@Cleland
2020-05-14T01:33:16.000000Z
字数 4347
阅读 952
00:课程 Python 开发环境配置
Python入门爬虫与数据分析
工欲善其事,必先利其器。
在开始这门专栏课爬虫之旅前,我们需要先安装配置好 Python 开发环境。我用的是 Windows 系统,所以主要讲 Windows 下的环境安装,其他平台可以自行搜索或者参考下方教程。
https://cuiqingcai.com/5052.html
1 安装 Python3
首先是安装 Python 软件,首选 Python 3。Windows 下安装 Python 首推通过 Anaconda 安装,它自带很多库,不用我们自己一个个单独去安装,简单省事。
官方下载链接:https://www.anaconda.com/distribution/
选择 Python 3 版本,根据你的系统版本选择 32 或者 64 位的安装包下载。

下载完成之后,双击安装包安装即可,过程中有几点注意事项。

- 最好按默认位置安装,以免后续出现很多不必要的问题。

不要勾选“Add Anaconda to my PATH environment variable”,即:添加 Anaconda 至环境变量,如果勾选会影响其他程序的使用。
如果你打算使用多个版本的 Anaconda 或者多个版本的 Python,那就不要勾选“Register Anaconda as my default Python 3.6”
安装完成后,通过下面命令验证是否安装成功:
- cmd 执行窗口输入 conda list ,若显示很多库名和版本号列表,说明安装成功。
安装完成之后,Python 3 的环境就配置好了。
详细安装步骤可参考下方链接:
https://zhuanlan.zhihu.com/p/32925500
接下来,我们安装专栏课所需的库,多数库都可以通过 cmd 命令窗口执行下面的命令安装好:
pip3 install 库名称
2 请求库安装
抓取网页,我们需要模拟浏览器向服务器发出请求,所以需要一些 Python 库来实现 HTTP 请求操作,这些库就叫请求库。
Request
Requests 库是最常用的请求库,我们在 cmd 运行窗口中执行下面一行命令安装它。
pip3 install requests
安装完成后,运行下面命令,如果没有报错说明 requests 库安装成功。
python3import requests
Selenium
Selenium 是一个自动化测试工具,利用它我们可以驱动浏览器执行特定的动作,如点击、下拉等操作。对于一些 JavaScript 渲染的页面来说,这种抓取方式非常有效,下面来安装它。
pip3 install selenium
然后设置我们的浏览器(如 Chrome、Firefox 等)来配合 Selenium 工作。
ChromeDriver
我使用的是 Chrome,所以我们需要安装一个驱动:ChromeDriver,来驱动 Chrome 浏览器完成相应的操作。
先查看 Chrome 的版本号,可点击 Chrome 菜单“帮助”→“关于 Google Chrome”看到。

然后到 ChromeDriver 官网下载对应版本的驱动
https://chromedriver.storage.googleapis.com/index.html
下载完成后,将 ChromeDriver.exe 配置到环境变量下:直接拖拽到 Python 的 Scripts 目录下就可以。

cmd 输入 chromedriver ,返回下面的语句说明配置成功:

PhantomJS
除了 Chrome,Selenium 还常结合 PhantomJS 使用。它是一个无界面、可脚本编程 WebKit 浏览器引擎,这样在运行的时候就不会再弹出一个浏览器。它的运行效率高,支持各种参数配置,使用非常方便。
下载地址:http://phantomjs.org/download.html
下载完成后,接着配置环境变量,同配置 chromedriver.exe 一样,直接将 phantomjs.exe 复制到 Python 的 Scripts 文件夹中就行。
然后 cmd 命令行中输入phantomjs -v,如果会显示 phantomjs 的版本号,说明 phantomjs 配置成功。

3 解析库安装
网页请求成功后会返回响应,接下来利用一些库区解析网页内容,可以高效提取出我们想要的信息,这些库就是解析库。
lxml
lxml 支持 HTML、XML 和 XPath 的解析,效率很高。
pip3 install lxml
Beautiful Soup
Beautiful Soup 是 Python 的一个 HTML 或 XML 的解析库,功能非常强大,安装它之前,需要先安装好 lxml。
pip3 install beautifulsoup4
pyquery
pyquery 同样是一个强大的网页解析工具,提供和 jQuery 类似的语法来解析 HTML 文档,支持 CSS 选择器,使用非常方便。
pip3 install pyquery
4 安装数据库
爬取下来的数据有许多存储方式,保存到数据库是一个很好的选择,本课程主要介绍 MySQL 和 MongoDB 两种。
MySQL
官网下载地址:
https://dev.mysql.com/downloads/installer/

选择第二个选项单击 Download,会弹出下面的界面,这里要注意,默认会让你注册后才能下载,如果不想这么麻烦,就点击下方箭头处直接下载。

下载完成双击安装包安装即可,详细的安装步骤可参考下方链接:
https://zhuanlan.zhihu.com/p/37152572
安装完成后,需要启动 MySQL 服务,这样才能存储数据。依次点击“计算机”→“管理”→“服务”页面开启和关闭 MySQL 服务即可。

MongoDB
下载地址:https://www.mongodb.com/download-center/community

下载完成后,可以自定义安装路径。这里不要勾选"install mongoDB compass",否则可能要很长时间都一直在执行安装。
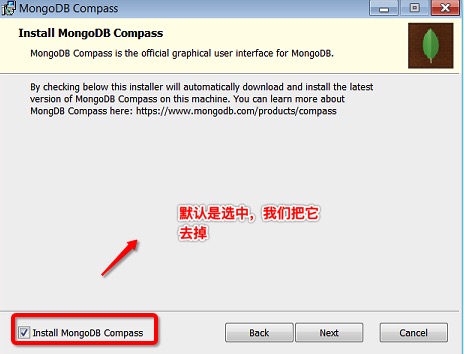
安装好后,我们需要启动 MongoDB 服务以便存储数据,具体操作方法:进入 MongoDB 的安装目录,此处是 C:\MongoDB\Server\3.4,在 bin 目录下新建同级目录 data。

然后进入 data 文件夹,新建子文件夹 db 来存储数据目录。

之后打开命令行,进入 MongoDB 安装目录的 bin 目录下,运行 MongoDB 服务:
mongod --dbpath "C:\MongoDB\Server\3.4\data\db"
注:路径需替换成你电脑中 MongoDB 安装路径。
运行之后,会输出一些信息表示成功启动 MongoDB 服务,进一步地,需将 MongoDB 配置成系统服务,以便可以持续使用。
新建一个日志文件,在 bin 目录新建 logs 同级目录,进入之后新建一个 mongodb.log 文件,用于保存 MongoDB 的运行日志。

在“开始”菜单中搜索 cmd,找到命令行,然后右击它以管理员身份运行,否则可能配置失败。

输入下面一串命令:
mongod --bind_ip 0.0.0.0 --logpath "C:\MongoDB\Server\3.4\logs\mongodb.log" --logappend --dbpath "C:\MongoDB\Server\3.4\data\db" --port 27017 --serviceName "MongoDB" --serviceDisplayName "MongoDB" --install
注:这里同样需把路径替换成你电脑中 MongoDB 安装路径。

如果没有出现错误提示,说明 MongoDB 服务已经安装成功,可以在服务管理页面查看到系统服务。

至此,MongoDB 安装完成。
5 安装存储库
pyMySQL
如果想要将数据存储到 MySQL 中,需要借助 PyMySQL 来操作。
pip3 install pymysql
这里建议安装一款 MySQL 的可视化数据库管理软件:Navicat
下载链接:https://www.navicat.com.cn/download/navicat-for-mysql

可以很方便地管理数据。

PyMongo
在 Python 中向 MongoDB 中存储数据,需要借助于 PyMongo 库。
pip3 install pymongo
同样建议安装一款可视化数据库管理软件:Robo 3T
下载链接:https://robomongo.org/download

可以很方便地管理数据

6 安装爬虫框架
pyspider
https://cuiqingcai.com/5416.html
pyspider 是国人 binux 编写的强大的网络爬虫框架,带有强大的 WebUI、脚本编辑器等,支持多种数据库后端、多种消息队列,另外还支持 JavaScript 渲染页面的爬取,使用起来非常方便。
安装之前需先安装好 PhantomJS,如果没有安装,参考前面的教程安装好,然后执行:
pip3 install pyspider
安装完成后,在命令行下启动 pyspider:
pyspider all
在浏览器中打开:http://localhost:5000/,若能打开 pyspider 的 WebUI 管理页面,说明 pyspider 安装成功。

Scrapy
如果你的 Python 是 Anaconda 的话,Scrapy 安装起来就非常简单,在 Anaconda Prompt 命令行中执行下面命令就可以安装了。
conda install Scrapy
如果你的 Python 不是使用 Anaconda 安装的,可参考这个教程:
https://cuiqingcai.com/5421.html
7 安装绘图库
pyecharts
pyecharts 是一个用于生成 Echarts 图表的类库,可视化效果非常棒。
pip3 install pyecharts
还需要安装额外的地图包:
pip install echarts-countries-pypkg # 全球国家地图pip install echarts-china-provinces-pypkg # 中国省级地图pip install echarts-china-cities-pypkg # 中国市级地图:
更多内容可以参考:
http://pyecharts.org/#/zh-cn/customize_map
jieba
这是一款中文分词包,俗称:「结巴」,可以说是最好的 Python 中文分词组件。
pip3 install jieba
WordCloud
WordCloud 是一款有名的词云包,可以制作好看的词云图。
官网:https://amueller.github.io/word_cloud/
pip3 install wordcloud
如果报错,可以参考下面教程:
https://www.jianshu.com/p/88d264026e25
以上,就是本专栏课程的 Python 开发环境配置,接下来我们就可以开始爬虫之旅了。
