@77qingliu
2018-05-13T15:26:13.000000Z
字数 6446
阅读 1479
数据准备
信用评分
这里主要回顾信用风险评分中一些常用的数据准备过程。
原则上,数据准备重点关注的是:
- 从不同渠道收集和整合建立评分卡所需的数据
- 清理数据中所有的意外错误或被认为是极端值的取值
- 生成另外的候选因变量,期望他们可以帮助提高模型的预测力
另外,有三项数据准备任务对于评分卡开发是十分关键的,并且也是这里讨论的重点:
- 通过将某些类别合并并降低名义变量的基数性
- 将连续变量分段,以进行证据权重转换(WOE)。
- 抽样和权重计算
上述的前两项任务也常被称为变量分群。通常,进行分段和降低基数性是为了使生成的变量的预测力最强。
降低基数
当名义变量的类别数大于12个,降低基数就变得非常必要。降低名义变量的基数有三个主要策略:
- 将相同含义的变量合并。但是,由于没有考虑默认的状态变量和被合并类别之间的关联性,可能导致预测力降低
- 出现频率小的类别被合并为一个新的类别,并给与一个合适的标识,如“Other”
- 最后一种,也是绝大多数人偏爱的一种方法:合并变量的类别使某些预测力指标最大化。
SAS实现上面提到的前两种方法都是一些简单的IF-THEN-ELSE条件的简单数据步。
这里重点介绍更先进的第三种方法:最优分群。
以下图为例:
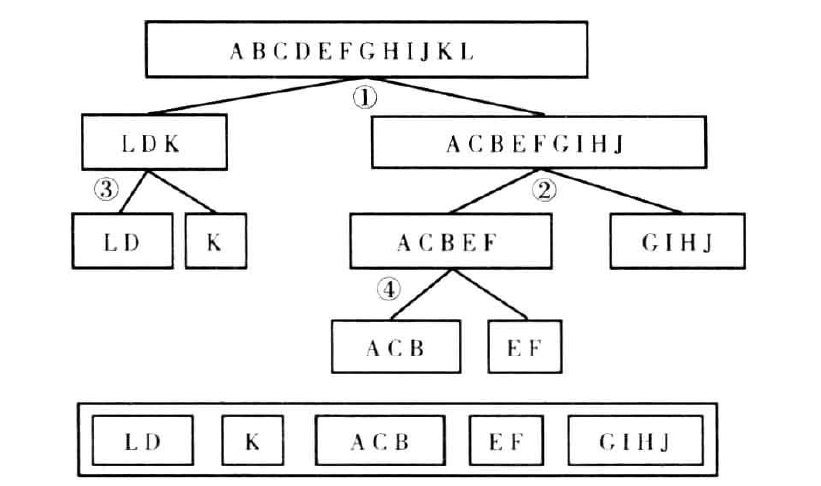
该算法的目的是生成较少数量的类别,该变量的某些预测力指标将得到优化。
进行最优分组的算法是基于决策树模型所用的方法。在这种情况下,首先假设所有的类别都属于一个组,然后,找出最优化的二元分割方法。最优化分割标准可以用一下四个常用的预测力指标:

宏%ReduceCats可以实现上表的四项指标,降低带有字符值的名义自变量IVVAR的基数。该宏的参数如下:

该宏的运行结果是映射数据集State-Map,它包含对状态分组的分段数。有宏%ApplyMap1可将宏%ReduceCats生成的映射应用于数据集,该宏的参数如下:

该宏生成一系列的IF-THEN条件,并用它们将初始类别映射到预期相等的分段数,执行宏%ApplyMap1的SAS日志

最后,一个示例演示上述过程:
data States1;length State $15.;input State $1-15 Freq;datalines;ARIZONA 35CALIFORNIA 33COLORADO 66FLORIDA 117ILLINOIS 49KANSAS 64LOUISIANA 88MARYLAND 22MASSACHUSETTS 79MICHIGAN 82MINNESOTA 75MISSISSIPPI 120NEW JERSEY 39NEW MEXICO 60NEW YORK 178OHIO 70PENNSYLVANIA 20TEXAS 38VIRGINIA 139WISCONSIN 98;run;/* Also generate the default indicator (at random) */data States2;retain Customer_ID 0;set states1;do i=1 to freq;Customer_ID=Customer_ID+1;if (ranuni(0) >0.8) then default=1; /* DV=Bad */else default=0; /* DV=Good */output;end;drop i freq;run;/* Call the macro ReuceCats */%let DSin=States2;%let IVVar=state;%let DVVar=default;%let Method=1; /*Using Gini */%let MMax=5;%let DSVarMAp=State_Map;%ReduceCats(&DSin, &IVVar, &DVVar, &Method, &Mmax, &DSVarMap);/* Print the State_Map dataset to the output window */proc print data=State_Map;run;/* Call the macro ApplyMaps1 to apply the reduction maps */%let DSin=States2;%let VarX=State;%let NewVarX=State_Group;%let DSVarMap=State_Map;%let DSOut=State2_m;/* Use: option MPRINT to view how the code for applying the mapsin the SAS Log *//* option mprint */;%ApplyMap1(&DSin, &VarX, &NewVarX, &DSVarMap, &DSout);/* Use PROC FREQ to confirm the counts in the new groups */proc freq data=State2_m;table State_Group;run;
连续变量的分段
连续变量必须要分段,以允许使用标准的评分卡格式。
信用评分开发中有两种常用的分段方法:等距分段和最优分段
在等距分段中,连续变量的取值范围被分为预先确定数量的等宽度区间。用宏%EqWBinn可以对连续变量进行等距分段。
而连续变量的最优分段,相当于名义变量的最优分群。实际上,最优分段和最优分群使用的算法都是基于相同的概念和方法。在下面介绍的一种方法中,连续变量被分为大量初始宽度相等的段,比如10个,然后将这些段看作名义变量,并用名义变量的最优分群程序进行分段
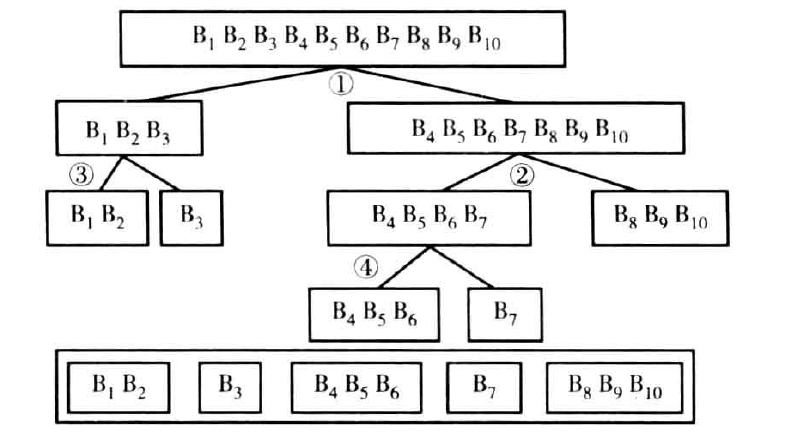
宏%BinContVar提供了上图算法的SAS实施。该宏先将连续变量按照最小分段百分比分成1/Acc段,然后对这些段进行分组,直到剩余MMax个为止。宏的参数如下:

该宏也将生成一个映射数据集,这个数据集可通过%ApplyMap2生成一组IF-THEN语句来定义输出数据集中新变量的分段数量
示例如下
data Customers;Input Income Default @@;datalines;2339.95 0 1578.3 0 1453.02 0 1398.77 1 2988.94 0 1970.5 0 1765.14 0 1016.64 1 1024.72 1 3731.1 01296.54 1 1375.53 1 2454.93 0 1458.21 1 3607.17 0 1137.89 1 2618.88 0 3066.08 0 1651.19 0 2122.69 02384.87 0 1117.99 1 3059.15 0 2632.47 0 1321.09 1 3481.08 0 2599.82 0 3421.61 0 2615.36 0 2177.07 03129.73 0 1597.58 0 1996.46 0 2561.42 0 1143.17 0 3517.13 0 1044.27 1 2149.7 0 1062.72 1 2802.59 01170.76 1 1839.54 1 1341.2 0 2687.47 0 1882.49 0 1001.02 1 1222.01 1 3773.33 0 2108.08 0 3555.37 03860.08 0 3471.33 0 2836.04 0 3279.11 0 3359.93 0 2661.54 0 3075.54 0 3335.51 0 3615.98 0 2608.25 03291.14 0 2738.75 0 3297.46 0 2329.84 0 1579.09 0 1005.38 1 3467.94 0 2460.84 0 3786.78 0 1697.54 01344.75 0 2546.71 0 1044.77 1 1754.39 0 3088.03 0 3190.34 0 1643.03 0 1159.4 0 1594.84 1 2195.37 02040.43 0 2288.39 0 1254.77 1 2177.82 0 1432.33 1 2090.93 0 1592.75 1 3649.18 0 1192.09 0 1870.53 01344.73 0 3112.17 0 3594.69 0 1256.47 0 1884.62 0 2804.8 0 2397.37 0 3106.19 0 2153.69 0 2901.84 01932.5 0 2967.7 0 3742.8 0 2741.32 0 3229.37 0 2955.23 0 3984 0 1764.69 0 3262.91 0 3556.29 01371.41 0 1506.34 0 3835.23 0 1017.64 1 2786.11 0 1027.96 1 2705.19 0 1112.11 1 1345.8 1 3224.26 03381.09 0 3564.85 0 3860.62 0 2039.35 0 2232.72 0 1755.91 1 2730.88 0 3071.92 0 3859.66 0 2728.11 03908.71 0 1900.97 0 2365.91 0 1173.9 1 3046.59 0 3247.21 0 1765.75 1 1851.27 0 3168.86 0 1180.68 11126.39 1 3716.19 0 3482.85 0 1177.04 1 2869.67 0 2112.35 0 1259.28 1 2034.07 0 2781.34 0 2650.68 01098.68 1 3413.67 0 3832.62 0 1446.92 0 2823.57 0 2964.95 0 3480.61 0 3982.74 0 2223.56 0 2324.61 01839.08 0 2816.05 0 2161.21 0 2215.25 0 1829.55 1 3088.54 0 2006.91 0 1895.16 0 3540.52 0 1159.11 13753.1 0 2583.6 0 1694.81 0 1800.39 0 2831.79 0 1953.42 0 2326.95 0 3963.79 0 3478.85 0 1445.58 01559.44 0 2785.78 0 1677.91 1 2529.97 0 1929.34 0 3347.23 0 2467.97 0 3704.05 0 1370.85 1 1324.15 02131.14 0 3558.72 0 3580.39 0 1241.11 1 3914.43 0 2829.92 0 2112.3 0 1990.34 0 1265.65 1 3572.18 0;run;/* Call the binning macro */%let DSin=Customers;%let IVVar=Income;%let DVVar=Default;%let Method=1;%let MMax=5;%let Acc=0.01;%let DSVarMap=Income_Map;%BinContVar(&DSin, &IVVar, &DVVar, &Method, &MMax, &Acc, &DSVarMap);/* Print the binning map dataset *//* A simple layout */Proc print data=Income_Map;run;/* A more fancy printout */options linesize=120;proc print data=Income_Map split='*' ;var bin LL UL BinTotal;label bin ='Bin*Number*========='LL='Lower*Bound*========='UL='Upper*Bound*========='BinTotal='Bin*Size*=========';format LL Comma10.2;format UL Comma10.2;format BinTotal Comma10.0;title 'Mapping rules for binning variable: Income';run;/* Apply the mapping scheme *//* use:options mprint ;to see the binning statements in the SAS Log */%let DSin=Customers;%let VarX=Income;%let NewVarX=Income_bin;%let DSVarMap=Income_map;%let DSout=Customers_Income_b;%ApplyMap2(&DSin, &VarX, &NewVarX, &DSVarMap, &DSout);
抽样和权重计算
抽样方法
信用评分开发是基于对申请或交易数据库的抽样。有三种常用的抽样方法:
- 随机抽样,从总体中抽取两个不想交的样本
- 均衡抽样,设计的样本中的目标变量具有特定的构成,如50%正常和50%违约。
- 分层抽样,用一个或多个于业务申请相关的变量的值将数据分层。
随机抽样
SAS中proc surveyselect可用于从数据集中抽取随机样本。宏%RandomSample是surveyselect的一个简单形式,以方便使用。
可以用宏%RandomSample从总体中抽取两个随机样本,分别作为开发数据集和验证数据集。但是,无法保证这两个数据集是不相交的。为了从一个总体数据集中抽取两个不相交的样本,提供了宏%R2Partitions,下表是其参数:

均衡抽样和权重
在均衡抽样中,从总体中抽取两个样本,每个样本中违约的百分比与初始总体不同。下图表示从规模为N的总体中抽取的两个样本DS1和DS2,其规模分别是N1和N2。
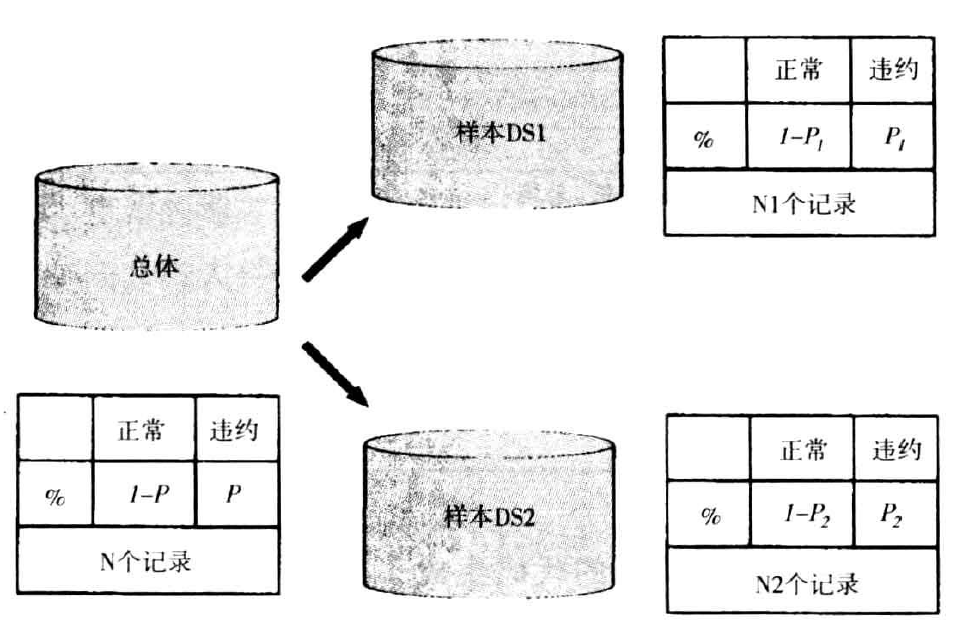
总体中具有违约状态的记录数必须满足抽取两个样本的需要。这被称为一致性条件,其正式表达式如下:
宏%B2Partitions尝试抽取两个样本并验证一致性条件,其参数如下表:

示例程序如下:
Data Population;do ID=1 to 1500;if ID <=300 then DV=1;else DV=0;x=ranuni(0);output;end;run;/* Call the macro */%let S=Population;%let IDVar=ID;%let DV=DV;/* The Modeling Sample */%let S1=Modeling;%let N1=500;%let P1=0.50;/* The Validation Sample */%let S2=Validation;%let N2=200;%let P2=0.20;/* The error variable */%let Status=;%B2Partitions(&S,&IDVar,&DV,&S1,&N1,&P1,&S2,&N2,&P2,Status);/* Display the status variable in the SAS log. */%put &status;/* Check the percentage of Bad in samples */proc freq data=Modeling;table DV;run;proc freq data=Validation;table DV;run;
计算样本权重
以下表为例,理解如何对均衡样本分配权重

定义一个因子,该因子将映射样本DS1中的2500条记录以代表总体中初始的10000条记录,由此可以计算出样本中标识为违约的记录的权重。
通常要正态化这些值,使其和为1.0,具体的计算公式见下表: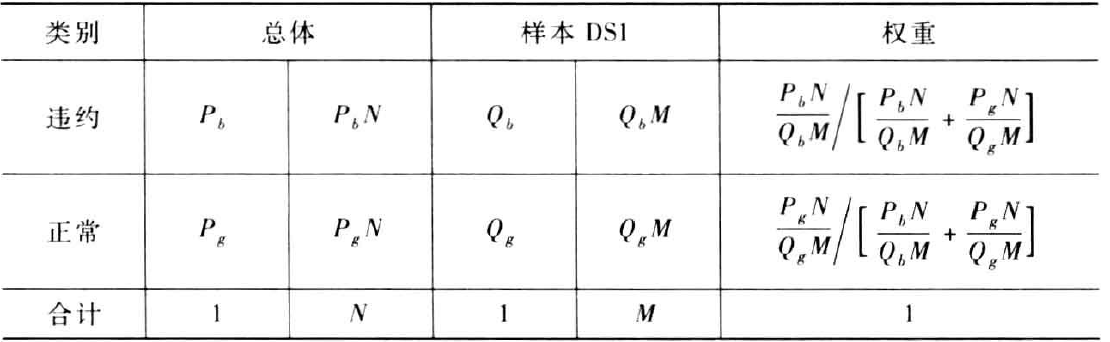
宏%BSWeight计算样本权重,并创建输出变量。宏的参数如下:

应用示例:
Data Population;do ID=1 to 1500;if ID <=300 then DV=1; else DV=0;x=ranuni(0);output;end;drop ID;run;Data Modeling;do ID=1 to 500;if ID <=250 then DV=1; else DV=0;x=ranuni(0);output;end;drop ID;run;%let PopDS= Population;%let SDS = Modeling;%let DVVAr= DV;%let WTVar=Weight;%let DSout=Modeling_W;%BSWeight(&PopDS, &SDs, &DVVar, &WTVar, &DSout);proc freq data=Modeling_w;table Weight * DV /norow nocol nopercent ;run;
