@c-xy
2017-01-07T18:11:25.000000Z
字数 8640
阅读 357
随机行走过程的研究
姓名:曹昕宇
学号:2014301020176
摘要
本文主要用Python语言对一系列随机过程做了模拟,通过观察数值计算的结果,并将其与概率论的结论相比较,证明数值计算的结果在处理随机过程方面是可信的。文中涉及的随机过程首先为一维情况下的随机行走,这其中分别讨论了左右概率相同和不同的情况。之后延伸到二维情况,并对二维系统中熵随时间变化的情况作了简单讨论。
关键词:随机行走 平均值 熵
一、背景介绍
本文中我们考虑这样一类系统,其中随机性占据重要位置,这种系统被称为随机系统。这些系统一般含有较大数目的“自由度”,比如一滴雨水中的大量水分子,或是一块铁磁体中的大量自旋。
在这种系统中,尽管理论上每个粒子的运动可以由力学定律决定,但是这会带来天文数字的微分方程,难以实际求解。为此,我们使用概率论来描述这个系统,使得原系统和这个随机系统在某些我们感兴趣的宏观性质上一致。通过探究这个随机系统,我们可以了解真实系统。
处理随机系统时,如果我们想用实验来探究其中规律,由于为了体现统计规律,实验的次数应该非常大,现实的实验将不可避免的耗时耗力,难以实现。为此,我们可以使用数值计算方法,利用随机数产生器产生随机数,利用计算机的快速计算能力,完成成千上万次的实验任务。
在许多随机过程中,这里我们感兴趣的是随机行走问题。一维情况下的随机行走问题,指的是一个粒子初始时刻位于原点,之后每次经过同样的时间间隔,其或者向左行走或者向右行走,两个方向的概率可能相同,也可能不同,步长可能一定也可能在一个范围内随机。其二维情况下则其每一步的方向任意,其它性质和一维情况相似。
二、左右等可能随机行走(步长一定或随机)
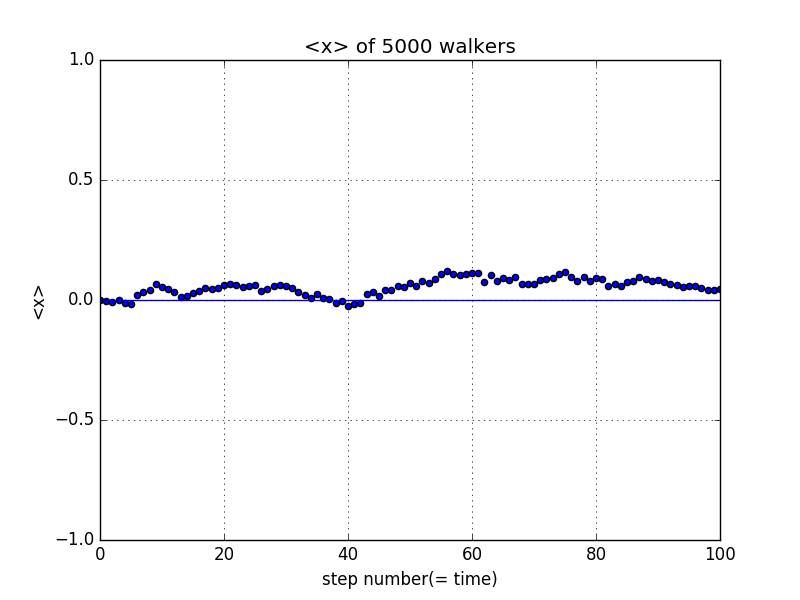
这里我们考虑一个典型的一维随机行走问题。粒子初始时刻位于x=0处,步长为1,相邻的两步之间时间间隔固定(故步数正比于时间),每一步向左和向右概率均为0.5。我们假设有5000个相同的粒子,观察它们运动的平均性质。
它们距离原点的平均距离随步数的变化关系为
from __future__ import divisionimport numpy as npimport matplotlib.pyplot as pltsteps = np.linspace(0, 100, 101)x_ave = np.zeros(101)x_y0 = np.zeros(101)x_now = np.zeros(5000)for i in range(100):for j in range(5000):ruler = np.random.rand()if ruler<=0.5:x_now[j] = x_now[j] + 1else:x_now[j] = x_now[j] - 1average = sum(x_now)/5000x_ave[i+1] = averageplt.scatter(steps, x_ave)plt.plot(steps, x_y0)plt.xlim(0,100)plt.ylim(-1,1)plt.grid(True)plt.xlabel('step number(= time)')plt.ylabel('<x>')plt.title('<x> of 5000 walkers')plt.show()
可见,这个系统中粒子距离原点的平均距离保持在0附近波动。按照概率论,粒子向左向右的概率相同,其距离原点的平均距离应该为0。这里数值结果和理论结果是一致的。
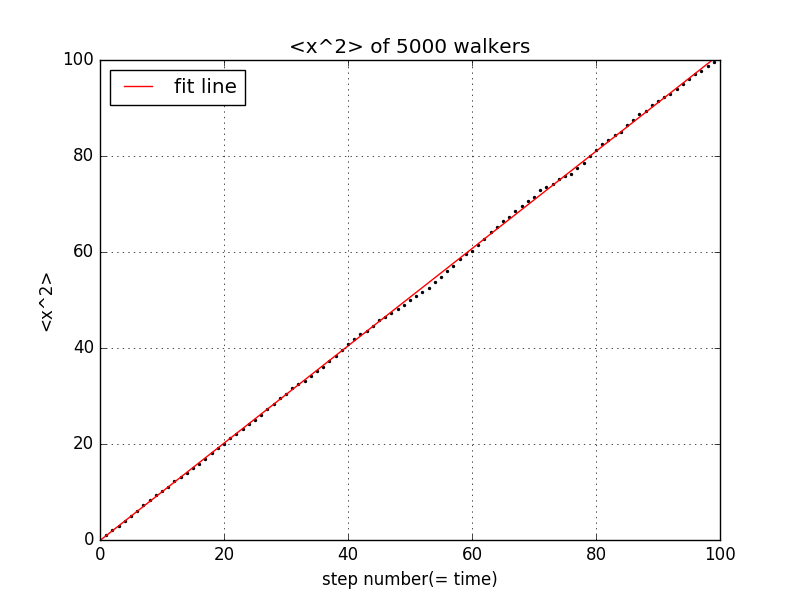
它们距离原点距离平方随步数的变化关系为
from __future__ import divisionimport numpy as npimport matplotlib.pyplot as pltsteps = np.linspace(0, 100, 101)x2_ave = np.zeros(101)x_y0 = np.zeros(101)x_now = np.zeros(5000)x2_now = np.zeros(5000)for i in range(100):for j in range(5000):ruler = np.random.rand()if ruler<=0.5:x_now[j] = x_now[j] + 1else:x_now[j] = x_now[j] - 1x2_now[j] = x_now[j]**2average2 = sum(x2_now)/5000x2_ave[i+1] = average2para = np.polyfit(steps, x2_ave,1)poly = np.poly1d(para)y_fit = poly(steps)plt.scatter(steps, x2_ave,s=2)plt.plot(steps, y_fit, 'r', label = 'fit line')plt.legend(loc='upper left')plt.xlim(0,100)plt.ylim(0,100)plt.grid(True)plt.xlabel('step number(= time)')plt.ylabel('<x^2>')plt.title('<x^2> of 5000 walkers')plt.show()
x的平方的平均值与步数近似为线性关系。这种线性关系在一维扩散系统中也有出现,表明这个随机行走的过程是“类扩散的”。
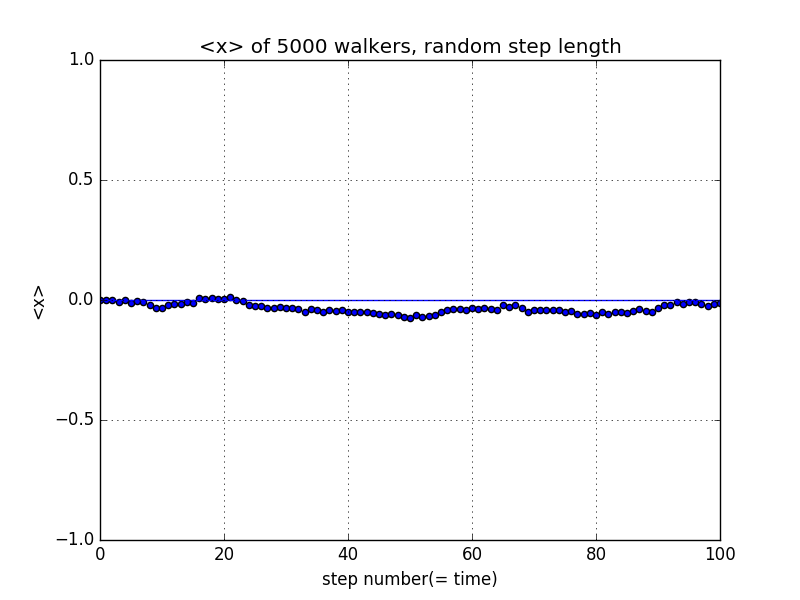
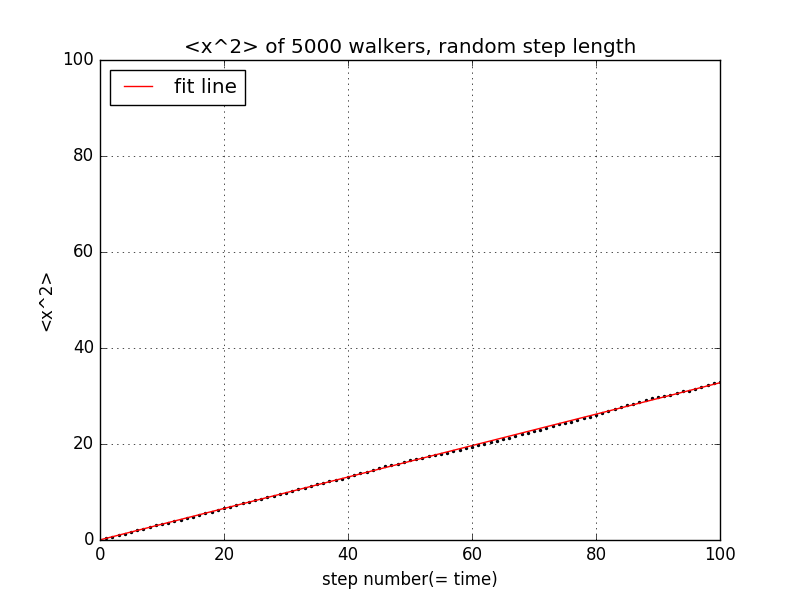
接下来我们将情况一般化,此时每一步的步长为-1~+1之间的一个值,且取每一个值的概率是一定的。此时两个平均值随步数的变化关系为
from __future__ import divisionimport numpy as npimport matplotlib.pyplot as pltsteps = np.linspace(0, 100, 101)x_ave = np.zeros(101)x_y0 = np.zeros(101)x_now = np.zeros(5000)for i in range(100):for j in range(5000):length = 2*np.random.rand() - 1x_now[j] = x_now[j] + lengthaverage = sum(x_now)/5000x_ave[i+1] = averageplt.scatter(steps, x_ave)plt.plot(steps, x_y0)plt.xlim(0,100)plt.ylim(-1,1)plt.grid(True)plt.xlabel('step number(= time)')plt.ylabel('<x>')plt.title('<x> of 5000 walkers, random step length')plt.show()
from __future__ import divisionimport numpy as npimport matplotlib.pyplot as pltsteps = np.linspace(0, 100, 101)x2_ave = np.zeros(101)x_y0 = np.zeros(101)x_now = np.zeros(5000)x2_now = np.zeros(5000)for i in range(100):for j in range(5000):length = 2*np.random.rand() - 1x_now[j] = x_now[j] + lengthx2_now[j] = x_now[j]**2average2 = sum(x2_now)/5000x2_ave[i+1] = average2para = np.polyfit(steps, x2_ave,1)poly = np.poly1d(para)y_fit = poly(steps)plt.scatter(steps, x2_ave,s=2)plt.plot(steps, y_fit, 'r', label = 'fit line')plt.legend(loc='upper left')plt.xlim(0,100)plt.ylim(0,100)plt.grid(True)plt.xlabel('step number(= time)')plt.ylabel('<x^2>')plt.title('<x^2> of 5000 walkers, random step length')plt.show()
由图可知,此时x的平均值在0附近波动,x的平方的平均值与步数近似为线性关系,此过程也是“类扩散的”。
三、左右不等可能的随机行走
这里我们考察当向左向右的运动概率不相同时的情况。我们让向右行走的概率为0.75,向左为0.25,固定步长为1,观察两种平均值随步长的变化关系为
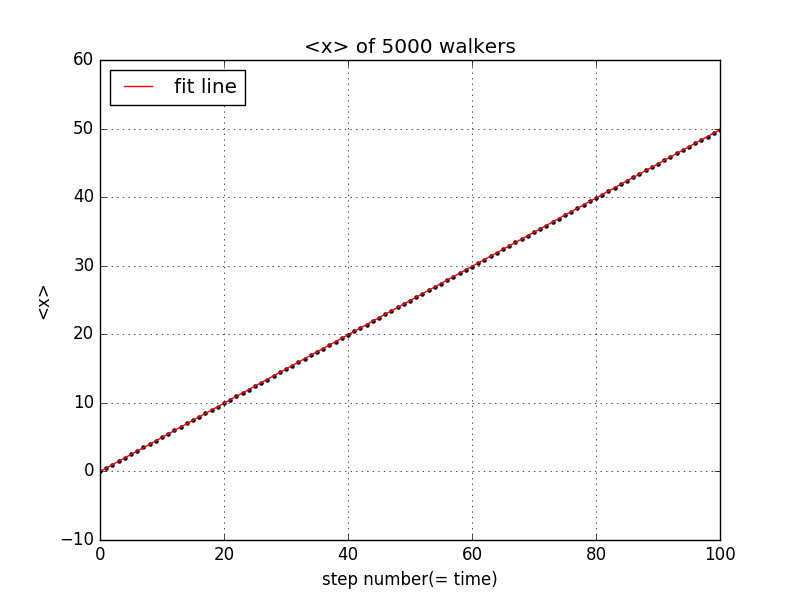
from __future__ import divisionimport numpy as npimport matplotlib.pyplot as pltsteps = np.linspace(0, 100, 101)x_ave = np.zeros(101)x_now = np.zeros(5000)for i in range(100):for j in range(5000):ruler = np.random.rand()if ruler<=0.75:x_now[j] = x_now[j] + 1else:x_now[j] = x_now[j] - 1average = sum(x_now)/5000x_ave[i+1] = averagepara = np.polyfit(steps, x_ave,1)poly = np.poly1d(para)y_fit = poly(steps)plt.scatter(steps, x_ave, s=5)plt.plot(steps, y_fit, 'r', label = 'fit line')plt.legend(loc='upper left')plt.xlim(0,100)plt.grid(True)plt.xlabel('step number(= time)')plt.ylabel('<x>')plt.title('<x> of 5000 walkers')plt.show()
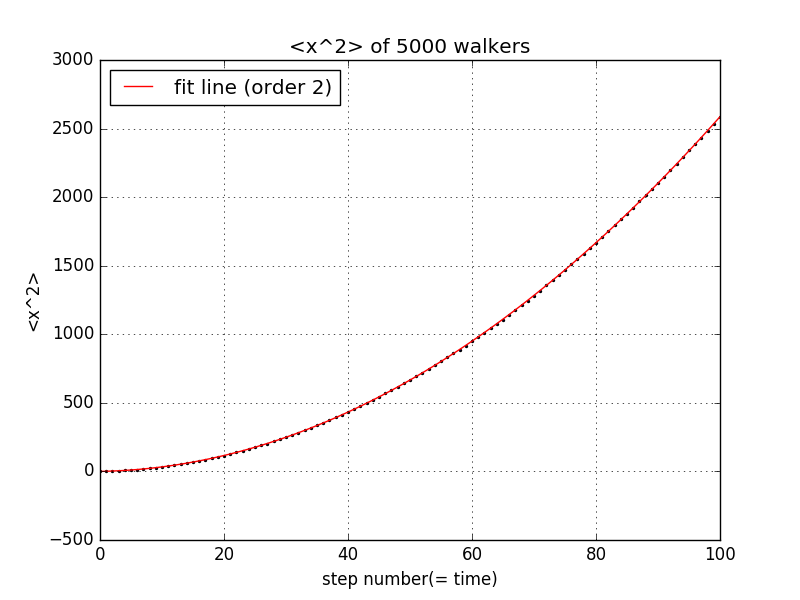
from __future__ import divisionimport numpy as npimport matplotlib.pyplot as pltsteps = np.linspace(0, 100, 101)x2_ave = np.zeros(101)x_y0 = np.zeros(101)x_now = np.zeros(5000)x2_now = np.zeros(5000)for i in range(100):for j in range(5000):ruler = np.random.rand()if ruler<=0.75:x_now[j] = x_now[j] + 1else:x_now[j] = x_now[j] - 1x2_now[j] = x_now[j]**2average2 = sum(x2_now)/5000x2_ave[i+1] = average2para = np.polyfit(steps, x2_ave,2)poly = np.poly1d(para)y_fit = poly(steps)plt.scatter(steps, x2_ave,s=2)plt.plot(steps, y_fit, 'r', label = 'fit line (order 2)')plt.legend(loc='upper left')plt.xlim(0,100)plt.grid(True)plt.xlabel('step number(= time)')plt.ylabel('<x^2>')plt.title('<x^2> of 5000 walkers')plt.show()
由图可知,x的平均值随步数线性增大,其平方的平均与步数成二次关系。这与概率论的结论相同。
四、随机行走与扩散
这里我们讨论随机行走与扩散之间的相似性。选取大量随机行走者,模拟其在空间上密度随时间的变化关系,在一维情况下,可得
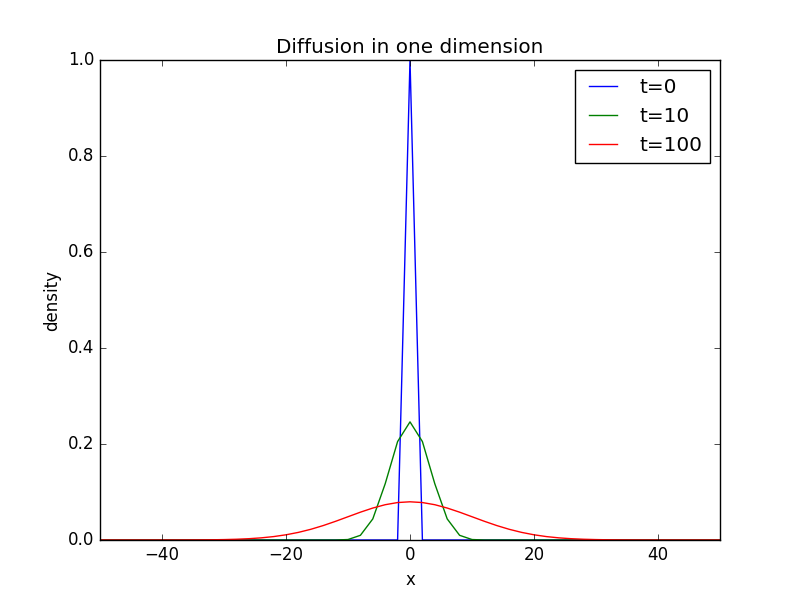
import numpy as npimport matplotlib.pyplot as pltfrom copy import deepcopydef density(t_end):x = list(np.linspace(-50,50,101))d = list(np.zeros(50)) + list(np.ones(1)) + list(np.zeros(50))d1 = deepcopy(d)for i in range(t_end):for j in range(101):if j==0 or j==100:passelse:d[j] = 0.5* (d1[j+1] + d1[j-1])d1 = deepcopy(d)for i in range(101):if i==0 or i==100:passelse:if d[i]==0:d[i] = 0.5*(d1[i+1] + d1[i-1])return x, dx1, d1 = density(0)[0], density(0)[1]x2, d2 = density(10)[0], density(10)[1]x3, d3 = density(100)[0], density(100)[1]plt.plot(x1,d1,label='t=0')plt.plot(x2,d2,label='t=10')plt.plot(x3,d3,label='t=100')plt.xlabel('x')plt.ylabel('density')plt.title('Diffusion in one dimension')plt.xlim(-50,50)plt.legend()plt.show()
由图可知,随着时间的增大,密度曲线的峰值下降,范围增大,总面积保持不变。
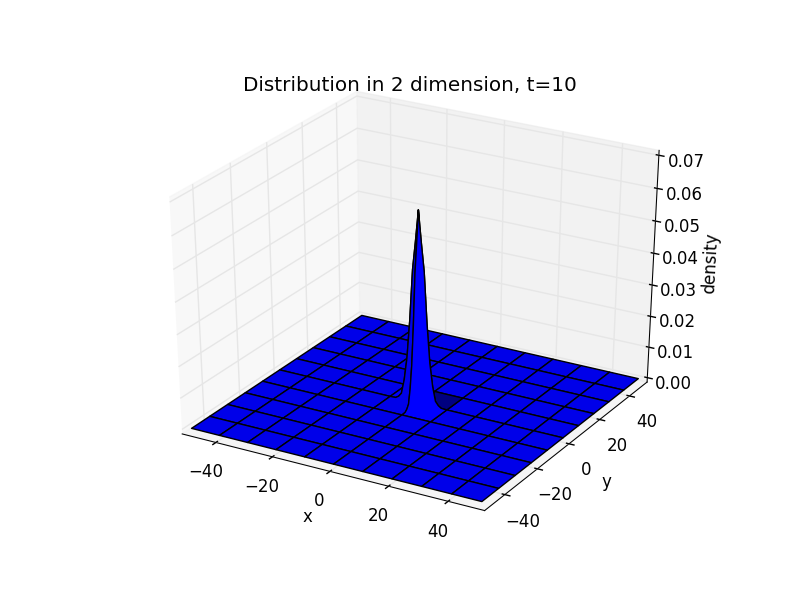
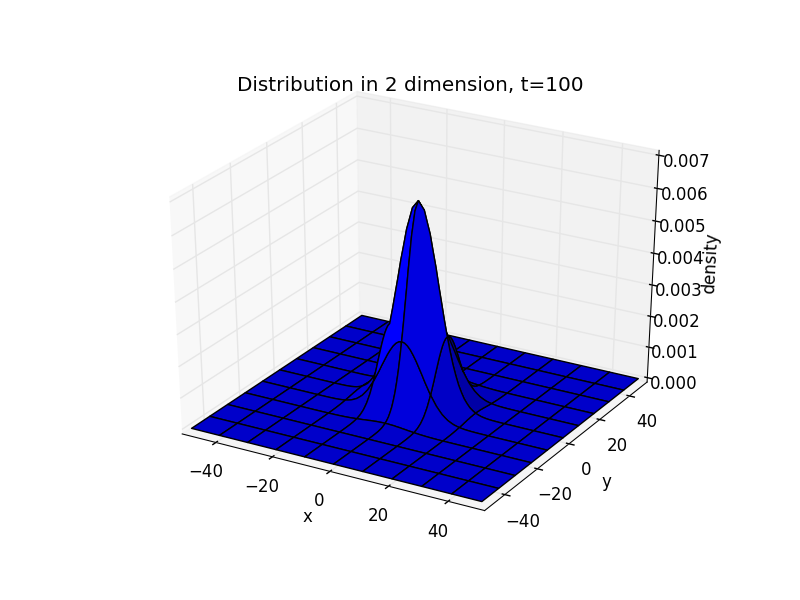
在二维情况下,可得
import numpy as npimport matplotlib.pyplot as pltfrom copy import deepcopyimport matplotlib.cm as cmfrom mpl_toolkits.mplot3d import Axes3Ddef density(t_end):x = np.linspace(-50,50,101)y = np.linspace(-50,50,101)x,y = np.meshgrid(x,y)d = np.zeros((101,101))d[50][50]=1d1 = deepcopy(d)for t in range(t_end):for i in range(101):for j in range(101):if i==0 or i==100 or j==0 or j==100:passelse:d[i][j]=0.25*(d1[i+1][j] + d1[i-1][j] + d1[i][j+1] + d1[i][j-1])d1=deepcopy(d)for i in range(101):for j in range(101):if i==0 or i==100 or j==0 or j==100:passelse:if d[i][j]==0:d[i][j]=0.25*(d1[i+1][j] + d1[i-1][j] + d1[i][j+1] + d1[i][j-1])return x,y,dx,y,z = density(100)[0],density(100)[1],density(100)[2]fig = plt.figure()ax = fig.add_subplot(111, projection='3d')ax.plot_surface(x, y, z)ax.set_xlabel('x')ax.set_ylabel('y')ax.set_zlabel('density')ax.set_title('Distribution in 2 dimension, t=100')plt.xlim(-50,50)plt.ylim(-50,50)plt.show()
import numpy as npimport matplotlib.pyplot as pltfrom copy import deepcopyimport matplotlib.cm as cmfrom mpl_toolkits.mplot3d import Axes3Ddef density(t_end):x = np.linspace(-50,50,101)y = np.linspace(-50,50,101)x,y = np.meshgrid(x,y)d = np.zeros((101,101))d[50][50]=1d1 = deepcopy(d)for t in range(t_end):for i in range(101):for j in range(101):if i==0 or i==100 or j==0 or j==100:passelse:d[i][j]=0.25*(d1[i+1][j] + d1[i-1][j] + d1[i][j+1] + d1[i][j-1])d1=deepcopy(d)for i in range(101):for j in range(101):if i==0 or i==100 or j==0 or j==100:passelse:if d[i][j]==0:d[i][j]=0.25*(d1[i+1][j] + d1[i-1][j] + d1[i][j+1] + d1[i][j-1])return x,y,dx,y,z = density(100)[0],density(100)[1],density(100)[2]fig = plt.figure()ax = fig.add_subplot(111, projection='3d')ax.plot_surface(x, y, z)ax.set_xlabel('x')ax.set_ylabel('y')ax.set_zlabel('density')ax.set_title('Distribution in 2 dimension, t=100')plt.xlim(-50,50)plt.ylim(-50,50)plt.show()
import numpy as npimport matplotlib.pyplot as pltfrom copy import deepcopyimport matplotlib.cm as cmfrom mpl_toolkits.mplot3d import Axes3Ddef density(t_end):x = np.linspace(-50,50,101)y = np.linspace(-50,50,101)x,y = np.meshgrid(x,y)d = np.zeros((101,101))d[50][50]=1d1 = deepcopy(d)for t in range(t_end):for i in range(101):for j in range(101):if i==0 or i==100 or j==0 or j==100:passelse:d[i][j]=0.25*(d1[i+1][j] + d1[i-1][j] + d1[i][j+1] + d1[i][j-1])d1=deepcopy(d)for i in range(101):for j in range(101):if i==0 or i==100 or j==0 or j==100:passelse:if d[i][j]==0:d[i][j]=0.25*(d1[i+1][j] + d1[i-1][j] + d1[i][j+1] + d1[i][j-1])return x,y,dx,y,z = density(100)[0],density(100)[1],density(100)[2]fig = plt.figure()ax = fig.add_subplot(111, projection='3d')ax.plot_surface(x, y, z)ax.set_xlabel('x')ax.set_ylabel('y')ax.set_zlabel('density')ax.set_title('Distribution in 2 dimension, t=100')plt.xlim(-50,50)plt.ylim(-50,50)plt.show()
注意这里三张图的z轴范围不同。可见,二维情况下结论与一维时是一致的。而这种行为符合我们对一个扩散过程的直观感受,即在初始时刻在某点滴入一定的扩散物,之后扩散物以该点为中心向四方扩散,直到各处的密度相同。
五、二维扩散体系中熵的变化
这里我们考虑在一个二维体系中熵是如何变化的。我们考察仅存在单个粒子时的情况。当二维系统为长为30的点阵时,熵与时间的关系为:
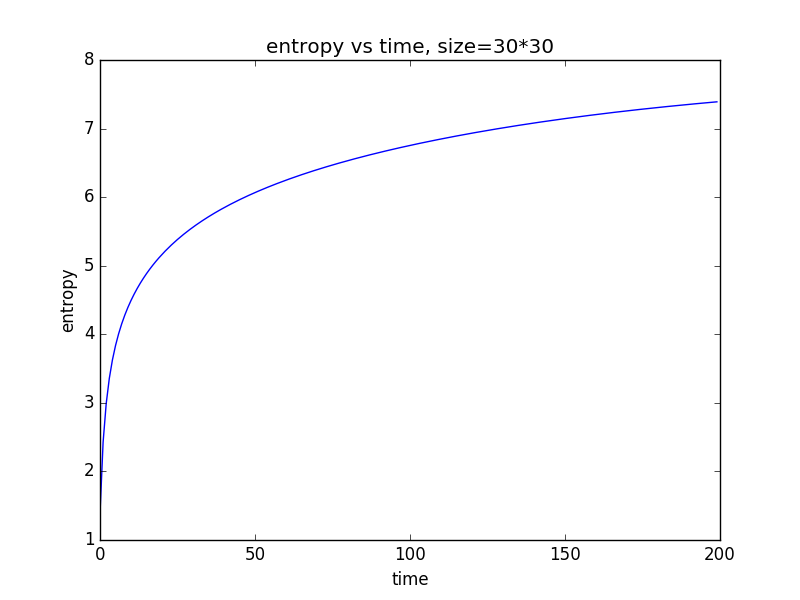
可见,随着时间增大,熵的值增大,但是其增长速度降低。最终它会收敛到一个定值。
六、结论
通过基于Python语言的数值计算,我们对随机行走过程可以得出如下结论:
1.对于一维的等可能随机行走,左右步长一定时,其与原点的距离平均值在0附近,距离平方的平均值线性增加。左右步长随机(-1~+1等可能)时,结论不变,只是距离平方的平均值的增加速度降低。
2.对于左右不等可能的随机行走,在左右步长一定时,距离平均值线性增肌,距离平方的平均值二次型增加。
3.对于一维和二维的随机行走过程,当粒子数很多时,其在各点密度显现出扩散的行为,是类扩散的。
4.在二维随机行走体系中,随着时间增大,系统的熵增大,增长速度降低,并最终收敛到一个定值。
这些结论与概率论的结果和我们的直觉是相符的。由此证明,基于Python语言的数值计算结果在模拟随机系统上有很大的作用,其结果是可信的。
参考文献
[1]计算物理 Nicholas J.Giordano, Hisao Nakanishi
