅读 874
使用开发工具查找HTML元素
python官方文档
一旦您的程序使用请求模块下载了一个网页,您将页面的HTML内容作为单个字符串值。现在你需要弄清楚哪一部分的HTML对应于您感兴趣的网页上的信息。
这是浏览器开发人员工具可以帮助的地方。假设您想编写一个程序来从http://weather.gov/中提取天气预报数据。在编写任何代码之前,请做一点研究。如果您访问该网站并搜索94105邮政编码,该网站将带您浏览显示该地区预测的页面。
如果您有兴趣收集该邮政编码的温度信息怎么办?右键单击页面上的位置,然后从出现的上下文菜单中选择“检查元素”。这将显示“开发人员工具”窗口,该窗口显示生成该网页特定部分的HTML。图11-5显示了打开HTML温度的开发工具。
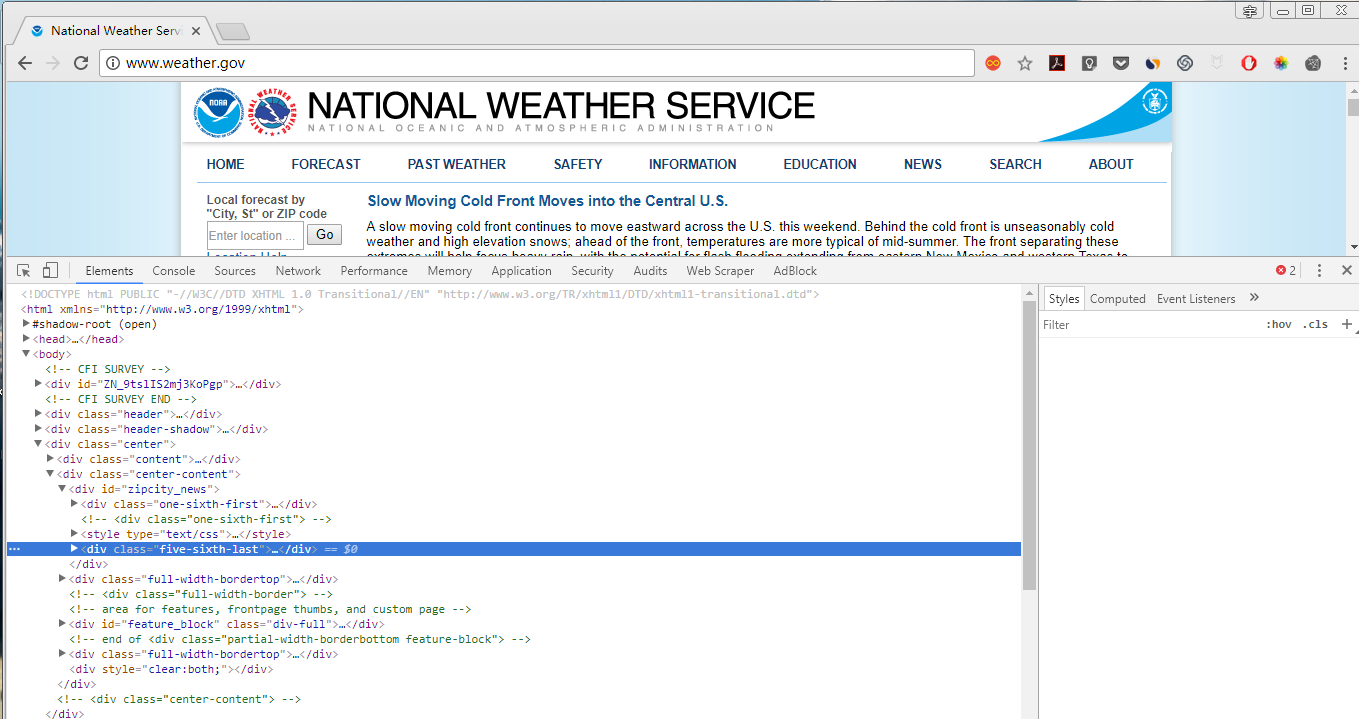
从开发人员工具,您可以看到HTML负责网页的温度部分 :<p class="myforecast-current -lrg">59°F</p>. 这正是你要找的温度信息。
似乎温度信息包含在一个 <p> 元素与 myforecast-current-lrg 类.现在你知道你在找什么,BeautifulSoup 模块将帮助您在字符串中找到它。
使用BeautifulSoup模块解析HTML
BeautifulSoup是用于从HTML页面提取信息的模块(并且比正则表达式更好地为此目的)。 BeautifulSoup模块的名称是bs4(对于Beautiful Soup,版本4)。要安装它,您需要从命令行运行pip install beautifulsoup4。
对于本章,“BeautifulSoup”示例将在硬盘驱动器上解析(即分析和识别HTML文件的部分)。在IDLE中打开一个新的文件编辑器窗口,输入以下内容,并保存为example.html。或者,从http://nostarch.com/automatestuff/下载。
<!-- This is the example.html example file. --><html><head><title>The Website Title</title></head><body><p>Download my <strong>Python</strong> book from <a href="http://inventwithpython.com">my website</a>.</p><p class="slogan">Learn Python the easy way!</p><p>By <span id="author">Al Sweigart</span></p></body></html>
正如你所看到的,即使一个简单的HTML文件涉及许多不同的标签和属性,事情很快就会与复杂的网站混淆。幸运的是,BeautifulSoup使得使用HTML更容易。
从HTML创建一个BeautifulSoup对象
bs4.BeautifulSoup()函数需要使用包含HTML进行解析的字符串进行调用。 bs4.BeautifulSoup()函数返回的是一个BeautifulSoup对象。
import requests, bs4res = requests.get('http://nostarch.com')res.raise_for_status()noStarchSoup = bs4.BeautifulSoup(res.text)type(noStarchSoup)
bs4.BeautifulSoup
该代码使用requests.get()从No Starch Press网站下载主页面,然后将响应的文本属性传递给bs4.BeautifulSoup()。它返回的BeautifulSoup对象存储在名为noStarchSoup的变量中。
您还可以通过将File对象传递到bs4.BeautifulSoup()来从硬盘驱动器加载HTML文件。确保example.html文件位于工作目录中
exampleFile = open('example.html')exampleSoup = bs4.BeautifulSoup(exampleFile)type(exampleSoup)
bs4.BeautifulSoup
一旦你有一个BeautifulSoup对象,你可以使用它的方法来定位HTML文档的特定部分。
使用select()方法查找元素
您可以通过调用select()方法并为要查找的元素传递一个CSS选择器的字符串,从BeautifulSoup对象中检索一个网页元素。选择器就像正则表达式:它们指定要在HTML页面中寻找的模式,而不是一般的文本字符串。
CSS选择器语法的全面讨论超出了本书的范围(在http://nostarch.com/automatestuff/上的资源中有一个很好的选择器教程),但是这里简要介绍了选择器。表11-2显示了最常见的CSS选择器模式的示例。
| 选择器传递给select()方法 | 匹配 |
|---|---|
| soup.select('div') | 所有元素命名<div> |
| soup.select('#author') | 具有作者id属性的元素 |
| soup.select('.notice') | 使用CSS类属性的所有元素命名通知 |
| soup.select('div span') | 所有元素命名 <span> 它们在一个名为的元素内 <div> |
| soup.select('div > span') | 所有元素命名<span> 它们直接在一个名为的元素内 <div>, 之间没有其他元素 |
| soup.select('input[name]') | 所有元素命名 <input> 具有任何值的name属性 |
| soup.select('input[type="button"]') | 所有元素命名<input> 有一个属性命名 type button |
可以组合各种选择器图案以进行复杂的匹配。 例如, soup.select('p #author') 将 匹配 author元素 的id 属性,只要它也在里面 <p> 元件。
select()方法将返回一个Tag对象的列表,这就是Beautiful Soup如何表示一个HTML元素。该列表将为BeautifulSoup对象的HTML中的每个匹配包含一个Tag对象。标签值可以传递给str()函数来显示它们所代表的HTML标签。标签值还有一个attrs属性,它将标签的所有HTML属性显示为字典
import bs4exampleFile = open('example.html')exampleSoup = bs4.BeautifulSoup(exampleFile.read())elems = exampleSoup.select('#author')type(elems)
list
len(elems)
0
