@Rays
2022-12-06T15:25:06.000000Z
字数 4125
阅读 1934
LINE是如何在大规模数据平台上引入数据族系功能
摘要: 随着LINE数据流水线的复杂性与日俱增,在发生数据相关的问题时,难以弄清楚数据间的关系。为此,LINE数据平台部门在内部系统中引入了数据族系功能。数据族系提供对特定目标数据的追踪功能,包括数据如何生成,直至发展为当前的状态,以及数据在该路径上的变更情况。本文介绍了LINE数据族系功能的设计、配置和功能。
作者: Shinji Shimamura
正文:
大家好,我是LINE数据平台部门IU开发团队的岛村真司。
数据平台部门运营着一个数据规模约400PB的分析平台,称为“IU”(Information Universe,信息宇宙)。LINE各个应用生成的数据,由IU收集、处理、分析并可视化,提供给LINE员工使用。我所在的IU开发团队,一直致力开发IU Web,提供数据编目功能,支持LINE各部门的每个服务安全高效地使用IU数据。
我们在开发IU中曾面对的一个挑战是,随着数据流水线的复杂性与日俱增,在发生数据相关的问题时,数据间的关系会越来越难以理解。为解决该挑战,我们在IU Web中引入了数据族系功能。下面我将分享数据族系的功能,在开发中存在的问题,以及最终的解决方案。
LINE为什么要引入数据族系
企业要基于可靠的数据做出决策,一个重要前提是企业应提升对自身数据系统状态的认知能力,即数据可观察性。数据族系被定位为数据可观察性的五大支柱之一。数据族系赋能对特定目标数据的追踪,包括数据如何生成,直至发展为当前的状态,以及数据在该路径上的变更情况。数据族系使用户可以轻松地追踪数据错误,掌握数据的依赖关系。但随着数据量的增加,以及数据平台上相关组织数量的增加,数据流水线变得更为复杂,数据族系也变得愈发难以理解。
正如我们在去年LINE开发者日中所分享的(以日语撰写),IU处理着大量的数据(每日近15万个任务),面对如下挑战:
数据生成任务一旦失败,调试难度大;
- 在数据生成任务失败时,我们的惯常做法是查看该任务的源代码,查明数据生成所使用的数据表,确定该数据表中是否存在分区。
更改数据表模式时,难以判定其影响范围;
- 在更改数据表模式时,我们的惯常做法是找出受到影响的数据表,并检查这些数据表的属主。
为解决上述挑战,我们着手开发了数据族系。
数据族系的设定目标
面对挑战,我们设定数据族系应实现的功能如下:
- 支持对数据相关问题的有效、全面审视;
- 提升对数据变更影响情况的初步测定。
数据族系的功能
下面分享在IU Web中实际开发的数据族系功能。
表族系
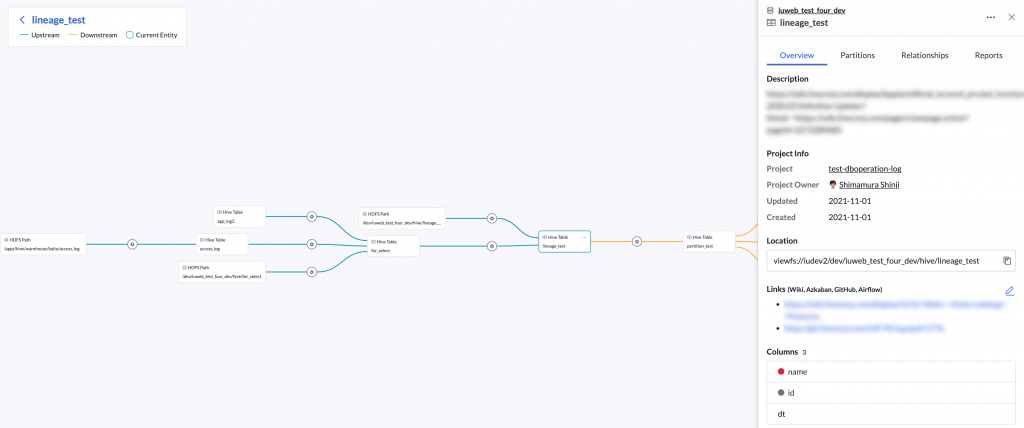
表族系支持图形方式查看数据表间的关系,展示选定数据表的属主、分区等元数据。下图中,绿色箭头显示上游情况,即数据生成后到选定表的路径情况;橙色箭头显示下游情况,即指定数据表变更所影响的数据集的情况。
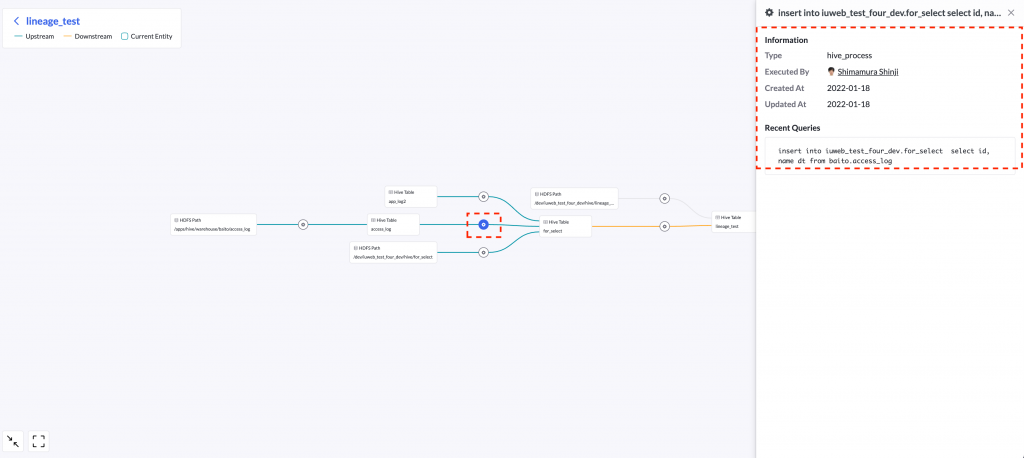
选择齿轮图标,会显示数据生成所执行查询的相关信息。
列族系
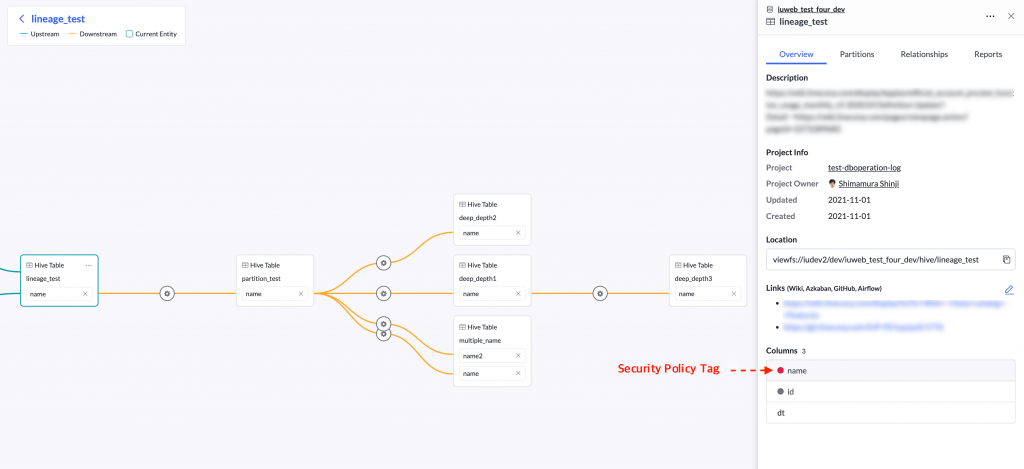
列族系以图形方式显示数据列间的关系,方便用户查看数据列更改的影响范围,了解哪里使用了高安全级数据列。例如,下图显示以红色圆圈标识的“name”数据列的数据族系。红色圆圈表示已为该数据列设置了高安全级的标签。
仪表盘族系
仪表盘族系显示OASIS仪表盘与数据表的关联关系。OASIS是IU内部开发提供的一个报告工具。仪表板族系功能使用户能精准把握数据源和数据使用情况,在数据发生更改或故障时掌握仪表盘的受影响情况,并指向具体的数据用例。
https://s1.ax1x.com/2022/12/05/zyPua4.png
通知功能
为实现用户对数据异常和变更的即刻检测,数据族系提供了两类通知功能。
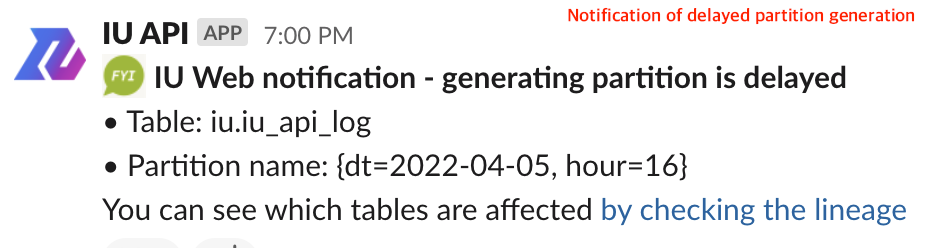
- 分区生成延迟的通知:一旦分区生成发生延迟,就通过Slack Channel发出通知。Slack通知会关联到分区生成延迟表的表族系,使用户有效调查数据源中导致延迟的位置。
- 数据库(表)更改的通知:一旦属性信息变更,就发出通知,包括数据库(表)模式、标签和描述。使用数据族系的情况下,如果在数据表上设定了通知,那么一旦该表的数据生成路径产生变更,也发出通知。该功能使得用户能及时获悉变更对每个操作和系统的影响。
系统配置
下面介绍实现上述数据族系功能的系统配置。
Apache Atlas
Apache Atlas用于获取数据表之间的关系。先介绍一下Atlas。Atlas是一个开源的数据编目系统,使用Apache Hive、Apache Spark等存储数据更改产生的元数据。除了数据族系功能,Atlas还可以用于元数据搜索、标签和权限管理等。
族系的系统配置
IU Web当前支持Hive族系和仪表盘族系。
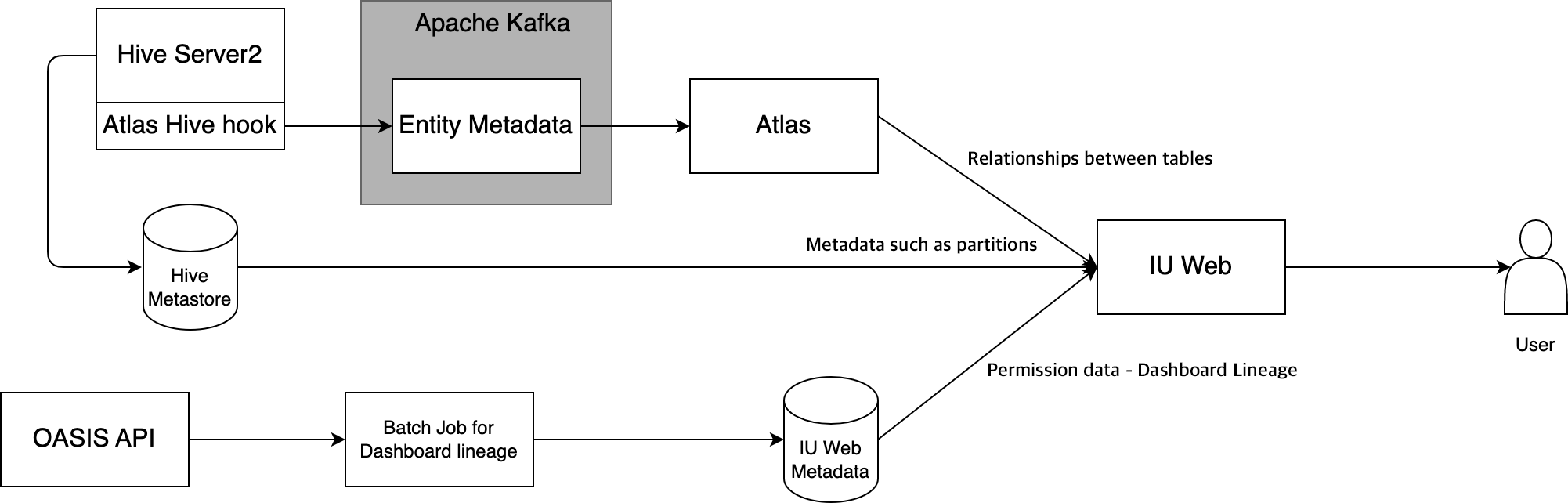
首先介绍Hive族系的系统配置。如下图所示,Hive族系在HiveSever2上部署了由Atlas提供的Atlas Hive Hook,变更操作经由Apache Kafka注册到Hive中。IU Web使用Atlas REST API获取数据表之间的关系。最终,通过组合Atlas提供的带有认证信息的数据,以及Hive Metastore和IU Web中管理的仪表盘族系信息,显示数据族系。鉴于族系UI功能也是由Altas提供,通过将保持在IU Web和Hive Metastore中的信息添加到Atlas提供的信息中,可为用户给出一些有用的功能。
在上面的功能描述中,仪表盘族系是关联到OASIS仪表盘的。通过分析其中包含的SQL查询,实现与仪表盘的关联。OASIS支持两种引擎,即Trino和Spark SQL。其中的关键问题,是如何实现SQL查询与数据编目的关联。IU Web使用了Trino和Spark SQL官方的解析库去分析SQL,抽取SQL查询中包含的数据表,保存并使用SQL查询和IU Web间的对应关系。截至2022年5月,已有约8.5万条SQL查询关联到数据表。
主要的挑战及我们的解决方案
Apache Atlas的性能问题
我们在使用Atlas REST API获取特定数据表的数据族系时,出现了性能问题。其主要原因在于,API调用增加了Atlas的内存消耗,导致Atlas挂起,不再可用,需要重启。我们数据平台部门与厂商Cloudera合作共同解决了这一问题,参见ATLAS-3590和ATLAS-3558。即便做了如上修复,某些表上的API调用依然耗时近30分钟,因此我们仍需去改进性能。
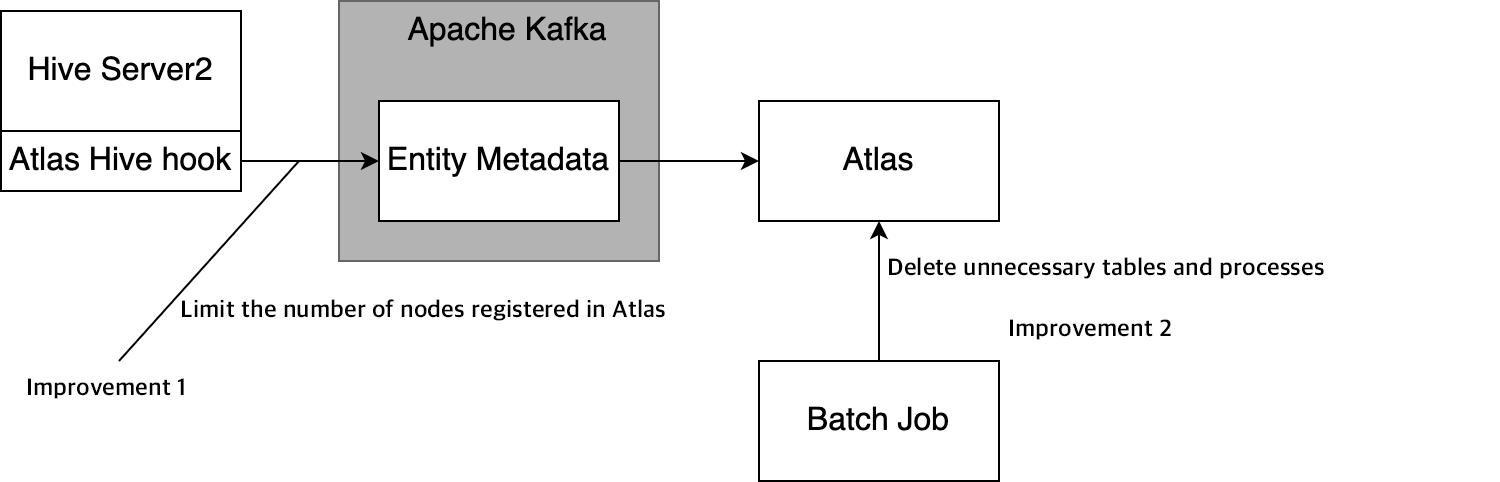
我们调查了导致Atlas API反应慢的原因,发现数据族系图的节点过多,导致显示的延迟。具体而言,我们发现每小时和每日任务会生成一些临时表。在每次任务执行时,连接到这些表的节点增加,导致图中的节点过多。为降低节点数量,我们引入如下两处改进:
- 降低Atlas注册到Hive中的节点数量:Altas Hive Hook提供了一个设置项,支持使用正则表达式禁用Atlas注册(即ATLAS-3006)。我们使用该设置项,避免含有“tmp”等标签临时表字符串的数据表注册到Atlas。这使得注册到Atlas的数据表数量降低了近90%。
- 使用批处理任务,移除Atlas中非必要的数据表和进程:尽管上述方法避免了临时表的注册,但每次任务执行时会在在一些特定表中增加与临时表相关的Hive Process节点,导致族系图中的节点增加。为解决这个问题,我们引入了批处理任务,从Atlas中移除了与临时表关联的Hive Process节点。该批处理任务每日移除近30万个节点。
通过引入上述改进,Atlas API的执行时间在通常情况下降至不高于6秒,最坏情况下不高于15秒。
复杂的数据族系
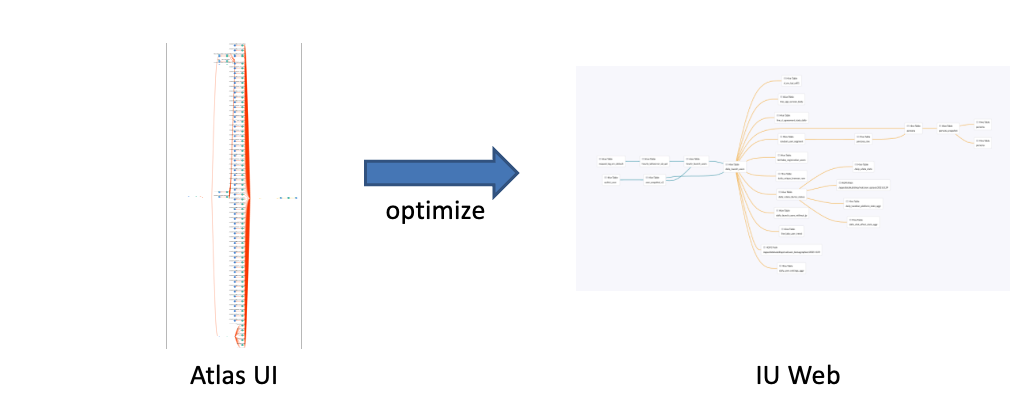
一些数据表中的数据族系节点过多,导致用户难以从中确认他们认定的数据生成路径。为解决该问题,我们在IU Web中对Atlas API返回的数据族系做了如下两处优化,实现仅显示用户所需的数据族系:
- 显示数据族系时,隐藏数据列:部分数据族系中,数据表直接连接到数据列。数据表具有许多列,会导致族系中存在大量节点。另一方面,我们发现如果数据表A和B中的列是相关的,那么A和B同样具有关联关系。隐藏数据列并不会移除数据表之间的关系。基于此,我们决定在显示表族系时隐藏数据列。
- 隐藏低重要性的HDFS路径节点:我们决定隐藏那些被认为并不重要的HDFS路径节点。例如,路径中包含“tmp”。
由此,我们简化了Atlas UI中复杂、难以理解的数据族系,更易于在IU Web中理解。效果如下图所示。
数据族系的使用效果和场景
LINE自2021年11月引入数据族系功能以来,使用者在逐渐增加。截至2022年5月,该功能已用于79个服务和部门,包括那些执行日常处理数据的部门,例如数据ETL、数据管理和数据科学部门。
尤其值得一提的是,我们收到数据ETL团队的反馈,现在易于确认数据表维护(即DROP TABLE和ALTER TABLE操作)期内的影响范围。此外,我们日常也在Slack上与IU使用者做交流,确认数据族系的使用情况,包括用于调查导致数据错误的原因等。
下一步计划
在确认了数据族系的使用效果后,我们计划在数据族系中增添更多的相关功能。下面给出计划中的两个功能:
- 扩展数据族系的追踪范围:短期目标是通过新添对Apache Spark和Hive Metastore数据族系的支持,实现对IU中大部分数据的覆盖。长期目标是实现对IU以外数据变更的追踪。支持用户在更大范围上理解数据关系。
- 提高安全治理:Atlas可以使用数据族系传播数据编目的策略标签。例如,如果在特定的数据表或列中对个人可识别信息做了标签,那么该标签会通过标签传播,自动分配给所有使用了该数据表的表。通过引入标签传播通知、标签设置和使用标签设置访问权限等功能,我们可以提高安全性。
总结
IU开发团队致力于解决大规模数据平台上构建数据编目中所面对的问题。我们招募有志于为LINE雇员提供数据支持的人,以及对数据相关技术领域感兴趣的人。为了进一步提升企业的数据利用,我们面对很多亟待解决的问题,而我们的人手依然不足。对此有兴趣者,可通过如下链接申请加入我们团队。需要注意的是,大数据相关经验的要求并非必要前提。我在加入团队时,也没有此项的相关经验。
原文链接:A story of introducing data lineage into LINE's large-scale data platform
