@Sherlockyang
2019-01-16T13:18:41.000000Z
字数 1952
阅读 520
PAC and regret
论文阅读
这篇论文提及到,在大型的或者无限状态的MDP中,通过采样模型,一些MDP中的状态转移是可以用一些状态模型观测得到的。此时,采样复杂度就是为了达到学习目的,所需要的某种采样模式的次数。
This thesis considers various sampling models in which transitions based on the MDP can be observed by calling the sampling model.
The sample complexity can be construed to be the number of calls to the sampling model required to achieve "learning".
定义:Generative Model 是一个随机算法,即输入,能根据状态转移概率类似于自生自灭。
这种模式可以允许agent根据,重置当前状态到一个被采样的状态去。
2.near-optimal
文中试图用一种方式去讲解什么是near-optimal
关于phased value iteration 这个例子,作者给出了证明,证明其只要使用了采样算法(Generation model)被使用了
即被采用并用于估计Transition这么多次,则有大于得概率使得返回策略对于所有的状态来说:
image_1d1bcv57689p1p6p1ume17f6i222d.png-66.8kB
其证明如下:
假设有如下式子成立:
所以:
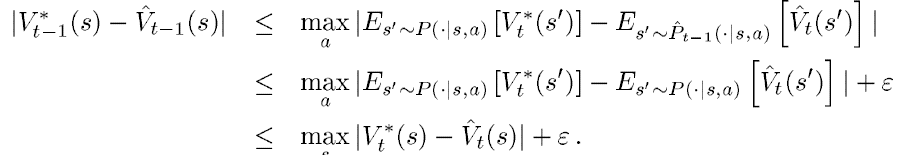
同理,则有对于贪婪策略也有如下推导
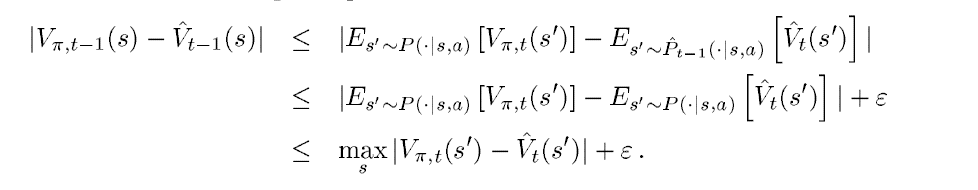
使用迭代公式,很容易得出如下结论
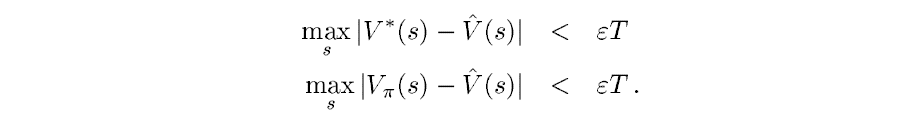
因此则有如下:
但是,我们希望的是得到一个
这样的误差,所以,问题是需要提高该值的精度
即让当前的
要对所有的(s,a),都要成立,则有如下边界:
推出
即
此时 由霍伊夫定不等式可以得到,有的概率可以让其值在满足:
或者(个人比较喜欢下一种)
关于2的总结
要想达到上述目标,关键是在于其假设的估计值与期望值的差距大小,似乎是一种PAC的方式,我目前不清楚是否后文会给出详细的PAC的证明,但是现在从目前的理解来看,这个东西就有点像算法。即如何设置一个值来保证其在这些学习过程中,能够达到近似最优(near-optimal)
