@cleardusk
2015-11-27T11:39:23.000000Z
字数 2770
阅读 2020
DL 在线书籍源码阅读(三)
GjzCVCode
2.2 CNN
该书的 CNN 实现源码是基于 Theano 实现的,源码我只是大概浏览了一遍,没有细看,与之前两个版本的区别有些大。该书作者的实现也借鉴了别人的代码。
This program incorporates ideas from the Theano documentation on
convolutional neural nets (notably,
http://deeplearning.net/tutorial/lenet.html ), from Misha Denil's
implementation of dropout (https://github.com/mdenil/dropout ), and
from Chris Olah (http://colah.github.io )self.
细读代码我还需要花点时间,也需要简单地了解一下 Theano。时间仓促,就大概写一下自己对 DNN 及 CNN 的认识。
2.2.1 DNN
作者在倒数第二章讲的主题是:为什么 Deep neuron network 训练这么难?之前一只用的是单层的隐藏网络,用了多层后,按理说效果应该会好一点,类似这样的网络。
training_data, validation_data, test_data = \mnist_loader.load_data_wrapper()net = network2.Network([784, 30, 30, 30, 30, 10], cost=network2.CrossEntropyCost)net.default_weight_initializer() # use another weight initialization methodnet.SGD(training_data, 30, 10, 0.1, lmbda=5.0, evaluation_data=validation_data,monitor_evaluation_accuracy=True)
但结果是,这样简单地叠加多层网络并不能改善准确率,当然,准确率也没有下降。
在分析 DNN 的训练过程中,会发现有 vanishing gradient 和 exploding gradient 的 problem,就是每一层网络训练的速度不一致,有时候底层比高层网络快,有时候慢。
最后总结了一些 DNN 的阻碍:
- Instability to gradient-based learning(vanishing, exploding)
- The choice of activication function
- The way weights are initialized
- Details of how learning by gradieng descent is implemented
2.2.2 CNN
当然,上面提到的一些问题被很好地解决了,比如 DNN 的其中一个模型:CNN。CNN 有三个特征,这也决定了它的网络结构。
Local receptive fields

Shared weights
比如上图中的 25 条 weights 是被共享的,所有这样的 weights 都是一样的。
σ(b+∑l=04∑m=04wl,maj+l,k+m).(3) Pooling layers

完整的一个应用于 MNIST 的一个简单的 CNN model

至于为什么 CNN 能工作起来,效果这么好,文中说是 CNN 的 ConvNet 层能够学习数据(这里是图像)的 spatial structure,也就是 feature。从 low level 到 high level 的 feature 的训练,让 CNN 能够发挥作用。当然,我并不是很明白 how it can work so well。
2.2.3 一些 Tricks
- Using rectified linear units,就是 ReLu,caffe 的一个示例用的也是这个。
- Expanding the training data,这个前面也说过,这里将原始数据 expand 了五倍,往上下左右各移动一个像素加上原始的,是原数据的 5 倍。
- Using an ensemble of networks, 这个 trick 还没用,我现在也不清楚到底怎么用,到底如何将几个 network 的结果 ensemble,文中并没有给示例代码。
2.2.4 Run
之前测试了一两个,发现跑的太慢了,干脆选了个效果最好的扔那跑,结果跑了 6.7 个小时(cpu mode)。test data 上最好的准确率是 99.59%。
代码
def test_best():"""One epoch takes 1196.6 s."""epoch = 20training_data, validation_data, test_data = network3.load_data_shared()expanded_training_data, _, _ = network3.load_data_shared("../data/mnist_expanded.pkl.gz")mini_batch_size = 10net = Network([ConvPoolLayer(image_shape=(mini_batch_size, 1, 28, 28),filter_shape=(20, 1, 5, 5),poolsize=(2, 2),activation_fn=ReLU),ConvPoolLayer(image_shape=(mini_batch_size, 20, 12, 12),filter_shape=(40, 20, 5, 5),poolsize=(2, 2),activation_fn=ReLU),FullyConnectedLayer(n_in=40*4*4, n_out=1000,activation_fn=ReLU, p_dropout=0.5),FullyConnectedLayer(n_in=1000, n_out=1000,activation_fn=ReLU, p_dropout=0.5),SoftmaxLayer(n_in=1000, n_out=10, p_dropout=0.5)],mini_batch_size)time_begin = time.clock()net.SGD(expanded_training_data, epoch, mini_batch_size, 0.03, validation_data,test_data)time_end = time.clock()print '%d epoch takes %.1f s' % (epoch, (time_end - time_begin))
结果
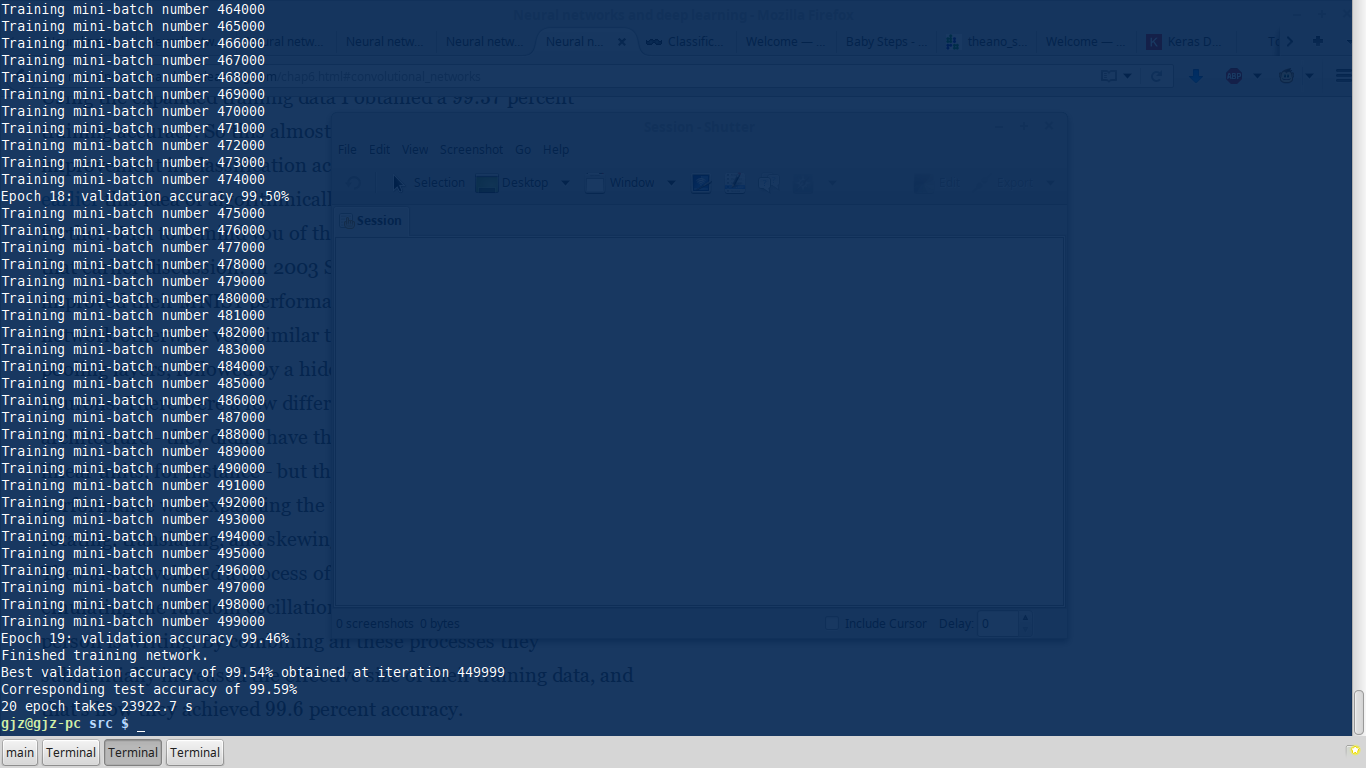
暂时写到这,有时间会继续更新。
