@gzm1997
2018-03-12T16:16:34.000000Z
字数 4412
阅读 2255
计网笔记第三章
计网笔记
传输层服务和协议
- 在两个不同主机上的应用之间提供逻辑上的连接
- 传输协议运行在两个端系统上
- 发送方:把应用层的message划分为传输层的segment,传送到网络层
- 接收方:重组segment为应用层的message,传送到应用层
传输层和网络层
网络层
两个主机之前的逻辑连接
传输层
两个进程之间的逻辑连接
Internet transport-layer protocals 网络传输层协议
TCP
可靠,按顺序传输
具有:
拥塞控制
流量控制
连接设置
UDP
不可靠
不按顺序传输
传输层的Multiplexing/demultiplexing 复用和分用
多路分解demultiplexing,将传输层的报文段数据交付到正确的套接字上工作
多路复用Multiplexing,源主机从不同的套接字中收集数据块,并为每个数据块封装上首部信息从而生成报文段,然后将报文段传递到网络层
示意图:
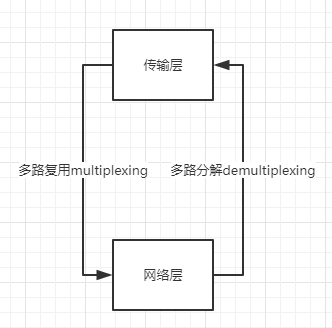
socket套接字的发送方的复用和接收方的分用都是依靠transport header来实现的
发送方的复用:
处理来自各个套接字的数据,增加transport header,等下被分用的时候用到接收方的分用:
使用transport header来把接收到的segment递给对的socket套接字(因为一个主机上有可能运行着多个套接字)
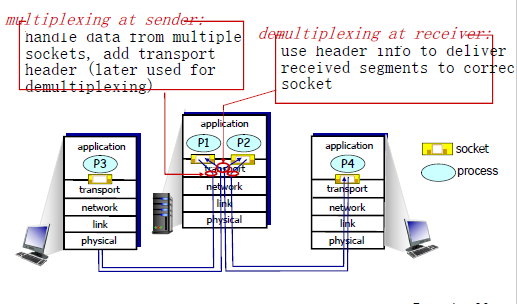
分用的工作原理
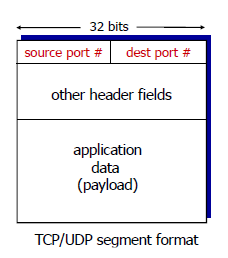
TCP/UDP segment形式
主机会使用ip地址和端口来引导segment到正确的socket套接字
无连接分用(UDP)
- 当主机接收到udp segment之后
- 检查segment中的destination port目标端口
- 以端口引导udp segment到相应的socket
- 带有相同的destination port的ip数据报但是源ip地址会被引导到相同的目标socket
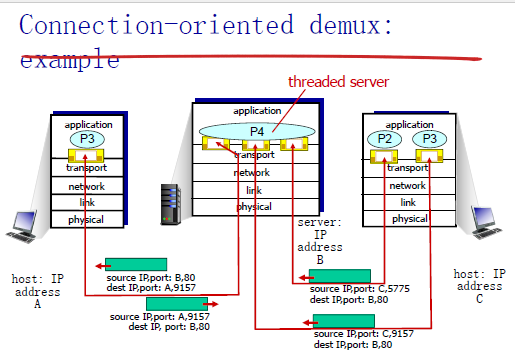
Connection-oriented demux 面向连接分用
TCP套接字根据一个4元组来区分:
- 源ip地址
- 源端口
- 目标ip地址
- 目标端口
分用:接收方使用所有这4个值来引导segment到正确的套接字上
服务端主机可以支持多个并发的TCP套接字
- 每个套接字有自己的4元组
web服务器对于不同的连接客户端有不同的套接字
- 非持久HTTP对于每个请求有不同的套接字
下面这个面向连接的套接字有点迷,有两台来自不同机器的segment发送到同一台机器上的同一个端口上,这时候,他们会被引导到**不同的socket**s上。
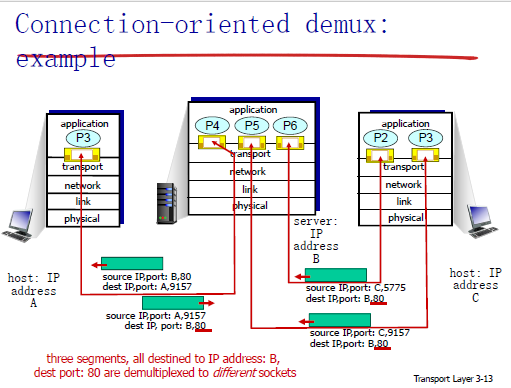
但是下面这个例子就很正常了,当时有多个目标ip地址和端口都相同的segment的时候,服务端应该使用线程,把不同的segment引导到不同的线程上处理:
UDP user datagram protocol用户数据报协议
- udp可能会丢包
- 打乱应用层的顺序
- 发送方和接收方之间不用握手
- 没个udp的segment之间是独立的
在UDP上可靠传输
- 在应用层上增加可靠性
- 特定应用程序错误恢复
UDP segment header
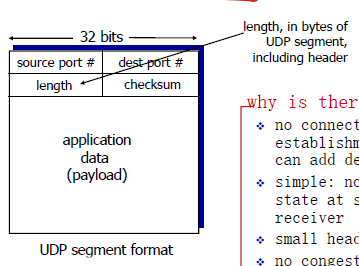
为什么要用UDP?
- 不用连接那么麻烦
- 简单(还是不用连接)
- header尺寸很小
- 没有阻塞控制
UDP checksum校验和
- 发送方:
- 处理header field为一个16位的序列
- checksum:短内容的反码
- 发送方把checksum的值放到UDP的checksum位置上
- 接收方:
- 计算接收到的segment的校验和
- 检查当计算出来的检验和等于检验和位上的值,等于-没有错误,否则-出错了。
检验和例子
两个16位整数相加

RDT reliable data transfer protocol可靠数据传输协议
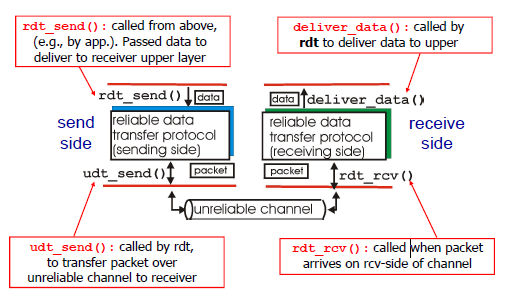
- 上一层例如应用层把数据传递给传输层,传输层使用可靠数据传输协议,传输层使用udt_send() 不可靠发送发送到不可靠通道
- 接收方使用rdt_rcv() 可靠接受接收segment,接收方的传输层使用可靠数据传输协议,然后使用deliver_data() 把segment转为message到上层的应用层
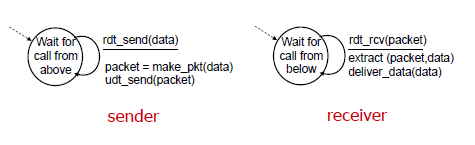
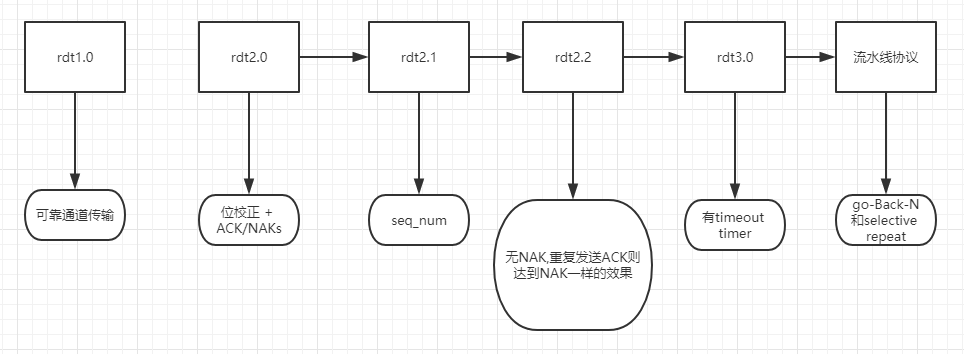
rdt1.0:通过可靠通道的可靠传输
下层的通道非常可靠
- 没有位错误
- 没有包丢失
发送方和接收方的有限状态机是分开的
- 发送方把数据发送到下层的通道
- 接收方从下层通道读数据
rdt2.0 带有位错误的通道
- 使用校验和来去除位错误
- 怎样从错误中恢复:
- acknowledgements (ACKs):接收方明确地告诉发送方packet没有问题
- negative acknowledgements (NAKs):接收方明确地告诉发送方packet有问题
- 发送方会把在NAK清单上的从新发一次
rdt2.0新机制:
- 错误检测
- 反馈,控制信息(ACK,NAK从客户端到服务端)
rdt2.0原理:
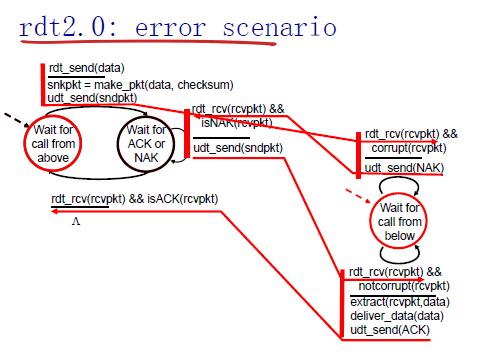
rdt2.0致命错误
当ACK/NAK出错的时候,怎办?
- 发送方无法知道接收方发生了什么
- 不能重新发送
处理重复packet:
- 如果ACK/NAK出错了,发送方重新发送目前的packet
- 发送方给每个packet增加一个序列号
- 接收方会忽视重复的packet
rdt2.1:处理错误ACK/NAKs
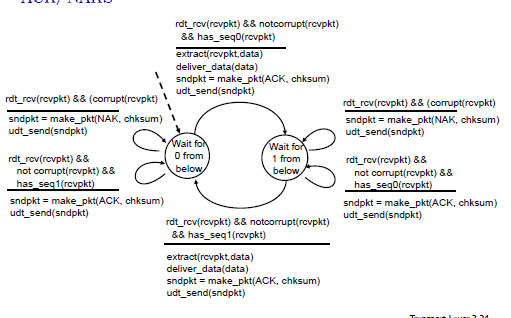
rdt2.2
无NAK,接收方最后一个包发送NAK,重复NAK导致重发,增加seq_num
rdt3.0
有timeout timer

由图可知,传输的时间远远短于等待的时间,链路的使用效率很低,所以就有了流水线协议。
流水线协议
- sequence number的范围需要增加
- 发送和接收方的缓存区
rdt总结
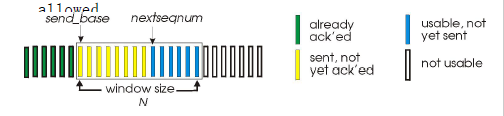
go-Back-N
- 流水线中可以发送N个unacked的包
- 接收方仅仅发送cumulative ack
- 如果有间隔不会ack packet
- 发送方对最老的unacked包有timer
- 当包过期的时候会重新发送
GBN窗口:
GBN工作原理:
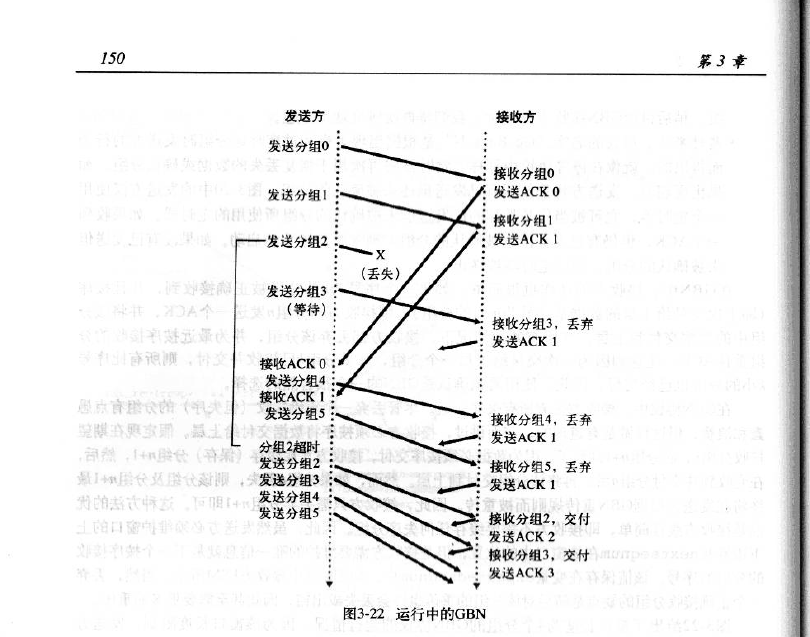
显示一次性发送0, 1, 2, 3四个包,0和1接收到了发送ack,但是3丢了,导致后面接着也发送的4,5包即使送到了接收方那里,接收方也是会丢弃的
selective repeat
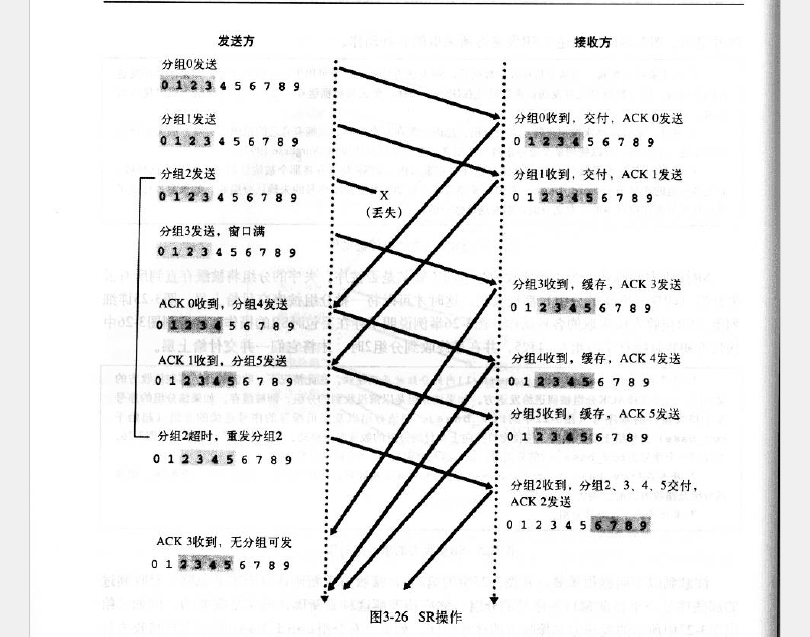
包0接收到了,交付,但是包1丢了,这时候包2 3 4。。会继续发送,但是接收方接收到之后是缓存,并且发送相应的ack2 3 4,当包1的timeout到了之后,重新发送2 3 ,这时候,包1 2 3 4。。交付
预测RTT
一般a的值为0.125
RTT和样例RTT之间是有误差的:
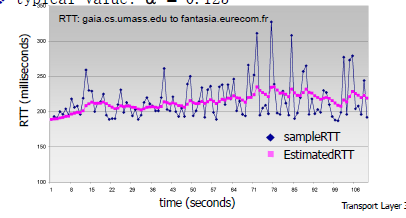
安全边缘safety margin:
一般而言,B = 0.25
估算timeoutInterval:
面向连接传输:TCP
tcp发送端事件:
- 从客户端接收带有seq #的数据段
- seq #是segment中第一个数据字节的byte-stream number
- 如果timer没在运行,那么让timer运行
- 认为计时器是计时最老的;unacked的数据段
- 过期时间:TimeOutInterval
timeout:
- 重新发送导致timeout的segment
- 重启计时器timer
ack recvd接收到ack:
- 如果ack是ack之前还没ack的的segment
- 更新被ack的segment
- 如果还有还没被ack的segment,开启计时器
TCP快速重传
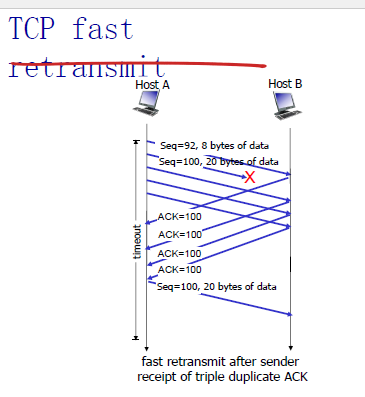
tcp快速重传:
如果发送方发现有三个对于同一个还没被ack的segment的acks,重新发送这个unack的segment
因为很有可能这个unacked已经丢失了,所以不等到timeout了。
快速重传算法:
event: ACK received, with ACK field value of yif (y > SendBase) {SendBase = yif (there are currently not-yet-acknowledged segments)start timer}else {increment count of dup ACKs received for yif (count of dup ACKs received for y = 3) {resend segment with sequence number y}
流量控制
TCP连接的接受的一边会有一个接受缓冲区receive buffer:
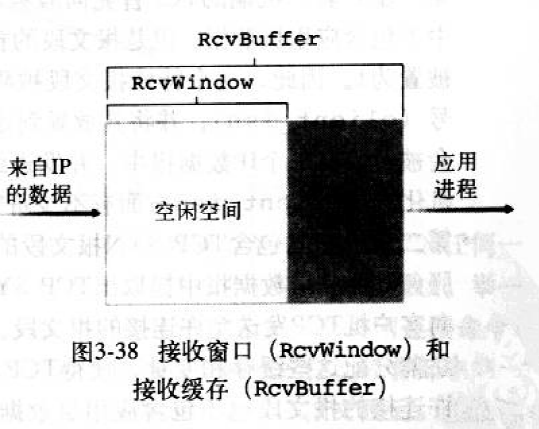
接受方的空余接受缓存区大小:
rwnd这个值放入发给发送方的报文段接收窗口字段中,通知发送方还有多少缓存空间,即:
控制使得:
连接管理
三方握手示意图:
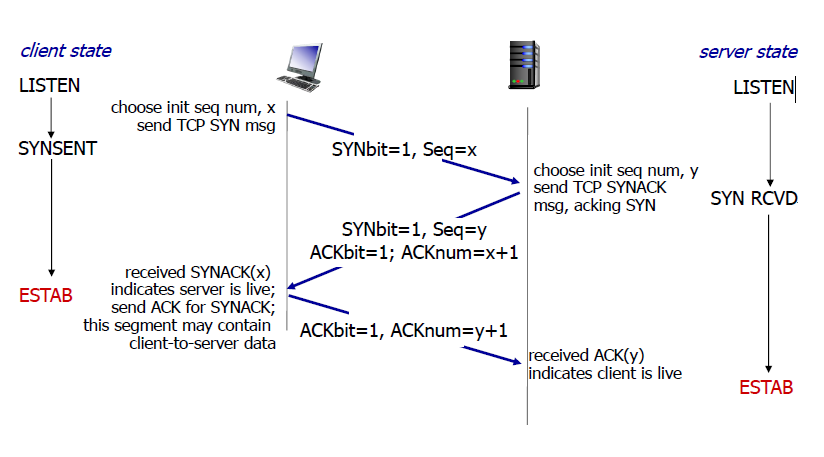
- 客户端随机选择一个序列号x,发送SYN报文段(SYN位为1,序列号位置为选择的序列号x)
- 服务端接收到SYN报文段,选择一个序列号y,发送SYNACK报文段(SYN位为1,序列号为y,ACKbit为1,ACKnum为x + 1)
- 客户端接收到SYNack报文段,知道服务端还活着,为这个SYNack报文段发送ACK,这个ACK报文段可能包含客户端到服务端的数据(ACKbit为1,ACKnum为y + 1)
- 服务端收到了ACK(y),知道客户端还活着。
断开连接:
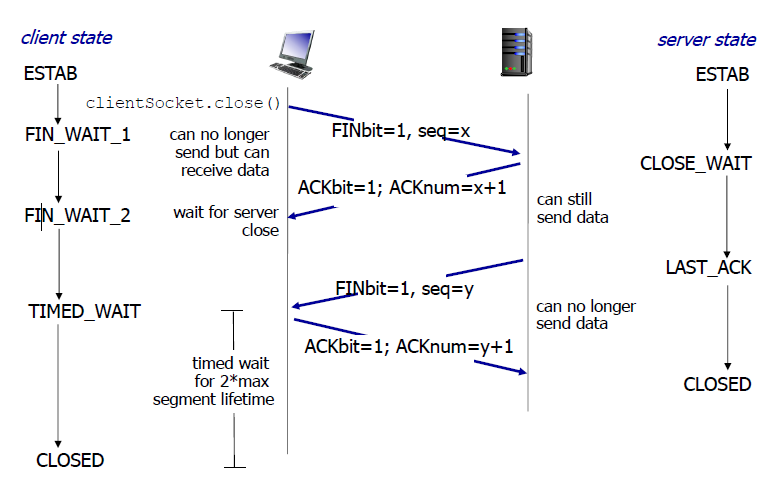
- 客户端先选择一个序列号x,发送tcp报文(FINbit为1,seq序列号位置为x)
- 服务端接收到这个Fin报文段之后,发送ACK报文段(ACKbit为1,ACKnum为x + 1)
- 服务端选择序列号y,发送tcp报文段(FINbit为1,seq序列号位置为y)
- 客户端接收到报文段之后,发送ACK报文段(ACKbit为1,ACKnum为y + 1)
阻塞
非正式地说就是太多数据被发送得太快以至于网络无法处理
后果:
- 丢包
- 长等待
阻塞的三种情况:
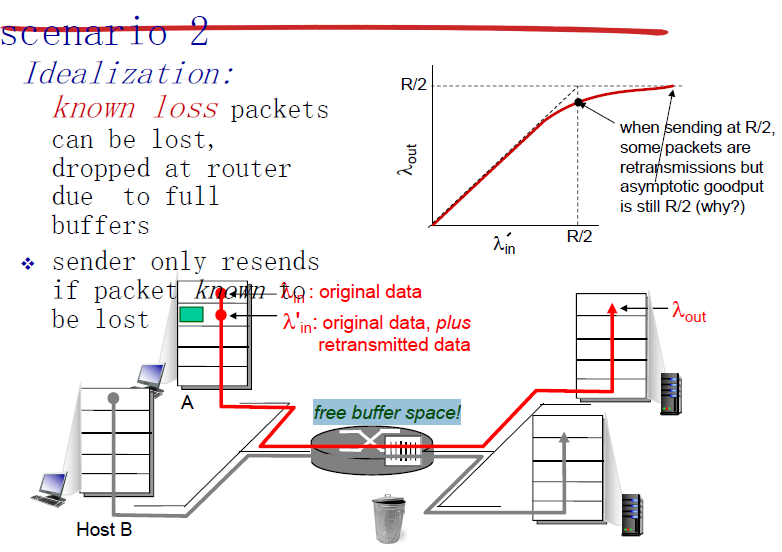
1. 路由器无限缓存
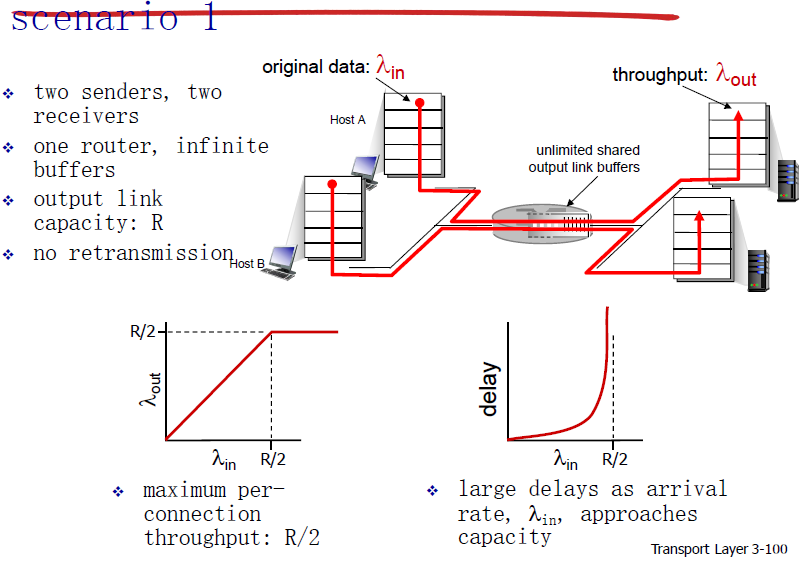
路由器有限缓存,发送方丢包后会重发
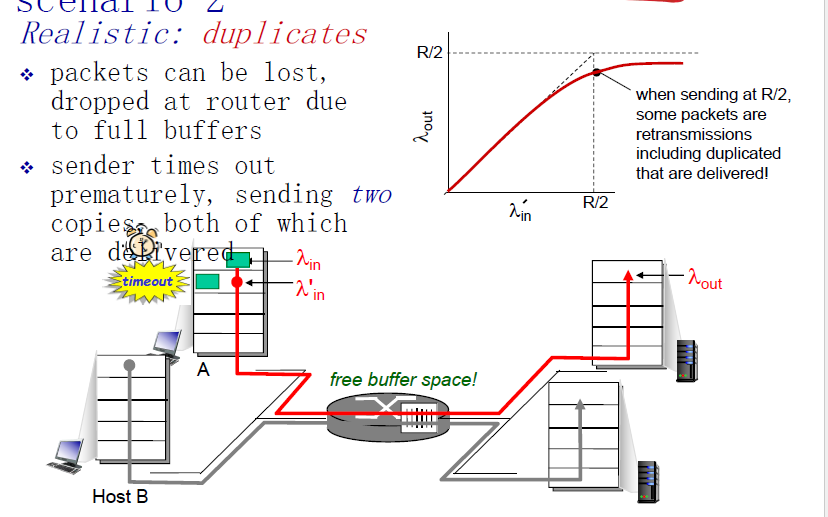
当有过早Timeout的时候
多台有限缓存路由器和多跳路径:
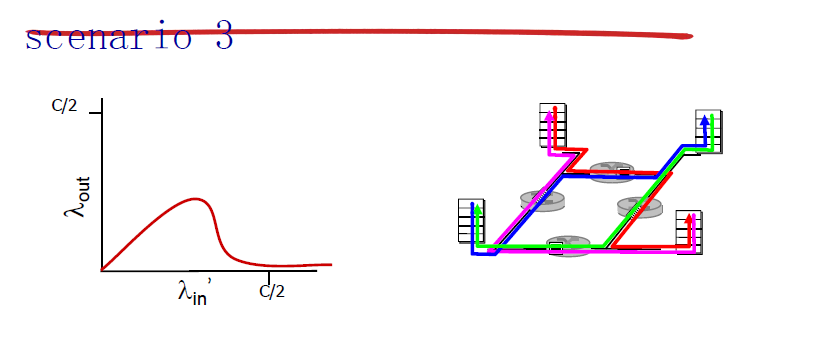
拥塞控制方法
- 端对端拥塞控制
网络层没有显式支持,端系统需要观察分组的丢失和延时 - 网络辅助的拥塞控制
网络层提供显示支持
TCP拥塞控制
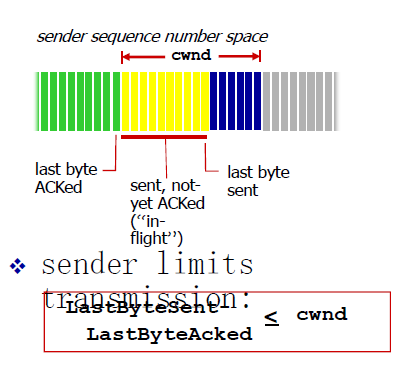
rwnd是接受窗口,cwnd是拥塞窗口
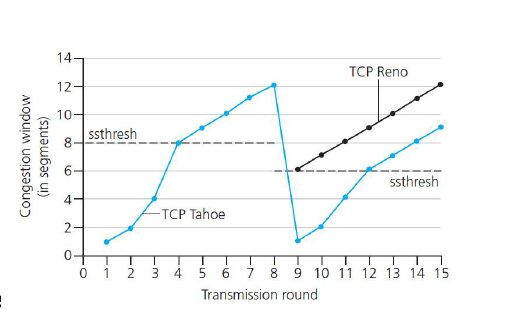
TCP慢启动

当连接建立,在第一次丢包之前,指数增长发送速率
1. 初始化拥塞窗口为1个MSS
2. 每个RTT之后,让cwnd翻倍
何时结束这种指数增长?
- 检测到丢包事件,cwnd设置为1,重新开始慢启动
- 当检测到丢包事件的时候把慢启动阈值ssthresh设置为拥塞窗口的一半,当达到ssthresh时,转移到拥塞避免模式
- 检测到3个冗余的ACK,执行快速重传,并进入快速恢复状态
拥塞避免
当进入拥塞状态时,cwnd大概是大概是上次拥塞状态的一半,这时,每个RTT只将cwnd增加一个MSS,例如在发送10个报文段,没收到一个ACK就增加1/10个MSS,在接受了10个ACK之后就增加了1个MSS
快速恢复
出现丢包事件时,cwnd设置为1MSS,并且ssthresh设置为cwnd的一半。
慢启动 -> 拥塞避免 -> 快速恢复
吞吐量
一条连接的平均TCP吞吐量:
