@boothsun
2018-03-15T11:41:31.000000Z
字数 10277
阅读 1889
学习Leader选举算法
ZK
读书笔记:《从Paxos到Zookeeper 分布式一致性原理与实践》
选举的前提约定
- 观察者不参与选举,只有跟随者才参与选举。
- 优先选事务ID(ZXID)大的,事务Id相同再优先选服务器编号大的(myid或称sid)。
- 超过半数的相同投票,那这个投票对应的SID(myid)机器即为Leader。(>= n/2 + 1 )
- 所有有效的投票都必须在同一个轮次中。
选举过程
术语
sid或者myid(服务器Id)
sid和myid可以等同,都是用来唯一标识一台Zookeeper集群中的机器,每台机器不能重复。回忆我们在安装Zookeeper集群的时候,会在
zoo.cfg文件中做如下简单配置:tickTime=2000initLimit=10syncLimit=5dataDir=/opt/soft/zookeeper/dataclientPort=2181server.1=master:2888:3888server.2=slave1:2888:3888server.3=slave2:2888:3888
注意,上面配置中有类似
server.id=host:port:port的配置,这里的id就是Server Id,用来标识该机器在集群中的机器序号。同时,在每台Zookeeper机器上,我们都需要在数据目录(即上述配置中dataDir参数所指定的那个目录)下创建一个myid文件,该文件就只有一行内容,并且是一个数字,即对应每台机器的Server Id数字。ZXID:事务ID
在Zookeeper中,事务是指能够改变Zookeeper服务器状态的操作,我们称之为事务操作或更新操作,一般包括数据节点创建与删除、数据节点内容更新和客户端会话创建与失效等操作。对于每一个事务请求,Zookeeper都会为其分配一个全局唯一递增的事务Id。从这些ZXID中也可以间接识别出Zookeeper处理这些更新操作请求的全局顺序。在某一个时刻,集群中每台机器的ZXID值不一定全都一致。
投票
Leader选举,顾名思义必须通过投票来实现。当集群中的机器发现自己无法检测到Leader机器的时候,就会开始尝试进行投票。
Quorum:过半机器数:
少数服从多数,过半投票,即当选。服务器状态:
Zookeeper集群中机器状态主要有:LOOKING、FOLLOWING、LEADING和OBSERVING 四种:- LOOKING:寻找Leader状态,当前集群中午Leader。
- FOLLOWING:跟随者状态,表明当前服务器角色是Follower。
- LEADING:领导者状态,表明当前服务器角色是Leader。
- OBSERVING:观察者状态,表明当前服务器角色是Observer。
具体的枚举状态可以参见源码(org.apache.zookeeper.server.quorum.QuorumPeer.ServerState)
public enum ServerState {LOOKING, FOLLOWING, LEADING, OBSERVING;}
产生选举动作的时机
Zookeeper集群中的每一台机器之间都通过心跳机制进行相互检测,一旦一台服务器出现以下两种情况之一,就会开始进入Leader选举:
- 服务器初始化启动。
- 服务器运行期间无法和leader保持连接。
而当一台机器进入Leader选举流程时,当前集群也可能会处于以下两种状态:
- 集群中本来就已经存在一个Leader。
- 集群中确实不存在Leader。
对于第一种已经存在Leader的情况,通常发生在集群中的某一台机器启动比较晚,在它启动之前,集群已经可以正常工作,即已经存在了一台Leader服务器。针对于这种情况,当该机器试图去选举Leader的时候,会被告知当前服务器的Leader的信息,对于该机器来说,仅仅需要和Leader机器建立器连接,并进行状态同步即可。
我们主要针对于第二种不存在Leader的情况进行分析。
具体过程:
任何时刻,只有处于“LOOKING”状态的机器才会尝试进行投票。
在这个投票消息中包含了两个最基本的消息:所推举的服务器的SID和ZXID,分别表示了被推举服务器的唯一标识和事务ID,所以我们以“(SID,ZXID)”的形式来标识一次投票信息。
现在,我们假设集群存活着3台机器,分别是Server1、Server2、Server3,SID和ZXID都分别为1、2、3。则投票分别为(1,1)、(2,2)、(3,3)。
- 第一次,Server1、Server2、Server3都选择自己作为Leader服务器来进行投票,并将自己的投票发给其他机器,同时会将自己的投票轮次计数器加1。
- 接收来自各个服务器的投票:当某台机器接收到投票会,会首先判断该投票的有效性,包括是否来自LOOKING状态的服务器、自己的选举轮次是否已经落后于该外部投票对应服务器的选举轮次,如果确实落后,就会立即更新自己的选举轮次,并且清空所有已经收到的投票,然后使用第一次的投票来进行比较以确定是否需要变更自己的投票,并将最终的投票结果发出。
处理投票:
在接收到来自其他服务器的投票后,针对于每一个投票,服务器都需要将别人的投票和自己的投票进行比较,规则是:优先选事务Id大的,相同再优先选编号大的- 对于Server1来说,它收到的投票是(2,2)和(3,3),因为(3,3)的事务Id最大,所以优先选择(3,3),于是Server1将自己的投票发送给其他服务器。
- 对于Server2来说,它收到的投票是(1,1)和(3,3),因为(3,3)的事务Id最大,所以优先选择(3,3),于是Server1将自己的投票发送给其他服务器。
- 对于Server3来说,它收到投票是(1,1)和(2,2),因为事务Id都比自己小,所以自己无须更新自己的选票,只是再向集群中所有机器发出上一次投票信息即可。
统计投票
经过第二次投票后,集群中每个服务器都会统计所有投票,如果已经有超过半数的机器接收到相同的投票信息,就会认为该投票信息对应的机器称为Leader。改变服务器状态:
一旦确定了Leader,每个服务器就会更新自己的状态:如果是Follower,那么就变更为FOLLOWING,如果是Leader,那么就变更为LEADING。
小结
- 为什么选择事务ID比较大的机器?
因为事务Id越大,则代表这台机器的数据就越新,也就越能够保证数据的恢复。
Leader选举的实现细节
下面,我们从源码角度分析Zookeeper中对FastLeaderElection的实现。
投票数据结构
类路径:org.apache.zookeeper.server.quorum.Vote
public class Vote {final private int version;final private long id;final private long zxid;final private long electionEpoch;final private long peerEpoch;// .......}

节点通信
在服务器启动时,每台机器都会启动一个QuorumCnxManager,负责各台服务器之间的底层Leader选举过程中的网络通信。QuorumCnxManager类路径。
消息收发队列
在QuorumCnxManager这个类内部维护了一系列的队列,用于保存接收到的、待发送的消息,以及消息的发送器。除接收队列外,这里提到的所有队列都有一个共同点 —— 按SID分组形成队列集合。
- recvQueue:消息接收队列,用于存放那些从其他服务器接收到的消息。
- queueSendMap:消息发送队列,用于保存那些待发送的消息。queueSendMap是一个Map,按照SID进行分组,分别为集群中的每台机器分配了一个单独队列,从而保证各台机器之间的消息发送互不影响。
- senderWorkerMap:发送器集合。每个SendWorker消息发送器,都对应一台远程Zookeeper服务器,负责消息的发送。同样,在senderWorkerMap中,也按照SID进行分组。
- lastMessageSent:最近发送过的消息。在这个集合中,为每个SID保留最近发送过的一个消息。
建立连接
为了能够进行互相投票,ZooKeeper集群中的所有机器都需要两两建立起网络连接。QuorumCnxManager在启动的时候,会创建一个ServerSocket来监听Leader选举的通信端口(Leader选举的通信端默认是3888)。开启端口监听后,ZooKeepr就能够不断地接收到来自其他服务器的“创建连接”请求,在接收到其他服务器的TCP连接请求时,为了避免两台机器之间重复地创建TCP连接,ZooKeeper设计了一种建立TCP连接的规则:只允许SID大的服务器主动和其他服务器建立连接,否则断开连接。服务器通过对比自己和远程服务器的SID值,来判断是否接受连接请求。如果当前服务器发现自己的SID值更大,那么会断开当前连接,然后自己主动去和远程服务器建立连接。
一旦建立起连接,就会根据远程服务器的SlD来创建相应的消息发送器SendWorker和消息接收器RecvWorker,并启动他们。
/** Listener thread*/public final Listener listener;// 构造方法初始化public QuorumCnxManager(.....) {// .....// Starts listener thread that waits for connection requestslistener = new Listener();// .....}/*** Thread to listen on some port*/public class Listener extends ZooKeeperThread {volatile ServerSocket ss = null;// ...../*** Sleeps on accept().*/@Overridepublic void run() {int numRetries = 0;InetSocketAddress addr;while((!shutdown) && (numRetries < 3)){try {// 这里省略创建Socket和线程重命名过程ss.bind(addr);while (!shutdown) {Socket client = ss.accept();setSockOpts(client);LOG.info("Received connection request "+ client.getRemoteSocketAddress());// 判断是否开启 sasl 权限校验if (quorumSaslAuthEnabled) {receiveConnectionAsync(client);} else {receiveConnection(client);}numRetries = 0;}} catch (IOException e) {// 这里省略 异常处理 部分代码}}// ........}public void receiveConnection(final Socket sock) {DataInputStream din = null;try {din = new DataInputStream(new BufferedInputStream(sock.getInputStream()));handleConnection(sock, din);} catch (IOException e) {LOG.error("Exception handling connection, addr: {}, closing server connection",sock.getRemoteSocketAddress());closeSocket(sock);}}private void handleConnection(Socket sock, DataInputStream din)throws IOException {Long sid = null;// ......// 注意这里就是对SID 进行判断if (sid < this.mySid) {/** This replica might still believe that the connection to sid is* up, so we have to shut down the workers before trying to open a* new connection.*/SendWorker sw = senderWorkerMap.get(sid);if (sw != null) {sw.finish();}/** 小连大,关闭小的,大的向小的重新发起连接*/LOG.debug("Create new connection to server: " + sid);closeSocket(sock);connectOne(sid);// Otherwise start worker threads to receive data.} else {SendWorker sw = new SendWorker(sock, sid);RecvWorker rw = new RecvWorker(sock, din, sid, sw);sw.setRecv(rw);SendWorker vsw = senderWorkerMap.get(sid);if(vsw != null)vsw.finish();senderWorkerMap.put(sid, sw);if (!queueSendMap.containsKey(sid)) {queueSendMap.put(sid, new ArrayBlockingQueue<ByteBuffer>(SEND_CAPACITY));}sw.start();rw.start();return;}}}
消息接收与发送
消息的接收过程是由消息接收器RecvWorker来负责的。ZooKeeper会为每个远程服务器分配一个单独的RecvWorker,每个RecvWorker只需要不断地从这个TCP连接中读取消息,并将其保存到recvQueue队列中。
消息发送过程也比较简单,由于ZooKeeper同样已经为每个远程服务器单独分别分配了消息发送器SendWorker,那么每个SendWorker只需要不断地从对应的消息发送队列中取出一个消息来发送即可,同时将这个消息放入lastMessageSent中来作为最近发送过的消息。在SendWorker的具体实现中,有一个细节需要我们注意一下:一旦Zookeeper发现针对当前远程服务器的消息发送队列为空,那么此时需要从lastMessageSent中取出一个最近发送过的消息来进行再次发送,这是为了解决接收方在消息接收前或者接收到消息后服务器挂了,导致消息尚未被正确处理。同时,Zookeeper能够保证接收方在处理消息时,会对重复消息进行正确的处理。
整体流程图如下:
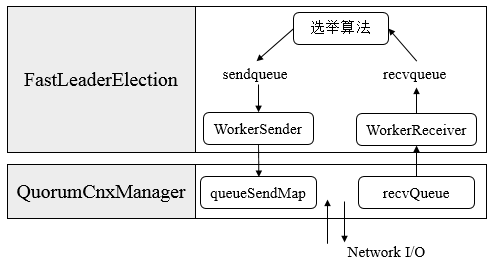
FastLeaderElection 具体实现
/*** 一旦QuorumPeer的状态变为LOOKING时,这个方法就会被调用 向其他节点发送消息,进行leader选举*/public Vote lookForLeader() throws InterruptedException {//........try {HashMap<Long, Vote> recvset = new HashMap<Long, Vote>();HashMap<Long, Vote> outofelection = new HashMap<Long, Vote>();int notTimeout = finalizeWait;// 选举轮次+1 & 初始化自己的选票 也就是第一次选自己的投票synchronized(this){logicalclock++;updateProposal(getInitId(), getInitLastLoggedZxid(), getPeerEpoch());}// 广播自己的选票sendNotifications();// 不停循环选举,直到找到leaderwhile ((self.getPeerState() == ServerState.LOOKING) &&(!stop)){// 从接收队列中 获取消息Notification n = recvqueue.poll(notTimeout,TimeUnit.MILLISECONDS);/** Sends more notifications if haven't received enough.* Otherwise processes new notification.*/if(n == null){if(manager.haveDelivered()){//一旦Zookeeper发现针对当前远程服务器的消息发送队列为空,那么此时需要从lastMessageSent中取出一个最近发送过的消息来进行再次发送,// 这是为了解决接收方在消息接收前或者接收到消息后服务器挂了,导致消息尚未被正确处理sendNotifications();} else {manager.connectAll();}}else if(self.getVotingView().containsKey(n.sid)) { // 收到投票信息 验证一下是否是自己所在集群中集群发出的投票消息switch (n.state) {case LOOKING:// 外部选票轮次大于自己选票轮次(自己落后) , 操作如下:// 1. 立即更新自己的选举轮次(logicalclock)// 2. 清空本轮所有已经收到的投票// 3. 将收到的选票和自己的初始投票做PKif (n.electionEpoch > logicalclock) {logicalclock = n.electionEpoch;recvset.clear();if(totalOrderPredicate(n.leader, n.zxid, n.peerEpoch,getInitId(), getInitLastLoggedZxid(), getPeerEpoch())) {updateProposal(n.leader, n.zxid, n.peerEpoch);} else {updateProposal(getInitId(),getInitLastLoggedZxid(),getPeerEpoch());}//广播自己的选票sendNotifications();} else if (n.electionEpoch < logicalclock) { //外部投票的选举轮次小于内部投票,直接忽略消息。if(LOG.isDebugEnabled()){LOG.debug("Notification election epoch is smaller than logicalclock. n.electionEpoch = 0x"+ Long.toHexString(n.electionEpoch)+ ", logicalclock=0x" + Long.toHexString(logicalclock));}break;} else if (totalOrderPredicate(n.leader, n.zxid, n.peerEpoch,proposedLeader, proposedZxid, proposedEpoch)) { // 外部选票和内部选票轮次一致 直接PK,然后更新自己的投票并广播出去updateProposal(n.leader, n.zxid, n.peerEpoch);sendNotifications();}if(LOG.isDebugEnabled()){LOG.debug("Adding vote: from=" + n.sid +", proposed leader=" + n.leader +", proposed zxid=0x" + Long.toHexString(n.zxid) +", proposed election epoch=0x" + Long.toHexString(n.electionEpoch));}// 保存本轮已经收到的投票 由于是Map且key是sid,所以只会保存每台机器最新的投票recvset.put(n.sid, new Vote(n.leader, n.zxid, n.electionEpoch, n.peerEpoch));// 判断自己选的节点是否有足够多的投票 ,如果是,则直接返回自己选节点,确定该节点为leader。// 注意:终止的条件 不考虑权重的情况下是:this.half = n/2; set.size() > half ;if (termPredicate(recvset,new Vote(proposedLeader, proposedZxid,logicalclock, proposedEpoch))) {// Verify if there is any change in the proposed leader// 等待finalizeWait时长,如果该时间段内,没有收到消息,则认定自己选举的节点就为leader了while((n = recvqueue.poll(finalizeWait,TimeUnit.MILLISECONDS)) != null){ //指定时间段内 又收到消息了if(totalOrderPredicate(n.leader, n.zxid, n.peerEpoch,proposedLeader, proposedZxid, proposedEpoch)){ //选票PK,如果自己的选票被PK下去了,则将新消息放入消息队列,重新开始另一轮循环。否则继续等待recvqueue.put(n);break;}}/** 指定时间段内没有收到更高的选票,则认定自己选定的人就是leader,开始更新自己的状态*/if (n == null) {//如果当前选择的是自己是leader,则更新自己状态为LEADING,否则更新自己状态是FOLLOWING或者OBSERVINGself.setPeerState((proposedLeader == self.getId()) ?ServerState.LEADING: learningState());Vote endVote = new Vote(proposedLeader,proposedZxid,logicalclock,proposedEpoch);leaveInstance(endVote);return endVote;}}break;case OBSERVING:LOG.debug("Notification from observer: " + n.sid);break;case FOLLOWING:case LEADING:/** 如果收到的选票 是一个状态为LEADING的机器发过来的,就验证一下是否是在同一选举轮次,* 如果是,再验证自己收到的全部选票是否是证实该机器就是leader,如果是,则更新自己状态*/if(n.electionEpoch == logicalclock){recvset.put(n.sid, new Vote(n.leader,n.zxid,n.electionEpoch,n.peerEpoch));if(ooePredicate(recvset, outofelection, n)) {self.setPeerState((n.leader == self.getId()) ?ServerState.LEADING: learningState());Vote endVote = new Vote(n.leader,n.zxid,n.electionEpoch,n.peerEpoch);leaveInstance(endVote);return endVote;}}//保留外部选票outofelection.put(n.sid, new Vote(n.version,n.leader,n.zxid,n.electionEpoch,n.peerEpoch,n.state));// 如果不在同一轮次,则根据本轮自身收到的全部外部选票再推断一下,该机器是否确实是leaderif(ooePredicate(outofelection, outofelection, n)) {synchronized(this){logicalclock = n.electionEpoch;self.setPeerState((n.leader == self.getId()) ?ServerState.LEADING: learningState());}Vote endVote = new Vote(n.leader,n.zxid,n.electionEpoch,n.peerEpoch);leaveInstance(endVote);return endVote;}break;default:LOG.warn("Notification state unrecognized: {} (n.state), {} (n.sid)",n.state, n.sid);break;}} else {LOG.warn("Ignoring notification from non-cluster member " + n.sid);}}return null;} finally {// ......}}
