@Rays
2021-10-18T09:16:29.000000Z
字数 4564
阅读 1809
Dr. Squirrel:加速Flink布局的Pinterest自助诊断工具
摘要: 为简化和加速故障排查,Flink构建并推出了称为Dr. Squirrel的诊断工具,揭示并聚合任务状态,洞悉根本致因,提供解决问题的可操作过程。自发布以来,该工具显著提升了开发人员和平台团队的工作效率。
作者: Pinterest工程团队
正文:
注:本文作者Fanshu Jiang和Lu Niu任职于Pinterest流处理平台团队。
Pinterest流处理已赋能多项实时用例。近几年来,基于Flink的平台支持近实时地产出活跃内容和度量报告,表现出了对业务的巨大价值,并在未来有潜力去赋能更多的用例。但要充分发掘Flink的潜力,需解决开发速度上的问题。
要形成生成环境中稳定的数据流,从写下第一行代码开始需数周时间。其中Flink任务的故障排查和调优尤其耗时,因为在排查中会面对海量的日志和度量,调优中会涉及林林总总的配置。查找出导致开发问题的根本致因,在一定程度上需要深入理解Flink的内部机制。这不仅影响了开发速度,引发低于预期的Flink上手体验,而且导致大量的平台支持需求,限制了流处理用例的可扩展性。
为简化和加速故障排查,我们构建并推出了一款Flink诊断工具,称为Dr. Squirrel。该工具揭示并聚合任务状态,洞悉根本致因,提供解决问题的可操作过程。自发布以来,该工具显著地提升了开发人员和平台团队的工作效率。
Flink任务排查的难点
日志和度量散布于大规模存储中,其中仅少量涉及故障
故障排查中,工程人员的通常做法是:
- 通过YARN界面,滚动浏览长篇累牍的JM/TM日志。
- 查看数十种任务/服务器度量面板。
- 搜索任务的配置,并逐一验证。
- 点击Flink Web界面提供的各项任务图,查看检查点对齐(alignment)、数据偏斜和反压(backpressure)等细节信息。
检查这些状态颇为耗时,但其中的90%是并无异常的,或是与根本致因无关。如果能提供相关信息的一站式聚合,仅揭示与故障排查相关的问题,这无疑将节省大量的时间。
发现存在问题的度量后,应采取怎样的措施?
任务相关方在发现有问题度量后,常常会问到这个问题。因为要获得根本致因,还需做更多的推理。例如,检查点超时可能表明超时配置不正确,也可能是由于反压、s3文件系统上传慢、垃圾回收机制、数据偏斜等问题导致。TaskManager日志丢失可能表明节点故障,但通常是由于堆问题或者RocksDB statebackend OOM问题导致。排查并彻底验证每个可能致因,这需要一定时间。但80%的问题修复是有规律可循的。因此作为平台团队,我们考虑是否可以通过编程去分析系统状态,无需任务相关方推断就能给出真实致因。
故障排查文档远远不够
我们向用户提供故障排查文档。但随着故障排查用例的持续增长,文档的篇幅也越来越长,难以快速地查找到问题的相关诊断和操作。为确定根本致因,工程人员不得不手工执行if-else检测逻辑,导致自助式检测难以顺利开展,同时其它问题也仍要依赖平台团队去故障排查。此外,在平台推出新的任务健康需求时,文档尚未完美到可据此做出响应。我们意识到,为了更有效地分享故障排查要点,强化逐个集群任务的健康需求,需要我们去开发一款新的工具。
Dr. Squirrel:自助式故障排查诊断工具
鉴于上述挑战,我们构建并推出了一款快速问题检测和排查诊断工具,称为Dr. Squirrel。其设计目标是:
- 将故障排查时间从小时级削减到分钟级。
- 将开发人员的多种故障排查工具聚合为一款。
- 故障排查中不必掌握Flink内部机制,仅需略有了解。
总而言之,该工具将有用信息聚合为一处,执行任务健康检查,清晰标记非健康的任务,分析根本致因,给出可操作步骤,帮助修复问题。下面介绍部分高亮特性。
更有效的日志查看
对于每个运行的任务,Dr. Squirrel将高亮标识TaskManager丢失和OOM问题等直接触发重启的异常,帮助在海量堆积日志中快速地查找出值得关注的相关异常。它收集警告(warning)、错误(error)和信息(info)日志各部分中所有包含堆栈追踪的信息,并检查每个日志内容中是否存在“error”关键字,为在故障排查指南中逐步解决问题提供线索。
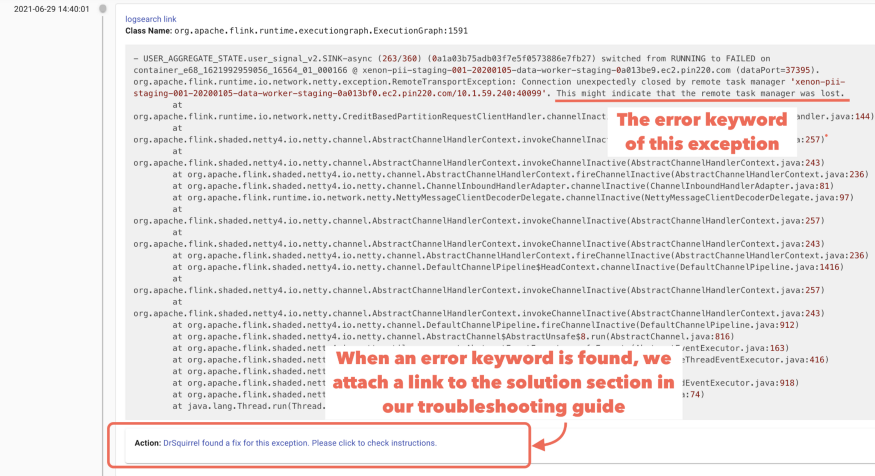
Dr. Squirrel的搜索条支持对全日志的搜索,并基于此提供两种更高效的日志查看方式,即时间线(Timeline)视图和特异(Unique exception)视图。时间线视图如下图所示,其中按时间顺序为用户提供具有“Class Name”信息的日志查看,并预先生成ElasticSearch链接,以满足细节查看需求。
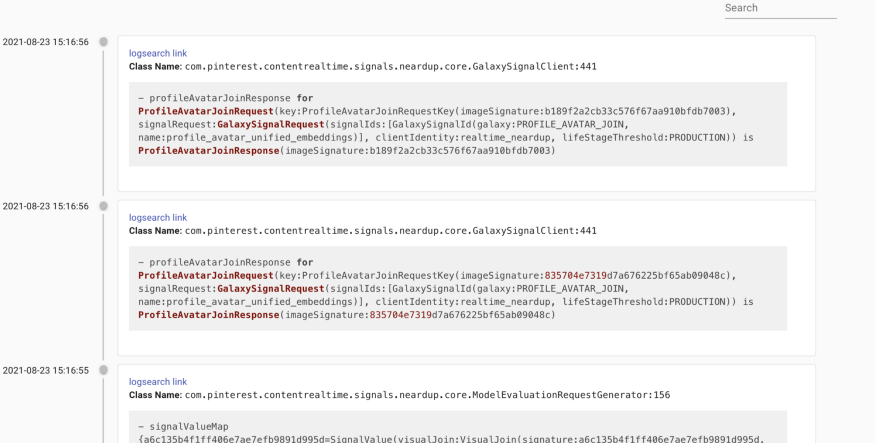
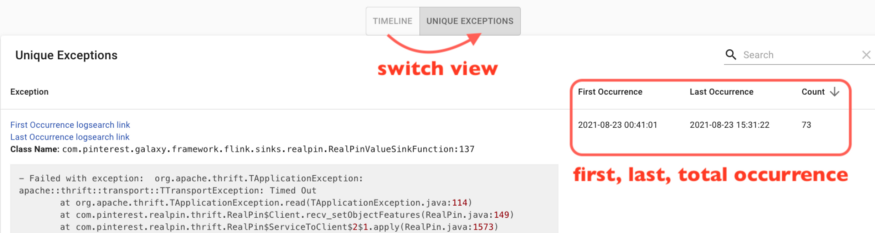
用户只需点击一下,可会切换到特异视图。相同异常被分组为同一行显示,并提供首次出现、最近出现和合计出现次数等元数据,有助于识别最频繁发生的异常。
任务健康一目了然
Dr. Squirrel提供了健康查看页面,给出任务的确切健康情况,适合无论资深工程人员还是新手查看。不同于直接展示度量的面板,Dr. Squirrel对各个度量监控一小时,清晰给出是否符合我们平台稳定性需求。对于平台团队,这是一种有效的、可扩展的交流方式,强调任务的稳定性。
健康检查页面分为如下数个区域,各区域聚焦于不同的任务健康特性。快速地做一次整体浏览,就能很好地把握任务的整体健康情况。
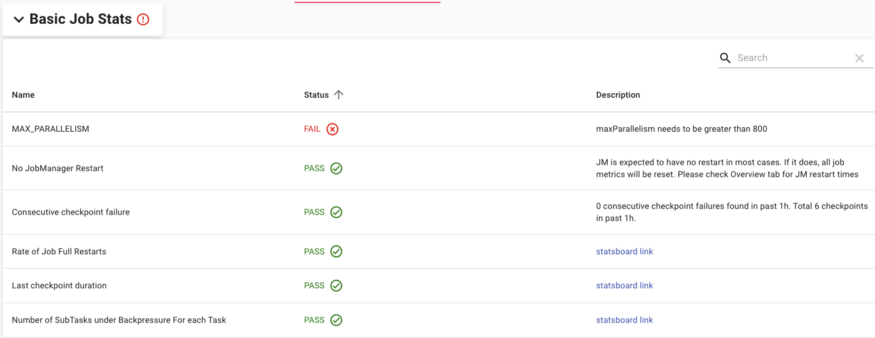
- 基本任务状态区域:展示基本健康状态,例如通量、完全重启率,检查点规模和持续时间,持续检查点失败、最近一小时内的最大并发等情况。未通过健康检查的度量,会标记为“Failed”,并置顶显示。
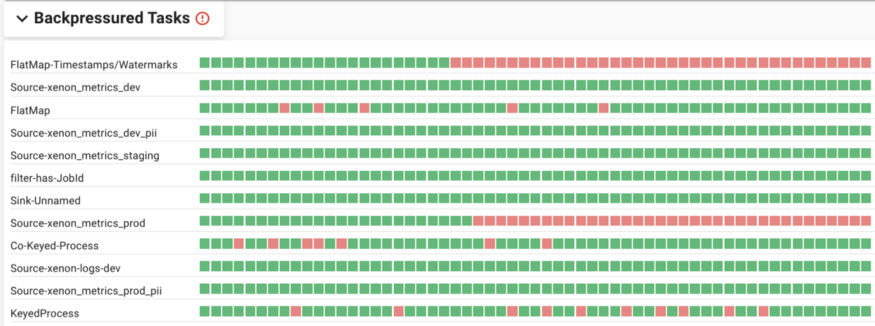
- 反压任务区域:以一定粒度追踪每个Operator的反压状态。如果一分钟内无反压,就可视化展示为一个绿色方块,否则展示一个红色方块。每个Operator展示为60个方块,表示最近一小时内的反压状态。这易于识别反压发生频次,并确定最先启动的Operator。
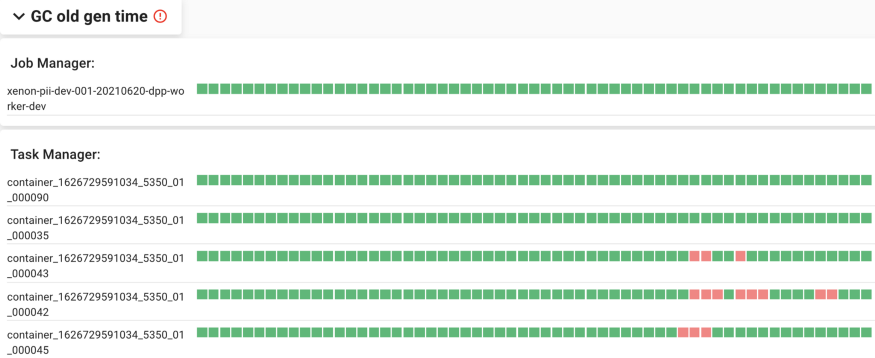
- 垃圾回收Old Gen时间区域:采用和反压任务区域同样的可视化方式,概览垃圾回收是否过于频繁发生。垃圾回收可对通量和检查点造成潜在影响。由于采用相同的可视化方式,我们可以清晰地查看垃圾回收和反压是否同时发生,进而判断垃圾回收是否是导致反压的潜在原因。
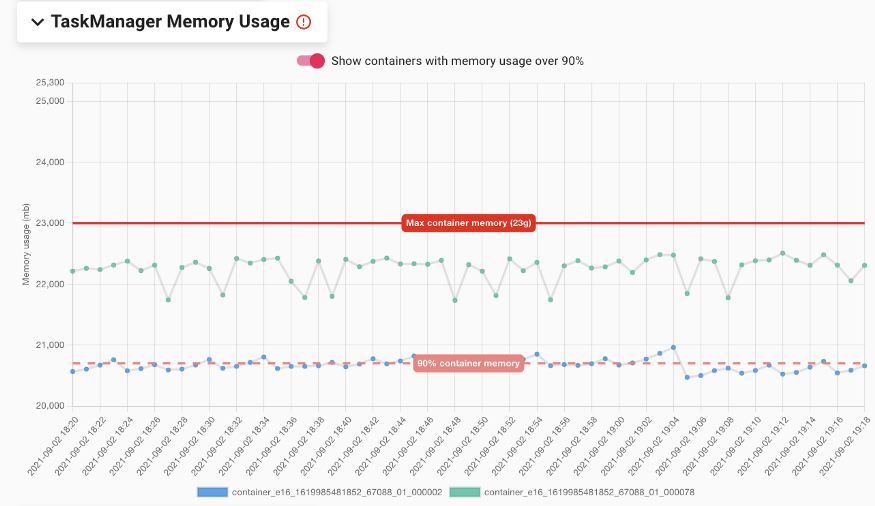
- JobManager/TaskManager内存使用区域:追踪展示YARN容器的内存使用情况,即通过运行在工作节点上的驻留进程收集Flink Java进程的常驻集规模(resident set size,RSS)。RSS内存包含所有Flink内存模型和未被Flink追踪的内存部分,例如JVM进程堆栈、线程元数据、使用JNI的用户代码内存分配,由此更为准确地展示了内存的使用情况。该区域中标记了配置后的最大JM/TM内存,以及90%使用阀值,为用户快速定位接近出现OOM问题的具体容器。
- CPU使用率区域:巡视所有使用CPU资源高于指定vcore的容器,帮助监控并避免在多租户Hadoop集群中出现“不安分的邻居”(Noisy neighbor)问题。即如果单个用户工作负载的CPU使用率过高,会影响到其它用户的性能和稳定性。
有效配置
Flink任务可在不同层级上配置,例如执行层的in-code配置,客户层的任务属性文件和命令行参数,以及系统层的flink-conf.yaml文件。在测试和热修复(hotfix)中,工程人员常常会发生在不同层级配置同一参数的问题。由于各层级间存在各异的覆盖关系,很难考虑到具体那一层级上的配置值是最终生效的。为解决这个问题,我们构建了一个配置库,指明任务运行中所使用的有效配置值,并提供给Dr. Squirrel展示。
可查询的聚类任务健康状况
Dr. Squirrel提供了丰富的任务状态展示,是掌握逐个集群任务健康状态的资源中心,并为探究平台改进提供洞悉。例如,列出排名前十位的重启根本致因,出现内存或反压问题任务的百分比等。
架构
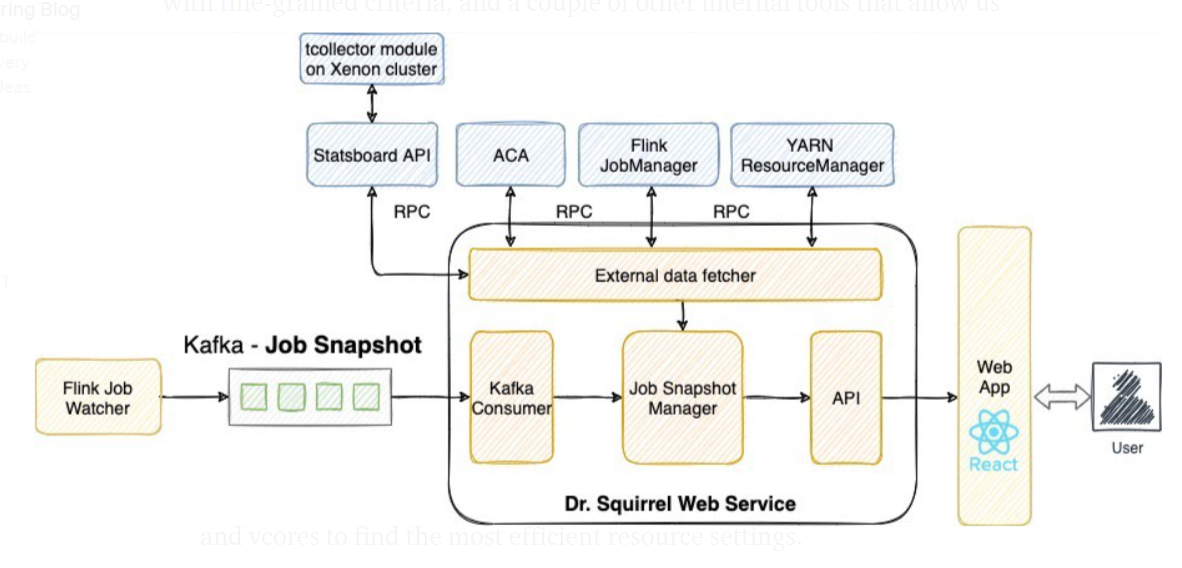
如上特性所示,度量和日志将汇集到同一处。为实现可扩展的信息采集,我们在自定义的Flink版本中添加了MetricReporter和KafkaLog4jAppender组件,持续发送度量和日志到Kafka Topic。此外,KafkaLog4jAppender还提供对我们很重要的日志的过滤功能,即堆栈跟踪(stacktrace)所给出的警告、错误和信息日志。随后,由作为Flink任务的FlinkJobWatcher执行一系列分析和转换,实现该任务度量和日志的连接运算。FlinkJobWatcher每隔5分钟创建一次任务健康快照,发送给作为Kafka Topic的JobSnapshot。
随着Flink用例的不断增长,导致生成大量的日志和度量。作为Flink任务,FlinkJobWatcher能处理不断增长的数据规模,易于并行调优,保证系统通量能匹配用例数量增长。
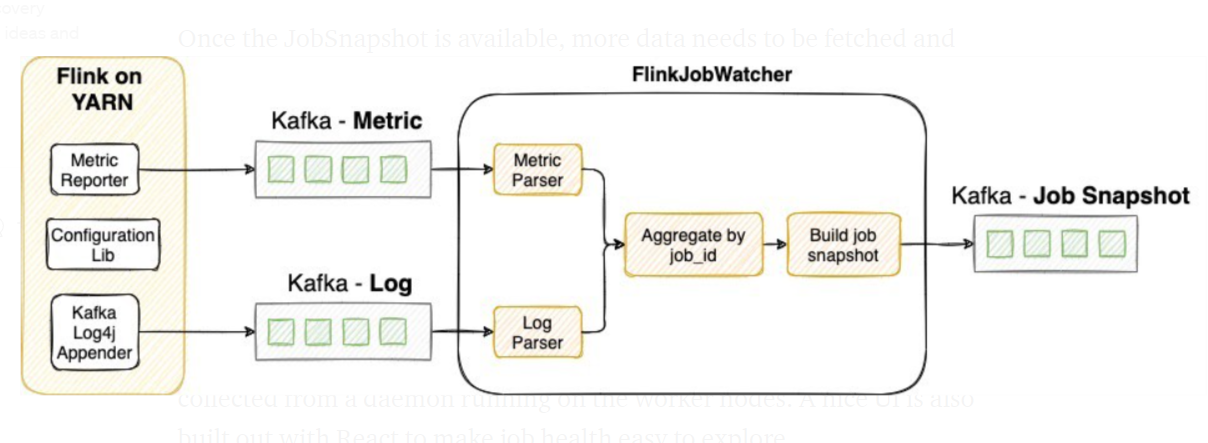
随着JobSnapshot的启用,越来越多的数据需获取和归并到JobSnapshot。针对此,我们使用dropwizard构建了RESTful服务,不断读取JobSnapshot Topic,并通过RPC拉取外部数据。其中,外部数据源包括从YARM ResourceManager获取的用户名和加载时间等静态数据、Flink REST API获取的配置、对比时序度量是否符合细粒度标准下阈值的内部工具Automated Canary Analysis(ACA),以及其他一些内部查看工具,它们通过运行工作节点驻留进程采集RSS内存、CPU使用率等自定义度量。我们还使用React实现前端用户界面,可更好地查看健康状态。
展望
我们将持续改进Dr. Squirrel,以提供更好的诊断能力,进而实现完全自助式检查。具体包括:
- 容量规划:监控并评估系统通量、内存和vcore使用情况,进而找出最有效的资源设置。
- 与CI/CD的集成:运行CI/CD流水线自动化,实现更改从开发到生产环境的验证和推送。我们将集成Dr.Squirrel到CI/CD,以推送新更改,提供更确切的任务健康情况。
- 报警和通知:向任务所有者和平台团队汇总报告健康状况。
- 任务粒度的代价估计:基于资源的使用情况,给出每个任务的代价估计,为预算的规划和掌控提供参考。
更多Pinterest流处理参考资料:
- Pinterest的统一Flink源:流数据处理(Unified Flink Source at Pinterest: Streaming Data Processing)
- 使用Apache Flink实现近实时图像相似度检测(Detecting Image Similarity in (Near) Real-time Using Apache Flink)
- Pinterest的视频架构:从Lambda到Kappa架构的演进(Pinterest Visual Signals Infrastructure: Evolution from Lambda to Kappa Architecture)
- 基于Apache Flink的Pinterest实验性实时业务平台(Real-time experiment analytics at Pinterest using Apache Flink)
原文链接: Faster Flink adoption with self-service diagnosis tool at Pinterest
