@77qingliu
2018-05-21T00:21:50.000000Z
字数 3860
阅读 2082
拒绝演绎
信用评分
定义和理由
在申请评分卡中,迄今为止都是假设开发评分卡使用的数据样本来源于已知账户状态的事后结果。模型开发使用的数据实际上并不是从申请中随机选择的,而仅仅是从过去已经被接受的账户中选择。因此,将模型结果应用于全部总体隐含着对被拒绝账户的忽视。进而,建立评分卡时对拒绝账户的状态进行演绎并将其纳入评分卡开发数据集。这种方法被称为拒绝演绎。
拒绝演绎的方法
拒绝演绎的方法可以分为两大类。
- 简单赋值方法。由分析人员将被拒绝的账户指定为两种账户状态中的一种,即正常或违约。
- 通过外推法将模型范围扩展到被拒绝记录的方法,称为强化法。
演绎被拒绝申请的真实状态的唯一方法是系统性地接受拒绝申请记录中一个样本并监测真实表现随时间的变化,度量他们的违约行为。然后,假设其余被拒绝申请具有相似的违约分布。尽管这是最可靠的方法,但由于放任某些账户发生违约的相关成本而使其并不具有可行性。
简单赋值法
忽略被拒绝申请
这是所有方法中最简单的一种
赋予被拒绝申请违约状态
这种方法仅适用于初始审批通过率很高的情况,如95%的申请被批准,以及初始评分计划的准确性具有很高的置信水平。
比例赋值
随机赋予被拒绝账户正常和违约状态,而不是全部赋予违约状态。然而,要保持正常对违约的比率与审批通过总体的一致。
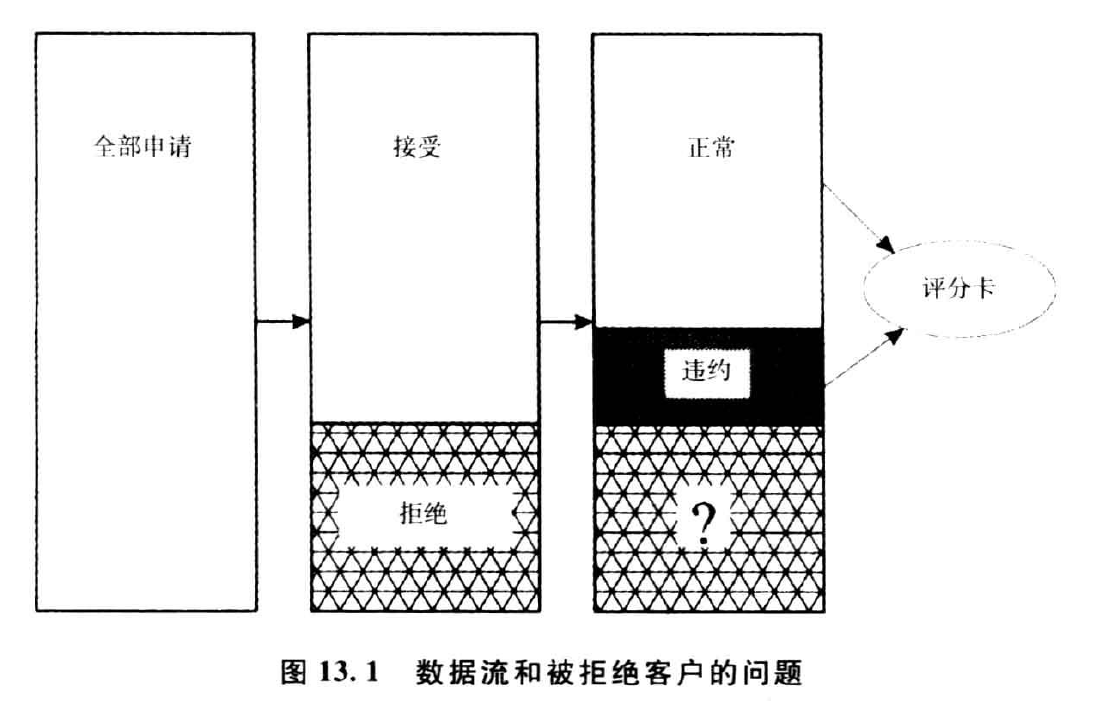
宏%PropAssign根据随机选择实施状态值的比例赋值,其参数如下:
示例程序:
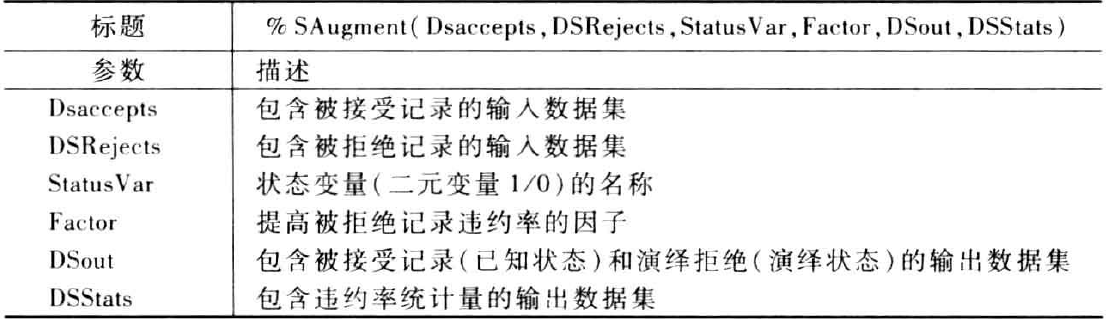
data acc;do i=1 to 1000;score = int(ranuni(0)*1000);status=0;if score <200 and ranuni(0)>0.8 then status=1;if score>=200 and score<400 and ranuni(0)>0.85 then status=1;if score>=400 and score<600 and ranuni(0)>0.90 then status=1;if score>=600 and score<800 and ranuni(0)>0.95 then status=1;if score>=800 and ranuni(0)>0.98 then status=1;output ;end;run;data rej;do i=1 to 1000;score = int(ranuni(0)*1000);output ;end;run;/*******************************************************//* Call the macro *//*******************************************************/%let DSAccepts=acc;%let DSRejects=rej;%let statusVar=status;%let Factor =1.5;%let DSout=AllData;%let DSStats=stats;%PropAssign(&DsAccepts, &DSRejects, &StatusVar, &Factor, &DSout, &DSStats);proc print data=stats;run;
打印统计数据集输出内容:
强化法
简单强化
这种方法是用数据中接受部分开发的模型对被拒绝账户进行评分。低分值的拒绝账户,低于预先约定的临界值,将被赋予违约状态,而剩余的被拒绝账户则被赋予正常状态。通常,选择的临界值是被拒绝账户的坏账率高于接收账户的坏账率的分值。拒绝账户被赋予状态值后,可以用全部账户开发新的模型并用于最终评分卡。
这种方法也被称为严格临界值法,因为给被拒绝账户赋予状态值使用的临界值是一个固定值。
简单强化法易于实施,但由于临界值的选择是随意的,最终结果将取决于分析人员的选择。宏%SAugment可以实施简单强化。其参数如下
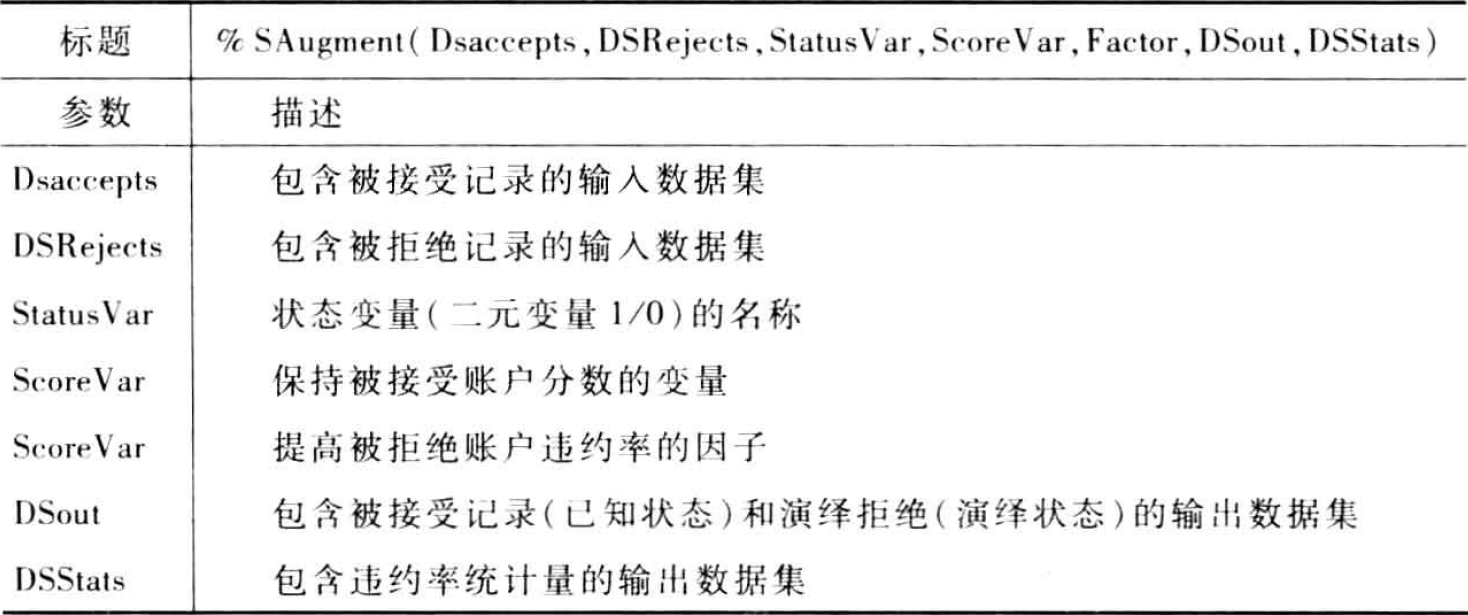
示例程序
data acc;do i=1 to 1000;score = int(ranuni(0)*1000);status=0;if score <200 and ranuni(0)>0.8 then status=1;if score>=200 and score<400 and ranuni(0)>0.85 then status=1;if score>=400 and score<600 and ranuni(0)>0.90 then status=1;if score>=600 and score<800 and ranuni(0)>0.95 then status=1;if score>=800 and ranuni(0)>0.98 then status=1;output ;end;run;data rej;do i=1 to 1000;score = int(ranuni(0)*1000);output ;end;run;/* Call the macro */%SAugment(acc, rej, status, Score, 5, all, stats);proc print data=stats;run;
简单强化结果

模糊强化
为了弥补简单强化法中演绎值依赖于临界值的缺点,模糊强化法并不直接给拒绝账户赋予正常或违约的状态值,而是创建加权的正常和违约。拒绝中记录中的每个记录都用一个代表加权正常和加权违约的新纪录代替,其中,加权的正常和违约是模型计算出来的正常和违约的概率。新的记录及其独赢的权重,被加入接受数据集并用于开发最终模型。宏[%FAugment]可以实施模糊强化,其参数如下:
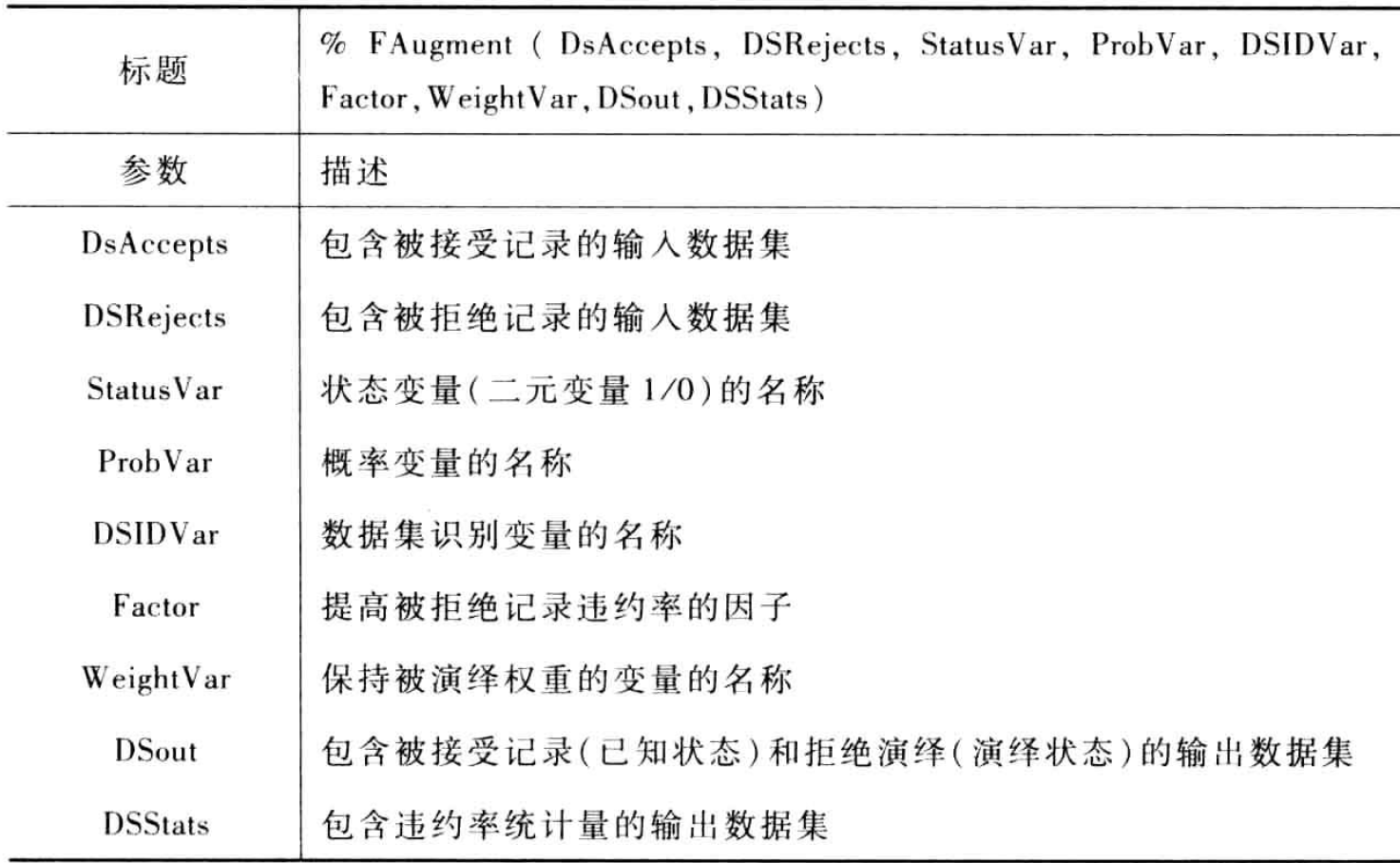
示例程序
data acc;do i=1 to 1000;Prob = 1-ranuni(0);status=0;if Prob <0.2 and ranuni(0)>0.8 then status=1;if prob>=0.2 and prob<0.4 and ranuni(0)>0.85 then status=1;if Prob>=.4 and prob<0.6 and ranuni(0)>0.90 then status=1;if Prob>=0.6 and prob<0.8 and ranuni(0)>0.95 then status=1;if prob>=0.8 and ranuni(0)>0.98 then status=1;output ;end;run;data rej;do i=1 to 1000;Prob= ranuni(0);output ;end;run;/* Call the macro */%FAugment(acc, rej, Status, Prob, _source, 5, Weight ,all, Stats);proc print data=stats;run;
打包
无论简单还是模糊强化都忽略了一个事实,那就是被拒绝账户分布在模型生成的分数段的全部范围内。以包含6000个信用卡申请的数据集为例,其中只有5000个被接受。用被接收的5000个记录开发一个评分卡,然后用该卡对被拒绝的1000个记录进行评分。下变显示了被接受账户实际状态的分布以及每个分值区间内被拒绝账户的数量。
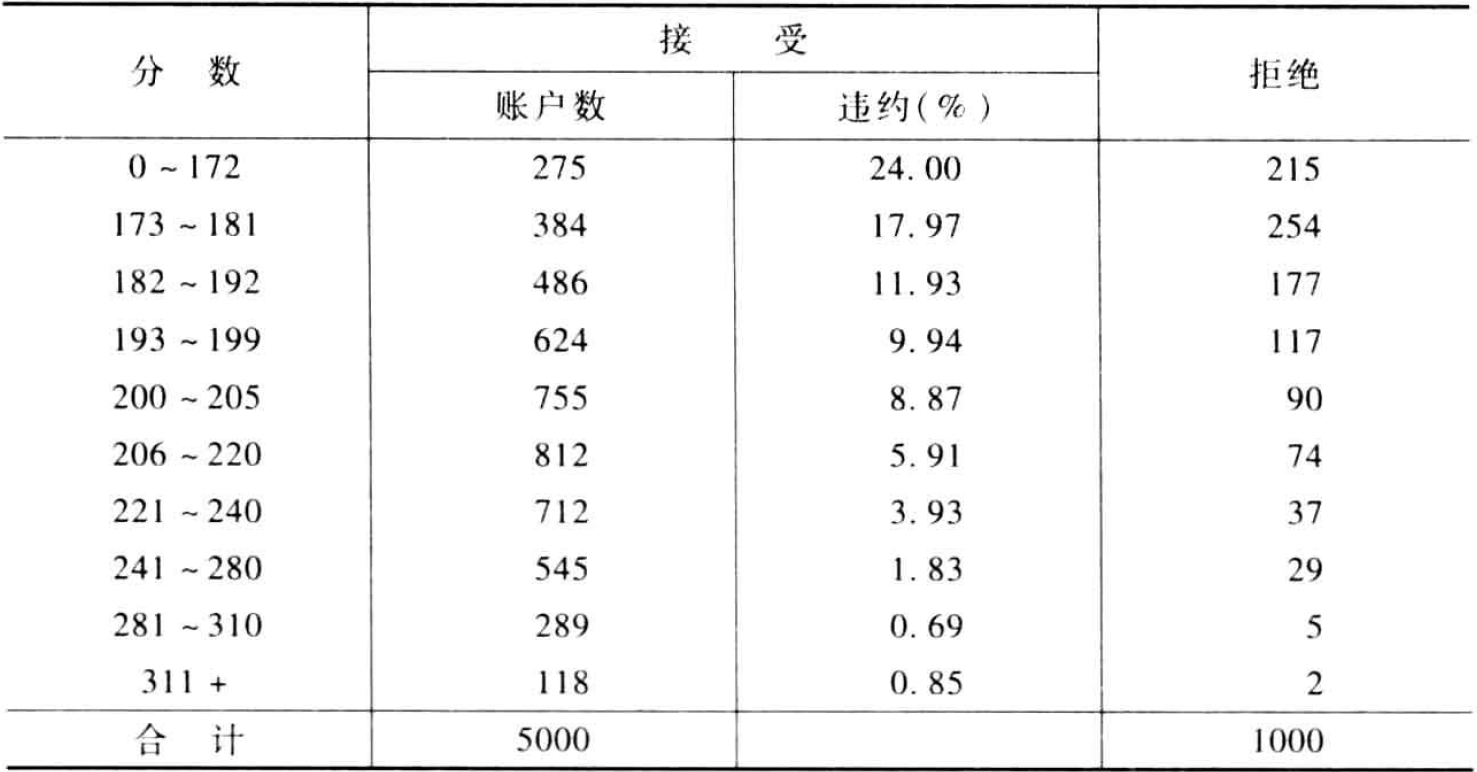
打包法的基本原理是指定每个分值区间的被拒绝账户的违约数量,从而使被拒绝账户的违约分布于接收账户中的一样。每个分值区间记录的赋值可以随机进行,也可以使用该分值段的分数值。
拒绝账户被赋予状态值后,两个数据集被合并开发一个新的模型。然而,由于预期到拒绝账户的违约率较高,低分值段的拒绝账户被赋予比接受账户管擦到的更高的违约率。通常,这些较高的违约率要经过几次迭代调整,使最终获得的拒绝账户的总体坏账率是接受账户的2-5倍,下表是赋值的第一次迭代:
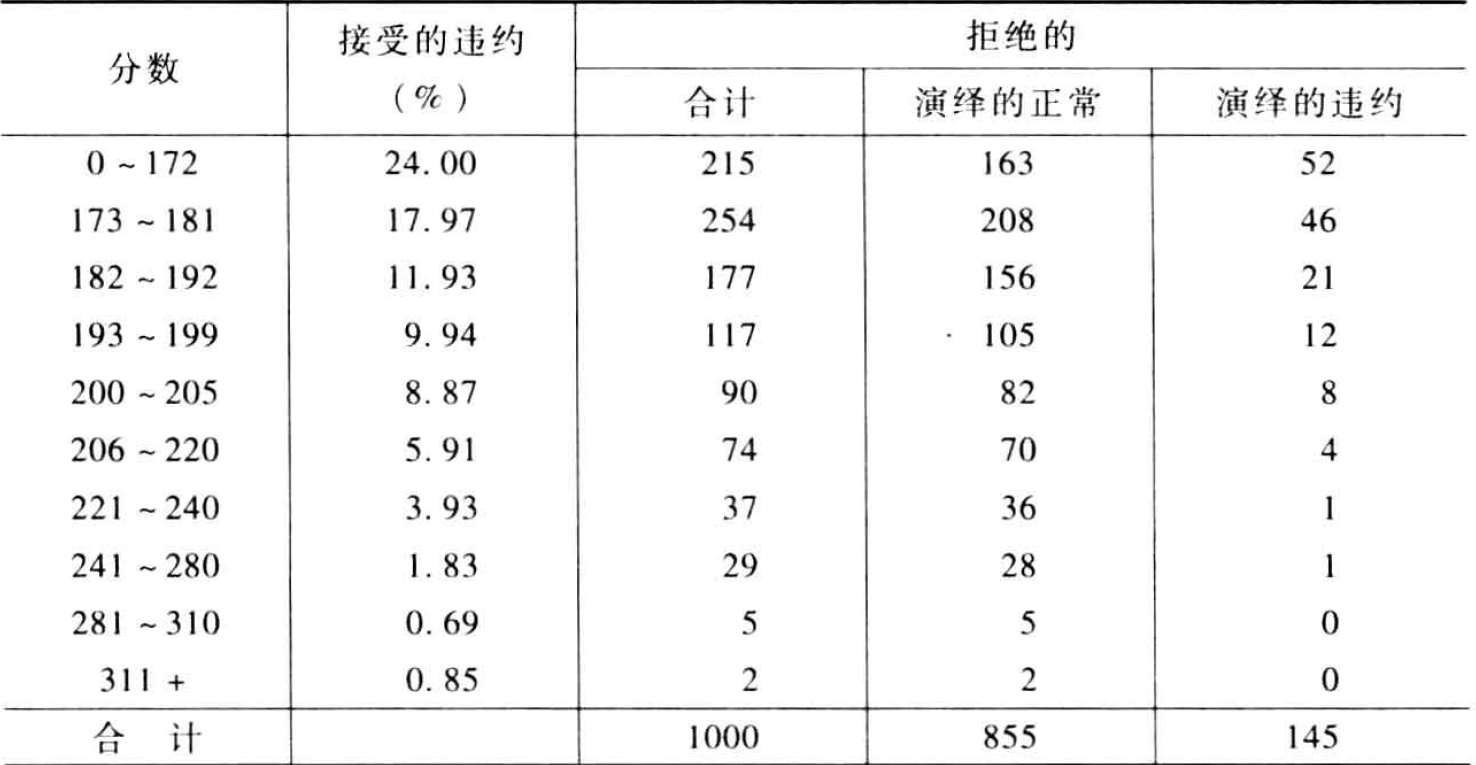
宏%Parceling用一个简单的因子实施打包强化法,以提高拒绝记录的坏账率,其参数如下:
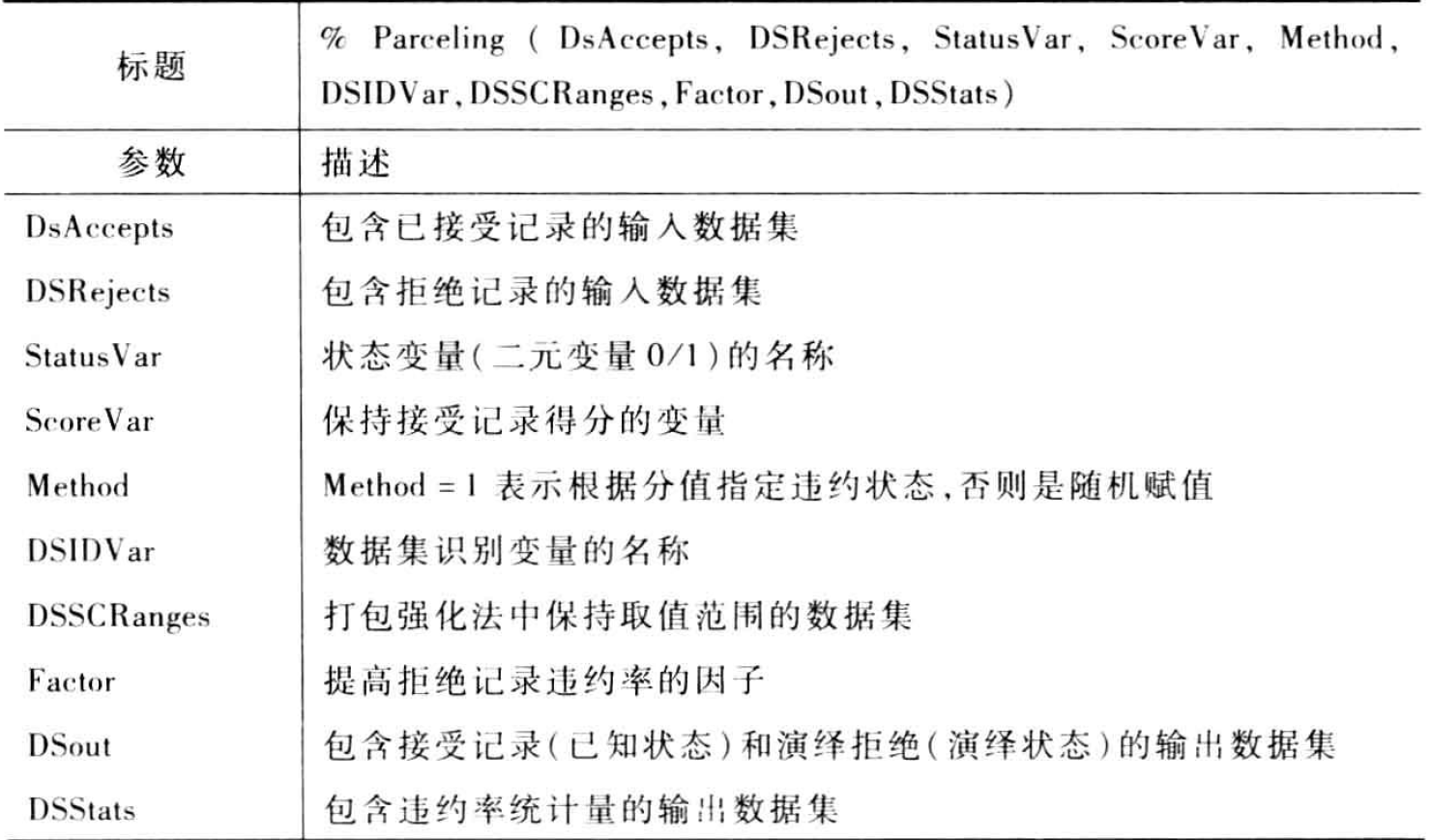
示例程序
data acc;do ID=1 to 1000;score = int(ranuni(0)*1000);status=0;if score <200 and ranuni(0)>0.8 then status=1;if score>=200 and score<400 and ranuni(0)>0.85 then status=1;if score>=400 and score<600 and ranuni(0)>0.90 then status=1;if score>=600 and score<800 and ranuni(0)>0.95 then status=1;if score>=800 and ranuni(0)>0.98 then status=1;output ;end;run;data ranges;input LowerLimit UpperLimit;datalines;0 100100 200200 300300 400400 500500 600600 700700 800800 900900 1000;run;data rej;do ID=1001 to 2000;score = int(ranuni(0)*1000);output ;end;run;/* Call the macro */%Parceling(acc, rej, Status, Score, 2, _source, Ranges, 2, all, Stats);proc print data=stats;run;
拒绝演绎的应用
为了使用拒绝演绎的结果,经过演绎的拒绝记录被加入接受账户中,用全部数据集重新开发一个新的模型。新模型的参数将与只使用接受账户开发的模型的参数有所差异。因此,重复该过程直到模型参数收敛于最终值。下图描述该运算过程:
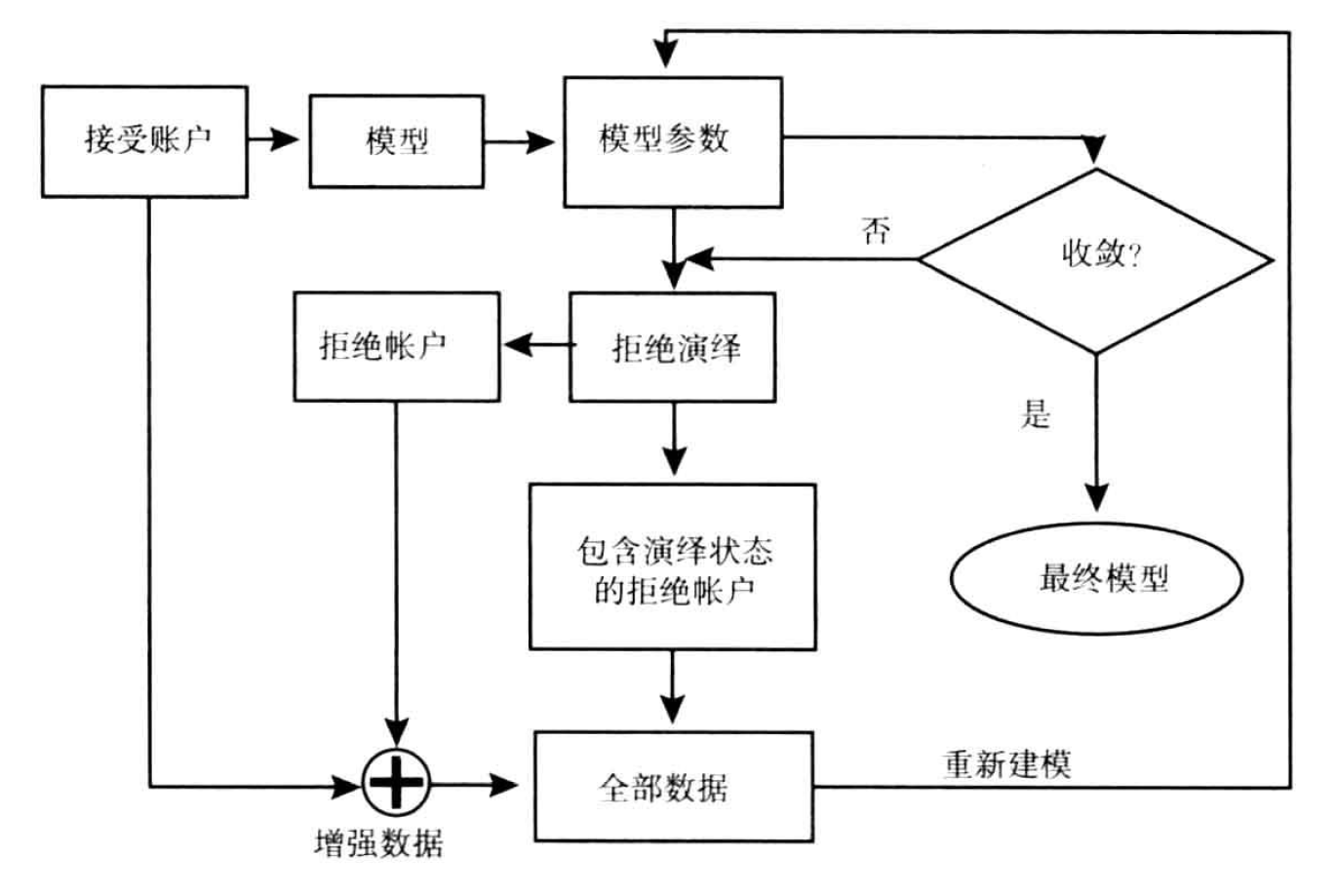
上图计算过程中使用的典型收敛标准包括:
- 模型参数值的收敛
- 接收和拒绝记录中违约的概率估计的收敛
- 经过几次迭代过程后,分值的频率分布在某些预先设定的分值区间变得稳定。
