@qidiandasheng
2021-01-04T02:46:16.000000Z
字数 25353
阅读 2302
面向对象之六大原则(😁)
架构
六大原则介绍
其实我们常说的是五大设计原则,简称SOLID原则,是除了下面迪米特法则外其他原则首字母的缩写合成的名字。
| 缩写 | 英文名称 | 中文名称 |
|---|---|---|
| SRP | Single Responsibility Principle | 单一职责原则 |
| OCP | Open Close Principle | 开闭原则 |
| LSP | Liskov Substitution Principle | 里氏替换原则 |
| LoD | Law of Demeter ( Least Knowledge Principle) | 迪米特法则(最少知道原则) |
| ISP | Interface Segregation Principle | 接口分离原则 |
| DIP | Dependency Inversion Principle | 依赖倒置原则 |
单一职责原则
理解:不同的类具备不同的职责,各司其职。如果发现有一个类拥有了两种职责,那么就要问一个问题:可以将这个类分成两个类吗?如果真的有必要,那就分开,千万不要让一个类干的事情太多。
总结:一个类只承担一个职责
开闭原则
理解:类、模块、函数,可以去扩展,但不要去修改。如果要修改代码,尽量用继承或组合的方式来扩展类的功能,而不是直接修改类的代码。当然,如果能保证对整个架构不会产生任何影响,那就没必要搞的那么复杂,直接改这个类吧。
总结:对软件实体的改动,最好用扩展而非修改的方式。
里氏替换原则
理解:一个对象在其出现的任何地方,都可以用子类实例做替换,并且不会导致程序的错误。换句话说,当子类可以在任意地方替换基类且软件功能不受影响时,这种继承关系的建模才是合理的。
总结:子类可以扩展父类的方法,但不应该复写父类的方法。
接口隔离原则
理解:一个类实现的接口中,包含了它不需要的方法。将接口拆分成更小和更具体的接口,有助于解耦,从而更容易重构、更改。
总结:对象不应被强迫依赖它不使用的方法。
依赖倒置原则
理解:高层模块不应该依赖低层模块,二者都应该依赖其抽象;抽象不应该依赖细节;细节应该依赖抽象。
总结:面向接口编程,提取出事务的本质和共性。
迪米特法则
理解:一个对象对另一个对象了解得越多,那么它们之间的耦合性也就越强,当修改其中一个对象时,对另一个对象造成的影响也就越大。
总结:一个对象应该对其他对象保持最少的了解,实现低耦合、高内聚。
组合/聚合复用原则
理解:合成/聚合复用原则就是在一个新的对象里面使用一些已有的对象,使之成为新对象的一部分;新的对象通过向这些对象的委派达到复用已有功能的目的。它的设计原则是:要尽量使用合成/聚合,尽量不要使用继承。
总结:就是说要少用继承,多用合成关系来实现。
高内聚、松耦合
“高内聚、松耦合”是一个非常重要的设计思想,能够有效提高代码的可读性和可维护性,缩小功能改动导致的代码改动范围。“高内聚”用来指导类本身的设计,“松耦合”用来指导类与类之间依赖关系的设计。所谓高内聚,就是指相近的功能应该放到同一个类中,不相近的功能不要放到同一类中。相近的功能往往会被同时修改,放到同一个类中,修改会比较集中。所谓松耦合指的是,在代码中,类与类之间的依赖关系简单清晰。即使两个类有依赖关系,一个类的代码改动也不会或者很少导致依赖类的代码改动。
其实以上的一些原则都是为了实现代码的高内聚、松耦合。
单一职责原则(Single Responsibility Principle)
定义
一个类只允许有一个职责,即只有一个导致该类变更的原因。
定义的解读
类职责的变化往往就是导致类变化的原因:也就是说如果一个类具有多种职责,就会有多种导致这个类变化的原因,从而导致这个类的维护变得困难。
往往在软件开发中随着需求的不断增加,可能会给原来的类添加一些本来不属于它的一些职责,从而违反了单一职责原则。如果我们发现当前类的职责不仅仅有一个,就应该将本来不属于该类真正的职责分离出去。
不仅仅是类,函数(方法)也要遵循单一职责原则,即:一个函数(方法)只做一件事情。如果发现一个函数(方法)里面有不同的任务,则需要将不同的任务以另一个函数(方法)的形式分离出去。
优点
如果类与方法的职责划分得很清晰,不但可以提高代码的可读性,更实际性地更降低了程序出错的风险,因为清晰的代码会让bug无处藏身,也有利于bug的追踪,也就是降低了程序的维护成本。
单一职责原则是为了实现代码高内聚、低耦合,提高代码的复用性、可读性、可维护性。
代码讲解
需求点
初始需求:需要创造一个员工类,这个类有员工的一些基本信息。
新需求:增加两个方法:
判定员工在今年是否升职
计算员工的薪水
不好的设计
//================== Employee.h ==================@interface Employee : NSObject//============ 初始需求 ============@property (nonatomic, copy) NSString *name; //员工姓名@property (nonatomic, copy) NSString *address; //员工住址@property (nonatomic, copy) NSString *employeeID; //员工ID//============ 新需求 ============//计算薪水- (double)calculateSalary;//今年是否晋升- (BOOL)willGetPromotionThisYear;@end
由上面的代码可以看出:
- 在初始需求下,我们创建了Employee这个员工类,并声明了3个员工信息的属性:员工姓名,地址,员工ID。
- 在新需求下,两个方法直接加到了员工类里面。
新需求的做法看似没有问题,因为都是和员工有关的,但却违反了单一职责原则:因为这两个方法并不是员工本身的职责。
calculateSalary这个方法的职责是属于会计部门的:薪水的计算是会计部门负责。willPromotionThisYear这个方法的职责是属于人事部门的:考核与晋升机制是人事部门负责。
而上面的设计将本来不属于员工自己的职责强加进了员工类里面,而这个类的设计初衷(原始职责)就是单纯地保留员工的一些信息而已。因此这么做就是给这个类引入了新的职责,故此设计违反了单一职责原则。
我们可以简单想象一下这么做的后果是什么:如果员工的晋升机制变了,或者税收政策等影响员工工资的因素变了,我们还需要修改当前这个类。
那么怎么做才能不违反单一职责原则呢? 我们需要将这两个方法(责任)分离出去,让本应该处理这类任务的类来处理。
较好的设计
我们保留员工类的基本信息:
//================== Employee.h ==================@interface Employee : NSObject//初始需求@property (nonatomic, copy) NSString *name;@property (nonatomic, copy) NSString *address;@property (nonatomic, copy) NSString *employeeID;
接着创建新的会计部门类:
//================== FinancialApartment.h ==================#import "Employee.h"//会计部门类@interface FinancialApartment : NSObject//计算薪水- (double)calculateSalary:(Employee *)employee;@end
和人事部门类:
//================== HRApartment.h ==================#import "Employee.h"//人事部门类@interface HRApartment : NSObject//今年是否晋升- (BOOL)willGetPromotionThisYear:(Employee*)employee;@end
通过创建了两个分别专门处理薪水和晋升的部门,会计部门和人事部门的类:FinancialApartment 和HRApartment,把两个任务(责任)分离了出去,让本该处理这些职责的类来处理这些职责。
这样一来,不仅仅在此次新需求中满足了单一职责原则,以后如果还要增加人事部门和会计部门处理的任务,就可以直接在这两个类里面添加即可。
UML 类图对比
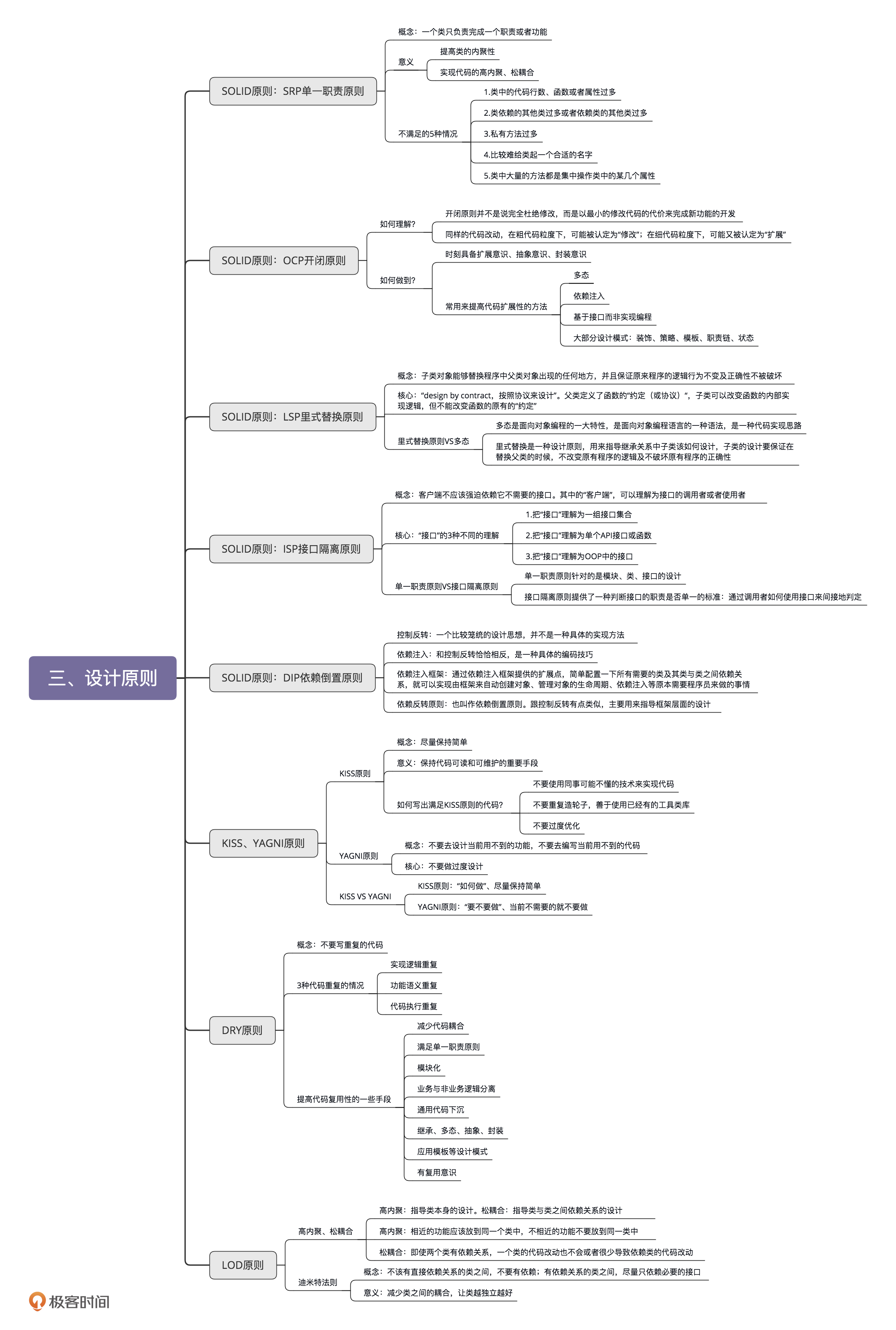
未实践单一职责原则:

实践了单一职责原则:
如何实践
对于上面的员工类的例子,或许是因为我们先入为主,知道一个公司的合理组织架构,觉得这么设计理所当然。但是在实际开发中,我们很容易会将不同的责任揉在一起,这点还是需要开发者注意的。
不同的应用场景、不同阶段的需求背景、不同的业务层面,对同一个类的职责是否单一,可能会有不同的判定结果。
比如下面这个用户信息类,如果这个app比较简单地址那部分只是简单的展示,那么放到用户类里面没问题。但如果app后面做了电商业务,需要地址这部分拆分出来独立为物流信息类会更合适。再后面如果公司内部多个app统一账户系统,也就是用户一个账号可以在公司内部的所有产品中登录,我们则可以把email和telephone独立出来为身份认证信息类会更合适。
public class UserInfo {private long userId;private String username;private String email;private String telephone;private long createTime;private long lastLoginTime;private String avatarUrl;private String provinceOfAddress; // 省private String cityOfAddress; // 市private String regionOfAddress; // 区private String detailedAddress; // 详细地址// ... 省略其他属性和方法...}
一些侧面的判断指标更具有指导意义和可执行性,比如,出现下面这些情况就有可能说明这类的设计不满足单一职责原则:
- 类中的代码行数、函数或者属性过多;
- 类依赖的其他类过多,或者依赖类的其他类过多;
- 私有方法过多;
- 比较难给类起一个合适的名字;
- 类中大量的方法都是集中操作类中的某几个属性。
开闭原则(Open Close Principle)
定义
一个软件实体如类、模块和函数应该对扩展开放,对修改关闭。
添加一个新的功能,应该是通过在已有代码基础上扩展代码(新增模块、类、方法、属性等),而非修改已有代码(修改模块、类、方法、属性等)的方式来完成。关于定义,我们有两点要注意。第一点是,开闭原则并不是说完全杜绝修改,而是以最小的修改代码的代价来完成新功能的开发。第二点是,同样的代码改动,在粗代码粒度下,可能被认定为“修 改”;在细代码粒度下,可能又被认定为“扩展”。
定义的解读
- 用抽象构建框架,用实现扩展细节。
- 不以改动原有类的方式来实现新需求,而是应该以实现事先抽象出来的接口(或具体类继承抽象类)的方式来实现。
优点
实践开闭原则的优点在于可以在不改动原有代码的前提下给程序扩展功能。增加了程序的可扩展性,同时也降低了程序的维护成本。
代码讲解
需求点
设计一个在线课程类:
由于教学资源有限,开始的时候只有类似于博客的,通过文字讲解的课程。 但是随着教学资源的增多,后来增加了视频课程,音频课程以及直播课程。
不好的设计
最开始的文字课程类:
//================== Course.h ==================@interface Course : NSObject@property (nonatomic, copy) NSString *courseTitle; //课程名称@property (nonatomic, copy) NSString *courseIntroduction; //课程介绍@property (nonatomic, copy) NSString *teacherName; //讲师姓名@property (nonatomic, copy) NSString *content; //课程内容@end
Course类声明了最初的在线课程所需要包含的数据:
- 课程名称
- 课程介绍
- 讲师姓名
- 文字内容
接着按照上面所说的需求变更:增加了视频,音频,直播课程:
//================== Course.h ==================@interface Course : NSObject@property (nonatomic, copy) NSString *courseTitle; //课程名称@property (nonatomic, copy) NSString *courseIntroduction; //课程介绍@property (nonatomic, copy) NSString *teacherName; //讲师姓名@property (nonatomic, copy) NSString *content; //文字内容//新需求:视频课程@property (nonatomic, copy) NSString *videoUrl;//新需求:音频课程@property (nonatomic, copy) NSString *audioUrl;//新需求:直播课程@property (nonatomic, copy) NSString *liveUrl;@end
三种新增的课程都在原Course类中添加了对应的url。也就是每次添加一个新的类型的课程,都在原有Course类里面修改:新增这种课程需要的数据。
这就导致:我们从Course类实例化的视频课程对象会包含并不属于自己的数据:audioUrl和liveUrl:这样就造成了冗余,视频课程对象并不是纯粹的视频课程对象,它包含了音频地址,直播地址等成员。
很显然,这个设计不是一个好的设计,因为(对应上面两段叙述):
- 随着需求的增加,需要反复修改之前创建的类。
- 给新增的类造成了不必要的冗余。
之所以会造成上述两个缺陷,是因为该设计没有遵循对修改关闭,对扩展开放的开闭原则,而是反其道而行之:开放修改,而且不给扩展提供便利。
较好的设计
首先在Course类中仅仅保留所有课程都含有的数据:
//================== Course.h ==================@interface Course : NSObject@property (nonatomic, copy) NSString *courseTitle; //课程名称@property (nonatomic, copy) NSString *courseIntroduction; //课程介绍@property (nonatomic, copy) NSString *teacherName; //讲师姓名
接着,针对文字课程,视频课程,音频课程,直播课程这三种新型的课程采用继承Course类的方式。而且继承后,添加自己独有的数据:
文字课程类:
//================== VideoCourse.h ==================@interface VideoCourse : Course@property (nonatomic, copy) NSString *videoUrl; //视频地址@end
音频课程类:
//================== AudioCourse.h ==================@interface AudioCourse : Course@property (nonatomic, copy) NSString *audioUrl; //音频地址@end
直播课程类:
//================== LiveCourse.h ==================@interface LiveCourse : Course@property (nonatomic, copy) NSString *liveUrl; //直播地址@end
这样一来,上面的两个问题都得到了解决:
随着课程类型的增加,不需要反复修改最初的父类(Course),只需要新建一个继承于它的子类并在子类中添加仅属于该子类的数据(或行为)即可。
因为各种课程独有的数据(或行为)都被分散到了不同的课程子类里,所以每个子类的数据(或行为)没有任何冗余。
而且对于第二点:或许今后的视频课程可以有高清地址,视频加速功能。而这些功能只需要在VideoCourse类里添加即可,因为它们都是视频课程所独有的。同样地,直播课程后面还可以支持在线问答功能,也可以仅加在LiveCourse里面。
我们可以看到,正是由于最初程序设计合理,所以对后面需求的增加才会处理得很好。
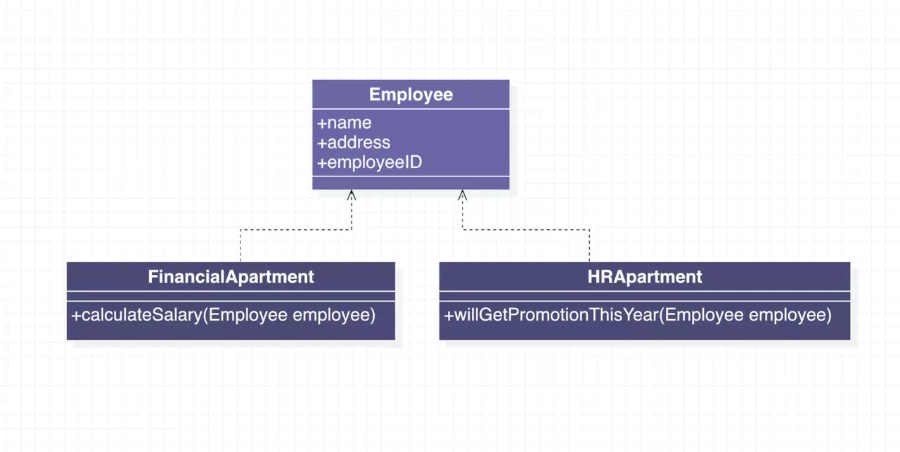
UML 类图对比
未实践开闭原则:

实践了开闭原则:
在实践了开闭原则的 UML 类图中,四个课程类继承了Course类并添加了自己独有的属性。(在 UML 类图中:实线空心三角箭头代表继承关系:由子类指向其父类)
代码讲解二
以下Java代码就是简单的基于抽象、多态、依赖注入来实现开闭原则的例子:
// 这一部分体现了抽象意识public interface MessageQueue { //... }public class KafkaMessageQueue implements MessageQueue { //... }public class RocketMQMessageQueue implements MessageQueue {//...}public interface MessageFromatter { //... }public class JsonMessageFromatter implements MessageFromatter {//...}public class ProtoBufMessageFromatter implements MessageFromatter {//...}public class Demo {private MessageQueue msgQueue; // 基于接口而非实现编程public Demo(MessageQueue msgQueue) { // 依赖注入this.msgQueue = msgQueue;}// msgFormatter:多态、依赖注入public void sendNotification(Notification notification, MessageFormatter msg){//...}}
如何实践
为了更好地实践开闭原则,在设计之初就要想清楚在该场景里哪些数据(或行为)是一定不变(或很难再改变)的,哪些是很容易变动的。将后者抽象成接口或抽象方法,以便于在将来通过创造具体的实现应对不同的需求。
里氏替换原则(Liskov Substitution Principle)
定义
- 所有引用基类的地方必须能透明地使用其子类的对象,也就是说子类对象可以替换其父类对象,而程序执行效果不变。
- 如果对每一个类型为S的对象o1,都有类型为T的对象o2,使得以T定义的所有程序P在所有的对象o1都代换成o2时,程序P的行为没有发生变化,那么类型S是类型T的子类型。
定义的解读
在继承体系中,子类中可以增加自己特有的方法,也可以实现父类的抽象方法,但是重写父类的非抽象方法时需要慎重,否则该继承关系就不是一个正确的继承关系。
父类中已实现的方法其实是一种已定好的规范和契约,如果我们随意的修改了它,那么可能会带来意想不到的错误。
里式替换原则就是用来指导,继承关系中子类该如何设计的一个原则。理解里式替换原则,最核心的就是理解design by contract,按照协议来设计”这几个字。父类定义了函数的“约定”(或者叫协议),那子类可以改变函数的内部实现逻辑,但不能改变函数原有的“约定”。这里的约定包括:函数声明要实现的功能;对输入、输出、异常的约定;甚至 包括注释中所罗列的任何特殊说明。
多态和里式替换的区别
多态是一种特性、能力,里氏替换是一种原则、约定。
虽然多态和里氏替换不是一回事,但是里氏替换这个原则 需要多态这种能力才能实现。
里氏替换最重要的就是替换之后原本的功能一点不能少。
优点
可以检验继承使用的正确性,约束继承在使用上的泛滥。
代码讲解
需求点
实现一个计算机,能够简单的实现两数的相加
后面增加需求变成两数相加再加100。
不好的设计
父类实现了A+B的方法:
//================== Calculator.h ==================@class Calculator;@interface Calculator : NSObject- (int)funcA:(int)A withB:(int)B;@end//================== Calculator.m ==================#import "Calculator.h"@implementation Calculator- (int)funcA:(int)A withB:(int)B{return A+B;}@end
子类实现,A+B+100的方法:
//================== NewCalculator.h ==================@class NewCalculator;@interface NewCalculator : Calculator- (int)funcA:(int)A withB:(int)B;- (int)newfuncA:(int)A withB:(int)B;@end//================== NewCalculator.m ==================#import "NewCalculator.h"@implementation NewCalculator- (int)funcA:(int)A withB:(int)B{return A-B;}- (int)newfuncA:(int)A withB:(int)B{int c = [self funcA:A withB:B];return c+100;}@end
NewCalculator *newCalculator = [NewCalculator new];[newCalculator newfuncA:50 withB:30];输出结果为:120
上面的运行结果明显是错误的,实际应该为180。类NewCalculator继承自Calculator,后来需要增加新功能,类NewCalculator新写了一个方法,然后因为直接复写了父类Calculator里相加的方法,不小心写错成了相减,导致了整个程序出错。
上述子类就是因为违反里氏替换原则,直接复写了父类的方法,导致出现的问题。
较好的设计
这也并不是较好的设计,只是不复写了父类的方法,遵守了父类的规范和契约,遵守了里氏替换原则,减少了带来意想不到的错误的可能。
//================== NewCalculator.h ==================@class NewCalculator;@interface NewCalculator : Calculator- (int)newfuncA:(int)A withB:(int)B;@end//================== NewCalculator.m ==================#import "NewCalculator.h"@implementation NewCalculator- (int)newfuncA:(int)A withB:(int)B{int c = [self funcA:A withB:B];return c+100;}@end
如何实践
里氏替换原则是对继承关系的一种检验:检验是否真正符合继承关系,以避免继承的滥用。因此,在使用继承之前,需要反复思考和确认该继承关系是否正确,或者当前的继承体系是否还可以支持后续的需求变更,如果无法支持,则需要及时重构,采用更好的方式来设计程序。
接口分离原则(Interface Segregation Principle)
定义
多个特定的客户端接口要好于一个通用性的总接口。
如果把“接口”理解为一组接口集合,可以是某个微服务的接口,也可以是某个类库的接口等。如果部分接口只被部分调用者使用,我们就需要将这部分接口隔离出来,单独给这部分调用者使用,而不强迫其他调用者也依赖这部分不会被用到的接口。
如果把“接口”理解为单个API接口或函数,部分调用者只需要函数中的部分功能,那我们就需要把函数拆分成粒度更细的多个函数,让调用者只依赖它需要的那个细粒度函数。
如果把“接口”理解为 OOP 中的接口,也可以理解为面向对象编程语言中的接口语法。那接口的设计要尽量单一,不要让接口的实现类和调用者,依赖不需要的接口函数。
定义解读
- 客户端(调用方)不应该依赖它不需要实现的接口。
- 不建立庞大臃肿的接口,应尽量细化接口,接口中的方法应该尽量少。
需要注意的是:接口的粒度也不能太小。如果过小,则会造成接口数量过多,使设计复杂化。
接口隔离原则与单一职责原则的区别
单一职责原则针对的是模块、类、接口的设计。接口隔离原则相对于单一职责原则,一方面更侧重于接口的设计,另一方面它的思考角度也是不同的。
接口隔离原则提供了一种判断接口的职责是否单一的标准:通过调用者如何使用接口来间接地判定。如果调用者只使用部分接口或接口的部分功能,那接口的设计就不够职责单一。
优点
避免同一个接口里面包含不同类职责的方法,接口责任划分更加明确,符合高内聚低耦合的思想。
代码讲解
需求点
现在的餐厅除了提供传统的店内服务,多数也都支持网上下单,网上支付功能。写一些接口方法来涵盖餐厅的所有的下单及支付功能。
不好的设计
//================== RestaurantProtocol.h ==================@protocol RestaurantProtocol <NSObject>- (void)placeOnlineOrder; //下订单:online- (void)placeTelephoneOrder; //下订单:通过电话- (void)placeWalkInCustomerOrder; //下订单:在店里- (void)payOnline; //支付订单:online- (void)payInPerson; //支付订单:在店里支付@end
在这里声明了一个接口,它包含了下单和支付的几种方式:
下单:
- online下单
- 电话下单
- 店里下单(店内服务)
支付:
- online支付(适用于online下单和电话下单的顾客)
- 店里支付(店内服务)
对应的,我们有三种下单方式的顾客:
1.online下单,online支付的顾客
//================== OnlineClient.h ==================#import "RestaurantProtocol.h"@interface OnlineClient : NSObject<RestaurantProtocol>@end//================== OnlineClient.m ==================@implementation OnlineClient- (void)placeOnlineOrder{NSLog(@"place on line order");}- (void)placeTelephoneOrder{//not necessarily}- (void)placeWalkInCustomerOrder{//not necessarily}- (void)payOnline{NSLog(@"pay on line");}- (void)payInPerson{//not necessarily}@end
2.电话下单,online支付的顾客
//================== TelephoneClient.h ==================#import "RestaurantProtocol.h"@interface TelephoneClient : NSObject<RestaurantProtocol>@end//================== TelephoneClient.m ==================@implementation TelephoneClient- (void)placeOnlineOrder{//not necessarily}- (void)placeTelephoneOrder{NSLog(@"place telephone order");}- (void)placeWalkInCustomerOrder{//not necessarily}- (void)payOnline{NSLog(@"pay on line");}- (void)payInPerson{//not necessarily}@end
3.在店里下单并支付的顾客:
//================== WalkinClient.h ==================#import "RestaurantProtocol.h"@interface WalkinClient : NSObject<RestaurantProtocol>@end//================== WalkinClient.m ==================@implementation WalkinClient- (void)placeOnlineOrder{//not necessarily}- (void)placeTelephoneOrder{//not necessarily}- (void)placeWalkInCustomerOrder{NSLog(@"place walk in customer order");}- (void)payOnline{//not necessarily}- (void)payInPerson{NSLog(@"pay in person");}@end
我们发现,并不是所有顾客都必须要实现RestaurantProtocol里面的所有方法。由于接口方法的设计造成了冗余,因此该设计不符合接口隔离原则。
较好的设计
要符合接口隔离原则,只需要将不同类型的接口分离出来即可。我们将原来的RestaurantProtocol接口拆分成两个接口:下单接口和支付接口。
下单接口:
//================== RestaurantPlaceOrderProtocol.h ==================@protocol RestaurantPlaceOrderProtocol <NSObject>- (void)placeOrder;@end
支付接口:
//================== RestaurantPaymentProtocol.h ==================@protocol RestaurantPaymentProtocol <NSObject>- (void)payOrder;@end
现在有了下单接口和支付接口,我们就可以让不同的客户来以自己的方式实现下单和支付操作了:
首先创建一个所有客户的父类,来遵循这个两个接口:
//================== Client.h ==================#import "RestaurantPlaceOrderProtocol.h"#import "RestaurantPaymentProtocol.h"@interface Client : NSObject<RestaurantPlaceOrderProtocol,RestaurantPaymentProtocol>@end
接着另online下单,电话下单,店内下单的顾客继承这个父类,分别实现这两个接口的方法:
1.online下单,online支付的顾客
//================== OnlineClient.h ==================#import "Client.h"@interface OnlineClient : Client@end//================== OnlineClient.m ==================@implementation OnlineClient- (void)placeOrder{NSLog(@"place on line order");}- (void)payOrder{NSLog(@"pay on line");}@end
2.电话下单,online支付的顾客
//================== TelephoneClient.h ==================#import "Client.h"@interface TelephoneClient : Client@end//================== TelephoneClient.m ==================@implementation TelephoneClient- (void)placeOrder{NSLog(@"place telephone order");}- (void)payOrder{NSLog(@"pay on line");}@end
3.在店里下单并支付顾客:
//================== WalkinClient.h ==================#import "Client.h"@interface WalkinClient : Client@end//================== WalkinClient.m ==================@implementation WalkinClient- (void)placeOrder{NSLog(@"place walk in customer order");}- (void)payOrder{NSLog(@"pay in person");}@end
因为我们把不同职责的接口拆开,使得接口的责任更加清晰,简洁明了。不同的客户端可以根据自己的需求遵循所需要的接口来以自己的方式实现。
而且今后如果还有和下单或者支付相关的方法,也可以分别加入到各自的接口中,避免了接口的臃肿,同时也提高了程序的内聚性。
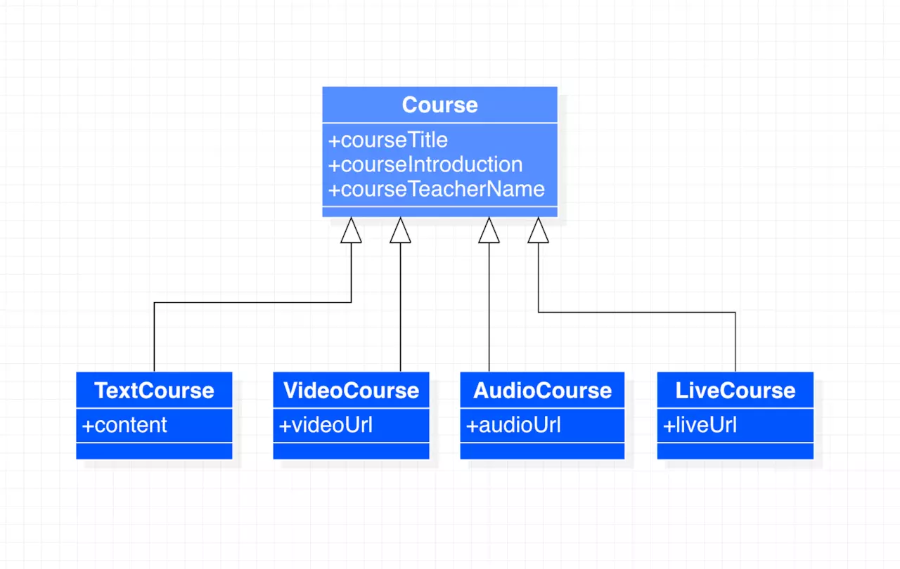
UML 类图对比
未实践接口分离原则:
实践了接口分离原则:
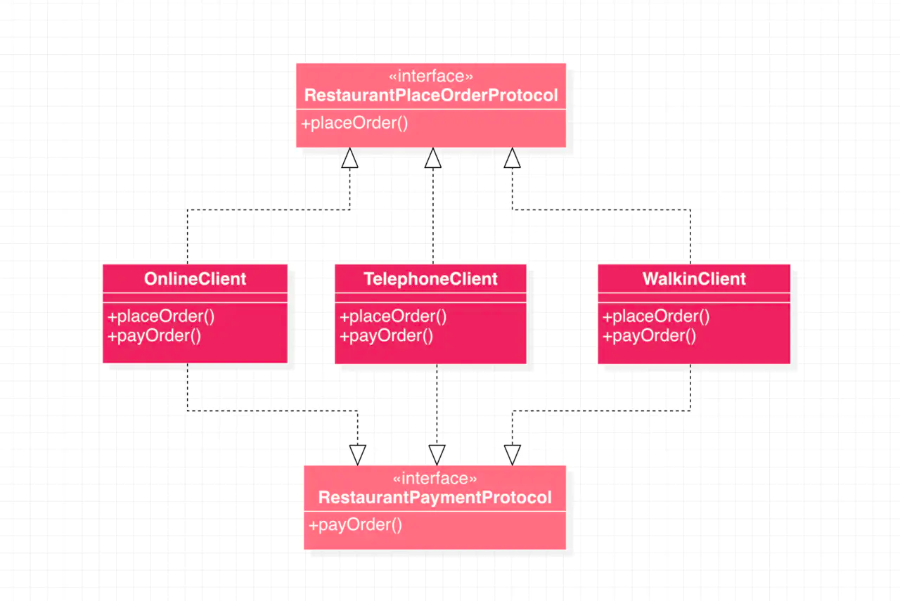
通过遵守接口分离原则,接口的设计变得更加简洁,而且各种客户类不需要实现自己不需要实现的接口。
代码讲解二
下面是一个配置相关的代码,包括用户配置,设置中心配置,主题配置。有两个需求,一个需求是需要动态更新配置,但只有设置中心配置和主题配置可以动态更新。另一个是显示配置的需求,只有设置中心和用户配置可以显示。
这里我们把更新和显示这两个接口隔离(OC里的协议),调用方只依赖他需要的接口。
//动态更新接口@protocol UpdateProtocol <NSObject>- (void)update;@end//显示配置接口@protocol ViewProtocol <NSObject>- (void)showConfig;@end
//用户配置@interface UserConfig : NSObject<ViewProtocol>@end@implementation UserConfig- (void)showConfig{}@end//设置中心配置@interface SettingConfig : NSObject<UpdateProtocol,ViewProtocol>@end@implementation UserConfig- (void)showConfig{}- (void)update{}@end//主题配置@interface ThemeConfig : NSObject<UpdateProtocol>@end@implementation ThemeConfig- (void)update{}@end
//更新中心@interface Updater : NSObject- (void)addUpdateConfig:(id<UpdateProtocol>)config;- (void)update;@end//显示中心@interface Viewer : NSObject- (void)addViewConfig:(id<ViewProtocol>)config;- (void)show;@end
//调用- (void)viewDidLoad {[super viewDidLoad];UserConfig *userConfig = [UserConfig new];SettingConfig *settingConfig = [SettingConfig new];ThemeConfig *themeConfig = [ThemeConfig new];Updater *updater = [Updater new];[updater addUpdateConfig:settingConfig];[updater addUpdateConfig:themeConfig];[updater update];Viewer *viewer = [Viewer new];[viewer addViewConfig:userConfig];[viewer addViewConfig:settingConfig];[viewer show];}
如何实践
在设计接口时,尤其是在向现有的接口添加方法时,我们需要仔细斟酌这些方法是否是处理同一类任务的:如果是则可以放在一起;如果不是则需要做拆分。
做iOS开发的朋友对UITableView的UITableViewDelegate和UITableViewDataSource这两个协议应该会非常熟悉。这两个协议里的方法都是与UITableView相关的,但iOS SDK的设计者却把这些方法放在不同的两个协议中。原因就是这两个协议所包含的方法所处理的任务是不同的两种:
UITableViewDelegate:含有的方法是UITableView的实例告知其代理一些点击事件的方法,即事件的传递,方向是从UITableView的实例到其代理。UITableViewDataSource:含有的方法是UITableView的代理传给UITableView一些必要数据供UITableView展示出来,即数据的传递,方向是从UITableView的代理到UITableView。
很显然,UITableView协议的设计者很好地实践了接口分离的原则,值得我们大家学习。
依赖倒置原则(Dependency Inversion Principle)
定义
- 依赖抽象,而不是依赖实现。
- 抽象不应该依赖细节;细节应该依赖抽象。
- 高层模块不能依赖低层模块,二者都应该依赖抽象。
依赖倒置和控制反转这个概念有点像,控制反转具体可以看一下这篇文章:控制反转(IOC)和依赖注入(DI)。
定义解读
- 针对接口编程,而不是针对实现编程。
- 尽量不要从具体的类派生,而是以继承抽象类或实现接口来实现。
- 关于高层模块与低层模块的划分可以按照决策能力的高低进行划分。业务层自然就处于上层模块,逻辑层和数据层自然就归类为底层。
也就是主要使用了面向对象四大特性里的抽象特性。
优点
通过抽象来搭建框架,建立类和类的关联,以减少类间的耦合性。而且以抽象搭建的系统要比以具体实现搭建的系统更加稳定,扩展性更高,同时也便于维护。
例子说明
比如:
- 我们喜欢吃油泼面
- 我们也喜欢吃鱼香肉丝盖饭
- 我们还喜欢吃江边城外烤全鱼
那么,这些如果写到代码里,将会是非常紧密的耦合,假如有一天我们不喜欢吃油泼面,或者无法吃到油泼面,则代码非常多的地方需要更改,因此可以进一步抽象:
- 我们喜欢吃面,我们→面←油泼面
- 我们也喜欢吃盖饭,我们→盖饭←鱼香肉丝盖饭
- 我们还喜欢吃烤鱼,我们→烤鱼←江边城外烤全鱼
还可以更进一步的抽象:
- 我们喜欢吃食物,我们→食物←面,盖饭,烤鱼
我们真正所需要的、依赖的,其实不是实际的类别与物件,而是它所拥有的功能。其实这就是依赖倒置原则DIP (Dependency Inversion Principle)
代码讲解
需求点
实现下面这样的需求:
用代码模拟一个实际项目开发的场景:前端和后端开发人员开发同一个项目。
不好的设计
首先生成两个类,分别对应前端和后端开发者:
前端开发者:
//================== FrondEndDeveloper.h ==================@interface FrondEndDeveloper : NSObject- (void)writeJavaScriptCode;@end//================== FrondEndDeveloper.m ==================@implementation FrondEndDeveloper- (void)writeJavaScriptCode{NSLog(@"Write JavaScript code");}@end
后端开发者:
//================== BackEndDeveloper.h ==================@interface BackEndDeveloper : NSObject- (void)writeJavaCode;@end//================== BackEndDeveloper.m ==================@implementation BackEndDeveloper- (void)writeJavaCode{NSLog(@"Write Java code");}@end
这两个开发者分别对外提供了自己开发的方法:writeJavaScriptCode和writeJavaCode。
接着创建一个Project类:
//================== Project.h ==================@interface Project : NSObject//构造方法,传入开发者的数组- (instancetype)initWithDevelopers:(NSArray *)developers;//开始开发- (void)startDeveloping;@end//================== Project.m ==================#import "Project.h"#import "FrondEndDeveloper.h"#import "BackEndDeveloper.h"@implementation Project{NSArray *_developers;}- (instancetype)initWithDevelopers:(NSArray *)developers{if (self = [super init]) {_developers = developers;}return self;}- (void)startDeveloping{[_developers enumerateObjectsUsingBlock:^(id _Nonnull developer, NSUInteger idx, BOOL * _Nonnull stop) {if ([developer isKindOfClass:[FrondEndDeveloper class]]) {[developer writeJavaScriptCode];}else if ([developer isKindOfClass:[BackEndDeveloper class]]){[developer writeJavaCode];}else{//no such developer}}];}@end
在Project类中,我们首先通过一个构造器方法,将开发者的数组传入project的实例对象。然后在开始开发的方法startDeveloping里面,遍历数组并判断元素类型的方式让不同类型的开发者调用和自己对应的函数。
思考一下,这样的设计有什么问题?
问题一:
假如后台的开发语言改成了GO语言,那么上述代码需要改动两个地方:
- BackEndDeveloper:需要向外提供一个
writeGolangCode方法。 - Project类的startDeveloping方法里面需要将BackEndDeveloper类的
writeJavaCode改成writeGolangCode。
问题二:
假如后期老板要求做移动端的APP(需要iOS和安卓的开发者),那么上述代码仍然需要改动两个地方:
- 还需要给Project类的构造器方法里面传入
IOSDeveloper和AndroidDeveloper两个类。而且按照现有的设计,还要分别向外部提供writeSwiftCode和writeKotlinCode。 - Project类的
startDeveloping方法里面需要再多两个elseif判断,专门判断IOSDeveloper和AndroidDeveloper这两个类。
很显然,在这两种假设的场景下,高层模块(Project)都依赖了低层模块(BackEndDeveloper)的改动,因此上述设计不符合依赖倒置原则。
那么该如何设计才可以符合依赖倒置原则呢?
答案是将开发者写代码的方法抽象出来,让Project类不再依赖所有低层的开发者类的具体实现,而是依赖抽象。而且从下至上,所有底层的开发者类也都依赖这个抽象,通过实现这个抽象来做自己的任务。
这个抽象可以用接口,也可以用抽象类的方式来做。
较好的设计
首先,创建一个接口,接口里面有一个写代码的方法writeCode:
//================== DeveloperProtocol.h ==================@protocol DeveloperProtocol <NSObject>- (void)writeCode;@end
然后,让前端程序员和后端程序员类实现这个接口(遵循这个协议)并按照自己的方式实现:
//================== 前端程序员类 ==================@interface FrondEndDeveloper : NSObject<DeveloperProtocol>@end@implementation FrondEndDeveloper- (void)writeCode{NSLog(@"Write JavaScript code");}@end//================== 后端程序员类 ==================@interface BackEndDeveloper : NSObject<DeveloperProtocol>@end@implementation BackEndDeveloper- (void)writeCode{NSLog(@"Write Java code");}@end
最后我们看一下新设计后的Project类:
//================== Project.h ==================#import "DeveloperProtocol.h"@interface Project : NSObject//只需传入遵循DeveloperProtocol的对象数组即可- (instancetype)initWithDevelopers:(NSArray <id <DeveloperProtocol>>*)developers;//开始开发- (void)startDeveloping;@end//================== Project.m ==================#import "FrondEndDeveloper.h"#import "BackEndDeveloper.h"@implementation Project{NSArray <id <DeveloperProtocol>>* _developers;}- (instancetype)initWithDevelopers:(NSArray <id <DeveloperProtocol>>*)developers{if (self = [super init]) {_developers = developers;}return self;}- (void)startDeveloping{//每次循环,直接向对象发送writeCode方法即可,不需要判断[_developers enumerateObjectsUsingBlock:^(id<DeveloperProtocol> _Nonnull developer, NSUInteger idx, BOOL * _Nonnull stop) {[developer writeCode];}];}@end
新的Project的构造方法只需传入遵循DeveloperProtocol协议的对象构成的数组即可。这样也比较符合现实中的需求:只需要会写代码就可以加入到项目中。
而新的startDeveloping方法里:每次循环,直接向当前对象发送writeCode方法即可,不需要对程序员的类型做判断。因为这个对象一定是遵循DeveloperProtocol接口的,而遵循该接口的对象一定会实现writeCode方法(就算不实现也不会引起重大错误)。
现在新的设计接受完了,我们通过上面假设的两个情况来和之前的设计做个对比:
假设1:后台的开发语言改成了GO语言
在这种情况下,只需更改BackEndDeveloper类里面对于DeveloperProtocol接口的writeCode方法的实现即可:
//================== BackEndDeveloper.m ==================@implementation BackEndDeveloper- (void)writeCode{//Old://NSLog(@"Write Java code");//New:NSLog(@"Write Golang code");}@end
而在Project里面不需要修改任何代码,因为Project类只依赖了接口方法WriteCode,没有依赖其具体的实现。
假设2:后期老板要求做移动端的APP(需要iOS和安卓的开发者)
在这个新场景下,我们只需要将新创建的两个开发者类:IOSDeveloper和AndroidDeveloper分别实现DeveloperProtocol接口的writeCode方法即可。
同样,Project的接口和实现代码都不用修改:客户端只需要在Project的构建方法的数组参数里面添加这两个新类的实例即可,不需要在startDeveloping方法里面添加类型判断,原因同上。
我们可以看到,新设计很好地在高层类(Project)与低层类(各种developer类)中间加了一层抽象,解除了二者在旧设计中的耦合,使得在低层类中的改动没有影响到高层类。
同样是抽象,新设计同样也可以用抽象类的方式:创建一个Developer的抽象类并提供一个writeCode方法,让不同的开发者类继承与它并按照自己的方式实现writeCode方法。这样一来,在Project类的构造方法就是传入已Developer类型为元素的数组了。
UML 类图对比
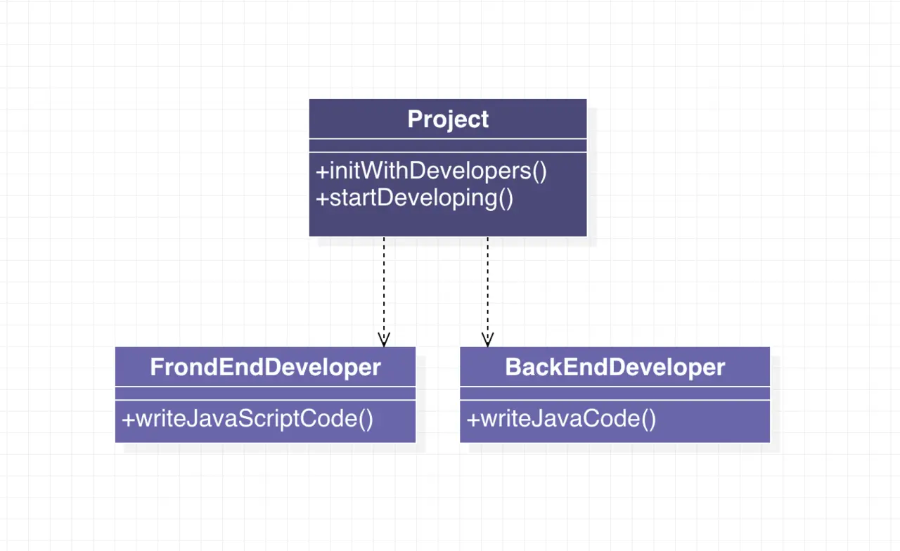
未实践依赖倒置原则:
实践了依赖倒置原则:
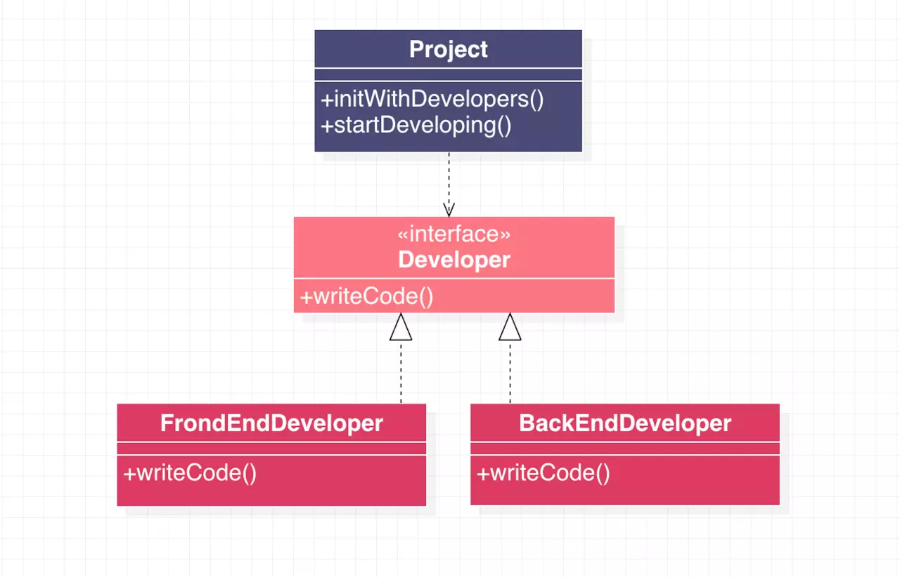
在实践了依赖倒置原则的 UML 类图中,我们可以看到
Project仅仅依赖于新的接口;而且低层的FrondEndDevelope和BackEndDevelope类按照自己的方式实现了这个接口:通过接口解除了原有的依赖。(在 UML 类图中,虚线三角箭头表示接口实线,由实现方指向接口)
如何实践
今后在处理高低层模块(类)交互的情景时,尽量将二者的依赖通过抽象的方式解除掉,实现方式可以是通过接口也可以是抽象类的方式。
迪米特法则(Law of Demeter)
定义
一个对象应该对尽可能少的对象有接触,也就是只接触那些真正需要接触的对象。
定义解读
- 迪米特法则也叫做最少知道原则(Least Know Principle), 一个类应该只和它的成员变量,方法的输入,返回参数中的类作交流,而不应该引入其他的类(间接交流)。
- 不该有直接依赖关系的类之间,不要有依赖。
- 有依赖关系的类之间,尽量只依赖必要的接口。
优点
实践迪米特法则可以良好地降低类与类之间的耦合,减少类与类之间的关联程度,让类与类之间的协作更加直接。
减少类之间的耦合,让类越独立越好。每个类都应该少了解系统的其他部分。一旦发生变化,需要了解这一变化的类就会比较少。
代码讲解
不该有直接依赖关系的类之间,不要有依赖
需求点
设计一个汽车类,包含汽车的品牌名称,引擎等成员变量。提供一个方法返回引擎的品牌名称。
不好的设计
Car类:
//================== Car.h ==================@class GasEngine;@interface Car : NSObject//构造方法- (instancetype)initWithEngine:(GasEngine *)engine;//返回私有成员变量:引擎的实例- (GasEngine *)usingEngine;@end//================== Car.m ==================#import "Car.h"#import "GasEngine.h"@implementation Car{GasEngine *_engine;}- (instancetype)initWithEngine:(GasEngine *)engine{self = [super init];if (self) {_engine = engine;}return self;}- (GasEngine *)usingEngine{return _engine;}@end
从上面可以看出,Car的构造方法需要传入一个引擎的实例对象。而且因为引擎的实例对象被赋到了Car对象的私有成员变量里面。所以Car类给外部提供了一个返回引擎对象的方法:usingEngine。
而这个引擎类GasEngine有一个品牌名称的成员变量brandName:
//================== GasEngine.h ==================@interface GasEngine : NSObject@property (nonatomic, copy) NSString *brandName;@end
这样一来,客户端就可以拿到引擎的品牌名称了:
//================== Client.m ==================#import "GasEngine.h"#import "Car.h"- (NSString *)findCarEngineBrandName:(Car *)car{GasEngine *engine = [car usingEngine];NSString *engineBrandName = engine.brandName;//获取到了引擎的品牌名称return engineBrandName;}
上面的设计完成了需求,但是却违反了迪米特法则。原因是在客户端的findCarEngineBrandName:中引入了和入参(Car)和返回值(NSString)无关的GasEngine对象。增加了客户端与GasEngine的耦合。而这个耦合显然是不必要更是可以避免的。
较好的设计
同样是Car这个类,我们去掉原有的返回引擎对象的方法,而是增加一个直接返回引擎品牌名称的方法:
//================== Car.h ==================@class GasEngine;@interface Car : NSObject//构造方法- (instancetype)initWithEngine:(GasEngine *)engine;//直接返回引擎品牌名称- (NSString *)usingEngineBrandName;@end//================== Car.m ==================#import "Car.h"#import "GasEngine.h"@implementation Car{GasEngine *_engine;}- (instancetype)initWithEngine:(GasEngine *)engine{self = [super init];if (self) {_engine = engine;}return self;}- (NSString *)usingEngineBrandName{return _engine.brand;}@end
因为直接usingEngineBrandName直接返回了引擎的品牌名称,所以在客户端里面就可以直接拿到这个值,而不需要间接地通过原来的GasEngine实例来获取。
我们看一下客户端操作的变化:
//================== Client.m ==================#import "Car.h"- (NSString *)findCarEngineBrandName:(Car *)car{NSString *engineBrandName = [car usingEngineBrandName]; //直接获取到了引擎的品牌名称return engineBrandName;}
与之前的设计不同,在客户端里面,没有引入GasEngine类,而是直接通过Car实例获取到了需要的数据。
这样设计的好处是,如果这辆车的引擎换成了电动引擎(原来的GasEngine类换成了ElectricEngine类),客户端代码可以不做任何修改!因为它没有引入任何引擎类,而是直接获取了引擎的品牌名称。
所以在这种情况下我们只需要修改Car类的usingEngineBrandName方法实现,将新引擎的品牌名称返回即可。
UML 类图对比
未实践迪米特法则:
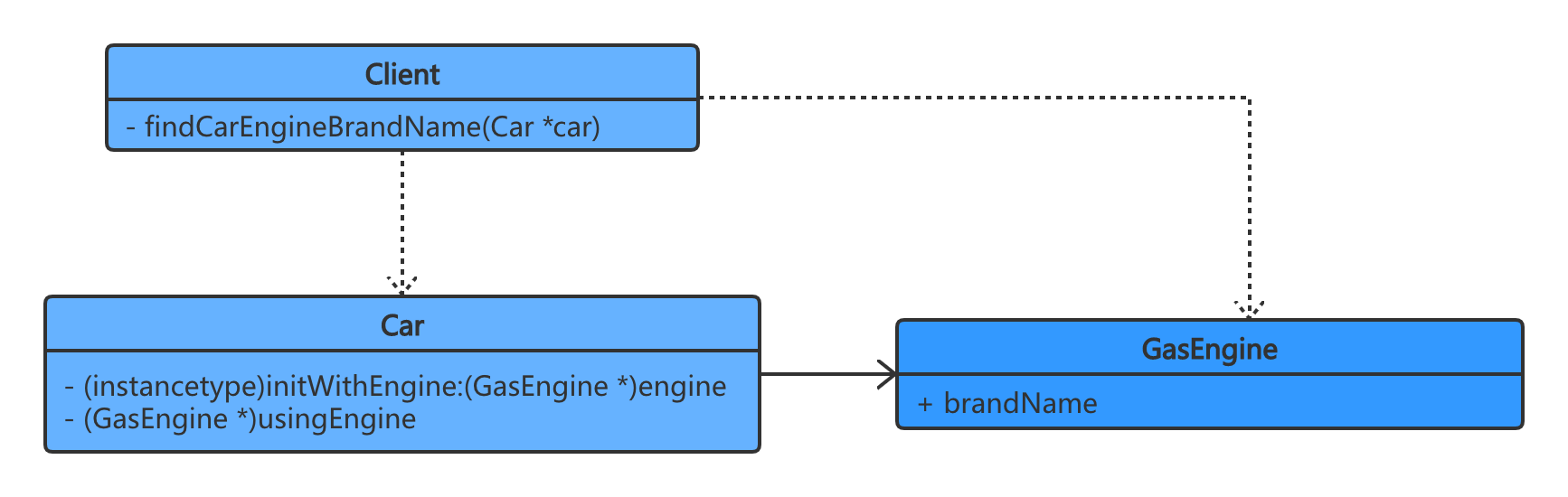
实践了迪米特法则:
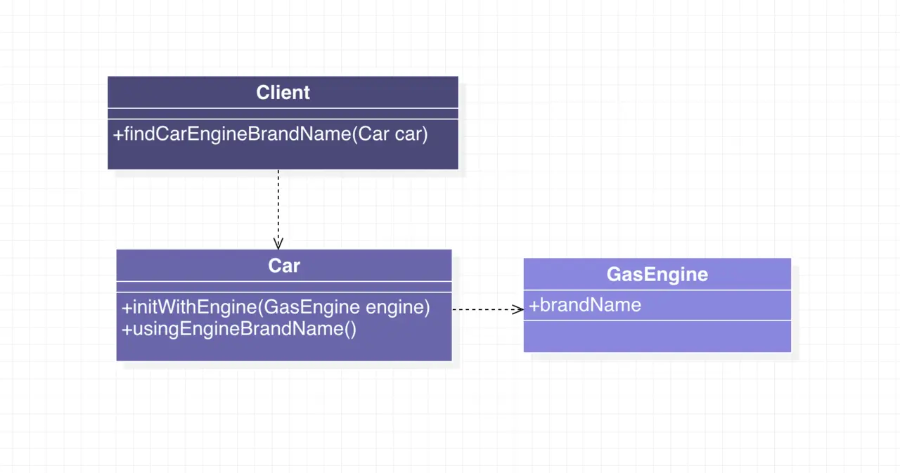
很明显,在实践了迪米特法则的 UML 类图里面,没有了Client对GasEngine的依赖,耦合性降低。
代码讲解二
有依赖关系的类之间,尽量只依赖必要的接口。
需求点
Serialization 类负责对象的序列化和反序列化。
不好的设计
public class Serialization {public String serialize(Object object) {String serializedResult = ...;//...return serializedResult;}public Object deserialize(String str) {Object deserializedResult = ...;//...return deserializedResult;}}
单看这个类的设计,没有一点问题。不过,如果我们把它放到一定的应用场景里,那就还有继续优化的空间。假设在我们的项目中,有些类只用到了序列化操作,而另一些类只用到反序列化操作。那基于迪米特法则后半部分“有依赖关系的类之间,尽量只依赖必要的接口”,只用到序列化操作的那部分类不应该依赖反序列化接口。同理,只用到反序列化操作的那部分类不应该依赖序列化接口。
public class Serializer {public String serialize(Object object) {String serializedResult = ...;...return serializedResult;}}public class Deserializer {public Object deserialize(String str) {Object deserializedResult = ...;...return deserializedResult;}}
上面拆分之后的代码更能满足迪米特法则,但却违背了高内聚的设计思想。高内聚要求相近的功能要放到同一个类中,这样可以方便功能修改的时候,修改的 地方不至于过于分散。
较好的设计
public interface Serializable {String serialize(Object object);}public interface Deserializable {Object deserialize(String text);}
public class Serialization implements Serializable, Deserializable {@Overridepublic String serialize(Object object) {String serializedResult = ...;...return serializedResult;}@Overridepublic Object deserialize(String str) {Object deserializedResult = ...;...return deserializedResult;}}
public class DemoClass_1 {private Serializable serializer;public Demo(Serializable serializer) {this.serializer = serializer;}//...}public class DemoClass_2 {private Deserializable deserializer;public Demo(Deserializable deserializer) {this.deserializer = deserializer;}//...}
上面我们通过抽象接口的方式来实现迪米特法则。尽管我们还是要往DemoClass_1的构造函数中,传入包含序列化和反序列化的Serialization实现类,但是,我们依赖的Serializable接口只包含序列化操作,DemoClass_1 无法使用 Serialization类中的反序列化接口,对反序列化操作无感知,这也就符合了迪米特法则后半部分所说的“依赖有限接口”的要求。
如何实践
今后在做对象与对象之间交互的设计时,应该极力避免引出中间对象的情况(需要导入其他对象的类):需要什么对象直接返回即可,降低类之间的耦合度。
