@awsekfozc
2016-02-18T13:24:14.000000Z
字数 1815
阅读 2503
Spark 安装
Spark
一、编译Spark
1) 检查网络 ping www.baidu.com
关闭hadoop等相关服务
2) 安装jdk和Maven
jdk版本1.6+
Maven版本3.0.4+
3)Maven镜像
如果编译不成功就添加
4)google DNS
/etc/resolv.conf
加入内容
nameserver 8.8.8.8nameserver 8.8.4.4
5)解压spark,并修改make-distribution.sh文件第129行到131行
VERSION=1.3.0SPARK_HADOOP_VERSION=2.5.0SPARK_HIVE=1SCALA_VERSION=2.10.4
6)安装scala
A、解压scala
B、配置环境变量
输入scala -version提示如下,说明安装成功

编译命令,使用此命令 需要删除setting.xml文件中设置的 maven仓库地址
./make-distribution.sh --tgz -Pyarn -Phadoop-2.4 -Dhadoop.version=2.5.0-cdh5.3.6 -Phive -Phive-thriftserver -Phive-0.13.1
看打这个界面 说明spark编译成功了,编译过程中scala会报很多警告,直接忽略就好。
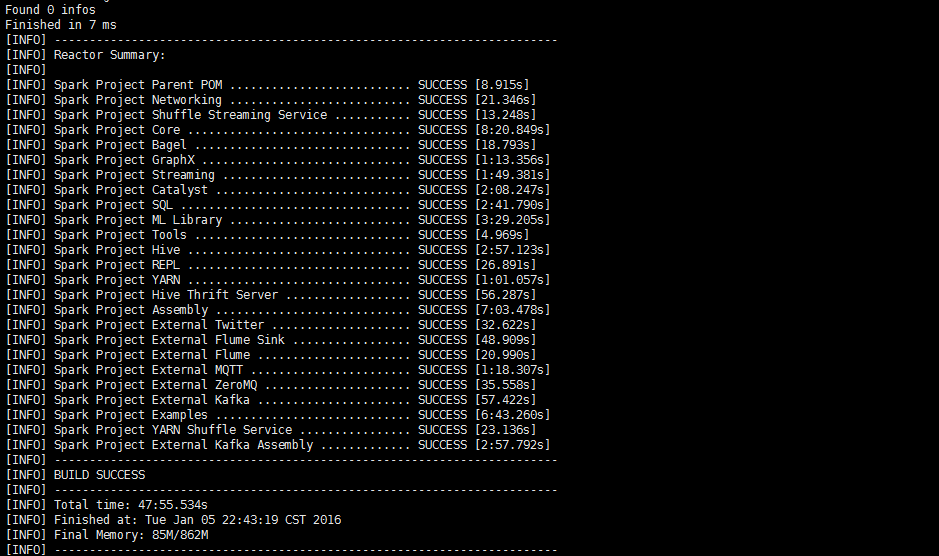
二、spark standalone
1)修改spark-env.sh,加入内容
JAVA_HOME=/opt/moduels/jdk1.7.0_67SCALA_HOME=/opt/moduels/scala-2.10.4HADOOP_CONF_DIR=/opt/moduels/hadoop-2.5.0/etc/hadoop###standalone siteSPARK_MASTER_IP=hadoop.zc.comSPARK_MASTER_PORT=7077SPARK_MASTER_WEBUI_PORT=8080SPARK_WORKER_CORES=2SPARK_WORKER_MEMORY=2gSPARK_WORKER_PORT=7078SPARK_WORKER_WEBUI_PORT=8081SPARK_WORKER_INSTANCES=1
2)配置wrok
###slaveshadoop.zc.com
3)启动
$ sbin/start-master.sh$ sbin/start-slaves.sh$ bin/spark-shell --master spark://hadoop.zc.com:7077
看到这个,就说spark本地模式启动成功
3)sc 对象基本API,这是需要启动Namenode和datanode
var rdd = sc.textFile("README.md") ;/*读取HDFS当前目录下的README.md文件*/rdd.count /*读取文件的行数*/rdd.count() /*读取文件行数Scala,调用无参数的方法 可以不带小括号*/rdd.first /*读取文件的第一行内容*//*统计文件内包含的某个单词的数量的集中不同方式*/rdd.filter((line: String) => line.contains("Spark")).countrdd.filter((line) => line.contains("Spark")).countrdd.filter(line => line.contains("Spark")).countrdd.filter(_.contains("Spark")).count/*scala wordcount*/var array = sc.textFile("hdfs://cdh5.hadoop.com:8020/user/gary/README.md").flatMap(_.split(" ")).map((_,1)).reduceByKey((_+ _)).collect
在此输入正文
