@yulongsun
2018-05-30T17:34:50.000000Z
字数 4834
阅读 2485
死磕Zookeeper系列-4-ZooKeeper与Paxos
zookeeper
#1、什么是Zookeeper?
1.1 简介
ZK是一个分布式的程序协调服务。
ZK包含一个简单的原语操作集合.可以基于ZK实现数据发布/订阅、负载均衡、命名服务、分布式协调/通知、集群管理、Master选举、分布式锁、分布式队列等特性。
1.2 ZK的分布式一致性特性
- 1、顺序一致性.
包含:全局有序和因果有序。
- 全局有序:如果一台Server上消息A在消息B之前发布,那么在所有Server上消息A都在消息B之前。
- 因果有序:对于顺序提交的消息B、A,如果消息B依赖于消息A,那么A将在B之前被执行。
- 2、原子性.
集群中的所有Server,要么都更新成功,要么都更新失败,没有中间状态。 - 3、单一视图性.
client不论连接到哪一个Server,展示给它的都是同一个视图。 - 4、可靠性.
如果消息M被一台Server接受,那么消息将被所有Server接受。 - 5、实时性.
ZK仅保证在一定时间段内,Client能从Server获取到最新的数据状态.
1.3 数据模型
在ZK中,节点分为两类
|-1、第一类是:构成集群的机器--【机器节点】。
|-2、第二类是:数据模型中的数据单元--【数据节点ZNode】。
|-ZNode又分:持久节点(PERSISTENT)和临时节点(EPHEMERAL)
|- 持久节点:指一旦ZNode被创建,除非主动移除,否在一直保存。
|- 临时节点:指临时节点的生命周期和[Client的会话]绑定,一旦[Client的会话]失效,那么[所有临时节点]都会被移除。
特殊:
|- 顺序节点(SEQUENTIAL):该节点创建时,会自动在子节点上加一个由父节点维护的、自增的后缀(上线:Integer.MAX_VALUE)。
节点详解
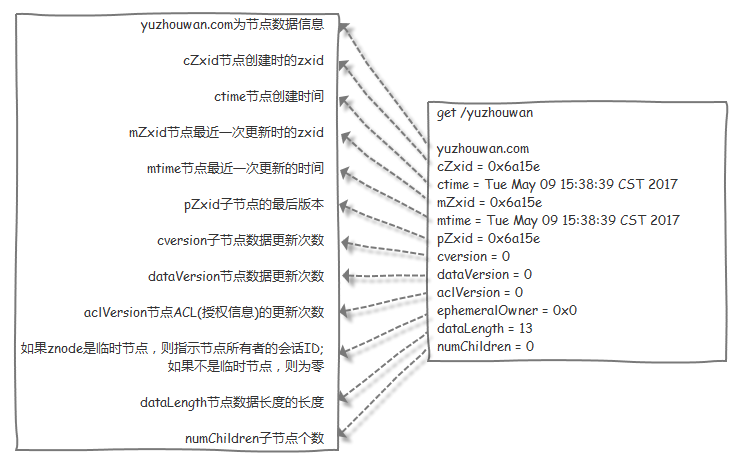
版本Version
ZK的每个ZNode上都会维护一个Stat的数据结构,记录节点更新次数,Stat中记录了3个Version:
- 1、dataVersion
- 2、cVersion
- 3、aclVersion
作用:这个
版本起到了控制ZK操作原子性的作用。
1.4 设计目的
- 1、简单的数据模型
- 2、可以构建集群
- 3、顺序访问
- 4、高性能
1.5 ZooKeeper内部结构
TODO
#2、ZK集群服务
2.1 核心思想
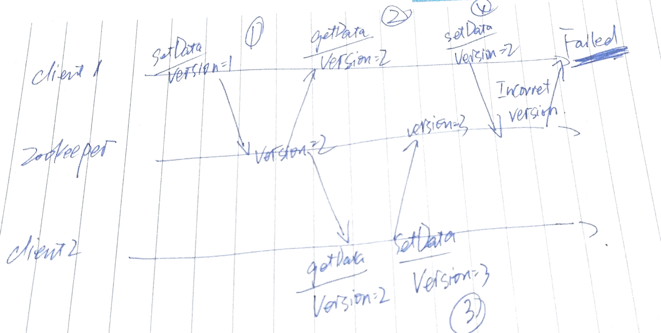
- 核心思想就是:提供一个[非锁机制]的Wait Free的用于分布式系统同步的核心服务。
- 乐观锁:系统核心对文件读写并不提供[加锁互斥]服务。But,提供[基于版本对比]的更新操作,客户端可以基于此逻辑实现加锁操作。实现逻辑如下:
2.2 运行模式
1、独立模式standalone mode--只有一台ZK服务器。适合测试,但不保证高可用性和恢复性。
2、集群模式replicated mode
2.3 读写机制
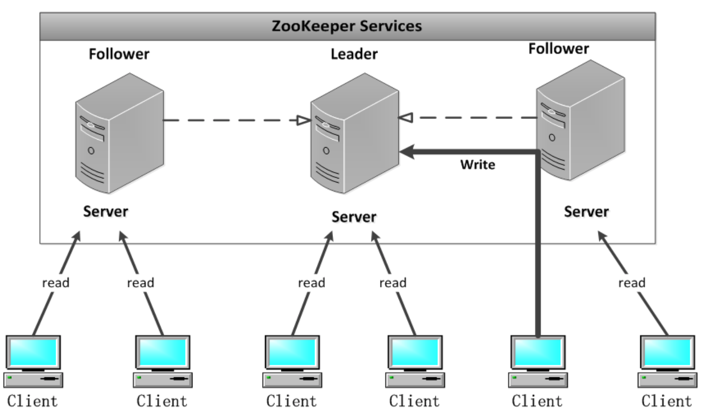
ZooKeeper通过以下两条基本保证来实现数据的一致性:
1、全局串行化所有写操作。
2、保证同一Client的指令被FIFO执行。读写请求
- 对于读请求,由所请求的Server响应。
- 对于写请求,都转发给Leader处理。
2.3 性能
TODO
#3、Zab协议详解
Zookeeper并没有采用Paxos算法,而是采用了基于2PC改造的Zab协议,作为数据一致性的核心算法。
ZooKeeper的核心是原子广播机制。-->这个机制保证了各个Server之间的同步。
3.1 术语
- 1、Zab中节点的三种状态
- following: 当前阶段是跟随者,服从Leader节点的命令;
- leading : 当前节点是Leader,负责协调事务;
- election/looking:节点处于选举状态;
- 2、quorum
集群中超过半数的节点集合。 - 3、epoch(重点)
可以理解为当前集群所处的周期。-- 就想每个皇帝都有自己的年号一样。 - 4、ZXID
- 低32位为counter
- 高32位为epoch
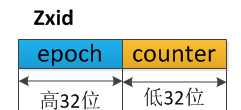
每当Leader发生变化的时候,counter=0,epoch+1。
3.2 Zab模式
崩溃恢复[选主]和消息广播[同步]
崩溃恢复
- 什么时候启动?--当服务启动或者Leader崩溃之后,Zab就进入了崩溃恢复模式。
- 什么时候退出?--当Leader被选举出来,且超过半数Server完成和Leader的同步之后,恢复模式结束。
消息广播
- 正常Zab协议工作时会一直处于广播模式。
- 一旦Leader和半数Follower完成同步完成之后,就开始进行消息广播,即进入消息广播模式。
- 这个时候,如果有Server加入集群,那么这个Server就会先进入崩溃恢复模式,进行状态同步,待状态同步完成之后,也参与消息广播。
- ZooKeeper一直维持Broadcast,直到Leader崩溃或者Leader失去半数Follower。
3.3 深入理解Zab协议
3.3.1、四个阶段
Phase 0、Leader Election 选举阶段
节点处于选举阶段。只有达到#Phase3阶段时,准Leader才会成为真正的Leader。
这一阶段的主要目的是选出准Leader,然后进入下一阶段。准Leader节点的保准是:得到超过半数节点的票数。
Phase 1、Discovery 发现阶段
这一阶段的主要目的是:发现大多数节点接收的最新提案,并且准Leader生成新的epoch,让Follower接受,更新它们的acceptEpoch。
Phase 2、Synchronization 同步阶段
这个阶段的主要任务是:利用Leader前一阶段获取的最新提案历史,同步集群中的所有副本。
只有当Quorum都同步完成,准Leader才会成为真正的Leader。Follower只会接受zxid比自己的lastZxid大的提案。
Phase 3、Broadcast 广播阶段
到这个阶段,ZK集群才向外提供事务服务,并且Leader可以进行消息广播。如果有新节点加入,需要对新节点进行同步。
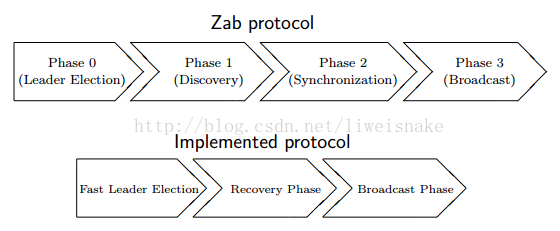
3.3.2、Zab协议实现
基于Java实现的Zab跟上面的定义有些不同,选举阶段使用的是 Fast Leader Election(FLE),它包含了 Phase 1 的发现职责。因为 FLE 会选举拥有最新提议历史的节点作为 Leader,这样就省去了发现最新提议的步骤。实际的实现将 Phase 1 和 Phase 2 合并为 Recovery Phase(恢复阶段)。所以,ZAB 的实现只有三个阶段:
1、Fast Leader ELection
2、Recovery Phase
3、Broadcast Phase
Zab协议需要处理的两件事:
1、已经处理过的Proposal不能被丢弃;
2、已经丢弃的Proposal不能被重复提交;
3.4 Zab协议和Paxos的区别
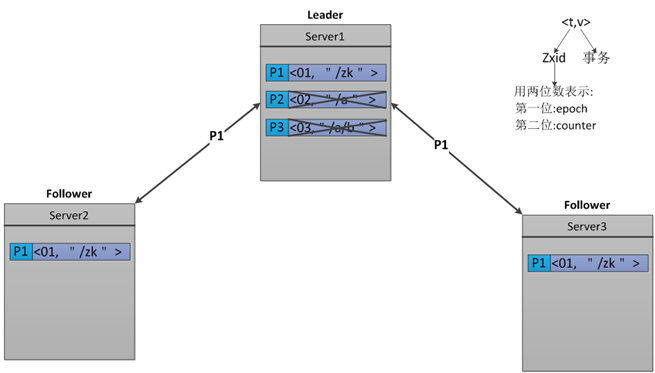
用示例解释
Paxos
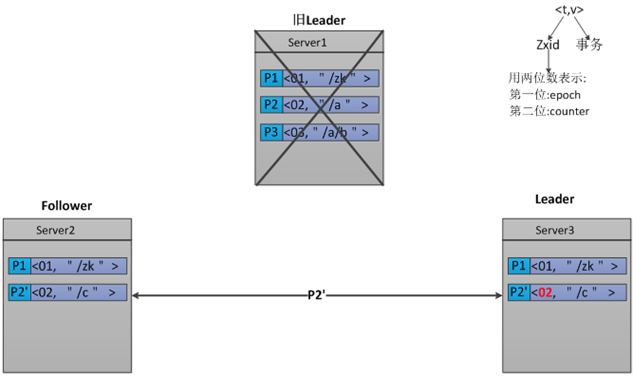
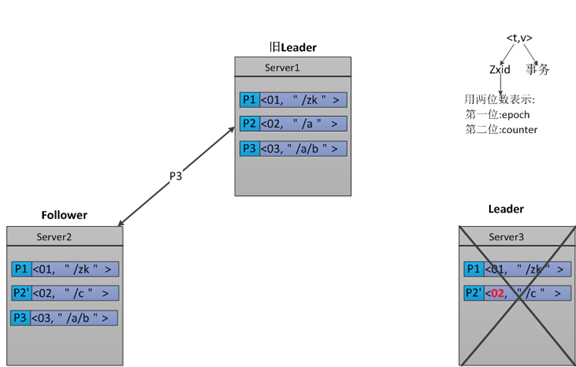
Zab
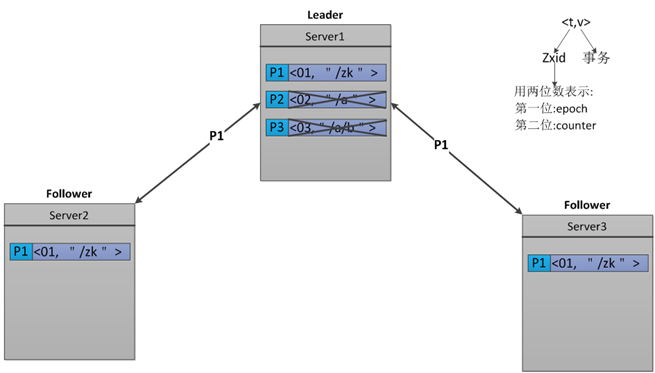
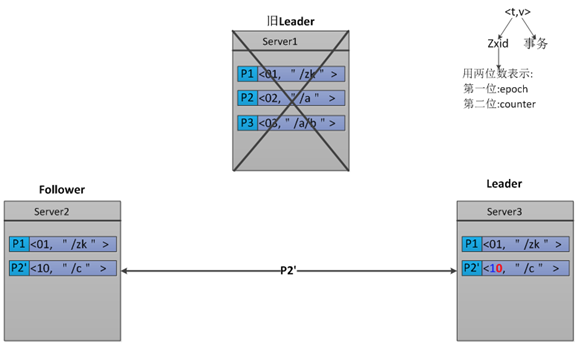
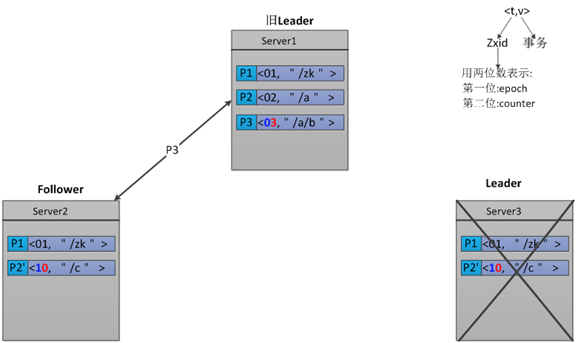
3.5 Paxos的瓶颈
ZooKeeper的主要功能是维护一个高可用且一致的数据库,数据库内容复制在多个节点上,总共2f+1个节点中只要不超过f个失效,系统就可用。实现这一点的核心是ZAB,一种Atomic Broadcast协议。所谓Atomic Broadcast协议,形象的说就是能够保证发给各复本的消息顺序相同。
由于Paxos的名气太大,所以我看ZAB的时候首先就想为什么要搞个 ZAB,ZAB相比Paxos有什么优点?这里首要一点是Paxos的一致性不能达到ZooKeeper的要求。举个例子。
假设一开始Paxos系统中的 leader是P1,他发起了两个事务<t1, v1>(表示序号为t1的事务要写的值是v1)和<t2, v2>的过程中挂了。新来个leader是P2,他发起了事务<t1, v1'>。而后又来个新leader是P3,他汇总了一下,得出最终的执行序列<t1, v1'>和<t2, v2>,即P2的t1在前,P1的t2在后。注意:在这我们可以看出,对于序号为t1的事务,Leader2将Leader1的覆盖了这样的序列为什么不能满足ZooKeeper的需求呢?ZooKeeper是一个树形结构,很多操作都要先检查才能确定能不能执行,比如P1的事务t1可能是创建节点“/a”,t2可能是创建节点“/a/aa”,只有先创建了父节点“/a”,才能创建子节点“/a/aa”。而P2所发起的事务t1可能变成了创建“/b”。这样P3汇总后的序列是先创建“/b”再创建“/a/aa”,由于“/a”还 没建,创建“a/aa”就搞不定了。
#4、工作原理
4.1 选主流程
当Leader崩溃或者Leader失去大多数的follower,这时候zk进入恢复模式,恢复模式需要重新选举出一个新的Leader,让所有的Server都恢复到一个正确的状态。Zk的选举算法有两种:一种是基于basic paxos实现的,另外一种是基于fast paxos算法实现的。系统默认的选举算法为fast paxos。
basic paxos
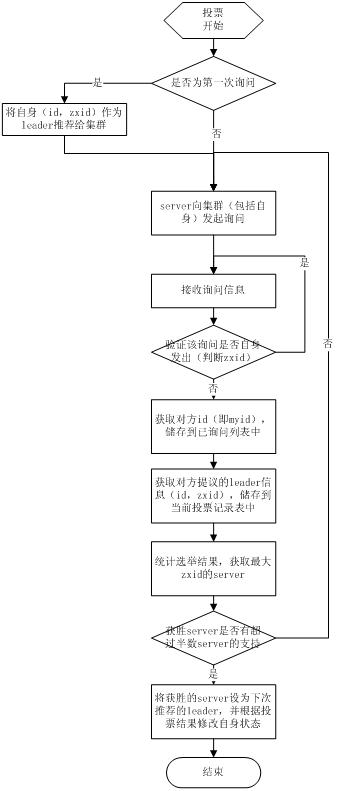
fast paxos
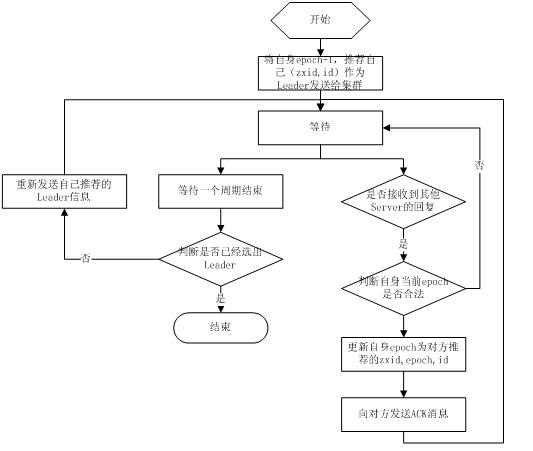
4.2 同步流程

#5、工作流程
5.1 Leader工作流程
Leader处理写请求
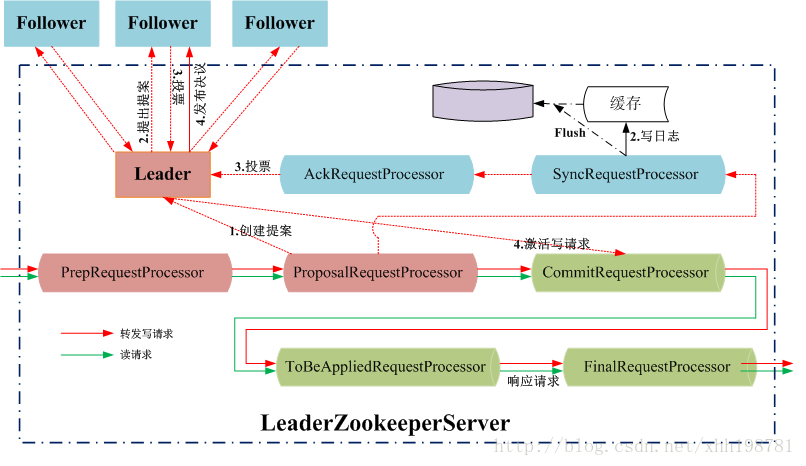
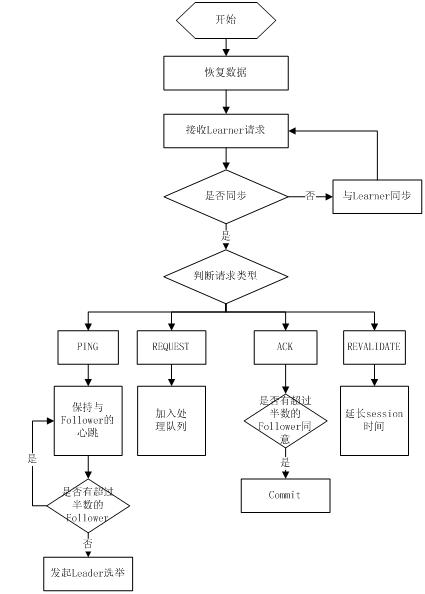
Leader的主要2个功能
1、恢复数据.
2、维持和Learner的心跳,接受Learner请求并处理不同请求。
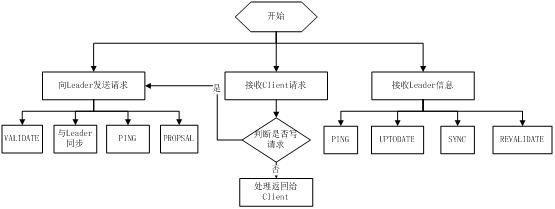
5.2 Follower工作流程
Follower处理读请求
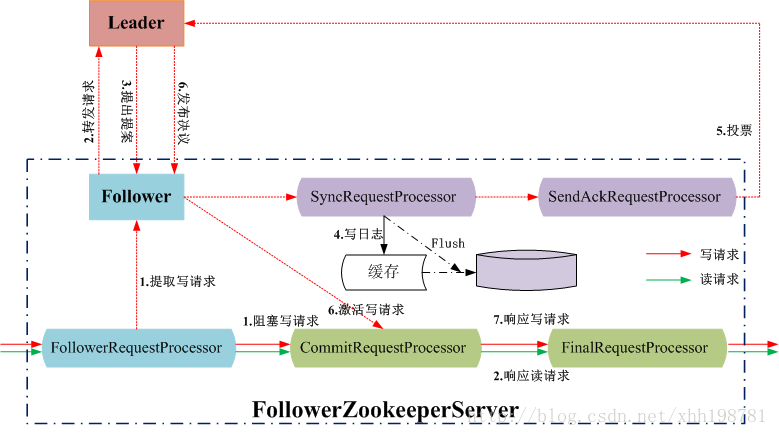
Follower的4个主要功能
1、向Leader发送消息(PING消息、REQUEST消息、ACK消息、REVAILDTE消息)
2、接受Leader消息并进行处理。
3、接受Client请求,如果是写请求,转发给Leader进行投票。
4、返回Client结果。
#6、典型应用场景
TODO 另起文章
#7、面试题&FAQ
Q1、如何使用ZK进行选举?画图说明
Q2、用ZooKeeper作任务分配如何实现?
Q3、什么是脑裂?如何解决脑裂?并说明NameNode和RescoureManager如何避免脑裂?
Q4、如何实现分布式数据存储的一致性?
Q5、讲一下一致性Hash。哪些地方使用了一致性Hash
Q6、一致性Hash与Paxos的区别?
Q7、讲一下2PC、以及2PC在什么情况下会出现数据不一致?
Q8、Zab协议如何避免阻塞?
Q9、2PC会在什么时候发生阻塞?
Q10、叙述Zab集群同步过程
Q11、ZK在重新选举Leader的时候,还可以继续执行事务请求吗?
Q12、ZK可以进行横向扩展吗?可以通过增加机器增加集群的性能吗?
Q13、主从架构下,Leader崩溃,数据一致性怎么保证?
Q14、选举Leader的时候,整个集群无法处理写请求,如何快速进行Leader选举?
Q15、Paxos与Zab协议有什么区别?为什么要搞Zab?Zab相比Paxos相比有什么优点?
Q16、ZK集群数量选择?
A13:Leader 崩溃之后,集群会选出新的 Leader,然后就会进入恢复阶段,新的 Leader 具有所有已经提交的提议,因此它会保证让 followers 同步已提交的提议,丢弃未提交的提议(以 Leader 的记录为准),这就保证了整个集群的数据一致性。
A14:这是通过 Fast Leader Election 实现的,Leader 的选举只需要超过半数的节点投票即可,这样不需要等待所有节点的选票,能够尽早选出 Leader。
A16:生产环境中最好部署奇数个(3\5\7...),偶数个是不可以的。
也就是说:2个ZK,1个挂掉了,那么整个ZK集群就不可用了,因为剩下1个没有超过总数2个的一半,剩下的1个ZK也不可用了,所以2个ZK的容忍度是0。
同理:3个ZK挂掉1个,还剩2个,超过总数3个的一半,整个集群可用,所以3个ZK的容忍度是1。
所以:3—>1, 4—>1, 5—>2, 6—>2 ===>2n和2n-1的容忍度是一样的,所以没必要再增那一台不需要的。
#8、参考
1、Zookeeper 原理与优化 推荐指数:★★★★ //苏宁
2、《从Paxos到ZooKeeper》
3、Zab协议
4、ZooKeeper学习第七期--ZooKeeper一致性原理 推荐指数:★★★★★
5、Zookeeper ZAB 协议分析//蚂蚁
6、zookeeper原理(转)
7、ZooKeeper 选主流程
