@awsekfozc
2016-01-27T03:13:29.000000Z
字数 3925
阅读 3574
hadoop2.x部署(SingleCluster)[1]
Hadoop
- JDK安装
- hadoop2.x安装,配置环境
- HDFS配置
- YARN配置
- 运行第一个mapreduce
1.JDK
检查是否安装JDK
$rpm -qa|grep java
卸载已安装的JDK
$rpm -e --nodeps XXXX
解压安装包[2]
$ sudo chmod 755 jdk-7u67-linux-x64.tar.gz --修改权限$ sudo chown zhangcheng:zhangcheng jdk-7u67-linux-x64.tar.gz --修改档案拥有者,用户组$ tar -zxf jdk-7u67-linux-x64.tar.gz -C /opt/modules/ --解压JDK到/opt/modules/
配置环境变量
$ sudo vi /etc/profile --编辑环境变量配置文件--加入以下文本 JAVA_HOME=JDK的绝对路径## JAVA_HOMEexport JAVA_HOME=/opt/modules/jdk1.7.0_67export PATH=$PATH:$JAVA_HOME/bin--保存文件$ source /etc/profile --使环境变量生效$ java -version --验证安装结果
2.hadoop[3]
解压,删除无用文件 (可选)
$ tar -zxf hadoop-2.5.0.tar.gz -C /opt/modules/--可选项,删除doc文档$ cd /opt/modules/hadoop-2.5.0/share$ rm -rf doc/--可选项,删除cmd文件$ cd /opt/modules/hadoop-2.5.0/sbin$ rm -rf ./*.cmd$ cd /opt/modules/hadoop-2.5.0/libexec$ rm -rf ./*.cmd$ cd /opt/modules/hadoop-2.5.0/etc/hadoop$ rm -rf ./*.cmd
配置环境
hadoop环境配置文件都置于/opt/modules/hadoop-2.5.0/etc/hadoop目录之下。使用Notepad++来配置。
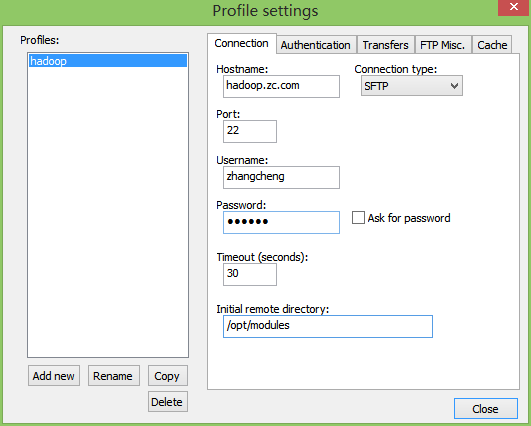
标签: hadoop配置
文件:/opt/modules/hadoop-2.5.0/etc/hadoop/hadoop-env.sh
配置内容:
<!-- hadoop-env.sh,配置hadoop的JAVA_HOME -->export JAVA_HOME=/opt/modules/jdk1.7.0_67<!-- yarn-env.sh,配置yarn的JAVA_HOME -->export JAVA_HOME=/opt/modules/jdk1.7.0_67<!-- mapred-env.sh,配置mapreduce的JAVA_HOME -->export JAVA_HOME=/opt/modules/jdk1.7.0_67
3.HDFS
core-site.xml(namenode配置)
<!-- 配置namenode地址 --><!-- value说明:hdfs地址 --><configuration><property><name>fs.defaultFS</name><value>hdfs://hadoop.zc.com:8020</value></property></configuration>
slaves(datanode配置)
<!-- 添加使用机的主机名 -->hadoop.zc.com
hdfs-site.xm(配置副本数)
<!-- 配置副本数 --><!-- value说明:副本的数量 --><configuration><property><name>dfs.replication</name><value>1</value></property></configuration>
格式化HDFS
$ bin/hdfs --查看命令$ bin/hdfs namenode -format --格式化HDFS<!--查看日志:INFO common.Storage: Storage directory /tmp/hadoop-zhangcheng/dfs/name has been successfully formatted.-->
启动HDFS
<!--启动namenode-->$ sbin/hadoop-daemon.sh start namenode<!--启动datanode-->$ sbin/hadoop-daemon.sh start datanode<!--查看启动-->$ jps<!--启动出错请查看日志:/opt/modules/hadoop-2.5.0/logs-->
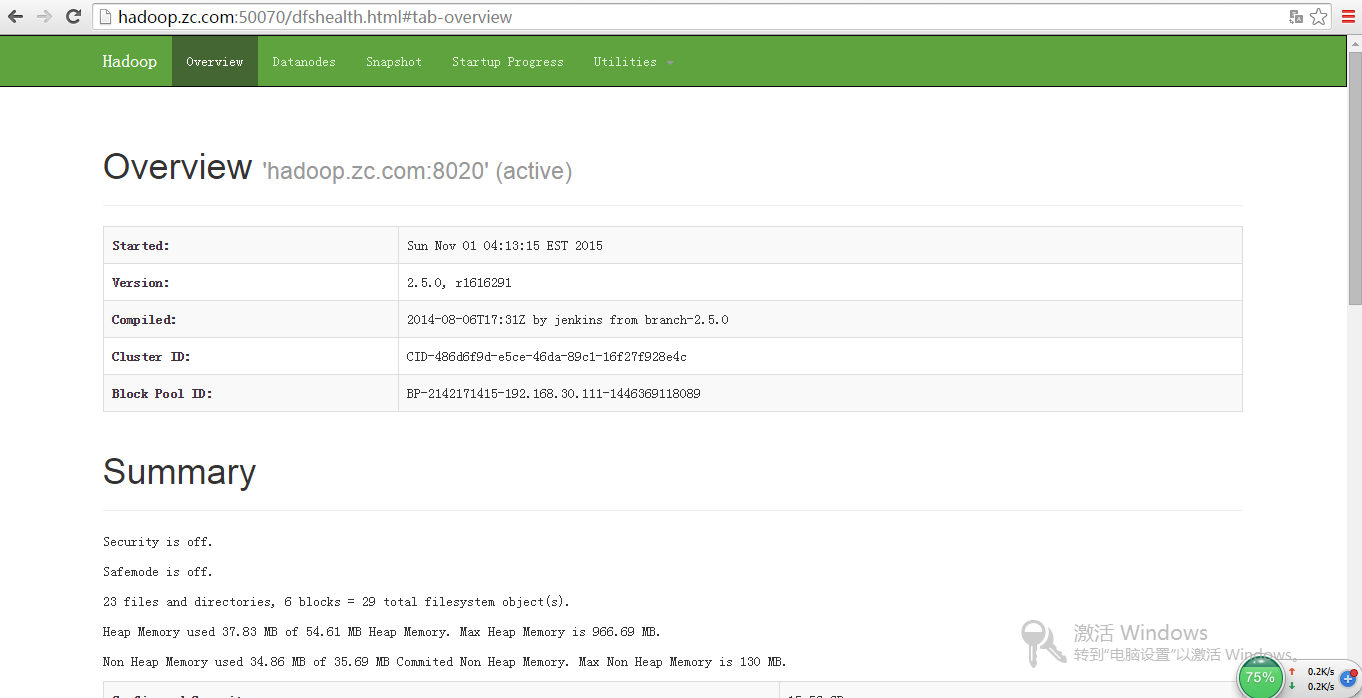
运行HDFS管理web
上传,读取,下载
<!--新建目录-->$ bin/hdfs dfs -mkdir -p /user/zhangcheng/tmp<!--上传文件-->$ bin/hdfs dfs -put etc/hadoop/core-site.xml /user/zhangcheng/tmp<!--读取文件-->$ bin/hdfs dfs -cat /user/zhangcheng/tmp/core-site.xml<!--下载文件-->$ bin/hdfs dfs -get /user/zhangcheng/tmp/core-site.xml /home/zhangcheng/g-core-site.xml
4.YARN
yarn-site.xml
<configuration><!--配置服务框架(以下为mapreduce框架的配置,NodeManager)--><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property><!--配置ResourceManager--><property><name>yarn.resourcemanager.hostname</name><value>hadoop.zc.com</value></property></configuration>
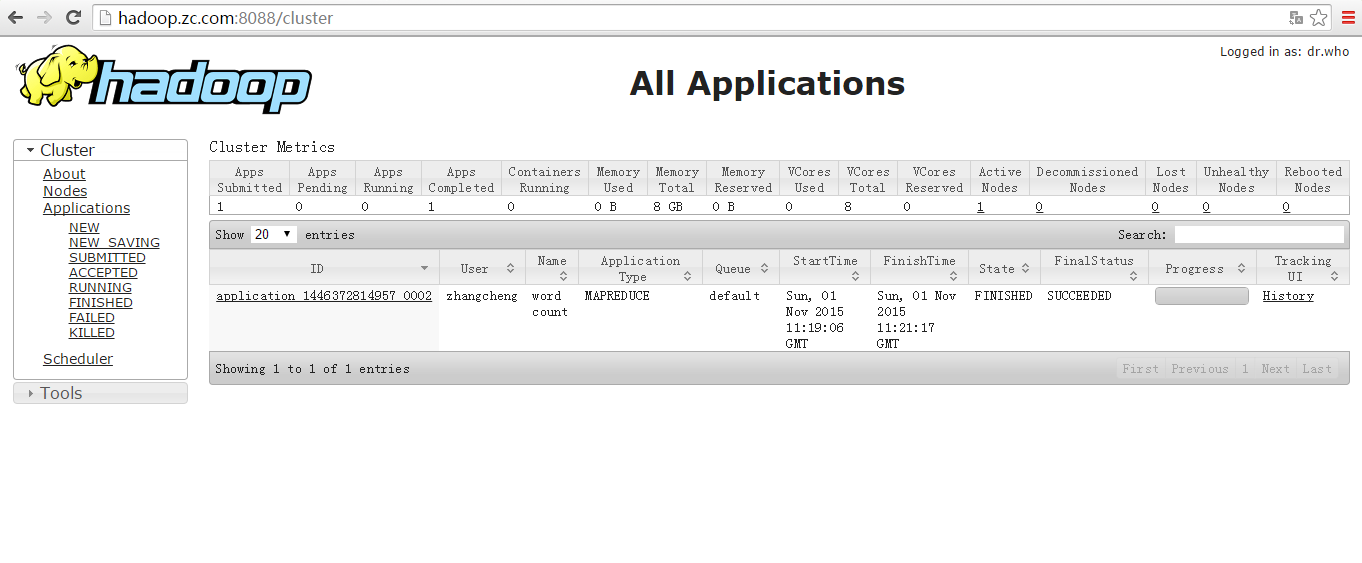
启动YARN管理WEB
<!--启动ResourceManager-->$ sbin/yarn-daemon.sh start resourcemanager<!--启动NodeManager-->$ sbin/yarn-daemon.sh start nodemanager<!--启动出错请查看日志:/opt/modules/hadoop-2.5.0/logs-->
5. 第一个mapreduce(wordcount)
运行在yarn配置
<!--mapred-site.xml(mapred-site.xml.template改名)--><!--配置mapreduce运行在yarn上--><configuration><property><name>mapreduce.framework.name</name><value>yarn</value></property></configuration>
准备input目标
<!--新建或者是已有文件-->$ vi wc.inp<!--上传要wordcount的文件-->$ bin/hdfs dfs -put /opt/datas/wc.inp /user/zhangcheng/mapreduce/wordcount/input
运行wordcount
<!--input,output-->$ bin/yarn jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.5.0.jar wordcount /user/zhangcheng/mapreduce/wrodcount/input/ /user/zhangcheng/mapreduce/wordcount/output/<!--查看运行结果-->$ bin/hdfs dfs -text /user/zhangcheng/mapreduce/wordcount/output/part-r-0000

[1] http://hadoop.apache.org/docs/current/hadoop-project-dist/hadoop-common/SingleCluster.html ↩
[2] 普通账户加入sudo权限。方法:切换到root用户
# vi /etc/sudoers
在第一行添加如下内容:
zhangcheng ALL=(root)NOPASSWD:ALL ↩
[3] 地址:https://archive.apache.org/dist/hadoop/common/ ↩
