@nataliecai1988
2017-09-25T01:24:47.000000Z
字数 5633
阅读 1850
百度开源移动端深度学习框架mobile-deep-learning(MDL)(AI前线)
投稿 百度
进一步揭秘:百度开源移动端深度学习框架MDL
作者:王柳、杨延展、刘瑞龙
编辑:Natalie
2017年9月25日,百度在GitHub(https://github.com/baidu/mobile-deep-learning)开源了移动端深度学习框架mobile-deep-learning(MDL)的全部代码以及脚本,希望这个项目在社区的带动下能够更好地发展。
mobile-deep-learning(简称MDL)致力于让卷积神经网络能够极度简单地部署在手机端,目前已稳定运行于百度多款应用中。MDL针对arm平台架构做了精心优化,同时支持iOS和Android,在CPU和GPU上的运算速度均处于业界领先水平,拥有运算速度快、库体积小、部署简便等特点。
行业背景
在当下互联网行业中,机器学习、神经网络等技术逐步在业界落地实施,而目前大部分还是集中在服务端技术。由于移动端硬件等因素的限制,深度学习技术的应用有着诸多困难,2016年百度为在客户端使用深度学习能力做了大量工作,在2017年初解决所有技术障碍,并在iOS版手机百度上线,2017年8月份在Android版手机百度上线。
移动端使用深度学习后,可以在不发起网络请求的情况下完成图像识别、视频风格化、语音识别等各种任务。目前,在国内外深度学习领域中,移动客户端可用的深度学习框架非常少,大部分由于体积过大、运行速度慢、资源占用高、兼容性差等原因而无法在移动端应用。
下表对比了目前已有的移动端机器学习库,从体积上看,目前MDL是最小的;CPU速度上,MDL和ncnn相当;在支持CPU的同时,MDL还支持GPU运算。目前MDL在iOS版提供了利用matel加速运算的能力,兼容所有iOS8以上版本,使用GPU加速后的运算性能会有几倍的提升。
| 框架 | Caffe2 | Tensorflow | ncnn | MDL(CPU) | MDL(GPU) |
|---|---|---|---|---|---|
| 计算硬件 | CPU | CPU | CPU | CPU | GPU |
| 手机计算速度 | 慢 | 慢 | 很快 | 很快 | 极快 |
| 手机库大小 | 大 | 大 | 小 | 小 | 小 |
| 系统兼容性 | Android&iOS | Android&iOS | Android&iOS | Android&iOS | iOS |
MDL框架设计
设计思路
作为一款移动端深度学习框架,我们充分考虑到移动应用自身及运行环境的特点,在速度、体积、资源占用率等方面提出了严格的要求,因为其中任何一项指标对用户体验都有重大影响。
同时,可扩展性、鲁棒性、兼容性也是我们设计之初就考虑到了的。为了保证框架的可扩展性,我们对layer层进行了抽象,方便框架使用者根据模型的需要,自定义实现特定类型的层,我们期望MDL通过添加不同类型的层实现对更多网络模型的支持,而不需要改动其他位置的代码;为了保证框架的鲁棒性,MDL通过反射机制,将C++底层异常抛到应用层,应用层通过捕获异常对异常进行相应处理,如通过日志收集异常信息、保证软件可持续优化等;目前行业内各种深度学习训练框架种类繁多,而MDL不支持模型训练能力,为了保证框架的兼容性,我们提供Caffe模型转MDL的工具脚本,使用者通过一行命令就可以完成模型的转换及量化过程,后续我们会陆续支持PaddlePaddle、TensorFlow等模型转MDL,兼容更多种类的模型。
总体架构
MDL框架的总体架构设计图如下:
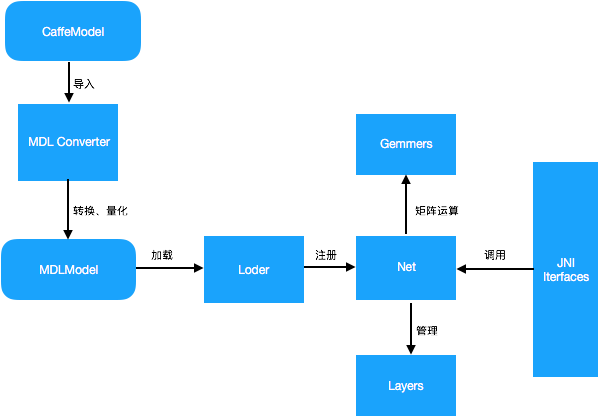
MDL框架主要包括模型转换模块(MDL Converter)、模型加载模块(Loader)、网络管理模块(Net)、矩阵运算模块(Gemmers)及供Android端调用的JNI接口层(JNI Interfaces)。其中,模型转换模块主要负责将Caffe模型转为MDL模型,同时支持将32bit浮点型参数量化为8bit参数,从而极大地压缩模型体积;模型加载模块主要完成模型的反量化及加载校验、网络注册等过程,网络管理模块主要负责网络中各层Layer的初始化及管理工作;MDL提供了供Android端调用的JNI接口层,开发者可以通过调用JNI接口轻松完成加载及预测过程。
iOS GPU部分架构设计图如下:
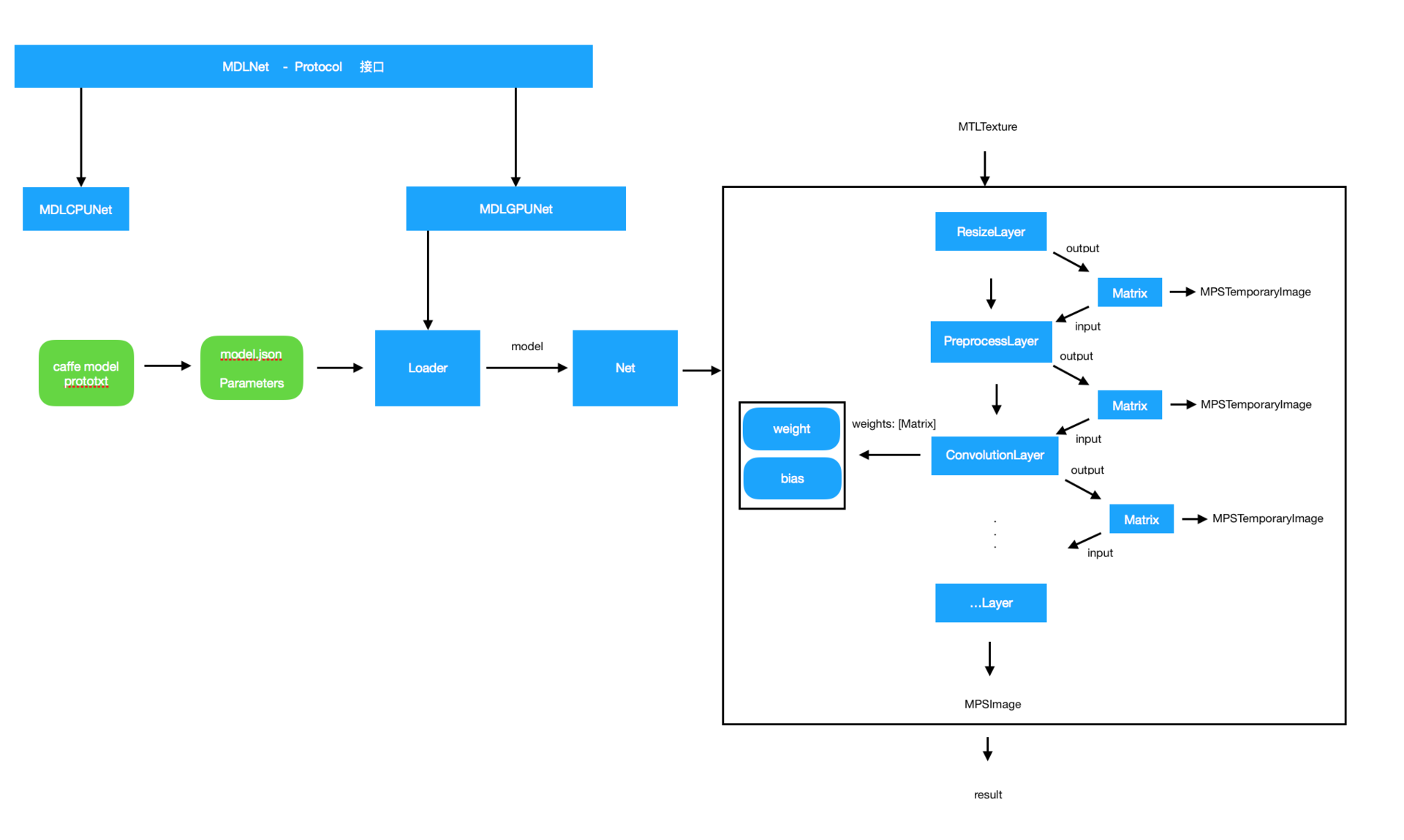
模型转换模块(MDL Converter)中,在iOS GPU处理参数部分有一个特殊步骤,caffemodel存储权重参数的矩阵顺序为[outputChannels, inputChannels, kernelHeight, kernelWidth], 而Metal所使用的权重参数为[outputChannels, kernelHeight, kernelWidth, inputChannels],脚本所做的操作就是将参数提取出来并且按照Metal所使用的顺序进行重新排序。
iOS GPU库部分的实现分为两个部分,即Loader和Net:Loader部分将json 文件、权重参数和偏置参数加载进model对象和Matrixs(存储的是Matrix对象, Matrix代表矩阵类型,Layer的输入输出、Convolution的权重和偏置都作为一个矩阵存储在Matrix的实例对象中),通过Loader步骤,权重和偏置从文件读取到内存中。
Net所做的工作是获取接口给的输入,经过一系列Layer的计算处理,取得最终结果。Layer可以是苹果MetalPerformanceShader提供的API,也可以是通过Metal自定义的Layer,不同的网络结果会使用到不同种类的Layer。
这里还有一层Preprocess层需要注意。这一层需要外部使用Metal指定预处理的步骤,同时,如果使用Caffe训练的网络则使用的输入为BGR顺序,而ResizeLayer后的像素顺序为RGB,所以在这个步骤要处理像素顺序为BGR;处理中间结果使用的是MPSTemporaryImage,MPSTemporaryImage可以保证在使用完这块内存之后马上释放,而不是等到整个预测结束之后才释放,所以整体对内存的消耗非常低。
通过Loader加载数据到Net的predict获取结果,再到不使用时调用clear接口就完成了一个完整的预测过程。
MDL优势介绍
体积小
为了尽可能减少框架的体积,我们摆脱了对各种第三方类库(如OpenBlas、ProtoBuf等)的依赖,最终库体积仅350Kb左右,基本能够随包安装,即使离线下载,耗费流量也极少。下图是MDL同其他深度学习框架的体积对比。
")
由上图可见,传统的深度学习框架如Caffe2和Tensorflow的手机端集成库体积都超过8M,MDL和ncnn体积相当,都控制在0.5M内。
速度快
MDL在CPU上使用多线程技术实现并行优化,同时针对ARM架构,利用NEON intrinsics及内联汇编对计算操作进行了深度优化。在CPU上,我们对squeezenetV1.1网络模型完成一次forward的时间约133ms,对googlenet网络模型完成一次forward的时间约360ms。下图是MDL同其他深度学习框架的对比,测试手机为小米6,系统版本MIUI8。
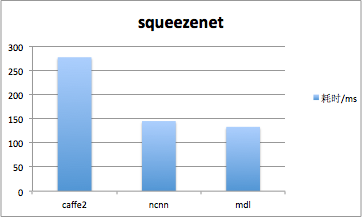
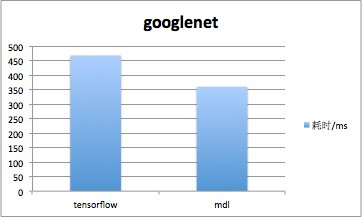
可见MDL在CPU上单次forward速度远快于TensorFlow和Caffe2,ncnn速度表现也很不错,基本与MDL持平。
在iOS上,MDL使用GPU进行并行计算,极大提升了运算速度。使用GPU运算,MDL对squeezenetV1.1网络模型完成一次forward的时间约36ms,对googlenet网络模型完成一次forward的时间约130ms。下图是MDL同其他框架的速度对比,测试手机是iphone5SE,系统是iOS 10.3.3。
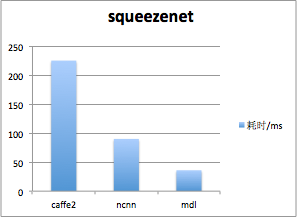
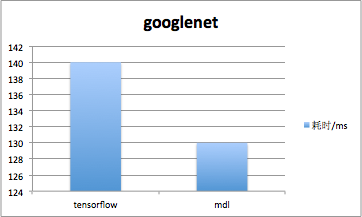
采用GPU并行计算的MDL框架,同ncnn、Caffe2等框架相比,在iOS上速度优势十分明显。
集成使用简单
MDL使用Cmake构建,具有良好的跨平台编译能力,目前支持Android、iOS、Mac和Linux的构建。MDL提供极其友好的编译脚本,支持一键部署,脚本参数就可以切换iOS/Android/Mac编译目标,简单到极致。
资源占用少
在用户体验至上的时代,应用资源占用大小也是决定其是否可最终上线的重要因素。MDL经过苛刻的性能优化,并经历线上验证。MDL运行squeezenet模型执行分类任务时,DeviceMonitor统计到的手机CPU使用率峰值仅4.47%,内存占用31.3M左右,而TensorFlow运行googlenet执行分类任务,DeviceMonitor统计到的手机CPU使用率峰值为30%,内存占用56.6M左右。
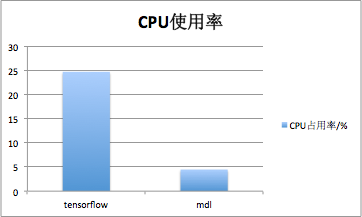
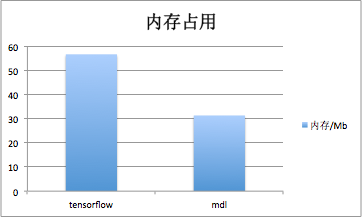
支持GPU加速
MDL在iOS下使用了苹果提供的MetalPerformanceShader和Metal框架进行矩阵运算。GPU适合做大量并行运算,在矩阵运算场景下,使用GPU进行运算的优势很大,而Metal是针对苹果设备优化过的操作GPU的语言,所以在性能和效率上,对比使用CPU进行运算会有很大的提升。在iPhone5SE设备上,使用MDL对1280*720视频流的帧使用squeezenet进行识别时,一帧的识别时间最快可以达到30ms左右,稳定在36ms左右。而且使用GPU进行识别对性能的消耗是非常低的,在对1280*720视频流进行每秒20次的连续识别时,内存占用为15MB左右,使用较长时间手机也不会发热,无论是在速度上还是在性能上都体现出了优势。
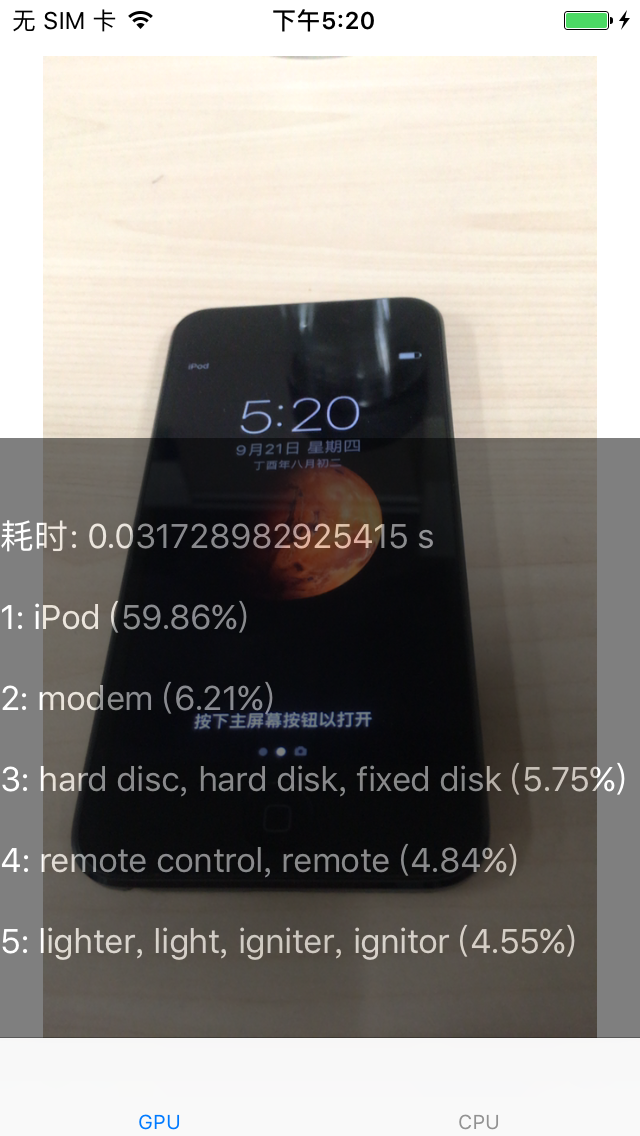
MDL优化细节
1. 剥离所有第三方依赖,轻量上阵
传统的深度学习框架都会引入大量的第三方类库。举例来说,大部分框架都会选择同时接入多个后端(backend),如OpenBlas、NNPack等等,用以支撑具体的计算操作;模型的加载和序列化也会使用额外的类库,如ProtoBuffer等。而移动端由于存储空间的限制,对于框架的体积极为敏感,过多引入第三方类库会使框架本身变得臃肿庞大,对于很多的移动端应用场景而言是无法接受的。为此,MDL进行了精心的框架设计,摘除了所有第三方依赖。对于神经网络的计算过程,MDL使用了自建的相对小巧的计算库;对于模型的加载和序列化,MDL使用了极简版的Json解析器。通过摘除第三方依赖,使得MDL极为轻量,不仅体积小巧,而且构建过程也更加简易。
2. 纯C/C++实现,天然跨平台
MDL选择纯C/C++实现框架代码,保证了程序能高效运行;使用CMake进行工程构建,保证了其天然的跨平台构建能力。目前MDL支持iOS、Android、Mac及Linux的构建。不论是iOS还是Android开发人员,都可以轻松地获取、编译和部署MDL代码。
3. 精心的ARM NEON优化,保证移动端的运算速度
目前ARM是移动端的主要CPU架构。针对ARM架构,MDL利用NEON intrinsics及内联汇编对计算操作进行了深度优化。MDL通过大量使用NEON intrinsics,充分利用了ARM架构的SIMD矢量计算能力,一条指令、多条数据,把同类计算任务并行执行,对矩阵乘法、Lrn层计算等等都起到了显著的加速效果。同时,MDL还使用了内存对齐、指令预取、循环展开等技巧深度挖掘CPU的计算潜力。并对一些计算方法,使用数学上的近似计算,在保证精度的前提下简化其计算复杂度。
4. 调整代码结构,最大限度的减少前向传播过程中的计算开销
MDL提供了专门的转化脚本,用以将Caffe模型转化为MDL可以加载的模型。在模型转化过程中,MDL充分考虑了运行时的开销问题,尽量将所有不依赖运行时的操作,转移到脚本转化的阶段来完成;尽量将所有不依赖于前向传播的操作,转移到模型的加载阶段来完成。例如,所有提前就可以决定的矩阵形状调整、临时变量的形状计算、内存分配等等,全部交给转化脚本及模型加载的代码逻辑来实现。从而一定程度上减少了网络模型前向传播过程中的计算压力。
5. 内置量化模型工具,极大压缩模型文件的体积
移动端对于体积极为敏感,常见的深度学习网络模型如GoogleNet等,都有较大的权重文件,对于很多移动端的应用场景并不适用。为此,MDL内置了模型压缩工具,可以读取量化后的模型文件,极大地减少了模型文件的体积。更轻量,更适用。对于很多应用而言,甚至可以将压缩后的模型文件直接内置到App中。
6. 充分支持多分支结构,优化并行逻辑
移动端CPU相对桌面CPU有很多性能退化,简单暴力地使用多线程加速往往会适得其反。优秀的多线程加速,必须最小化线程间切换的开销,必须考虑线程切换后导致的缓存失效等问题。深度学习网络中大量使用了矩阵乘法,矩阵乘法对缓存命中率的要求极高,因此,移动端上的深度学习框架必须对多线程优化慎之又慎。MDL充分利用了神经网络中的多分支结构,能够自动利用神经网络中天然存在的并发计算流程,从而较好地避免了上述问题,提高了网络计算的性能。
后续规划
为了让MDL体积进一步缩小,MDL并未使用protobuf做为模型配置存储,而是使用了Json格式。目前MDL支持Caffe模型转换到MDL模型,未来会支持全部主流模型转换为MDL模型。
随着移动端设备运算性能的提升,GPU在未来移动端运算领域将会承担非常重要的角色,MDL对于GPU的实现极为看重。目前MDL已经支持iOS GPU运行,iOS10以上版本机型均可以使用。根据目前得到的统计数据显示,iOS10已经涵盖绝大部分iOS系统,在iOS10以下可以使用CPU运算。除此之外,虽然Android平台目前的GPU运算能力与CPU相比整体偏弱,但日益涌现的新机型GPU已经越来越强大。MDL后面也将加入GPU的Feature实现,基于OpenCL的Android平台GPU运算会让高端机型的运算性能再提升一个台阶。
最后再次奉上MDL的GitHub目录:https://github.com/baidu/mobile-deep-learning,欢迎有识之士济济加入,将深度学习技术在移动端广泛应用、播扬海内。
