@EVA001
2018-07-13T16:38:49.000000Z
字数 10171
阅读 1909
复杂网络的基本概念和参数
复杂网络的定义
复杂网络是从拓扑学的角度对自然界大量复杂系统进行描述的一种很好的方式 [5,6,21] 。
从统计物理学的角度来看,网络是一个包含了大量个体以及个体之间相互作用的系统,
是把某种现象或某类关系抽象为个体(顶点)以及个体之间相互作用(边)而形成的用
来描述这一现象或关系的图。人们很早就思考过网络结构的问题,但受到当时的科学
发展和技术的影响,一直以为网络的结构是规则的或随机的,直到1998年和1999年小
世界网络模型和无尺度网络的提出 [3,4] ,人们才又重新思考网络结构问题,而人类计算
能力的提高、科技的发展也为人们研究这一问题提供了有力的支持。
钱学森 [22] 曾给出了复杂网络的一个较严格的定义:具有自组织、自相似、吸引子、
小世界、无标度(无尺度)中部分或全部性质的网络称为复杂网络。而周涛则认为复杂
网络大致包含以下几层含义:首先,它是大量真实复杂系统的拓扑抽象;其次,它至少
在感觉上比规则网络和随机网络复杂,因为我们可以很容易地生成规则网络;但就目
前而言,还没有一种能够生成完全符合真实网络统计特征的简单方法;最后,由于复
杂网络是大量复杂系统得以存在的拓扑基础,因此对它的研究被认为有助于理解“复
杂系统之所以复杂”这一至关重要的问题 [23] 。
在图论里,复杂网络被表示为由一个点集v(G)和一个边集E(G)组成的一个图。E(G)
中的每条边e有v(G)中的一对点(u,v)与之对应。网络的节点数即个体数为N(v),个体
之间的相互作用数即边数记为L(E)。这样,网络可以用几何图形表示,许多大网络、大
系统问题,经过用图模拟,使研究变得概念清晰、形象直观、目标明确和计算简化。
在数学上,复杂网络则用邻接矩阵表示,矩阵的行、列号表示网络中的节点,而
矩阵元表示节点之间的相互联系。例如,对于一个包含有N个节点的复杂网络来说,其
邻接矩阵是N阶方阵,其矩阵元a ij 表示网络中点i与点j的连接关系:如果点i与点j相连,
则相应矩阵元a ij 为1,否则为0。通过将网络表示为矩阵,人们可以方便地运用代数的
技巧解决复杂网络的问题,有利于在计算机上进行模拟和运算。在一定程度上我们可
以说,一个邻接矩阵(Adjacency Matrix)包含了一个网络拓扑结构的所有信息。
复杂网络的基本参数
近年来,人们在刻画复杂网络结构的统计特性上提出了许多概念和方法,其中有
三个基本概念分别是:平均路经长度、聚集系数和度分布。
平均路经长度(characteristic path length)
网络中两个节点i和j之间的距离d ij 定义为连接这两个节点的最短路径上的边数。
网络的特征路径长度L被定义为网络中每一对点之间的最短距离的平均值:

其中N为网络节点数。
聚类系数(clustering coefficient)
在很多真实网络的拓扑结构中,存在下述的情况,即如果顶点A与顶点B相连,并
且顶点B与顶点C相连,那么顶点A也极有可能与顶点C相连。以社会网络为例,你的两
个朋友也很可能也是朋友。这一现象在物理学界被称为网络的聚类性。刻画网络的聚
类性通常采用图论中的聚类系数(clustering coefficient)这一特征量来刻画。它是一个
用来刻画网络局域性质的量,用字母C表示。对于网络中的某一个点i来说,其聚类系
数C i 表示与i相连接的点中任意两点之间互相连接的概率。C i 的定义如下 [21] :若与i相
连接的点的数目为K i ,则在这K i 个点之间最多存在E m = K i (K i −1)/2条边。若其中实
际存在的边的数目为E i ,则i点的聚类系数C i 被定义为E i 与E m 的比值:

网络的聚类系数C则被定义为网络中所有节点的聚类系数的平均值:

3.度分布(degree distribution)
度(degree)是单个节点的属性中简单而又重要的概念。节点i的度K i 被定义为与该
节点连接的其他节点的数目。有向网络中的一个节点的度分为出度(out-degree)和入
度(in-degree)。网络中所有节点的度的平均值称为网络的节点平均度,用hki表示。网
络中节点的度的分布情况可用分布函数p(k)来描述。它表示网络中任意选出一个节点
其度值为k的概率。基于这一定义,我们知道,规则网络的度分布为Delat分布,随机网
络的度分布近似为Poisson分布 3 。然而,近年来大量实验结果表明 [5,6,21] ,许多真实网
络的度分布明显不同于Poisson分布。特别地,许多网络的度分布可用幂率形式:
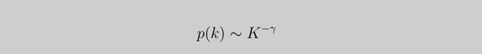
来更好地描述。幂律型分布也称无标度分布,具有幂率型度分布的网络称为无标度网络。
§2.3 数据场理论与拓扑势
§2.3.1 数据场
场的概念最早是由英国物理学家发拉底提出来的。如果空间Ω中的每个点都对应
某个物理量或者数学函数的一个确定值,则称在Ω上确定了该物理量或数学函数的一
个场 [24] 。借鉴了物理学中场的思想,我们将物质粒子间的相互作用及其场描述方法引
入抽象的数域空间。将每一个对象都看作空间中具有一定质量的质点,在其周围存在
一个作用场位于场中的每一个对象都将受到其他对象的影响,那么这个空间就构成了
一个数据场。描述场的属性的物理量通常是一个以空间位置(坐标)为自变量的矢量函
数或标量函数,物理学中分别称之为矢量场和标量场,如温度场、密度场,这些是标量
场;而电场、磁场则属于向量场。在基础物理学中,稳定有源场被称为有势场或者保
守场。其中势的物理含义是:把一个单位质点,如引力场中的单位质量、静电场中的
单位正电荷,从场中的某一点A移动到参考点时场力所做的功。势函数通常被看作是
质点位置的函数,而与质点的存在与否无关。根据物理学中稳定有源场的势函数性质,
即稳定有源场的势函数是一个关于场点空间位置的单值函数,具有各向同性,空间任
一点的势值大小与代表场源强度的参数成正比,与该点到场源的距离呈递减关系,可
以给出数据场势函数形态的基本规则 [25,26] 如下:
给定空间Ω中的数据对象x,和任意一个y∈Ω,即对象x在点y处产生的势值Φ x (y),
则Φ x (y)应同时满足:
(1)Φ x (y)是定义在空间Ω上的连续、光滑、有限函数;
(2)Φ x (y)各向同性;
(3)Φ x (y)是距离||x – y||的单值递减函数。当||x − y||=0时,Φ x (y)达到最大值,
但不是无穷大;当→∞时,Φ x (y)→0。
§2.3.2 拓扑势
在描述数据场的属性时,人们引入了势函数.节点拓扑势的概念就是数据场理论提
出的 [27] 。由于势函数是位置或距离的函数,故而可以叠加 [28] 。在描述数据场的属性时,人
们引入了势函数.节点拓扑势的概念就是数据场理论提出的 [27] 。由于势函数是位置或
距离的函数,故而可以叠加 [28] 。拓扑势刻画了在不同拓扑位置上节点产生的局域影响
作用,能细分复杂网络中节点的重要性排序;建立了度和介数等衡量参数之外的重要
指标,能合理有效地分析静态网络的一些特性。所以,节点拓扑势的大小描述了网络
拓扑中的某个节点受自身和近邻节点共同影响所具有的势值。典型的节点重要性度量
有节点度、介数和中心接近度等。那些网络中度较大的节点、介数较大的节点、靠近
网络中心的节点在网络中的地位都比较重要,重要节点之间的边也就比较重要。因此,
用节点的拓扑势来衡量节点的重要性,并且对网络节点进行分层能更为精细、真实地反
映节点在整个网络中的的重要性、发现网络中的重要节点和敏感连接,使网络的分层
更为准确。
在网络拓扑结构中,通常采用拓扑距离来计算节点通过网络拓扑传递所产生的势。
假设用G(N,V)来表示网络拓扑结构,节点i处拓扑势φ(i)为:

在式中,m j 代表节点j的质量,通常可映射为实际网络中的某些属性,如节点数据流
量或者节点度等;d j−→ i 代表节点j到节点i的最短路径长度;σ为影响因子,即节点影响
的范围,通常可根据网络中节点的势熵对其进行优选。当σ=0时,φ(j→i)→0,所以
φ(i)=m i = M,势熵趋近于H max =lg N 。当σ→∞时,φ(j→i)→m j ,即任意两个节点间
的影响完全相同φ(i)=NM,经Z归一化后,势熵再次趋近H max =lg N 。因此,可知随影
响因子的单调递增,势熵H的变化曲线在两端达到极大值,中间将存在一个极小值,此
时节点的势分布最不均匀,不确定性最小,如下图所示。
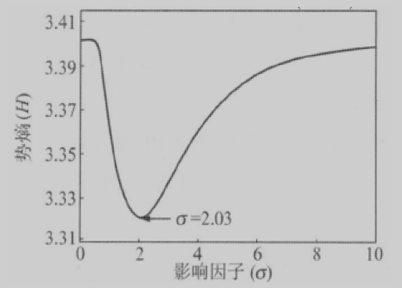
图 2.7 影响因子优选示意图
§2.4 本章小结
本章首先介绍了有关复杂网络研究的发展历程、复杂网络的定义和几种评价复杂
网络的基本参数,然后介绍了数据场的相关理论,并描述了节点拓扑势的定义、计算
和优化方法。
复杂网络现象在现实世界中非常普遍,许多表面上没有丝毫联系的系统,经过抽
象,建立相应的网络模型之后,都表现出许多相似之处,比如都具有较高的聚集系数
和较短的网络平均距离。这些系统既包括自然系统也包括人造系统。无论是自然系统
还是人造系统,一般来说,某个系统现在所表现出来的拓扑结构是以系统某种功能为
目标进化而来的,而不是根据系统的目标解析函数的极值构建的,因此目前的系统性
能并不是系统能够达到的最优值。而目前的研究,无论是在建模还是在拓扑可视化方
面,都是百家争鸣。所有研究都试图找到与现实复杂网络更贴近的模型。所以本文认
为,(1)需要从复杂网络拓扑的结构特征出发建立复杂网络模型,以期得到一个尽可能
全面描述复杂网络的拓扑结构。(2)通过网络化数据挖掘方法发现复杂网络节点之间所
蕴含的关系对节点进行分类和可视化布局是研究复杂网络的一个重要方向。
2.1.1
力导引布局算法
(1) FR 算法
T. M. Fruchterman 等在弹力模型的基础上提出了 FR 算法,该算法将节点看作
物理系统中的原子,通过引入原子间的斥力和引力的概念建立力导引模型。布局的
原则是有边相连的节点应当位置上相近,但要保持一定的距离,没有边相连的节点
应当尽可能的远离。为了达到上述布局效果,引力只存在于有边相连的节点之间,
斥力存在于所有的节点之间。引力和斥力的计算公式如下:

其中,d 为节点之间的距离,k 为相连节点之间的理想距离。理想距离 k 的计算公式如下:

FR 算法在 P. Eades 提出的弹力模型的基础上加入了模拟退火原则,温度从初始值一直降为 0
,温度控制着节点的移动幅度。随着温度的降低,布局趋向于稳定, 节点的移动范围也随之变小。
FR 算法的实现很简单,每次迭代包括三步:计算相邻节点之间的引力,计算所有节点之间的斥力,
根据温度控制节点的运动幅度。在计算引力的过程中,只计算相邻节点之间的引力,时间复杂度为
O(|E|)。在计算斥力的过程中,需要计算每对节点之间的斥力,时间复杂度为 O(|V|2)。
由于计算斥力的时间复杂度较高,Fruchterman 和 Reingold 提出了一种利用网格改进的斥力计算方法。
该方法忽略较远节点之间的斥力,因此大大降低了斥力的计算复杂度,对于分布均匀的网络图,
斥力的计算时间复杂度为 O(|V|)。
(2) KK 算法
T. Kamada 等在弹力模型的基础上提出了能量模型 KK 算法。不同于 P. Eades提出的弹力模型
以及 Fruchterman 和 Reingold 提出的 FR 算法,KK 算法对每条边的长度赋予了实际意义,
并认为两点间的理想几何距离应当是两点间的图论距离。在KK 算法的能量模型中,
理想几何距离由节点对的最短距离计算得出。假设 lij是节点 vi和节点 vj间的理想距离,具体定义如下:

其中,dij是节点 vi和节点 vj的最短距离,L 是布局所展示范围内的边长最佳距离。L的具体定义如下:

其中,L0是布局画布的长度。KK 算法给出了布局总能量公式,总能量值越小,布局效果越好,其公式定义如下:
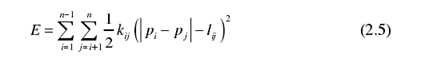
其中,pi表示点 i 的坐标,kij是弹力系数。P. Eades 提出的弹力模型并没有遵循胡克定律,
T. Kamada 等在 KK 算法中引入了胡克定律,弹力系数 kij具体公式如下:

式中,K 是常数。KK 算法的目标是求得总能量的最小值,从而得到所对应的布局作为最终布局效果。
由于要计算每对节点间的最短距离,计算时间花费较大,同时需要存储节点对间的距离,空间花费也较大。
虽然时间花费和空间花费都较高,但是 KK 算法给出了有关好的布局简单且直观的定义,
即节点间的几何距离应当对应于节点间的图论距离。
2 社区布局算法
(1) FADE 算法
A. Quigley 和 P. Eades 在 Barnes-Hut 所提出的层次空间分解方法的基础上提出
了 FADE 算法,该算法相比于原有的力导引布局算法,时间复杂度降到了O(|E|+|V|log|V|)。
FADE 算法中用分解树的方法计算节点间的亲密程度从而避免计算所有节点对之间的距离,
同时利用空间分解构造几何聚类,结合力导引算法实现网络聚类。
FADE 算法包括以下步骤:首先,根据节点的最新位置信息,利用空间分解构
造出一个空间集合聚类;然后,计算相邻节点的引力和所有节点间的斥力,更新节
点新的位置信息。重复以上步骤,直到算法收敛。
(2) Linlog 算法
现有的布局算法中,大部分算法都无法展示网络中的聚类特征。从 FR 弹力模
型开始,多数布局模型趋向于统一边长,以使节点分布均匀且度数较高的节点分布
在可视化区域的中心位置,然而这种分布具有很大的局限性,不便于展示网络聚类
信息。针对这一问题,A. Noack 提出了一种新的用于展示网络聚类特征的力模型,
该模型的能量函数定义如下:

Linlog 模型能够很好地展示网络聚类特性,但是算法时间复杂度达到了 O(|V|3),
因此该方法不能够很好地应用于大规模的网络数据。
图的可视化问题是数学和计算机科学的结合,包括几何图论和信息可视化相
关的学科内容,被广泛应用在网络分析、制图学、生物信息学、天体物理学等领
域。图的可视化问题可以追溯到 13 世纪,逻辑学家 Ramon Llull 为了研究分析各
种哲学定义之间的关系时,绘制了大量的完全图5 上个世纪 80 年代,
科学计算领域蓬勃发展,大量存在关联的数据随之产生,人们为了从宏观的角度
了解数据的含义和彼此之间的关联,提出了以图进行展示的可视化思想。
之后,人们对复杂网络分析的需求对可视化技术提出了更高要求,
图可视化技术也进入高速发展的阶段6。
本节将首先对图可视化问题的基本概念进行介绍,然后将介绍国际上普遍认
可的布局美学标准,最后再介绍三类常见的图可视化方法。
1.2.1 图可视化问题基本概念
1.2.1.1图
在数学上,一个图(Graph)是表示节点与节点之间关系的方法,是图论的基
本研究对象。一个图看起来是由一些顶点和连接这些顶点的边组成。图 G
是可由二元组(V,E)表示,其中V是边集,是 E 节点集。图有多种变体,包括简单图、
多重图、无向图、有向图等。
1.2.1.2图布局
图G的一种布局方法 是将G的每个顶点vV 映射到平面上的一个点
P(v) ,并将 G的每条边 (u,v) 映射到平面上两个端点分别为 P(u), P(v)
的简单Jordan 曲线。若G的每条边都被映射成一条直线段,我们称布局方法
是一个直线画法;若G的每条边都被映射成一条折线,我们称
是一个折线画法;若G的每条边都被映射成一条平行、垂直线段链,称画法
是一个正交画法;若G的任两条边的映像都不相交,称画法
是一个平面画法6。
本文中,我们主要研究无向图的直线画法,这样,布局算法的目的就是将图
画到某个有限区域中,在保证一定美学标准规则的前提下,对图中的每个顶点
v指定一对坐标(x, y),然后将有边相连的顶点之间画一条直线段即可。
1.2.2 图布局的美学评价标
对于一般的图布局方法,根据不同的应用和观点,会有不同的美学标准,绘
图美学标准的鼻祖
Sugiyama
在文献
7
中定义了
5
项美学标注,以改进网络图的
易读性,包括:
(1)边交叉数最小原则。为了能够清晰展示图的网络结构,进行绘制时应尽量避免边的交叉。
(2)邻接点空间位置靠近原则。为了减小边的长度,应尽量将具有相同连接边的节点布局在相邻的位置上。
(3)直线边原则。网络中的边必须使用直线边,不允许出现曲线边。
(4)边平衡布局原则。具有相同节点的多条边尽量以该节点为中心进行平
衡布局。
(5)节点层次布局原则。引入层的概念,通过把节点布局在水平或竖直的
后来,Sugiyama等又给出了规律性和可塑性的定义8
(6)区域最小化原则。绘制网络图应使图的最小外包矩形尽量小,以节省屏幕空间。
(7)高度节点居中原则。高度节点应尽量布局在图的中心位置。
(8)节点密度均匀原则。尽量保证单位区域的布局节点数量相同。
(9)凸多边形原则。尽量保证相接边构成的多边形为凸多边形。
2.2 大规模图数据的化简
图化简的目的是优化布局结果,提高图的可读性。对于大规模图数据的布局,
一个好的化简方法更是尤为重要,本节介绍了两类化简方法。多层级化简方法主
要目的是优化算法的布局结果,使之更符合公认的美学标准。视觉聚集化简方法
提高了图的可读性和交互性能。
2.2.1 多层级化简
在经典的力导引算法中,算法需要不断迭代获取整个系统能量的最小值,实
际上,这个最小值只是一个局部最优解。如果节点的初始布局是随机的,那么我
们需要从初始的高能状态出发进行搜索,直至找到一个能量最小值。当需要布局
的节点数量很大时,算法最终求得的最优解与整个系统的最优解相去甚远,直接
导致了低质量可视化结果产生。为此,如果我们能找到一个系统总能量较小的状
态作为算法的初始布局输入,最终得到的布局结果将会令人满意。
为了实现这一目标,分层多级化简的思想被引入到经典的力导引算法中去。
多层级技术就是根据一定的标准将原始图分成多个层次,忽略高抽象层级的细节,
保留粗糙的,只有大体结构的图。在此基础上不断添加细节,直到将原图恢复完
毕。这类思想已经被成功应用在图划分(Graph Partition)[20][21],矩阵排序
(Matrix ordering)[22],旅行商问题[23]等。
分层布局的思想共分为两个阶段:
粗化阶段:对原图0G进行若干次粗化,直到满足预先设定的条件,最终生成一个大小递减的化简图序列
0 1, ,...,,...,k cG G G G。其中, ... ...1 0Vc Vk V V ,Gk1由Gk化简得到。
需要注意的是粗化图必须保留原图的基本特征,换而言之,化简后的图一定要和原图“相像”,
这样对其布局才能接近最优解。
细化阶段:细化是粗化的逆过程,首先采用经典的力导引算法对最粗化图Gc进行布局,因为
Gc中包含的节点数量最少,一个较优的布局结果{ }cx 可以很容易得到。然后图Gc被不断细化,在布局结果
{ }cx 的基础上不断扩展,直到得到图 G0的布局结果图。
基于边塌陷(EC, edge collapsing)[21][24]和极大独立子集(MIVS, maximal independent vertex set)
的两种图化简方法是对图进行粗化的有效方法。现介绍如下。
2.2.1.1 边塌陷
边塌陷算法是 Hoppe 于 1993 年首先提出的[25],它是一种适用于网络模型化简的方法。
对于一幅连通图,每次化简时,算法选定一条边 e 的两个顶点u,v ,将其中的一个顶点 u
“折叠”至 v,然后节点 u,v 和边 e 合成一个新的顶点。图 2.1 是一个折叠过程的示意图。
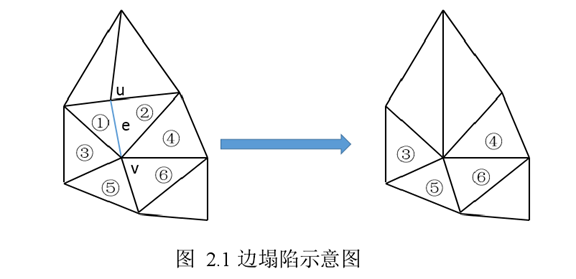
上述过程中,算法折叠了边 e,节点 u,v 和边 e 在折叠之后合成了一个新的节点,三角形①②从图中消失,图中原来以
u,v 为顶点的多边形全部改为以新产生的节点为顶点。边塌陷算法的优势在于它可以生成连续的细节层次,化简后的图的结构与之
前相近,同时具有良好的扩展性。应用较为广泛的边塌陷算法通过随机生成匹配边集进行化简。
2.2.1.2 极大独立集化简
设集合 I 是无向图 G 的一个顶点子集,对于集合 I 中的任意两个节点在 G中都不相邻,则我们称集合
I 是 G 的一个独立集。如果 I 中加入一个非 I 集合的顶点后,I 集合不再是独立集,则称集合 I 为极大独立集。
化简时,对于图 G 的极大独立点集 I,如果 I 中的任意两节点 u,v 之间的图距离不超过 3,则将 u,v
相连。
图 2.2 是利用极大独立集对图进行化简的过程。图中点集{v1,v4,v6}为原图的极大独立点集,连接 v1v3
, v1v6, v4v6 即得到化简图。
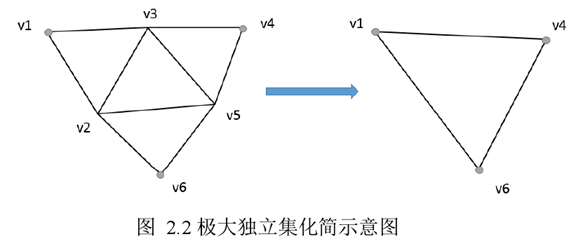
当图中节点的平均度数较高时,使用边塌陷方法对图进行化简效果不明显,
利用极大独立集对图进行化简可以有效地降低化简图中的节点数量,缩小图的规
模。
2.2.2 视觉聚集化简
如上文所述,节点聚集覆盖和边大量交叉是大图可视化中最需要解决的问题
之一。一个好的布局应该尽可能减少图中的视觉聚集现象。实际中,对于大图的
视觉聚集优化是比较困难的,目前应用较为广泛的化简方法有边位移、顶点聚类
和抽样三种。
2.2.2.1 边位移
通过图的曲线画法或者折线画法可以使边的交叉数量降低,这类边位移方法
是削弱边的视觉聚集现象最重要的方法之一。对于节点位置已经预定义好的图来
说(如地图布局),布局算法不能够移动节点,对边的描画就格外重要。Dwayer
等人使用压力限制方法对力导引布局算法进行优化,他们对节点的
移动和边的拐点位置进行了限定,最小化边交叉数,以减少节点和边的重叠以及
边与边的交叉[26]。然而,求解最少边交叉数量是一个 NP 完全问题,对于大规模
图的布局优化需要花费大量时间,优化代价太高。即便找到了该问题的最优解,
我们依然无法杜绝边的交叉,从提高美观性的角度上来讲,意义不大。
合流布局[27]是另一类边位移方法,该方法同样能够削弱因边大量交叉造成
的视觉混乱,这类方法将边描画成平滑的曲线,使相交的边合成一条路径,让交
叉的区域看起来更加自然。合流布局的缺点是观察者容易迷失在拐点众多的复杂
的布局网中。图 2.3 展示了合流布局结果图[27]。
边聚类算法是合流布局算法的改进,该方法的改进思想是:将有连接关系的
任意两个节点区分开来表示,而非将所有交叉边融合成一条边。边聚类算法旨在
缩小边覆盖的区域,而非减少交叉点数目。捆绑在一起的边能够释放出更多的布
局空间,视觉聚集现象明显得到缓解[28]
。
图 2.4 中展示了某个软件系统中的各个关联模块之间的调用关系布局图[28]
。
2.4(a)为气球布局结果,2.4(b)为气球布局+边聚类布局。显然,图
2.4(b)更清晰地揭示了各层次结构之间的调用关系,用户通过聚类的边的宽度能够直观地感受到
不同模块之间联系的强弱。
2.2.2.2 节点聚类
节点聚类问题出现在很多研究领域中,在图的可视化问题中,节点聚类的目
的是将整个图划分成若干子图,然后将这些子图画成单个节点或者较小的区域。
把相关的视觉元素合并可以释放出大量的可视化空间,降低视觉聚集复杂度。此
外,聚类图有利于用户对全图整体结构的感知和理解。
多种多样的聚类技术已经被应用于布局算法中,各聚类算法之间彼此最大的
区别在于不同数据集元素之间的距离或相似度的定义互不相同。节点相似度的衡
量方法分为基于内容和基于结构两类。
基于内容的方法通常根据图数据的语义相关程度进行聚类,这种方法可以产
生非常有意义的聚类结果。但是这种方法与图的具体语义内容密切相关,针对特
定问题的聚类方法并不具有普遍适用性,因此科研人员对这类方法的研究非常少。
相比于基于内容的聚类方法,基于结构的聚类方法的应用要广泛许多。结构
聚类通常指聚类内部的节点之间的联通性要远远大于内外部节点之间的连通性,
包括聚簇大小、集合相似度、统计差异性等思想也被应用于结构聚类算法中[29][30]。
基于结构的聚类方法可以分成三种,分别是图论法、贪心法、迭代法。图论法利
用相似矩阵来计算单个节点之间的相似性,相似度相近的节点被聚类为一簇[31]。
贪心方法中,选择某些较为重要的节点(如度较高)作为簇的核心节点,然后一
个一个加入满足条件的节点,直到聚簇的规模足够大,以此生成聚类。迭代法通
过对之前迭代产生的簇进行聚类,将小的子图合成更大的聚类子图,直到全部节
点合成一个最大簇。整个迭代过程会使图形成一个比较有层次的结构,如图 2.5所示[32]。
节点聚类算法的时间复杂度通常较高,找到图的最优节点聚类是 NP 完全问题。
Kernighan 和 Lin 在 1970 年提出了经典的层次聚类算法,对于节点数为n,
边数 m 的图来说,KL 算法的时间复杂度为2O(m n)[33]。近年来,数据规模的不
断增长推动了快速聚类算法发展和完善。Newman 提出的适于发掘网络社区结构
的聚类算法时间复杂度仅为O((mn)n)[34]。 一个好的聚类布局算法应该满足以下标准:
聚类均匀:在聚类结果的每个层次中,簇的大小应一致,每个簇中的节
点数目应分配均匀。
低聚类层级:递归分解过程中产生的层级数应尽可能少。
比例和谐:聚类子图的横纵比应接近 1。
高效:计算聚类和布局时间不应过长。
对称性:布局展示结果的对称性应被保证。
2.2.2.3 抽样
抽样是一种降低布局结果视觉聚集程度的新方法。Krishnamurthy[35]等人指
出,随机抽掉原图中节点,将图尽行压缩,若删除的节点数目不超过总数的 30%
,图的大部分性质仍然会得以保留。Rafiei 和 Curial 在文献[36]研究了多种抽样策略,
证实了大多数情况下,大图的拓扑性质不会发生变化。他们还提出了“焦点”
的概念以优化抽样结果的准确度。
抽样作为一个新生方法依然存在不足之处。它具有不可预测性,不同的抽样
结果亦会使用户产生不同的直观感受。因此,如何定义一个较为完善的抽样策略
对于研究人员来说仍是一个不小的挑战。Cui 提出的直方图差分法和最邻近法是
用来衡量数据抽样质量的有效方法[37]
1:
