@LittleRewriter
2018-06-15T11:43:03.000000Z
字数 48240
阅读 2015
qbxt集训 数学专题
数学
D1的考试
T1
给一个数字串,如果可以划分成两个部分使得且是完全立方数,则称该划分是一个好划分。
若一个数字串有至少两个好划分,则称为膜法串。输出一个位的膜法串。
30分做法:打表
正解:多几个0打表,因为1000是个完全立方数。
T2
把分为组,每组两个元素,每组的权值是两个元素之和,求划分的最大权值的期望。
20分做法:阶乘枚举一下
正解:
直接求答案恰好是v的概率是不好求的。所以我们可以先转化问题为,这样就可以利用前缀性质。
想要让答案不大于v,我们可以将分为和的。关注到这样一个性质,即对于一个的数,当且仅当选取一个的才能满足其和,又由于,则。
不妨设,我们关注到这样一个性质。对于,想要,就有种选择。同理对,有种选择,但由于使用了一种,所以只有种。同理,我们发现,对于的所有元素都有种选择。因而,这个元素的情况有种。
对于剩余的个元素来说,实际上等价于一个完全图计数问题。即。阶乘可以预处理一波。
于是,就可以实现了。注意要加乘法逆元,因为我太弱了不知道费马定理只会exgcd。附上我比老师长了四倍的代码 233
#include <bits/stdc++.h>using namespace std;#define mod 1000000007#define LL long longLL mul[500003], n, ans[500003], qwq[500003];LL exgcd(LL a, LL b, LL& x, LL& y) {if(!b) {x = 1, y = 0; return a;}LL q = exgcd(b, a % b, x, y);LL t = x; x = y; y = t - a / b * y;return q;}LL getni(LL x) {LL xx, yy;exgcd(x, mod, xx, yy);return (xx + mod) % mod;}LL ksm(LL a, LL b) {LL tans = 1;while(b) {if(b & 1) tans = (tans * a) % mod;a = (a * a) % mod;b >>= 1;}return tans;}LL msmul(LL a, LL b) {a %= mod, b %= mod;LL tans = 0;while(b) {if(b & 1) tans = (tans + a) % mod;a = (a + a) % mod;b >>= 1;}return tans;}void init() {mul[0] = 1;for(int i = 1; i <= n / 2; ++i) {mul[i] = (mul[i - 1] * (i * 2 - 1)) % mod;}}int main() {cin>>n;init();for(LL p = n + 1; p <= n + n - 1; ++p) {LL k = p / 2;ans[p - n] = (ksm(p - n, n - k) * mul[n / 2 - n + k]) % mod;}LL sum = ans[n - 1] % mod; sum = getni(sum);for(int i = 1; i <= n - 1; ++i) qwq[i] = (ans[i] - ans[i - 1]) % mod;LL tmp = 0;for(int i = 1; i <= n - 1; ++i) {tmp = (tmp + msmul(qwq[i], (i + n) * sum)) % mod; //这一步不加慢速乘会爆LL很惨QAQQAQQAQ}cout<<(tmp + mod) % mod<<endl;}
关于完全图计数的证明:
等价于分组分配问题,则,关注到,同理可以消去多余部分,最后得到结果
T3
若一个数的奇数位之和和偶数位之和的最大公约数均大于0不超过K,则称为幸运数。求有多少幸运数。
30分做法:分块打表,可以隔记一次答案。
60:数位dp.
将转化为
首先我们做一遍背包,用表示i个数字和为S的方案数。
然后以前缀分类,例如,我们分别维护,可以求得0xxx,10xx,11xx,120x,121x,122x,1230,1231,1232,1233,1234,对于剩余部分的情况,我们可以枚举每个满足的和,这个解可以在预处理中迅速转移。
100:关注到,因此我们可以进行信息压缩。维护i个数位没有填写时,已填写的i同奇偶的数位和为,不同位的数位和为,那么,然后就可以迅速枚举、迅速求值。
一类递归问题
汉诺塔
手动模拟一下可以发现。
得封闭形式:
封闭形式:用与无关的次数计算
假设我们猜想了这个通项,想证明其正确性,可以考虑数学归纳法。
变形1
从A到C需要先经过B
,
变形2
从A局面到B局面,要求最优策略步数最多
每一种状态都包含在从都在第一个到都在第三个的状态上,因而这种策略最多。
变形3
计算给定一个初状态和一个末状态需要多少步
考虑一个无序状态到有序状态,其中有序状态指的是所有已访问过的盘子都在某个柱子上。
int solve(int* a, int n, int t) {while(n && a[n] == t) n--; //已经在了if(!n) return 0; //没有了int x = 6 - a[n] - t;//剩下的柱子return solve(a, n - 1, x) + 1 + H[n - 1]; //把剩下的移动到柱子x}int main() {while (a[n] == b[n]) n --;int t = 6 - a[n] - b[n];ans = solve(a, n - 1, t) + 1 + solve(b, n - 1, t);ans = min(ans, solve(a, n - 1, b[n]) + 1 + s[n - 1] + 1 + solve(b, n - 1, a[n]));}
其中数组存储的是当前第i个盘在哪个柱子上,我们就把它移动到新的一个柱子上,同时,由于前n-1个已经有序,将有序的移动需要的代价是,该柱子移动代价是,其余部分的是solve(a, n - 1, x)。
我们不妨用一个例子来解释。
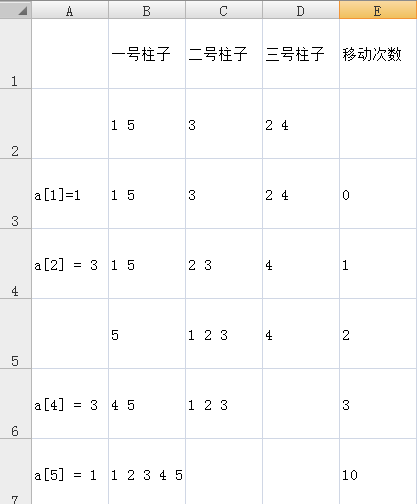
不过这样会被hack,如下面的:

从如图到A、C的交换的情况,把第二个盘子先移到B,再把那一堆移到A,最后移过去,会更优。
所以我们需要求个min:
int main() {while (a[n] == b[n]) n --;int t = 6 - a[n] - b[n];ans = solve(a, n - 1, t) + 1 + solve(b, n - 1, t);ans = min(ans, solve(a, n - 1, b[n]) + 1 + s[n - 1] + 1 + solve(b, n - 1, a[n]));}
变形4
四柱汉诺塔,即有四个柱子。
我们可以先放k个,然后就变成了三柱汉诺塔。
变形5
m个柱子的汉诺塔,则令为i个盘子j个柱子的最小值。
平面上的直线
,,,
,叠加可得封闭形式。
变形
一个V字形直线和其他相交,则有多少?
,因为每个V可以和另外一个V有两个交点。
也可以考虑亏损,
快速幂
求
也可以用倍增实现,可以减少常数。
LL ksm(LL x, LL y, LL p) {LL z = 1;while(y) {if(y & 1) (z *= x) %= mod;(x *= x) %= mod;y >>= 1;}return z;}
高精度
struct bign {int n[N], l;bign() { memset(n, 0, sizeof(n)), l = 0; }void cl() { memset(n, 0, sizeof(n)), l = 0; }int& operator[] (int i) { return n[i]; }void rd() {scanf ("%s", sn + 1);int k = 1, ls = strlen(sn + 1);Rep(i, 1, ls) {n[l] += (sn[ls - i + 1] - '0') * k, k *= 10;if (i % 4 == 0 || i == ls) l ++, k = 1;}l --;}void pr() {int len = 0;Rep(i, 0, l) {int k = n[i];Rep(j, 1, 4) sn[++ len] = '0' + k % 10, k /= 10;}while (len > 1 && sn[len] == '0') len --;Dwn(i, len, 1) printf("%c", sn[i]);puts("");}} ans, sum;bign make(LL x) {bign a;while (x) a[a.l ++] = x % lm, x /= lm;if (a.l) a.l --;return a;}bign operator+ (bign a, bign b) {bign c = a; c.l = max(a.l, b.l);Rep(i, 0, c.l) {c[i] += b[i];c[i + 1] += c[i] / lm, c[i] %= lm;}while (c[c.l + 1]) c.l ++, c[c.l + 1] += c[c.l] / lm, c[c.l] %= lm;return c;}bign operator- (bign a, bign b) {bign c = a;Rep(i, 0, c.l) {c[i] -= b[i];if (c[i] < 0) c[i] += lm, c[i + 1] --;}while (c.l && !c[c.l]) c.l --;return c;}bign operator* (bign a, bign b) {bign c; c.l = a.l + b.l;Rep(i, 0, a.l) {Rep(j, 0, b.l) {c[i + j] += a[i] * b[j];//c[i + j + 1] += c[i + j] / lm;//c[i + j] %= lm;}}Rep(i, 0, c.l) c[i + 1] += c[i] / lm, c[i] %= lm;while (c[c.l + 1]) c.l ++, c[c.l + 1] += c[c.l] / lm, c[c.l] %= lm;return c;}bign operator+ (bign a, LL x) { return a + make(x); }bign operator- (bign a, LL x) { return a - make(x); }bign operator* (bign a, LL x) { return a * make(x); }bign operator/ (bign a, LL b) {bign c; LL d = 0;c.l = a.l;Dwn(i, a.l, 0) d = d * lm + a[i], c[i] = d / b, d %= b;while (c.l && !c[c.l]) c.l --;return c;}
数论基础
数论是什么
用整除理论、同余理论通过整除性质解决整数问题。
整除
,即
满足自反性、对称性、传递性
,
素数
除1和自身外不存在能整除的正整数。
有无限多个,证明:假定有有限多个,另
素数定理
小于的素数个数近似为
算数基本定理
朴素的判断素数
试除法
如果已经预处理出所有素数,则可优化到
nlhdalao的优化:我们发现这个数一定是或,可以优化枚举。
朴素的分解质因数
试除。
因子
从试除,若是一个因子,那么也是。
for(int i = 1; i * i <= n; ++i) {if(n % i == 0) {d[++siz] = i;if(i * i < n) d[++dsz] = n / i;//特判}}
上面的特判是回避掉的情况。
如果知道,则因子数量为
埃氏筛法
逐次枚举,如果没有被标记就标为素数,并把所有倍数标记。
not_prime[1] = 1;for(int i = 2; i <= n; ++i) {if(!not_prime[i]) { //1for(int j = i * 2; j <= n; j += i)not_prime[j] = 1;}}
,为调和级数。近似可以这样计算:,则可以放缩为,因此其复杂度。
如果加上1的判断可以优化到
线性筛
for(int i = 2; i <= n; ++i) {if(!not_prime[i])prime[++siz] = i; //存素数for(int j = 1; j <= siz; ++j) { //枚举筛过的所有素数if(i * prime[j] > n) break; //乘积大于n,不必再筛not_prime[i * prime[j]] = 1;if(i % prime[j] == 0) break; //保证复杂度,核心。}}
例如30 = 2 * 3 * 5,那么会被6 * 5、10 * 3、15 * 2各筛一次。但是当枚举到i的非最小素因子的时候,就break掉了,直到遇到最小素因子。所以这句话保证了每个数被最小素因子筛掉,复杂度降为
例题
给个数,判断是不是质数。
预处理即可。
区间筛
SPOJ Prime1
给l, r,,,求素数
O(能过):暴力试除
O(更能过):预处理的所有素数
预处理,枚举区间内的素数筛掉。
for(int i = 1; i <= psz; ++i) {int p = prime[i];for(int j = (l - 1)/ p + 1; j <= r / p; ++j)not_prime[j * p - l] = 1;}
复杂度
模运算
除法定理
存在唯一使得
令,
则
实数意义扩展
从长m的圆环上某一点开始走长度为n离起点的距离
最大公约数
m, n的公约数的最大整数
int gcd(int a, int b) {return !b ? a : gcd(b, a % b);}
最坏情况下是一个斐波那契数列。
因而递归两次规模至少减小一半,
gcd递归定理
我们首先需要证明
显然有。
令,则
存在q使得,从而。由于,所以,
又有,所以可以用类似的过程证得,所以
裴蜀定理
有整数解当且仅当
我们首先有的线性组合集最小正元素
然后我们知道一定存在。
可以拓展到多元,即
推论:
1), 则
2)a, b互质的充要条件是
3),且,
4)p为质数,,则或
5)p为质数,,则
算数基本定理的几个推论
若
例题
hdu4497 GCD and LCM
,gcd为G,lcm为L,G、L已知,求三元组个数
对每个素因子单独处理。
对于单个p因子,相当于求,,所以我们需要一个,一个的。设中间的数是,若有种,如果或有种,所以共种。
扩展欧几里得
int exgcd(int a, int b, int& x, int& y) {if(!b) {x = 1, y = 0; return a;}int d = exgcd(b, a % b, y, x);y -= (a / b) * x;return d;}
则全部解为,
例题
NOIP2012 同余方程
求解
等价于求解
POJ1061/luogu1516 青蛙的约会
找到关系式,我们发现
化简:
最终答案:
NOI2002/luogu2421 荒岛野人
从1到M枚举,然后我们列出上题的式子,如果即在有生之年会遇到就break掉。
最坏复杂度,但是能过。
同余关系
满足自反性、对称性、传递性、可加减性
逆元
对于m,对于a,存在b满足,称b是模m意义下的逆元。可以记作
解即可。其有逆元的条件是。
当p为质数,可以直接求,由费马小定理可得。
可以预处理.
借助阶乘预处理:我们先得出的逆元,那么。
那么
q[1] = 1;for(int i = 2; i <= n; ++i)q[i] = q[i - 1]*i%mod;p[n] = power(q[n], mod - 2);for(int i = n; i > 1; --i) p[i - 1] = p[i]*i%mod;for(int i = 1; i <= n; ++i) inv[i] = q[i - 1] * p[i] % mod;
另一种预处理:我们知道。由于,则
从而
从而
剩余类、完系、简系
- 剩余类:
- 完系:从各取一个作为代表
有这样的特征,即将完系中每个元素+b - 简系:简化剩余系,即去除在完系中与p不互质的
费马定理
首先需要一个结论。
考察这样一个数列:令
这个数列是一个周期数列,且
这一结论的证明:用数归可以简单的证明是(a, b)的倍数,所以我们可以约去。考虑到当且仅当,所以应该取遍了。
费马定理的内容:
素数测试
费马测试
如果的合数是以a为底的伪素数。我们可以打表求一个伪素数表,在前10亿的自然数有1272个。
如果我们取若干a,会有一类数始终不符合。
二次探测定理
,则
设待测数是n,。我们发现,
Miller-Rabin测试
在费马测试的基础上的Miller-Rabin测试是一种更为快捷的素数测试方法。
我们先来举一例。不妨设此时测试的底是2,由于,如果341是素数,由于,则应当有。而由于有,所以我们应该有,但是这里不成立了;。
那么,对于一个目标的判断数,如果我们知道,其中是奇数,我们就可以一步一步倒推。即,如果,那么应有。
不过这里需要注意,如果一直判断到所有的2都用完仍然是1,那就表明通过了MR测试。但是,如果到某一个位置的时候,得到的是n-1,那么就不满足了二次探测定理的适用条件。从而,此时就不得不退出MR测试。如果到某个位置,既不是1也不是-1,就说明不可能是素数了。
同样,我们可以多进行几组数据测试,例如对于k为底的,我们可以分解为且,其余同理。
老师的板子给的是一种非递归版本。
#include <iostream>#include <cstdio>#include <algorithm>#include <cstring>#include <cmath>#include <string>#include <ctime>#define Rep(i, x, y) for (int i = x; i <= y; i ++)#define RepE(i, x) for (int i = pos[x]; i; i = g[i].nex)#define C 240#define TIME 10using namespace std;typedef long long LL;LL ans;int T;LL Mult(LL x, LL y, LL md) {LL z = 0;while (y) {if (y & 1) (z += x) %= md;(x += x) %= md, y >>= 1;}return z;}LL Pow(LL x, LL y, LL md) {LL z = 1; x %= md;while (y) {if (y & 1) z = Mult(z, x, md);x = Mult(x, x, md), y >>= 1;}return z;}LL gcd(LL x, LL y) {if (x == 0) return 1;if (x < 0) return gcd(-x, y);return !y ? x : gcd(y, x % y);}bool Witness(LL a, LL n) {LL t = 0, u = n - 1;while (!(u & 1)) t ++, u /= 2;LL x0 = Pow(a, u, n);if (x0 == 1) return 0;for (int i = 0; i < t; i ++) {if (x0 == n - 1) return 0;x0 = Mult(x0, x0, n);}return 1;}bool Miller_Rabin(LL n, int t) {if (n == 2) return 1;if ((n & 1) == 0) return 0;srand(time(0));for (int i = 0; i < t; i ++) {LL a = rand() % (n-1) + 1;if (Witness(a, n)) return 0;}return 1;}int main(){srand(time(0));scanf ("%d", &T);while (T --) {LL n; scanf("%I64d", &n);if (Miller_Rabin(n, TIME)) printf ("Prime\n");else {printf ("NotPrime\n");}}return 0;}
中国剩余定理
两两互素的求法:
,为逆元
事实上,我们发现
可以看百度百科。
非互素的求法:
,
等价于
有解:
我们用扩欧可以解出来特解,令,则,
从而,,令,上面的方程就转化为了
数论分块
求
for(int i = 1, j; i <= n; i = j + 1) { //j维护n/j = n/i的所有情况中最大的jj = (n / (n / i)); //玄学步骤,祖传秘方,只可意会,不可言传ans += (j - i + 1) * (n / i);}
比如n = 10,i = 4,10/4 = 2,,10/2=5,则在上结果都是2,所以我们就加上这个东西。
求,
前一部分,后一部分等价于一个等差数列求和。
求

BSGS
求,为质数
令,
我们存,然后枚举t、c。
原根和质数
,的最小正整数称为模m的阶
性质:1),r为阶。
特别的,
2)且为素因子,。逆命题也成立。
原根:的阶
用上面的性质2枚举并检查一下。原根比较小,嗯。
bool check(int g, int m) {for(int i = 2; i * i < m; ++i){if((m - 1) % i == 0 && (ksm(g, i, m) == 1 || ksm(g, (m - 1)/i, m) == 1))return 1;return 0;}}
若m有原根g,那么为m的缩系。
从而与m互素,则,
因而记,称为g的离散对数。
离散对数具有的性质和对数类似。
,p为素数
先求出p的原根g
令,,这一步是可以BSGS的。
则
由于
所以化成了这个同余方程。
数论函数
积性函数
如果为素数,,则称为积性函数
欧拉函数
定义:在中不和互素的数的个数
性质:
1)积性:我们可以理解成,
2)p为素数,
其原因是这样的,和不互质的一定有因数p,
因此我们可以用线性筛求
for(int i = 2; i <= n; ++i) {if(!not_prime[i])prime[++siz] = i, phi[p] = p - 1;for(int j = 1; j <= siz; ++j) {if(i * prime[j] > n) break;not_prime[i * prime[j]] = 1;if(i % prime[j] == 0) {phi[i * prime[j]] = phi[i] * prime[j];break;} else phi[i * prime[j]] = phi[i] * (prime[j] - 1);}}
3)
我们考虑,那么约分之后恰好取遍了所有情况。
例如,对于6,,恰好取遍了1、2、3、6这四个因数的所有互质数。
欧拉定理
所以对于不是素数的逆元也可以用欧拉定理求得。
1)积性
该性质显然。由此可以做线性筛:
mu[1] = 1;for(int i = 2; i <= n; ++i){if(not_prime[i] == 0) {prime[tot++] = i; mu[i] = -1;}for(int j = 1; prime[j] * i <= n; ++j) {not_prime[prime[j] * i] = 1;if(i % prime[j] == 0){mu[prime[j] * i] = 0;break;}mu[prime[j] * i] = -mu[i];}}
2)
证明:显然
否则,如果分解为一系列互异素数的乘积,有个,那么由二项式定理
反演(相声)
//zrt的反演先咕咕咕了
一些栗子:
从而,带进去试一试,是对的,嗯。
gcd与数论函数八题
1)BZOJ2818 的对数
等价于的前缀和。
2)为素数,的对数
先枚举质数。这时我们将问题变成了的个数,即的个数,于是就划归到了1。
在展开下面的几道题之前,我们先来得一个结论。
,,则的个数有
这个较为显然,因为我们必须在这个区间内找到所有d的倍数。
然后就变得稍微可做(并不)一点。
3)SP7001 求,
的组数,那么根据上面的结论,有
的组数,这个比较难求。
由于,在本题中,由第二种形式:,进一步变形可以得到
然后就可以求了。
#include <cstdio>#include <algorithm>#include <iostream>#define int long longusing namespace std;int prime[100003], mu[1000003], T, n, cnt = 1;bool not_prime[1000003];void getprime() {mu[1] = 1, prime[1] = 1, not_prime[1] = 1;for(int i = 2; i <= 1000001; ++i) {if(!not_prime[i]) {prime[++cnt] = i;mu[i] = -1;}for(int j = 2; prime[j] * i < 1000001 && j <= cnt; ++j) {not_prime[i * prime[j]] = 1;if(i % prime[j] == 0) {mu[i * prime[j]] = 0; break;}mu[i * prime[j]] = -mu[i];}}}int calc(int x) {return 1LL * mu[x] * (n / x) * (n / x) * (n / x) + 3LL * (mu[x] * (n / x) * (n / x));}signed main(void) {getprime();scanf("%lld", &T);while(T--) {scanf("%lld", &n);int ans = 3;for(int i = 1; i <= n; ++i) {ans += calc(i);}cout<<ans<<endl;}}
4)luogu3455 ,,组数据,
类似上面的,令的组数,则
令的组数,则
从而反演,
令,则
现在要求多组数据,我们可以采用数论分块来求。
这个玩意的求法:
,原理是啥这个可以意会一下,因为我们其实是在取一个公共部分。
#include <bits/stdc++.h>using namespace std;#define N 50003#define LL long longint prime[N], mu[N], cnt = 0, sum[N]; bool not_prime[N];inline void getprime() {not_prime[1] = 1; mu[1] = 1;for(int i = 2; i < N; ++i) {if(!not_prime[i]) {prime[++cnt] = i;mu[i] = -1;}for(int j = 1; i * prime[j] < N && j <= cnt; ++j) {not_prime[i * prime[j]] = 1;if(i % prime[j] == 0) {mu[i * prime[j]] = 0; break;}else mu[i * prime[j]] = -mu[i];}}for(int i = 1; i < N; ++i) sum[i] = sum[i - 1] + mu[i];}inline LL getR(LL n, LL L) {return n / (n / L);}int main() {getprime();int T;cin>>T;while(T--) {int d, a, b; LL ans = 0;scanf("%d%d%d", &a, &b, &d);a /= d, b /= d;for(int i = 1, j; i <= min(a, b); i = j + 1) {j = min(a / (a / i), b / (b / i));ans += 1LL * (sum[j] - sum[i - 1]) * (a / i) * (b / i);}cout<<ans<<endl;}}
5)luogu2522 ,,,多组数据。
同上面的求解过程。
不过需要套一个二维前缀和类似的容斥。也许我们的第一反应是,不过其实并不是。这点务必小心,因为这里的并非代表从到的面积,而是代表到的面积,也就是同时取到最大值时候的x, y和最小值时候的x, y。
6)gcd(x, y)为质数,,
//这题放弃理解。。
由于
所以原式=
然后用玄学技巧更改求和指标
原式
令,则
令
然后可以在筛完之后跑一遍埃氏筛预处理F(x)。
7)
我们可以质因数分解并暴力求之。看上去复杂度大的一比,不过其实能过。
8)luogu1447 能量采集
莫反法固然是推不动的,还是容斥比较能接受。
经过的整点一定是满足,的,所以一共有个整点。
我们令为的个数,为的个数。这样,我们发现,逆推即可。
而
然后就可以求出来了。
#include <bits/stdc++.h>using namespace std;#define LL long longint n, m;LL g[100003], ans;int main() {cin>>n>>m;for(int i = n; i >= 1; --i) {g[i] = 1LL * (n / i) * (m / i);for(int j = 2; 1LL * i * j <= 1LL * min(n, m); ++j)g[i] -= g[i * j];ans += g[i] * 2 * i;}ans -=1LL * n * m;cout<<ans<<endl;}
复杂度:,为调和级数,约为
概率与期望
大佬推荐:http://www.yhzq-blog.cc/%E6%A6%82%E7%8E%87%E6%95%B0%E5%AD%A6%E6%9C%9F%E6%9C%9B%E6%80%BB%E7%BB%93/
概率的解释
频率学派
贝叶斯学派:构建模型
样本空间、事件、概率
样本空间是一个集合,元素是基本事件
概率:一种事件到实数的映射
事件A发生,B一定发生
条件概率:
当,两两独立,
数学期望
期望有线性性。
习题
cf280C Game on tree
https://blog.csdn.net/acmmmm/article/details/41688045
写的不错的样子。。
考虑到一个点被染的情况下一定是祖先没有被染。
由于我们要求操作次数,这个操作次数指的是这个点要被染黑。
它有dep[x]个祖先,而它自己被染黑的概率就是1/dep[x]。又由于操作的代价是1,所以
由期望的可加性,
话说这题坑在50多点的是翻译的锅……原题有一句根节点编号是1,所以这是个无向图。
luogu4316 绿豆蛙的归宿
每条边期望总长度:期望到达每边次数 * 边权
那么到达每一个边的期望次数是多少呢?是期望到达入点的次数和除以出度。
那么到达入点的次数是多少呢?是进入该节点的边的期望长度之和。
然后呢,这玩意是个DAG。所以我们可以用拓扑序转移。
#include <iostream>#include <cstdio>#include <vector>#include <queue>#include <iomanip>using namespace std;#define N 100003struct node{int to; double va;node(){};node(int a, double b) {to = a, va = b;}};vector<node> edge[N];int degree[N], rank[N], cnt, st, n, m;double dp[N], time[N], ans;inline void add_edge(int fr, int to, double va) {edge[fr].push_back(node(to, va));degree[to]++;}void topo_sort() {queue<int> q;for(int i = 1; i <= n; ++i) if(degree[i] == 0) q.push(i), st = i, degree[i]--, rank[++cnt] = i;while(!q.empty()) {int t = q.front(); q.pop();for(int i = 0; i < edge[t].size(); ++i) {int qwq = edge[t][i].to;degree[qwq]--;if(!degree[qwq]) q.push(qwq), rank[++cnt] = qwq;}}}double work() {dp[rank[1]] = 0; time[rank[1]] = 1;for(int i = 1; i <= n; ++i) {int nownode = rank[i];for(int j = 0; j < edge[nownode].size(); ++j) {int nxt = edge[nownode][j].to; double val = edge[nownode][j].va;time[nxt] += time[nownode] / edge[nownode].size();ans += (time[nownode] / edge[nownode].size()) * val;}}return ans;}int main() {scanf("%d%d", &n, &m);int xx, yy; double vv;while(m--) {scanf("%d%d%lf", &xx, &yy, &vv);add_edge(xx, yy, vv);}topo_sort();cout<<fixed<<setprecision(2)<<work()<<endl;}
luogu3232
我们希望期望次数大的编号小。
走某条边的概率:1/度数
从而,,其中j和1有边
对于其他点,,其中i和j有边
然后可以由此列出来方程组,套高斯消元即可。
POJ2096 Collecting Bugs
dp[i][j]表示现在修出来i种分属j种,则
这玩意看上去不可求,但是我们加起来移项就可做了。
不知道是啥的题
n种物品,每次购买随机到一种,买到n种物品的期望次数
买到k种,继续买,失败概率为,则,化简有
所以
UVA11021
dp[i]:i天内全死的概率
那么我们考虑如果第一只产生了只后代,那么有的概率,并且这i只必须在剩下的天内死亡。由于这里是独立事件,所以概率为
同理,以此类推有,
而
BZOJ1419
用维护 还剩 i张R和j张B
那么,因为如果是0还不如不拿。
初始化:,
UVA10529 Dumb Bones
相当于从_____到|||||的期望次数
我们令:从i~j全倒,然后发现一个性质,由于骨牌是一样的,所以可以将变换为表示长度是i的骨牌起来的最小次数。
那怎么来的呢?是从扶起,,并扶起第块。于是扶起第i块成功的期望就是,表示没有倒。
由于倒一次的概率是,因此期望次数为
由于倒一次的前提是前几次都没有倒,也就是
我们考虑条件概率,在倒的前提下左边倒的概率就是
同理,右边的概率是
注意这里还要加上表示一开始的代价
从而,
即:
luogu4206 聪聪和可可
预处理:A在i,B在j,A下一步去哪里
那么我们发现,用为A在i,B在j的相遇时间
指的就是A走两步之后到的地方。
,其中j与k相邻
SPOJ4060
维护剩i个Alice先手的胜率,维护剩i个Bob先手的胜率
这两个函数是对称的,并且
,
然后我们把后面的式子带进去,得到
所以
同理
然后根据一些玄学结论,n趋于时两个值都会趋于一个定值。所以,我们只需要就可以大概精确到最终结果。
当然,这其实是一个很有效的骗分方法。
迷失游乐园
嗯,这题啊,不存在的。
玄学的题(长者)
例1
在小葱和小泽面前有三瓶药,其中有两瓶是毒药,每个人必须喝一瓶,小葱和小泽各自选了一瓶药,小泽手速比较快将药喝了下去,然后就挂掉了。小葱想活下去,他是应该喝掉手上的这瓶,还是另外剩下的一瓶呢?
当小泽拿了第一瓶之后,列个树状图。

所以答案是换不换都可以。
参赛者会看见三扇关闭了的门,其中一扇的后面有一辆汽车,选中后面有车的那扇门可赢得该汽车,另外两扇门后面则各藏有一只山羊。当参赛者选定了一扇门,但未去开启它的时候,节目主持人开启剩下两扇门的其中一扇,露出其中一只山羊。主持人其后会问参赛者要不要换另一扇仍然关上的门。问题是:换另一扇门会否增加参赛者赢得汽车的机率?

所以换比较好。
例2
先算从到概率是
从回去概率是,由于有顺序所以还要乘上
综上所述到再回来答案应该是
因此
我们发现后面可以逆用二项式定理
例2.333333
一条路有100个石头,有会挂;一条路有1000个石头,有会挂,选哪条路挂掉的概率大?
比较和
,所以选1000条路的挂掉概率大。
例4
做法一:枚举总共向右走了多少步,并且走的过程中不超过0,需要乘一个卡特兰数:
然后发现不可推。
做法二:到0的概率
解法三:两种情况,第一种走到-1,概率是;第二种是走到1,再回到-1,等价于回到0在回到-1,1到0是p,0到-1也是p,从而有
解得
由于概率>1,所以答案为
例5
和上一题一样。因为死相当于-1,活相当于+1.
代数
排列
一个长度为n的排列指的是n个数,,每个数恰好出现一次,就称为一个排列。
例如,3 1 2、1 2 3 4是一个排列,1 2 3 5不是一个排列。
逆序对:对一个排列,,称为一组逆序对。
对换:将排列两个位置交换,形成一个新的排列,这样的操作叫做对换。
偶排列:逆序对数是偶数
奇排列:逆序对数是奇数
例如,3 1 2 4 5有逆序对,就称之为偶排列。
对换改变排列的奇偶性
即:一个奇排列对换之后会变为偶排列,偶排列对换之后会变为奇排列。
证明: 我们交换,那么对逆序对的影响与,无关。
不妨设,交换之后逆序对会。如果有个数,个数在,个数
交换之前这个区间逆序对的贡献是,交换之后比小的有,比大的有,所以变换的逆序对是,所以对换前后中间的逆序对奇偶性不改变,唯一的差异是多了1.所以对换改变排列的奇偶性。
在n阶排列中,奇偶排列各占一半。
证明:对于每一个奇排列,都能做出一个偶排列,所以偶排列数奇排列数,同理奇排列数偶排列
综上所述奇排列数=偶排列数
任意一个排列可以经过一系列对换变成自然排列,并且所作对换次数奇偶性与排列奇偶性相同。
证明:第一部分等价于证明一个排列可以排序,显然是可以的。
对于第二部分,由于对换的可逆性,我们不妨考虑从自然排列到当前排列的逆过程。
由于自然排列变成奇排列必须有奇数次对换,变成偶排列必须有偶数次对换,所以成立。
行列式
定义其值
其中是个排列。
这就相当于,从行列式中找到所有一行写一个数,一列选一个数的方法,再乘起来。
,其中指的是逆序对个数。
//行列式超慢版cin>>n;for(int a = 1; a <= n; ++a)for(int b = 1; b <= n; ++b)cin>>z[a][b];for(int a 1; a <= n; ++a) y[a] = a;int ans = 0;do{int res = 1;for(int a = 1; a <= n; ++a)res = res * z[a][y[a]];if(jipailie(y)) res = -res;ans += res;}while(next_permutation(y+1, y + n + 1));
引理:行列互换,值不变
互换指的就是这个:
我们来考虑
等价于从每一列选一个数使得行不同
由此,两者应该是等价的。
引理:用数乘行列式某一行等价于用这个数乘此行列式
由于一定会在这行选一数,所以显然。
引理:如果行列式中某一行是两组数之和,则这个行列式等于两个行列式之和,这两个行列式分别以这两组数为该行,而其余各行与原行列式对应各行相同
由于,所以可以这样拆。
证明是一个乘法分配率的形式。
令第i行,中,这样就证完了。
引理:对换行列式两行或两列位置,行列式反号
证明:对换行列式后,排列的奇偶性恰好改变,所以答案从正变负,从负变正
引理:若行列式中两行成比例,结果为0
证明:根据引理2,我们先转化为一个行列式有两行相同。
现在我们交换这两行,值应该变为相反数。但数值不变,所以,值为0.
引理:一行的某个倍数加到另一行,行列式值不变。
例如,
可以用引理3和引理5证明。
余子式
行列式的余子式是D去掉第i行、第j列之后的值。
例如,
代数余子式:
例如,
可以将大小n的行列式变成n个大小的行列式,同理,最后变成个大小是1的余子式。
Cramer法则
该线性方程组的系数行列式为
其值定为
那么定义
则有
例如,
是将第i列替换为最后的
所以,
证明:
引理:若系数行列式不为0,只有0解
显然,因为这代表存在两行系数成比例。
用Cramer法则可以解方程,复杂度
一般系数方程组
该方程不是n行n列的,所以不能用Cramer法则。
方程组的全体解是方程组的解集合,若两个方程组解集合相同就称为同解方程组。
定义线性方程组初等变换:
- 用非零数乘某一个方程
- 将某一个方程k被加到另一个方程上
- 交换两个方程位置
初等变换可以得到一个同解方程组。
定义系数矩阵:
增广矩阵:
将增广矩阵一直消成一个上三角矩阵。
举例:
增广矩阵:
将第二行减去第一行2,第三行减去第一行
同理消下去:
翻译成方程组,
代回,所以,
//gausscin>>n;for(int i = 1; i <= n; ++i)for(int j = 1; j <= n; ++j)cin>>a[i][j];for(int i = 1; i <= n; ++i) cin>>b[n];for(int i = 1; i <= n; ++i) a[i][n + 1] = b[i];//建扩展矩阵for(int i = 1; i <= n; ++i) {int p = i;bool find = false;for(int j = i; j <= n; ++j)if(sign(a[j][i])!=0) { //精度误差!!!for(int k = 1; k <= n + 1; ++k)swap(a[i][k], a[j][k]);find = true;break;} //交换if(!find) gg();for(int j = i + 1; j <= n; ++j) {double ratio = a[j][i] / a[i][i]; //比例for(inr k = 1; k <= n + 1; ++k)a[j][k] = a[j][k] - ratio * a[i][k]; //相减}}for(int i = n; i >= 1; --i) {for(int j = i + 1; j <= n; ++j)a[i][n+1] = a[i][n+1] - x[j] * a[i][j]; //消值x[i] = a[i][n+1] / a[i][i];}
注意这种情况下会炸,所以要交换
当且仅当方程式数量比未知数数量多,会有无解情况。如x=1且x=2
此外,当a非常小的时候ratio会有精度误差,所以我们需要用一种主元高斯消元来优化:
for (int i=1;i<=n;i++){int p=i;for (int j=i;j<=n;j++)if (fabs(a[j][i]) > fabs(a[p][i])) p=j;for (int j=1;j<=n+1;j++)swap(a[p][j],a[i][j]);if (sign(a[i][i]) == 0) gg();for (int j=i+1;j<=n;j++){double ratio = a[j][i] / a[i][i];for (int k=1;k<=n+1;k++)a[j][k] = a[j][k] - ratio*a[i][k];}}
小技巧:
const double eps = 1e-8;int sign(double x) {if(fabs(x) <= EPS) return 0;if(x > 0) return 1;return -1;}
可以判断浮点数正负。
luogu3389 模板题
矩阵
特殊矩阵
0矩阵:都是0
对角矩阵:
单位矩阵:
纯量矩阵:对角线上值一样的对角矩阵
上三角矩阵:
下三角矩阵:
特别的,对角矩阵既是上三角矩阵又是下三角矩阵
对称矩阵:关于对角线对称
反对称矩阵:相对对角线和为0
例如,是对称矩阵,反对称矩阵。
注意,反对称矩阵的对角线一定是0.
矩阵的运算
矩阵相等:所有位置上都相等
矩阵加法:对应位置加起来
矩阵减法:同理
注意两矩阵必须规模一样。
数量乘法:每个位置乘
矩阵乘法:的矩阵和的矩阵乘积是的矩阵
手算方法:求就取出第一个矩阵的第i行和第二个矩阵的第j列,做乘法,再加起来。
//martrix multiplicationcin>>n>>m>>k;for(int i = 1; i <= n; ++i)for(int j = 1; j <= m; ++j)cin>>m1[i][j];for(int i = 1; i <= m; ++i)for(int j = 1; j <= k; ++j)cin>>m2[i][j];for(int i = 1; i <= n; ++i)for(int t = 1; t <= k; ++t)for(int j = 1; j <= m; ++j)m3[i][j] = m3[i][j] + m1[i][t] * m2[t][j];
,0表示0矩阵
结合律
左分配率
右分配率
矩阵乘法交换率不一定成立。
则不一定成立,其成立条件是A可逆。当可逆时,可以两边同乘;否则我们可以构造反例:
矩阵的秩
n个n维向量确定一个n维空间。
对向量a,如果实数使得,那么.具有这样的性质就称a线性无关且维数为m。
可以理解成没有一维退化。
高斯消元的过程可以看做找一个线性无关组的过程。
下面我们定义秩:在一个矩阵中能找到多少组向量线性无关。所以矩阵的秩实质上决定了方程的自由元的个数。
换言之,高斯消元消到最后,有多少行不是0,就说明有多少秩。
逆矩阵
如果为n阶方阵,存在n阶方阵使得
那么称A是可逆的(非奇异的),B是A的逆矩阵;否则A是不可逆的(奇异)。(类似逆元)
定理:如果逆矩阵存在,那么逆矩阵唯一
证明:,在A左边两边同乘,则
记表示将矩阵写成行列式后的行列式值
证明:考虑
这个矩阵的det为
例如
我们构造
从而化为
即
上述矩阵的det是的det
上面的过程中,消去的过程就相当于恰好做了一遍矩阵乘法。
引理:为n阶方阵,使得,则,即,但逆命题不成立。
证明显然。
引理:,即是有逆矩阵的必要条件。
由上面的
证明可以用结合律。
A可逆,则有唯一解
求法:
法I:待定系数法
法II:
其中
T为代数余子式
法III:看下面
矩阵初等变换
- 用非零数乘某一个矩阵
- 将某一个行k倍加到另一行上
- 交换两行位置
将单位矩阵经过一次初等变换得到的矩阵称为初等矩阵。
所以初等矩阵有如下形式:
乘某一行得到的矩阵,该矩阵乘其他矩阵相当于将这个矩阵某一行乘

加上某一行得到的矩阵,该矩阵乘其他矩阵相当于将其他矩阵的某一行加上另一行

交换某一行得到的矩阵,该矩阵乘其他矩阵相当于交换某两行
因此,初等矩阵乘其他矩阵等价于让其他矩阵做初等变换。
初等矩阵可逆
我们一定可以构造出来一个可逆的矩阵。
如果B可以由A经过一系列初等变换得到,则称相抵,记作
相抵具有传递性,即具有等价关系。换言之,
利用初等变换求逆矩阵:
构造表示的矩阵
如果我们能找到一种初等变换过程使得A变成I,那么一系列初等变换的初等变换矩阵乘积就是
考虑高斯消元是将一个矩阵变成了上三角矩阵,代回过程是变成一个对角线矩阵,最后的化简过程是将对角线矩阵变成单位矩阵。
所以高斯消元的全过程相当于求解了一个逆矩阵。
例如:
首先化为
做高斯消元
继续消!
第一行减第三行
再消……
第二行取反,
左边的变成了单位矩阵,所以最后得到右边的矩阵:
这个矩阵就是原来的矩阵的逆矩阵。复杂度
矩阵乘法的应用
系数矩阵:
令
那么
所以
这样我们就可以求了。不过有趣的是,求仍然需要高斯消元。
快速矩阵乘法
,
我们能不能把乘法次数优化到7次呢?这样就可以降低很多复杂度了QwQ
……还真找出来了,暴搜出来的。Strassen算法就是干这个的。
令
于是,,,
有兴趣就去实验吧。。
矩阵求不带权图最短路
如果全BFS一遍,复杂度,现在给出一种做法
定义,u, v在种有边当且仅当中距离
用维护u, v在中距离,则,证明没有听懂。
然后有 或 ,证明没有听懂。
如果我们能递归计算出,问题就解决了。
有这样一条性质:如果 ,v的任意邻居有,证明没有听懂。
对每个u和w,枚举所有和v有关的边,则,证明没有听懂。
然后,然后,我就不知道了。
二维平面旋转问题

旋转到,可以用复数或者极坐标系
或者猜!
,
猜一猜发现,
我们大多写成
称之为旋转矩阵
基尔霍夫矩阵
表示某个点的度数,表示两点间边数的相反数
例如,

这个图的基尔霍夫矩阵是
基尔霍夫矩阵每一行和为0
度数=边数
将每一列加到第一列去,使得第一列变成0.
是一棵树,任意余子式
我们先考察这样一个基尔霍夫矩阵,发现我们一定能找到一种编号方法使得一颗子树恰好对应一个子矩阵。
将左上角的+1,再删除,这样形成的两颗子树会分别对应和。于是我们发现,左边的矩阵的减一恰好对应了生成树的基尔霍夫矩阵。
所以,同理我们会发现,如果将,一定将一个矩阵分成若干个类似的小矩阵。换言之,对于这个余子式而言,我们可以一直递归下去
考虑数归,假设图以1为根。删除根之后,一定能找到一种编号方法使得每个子树编号连续。令,则基尔霍夫矩阵会变成这样的形态:
其中每一个方框指一颗子树。
那么我们发现,删除根节点之后,对于每一个块,左上角会有一个和1的连边,所以成了相同的形态。这样,我们就可以归纳下去。
//然后忘了
是一棵树,给矩阵 加上1之后
上面已经用过了 233
矩阵树定理
给定图G,G的生成树等于其对应的主余子式的绝对值。
主余子式指的是,在主对角线上一个值的余子式。
例如,
写出其基尔霍夫矩阵:
我们随便在主对角线上取一个余子式,比如
求一下,发现答案是4.
完全图的生成树个数是
求法
由于行列式的6条性质,我们可以对行列式做高斯消元,消成上三角矩阵,注意交换次数需要在高斯消元中顺便求出。
此时,行列式的值就是对角线的乘积,因为第一列只能选择第一个数,同理第二列只能选择第二个,......
即:,其中k是高斯消元中的交换次数。
线性基
luogu3832 线性基
从n个数中选出任意个使得异或和最大
我们将每个数看成一个向量,等价于找一个异或意义下线性无关的组合,换言之就是跑一遍高斯消元,得到上三角矩阵。这个上三角矩阵实质上是线性无关的。
好了上面的看不懂也没有关系,我们来整理一种直接插入的做法。
首先从后往前枚举最高位,为啥倒序不需要理解,dalao说否则会有后效性。然后我们如果找到一个没有数的位,就插进去,否则就消一消。
inline void insert(LL x) {for(LL i = 50; i >= 0; --i) {if(x & (1LL << i)) {if(!base[i]) {base[i] = x;break;}else x ^= base[i];}}}
然后输出结果就 暴力倒序枚举取个最大值。
inline LL query() {LL ans = 0;for(LL i = 50; i >= 0; --i) {if(ans < (ans ^ base[i]))ans ^= base[i];}return ans;}
例题完全没听懂,告辞。
数数
核心
不重不漏
推荐
《具体数学》
《组合数学》 Richard
oeis.org
sample
5男人6女人2男孩4女孩选1男人1女人1男孩1女孩的方案:
0~9排列数:;首位不为0:或
若有理数是无限小数,则必然是无限循环小数:考虑列竖式,那么余数一定是,但是由于有无限位,所以一定会出现循环节.
10000以内不能被4、5、6任意一个数整除的自然数:
a-f按顺序入栈,但随时可以出栈,形成的出栈序列数量:
分类计数原理和分布计数原理
将问题空间分为不同子空间,并且其并集是整个问题空间,可以加起来
问题有不同阶段,然后乘起来
抽屉原理
有n个笼子,有n+1个鸽子,那么一定有至少1个笼子里有两只鸽子
拓展:Ramsey定理
排列
n个元素的排列数,特别的,
圆排列:把n个元素排成环,那么每种排列都会重复n次,所以总方案数是
错位排列:n个人每个人写了封信,送别人,不拿到自己的信的方案数
,我们不妨分一下类,那么第n个人有种拿法。假定他拿了第号信,如果第个人拿了第封信,那么就相当于是一个的错排;否则,我们相当于对第个人加了一条限制不能拿n,和是一样的。

多重集全排列:例如,11222的排列有
我们不妨先将相同的东西看成不一样的,那么就有种。但是我们实质上将11看成不一样多算了,222看成不一样多算了
组合数
一个大小n的集合,选m个集合的方案数是,也记作
其中,可以理解成让选的部分和不选的部分都不重复。
插板法:
n个相同的球,m个不同的盒子
等价于
每个盒子至少一个球:即,等价于在个空里插个板,即
盒子可以为空:
每个盒子至少两个球:
捆绑法:BZOJ2729 n男m女2老师,老师老师不相邻,女生女生不相邻
,但这样有重,会缺少两个女生在一起,老师插进去的情况。
所以我们考虑捆绑,即先把老师当成男生,然后再减去两个老师捆绑的数量,即
二项式定理:
NOIP2011D2t1
组合数的计算
求
:利用组合数递推,
且p为素数:暴力求,不过需要求逆元
且p非素数
不互素,所以不能用逆元。令,,假定,如果我们能求出每一部分的值,最后我们可以用CRT合并起来。
我们可以将,此时约去之后就可以跑逆元了,。
由于数据范围比较小,所以我们可以暴力!
下面这个用来求出来所有质数p的因数数量。
int count_baoli(int n){int cnt = 0;for(int i=1;i<=n;i++){int t=i;while(t%p == 0) cnt++,t/=p;}return cnt;}
下面这个则用来求和p没有关系的东西。
int count2_baoli(int n){int s = 1;for(int i=1;i<=n;i++){int t=i;while(t%p == 0) t/=p;s=s*t%p;}return s;}
:
将上面的方法继续优化。现在的关键就在于如何求出和。
找个规律看看?比如,1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
取出3的倍数:3 6 9 12 15,除以3:1 2 3 4 5……成了一个新的整数序列。
于是我们就可以递归了。
int count1(int n) {if(n > 0) return n / p + count(n / p);return 0;}
那怎么求呢?我们将这个数列分成一堆长度为p的块,那么我们先暴力一个,然后就有个块存在贡献。至于除了块意以外部分我们就可以暴力来求啦。
int count2(int n){if(n>0){int s = 1;int s2 = 1;for(int i=1;i<p;i++) s2=s2*i%pk; //s2是(p-1)!在p^k下的值if(n/p>0 ) s = s *pow(s2,n/p,pk)%pk ; //每块暴力求值s = s*count2(n/p)%pk; // 递归n%=p;for(int i=1;i<=n;i++){s = s*i%pk; //剩下的部分的暴力求值}return s;}return 1;}
,p为素数
卢卡斯定理:
例题
tyvj1298 分苹果
,是当成有区别的,但是这样和顺序是有关系的,还要除6.
不过对于x00这种情况,有三种,是有些独特的就先减去3种,而这3种情况下只算一种,所以最后+1。而xx0,三个袋子也是不一样的,所以无需忌惮。
除2怎么办?把mod p变成mod 2p,然后最后偶数就不会被模掉。
卡特兰数
要对1、1、2、5、14、42、132敏感!

相当于从起点到终点的非降路径,即不越线的路径

如果在某个位置接触这条线,我们以这条棕色线为对称轴对称下面的部分。这样,这个方案数就合法了。所以,这样的方案实质上对应了去终点的。所以总方法数:
->合法括号序列数、进站次序、n节点二叉树数量、n+1边形三角剖分数都是卡特兰数。
斯特林数
第二类斯特林数
n个数的集合划分为k个非空集合的方法的数目,如表示3个数划分到两个集合.
前者表示第n个数放到了一个新的盒子里,只有一种方案;否则放在一个有球的盒子里,会有k种选择。
如果划分到k个可区分的盒子里,则有
第一类斯特林数
n个不同元素排成k个非空环排列的方法数
这里是加到一个环里面,所以有个位置可以插入
划分数
不能隔板,否则会重。
n划分为k个正整数之和的划分数
dp[i][j]表示和为i数值个数是j

最小值,我们去掉最小值,转移到
最小值,我们把所有的都-1,即

n划分若干正整数之和的划分数
将上面的图转过来,问题化为最大值是k的方案数
然后这个方案数也是一样的东西,所以答案是
n划分为最大数不超过k的划分数
n划分为若干奇正整数之和划分数
n划分若干不同整数之和的划分数
其实我已经理解不了了。
平衡
枚举k,枚举左右之和,变成了一个数的划分。
群
群
一堆元素、一个运算、满足封闭性(不超过这个集合),结合律,幺元存在唯一(),逆元存在唯一
置换群
置换是一种从到的一一映射,以达成一种重构。例如,的一个置换是,相当于按照这个顺序重构了一下原来的排列。
我们可以把一个置换群想象成一个有个点的无向图,在经过一系列变换置之后回到了出发点,就成了一个环。
如果一个状态在置换之后不发生改变,那个这个状态是置换的不动点。
置换乘积
相当于复合函数
特别的,在置换群中幺元是1234到1234的置换,逆元是按照第一列逆过来sort。
Burnside引理
是不是发现一点都不神奇……而是看不懂……
我们一点一点来,的含义是等价类的方案数。那什么叫做等价类呢?就是满足等价关系的方案数。那什么是等价关系呢?就是题上告你的xxx算一种。
比如说,一个经典的栗子:对一个的正方形格格染色,如果旋转之后长相一样的,问有多少种。

那么就会有一些很愉悦的东西。
先设四个点的标号是1,2,3,4
如果不操作什么都不改变的群有哪些?16个图各自成一个置换群。
这个群是这样的:
如果顺时针旋转呢?(1)(2)(3 4 5 6)(7 10 8 9) (11 12)(16 15 14 13)
群则是这样:
如果旋转呢?(1)(2)(3 5)(4 6)(7 9)(8 10)(11)(12)(13 15)(14 16)
如果逆时针旋转呢?(1)(2)(6 5 4 3)(9 8 10 7) (11 12)(13 14 15 16)
一共有四种操作,我们就说这玩意是四种置换群。换句话说,就是规定了四种映射,把一个东西变成另一个东西。
找一找不动点,我们给出一个符号,表示f的不动点数目。上面的四种操作不动点数目就是单个括号的,分别是16、2、2、4
Burnside引理的意思就是,答案是所有映射的不动点数目的平均值,也就是6.
Polya定理
好了,现在的问题是怎样求出来有多少不动点,这就是Polya定理做的事情。
如果一个置换群有m个循环,那么不动点数目是,其中k是颜色数。
什么是循环?考察
从1走路,到4去,4要到3去,3要到2去,2要到1去,回来了,这就是一个循环。
1到3去,3到1去,所以有2个循环。
换言之我们可以理解成一直走路,直到走回来,有多少个圈。
于是,循环数分别是4、1、2、1,所以答案就是
将一个正方形的四个顶点染色,有多少种本质不同的染法?旋转和对称同构算一种。
多建四个,发现答案是6.
给六个珍珠串成的项链染三种色,有多少种本质不同的染法?
数不出来了。。
生成函数
泰勒展开
把某一个函数展开成一个无限的多项式
我们不关心收敛,只关心在某个数值的时候可以写成某个形式。
广义牛顿二项式定理
我们发现可以用复杂的东西表达简单的东西。
形式幂级数
常见生成函数
1,1,1,1...
1,0,0,...,1,0,...
1,2,3,...
1,2,4,8,...
C(n,0),C(n,1),...,C(n,n)
运算
可以解递推式
例如,
带入
指数型生成函数
从而我们让
这样在计算排列的时候是有优势的,因为
两个生成函数相乘是
化简得到
求n位数数量使得各个数都是奇数且1、3出现偶数次
:各个数字是奇数,1、3出现偶数次
:各个数字是奇数,1奇数3偶数
:各个数字是奇数,1、3出现奇数次
转移:,,
然后可以求生成函数(没听懂 QAQ)
算两次算法
一个完全图,有一些红边,一些蓝边,问你有多少红色红色三角形。
对于一个角,我们考虑:只能是红红/红蓝/蓝蓝.算角是,其中同色是,n是点数,是蓝色个数
对于一个三角形,可以是同色三角形,可以是异色三角形,并且后者必定是红红蓝/蓝蓝红,a是同色角个数,b是异色角个数,x是同色三角形数,y是异色三角形数。
所以
刚刚上大学的洁洁在学习组合数学的过程中遇到一道麻烦的题目,她希望你能帮助她解决。给定一张无向完全图G,其中大部分边被染成蓝色,但也有一些边被染成红色或者绿色。现在,洁洁需要给这张图的多样性进行打分。一张图的多样性取决于它的同色和异色三角形的个数。具体来说,G中每有一个三边颜色不同的三角形可以得3分,每有一个三边颜色相同的三角形则要被扣掉6分,其它三角形不得分也不扣分。
现在,请你写一个程序来计算G的多样性分数。

上面的分别对应六种角,STL对应三种情况的三角形,从而有
,其中x和y分别指同色角和异色角个数,最后题目求得恰好是
有一完全图,边是红或蓝,有这样的可能性:
1. 红,蓝
2. 一边红,其他蓝,红概率,
3. 一边蓝,其他红,蓝概率,
输入n和可能情况,求期望红色个数
表示e是红色这个时间是否发生,那么以u为顶点的同色角个数为
然后就可以抄题解了。
本题考查概率期望和数三角形的知识。
注意到,在普通算同色三角形问题中,我们只需要计算同色角和异色角的个数。
在这里,我们只需要计算同色角和异色角的期望个数。
值得注意的一点是,在这题里,边的存在性不是独立的。对于一个顶点连出去的同一组边,我们要单独考虑。
由于需要线性时间完成,所以我们需要使用懒惰更新的计数方法,每次计算每一组对每一个顶点的同色角和异色角期望的贡献。
本题细节较多,需要仔细推导和检查。
嗯?这说了啥?别问我啊。
简单的多项式乘法
//这里记录FFT的可能性不大,仅讨论一种分治做法。
多项式的卷积
如果,
则
我们将记为卷积。复杂度
分治法加速
不妨设,,,分成这两部分。
那么我们发现,
于是,我们令,,
所以我们可以得到,
其复杂度:,由主定理可知复杂度
嗯,基本上就够联赛用了。常数小,并且复杂度也足够优秀。
D6测试
T3
然后就可以数论分块了。
用龟速乘会T,所以可以跑费马求逆元。注意先取模。
#include <bits/stdc++.h>using namespace std;#define LL long longLL ny;inline LL msmul(LL a, LL b, LL p) {LL ans = 0;while(b) {if(b & 1) ans = (ans + a) % p;a = (a + a) % p;b >>= 1;}return ans;}inline LL ksm(LL a, LL b, LL p) {LL ans = 1;while(b) {if(b & 1) ans = (ans * a) % p;a = (a * a) % p;b >>= 1;}return ans;}inline LL getsum(LL l, LL r, LL p) {l %= p, r %= p;LL x = (((r * (r + 1)) % p * (2 * r + 1)) % p * ny) % p;LL y = (((l * (l - 1)) % p * (2 * l - 1)) % p * ny) % p;return (x - y + p) % p;}int main() {LL n, p, ans = 0;cin>>n>>p;ny = ksm(6, p - 2, p);for(LL i = 1, j; i <= n; i = j + 1) {j = n / (n / i);ans = (ans + getsum(i, j, p) * (n / i) % p) % p;//cout<<ans<<endl;}cout<<ans<<endl;}
T2
没看到p是素数QAQ所以实质上跑一遍膜p-1的快速幂就行了
不过对于非素数的情况,实际上有扩展欧拉定理:
#include <iostream>#include <cstdio>#include <algorithm>#include <cmath>using namespace std;#define LL long longinline LL getphi(LL x) {LL m = x;for(LL i = 2; i * i <= x; ++i) {if(x % i == 0) {m = m / i* (i - 1);while(x % i == 0) x /= i;}}if(x != 1) m = m / x * (x - 1);return m;}inline LL msmul(LL a, LL b, LL p) {LL ans = 0;while(b) {if(b & 1) ans = (ans + a) % p;a = (a + a) % p;b >>= 1;}return ans;}inline LL ksm(LL a, LL b, LL p) {LL ans = 1;while(b) {if(b & 1) ans = msmul(ans, a, p);a = msmul(a, a, p);b >>= 1;}return ans;}inline bool issmall(LL b, LL c, LL p) {if(b == 1) return true;LL k = (int)(1.0 * log(p) / log(b));return c <= k;}inline LL gcd(LL a, LL b) {return b ? gcd(b, a % b) : a ;}int main() {LL a, b, c, p;cin>>a>>b>>c>>p;LL mm = getphi(p);LL mi;if(gcd(a, p) == 1) mi = ksm(b, c, mm);else if(issmall(b, c, p)) mi = ksm(b, c, p);else mi = ksm(b, c, mm) + mm;LL ans = ksm(a, mi, p);cout<<ans<<endl;return 0;}
T1
先变成一个K进制数。如果存在一个周期,那么肯定不满足。比如K = 10, N = 4,那么1212这个数存在一个周期,那么由于这个东西会循环的滚动,所以一定会有一个更大的存在。
如果一个数是非周期的,我们可以循环左移。结论:只有字典序最小的会满足该性质。这实际上等价于保证字典序小于任意一个后缀,于是保证最后算下来使得小数也递增。这样的循环同构有n组,所以是非周期数/n.
既然这样就很好搞了,我们需要的就是求出来n位的不存在周期的数,然后/n,就是结果。那怎么求呢,DP一下.
我们让表示有i位的不存在周期的整数,首先这样的整数应该有个。如果存在循环节,就意味着表示了以d为循环节的n位数个数。
所以
其实等价于n个珠子的项链,k染色,旋转同构的方案数(OEISA074650)。不过群论看上去复杂度挺大?所以老老实实写DP吧。
#include <bits/stdc++.h>using namespace std;#define LL long longLL n, k, p;vector<int> v;LL dp[100003];inline LL ksm(LL a, LL b, LL p) {LL ans = 1;while(b) {if(b & 1) ans = (ans * a) % p;a = (a * a) % p;b >>= 1;}return ans;}inline LL fj(LL x) {for(int i = 1; i * i <= x; ++i) {if(x % i == 0) {v.push_back(i);if(i * i != x) v.push_back(x / i);}}}int main() {p = (int)(1E9+7);cin>>n>>k;fj(n);sort(v.begin(), v.end());dp[0] = k;for(int i = 0; i < v.size(); ++i) {dp[i] = ksm(k, v[i], p);for(int j = 0; j < i; ++j)if(v[i] % v[j] == 0)dp[i] = (dp[i] + p - dp[j]) % p;}cout<<(dp[v.size() - 1] * ksm(n, p - 2, p)) % p<<endl;}
windows快捷键
alt+f4 关闭当前窗口
win+tab 多桌面(win10限定)
win+方向键 窗口化放到左右两侧或最大化、最小化
win+E 我的电脑
win+D 全部最小化
win+L 到账户登录界面,防止被发qq
win+R 运行,如calc 计算器 mspaint 画图 notepad 记事本 win7以前可以用winmine开扫雷
Ctrl+Alt+A 有QQ截图
PrtSc 截图
win+num 切换到级别为num的窗口
Alt和Ctrl中间的那个键是右键,右键+W+F就行
找文件的时候直接输入文件名就可以,比如

按d可以到devcpp.exe,按两次就变到下一个了qwq
gdb
配置环境变量
桌面->计算机->属性->高级系统配置->环境变量,如果没有PATH变量就新建。打开DEVcpp安装文件夹,打开MinGW64,进入bin,把地址栏上的东西复制到path里。
编译
在任意路径建立一个名字叫a.cpp的文件,写一个A+Bproblem,代码如下:
#include <cstdio>#include <cstdlib>#include <cstring>using namespace std;int main() {int a, b;scanf("%d%d", &a, &b);printf("%d\n", a + b);return 0;}
注意一定要随时保存!
然后关闭它。
点一下地址栏,写CMD三个字母,出现一个黑框框。
输入g++,并按回车。如果出现g++:fatal error...说明编译成功。
输入g++ a.cpp -o a.exe -g -Wall -Wextra -Wconversion && size a.exe
出现界面如图:
a.cpp -o a.exe 把a.cpp编译为a.exe
-g:允许使用gdb调试
后面的三个:表示输出警告信息
size a.exe:输出空间,比如开个很大的数组之后会变成
想要计算,将bass的数据/1024/1024就是空间
调试
输入gdb a.exe,进入如下界面:

r 运行程序
l 查看程序
b main 在main函数设置断点
s 下一步
finish 执行完当前函数之后退出
n 执行下一行
p 查看变量
display x 将x加入常视变量
q 退出gdb
b 13 if (a == 123) 在13行设置断点,当且仅当a=123生效
入门困难
