@Heath
2015-10-27T14:33:13.000000Z
字数 681
阅读 3479
编译原理第五周
13331130 李有才
编译原理
一. 考虑以下 NFA:
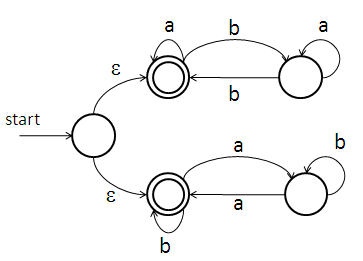
这一 NFA 接受什么语言(用自然语言描述)?
由(偶数个a和任意个b)或(偶数个b任意个a)组成的字符串。
构造接受同一语言的 DFA.

二. 正则语言补运算
画出一个 DFA,该 DFA 恰好识别所有不含 011 子串的所有二进制串.
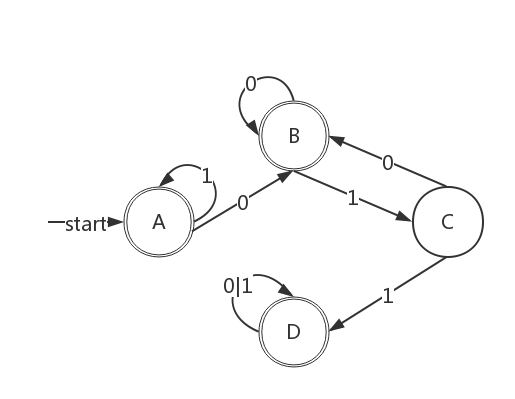
假如要求你再画一个 DFA,该 DFA 恰好识别所有不含 101 子串的所有二进制串。你从中总结出解决这一类问题的普遍规律是什么?
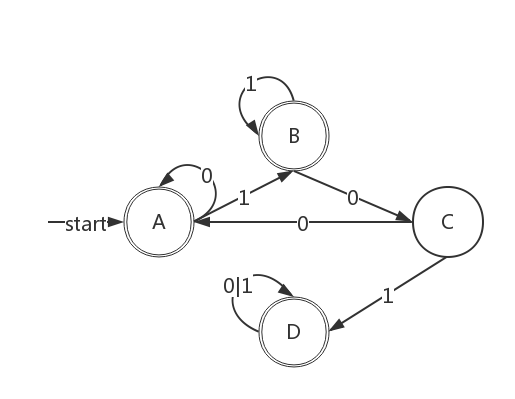
规律:求“不包含”一类的问题,可以先构造题目所描述的语言L的补L'的DFA,然后把其中的非接受状态变为接受状态,接受状态变为非接受状态。再证明:对任一正则表达式 R,一定存在另一正则表达式 R',使得 L(R')是 L(R)的补集.
已知
(1)DFA与正则表达式等价;
(2)将接受状态变为非接受状态,非接受状态变为接受状态,可得到DFA的补。
由(1),构造出DFA(R),由(2)构造出DFA的补DFA(R'),这一步的得到的DFA所表示的语言是R的补,再由(1)可得存在表达式R',使得 L(R')是 L(R)的补集。
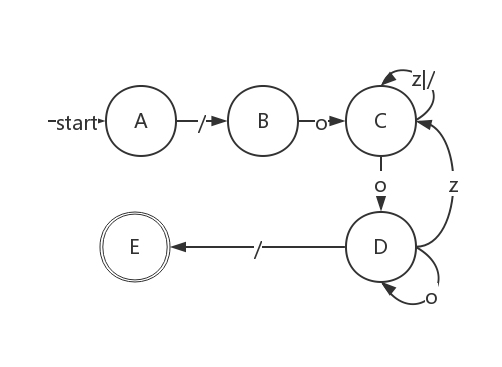
三. 设有一门小小语言仅含 z 、o 、/ (斜杠)3 个符号,该语言中的一个注释由/ o 开始、以 o / 结束,并且注释禁止嵌套.
请给出单个正则表达式,它仅与一个完整的注释匹配,除此之外不匹配任何其他串。书写正则表达式时,要求仅使用最基本的正则表达式算子(ε, |, *, +,?).
/o(o∗z|/)∗o+/ 给出识别上述正则表达式所定义语言的确定有限自动机(DFA). 你可根据问题直接构造DFA,不必运用机械的算法从上一小题的正则表达式转换得到 DFA.