@boothsun
2025-06-06T07:46:12.000000Z
字数 7089
阅读 1592
InnoDB和MyISAM对比
MySQL
参考原文地址如下:
1. MySQL数据库InnoDB存储引擎Log漫游(1)
2. 轻松理解MYSQL MVCC 实现机制
3. 关于innodb中MVCC的一些理解
MyISAM与InnoDB的对比
| 特性 | MyISAM | InnoDB |
|---|---|---|
| 事务 | 不支持 | 支持 |
| 锁粒度 | 表级锁 | 行级锁 + 表级锁 |
| 外键 | 不支持 | 支持 |
| 全表行数查询 | 通过内置计数器保存表具体行数 | 全表扫描计算 |
| 构成上的区别 | 每个MyISAM在磁盘上存储为三个文件。文件名字都是以表名开头。 主要分为以下三种: 1. .frm(表定义) 2. .MYD(MyData 表数据) 3. .MYI(My Index 索引文件) |
InnoDB使用聚簇索引,所有数据都存储在一个文件中 |
InnoDB事务的实现原理
InnoDB的隔离性是由锁实现的;原子性、一致性、持久性是通过数据库的redo日志和undo日志来完成的。redo log 称为重做日志,用来保证事务的原子性和持久性。undo log用来保证事务的一致性。
隔离性实现
原子性、一致性、持久性实现原理
redo log:
redo log是新数据的备份,在事务COMMIT操作完成之前,InnoDB会要求必须先将该事务的所有操作日志写入到redo log中,而不需要将数据持久化。当系统崩溃后,虽然数据还没有持久化,但是Redo log 已经持久化了,MySQL可以根据Redo log的内容,将所有数据恢复到最新的状态。通过这种方式实现事务的持久性和原子性。
再细化一点的内部操作是,在事务执行过程中,InnoDB会将执行过程写到内存中的重做日志缓冲区(redo log buffer),在事务执行成功执行完毕后,InnoDB会将内存中的日志缓冲区内log同步到磁盘上的重做日志文件(redo log file)中,从而以文件的形式固化;如果事务执行过程中失败或者回滚等,可由应用程序进行回滚或者在Connection超时断开时自动Rollback;如果事务执行过程中,发生MySQL故障或者机器故障,则内存中的重做日志缓冲区将会丢失,自动回滚,也不会持久化到MySQL中,这样就实现了事务的原子性。
在MySQL宕机恢复后,写到磁盘的redo log将会由MySQL自动持久化到MySQL数据区,也不会产生丢失。这样就实现了事务的持久性。
undo log:
记录了事务修改前的数据状态,是对修改前数据的一种备份,是为了事务回滚操作做的准备。假设修改tb表中id=2的行数据,把Name="B"修改为Name="B2",那么undo日志就会用来存放Name=“B”的记录,如果这个修改出现异常,可以使用undo日志来实现回滚操作,保证事务的一致性。
对数据的变更操作,主要来自 insert update delete,而undo log中分为两种类型,一种是 insert_undo( insert操作 ),记录插入的唯一键值;一种是update_undo(包含update及delete操作),记录修改的唯一键值以及old column记录。
当事务回滚时,InnoDB将执行相反的操作。对于每个insert,会从undo日志中获取唯一键值来完成delete操作;对于每个delete,InnoDB存储引擎会执行一个insert将 old column记录再次插入进去。对于每个update,InnoDB存储引擎会执行一个相反的update,将修改前的行放回去。
处理回滚操作,undo的另一个作用是MVCC,即在InnoDB存储引擎中MVCC的实现时通过undo来完成的。当用户读取一行记录时,若该记录已经被其他事务占用,当前事务可以通过undo读取之前的行版本信息,以此实现非锁定读取。
undo log 过程中也会产生redo log,这是因为undo log也需要持久性的保护。
Undo Log的过程可以简述如下:
假设有A、B两个数据,值分别为1,2,现在需要将其值改为3和4:
- A. 事务开始.
- B. 记录A=1到undo log.
- C. 修改A=3.
- D. 记录B=2到undo log.
- E. 修改B=4.
- F. 将undo log写到磁盘。
- G. 将数据写到磁盘。
- H. 事务提交
Undo + Redo事务的简化过程:
- A. 事务开始.
- B. 记录A=1到undo log.
- C. 修改A=3.
- D. 记录A=3到redo log.
- E. 记录B=2到undo log.
- F. 修改B=4.
- G. 记录B=4到redo log.
- H. 将redo log写入磁盘。
- I. 事务提交
IO性能:
Undo + Redo的设计主要考虑的是提升IO性能。虽说通过缓存数据,减少了写数据的IO;但是却引入了新的IO,即写Redo Log的IO。如果Redo Log的IO性能不好,就不能起到提高性能的目的。
为了保证Redo Log能够有比较好的IO性能,InnoDB 的 Redo Log的设计有以下几个特点:
A. 尽量保持Redo Log存储在一段连续的空间上。因此在系统第一次启动时就会将日志文件的空间完全分配。
以顺序追加的方式记录Redo Log,通过顺序IO来改善性能。
B. 批量写入日志。日志并不是直接写入文件,而是先写入redo log buffer。当需要将日志刷新到磁盘时(如事务提交),将许多日志一起写入磁盘。
C. 并发的事务共享Redo Log的存储空间,它们的Redo Log按语句的执行顺序,依次交替的记录在一起, 以减少日志占用的空间。例如:Redo Log中的记录内容可能是这样的:
记录1: < trx1, insert …>
记录2: < trx2, update …>
记录3: < trx1, delete …>
记录4: < trx3, update …>
记录5: < trx2, insert …>
D. 因为C的原因,当一个事务将Redo Log写入磁盘时,也会将其他未提交的事务的日志写入磁盘。
E. Redo Log上只进行顺序追加的操作,当一个事务需要回滚时,它的Redo Log记录也不会从Redo Log中删除掉。
事务恢复策略
前面说到未提交的事务和回滚了的事务也会记录Redo Log,因此在进行恢复时,这些事务要进行特殊的处理。具体的恢复策略可以有以下两种:
- 进行恢复时,只重做已经提交了的事务。
- 进行恢复时,重做所有事务包括未提交的事务和回滚了的事务。然后通过Undo Log回滚那些未提交的事务。
InnoDB存储引擎的恢复机制
InnoDB是使用了第二种策略,InnoDB存储引擎中的恢复机制有以下几个特点:
在重做redo log时,并不关心事务性。恢复时,没有BEGIN,也没有COMMIT、ROLLBACK的行为,也不关心每个日志是哪个事务的。尽管事务ID等事务相关的内容其实已经记录到了Redo Log中,这些内容只是被当做要操作的数据的一部分。
使用第二种策略就必须要将undo log持久化,而且必须要在写redo log之前将对应的undo log写入磁盘。
undo和redo log的这种关联,使得持久化变得复杂起来。为了降低复杂度,InnoDB将undo log看作数据,因此记录undo log的操作也会记录到redo log中。这样undo log就可以像数据一样缓存起来,而不用在redo log之前写入磁盘了。
包含udo Log操作的redo Log,看起来是这样的:
记录1: <trx1, Undo log insert <undo_insert …>>
记录2: <trx1, insert …>
记录3: <trx2, Undo log insert <undo_update …>>
记录4: <trx2, update …>
记录5: <trx3, Undo log insert <undo_delete …>>
记录6: <trx3, delete …>到这里,还有一个问题没有弄清楚。既然Redo没有事务性,那岂不是会重新执行被回滚了的事务?确实是这样。同时Innodb也会将事务回滚时的操作也记录到redo log中。回滚操作本质上也是对数据进行修改,因此回滚时对数据的操作也会记录到Redo Log中。一个回滚了的事务的Redo Log,看起来是这样的:
记录1: <trx1, Undo log insert <undo_insert …>>
记录2: <trx1, insert A…>
记录3: <trx1, Undo log insert <undo_update …>>
记录4: <trx1, update B…>
记录5: <trx1, Undo log insert <undo_delete …>>
记录6: <trx1, delete C…>
记录7: <trx1, insert C>
记录8: <trx1, update B to old value>
记录9: <trx1, delete A>
一个被回滚了的事务在恢复时的操作就是先redo再undo,因此不会破坏数据的一致性。
MVCC实现
什么是MVCC
MVCC是一种多版本并发访问控制机制。我们都知道,锁机制可以控制并发操作,但是其系统开销较大,而MVCC可以在大多数情况下代替行级锁实现非锁定读操作。
InnoDB进行读操作时,如果发现读取的行被其他线程加上了排他锁(DELETE、UPDATE),这时读取操作不会因此而等待行上锁的释放。相反,InnoDB存储引擎会去读取正在加锁的事务的undo log日志,读该行被加锁前的快照数据。
可以看到,非锁定读的机制大大提高了数据读取的并发性,它也是REPEATABLE READ隔离级别(InnoDB存储引擎默认隔离级别)的默认读取方式,即读取不会占用和等待表上的锁,但是并不是每个事务隔离级别下读取的都是MVCC形式的。同样,即使都是使用MVCC形式,但是对于快照数据的定义也不同。
快照数据其实就是当前行数据之前的历史版本,可能有多个版本。一个行可能有不止一个快照数据。Read Committed和Repeatable Read两种存储引擎下,都使用了MVCC这种非锁定的一致性读,但是对于快照数据的定义却不相同。在Read Committed事务隔离级别下,对于快照数据,非一致性读总是读取被锁定行的最新一份快照数据。但是在Reapeatable Read 事务隔离级别下,对于快照数据,非一致性读总是读取事务开始时的行数据版本。
InnoDB中对MVCC的实现
Innodb MVCC主要是为Repeatable-Read事务隔离级别做的。在此隔离级别下,A、B客户端所操作的数据相互隔离,互不干扰。
Innodb存储的最基本row中包含一些额外的存储信息DATA_TRX_ID,DATA_ROLL_PTR,DB_ROW_ID,DELETE BIT:
- 6字节的DATA_TRX_ID 标记了最新更新(update、insert、delete操作)这条行记录的transaction id。 这个ID是由MySQL自动生成的,MySQL每处理一个事务,都会自增产生一个事务Id。
- 7字节的DATA_ROLL_PTR 指向当前记录项的rollback segment的undo log记录,找之前版本的数据就是通过这个指针
- 6字节的DB_ROW_ID,当由innodb自动产生聚集索引时,聚集索引包括这个DB_ROW_ID的值,否则聚集索引中不包括这个值.,这个用于索引当中
- DELETE BIT位:用于标识删除此条记录的事务Id,如果记录没有被删除,则此处值是undifined;真正意义的删除是在commit之后的purge。
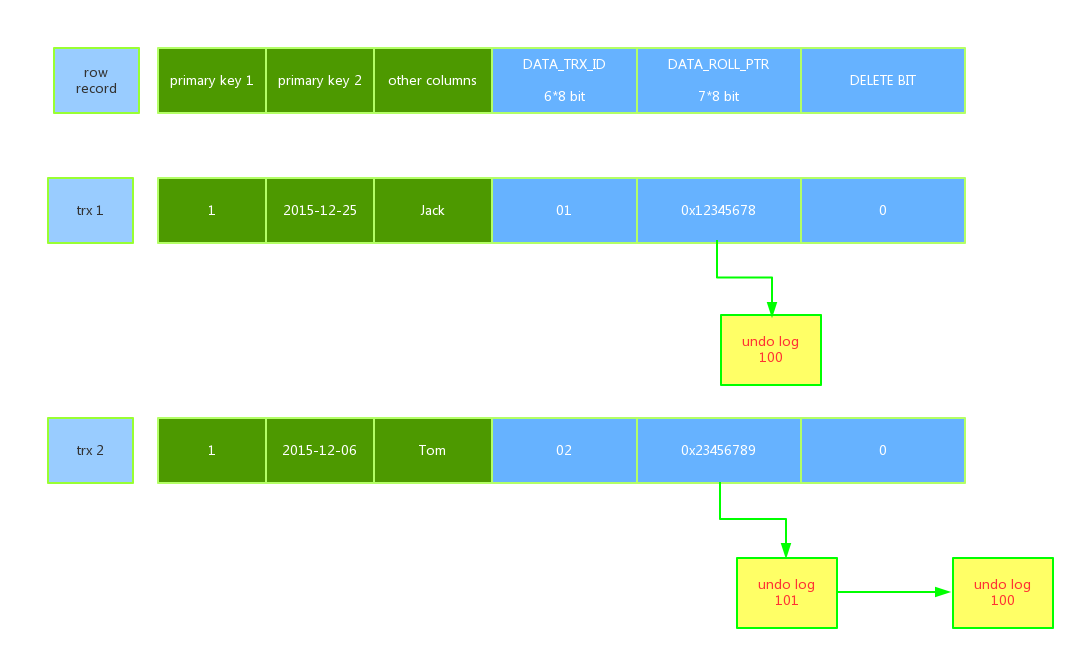
假设 我们有下列表和数据:
create table yang(id int primary key auto_increment,name varchar(20));
表内容如下(后面两列时隐藏列,我们通过查询语句并看不到):
| ID | NAME | DATA_TRX_ID | DATA_ROLL_PTR | DELETE BIT |
|---|---|---|---|---|
| 1 | yang | 1 | undefined | undefined |
| 2 | long | 1 | undefined | undefined |
| 3 | fei | 1 | undefined | undefined |
SELECT:
InnoDB会根据以下两个条件检查每行记录:
1. InnoDB只会查找版本早于当前事务版本的数据行(也就是 行的系统版本号 小于或等于当前事务的版本号),这样就可以确保当前事务读取到的行,要么是在自己开始前已经存在,要么是自己本身做的插入或者修改。
2. 行的删除版本要么未定义,要么大于当前事务版本号,这可以确保事务读取到的行,在事务开始之前未被删除。
只有上述两点同时满足的记录,才能返回作为查询结果。
DELETE操作:
InnoDB会为删除的每一行记录保存当前事务的事务ID作为删除标识。假设现在有事务ID为2的Connection进行如下操作:
start transaction ;select * from yang ; //(1)select * from yang ; //(2)commit ;
假设1:
假设在执行这个事务ID为2的过程中,刚执行到(1)时,有另一个事务ID为3往这个表里插入了一行数据。事务Id为3的Connection进行了如下操作:
start transaction ;insert into yang values(NULL,'tian');commit ;
这时表中的数据如下:
| ID | NAME | DATA_TRX_ID | DATA_ROLL_PTR | DELETE BIT |
|---|---|---|---|---|
| 1 | yang | 1 | undefined | undefined |
| 2 | long | 1 | undefined | undefined |
| 3 | fei | 1 | undefined | undefined |
| 4 | tian | 3 | undefined | undefined |
然后接着执行事务2中的(2),由于id=4的数据的事务ID为3,执行当前事务的ID为2,而InnoDB只会查找事务ID小于等于当前事务ID的数据行,所以id=4的数据行并不会在执行事务2中的(2)被检索出来,在事务2中的两条select 语句检索出来的数据都只会下表:
| ID | NAME | DATA_TRX_ID | DATA_ROLL_PTR | DELETE BIT |
|---|---|---|---|---|
| 1 | yang | 1 | undefined | undefined |
| 2 | long | 1 | undefined | undefined |
| 3 | fei | 1 | undefined | undefined |
假设2:
假设在Id为2的事务执行完(1)操作后,接着Id为3的事务也执行完毕,又开始执行了Id为4的事务。事务Id为4的操作如下:
start transaction;delete from yang where id=1 ;commit ;
此时数据库表中的表如下:
| ID | NAME | DATA_TRX_ID | DATA_ROLL_PTR | DELETE BIT |
|---|---|---|---|---|
| 1 | yang | 1 | undefined | 4 |
| 2 | long | 1 | undefined | undefined |
| 3 | fei | 1 | undefined | undefined |
| 4 | tian | 3 | undefined | undefined |
接着执行事务Id为2的事务(2),根据SELECT检索条件可知,它会检索 更新事务Id小于等于当前事务ID的行和删除事务Id大于当前事务的行,而Id=4的行上面已经 说过了。Id=1的行由于删除事务Id大于当前事务的Id,所以事务2的(2)的查询语句也会把id=1的数据检索出来。所以,事务2中的两条select语句检索出来的数据如下:
| ID | NAME | DATA_TRX_ID | DATA_ROLL_PTR | DELETE BIT |
|---|---|---|---|---|
| 1 | yang | 1 | undefined | 4 |
| 2 | long | 1 | undefined | undefined |
| 3 | fei | 1 | undefined | undefined |
UPDATE:
InnoDB执行UPDATE,实际上是新插入了一行记录,并保存其更新事务Id为当前事务的ID,同时保存当前事务ID到要UPDATE的行的删除事务Id上。
假设3:
假设在执行完事务2的(1)后又执行,其它用户执行了事务3、4,这时,又有一个用户对这张表执行了UPDATE操作(此时事务Id为5):
start transaction;update yang set name='Long' where id=2;commit;
根据update的更新原则:会生成新的一行,并在原来要修改的列的删除时间列上添加本事务ID,得到表如下:
| ID | NAME | DATA_TRX_ID | DELETE BIT |
|---|---|---|---|
| 1 | yang | 1 | 4 |
| 2 | long | 1 | 5 |
| 3 | fei | 1 | undefined |
| 4 | tian | 3 | undefined |
| 2 | Long | 5 | undefined |
继续执行事务2的(2),根据select 语句的检索条件,得到下表:
| ID | NAME | DATA_TRX_ID | DELETE BIT |
|---|---|---|---|
| 1 | yang | 1 | 4 |
| 2 | long | 1 | 5 |
| 3 | fei | 1 | undefined |
purge(清除操作)操作
delete和update操作可能并不直接删除原有的数据。例如对于下述SQL语句:
DELETE FROM t WHERE A = 1 ;
表t上列a有聚簇索引,列b上有辅助索引。对于delete操作,通过前面关于undo log的介绍已经知道仅是将主键列等于1的记录delete flag设置为1,记录并没有被删除,即记录还是存在于B+树中。其次,对于辅助索引上a等于1,b等于1的记录同样没有做任何处理,甚至没有产生undo loh。而真正删除这行记录的操作其实被“延时”了,最终在purge操作中完成。
purge用于最终完成delete和update操作。这样设计是因为InnoDB存储引擎支持MVCC,所以记录不能在事务提交时立即进行处理。这时其他事务可能正在引用这行,故InnoDB存储引擎需要保存记录之前的版本。而是否可以删除该记录通过purge来进行判断。若该行记录已不被任何其他事务引用,那么就可以进行真正的delete操作。可见,purge操作是清理之前的delete和update操作,将上述操作“最终”完成。而实际执行的操作为delete操作,清理之前行记录的版本。
