@zzy0471
2018-08-04T23:36:41.000000Z
字数 2201
阅读 1679
机器学习-评估方法与性能度量
机器学习
学习模型的泛化能力需要进行评估,现将主要的评估方法和性能度量总结如下
评估方法
留出法(hold-out)
将数据集D划分为互斥的两部分,一个作为训练集S,另一个作为测试集T,其中T的规模大约为D的1/5到1/3。该法的优点在于足够明了,缺点在于若令S较大,T较小,则使用T进行测试的结果可能不够准确;如果令T较大,S和D的规模会相差较大,用S训练得出的模型可能和用D训练得出的模型差别较大。一般的,往往不会单次使用留出法,而是多次随机划分S和T,将多次评估结果的平均值作为最终的评估结果。另外,为保证T和D的分布一致,可能需要分层采样。
交叉验证法(cross validation)
将数据集D划分为大小相似的k个互斥子集,然后进行k(通常取5、10,20)次评估,每次评估时,使用子集作为测试集,剩余k-1个子集作为训练集,最终的评估结果为k次评估的平均值。通常该验证法会随机划分多次子集,最终结果取其平均值。交叉验证法相比留出法的优点是:能够保证所有样本都参与了训练和测试。
自助法(bootstrapping)
对具有m个样本的数据集D进行有放回随机抽取m次,得到一个新的数据集,将用作训练集,D\ (D中没有被抽到中的样本组成的集合)用作测试集。该法的优点在于避免留出法和交叉验证法由于训练集S和样本集D规模不同引发的偏差。显然,和D的分布情况不同,会导致偏差,通常数据集较小时使该法有用,数据量足够多时,留出法和交叉验证法更为常用。
评估度量指标
用于回归问题的度量方法有:
- 均方误差:
用于分类问题的度量方法有:
- 错误率:
- 准确率:
二分类问题的度量方法
用如下符号表示测试结果(课程中和书籍中的TNFP表示方式太绕,此处使用很好理解的“正负”的表示方式):
- 正正:正例被判断为正例
- 正负:正例被判断为负例
- 负正:负例被判断为正例
- 负负:负例被判断为负例
准确率为:,查全率为:,准确率表示的是预测为正例中真正正例的比例,查全率表示的是所有正例中被预测为正例的比例。准确率和查全率此消彼长,在实际应用中衡量取舍,如电商推荐类似产品看中准确率,找出谁是犯罪分子更看中查全率。通常用F1(准确率和查全率的调和平均数)度量综合准确率和查全率:
可加入参数调整准确率和查全率的权重:
当大于1时查全率有更大影响,当小于1时,准确率有更大影响。
ROC和AUC
在二分类问题中,除了准确率和查全率,还可以使用TPR(True Positive Rate)和FPR(False Positive Rate)度量。其中:
即:TPR表示所有正例被正确预测为正例的比例(也就是查全率),FPR表示负例被错误的预测为正例的比例。不同于精确率和查全率,精确率和查全率此消彼长,如果想把尽可能多的甜西瓜挑出来(提高查全率),就不免会出现把更多的生瓜当甜瓜的情况(精确率下降),而TPR和FPR并不是此消彼长,而是同向变化。
该概念常应用于医学检测,假设某种疾病的判断标准为:如果检查结果大于某阈值,则认为患病,否则为不患病,TPR表示确诊率,FPR表示误诊率,当医生下结论非常谨慎时,TRP较高,同时也把更多的非患病者诊断为了患病者,即FPR也高了。将测试样本排序,最可能是正例的样本放到首位,最不可能是正例的样本放到末位,初始阈值设为最大,即所有的样本均预测为反例,此时TPR和FPR都是0,逐步降低阈值会得到多组TPR和FPR,当阈值降到最低,即所有的样本都被预测为正例,此时TPR和FPR都是1,以TPR为纵轴、FPR为横轴绘制的曲线叫做ROC(Receiver Operation Characteristic),大致如下图(实际情况中,由于阈值个数有限,曲线不会如下图这般平滑)所示:
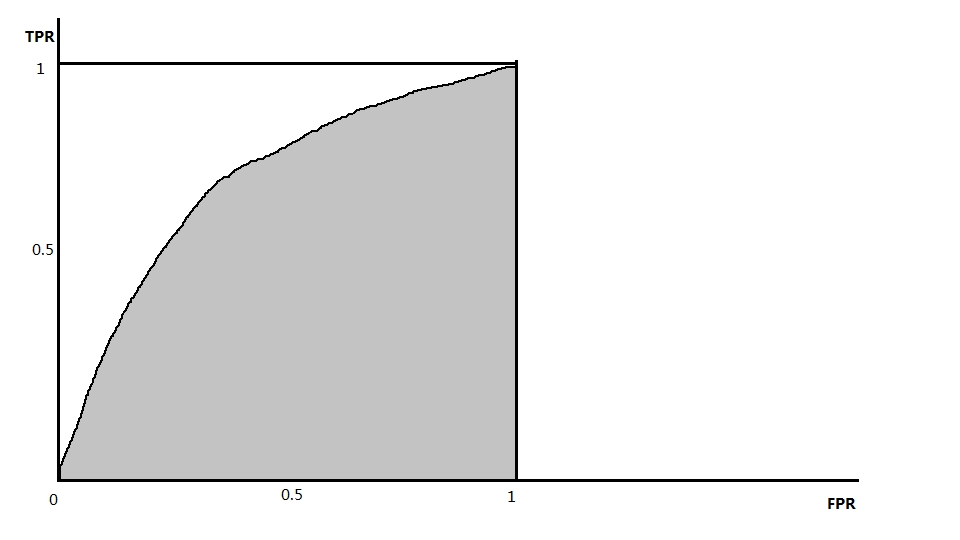
可见,给定一组坐标,TPR较高而FPR较低为是更为理想的结果,可以用ROC曲线下方面积来度量,容易知道:面积越大,结果越是理想,该面积被称为AUC(Area Under ROC Curve)
参考:
《机器学习工程师》网易云课堂出品
《机器学习》 周志华著
ROC曲线与AUC值
