@awsekfozc
2016-01-22T22:55:10.000000Z
字数 3540
阅读 3328
Spark RDD
Spark
1)RDD是什么
RDD,全称为Resilient Distributed Datasets 弹性分布式数据集,是一个容错的、并行的数据结构(分区的),可以让用户显式地将数据存储到磁盘和内存中,并能控制数据的分区。同时,RDD还提供了一组丰富的操作来操作这些数据。在这些操作中,诸如map、flatMap、filter等转换操作实现了monad模式,很好地契合了Scala的集合操作。除此之外,RDD还提供了诸如join、groupBy、reduceByKey等更为方便的操作(注意,reduceByKey是action,而非transformation),以支持常见的数据运算。
2)RDD五大特性
- A list of partitions
- 代码:protected def getPartitions: Array[Partition]
- 一个只读的分区记录集合,默认HDFS的每个块对应一个partition.
- A function for computing each split
- 代码:def compute(split: Partition, context: TaskContext): Iterator[T]
- 每个分区并行执行任务
- A list of dependencies on other RDDs
- 代码:protected def getDependencies: Seq[Dependency[_]] = deps
- RDD可以相互依赖。如果RDD的每个分区最多只能被一个Child RDD的一个分区使用,则称之为narrow dependency;若多个Child RDD分区都可以依赖,则称之为wide dependency。不同的操作依据其特性,可能会产生不同的依赖。例如map操作会产生narrow dependency,而join操作则产生wide dependency。
- Optionally, a Partitioner for key-value RDDs
- 代码:@transient val partitioner: Option[Partitioner] = None
- 对于key-value对的RDD,可以对结构指定partition
- Optionally, a list of preferred locations to compute each split on
- 代码:protected def getPreferredLocations(split: Partition): Seq[String] = Nil
- 本地性,优先读取本地数据
3)RDD创建
Parallelized Collections
scala> val data = Array(1, 2, 3, 4, 5)scala> val distData = sc.parallelize(data)
External Datasets
Spark can create distributed datasets from any storage source supported by Hadoop, including your local file system, HDFS, Cassandra, HBase, Amazon S3, etc. Spark supports text files, SequenceFiles, and any other Hadoop InputFormat.
scala> val distFile = sc.textFile("data.txt")
4)RDD API
map
map是对RDD中的每个元素都执行一个指定的函数来产生一个新的RDD。任何原RDD中的元素在新RDD中都有且只有一个元素与之对应。
scala> val a = sc.parallelize(1 to 9, 3)scala> val b = a.map(x => x*2)scala> a.collectres10: Array[Int] = Array(1, 2, 3, 4, 5, 6, 7, 8, 9)scala> b.collectres11: Array[Int] = Array(2, 4, 6, 8, 10, 12, 14, 16, 18)
mapPartitions
mapPartitions是map的一个变种。map的输入函数是应用于RDD中每个元素,而mapPartitions的输入函数是应用于每个分区,也就是把每个分区中的内容作为整体来处理的。
scala> val a = sc.parallelize(1 to 9, 3)scala> def myfunc[T](iter: Iterator[T]) : Iterator[(T, T)] = {var res = List[(T, T)]()var pre = iter.next while (iter.hasNext) {val cur = iter.next;res .::= (pre, cur) pre = cur;}res.iterator}scala> a.mapPartitions(myfunc).collectres0: Array[(Int, Int)] = Array((2,3), (1,2), (5,6), (4,5), (8,9), (7,8))
上述例子中的函数myfunc是把分区中一个元素和它的下一个元素组成一个Tuple。因为分区中最后一个元素没有下一个元素了,所以(3,4)和(6,7)不在结果中。
mapPartitions还有些变种,比如mapPartitionsWithContext,它能把处理过程中的一些状态信息传递给用户指定的输入函数。还有mapPartitionsWithIndex,它能把分区的index传递给用户指定的输入函数。
flatMap
与map类似,区别是原RDD中的元素经map处理后只能生成一个元素,而原RDD中的元素经flatmap处理后可生成多个元素来构建新RDD。
举例:对原RDD中的每个元素x产生y个元素(从1到y,y为元素x的值)
scala> val a = sc.parallelize(1 to 4, 2)scala> val b = a.flatMap(x => 1 to x)scala> b.collectres12: Array[Int] = Array(1, 1, 2, 1, 2, 3, 1, 2, 3, 4)
reduceByKey
顾名思义,reduceByKey就是对元素为KV对的RDD中Key相同的元素的Value进行reduce,因此,Key相同的多个元素的值被reduce为一个值,然后与原RDD中的Key组成一个新的KV对。
scala> val a = sc.parallelize(List((1,2),(3,4),(3,6)))scala> a.reduceByKey((x,y) => x + y).collectres7: Array[(Int, Int)] = Array((1,2), (3,10))
5)RDD dependency
RDD作为数据结构,本质上是一个只读的分区记录集合。一个RDD可以包含多个分区,每个分区就是一个dataset片段。RDD可以相互依赖。如果RDD的每个分区最多只能被一个Child RDD的一个分区使用,则称之为narrow dependency;若多个Child RDD分区都可以依赖,则称之为wide dependency。不同的操作依据其特性,可能会产生不同的依赖。例如map操作会产生narrow dependency,而join操作则产生wide dependency。
6)RDD Shuffle
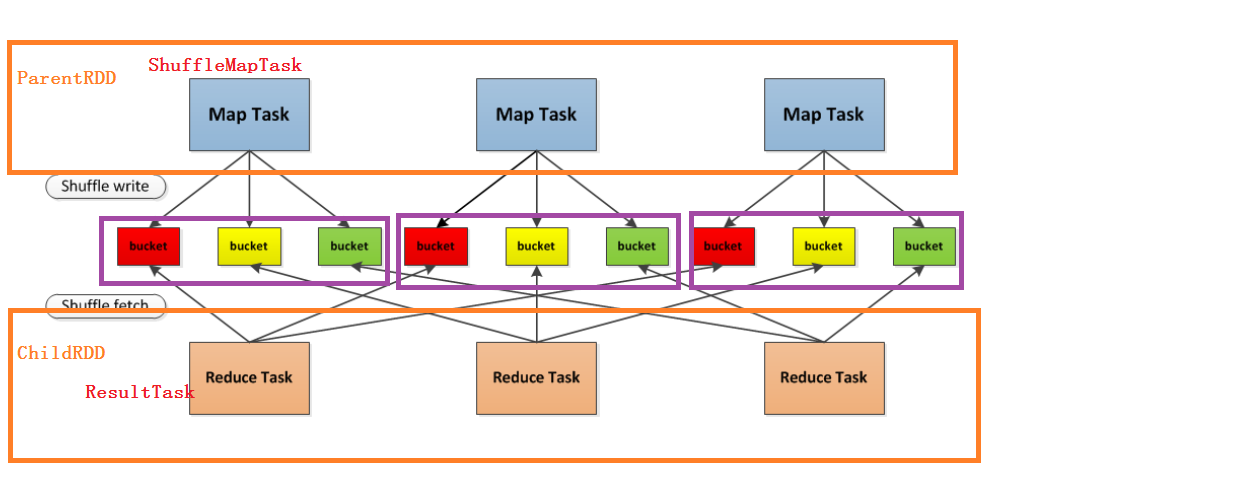
- 首先每一个Mapper会根据Reducer的数量创建出相应的bucket,bucket的数量是M×RM×R,其中MM是Map的个数,RR是Reduce的个数
- 其次Mapper产生的结果会根据设置的partition算法填充到每个bucket中去。这里的partition算法是可以自定义的,当然默认的算法是根据key哈希到不同的bucket中去。
- 当Reducer启动时,它会根据自己task的id和所依赖的Mapper的id从远端或是本地的block manager中取得相应的bucket作为Reducer的输入进行处理。
7)Spark Job submit
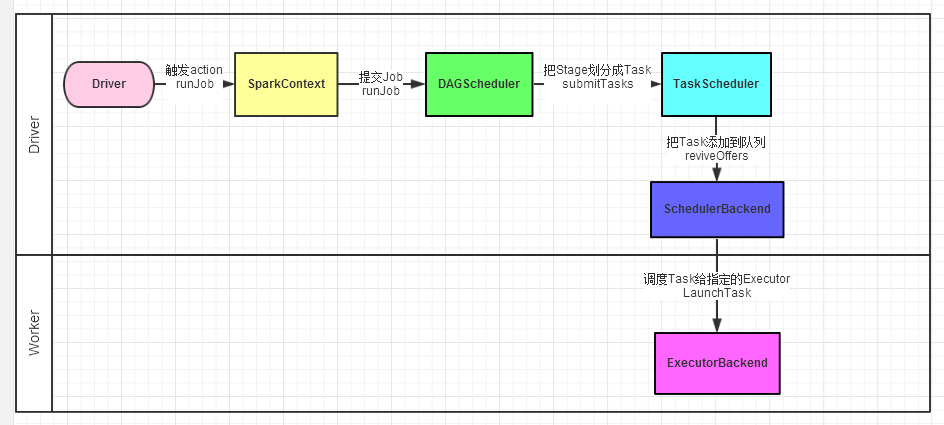
- Driver程序的代码运行到action操作,触发了SparkContext的runJob方法。SparkContext创建Executors
- SparkContext调用DAGScheduler的runJob函数。
- DAGScheduler把Job倒推划分stage,然后把stage转化为相应的Tasks,把Tasks交给TaskScheduler。
- 通过TaskScheduler把Tasks添加到任务队列当中,交给SchedulerBackend进行资源分配和任务调度。
- 调度器给Task分配执行Executor,ExecutorBackend负责执行Task。
在此输入正文
