@JudyYe
2016-07-05T20:33:55.000000Z
字数 1293
阅读 409
GENERIC 3D REPRESENTATION VIA POSE ESTIMATION AND MATCHING
overview
few fundamental superviesed tasks ---without finetuning---> secondary unsupervised tasks
rather than training a new model for every individual desired problem, we train a model to learn fundamental vision tasks that serve as the foundation for ultimately solving the desired problems.
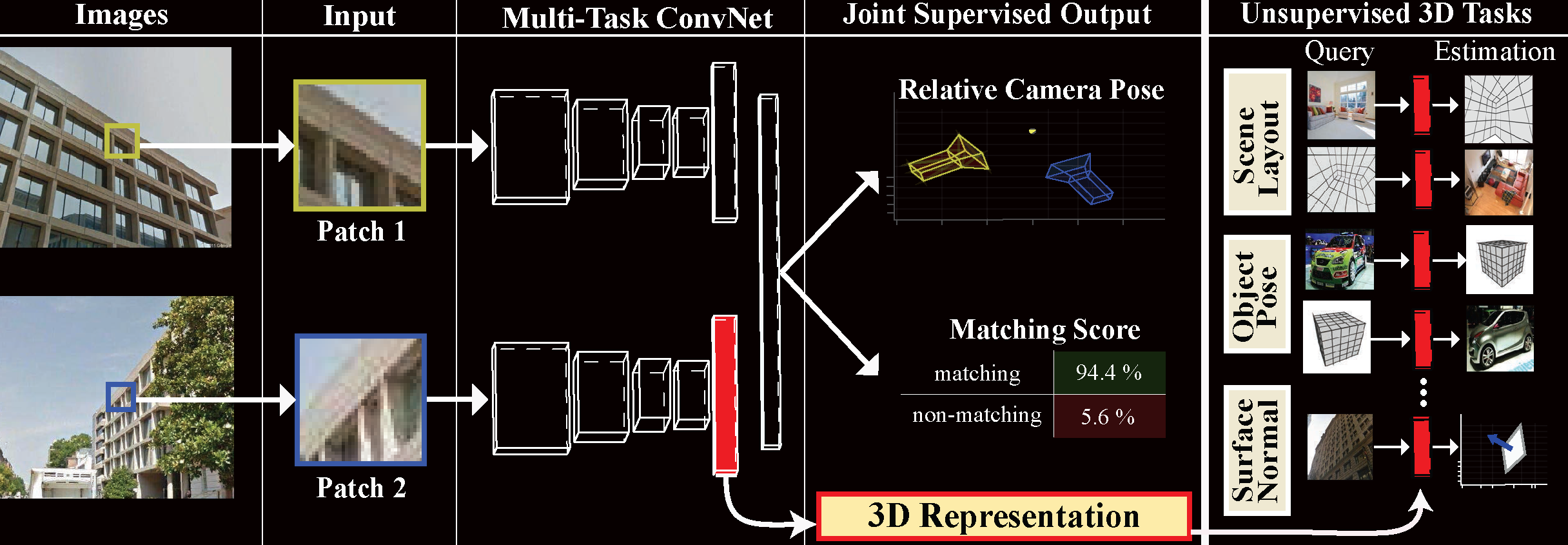
Learn a generic 3D representation through supervising two basic but fundamental 3D tasks.the two supervised tasks
- object-centric camera pose estimation
- wide baseline feature matching
- Then they directly generalize the model to unseen 3D tasks without fintuning. show
- scene layout estimation,
- object pose estimation,
- surface normal estimation
pipeline
result, evalutation
unsupervised tasks
- pose estimation
- more of a semantic task rather than geometric/3D. That adversely impacts a method that has a 3D understanding but not semantic (e.g., our representation).
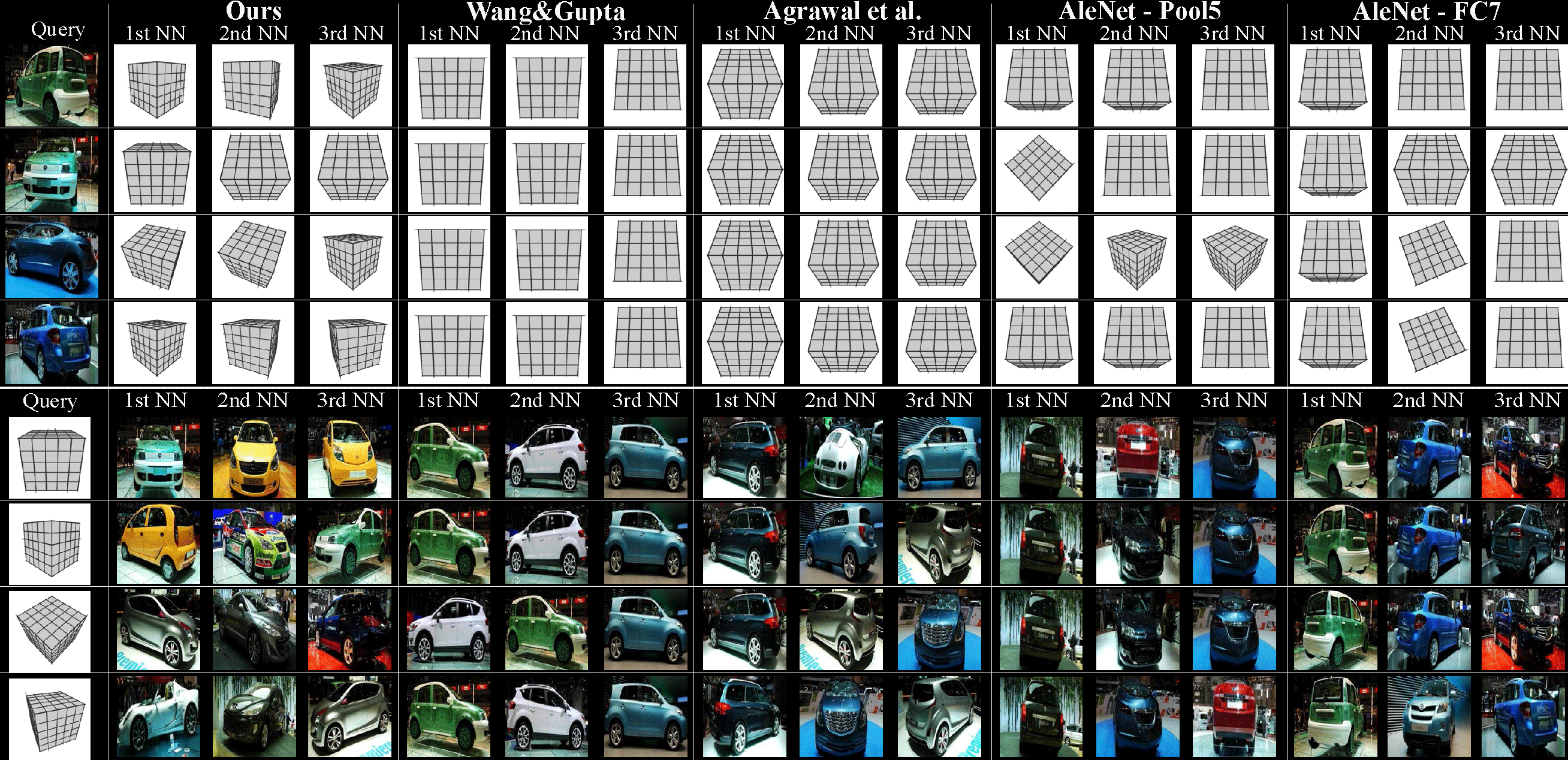
abstract of 3d object pose
- compare with Wang&Gupta
- our representation retrieves meaningful NNs while the baselines mostly overfit to appearance and retrieve either an incorrect or always the same NN.
scene layout estimation
- compare with Wang&Gupta

- compare with Wang&Gupta
supervised tasks state-of-art result
- camera estimation
- feature matching
discussion
- How to decide the fundamental supervised task?
- Better integrating method? More than late fusion for ConvNet fine-tuning? semantic(feature matching task?) + 3D aspects(camera pose estimation?)
silly questions
- How does the tsne visualization work?
