@EVA001
2017-12-02T12:44:39.000000Z
字数 17591
阅读 536
Spark学习笔记(一)
未分类
基本概括
概述
spark快速
- 扩充了mapreduce
- 基于内存计算(中间结果的存储位置)
spark通用
- 批处理hadoop
- 迭代计算 机器学习系统
- 交互式查询 hive
- 流处理 storm
spark开放
- Python API
- Java/Scala API
- SQL API
- 整合好hadoop/kafka
主要内容
- 环境搭建
- 核心概念RDD
- 架构
- 重要组件SparkStreaming
发展历史
2009 RAD实验室,引入内存存储
2010 开源
2011 AMP实验室,Spark Streaming
2013 Apache顶级项目
主要组件
Spark Core:
- 包括spark的基本功能,任务调度、内存管理、容错机制
- 内部定义RDDs(弹性分布式数据集)
- 提供APIs来创建和操作RDDs
- 为其他组件提供底层服务
Spark SQL:
- 处理结构化数据的库,类似于HiveSQL、Mysql
- 用于报表统计等
Spark Streaming:
- 实时数据流处理组件,类似Storm
- 提供API来操作实时数据流
- 使用场景是从Kafka等消息队列中接收数据实时统计
Spark Mlib:
- 包含通用机器学习功能的包,Machine Learning Lib
- 包含分类、聚类、回归、模型评估、数据导入等
- Mlib所有算法均支持集群的横向扩展(区别于python的单机)
GraphX:
- 处理图数据的库,并行的进行图的计算
- 类似其他组件,都继承了RDD API
- 提供各种图操作和常用的图算法,PageRank等
Spark Cluster Managers:
- 集群管理,Spark自带一个集群管理调度器
- 其他类似的有Hadoop YARN,Apache Mesos
紧密集成的优点:
- Spark底层优化后,基于底层的组件也会相应优化
- 减少组件集成的部署测试
- 增加新组建时其他组件可以方便使用其功能
hadoop应用场景
- 离线处理、对时效性要求不高、要落到硬盘上
spark应用场景
- 时效性要求高、机器学习、迭代计算
Doug Cutting的观点:
生态系统、各司其职
Spark需要借助HDFS进行持久化存储
运行环境搭建
基础环境:
- Spark - scala - JVM - Java7+
- Python - Python2.6+/3.4+
- Spark1.6.2 - Scala2.10/Spark2.0.0 - Scala2.11
- 搭建Spark不需要Hadoop,如果存在则需要下载相关版本(不是上述对应关系)
具体步骤:
详见http://dblab.xmu.edu.cn/blog/spark-quick-start-guide/
主要是两个步骤:
1. 安装Hadoop(不做介绍)
2. 解压Spark到对应位置,然后在spark-env.sh中添加SPARK_DIST_CLASSPATH
3. run-example SparkPi已可以正常运行示例
注意几点:
- Spark版本要严格对照Hadoop版本
- Spark运行不依赖Hadoop启动
- Spark运行目录bin的内容,要确保有执行权限[+x]
Spark目录:
- bin 包含和Spark交互的可执行文件,如Spark shell
- core,Streaming,python等 包含主要组件的源代码
- examples 包含一些单机的Spark job
Spark shell:
- Spark的shell能够处理分布在集群上的数据
- Spark把数据加载到节点的内存中,故分布式处理可以秒级完成
- 快速迭代计算,实时查询,分析等都可以在shell中完成
- 有Scala shell和Python shell
Scala shell:/bin/scala-shell
注意:
- 启动日志级别可以修改为WARN,在目录/conf/log4j.properties
- 开启Spark-shell要先启动hadoop,否则会出一下错误
[hadoop@hadoop01 bin]$ ./spark-shellSLF4J: Class path contains multiple SLF4J bindings.SLF4J: Found binding in [jar:file:/usr/local/spark/jars/slf4j-log4j12-1.7.16.jar!/org/slf4j/impl/StaticLoggerBinder.class]SLF4J: Found binding in [jar:file:/usr/local/hadoop/share/hadoop/common/lib/slf4j-log4j12-1.7.10.jar!/org/slf4j/impl/StaticLoggerBinder.class]SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory]Setting default log level to "WARN".To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).17/06/30 12:17:21 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable17/06/30 12:17:49 WARN metastore.ObjectStore: Version information not found in metastore. hive.metastore.schema.verification is not enabled so recording the schema version 1.2.017/06/30 12:17:49 WARN metastore.ObjectStore: Failed to get database default, returning NoSuchObjectExceptionjava.lang.IllegalArgumentException: Error while instantiating 'org.apache.spark.sql.hive.HiveSessionStateBuilder':at org.apache.spark.sql.SparkSession$.org$apache$spark$sql$SparkSession$$instantiateSessionState(SparkSession.scala:1053)at org.apache.spark.sql.SparkSession$$anonfun$sessionState$2.apply(SparkSession.scala:130)at org.apache.spark.sql.SparkSession$$anonfun$sessionState$2.apply(SparkSession.scala:130)at scala.Option.getOrElse(Option.scala:121)at org.apache.spark.sql.SparkSession.sessionState$lzycompute(SparkSession.scala:129)at org.apache.spark.sql.SparkSession.sessionState(SparkSession.scala:126)at org.apache.spark.sql.SparkSession$Builder$$anonfun$getOrCreate$5.apply(SparkSession.scala:938)at org.apache.spark.sql.SparkSession$Builder$$anonfun$getOrCreate$5.apply(SparkSession.scala:938)at scala.collection.mutable.HashMap$$anonfun$foreach$1.apply(HashMap.scala:99)at scala.collection.mutable.HashMap$$anonfun$foreach$1.apply(HashMap.scala:99)at scala.collection.mutable.HashTable$class.foreachEntry(HashTable.scala:230)at scala.collection.mutable.HashMap.foreachEntry(HashMap.scala:40)at scala.collection.mutable.HashMap.foreach(HashMap.scala:99)at org.apache.spark.sql.SparkSession$Builder.getOrCreate(SparkSession.scala:938)at org.apache.spark.repl.Main$.createSparkSession(Main.scala:97)... 47 elidedCaused by: org.apache.spark.sql.AnalysisException: java.lang.RuntimeException: java.net.ConnectException: Call From hadoop01/192.168.146.130 to hadoop01:9000 failed on connection exception: java.net.ConnectException: 拒绝连接; For more details see: http://wiki.apache.org/hadoop/ConnectionRefused;at org.apache.spark.sql.hive.HiveExternalCatalog.withClient(HiveExternalCatalog.scala:106)at org.apache.spark.sql.hive.HiveExternalCatalog.databaseExists(HiveExternalCatalog.scala:193)at org.apache.spark.sql.internal.SharedState.externalCatalog$lzycompute(SharedState.scala:105)at org.apache.spark.sql.internal.SharedState.externalCatalog(SharedState.scala:93)at org.apache.spark.sql.hive.HiveSessionStateBuilder.externalCatalog(HiveSessionStateBuilder.scala:39)at org.apache.spark.sql.hive.HiveSessionStateBuilder.catalog$lzycompute(HiveSessionStateBuilder.scala:54)at org.apache.spark.sql.hive.HiveSessionStateBuilder.catalog(HiveSessionStateBuilder.scala:52)at org.apache.spark.sql.hive.HiveSessionStateBuilder.catalog(HiveSessionStateBuilder.scala:35)at org.apache.spark.sql.internal.BaseSessionStateBuilder.build(BaseSessionStateBuilder.scala:289)at org.apache.spark.sql.SparkSession$.org$apache$spark$sql$SparkSession$$instantiateSessionState(SparkSession.scala:1050)... 61 moreCaused by: java.lang.RuntimeException: java.net.ConnectException: Call From hadoop01/192.168.146.130 to hadoop01:9000 failed on connection exception: java.net.ConnectException: 拒绝连接; For more details see: http://wiki.apache.org/hadoop/ConnectionRefusedat org.apache.hadoop.hive.ql.session.SessionState.start(SessionState.java:522)at org.apache.spark.sql.hive.client.HiveClientImpl.<init>(HiveClientImpl.scala:191)at sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method)at sun.reflect.NativeConstructorAccessorImpl.newInstance(NativeConstructorAccessorImpl.java:62)at sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45)at java.lang.reflect.Constructor.newInstance(Constructor.java:423)at org.apache.spark.sql.hive.client.IsolatedClientLoader.createClient(IsolatedClientLoader.scala:264)at org.apache.spark.sql.hive.HiveUtils$.newClientForMetadata(HiveUtils.scala:362)at org.apache.spark.sql.hive.HiveUtils$.newClientForMetadata(HiveUtils.scala:266)at org.apache.spark.sql.hive.HiveExternalCatalog.client$lzycompute(HiveExternalCatalog.scala:66)at org.apache.spark.sql.hive.HiveExternalCatalog.client(HiveExternalCatalog.scala:65)at org.apache.spark.sql.hive.HiveExternalCatalog$$anonfun$databaseExists$1.apply$mcZ$sp(HiveExternalCatalog.scala:194)at org.apache.spark.sql.hive.HiveExternalCatalog$$anonfun$databaseExists$1.apply(HiveExternalCatalog.scala:194)at org.apache.spark.sql.hive.HiveExternalCatalog$$anonfun$databaseExists$1.apply(HiveExternalCatalog.scala:194)at org.apache.spark.sql.hive.HiveExternalCatalog.withClient(HiveExternalCatalog.scala:97)... 70 moreCaused by: java.net.ConnectException: Call From hadoop01/192.168.146.130 to hadoop01:9000 failed on connection exception: java.net.ConnectException: 拒绝连接; For more details see: http://wiki.apache.org/hadoop/ConnectionRefusedat sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method)at sun.reflect.NativeConstructorAccessorImpl.newInstance(NativeConstructorAccessorImpl.java:62)at sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45)at java.lang.reflect.Constructor.newInstance(Constructor.java:423)at org.apache.hadoop.net.NetUtils.wrapWithMessage(NetUtils.java:792)at org.apache.hadoop.net.NetUtils.wrapException(NetUtils.java:732)at org.apache.hadoop.ipc.Client.call(Client.java:1479)at org.apache.hadoop.ipc.Client.call(Client.java:1412)at org.apache.hadoop.ipc.ProtobufRpcEngine$Invoker.invoke(ProtobufRpcEngine.java:229)at com.sun.proxy.$Proxy22.getFileInfo(Unknown Source)at org.apache.hadoop.hdfs.protocolPB.ClientNamenodeProtocolTranslatorPB.getFileInfo(ClientNamenodeProtocolTranslatorPB.java:771)at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)at java.lang.reflect.Method.invoke(Method.java:498)at org.apache.hadoop.io.retry.RetryInvocationHandler.invokeMethod(RetryInvocationHandler.java:191)at org.apache.hadoop.io.retry.RetryInvocationHandler.invoke(RetryInvocationHandler.java:102)at com.sun.proxy.$Proxy23.getFileInfo(Unknown Source)at org.apache.hadoop.hdfs.DFSClient.getFileInfo(DFSClient.java:2108)at org.apache.hadoop.hdfs.DistributedFileSystem$22.doCall(DistributedFileSystem.java:1305)at org.apache.hadoop.hdfs.DistributedFileSystem$22.doCall(DistributedFileSystem.java:1301)at org.apache.hadoop.fs.FileSystemLinkResolver.resolve(FileSystemLinkResolver.java:81)at org.apache.hadoop.hdfs.DistributedFileSystem.getFileStatus(DistributedFileSystem.java:1317)at org.apache.hadoop.fs.FileSystem.exists(FileSystem.java:1426)at org.apache.hadoop.hive.ql.session.SessionState.createRootHDFSDir(SessionState.java:596)at org.apache.hadoop.hive.ql.session.SessionState.createSessionDirs(SessionState.java:554)at org.apache.hadoop.hive.ql.session.SessionState.start(SessionState.java:508)... 84 moreCaused by: java.net.ConnectException: 拒绝连接at sun.nio.ch.SocketChannelImpl.checkConnect(Native Method)at sun.nio.ch.SocketChannelImpl.finishConnect(SocketChannelImpl.java:717)at org.apache.hadoop.net.SocketIOWithTimeout.connect(SocketIOWithTimeout.java:206)at org.apache.hadoop.net.NetUtils.connect(NetUtils.java:531)at org.apache.hadoop.net.NetUtils.connect(NetUtils.java:495)at org.apache.hadoop.ipc.Client$Connection.setupConnection(Client.java:614)at org.apache.hadoop.ipc.Client$Connection.setupIOstreams(Client.java:712)at org.apache.hadoop.ipc.Client$Connection.access$2900(Client.java:375)at org.apache.hadoop.ipc.Client.getConnection(Client.java:1528)at org.apache.hadoop.ipc.Client.call(Client.java:1451)... 104 more<console>:14: error: not found: value sparkimport spark.implicits._^<console>:14: error: not found: value sparkimport spark.sql^Welcome to____ __/ __/__ ___ _____/ /___\ \/ _ \/ _ `/ __/ '_//___/ .__/\_,_/_/ /_/\_\ version 2.2.0/_/Using Scala version 2.11.8 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_112)Type in expressions to have them evaluated.Type :help for more information.scala>scala> val lines = sc.textFile("/home/hadoop/look.sh")<console>:17: error: not found: value scval lines = sc.textFile("/home/hadoop/look.sh")^
- 注意Spark-shell中的textFile(path),参数path默认为hdfs://,要使用file://显式声明
scala> val lines = sc.textFile("/home/hadoop/look.sh")lines: org.apache.spark.rdd.RDD[String] = /home/hadoop/look.sh MapPartitionsRDD[1] at textFile at <console>:24scala> lines.count()org.apache.hadoop.mapred.InvalidInputException: Input path does not exist: hdfs://hadoop01:9000/home/hadoop/look.shat org.apache.hadoop.mapred.FileInputFormat.singleThreadedListStatus(FileInputFormat.java:287)at org.apache.hadoop.mapred.FileInputFormat.listStatus(FileInputFormat.java:229)at org.apache.hadoop.mapred.FileInputFormat.getSplits(FileInputFormat.java:315)at org.apache.spark.rdd.HadoopRDD.getPartitions(HadoopRDD.scala:194)at org.apache.spark.rdd.RDD$$anonfun$partitions$2.apply(RDD.scala:252)at org.apache.spark.rdd.RDD$$anonfun$partitions$2.apply(RDD.scala:250)at scala.Option.getOrElse(Option.scala:121)at org.apache.spark.rdd.RDD.partitions(RDD.scala:250)at org.apache.spark.rdd.MapPartitionsRDD.getPartitions(MapPartitionsRDD.scala:35)at org.apache.spark.rdd.RDD$$anonfun$partitions$2.apply(RDD.scala:252)at org.apache.spark.rdd.RDD$$anonfun$partitions$2.apply(RDD.scala:250)at scala.Option.getOrElse(Option.scala:121)at org.apache.spark.rdd.RDD.partitions(RDD.scala:250)at org.apache.spark.SparkContext.runJob(SparkContext.scala:2087)at org.apache.spark.rdd.RDD.count(RDD.scala:1158)... 48 elidedscala> val lines = sc.textFile("file:///home/hadoop/look.sh")lines: org.apache.spark.rdd.RDD[String] = file:///home/hadoop/look.sh MapPartitionsRDD[3] at textFile at <console>:24scala> lines.count()res1: Long = 26scala> lines.first()res2: String = #!/bin/bash
开发环境搭建
安装Scala环境
注意:
- Scala环境本身的安装跟Spark无关,Scala本身就是一门类似Java的语言
- 可以在非集群内的主机安装该开发环境,然后通过ssh提交集群运行即可
(Spark版本2.x.x - Scala版本2.11.x以上,在IDEA中新建项目时会在首选项中进行选择)
第一个Scala程序:WordCount
注意:
类似于Hadoop,如果开发环境不在集群内,例如在自己PC中的IDEA进行开发(使用虚拟机同理),那么就会产生两种运行方式,一是本地运行,二是提交集群运行。
本质上两种方式都是先打包,再上传(本地或集群)。即流程是一致的,但是在PC中引入的spark-core的作用是不同的,提交集群运行时,PC中的spark-core内容只是作为语法检查,类方法调用等辅助作用;但是本地运行时,除了上述功能外,其还充当了计算部分,即可以使PC成为一个类似节点的且有计算能力的存在。
全部步骤:
PC上安装Scala环境,IDEA,IDEA安装Scala插件
1.本地运行
- 新建Scala的Project,注意要选对应的scala版本
- 然后在build.sbt中添加spark-core的依赖,可以去MavenRepositories网站去查,找到sbt(ivy)的依赖格式就行了
- 然后新建一个scala class,选择object,书写代码,要使用本地模式
- 最后直接点击运行即可。
import org.apache.spark.{SparkConf, SparkContext}import org.apache.spark.rdd.RDDobject WordCount extends App {// 读取本地文件val path = "C:\\Users\\msi\\Desktop\\xiaomi2.txt"// 本地调试val conf = new SparkConf().setAppName("SparkDemo").setMaster("local")val sc = new SparkContext(conf)val lines = sc.textFile(path)val words = lines.flatMap(_.split(" ")).filter(word => word != " ")val pairs = words.map(word => (word, 1))val wordscount: RDD[(String, Int)] = pairs.reduceByKey(_ + _)wordscount.collect.foreach(println)}
打印结果:
注意下述的IP地址和file路径,确实是在本地运行的,而且就是引入的sparl-core起的作用
D:\Java\jdk1.8.0_77\bin\java "-javaagent:D:\JetBrains\IntelliJ IDEA...17/11/28 00:40:21 INFO Executor: Starting executor ID driver on host localhost17/11/28 00:40:21 INFO Utils: Successfully started service 'org.apache.spark.network.netty.NettyBlockTransferService' on port 58570.17/11/28 00:40:21 INFO NettyBlockTransferService: Server created on 192.168.230.1:5857017/11/28 00:40:21 INFO BlockManager: Using org.apache.spark.storage.RandomBlockReplicationPolicy for block replication policy17/11/28 00:40:21 INFO BlockManagerMaster: Registering BlockManager BlockManagerId(driver, 192.168.230.1, 58570, None)17/11/28 00:40:21 INFO BlockManagerMasterEndpoint: Registering block manager 192.168.230.1:58570 with 1992.9 MB RAM, BlockManagerId(driver, 192.168.230.1, 58570, None)...17/11/28 00:40:22 INFO HadoopRDD: Input split: file:/C:/Users/msi/Desktop/xiaomi2.txt:0+90317/11/28 00:40:22 INFO Executor: Finished task 0.0 in stage 0.0 (TID 0). 1111 bytes result sent to driver17/11/28 00:40:22 INFO TaskSetManager: Finished task 0.0 in stage 0.0 (TID 0) in 183 ms on localhost (executor driver) (1/1)...(小米客服那些事,1)(贤艾森秋t4krP0,1)(北京IHG向,1)17/11/28 00:40:22 INFO SparkContext: Invoking stop() from shutdown hook17/11/28 00:40:22 INFO SparkUI: Stopped Spark web UI at http://192.168.230.1:4040...Process finished with exit code 0
2.提交集群运行
- 第一步同本地模式
- 第二步同本地模式
- 然后新建一个scala class,选择object,书写代码,要使集群模式
- 最后直接点击运行即可。
import org.apache.spark.{SparkConf, SparkContext}import org.apache.spark.rdd.RDDobject WordCount extends App {// 读取hdfs文件val path = "hdfs://192.168.146.130:9000/spark/look.sh"//远程调试val conf = new SparkConf().setAppName("scalasparktest").setMaster("spark://192.168.146.130:7077").setJars(List("I:\\IDEA_PROJ\\ScalaSparkTest\\out\\scalasparktest_jar\\scalasparktest.jar"))val sc = new SparkContext(conf)val lines = sc.textFile(path)val words = lines.flatMap(_.split(" ")).filter(word => word != " ")val pairs = words.map(word => (word, 1))val wordscount: RDD[(String, Int)] = pairs.reduceByKey(_ + _)wordscount.collect.foreach(println)}
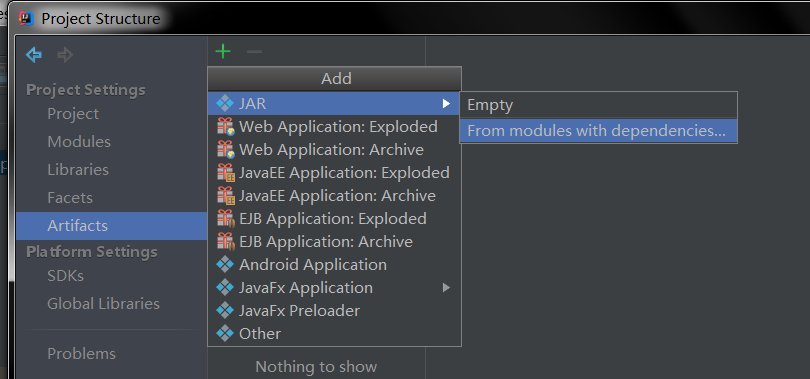
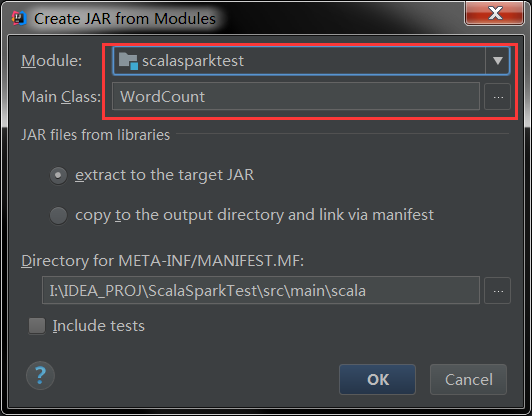
点击OK后,选择Jar打包后的路径
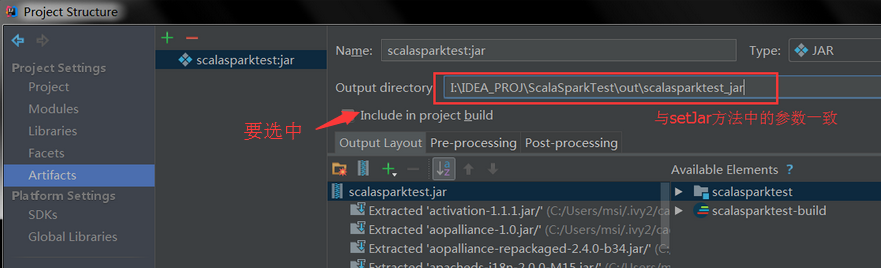
使用命令:
启动master: ./sbin/start-master.sh
启动worker: ./bin/spark-class org.apache.spark.deploy.worker.Worker spark://192.168.146.130:7077
需要配置spark-env.sh中:(下面设为localhost就远程不了了)
export SPARK_MASTER_HOST=192.168.146.130
export SPARK_LOCAL_IP=192.168.146.130
注意更新配置文件后需要把master和worker都重启才可以生效(单机两者都在一个机器上的情况)
出现的错误:
错误:java.io.FileNotFoundException: Jar I:\IDEA_PROJ\ScalaSparkTest\out\scalasparktest.jar not found
解决:修改setJar方法参数中的jar路径
错误:Could not connect to spark://192.168.146.130:7077
解决:重启worker和master,前提是spark-env.sh中的MASTER_IP和WORKER_IP要设置正确
错误:Exception: Call From msi-PC/192.168.230.1 to 192.168.146.130:8020 failed on connection exception: java.net.ConnectException: Connection refused: no further information;
解决:hdfs端口错误,很多教程写的是8020端口,但我hdfs是9000端口,所以要更正
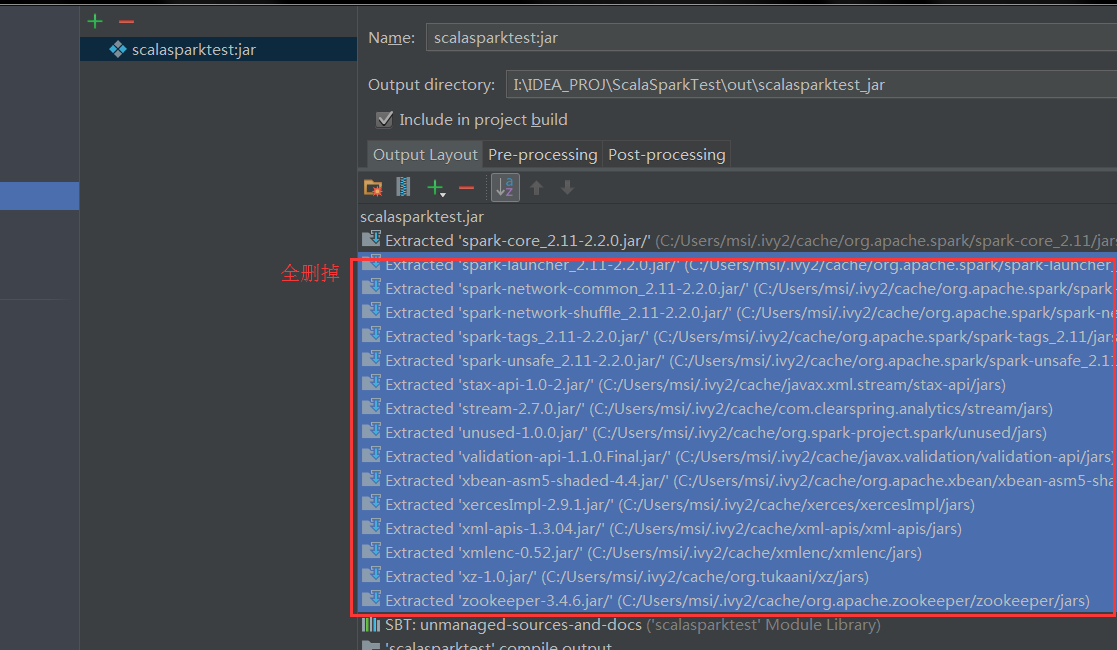
错误:Invalid signature file digest for Manifest main attributes
解决:打包的文件很大,把全部依赖都打包了,90多M,但正常应该10多M,删掉无用的依赖,并且把sbt中spark-core的依赖设为provided模式
错误:重复出现如下错误
17/11/28 20:20:52 WARN TaskSchedulerImpl: Initial job has not accepted any resources; check your cluster UI to ensure that workers are registered and have sufficient resources17/11/28 20:21:07 WARN TaskSchedulerImpl: Initial job has not accepted any resources; check your cluster UI to ensure that workers are registered and have sufficient resources17/11/28 20:21:22 WARN TaskSchedulerImpl: Initial job has not accepted any resources; check your cluster UI to ensure that workers are registered and have sufficient resources
解决:应该是将虚拟机挂起后再激活使用时出现的一些错误,将hadoop和spark都重启即可
提交集群运行的结果:(注意IP和端口,确实是提交到集群/虚拟机 上运行后返回的结果)
整个过程全部在IDEA中,完全达到了本地调试,自动上传集群,并返回结果的流程
D:\Java\jdk1.8.0_77\bin\java "-javaagent:D:\JetBrains\IntelliJ IDEA...17/11/28 02:09:39 INFO StandaloneAppClient$ClientEndpoint: Executor added: app-20170630223625-0006/0 on worker-20170630215502-192.168.146.130-50762 (192.168.146.130:50762) with 1 cores17/11/28 02:09:39 INFO StandaloneSchedulerBackend: Granted executor ID app-20170630223625-0006/0 on hostPort 192.168.146.130:50762 with 1 cores, 1024.0 MB RAM17/11/28 02:09:39 INFO StandaloneAppClient$ClientEndpoint: Executor updated: app-20170630223625-0006/0 is now RUNNING...17/11/28 02:09:43 INFO BlockManagerMasterEndpoint: Registering block manager 192.168.146.130:47071 with 413.9 MB RAM, BlockManagerId(0, 192.168.146.130, 47071, None)...17/11/28 02:09:50 INFO TaskSchedulerImpl: Adding task set 0.0 with 2 tasks17/11/28 02:09:50 INFO TaskSetManager: Starting task 0.0 in stage 0.0 (TID 0, 192.168.146.130, executor 0, partition 0, ANY, 4853 bytes)...17/11/28 02:09:55 INFO TaskSetManager: Starting task 1.0 in stage 0.0 (TID 1, 192.168.146.130, executor 0, partition 1, ANY, 4853 bytes)...17/11/28 02:09:55 INFO TaskSchedulerImpl: Adding task set 1.0 with 2 tasks17/11/28 02:09:55 INFO TaskSetManager: Starting task 0.0 in stage 1.0 (TID 2, 192.168.146.130, executor 0, partition 0, NODE_LOCAL, 4625 bytes)...17/11/28 02:09:56 INFO TaskSetManager: Starting task 1.0 in stage 1.0 (TID 3, 192.168.146.130, executor 0, partition 1, NODE_LOCAL, 4625 bytes)...(-ef|grep,1)($Jarstr,1)([[,1)(do,1)(YES,1)(while,1)("$Jarinfo",1)(echo,1)(#!/bin/bash,1)17/11/28 02:09:56 INFO SparkContext: Invoking stop() from shutdown hook...Process finished with exit code 0
