@cleardusk
2015-12-11T09:42:51.000000Z
字数 4071
阅读 2652
学习记录.12.11
GjzCV
转眼间一个月过去了。
主要工作
火力集中在 face research field 上,但感觉受了不少挫。
DL
第一天我把 A Lightened CNN for Deep Face Representation 这篇论文看的差不多了,网络的参数大概都弄懂了,虽然最后的那个 face alignment 的五个点,是怎么提取出来的我还不清楚,但我认为我可以开干了,caffe 稍微熟悉了,作者在 github 上也放出了 prototxt 网络定义文件和训练好的 model,心里想着可以跑一跑,如果跑不动我可以减少点数据,把网络的 size 改小点。准备第二天开工。这时老师传了一篇 paper 过来。。
ML
第一天晚上,我用 Face Recognition with Learning-based Descriptor 的 c++ 代码 train,用的 COFW 数据库,比较小,然后去睡觉了。早上看 log,训练花了 40 分钟,诶,训练的 model 在哪?定位了源码中保存 model 的位置,查了查 c++ fstream 的文档,解决了这个问题:参数不能有不存在的目录。训练好的模型 130M 左右,纯文本格式,每次一跑,加载 model 都需要三四秒,想着可以用二进制文件,读写部分用 c 写一下,应该能优化到一秒以内。第二天早上,老师又传了一篇 paper,其实就是之前传过的 Face Alignment at 3000 FPS via Regressing Local Binary Features 。看这篇论文花了一天多的时间,其实这篇论文的核心就是两个式子:
两个 target,两次 train,第一次是用 random forest 的方法来训练出 local binary feature,丢掉得到的 ( 是 landmark 的索引,landmark 由坐标对串构成,比如 对应的就是 , 是 shape,也是 landmark);第二次就是规规矩矩的以 square error 作为训练的 target,用这个得到的 代替前面的 。

这张图已经把 train 和 test 的过程说的很清楚了。 是 的 vector,即一组函数,每个 函数的参数是 , 是 shape,即 landmark 的坐标串, 是图像,即二维矩阵,本文用的是在 位置周围的 local region 对应的二维矩阵;train 的时候用 中的 target 来 train,test 的时候就用 train 好的 model(比如以 LBF.model 的文件名来存储)来 test,test 的步骤是:先得要一个 face 的 boundary box,这个可以通过人脸数据库中的 *.pts landmark 数据来 parse,或者通过 face detection 算法(比如 OpenCV 中提供的用 haar/lbp feature 和 adaboost 的算法,提供已经训练好的 frontalface,eye&glass 的 model,以 xml 格式 存储)来得到这个 boundary box(bbox short for it);接下来,得到的 bbox 干什么呢?先提一个 meanshape,meanshape 在 train 和 test 中都用到了,meanshape 就是计算所有 landmark 的平均值得到的一个 shape;在 test 过程中,bbox 记录了人脸的 location 以及 weight 和 hight,而 meanshape 只是一个标准化的,可以说是没有 location 和 width 和 hight 的 shape(也是 landmark),代表着数据库中所有人脸的平均长相(大众脸),meanshape 通过 bbox,还原出 bbox 中大致的 shape ,这时的 shape 有了 location,width 和 height,然后就通过 函数组,(shape, ) 作为参数,得到 LBP feature,LBP feature 就是一个 vector,vector feed 到 regression model 中,本文用的是基础的 linear regression model,target 是 square error,通过 linear regression 就得到了 predicted shape。
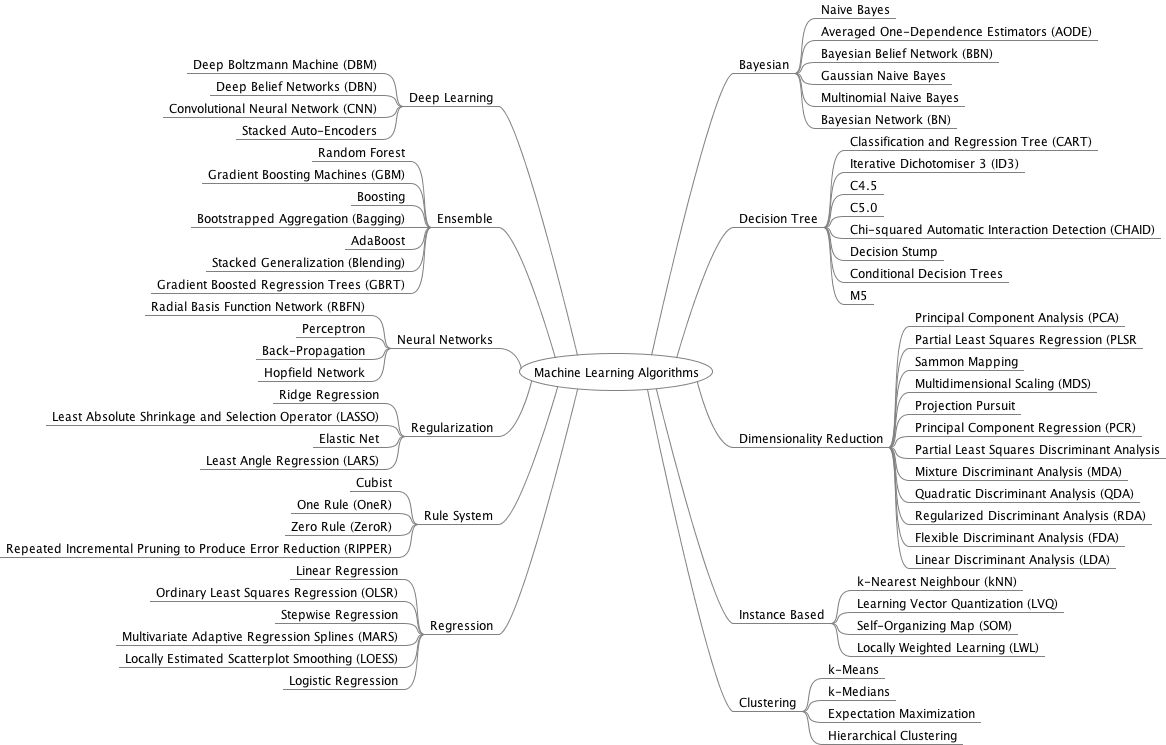
从比较 high level 的角度看,理解起来能接受,但是,一到具体的算法,我并不能很好的理解,比如 random forest,我还不知道文中是怎么用 random forest 算法来训练 的,以及 test 中,random forest 是如何 extract LBP feature 的,上面的叙述只是把 random forest 当做一个 black box,但这样肯定不行。关于 random forest,我下了文中引的原始的文献,一看 30 多页,便知道要去研究得费不少功夫,去了解它如何以及为什么能应用到图像上,也许还要花点时间,我泛泛地搜了下 random forest,在这个页面上,random forest 竟然在 Image Classification, Object Detection, Object Tracking, Edge Detection, Semantic Segmentation, Human / Hand Pose Estimation, 3D Localization, Low-Level Vision 这些领域都有应用。random forest 是 decision tree 的一种,我也找了一张 ML 算法的图,random forest tree 是属于 ensemble 方法的一种,ensemble 的意思就是给多个算法来个综合,提高 performance,random forest 就是一下子训练多个 tree,这样能有效减少 train error,其依据是数理统计的推导。random forest 我所不清楚的是,训练的参数存在于什么地方,如何去 train,error 又是什么,在本文中跟 又是怎么联系到一块的,虽然数据结构中接触了图 结构,但 decision tree 和 random forest tree 显然又不太像那么一回事,曾想通过调试 matlab 源码弄懂,边调试边吐槽这代码,我不是吐槽作者的水平(不过还要吐槽的是,最长的一行代码有 170 列),而是 matlab 可读性真的差劲,描述树结构,强类型语言如 C++/C#/Java 就强多了,我认为 matlab 适合快速验证想法,而不适合阅读,这是由于 matlab 的语言特性;当然,matlab 是可以写 class 的。
其它
在中间,我花了大概大半天时间,去搜了一下 face 研究的领域,比如 face detection 的历史,有肤色检测,有 motion detection,到后来的用 haar 特征等;还有 face detection --> face alignment --> feature extract --> match,face verification 是 one to one match,face identification 是 one to many match,这两个是有区别的等。我感觉早期用的数字图像处理的内容比较多,后来引了统计学进来,经常用到了 ML 中的算法,现在 DL 正热。但是,DL 其实是 ML 的一个分支,无论是 ML 还是 DL 用来研究 CV 领域中的问题,基础的数字图像处理是必不可少的,因为信息或者说 feature 都是从图像中来的;ML 跟信息论也有关系,用大白话说,既然是从数据提取信息,必然会涉及到信息论,,既然是从数据中学习,就会有一个熵减的过程。说是这么说,我不咋懂。
还花了一两天时间挑选 Linux 上的 C++ 的编辑器或者 IDE,以及选择合适的开发方式,最后选了 clion,结合 cmake,GCC 的 tool chain。之前一直用 Visual Studio,VS 是 C++ 最强 IDE 没有之一,有利也有弊,就不分析了;Linux 下强大的,是编译的工具链,一旦熟悉的话,搭建开发环境的效率是比 Windows 要高的,我从 GitHub 上 pull 一个项目编译,大部分就是
git clone git@github.com:someone/someprojectcd someprojectmkdir buildcd buildcmake ..
当然,很大概率上会编译失败,这时痛苦的解决之旅就会启程。当然,在 windows 上,可能有不少项目都不敢 pull 下来,都没法编译。不过,现在的项目的趋势都是跨平台了。
还有一天晚上,准备睡觉的时候,挂个脚本下东西,我一般最后会加个自动关机的选项,不知什么情况,网络断了,然后就自动关机的命令竟然被执行了。这时要困的不行,我又开了电脑,桌面竟然进不去!桌面 crash 掉了。以下省略若干字。。。
周五,就是今天,感觉状态不太好,就在 GitHub 上建了个 python 的小项目。
总结
我有过这个想法,把这篇论文,自己用 C++ 重新实现一遍,这必然要求自己完全搞懂所有的细节,此外,也可以锻炼以下码 C++ 的水平;然后再看看 dlib 实现的那个 One Millisecond Face Alignment with an Ensemble of Regression Trees,train 和 test 以下,两种方法对比一下。不过现在看来,真的搞的话,需要费不少力气了。
这周比较心浮气躁,打算下周沉下来,多接触点基础性的东西,看一些前沿的论文(发现看论文中提到的你都想不到的想法或者 trick 时,很有意思)。
