@LittleRewriter
2017-10-08T03:31:04.000000Z
字数 68885
阅读 1457
国庆集训整合
整合
D1讲题
T1
远超NOIPT1
30:枚举l,r
两重for,将区间扫一遍
60:思考这一做法
右端点每次向右移动一个位置
因此每一个字符都可以预处理前缀和
这样可以拿到60分
70:上述做法需要次
由于对某一字符对另25个字符没有必要枚举
可以优化一下(并没有听懂
90:考虑假设字符串s,希望算得[L,R]的权值
这就相当于统计字符的频次
对每一个字符记录一个前缀和
则quanzhi[l][r]为sum[k][r]-sum[k][l-1]-sum[j][r]+sum[j][l-1]
若枚举R,我们希望找到L使得结果最大
就可以让sum[k][l-1]-sum[j][l-1]
这里可以再找一个前缀最小值维护
即sum[k][j][x]表示前x个sum[k][x]-sum[j][x]
复杂度O(n*26*26)
100:同70,O(n*26)
T2
计算几何野鸡题
46:输出Yes
54:输出No
玄学:rand()YesNo
能互相看到有两种情况:
1)直接看到
2)反射一下看到
直接看到的情况:是否有墙或镜子挡住
判断线段是否直接相交
过镜子的情况:是否存在和墙相交的情况
即做出虚像,判断线段相交
那么如何处理:
(1)算出反射光线的办法
将第一个人对称连接即可
(2)算对称点的坐标
解几算出垂线方程
用这条线算出与镜子的交点
用中点坐标公式解出另一个点坐标
(3)对直线x=k与直线y=k的情况的处理
用一般式回避
(4)判断相交
法1:直接叉乘,不相同则相交
法2:
若平行则不相交
否则,用交点判断是否在线段上即可
NOIP出数学题不超高中范围
存实数一定要用double
T3
20:随机
30:输出5
奇怪的BFS
判断联通:看做36个点的图,相邻连边
并查集维护
读入可以读入字符串规避影响
搜索的奇技淫巧
搜索的基本形式
DFS:一棵树
BFS:扩散
-1 搜索使用的条件与范围
例如T2:枚举角度
最优解问题
可行解问题
解数量问题
0 DFS与BFS的判断
BFS:
一个状态到另一个状态的最小步数
状态可压缩且内存可保证或无需判重(sizeof(队列)=元素数*大小,内存开销大)
状态层数不会太深
DFS:
不能使用BFS的情况
一般来说上述三个条件满足那么BFS优于DFS
1 状态表示与判重
希望一个状态只被搜一次,因此需要判重
将一个状态表示出来:
如T3:
1)用3*3*4的数组表示一个状态
2)用3*3的数组表示一个状态,因为每一个方格的颜色不变,记录每个方格的位置即可
3)一个九位数int表示
因此用尽量简单的方式表示状态是思考主要方向
判重:
1)bool数组,前提的内存足够,如今天T3会有的大小
2)set判重,较慢但省空间,O(logn)
#include <set>using namespace std;set<int> s;int a;s.insert(a);//加入if(s.count(a)) /*...*///判断a出现次数,为1即存在//s.erase(a);
对于难以压缩的状态:
struct rec{int map[4][4];};//必须,否则会报错bool operator<(const rec &x,const rec&y){for(int a=0;a<4;++a){for(int b=0;b<4;++b){if(x.map[a][b]!=y.map[a][b])return x.map[a][b]<y.map[a][b];}}return false;}set<rec> s;s.insert(a);
//&的用法int gg(int x,int y) /*..*/将x,y拷贝一份进行运算int gg(int &x,int &y) /*..*/直接引用地址int gg(const int &x,const int &y) /*..*/保证x,y不变
2 通用剪枝方法
具体问题:
最优解:超过当前解则break;
尤其是DFS应用多
可行解:无通法
解数量:记忆化搜索,记录某一状态的答案
通用方法:
排除不可能的分支
走玄学意义上更好的分支
随机化:防止丧病出题人出恶意数据卡某一搜索顺序
(eg:靶形数独)
因此建议搜索绝对不要正着按顺序搜索
//random_shuffle可以生成一个随机排列#include <algorithm>for(int i=1;i<=6;++i) z[i]=i;random_shuffle(z+1,z+7);
建议开了dev-cpp的取消自动补全某些头文件功能
3 卡时
最优解问题
将=0变成>=0
1s建议设置到0.85s
#include <ctime>void dfs(){if(1000*(clock()-t)>=850*CLOCKS_PER_SECOND){//这玩意表示一秒有多少时间单元printf("%d",&ans);exit(0);//退出整个程序}}int t=clock();//单位为时钟单元
还可以卡评测机
4 双向BFS(Meet int the middle)
如果考到搜索约有10%概率会考
假设每一状态有三个状态
正常状态为,约有个状态
如果从终点也拓展状态,有,约有个状态
相当于个状态
使用的条件:
1)知道终止状态
2)可以从终止状态向前回推
3)终止状态逆转移状态与顺转移状态同阶
5 A*搜索
基本思想
以最短路为例
定义c为最优代价,表示长度
函数f(s)表示从起点走到s的最短路,g(s)表示s到终点的最短路
则c=min{f(s)+g(s)}
但是我们的搜索是顺着搜,因此我们只能确定f(s)
我们就猜测g(s)的值,用估价函数h(s)表示
会出现3种:
h(s)=g(s),达到最高效率,求出最优解
h(s)>c',直接剪枝,此时可能会剪掉)
h(s)>g(s),比较慢,但保证能搜出
本质:搜索顺序的改变
用优先队列维护拓展状态,每次取出f(s)+h(s)最小的状态
结合卡时效果更佳
举例:八数码问题
h(s):曼哈顿距离之和
6 分支界定
按某种权值
用priority_queue维护取出最优解
结合卡时以提高输出正解的概率
玄学优化,例如T3以连通块个数为权值
7 迭代加深搜索
如果真的考到可以尝试现场yy
出题人卡BFS内存不得不使用DFS
那么限定搜索深度
例如求最短路,搜10->有解,搜9->有解,...,搜4—>无解
则深度为5,即最短路为5
可以二分深度或者枚举深度
->推荐使用枚举:状态数是指数级增长的,因此枚举代价最大的是新拓展的一层,二分反而耗时
例题
八数码
八皇后
靶形数独(Luogu1074)
玄学优化:
正搜70-80
倒着搜95
倒着按列搜100
正常优化:
1)从里往外搜,优先填大数,加一个卡时可A
2)从可能性少的格子开始搜索
Mayan游戏(Luogu1312)
最小步数->BFS,不能双向
问题在于状态压缩,只能记录整张map
这样一个状态要5*7数组,每次移动最坏有35*2个分支
显然tan
可以开结构体扔set判重,不过开销也很大
所以我们用DFS解决
但DFS的问题在于,可能某一步无解,可能需要很深
这里我们可以采用迭代加深的方法优化
此外:
1)最优解优化
2)左换右=右换左,搜索量减半
Flowfree
直接暴搜比较慢
1,从外圈开始搜可以优化,一圈一圈往里搜
2,优先搜曼哈顿距离小的
3,如果某一路径将图分为两半,且在路径两侧有点存在,那么就会减去
这里我们可以每走几步BFS一次求出是否相交
D2讲题
T1
60分:打表
100分:
如果强行假定a<=b<=c,那么这一答案就是这样的。
由于,可以大量减少枚举次数。
而
由于,所以,直接加上即可
for(int a=1;a*a*a<=n;++a)for(int b=a;b*b<=n/a;++b)ans+=n/a/b-b;
复杂度
问题是如果一样,那么:
三个数都一样,枚举一下;
两个数都一样,不妨假设b=c
从而枚举b的值,可以枚举出来
将这两种情况剪掉即可
可以用这个自适应win/linux输出longlong:
#ifdef WIN32#define LL "%I64d"#else#define LL "%lld"#endif/.../printf("LL",a);
标程:
#include<cstdio>#include<cstdlib>#include<cstring>using namespace std;long long n;#ifdef unix#define LL "%lld"#else#define LL "%I64d"#endif//64位都可以int main(){freopen("a.in","r",stdin);freopen("a.out","w",stdout);scanf(LL,&n);long long ans=0,tmp=0;for (long long a=1,v;a*a<=(v=n/a);a++,ans++)for (long long b=a+1;b*b<=v;b++)tmp+=n/(a*b)-b;ans+=tmp*6;tmp=0;for (long long a=1,v;(v=a*a)<=n;a++){tmp+=n/v;if (a*a<=n/a) tmp--;}ans+=tmp*3;printf(LL "\n",ans);return 0;}
T3
30分:
对每一个值都可以算出来加成
这是可以优先考虑贡献小的搜
提高搜到最优解的速度
100分:
由于“昨天考过的今天都不考”
所以这是一道DP题
我们需要考虑卡包和卡包的距离与玄学值和玄学值的距离(例如,影响5的只有4,5,6 3个值)
设计状态:这样的九维状态
表示1-i的所有玄学值已经考虑过之后的结果,使用了这些玄学值即每一个卡包用了多少玄学值。由于只能有最多5个所以这几个值都<=5
接下来的代表第p包卡中有无玄学值i,两维
f[30][5][5][5][5][2][2][2][2]空间复杂度300000
这里枚举来确定加成。由于最后四维状态确定了有无i,算一下就行了(并不
嗯,标程,请感受一下来自dp的恶意:
#include<cstdio>#include<cstdlib>#include<cstring>#include<algorithm>using namespace std;#define now pre[a][b][c][d][e][s1][s2][s3][s4]#define dis(a,b,c,d) (abs(a-c)+abs(b-d))const int INF=0x3f3f3f3f;int A,B,C,D,E,num[10][10],value[10][10][10],delta[10][10][40],dp[31][6][6][6][6][2][2][2][2];char s[500];bool map[6][6][6][6];int main(){freopen("c.in","r",stdin);freopen("c.out","w",stdout);scanf("%d%d%d%d%d",&A,&B,&C,&D,&E);for (int a=0;a<6;a++){scanf("%s",s);int p=0;for (int b=0;b<6;b++){int px=p;while (s[px]!=']')px++;p++;num[a][b]=s[p]-'0';p++;p++;for (int c=1;c<=num[a][b];c++){int v=0;while (s[p]>='0' && s[p]<='9'){v=v*10+s[p]-'0';p++;}value[a][b][c]=v;p++;}p=px+1;}}int base=0;for (int a=0;a<6;a++)for (int b=0;b<6;b++)if (a>=2 && a<=3 && b>=2 && b<=3) ;else{sort(value[a][b]+1,value[a][b]+num[a][b]+1);for (int c=2;c<=num[a][b];c++)if (value[a][b][c]-value[a][b][c-1]==1) base+=A;for (int c=2;c<=3;c++)for (int d=2;d<=3;d++){if (dis(a,b,c,d)==1){for (int e=1;e<=num[a][b];e++){delta[c][d][value[a][b][e]]+=B;delta[c][d][value[a][b][e]-1]+=C;delta[c][d][value[a][b][e]+1]+=C;}}if (dis(a,b,c,d)==2){for (int e=1;e<=num[a][b];e++){delta[c][d][value[a][b][e]]+=D;delta[c][d][value[a][b][e]-1]+=E;delta[c][d][value[a][b][e]+1]+=E;}}}for (int c=0;c<6;c++)for (int d=0;d<6;d++)if (dis(a,b,c,d)<=2 && (c!=a || d!=b) && !map[a][b][c][d]){map[a][b][c][d]=map[c][d][a][b]=true;if (c>=2 && c<=3 && d>=2 && d<=3) ;else{int dist=dis(a,b,c,d);for (int e=1;e<=num[a][b];e++)for (int f=1;f<=num[c][d];f++){if (abs(value[a][b][e]-value[c][d][f])==0){if (dist==1) base+=B;else base+=D;}if (abs(value[a][b][e]-value[c][d][f])==1){if (dist==1) base+=C;else base+=E;}}}}}memset(dp,0x3f,sizeof(dp));dp[0][0][0][0][0][0][0][0][0]=base;for (int a=0;a<30;a++)for (int b=0;b<=num[2][2];b++)for (int c=0;c<=num[2][3];c++)for (int d=0;d<=num[3][2];d++)for (int e=0;e<=num[3][3];e++)for (int s1=0;s1<=1;s1++)for (int s2=0;s2<=1;s2++)for (int s3=0;s3<=1;s3++)for (int s4=0;s4<=1;s4++)if (dp[a][b][c][d][e][s1][s2][s3][s4]!=INF){int v=dp[a][b][c][d][e][s1][s2][s3][s4];for (int sx1=0;sx1<=(b!=num[2][2]);sx1++)for (int sx2=0;sx2<=(c!=num[2][3]);sx2++)for (int sx3=0;sx3<=(d!=num[3][2]);sx3++)for (int sx4=0;sx4<=(e!=num[3][3]);sx4++){int wmt=0;if (sx1){wmt+=delta[2][2][a+1];if (s1) wmt+=A;if (s2) wmt+=C;if (s3) wmt+=C;if (s4) wmt+=E;}if (sx2){wmt+=delta[2][3][a+1];if (s1) wmt+=C;if (s2) wmt+=A;if (s3) wmt+=E;if (s4) wmt+=C;}if (sx3){wmt+=delta[3][2][a+1];if (s1) wmt+=C;if (s2) wmt+=E;if (s3) wmt+=A;if (s4) wmt+=C;}if (sx4){wmt+=delta[3][3][a+1];if (s1) wmt+=E;if (s2) wmt+=C;if (s3) wmt+=C;if (s4) wmt+=A;}if (sx1 && sx2) wmt+=B;if (sx1 && sx3) wmt+=B;if (sx1 && sx4) wmt+=D;if (sx2 && sx3) wmt+=D;if (sx2 && sx4) wmt+=B;if (sx3 && sx4) wmt+=B;int &t=dp[a+1][b+sx1][c+sx2][d+sx3][e+sx4][sx1][sx2][sx3][sx4];if (t>v+wmt) t=v+wmt;}}int ans=INF;for (int a=0;a<=1;a++)for (int b=0;b<=1;b++)for (int c=0;c<=1;c++)for (int d=0;d<=1;d++)ans=min(ans,dp[30][num[2][2]][num[2][3]][num[3][2]][num[3][3]][a][b][c][d]);printf("%d\n",ans);return 0;}
T2
最优策略:朝着对面走先抢
因此有三个阶段:
1)遇上
2)轮流从大到小抢子树
3)遍历子树
因此1)是一大难点,采用倍增求LCA
假设两点距离为l,若l为偶数则走l/2,否则走
一定有一个人始终向上走,一个人某一阶段以后从上往下走,算出到LCA的距离即可。
标程:
#include<cstdio>#include<cstdlib>#include<cstring>#include<algorithm>using namespace std;const int maxn=100010;int n,m,en,z[maxn*3],f[maxn][20],q[maxn],depth[maxn],sum[maxn*3][2],fd[maxn],start[maxn],end[maxn],value[maxn];struct edge{int e,d;edge *next;}*v[maxn],ed[maxn<<1];void add_edge(int s,int e,int d){en++;ed[en].next=v[s];v[s]=ed+en;v[s]->e=e;v[s]->d=d;}int get(int p,int d){if (d==-1) return p;int x=0;while (d){if (d&1) p=f[p][x];d>>=1;x++;}return p;}int get_lca(int p1,int p2){if (depth[p1]<depth[p2]) swap(p1,p2);p1=get(p1,depth[p1]-depth[p2]);int x=0;while (p1!=p2){if (!x || f[p1][x]!=f[p2][x]){p1=f[p1][x];p2=f[p2][x];x++;}else x--;}return p1;}int calc(int p1,int p2){if (p1==f[p2][0]) return value[1]-value[p2];else return value[p1]+fd[p1];}int calcp(int p,int v){int l=start[p]-1,r=end[p];while (l+1!=r){int m=(l+r)>>1;if (v>z[m]) l=m;else r=m;}return r;}int main(){freopen("b.in","r",stdin);freopen("b.out","w",stdout);scanf("%d%d",&n,&m);int tot=0;for (int a=1;a<n;a++){int s,e,d;scanf("%d%d%d",&s,&e,&d);tot+=d;add_edge(s,e,d);add_edge(e,s,d);}depth[1]=1;int front=1,tail=1;q[1]=1;for (;front<=tail;){int now=q[front++];for (edge *e=v[now];e;e=e->next)if (!depth[e->e]){depth[e->e]=depth[now]+1;fd[e->e]=e->d;f[e->e][0]=now;int p=now,x=0;while (f[p][x]){f[e->e][x+1]=f[p][x];p=f[p][x];x++;}q[++tail]=e->e;}}int cnt=0;for (int a=n;a>=1;a--){int now=q[a];start[now]=cnt+1;for (edge *e=v[now];e;e=e->next)if (depth[e->e]==depth[now]+1){z[++cnt]=value[e->e]+e->d;value[now]+=value[e->e]+e->d;}z[++cnt]=tot-value[now];end[now]=cnt;sort(z+start[now],z+end[now]+1);sum[end[now]][0]=z[end[now]];sum[end[now]][1]=0;for (int a=end[now]-1;a>=start[now];a--){sum[a][0]=sum[a+1][0];sum[a][1]=sum[a+1][1];if ((a&1)==(end[now]&1)) sum[a][0]+=z[a];else sum[a][1]+=z[a];}cnt++;}for (int a=1;a<=m;a++){int p1,p2;scanf("%d%d",&p1,&p2);int lca=get_lca(p1,p2);int dist=depth[p1]+depth[p2]-2*depth[lca];int delta=dist/2+(dist&1);int px,px1,px2;if (depth[p1]-depth[lca]<delta) px=get(p2,dist-delta);else px=get(p1,delta);if (depth[p1]-depth[lca]<delta-1) px1=get(p2,dist-delta+1);else px1=get(p1,delta-1);if (depth[p2]-depth[lca]<dist-delta-1) px2=get(p1,delta+1);else px2=get(p2,dist-delta-1);int ans=0;if (p1==px){if (p2==px) ans=sum[start[px]][0];else{int v2=calc(px2,px);int p=calcp(px,v2);ans=sum[p+1][0]+sum[start[px]][1]-sum[p][1];}}else{if (p2==px){int v1=calc(px1,px);int p=calcp(px,v1);ans=v1+sum[p+1][1]+sum[start[px]][0]-sum[p][0];}else{int v1=calc(px1,px);int pp1=calcp(px,v1);int v2=calc(px2,px);int pp2=calcp(px,v2);if (pp2==pp1) pp2++;if (pp1>pp2) swap(pp1,pp2);ans=v1+sum[pp2+1][dist&1]+sum[pp1+1][1-(dist&1)]-sum[pp2][1-(dist&1)]+sum[start[px]][dist&1]-sum[pp1][dist&1];}}printf("%d\n",ans);}return 0;}
数据结构
标签(空格分隔): 未分类
考点
基础:
- 数组,链表
- 队列,栈
- 堆(priority_queue)
- 并查集
略复杂的:
- 树状数组/线段树二选一
《not only success 线段树完全版》
hdu炸了,请上http://acm.split.hdu.edu.cn/
- 树(存树)
- 树上LCA
- DFS序列、括号序列
更复杂的:
- 启发式合并
- 单调队列
- 前缀和
- 二分
- 分治
不需要掌握的
点分治分块莫队主席树平衡树
倍增LCA
找到最深的祖先
开一个数组f[i][j]
表示从i走步可以到达祖先
从而使枚举达到log级别
DFS序列与括号序列
并不是所有结构都可以表示成线段的结构,比如一棵树,并不能用线段树直接维护。这两个序列可以将树上问题转换为线性的,从而用线性数据结构维护。
DFS序列(类似前序遍历)
我们使用dfs序列将一棵树排成一个序列。
对树进行dfs,如图1
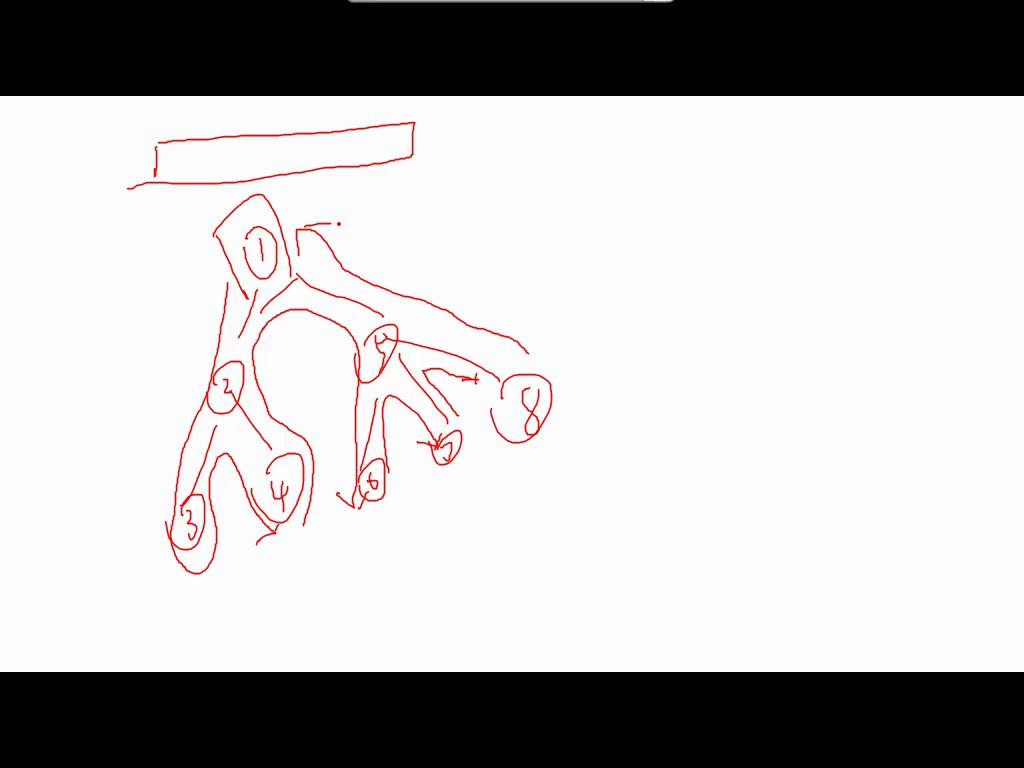
对子树的整体修改就可以转化为新的序列上的区间操作,这就可以将树转化为线性结构。
括号序列
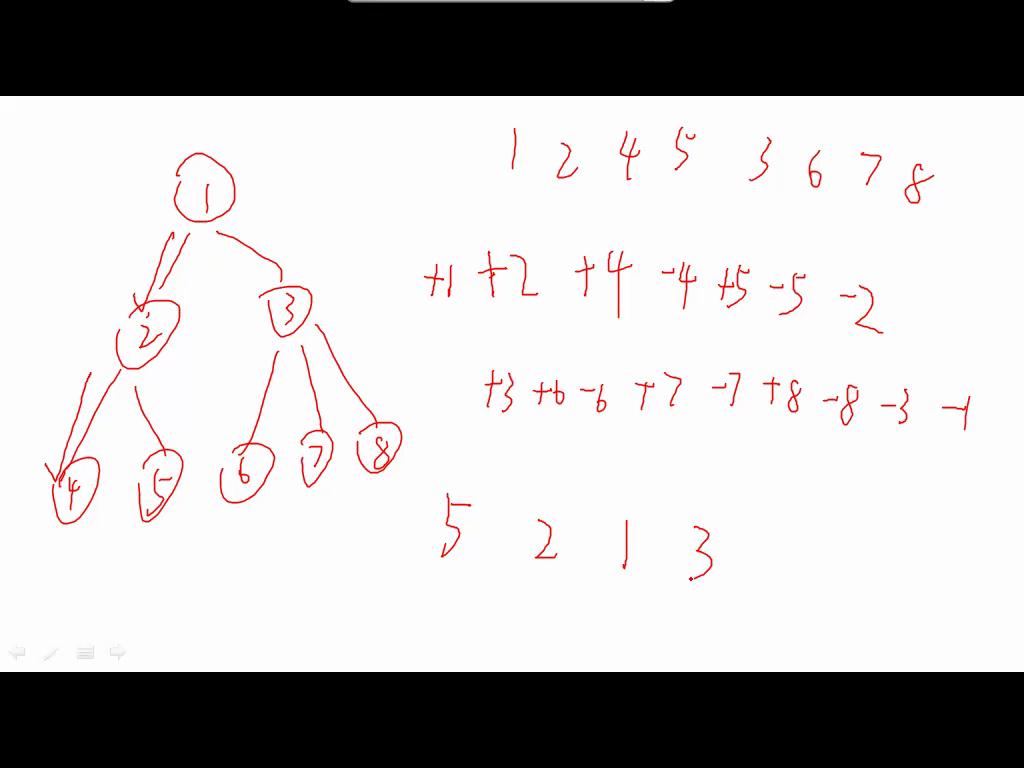
如图二,DFS过程中,1处记录一个+1符号,2处记录+2,4记录+4,之后无法继续进行DFS,记录-4,回溯。回到2,记录+5、-5...继续进行直到完成,结果:
+1 +2 +4 -4 +5 -5 -2 +3 +6 -6 +7 -7 +8 -8 -3 -1
将+看做(,-看做),形成一个合法的括号序列。
来考虑链。
例如链1->6,由1 3 6构成,那么括号序列上从1到6所有不在该链上的东西都会被消掉。留下的就是路径。这一性质只能用在无转弯、自上而下的链上。
而对于任意链,先求LCA,再使用即可。
启发式合并
有n堆东西,每次操作将两堆合并为一堆,维护合并过程。
可以使用并查集。
暴力时我们直接加入,复杂度,而启发式合并的区别就在于优先选择小的一堆,复杂度O(nlogn),这是因为小堆次数至少会扩大2倍,因此最多会被合并logn次,这样总复杂度为O(nlogn)
没什么专门的题,总之就是个神奇的玄学优化,yy一下就出来了
单调队列
定义
以1 3 2 4为例
加入1 1
加入3 1 3
加入2 1 2
加入4 1 2 4
不断删队尾直到保持单调性
应用:滑动窗口(LuoguP1886)
(几乎是唯一应用,有变式)
给出n个数,再给出一个k,有很多长度为k的子区间,求出这些区间的最小值。
暴力:扫一下,
线段树:区间询问最小值,log询问,
单调队列:
考虑如何求第一个区间的答案,对于单调递增的单调队列,第一个元素就是区间最小值。
对于区间[2,k+1]与[1,k],区别只有a[1]与a[k+1].加一个数直接插进去即可,而如果第一个数是最小值那么就是队首,而如果第一个数不是最小值这个数就必定已经被删掉了,否则就无法维护单调队列的单调性。这样转移就是O(1)的,总复杂度O(n)
分治
参考MergeSort
例题
T -5 平均值最大子区间
最大的数
不要思维江化.jpg
T -4 区间最小值乘区间长度最大
如果包含最小的数,那么要求的最大值就是整个区间长度与该数的乘积,因为这样比较大。
如果不包含这个数,那么这里考虑的两个区间就是左右两个区间。
这样就分治为左边与右边两个问题,用线段树维护区间最小值即可。
复杂度,这就是著名的笛卡尔树。
【思考题:如何O(n)】
T -3 区间端点最小值乘区间长度最大
这个与刚才不同对另一部分是有影响的,因此不能分治。
假设对点i,作为某一区间的左端点,我们希望右边的点比它大,那么我们就希望找出最靠右的比它大的数,这时可以解决这个问题。
这里我们可以二分一个长度代表后面l个数中有没有更大的。因此这里维护一个后缀最大值,O(1)的询问后l个数的最大值。
然后用这个结果更新答案即可。
线性做法证明很复杂,并不能证明,“两头砍最小的不断砍就行”
T -2 求出子区间中位数
用两个数,一个存比中位数小的,一个存比中位数大的
加一个小数会使中位数变大,因此将一个数扔到大根堆里,另一个同理。
枚举L,将R从右往左移,将一个一个加变成一个一个删除
排序一下,用一个链表维护从小到大的顺序,那么中位数就是中间位置的数。
删除O(1),删掉的数比中位数小则向后移动,否则向前移动,即转移也是O(1)的。
T -1 一个点阵有些特殊点,一个点的安全性就是到这些点的曼哈顿距离的最小值,要求求一条(1,1)到(n,n)的路径使安全性的最小值最大
(LuoguP1514)
见最大化最小值先想二分
假设现在二分结果为k,那么离特殊点曼哈顿距离<=k的点(将所有特殊点加入队列中BFS)全部标记为不能走,然后BFS判断是否联通。
如果只有一个特殊点,按曼哈顿距离倒序枚举距离为k的点。当距离为k时连通,那么k就是所求的值。
而如果有多个特殊点,倒着搞一下BFS的队列就是曼哈顿距离最大的。
如何判断是否连通呢?用并查集维护,每加入一个就扔到集合中。
T0 对序列A,B,求一个最大子区间[L,R]满足A区间[L,R]的和除以B区间[L,R]最大(实数除法)
暴力:预处理前缀和,枚举左右端点
假设结果为[L,R],那么A[L,R]/B[L,R]=x
如果现在的答案是m,check就是是否存在一个区间使得x>=m
那么该问题等价于判断A[L,R]-m·B[L,R]>=0
定义C[i]=A[i]-m·B[i],则问题为是否存在C[L,R]>=0
即是否存在C[i]>=0,然后回推,这就是在求A[i]-mB[i]>=0,也就是求A[i]/B[i]的最大值。
*对于实数上的二分,直接限定二分次数就行了,如30或50
当然并不是每个题都可以这样玄学的化简.
像这样求f(x)/g(x)最值的这类问题叫分数规划问题,一般二分答案
check函数一般列式化简,可以转化为一个比较简单的式子。
R可以任意设,稍大点就行
又如:假设每个边的权值有a,b,求一条路径使得最小
T12 给一棵大小为N的树,要求维护:1)换根 2)修改点权 3)查询子树最小值,N<=100000(BZOJ3306)
如果没有换根,DFS序+线段树硬搞
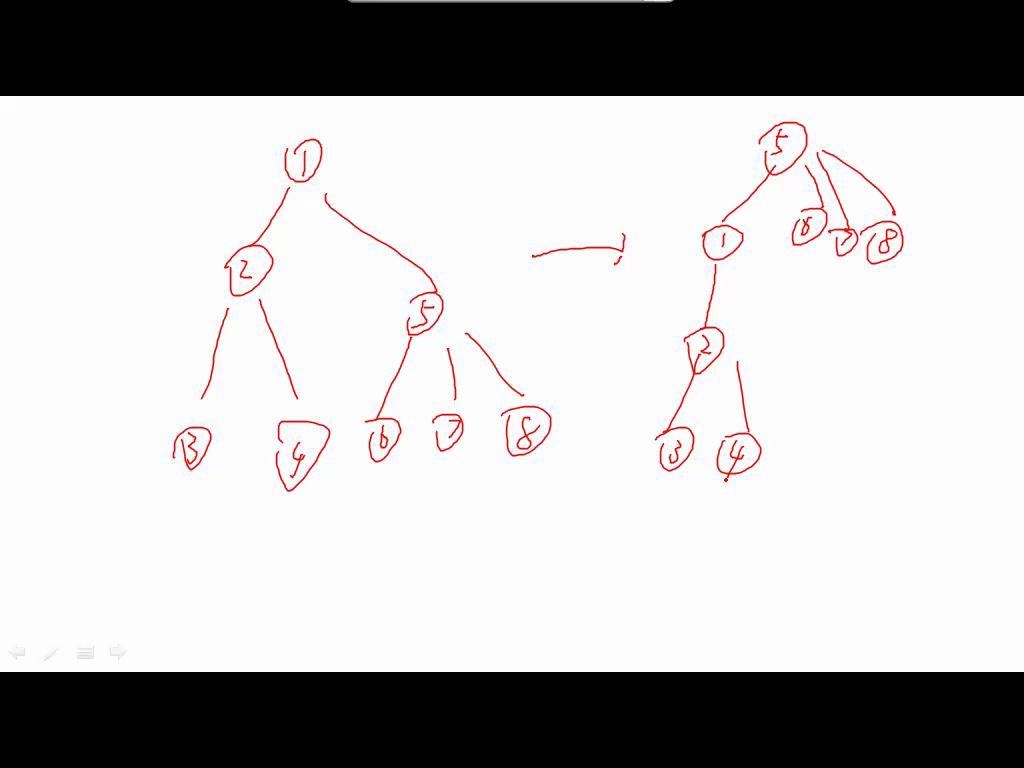
只有一部分的dfs序会改变
定一条从原父亲变成新父亲路径,如果不在这条路径上的点子树是不会改变的,直接询问。
否则,对于一个节点来说,儿子变父亲的伦理悲剧,使得唯一不是子树的只有从新根来的方向。由于儿子的dfs是个区间,这段区间就被去掉了。
假定原先区间为[p,q],儿子为[L,R],那么我们实际上就是询问[p,L-1]与[R+1,q]这两个区间,复杂度仍然是
T13 N个点的树,每个点点权v[i]。给q次询问,每次询问从p1到p2的路径上能不能找到三个点点权使之能组成三角形三边。(所有点的点权不超过int)
暴力:枚举
观察a+b>c,这是能组成三角形的条件。
因此a+b<=c不能组成,而a+b=c就是肥不辣鸡数列
由于该数列在45项后会爆int,而极限情况下46个点没有三角形就会爆int
也就是说,两个点之间不能超过45个结点。
因此当结果超过45就直接输出Y,否则暴力一下,这个复杂度是可以接受的。
钟神的建议
提高代码能力
写对暴力分
比如三分钟写出来线段树
多写搜索题或者模拟题对拍
调试能力
看着调试
Dev的调试
gdb调试
D3讲题
标签(空格分隔): 未分类
T1
从左往右扫过来,遇到一个')'
观察之前有没有左括号
->有则抵消,无则变左(变X次)
一直持续,扫完之后最终一定匹配后剩下'('
将一半的'('变成')'(变Y次)
所以结果为X+Y/2
标程:
#include <bits/stdc++.h>using namespace std;char s[100005];int i,p,o,ans;int main(){freopen("bracket.in","r",stdin);freopen("bracket.out","w",stdout);scanf("%s",s); p=strlen(s);for (i=0; i<p; i++){if (s[i]==')'){if (o==0){o++; ans++;} elseo--;}elseo++;}cout<<ans+o/2;// system("pause");return 0;}
T2
前置知识:找尽量多的区间互不相交
做法:按照右端点排序,能取就取,取出最多的互不相交的线段
本题是在这个基础上加了权值。下证该做法是适用的。
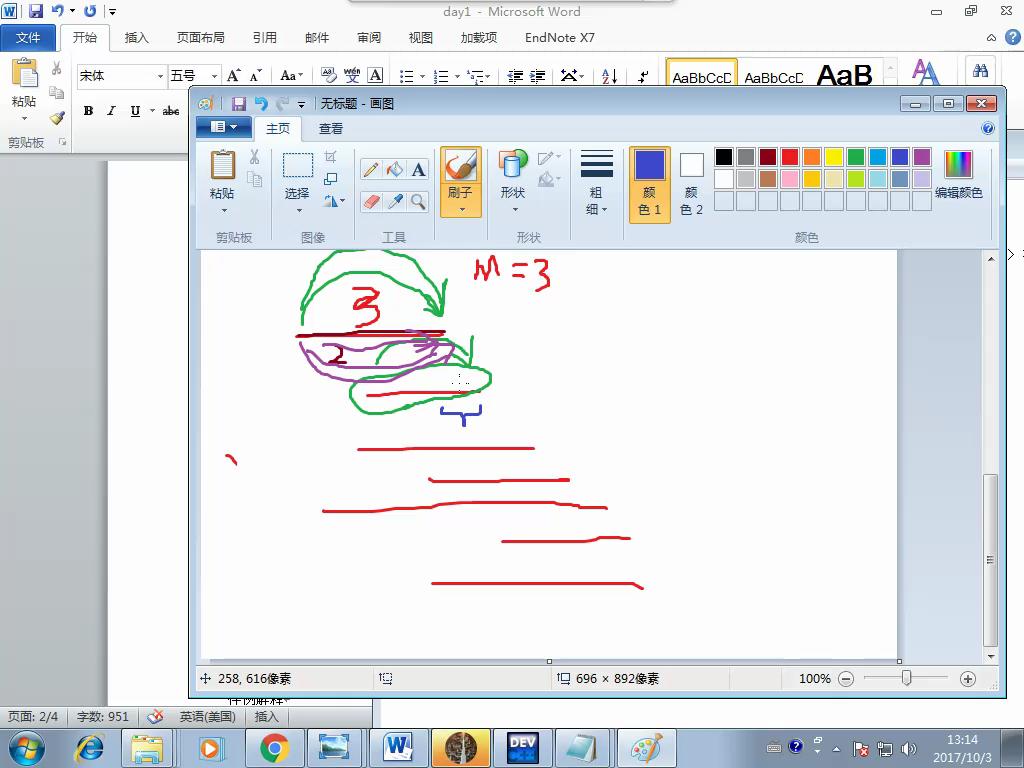
如图,紫色是直接取走,绿色是选一选。
显然,在同样的路线下,紫色是优于绿色的,因为这样可以留下更多的地方。
这样直接搞就是60分。
再来分析,我们是要维护一个f数组表示i时刻车上有多少只怪兽
伪代码:[x,y]加入Zfor(int i=x;i<y;++i) MAX=max(MAX,f[i]);t=min(Z,M-MAX);for (int i=X; i<Y; i++) f[i]+=t;ans+=t;cout<<ans;
因此维护的就是区间加入一些数和区间查询最大值
可以用线段树或者树状数组。
标程:
#include <cmath>#include <cstdio>#include <cstdlib>#include <iostream>#include <algorithm>using namespace std;int tree[65536][4],n,m,c,i,MIN,ans;struct node{int x;int y;int z;};node A[100005];int cmp(node i,node j){return i.y<j.y;}void Update(int k){tree[k*2][2]+=tree[k][3];tree[k*2+1][2]+=tree[k][3];tree[k*2][3]+=tree[k][3];tree[k*2+1][3]+=tree[k][3];tree[k][3]=0;}void work(int root,int l,int r,int k){if (l==tree[root][0] && r==tree[root][1]){tree[root][2]+=k;tree[root][3]+=k;return;}Update(root);int mid=(tree[root][0]+tree[root][1])/2;if (l<=mid) work(root*2,l,min(mid,r),k);if (r>mid) work(root*2+1,max(mid+1,l),r,k);tree[root][2]=min(tree[root*2][2],tree[root*2+1][2]);}int find(int root,int l,int r){if (l==tree[root][0] && r==tree[root][1]) return tree[root][2];Update(root);int mid=(tree[root][0]+tree[root][1])/2,p=453266144,q=453266144;if (l<=mid) p=find(root*2,l,min(mid,r));if (r>mid) q=find(root*2+1,max(mid+1,l),r);return min(p,q);}int main(){freopen("bus.in","r",stdin);freopen("bus.out","w",stdout);scanf("%d%d%d",&n,&m,&c);for (i=32768; i<=65535; i++) tree[i][0]=tree[i][1]=i;for (i=32767; i>=1; i--){tree[i][0]=tree[i*2][0];tree[i][1]=tree[i*2+1][1];}work(1,1+32767,m+32767,c);for (i=1; i<=n; i++){scanf("%d%d%d",&A[i].x,&A[i].y,&A[i].z);A[i].y--;}sort(A+1,A+n+1,cmp);for (i=1; i<=n; i++){MIN=find(1,A[i].x+32767,A[i].y+32767);if (MIN>A[i].z){work(1,A[i].x+32767,A[i].y+32767,-A[i].z);ans+=A[i].z;}else{work(1,A[i].x+32767,A[i].y+32767,-MIN);ans+=MIN;}}cout<<ans;return 0;}
不用线段树的做法:
从左往右枚举每一个时刻,扫描一下。一旦满载,赶走最迟下车的怪兽,直到出现不满载。这样相当于我们贪出了最好的选择。
因此这样维护的就是所有怪兽从大到小,用个heap维护就行。复杂度klogM
T3
-
枚举左上角、右上角、修改的数、和 -
矩阵前缀和 优化一下 -
预处理出每个矩阵的最小值,然后修改
前置知识:
最大子段和问题
f[i]为以i结尾的最大子段和
f[i]=max(f[i-1]+a[i],a[i])
而ans=max{f[i]}
最大子矩阵问题
枚举一个端点在哪一行,一个端点在另一行()
然后将每一列的和看做点,就是求最大子段和
那么对于本题,由于修改是最小的数,对于
f[i][0]表示以i结尾并且没有数被修改过的最大的和
f[i][1]表示以i结尾并且有数被修改过的最大的和
a[i]为第i列的和
则f[i][0]=max(f[i-1][0]+a[i],a[i])
f[i][1]=max(f[i-1][1]+a[i],f[i-1][0]+a[i]-MIN{i}+P,a[i]-MIN{i}+P)
结果就是MAX{f[i][0/1]}
当然这里还需要特判一下是否会恰好改变一个数
标程:
#include <cmath>#include <cstdio>#include <cstdlib>#include <iostream>#include <algorithm>#include <assert.h>//判断输入是否合法using namespace std;int n,m,a[305][305],MIN[305],b[305],dp[305][2],i,j,s[305][305],ans,P,k;int main(){freopen("puzzle.in","r",stdin);freopen("puzzle.out","w",stdout);while (cin>>n){ans=-1000000000;scanf("%d%d",&m,&P); assert(1<=n && n<=300 && 1<=m && m<=300 && -1000<=P && P<=1000);for (i=1; i<=n; i++)for (j=1; j<=m; j++) {scanf("%d",&a[i][j]); assert(-1000<=a[i][j] && a[i][j]<=1000); }for (i=1; i<=n; i++)for (j=1; j<=m; j++)s[i][j]=s[i-1][j]+a[i][j];for (i=1; i<=n; i++){for (j=1; j<=m; j++) MIN[j]=a[i][j];for (j=i; j<=n; j++){for (k=1; k<=m; k++) MIN[k]=min(MIN[k],a[j][k]);for (k=1; k<=m; k++) b[k]=s[j][k]-s[i-1][k]; dp[0][1]=-1000000000;for (k=1; k<=m; k++) dp[k][0]=max(dp[k-1][0]+b[k],b[k]),dp[k][1]=max(max(dp[k-1][1]+b[k],dp[k-1][0]+b[k]-MIN[k]+P),b[k]-MIN[k]+P);for (k=1; k<m; k++) ans=max(ans,max(dp[k][0],dp[k][1]));if (i==1 && j==n){ans=max(ans,dp[m][1]); int sum=0;for (k=m; k>1; k--) {sum+=b[k]; ans=max(ans,sum);}} elseans=max(ans,max(dp[m][1],dp[m][0]));}}cout<<ans<<endl;}return 0;}
DP选讲
标签(空格分隔): 懵逼 啥玩意 DP

常见dp优化
决策单调性:二分
前缀和与前缀最大值优化
斜率优化
矩阵乘法快速幂优化
数据结构优化
单调队列优化
单调队列模板
//L为头,R为尾,初始L=1,R=0void Insert(int x){while(l<=r&&a[r]<=x) r--;//由于寻找次数一定小于插入长度,所以保证复杂度O(n)s[++r]=x;}void Query(){return s[l];}void Delete(){//判断是否在单调队列中cnt++;if(t[l]==cnt) l++;}int main(){cin>>Q;while(Q--){cin>>A;if(A==1){cin>>x;Insert(x)}if(A==2){cout<<Query()<<endl;}if(A==3){Delete();}}}
多重背包
,将物品拆开
,将物品按照拆开
,单调队列
先枚举所有物品,再枚举所有可能情况,那么换一种写法:
--仍然是伪代码v[i]来表示第i个物品的价值 w[i]来表示体积for (int i=1; i<=n; i++)for (int k=0; k<=m; k++)for (int j=0; j<=c[i]; j++)if (k>=j*w[i])dp[i][k]=max(dp[i][k],dp[i-1][k-j*w[i]]+j*v[i])

来看红与蓝色,那么后一个转移来源与前一个的区别就是新添了一个少了一个,也就是线性维护这样几个操作:
插入队首元素
取出最大的元素
弹出队尾元素
就是单调队列
烽火传递
给定n个非负整数,选择其中若干数字,使得每连续k个数中至少有一个数被选出。要求选择的数字之和尽可能小。n<=1000。
dp[i]表示1~i是被选出的,那么dp[i]=min{dp[j]}+a[i]且
而每次转移只相差了a[i-k+1]与a[i+1]两个数,那么就是用一个线性结构维护这个操作,
这就是单调队列,也就是烽火传递可以O(n)实现
--还是伪代码for(int i=l;i<=k;++i) dp[i]=a[i];for(int i=0;i<k;++i) push(dp[i]);//压入for(int i=k;i<=n;++i){dp[i]=query()+a[i];//找最小值push(dp[i]);pop();//删除队尾}
也就是,一个dp值有c[i]个等差数列推得,而转移以min/max移动
通式:dp[i][j]=min{dp[i-1][k]}
最大子段和
- dp
见今天的题解 - 贪心
for (int i=1; i<=n; i++){sum+=a[i];if (sum<0) sum=0;MAX=max(MAX,sum);}cout<<MAX;
- 前缀和
for (int i=1; i<=n; i++)s[i]=s[i-1]+a[i];for (int i=1; i<=n; i++){ans=max(ans,s[i]-MIN);MIN=min(MIN,s[i]);}
任何一段区间[L,R]相当于S[R]-S[L-1],我们就是找到最大的S[R]与最小的S[L-1],用min记录一下。
加强版 成环
- 拉开拼成一个
这个做法翻车了,233333 - 单调队列
对于前缀和的做法枚举r时,随着r不断增加,右端点与左端点都会增加,然后用单调队列维护这一操作
装喷头
有一根长为n的数轴,要在这根数轴上装一些喷头,每个喷头的喷射半径在[a,b]之间并可调节。
其中有m个限制,形如li,ri,表示[li,ri]这一段区间的整点一定要同时被一个喷头喷到。
规定每个整点位置恰好被一个喷头喷到,并且喷头不允许喷出外。问至少装几个喷头。
n<=1000。
用dp[i]表示第i个位置装喷头,1~i都满足条件这样的最少喷头数量
这么搞转移列不出来
用dp[i]表示前i个位置都满足条件了,最少装多少喷头,dp[j]表示1~j都满足条件了,j+1~i没满足条件,装个喷头要恰好覆盖这些
由于喷头的喷水半径是个圆,所以2a<=i-j<=2b
因此dp[i] = min{dp[j]}+1 2a<=i-j<=2b
j的取值是有确定的,所以j是由区间构成的
标记时,若那么dp[i]=inf.
for (int i=1; i<=n; i++){if (!v[i]) dp[i]=inf;else{dp[i]=Query()+1;}Insert(dp[i+1-2a]);Delete(dp[i-2b]);}
NOI2005 瑰丽华尔兹
在一个n*m的矩阵上,有一些点是障碍,有一些点是空地。并且有一个点有个人。
这个人在[L1,R1]个时刻会向X1行动,[L2,R2]个时刻会向X2行动以此类推。总共有T段区间,且L[i+1]=R[i]+1,L[1]=1。
其中X1,X2,…,XT为上下左右中的一种。
为了使这个人在移动过程中不撞掉也不掉出矩阵,每次可以选择耗费1点能量让它不动,问最少耗费多少能量使得它再R[T]这个时刻还在这个矩阵上。
n,m<=200,T<=200,R[T]<=40000。
dp[i][j][k]第i时刻在(j,k)
枚举第i时刻用不用能量,可以转移为dp[i][j+v[i]][k+v[i]]
正确性可以保证,状态数比较大
枚举第i区间结束时在(j,k)用的能量
那么就是max{dp[i-1][j][k-x]+(t[i]-x)}(t[i]-x表示用了多少能量)
复杂度
用dp[i][j][k]表示第i个区间结束时最多走了多少步
以右方向为例来分析这个问题
那么t表示该时间段的时间且中途无障碍
即k>=k-x>=k-t也就是在[k-t,k]中转移
随k增加,让左右端点分别移动,这就是一个单调队列。
问题的关键是障碍,随着k的增加,会遇到障碍。如果走到障碍,本次不转移,左右端点分别移动到k+1,方便下一次运行。
具体实现时,由于由于要加x,就可以将队列中所有元素增加一,用一个变量维护一下。
然后是zhw本人的解释:
dp[i][j][k] 第i个时间段结束,人在(j,k)这个位置,这样子最多走多少步
假设 i这个时间段 这个人会往右走 // t=这一个时间段有多少时间
dp[i][j][k]=max{dp[i-1][j][k-x]+x} 0<=x<=t。(j,k-x)~(j,k) 没有障碍物
k-t<=p<=k 并且 (j,p)~(j,k)没有障碍物
dp[i][j][k]=max{dp[i-1][j][p]+x} k-t<=p<=k 并且 (j,p)~(j,k)没有障碍物
随着k的增加 k-t,k都一定会增加 单调队列
维护能更新的这个区间会怎么移动。 [l,r]
每次在插入进队列之前,把队列中所有元素+1,这件事是可以通过一个变量来维护的。
T*n^3
i这个时间段 这个人会往左、下、上走
一道神题
一个n*n的矩阵,每行每列恰好放两个棋子,问方案总数%p的值
似乎不能OEIS
似乎是本蒟蒻听懂的唯一一道题
dp[i][j][k]表示前i行有j列放了一个棋子,k列没有放棋子
对i+1行来说,
(0,0)表示放的两列之前都没放,则转化为dp[i+1][j+2][k-2]
(0,1)表示放的两列一个放过一个没放,则转化为dp[i+1][j][k-1]
(1,1)表示放的两列之前都放过一个,则转化为dp[i+1][j-2][k]
显然,
结果就是dp[n][0][0]
这样就是的做法。
再来思考一下,ijk之间有这样的关系
所以这里可以二维优化一维:
结果就是dp[n][0]
复杂度
如何达到O(n)的复杂度呢?
以块为单位,用dp[i]表示i*i的矩阵满足条件的方案总数
观察最后一列,前两个和任意两个是没有区别的
例如下图,这两种状态实质是相同的。
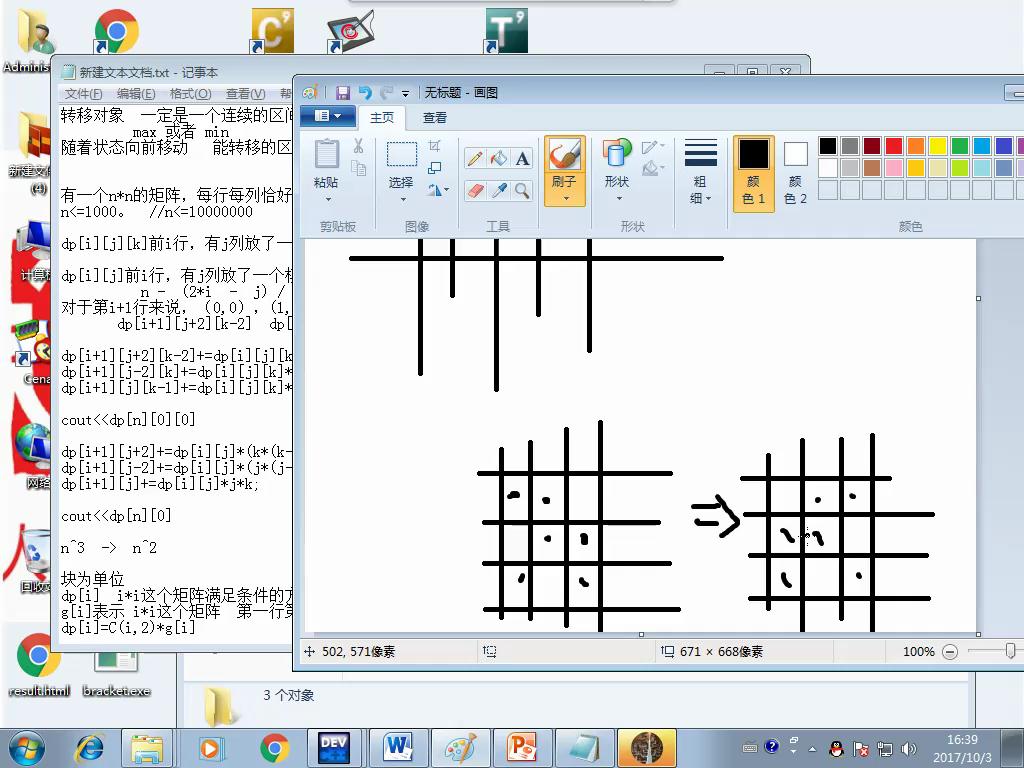
,g(i)表示第一行第n个第二行第n个都放了的总数
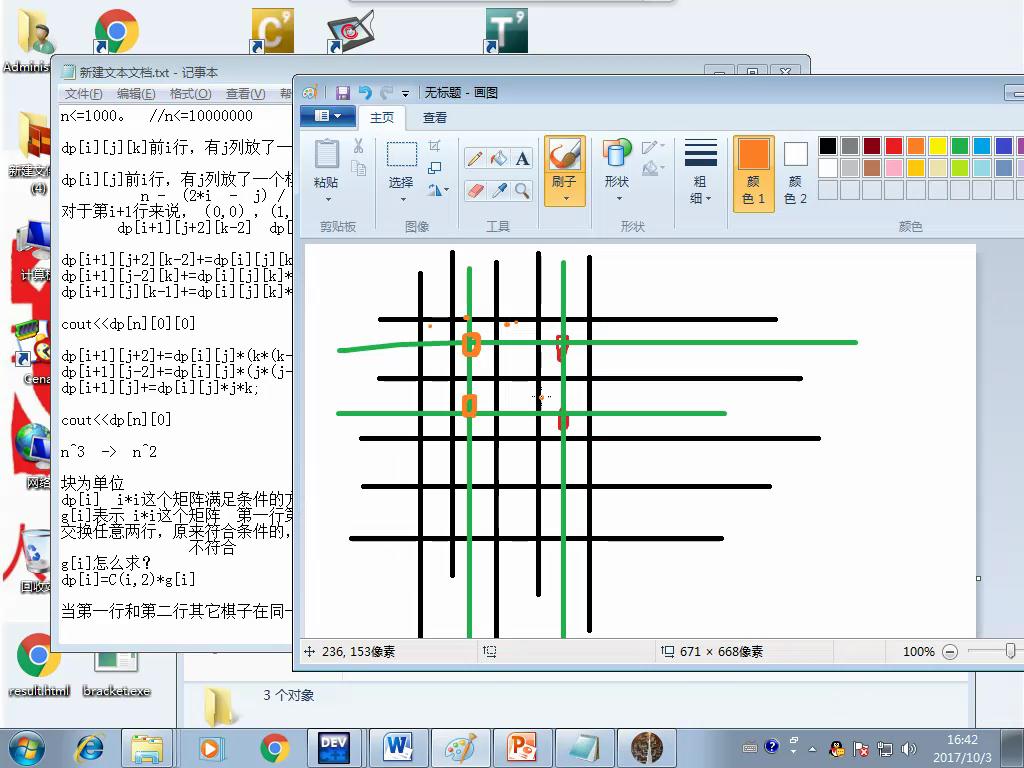
而对于g[i],如果第一行和第二行其它棋子在同一列,那么g[i]+=dp[i-2]*(i-1),如下图
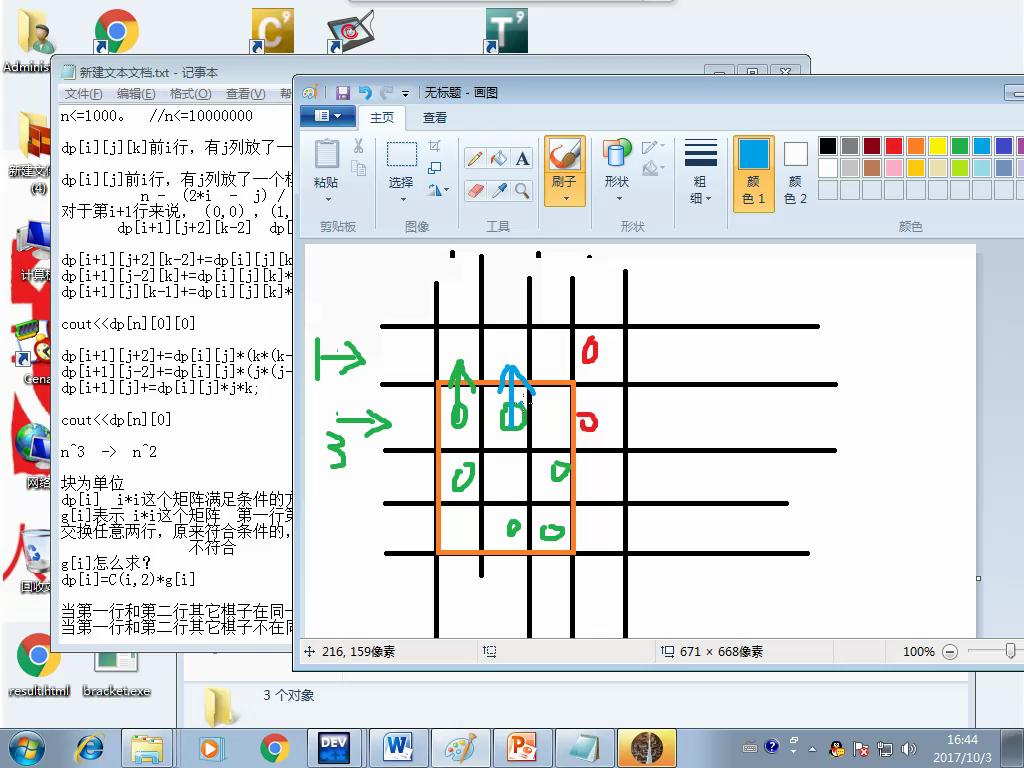
否则,如下图,每一个状态移上去就可以满足了。即g[i]+=dp[i-1]*2.
将上述结合一下,
我们完成了一个O(n)的方程。
综上所述,我们其实可以采用这样一种思路:
将原问题化简为与原问题相似规模较小的问题
从命题人的角度谈出题——zhw神犇的出题经验谈
标签(空格分隔): 人生经验
出题导论
出题可以掌控他人的秘密
这个题是可做的、是不是一眼题(不是裸题)、以合适的难度合适的算法出现
任何的题目都是不可能爆零的
比如今天的O(n)DP,可以放在D2T3
对于30%的数据,n<=5
对于50%的数据,n<=200
对于80%的数据,n<=2000
对于100%的数据,n<=1e8
也就是说,对于NOIP来说,正解搞不动,暴力分很多。
怎么搞出一道题
从经典题目中改编
最大子矩阵:
1)改变其中k个数
2)改变其中k个数变为相反数
有一个灵感的时候
苦思冥想一个奇怪的东西,找到一个落脚点
1)这个题目是一眼题->继续加强
2)这个题目不可做->放宽条件(缩小数据范围,魔改)
例:由二分思考
有这么一段代码
l=1; r=n; mid=(l+r)/2;
while (l<=r){ if (a[mid]<=m) l=mid+1; else r=mid-1; mid=(l+r)/2;}
是用来二分的,显然当a顺序时,若m在a中出现过,则a[r]=m。
现在a是一个1~n的排列,并且它的顺序被打乱了,求存在多少种排列,使得最终r=k。答案对1e9+7取模。
n,m,k<=10^6。
n,m,k<=10^9。
且x+y=logn
答案为
预处理一下1e6、2e6...1e9的阶乘即可
揣摩出题人的意思
题目考察什么问题
题目是否与经典问题相关
这个题目的难度(仅限NOIP)
做题
出题人都会做,我为什么不会做
之所以能做,是因为放宽了条件
之所以不能做,是因为加强条件
例 次大公约数
次大公因数=最大公因数/最小公质因数
枚举a[1]的质因数即可
再一次的变式 k大公约数->不可做
如何命题
树上的命题思路:树套小树,深度为一段区间的点,区间LCA等。
图上的命题思路:每条边以某个概率生成,每次以一定概率走某条边,缩点等。
序列上的命题思路:一段区间,每等差数列位置的区间,a{b{i}}与b{a{i}}构成树套环等。
辅助工具:gcd,max,期望,mex(最小未出现的正整数),sum等。
例:区间开根号向下取整 区间求和
任何一个不超过1e9的数只会经过不超过7次就会到达1,因此最坏7n次
暴力即可
命题中重要的事
你是出题人!
你是出题人!
你是出题人!
你是出题人!
你是出题人!
你是出题人!
你是出题人!
你是出题人!
当你想到一个好的idea,却不会做,不妨将其简化。
如果是一段序列,不妨将其随机。
如果是一棵树,不妨将其随机。
如果是一个矩阵,不妨将其变成黑白矩阵。
如果是一张图,不妨将其变成二分图。
甚至你可以指定一些特殊条件。(例如树的叶子个数,图的点的度数,每个数的大小等)
例如 叶子个数<=20,没有这个限制出题人都不会做
斟酌
作一个能回报社会的出题人
尝试命一道题
新`背包问题
有一个容量为m的背包,有n个物品,每个物品有价值和体积。
放若干物品,使得容量之和不超过m的情况下价值和在模p意义下最大。
n,p<=1000。
dp[i][j]->价值为j,体积最小为多少
那么dp[i+1][(j+v[i])%p]=min(dp[i+1][(j+v[i])%p],dp[i][j]+w[i]);
双端队列
队列首插入、队列尾插入、队列首删除、查询队列元素最大值
劈成两半,左边维护单调队列,右边维护一个栈,然后维护一个后缀最大值
当且仅当栈为空时从队列中删除
命题的意义
- 缓解经济压力。
- 设身处地的在出题人身上考虑。
- 一道题目之所以被出出来,一定是因为某人经过脑洞,再经过一系列思考,认定这道题目具有挑战性,之后才出出来的。
- 既然这道题目可做,那肯定存在突破口。
(当然在实际情况中没有那么轻松)
- 既然这道题目可做,那肯定存在突破口。
D4讲题
标签(空格分隔): 题解 爆零
T1
数据太弱暴力AC.jpg
比如向右看 5 6 7 这样单调递增
而维护这个东西就是只有一段插入,没有删除->单调栈
而查询最近的由于要删掉小的所以就是top减一这个位置。
从右向左:
for(int i=n;i>=1;--i){while(r&&s[r]<=h[i]) r--b[q[r]]+=a[i];//b[i]为第i个人收到的玫瑰数s[++r]=h[i];q[r]=i;//整个栈中第r个是i}
从左向右反过来就行。
复杂度O(n)
标程
#include <cmath>#include <cstdio>#include <cstdlib>#include <iostream>#include <algorithm>using namespace std;int n,s[50002],d[50002],ans[50002],ANS,a[50002],b[50002],r,i;int main(){freopen("treasure.in","r",stdin);freopen("treasure.out","w",stdout);cin>>n;for (i=1; i<=n; i++) scanf("%d%d",&a[i],&b[i]);s[1]=a[1]; d[1]=1; r=1;for (i=2; i<=n; i++){while (r!=0 && a[i]>s[r]) { ans[i]+=b[d[r]]; r--; }r++;s[r]=a[i];d[r]=i;}s[1]=a[n]; d[1]=n; r=1;for (i=n-1; i>=1; i--){while (r!=0 && a[i]>s[r]) { ans[i]+=b[d[r]]; r--; }r++;s[r]=a[i];d[r]=i;}for (i=1; i<=n; i++) ANS=max(ANS,ans[i]);cout<<ANS;return 0;}
T2
30%
暴搜点
50%
如果是长方形,那么一定是和糖果贴紧的
对于正方形,先离散化,然后枚举上边、下边、左边再枚举右边
最后将长方形变成正方形。
离散化
struct node {int x,y;} t[10005];int cmp(node i,ndoe j) {i.y<j.y;}for (i=1; i<=n; i++) cin>>a[i];for (i=1; i<=n; i++) t[i].x=i,t[i].y=a[i];sort(t+1,t+n+1,cmp);for (i=1; i<=n; i++){if (t[i].y!=t[i-1].y) now++;p[now]=a[t[i].x]; a[t[i].x]=now;}
离散化之后为n*n,直接枚举即可
80%
枚举上边、下边,判断左边是1的情况下右边是什么
由于是个正方形,随着左边的向右移动,右边一定向右移动,直接枚举即可。
100%
假如x可行,那么x+1能覆盖C个糖果,x-1不行。
所以答案是连续的,那么我们可以二分答案。
问题就是check()函数。
枚举上边,下边位置是固定的。那么就能确定哪些糖果被夹在区间中,而左边的移动带来右边的移动,如果用前缀和维护就可以O(n)判断
标程
#include <cmath>#include <cstdio>#include <cstdlib>#include <iostream>#include <algorithm>using namespace std;struct node {int x,y;} a[1005];int C,n,L,R,mid,b[1005],o,i;int cmp(node i,node j) {return i.x<j.x;}int CMP(int i,int j) {return i<j;}bool WORK(int l,int r){if (r-l+1<C) return false; o=0;for (int i=l; i<=r; i++) b[++o]=a[i].y;sort(b+1,b+o+1,CMP);for (int i=C; i<=o; i++)if (b[i]-b[i-C+1]<=mid) return true;return false;}bool OK(int x){int l=1;for (int i=1; i<=n; i++){if (a[i].x-a[l].x>x){if (WORK(l,i-1)) return true;while (a[i].x-a[l].x>x) l++;}}if (WORK(l,n)) return true;return false;}int main(){freopen("square.in","r",stdin);freopen("square.out","w",stdout);scanf("%d%d",&C,&n);for (i=1; i<=n; i++)scanf("%d%d",&a[i].x,&a[i].y);sort(a+1,a+n+1,cmp);L=0; R=10000; mid=(L+R)/2;while (L<=R){if (OK(mid)) {R=mid-1; mid=(L+R)/2;} else{L=mid+1;mid=(L+R)/2;}}cout<<L+1;return 0;}
T3
计算几何
40分
手算即可
60分
做出来s-t图。
答案就是最大值减去最小值
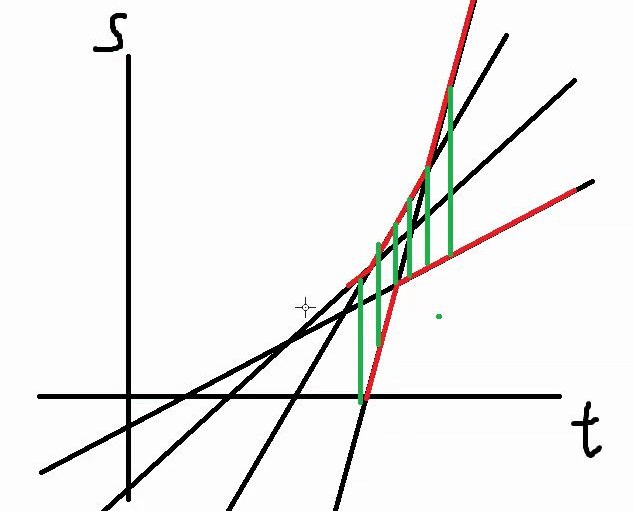
也就是绿色的东西
观察可知绿色在交点处似乎可以取到最值。怎么证明?我们使用反证法:
假设在某一个不是交点的位置取到了最值,那么我们一定能找到其它点更小。
所以自然而然的,求出所有交点,求出每只豹子的位置,更新答案。
80分
蛤?
100分
后来时刻只有进行追逐的才有意义,否则出发晚并且速度慢的就没意义。
因此只有这些追逐的交点才是有意义的。也就是求图像上界与下界。
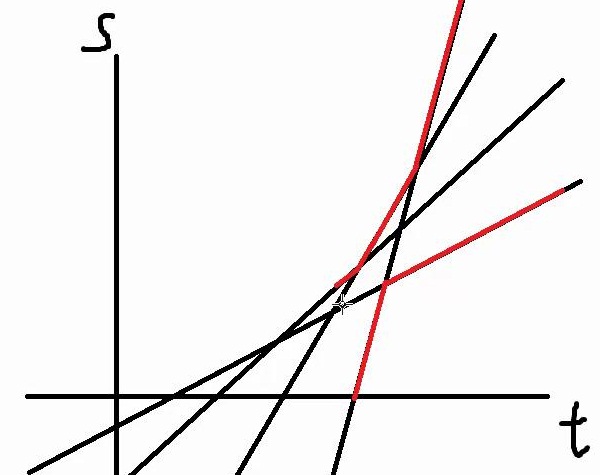
如图,对于这两条线,在后面的时候斜率大的占领靠上的。
那么按照斜率排序,每插入一条线就会将上界的一段后缀覆盖掉。也就是插入并赋值这个操作是O(1)的。
下界同理,由于我们可以维护出交点和对应的解析式,这个时候搞一个双指针:上追到下就让下移动,下追到上就让上移动。这样就可以O(n)跑完。
用栈维护一开始保证跑的慢的豹子一定先跑,跑的快的一定后跑
也就是:
上凸壳:对于两只豹子,一只跑得慢(v小)且后来才跑(t大),一只跑得快(v大)且一开始就跑(t小),我们保留后面那只。
下凸壳:对于两只豹子,一只跑得慢且后来才跑,一只跑得快且一开始就跑,我们保留前面那只。
这样预处理一下。
非常精妙的神奇方法
找见上凸壳与下凸壳,那么要求的东西一定是先变小后变大(上凸壳斜率增加,下凸壳减小)
也就是近似抛物线的一个东西
那么就可以二分
check()函数:
上凸壳斜率小于下面则往右,否则往左
斜率可以定义法求导或者直接维护一下得到。
也可以用神奇的三分做法
标程
//ZHW:这个标程写的很sabi#include<cstdio>#include<cstring>#include<cstdlib>#include<cmath>#include<iostream>#include<algorithm>using namespace std;const long double INF=(long double)1000000000*10;long double L,R,mid,ans,hh[100005];int r,rr,i,n,MAX,X,Y,cnt,vv[100005],vv2[100005];struct node2 {int t; long double l;} s[200005],S[200005];struct node {int t,v;} t[100005];int cmp(node i,node j) {return i.v<j.v || i.v==j.v && i.t>j.t;}struct Node {long double x;int y,z;} p[200005];int CMP(Node i,Node j) {return i.x<j.x;}long double work(int x,long double y) {return (long double)t[x].v*y-hh[x];}int main(){freopen("chase.in","r",stdin);freopen("chase.out","w",stdout);while (1){scanf("%d",&n);// if (n==0) return 0;MAX=0;for (i=1; i<=n; i++){scanf("%d%d",&t[i].t,&t[i].v);MAX=max(MAX,t[i].t);}sort(t+1,t+n+1,cmp); int MIN=t[n].t;for (i=n-1; i>=2; i--){if (t[i].t>MIN) vv[i]=1; elseMIN=t[i].t,vv[i]=0;}for (i=1; i<=n; i++) hh[i]=(long double)t[i].t*t[i].v;r=1; s[1].l=MAX; s[1].t=1; s[2].l=INF; vv[n]=0;for (i=2; i<=n; i++)if (!vv[i]){while (r && work(i,s[r].l)>=work(s[r].t,s[r].l)) r--;if (!r) {r=1; s[1].l=MAX; s[1].t=i; continue;}L=s[r].l; R=s[r+1].l; mid=(L+R)/2.0;for (int I=1; I<=80; I++){if (work(i,mid)>=work(s[r].t,mid)) {R=mid; mid=(L+R)/2.0;} else {L=mid; mid=(L+R)/2.0;}}s[++r].l=mid; s[r].t=i; s[r+1].l=INF;}rr=1; S[1].l=MAX; S[2].l=INF; S[1].t=n;MIN=t[1].t;for (i=2; i<n; i++)if (t[i].t<MIN) vv2[i]=1; elseMIN=t[i].t,vv2[i]=0;for (i=n-1; i>=1; i--)if (!vv2[i]){while (rr && work(i,S[rr].l)<=work(S[rr].t,S[rr].l)) rr--;if (!rr) {rr=1; S[1].l=MAX; S[1].t=i; continue;}L=S[rr].l; R=S[rr+1].l; mid=(L+R)/2.0;for (int I=1; I<=80; I++){if (work(i,mid)<=work(S[rr].t,mid)) {R=mid; mid=(L+R)/2.0;} else {L=mid; mid=(L+R)/2.0;}}S[++rr].l=mid; S[rr].t=i; S[rr+1].l=INF;}cnt=0;for (i=1; i<=r; i++) {p[++cnt].x=s[i].l; p[cnt].y=1; p[cnt].z=s[i].t;}for (i=1; i<=rr; i++) {p[++cnt].x=S[i].l; p[cnt].y=0; p[cnt].z=S[i].t;}sort(p+1,p+cnt+1,CMP); X=Y=0; ans=INF;for (i=1; i<=cnt; i++)//X为上凸壳指针,y为下凸壳指针{if (p[i].y==1) X=p[i].z; else Y=p[i].z;// printf("%.5f\n",(double)p[i].x);if (X && Y) ans=min(ans,work(X,p[i].x)-work(Y,p[i].x));}printf("%.2f\n",fabs((double)ans));return 0;}}
图论
标签(空格分隔): 图论
友链https://www.zybuluo.com/Superjohnson/note/905505
ORZ!
算法简单,难点在于构图
算法
最短路
最小生成树
拓扑排序
二分图最大匹配
Tarjan
并查集
2-SAT
~~网络流~~
构图
比如,给定n个奇数,拆成二进制,只保留其中一位,求最大抑或和。
这种糟东西是最难的图论
图的定义
- 自环
- 有向与无向
- 带权边
- 路径
- 简单路径
- 连通分量
- 强联通分量
- 极大强联通分量 一个点不可能存在与两个极大强联通分量
- 子图
- 完全图
- 竞赛图 任意两点间有一条有向边
图的表示
- 邻接矩阵 很方便 f[i][j]>0表示存在边,但是很占空间
- map存边 也很方便,但是很慢
- 邻接表
//数组实现cin>>u>>v;f[u][++f[u][0]]=i;//f[u][0]为能连出来几个点,f[u][i]表示第i个点是啥//复杂度是O(出度)//向量实现vector<int> f[n];cin>>u>>v;f[u].push_back(v);//内存复杂度O(m)//查询O(出度)
- 边表(前向星,链式前向星)
//预处理cin>>u>>v;o++e[o]=v;//用head[u]表示起点为u最大的编号next[o]=head[u];//u处理完连向v的这条边之后下一条是什么head[u]=o;//更新//遍历u为起点能连向哪些点for(i=head[u];i;i=next[i]) u->e[i];
zhw:我觉得没啥要用的地方
其它概念
-最大团、最大独立点集
选择一个图中的若干点,若任意两个点之间均有一条边联通,则这些点组成的集合是一个团。
最大团即最多的点组成的团。
选择一个图中的若干点,若任意两个点之间都没有一条边联通,则这些点组成的集合是一个独立点集。
最大独立点集即最多的点组成的独立点集。
最大团=n-最大独立点集。
求一个最大团是NP 暴搜n=59是极限(需要一天)
例 给定一个点数为3n的图,保证图中存在一个点数不小于2n的团。求一个点数为n的团。n<=1000。
每次找两个点,没有边,然后删掉
重复n次,剩下的一定是团,保证2个点最多只有1个点在团里
给定一张带点权和边权的图,点权和边权都是正整数。选择这个图的一个子图,要求这个子图连通,它的价值为点权之和除以边权之和。
问这个最大价值是多少。点数,边数<=100000。
直接搞和最大的两个。
因为对于一个树,可以剖开两半,
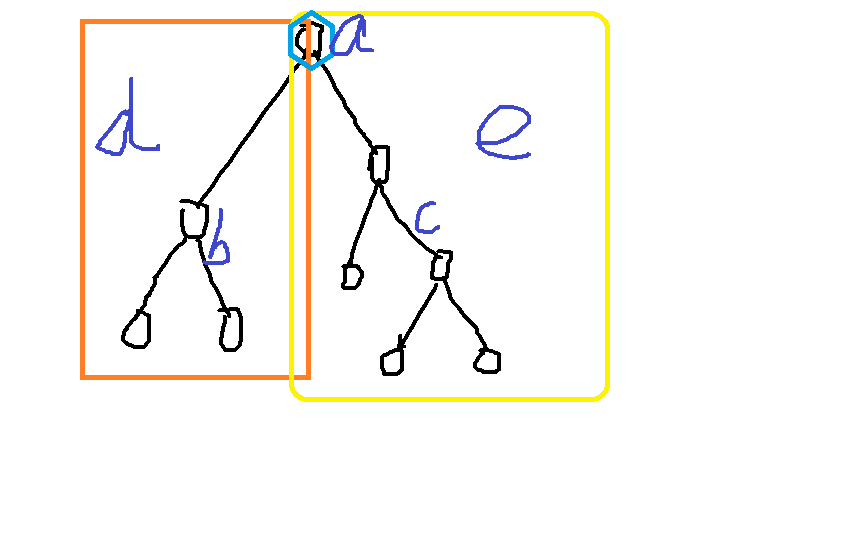
a为根节点,de为左右子树的边权,bc为左右子树点权
这是由于.这个的证明:
假设 (a+b)/d >= (b+c)/e -> ae+be>=bd+cd
证 (a+b)/d > (a+b+c)/(d+e) -> ae+bd+be>bd+cd
而一个图,也是显然的。
所以综上所述,两个点连起来一条边就是最好的办法。因此这个题其实是个贪心题。
正解
cin>>n>>m;for (i=1; i<=n; i++) cin>>a[i];for (i=1; i<=m; i++){cin>>u>>v>>z;ans=max(ans,(a[u]+a[v])/(z+0.0));}printf("%.2f\n",ans);
拓扑排序
每次找入度为0的点加入序列,删掉周围的边,O(|E|)
例 计数 拓扑排序方案总数
暴搜
没办法
如果图有阶段就可以乘法原理
例 给定一张n个点m条边的拓扑图(保证1号点能走到n号点),求存在多少点,将其删去后1号点走不到n号点。n,m<=100000。
这个点为所求当且仅当能从1走到并且能走到n
如果是一个拓扑图,那么就有一个序列只有左边到右边的路径,也就是该图是无后效性,可以用dp[i]表示从1号点走到i号点的方案总数
如果某个点是所求的点,那么这个点一定不存在跨越该点的边,否则这个点就不是。因此这里可以用乘法原理,f[k]·g[k]=f[n]
最短路
Dijkstra
令dis[i]表示当前u到i的最短路是多少。
①将dis[u]=0,dis[i]=inf(i!=u)。
②寻找最小的dis[x]且x曾经没被找到过。
③若x=v,输出答案并退出。
④枚举x的所有边,用dis[x]去更新其余dis[],回到步骤②。
时间复杂度为n^2,堆优化mlogn
使用范围:不存在负权边。
SPFA
令dis[i]表示当前u到i的最短路是多少。
①将dis[u]=0,dis[i]=inf(i!=u),并将u加入队列中。(相当于一次松弛)
②设当前队首为x,枚举x。
③枚举x的所有边,用dis[x]去更新其余dis[],若dis[i]此时被更新且i当前不在队列中,将其加入队列。
④将x弹出队列,若此时队列为空,结束,否则返回步骤②。
期望O(km),最坏O(nm),网格图会卡,但是很好用
也可以判断负环:一个点进入超过n次就是负环
斯坦那树
Floyd
dp
例题
给定一本词典,这个词典共有n个单词。以及两个长度相同且在词典中的字符串A和B。每次可以将A中的一个字母变成另一个字母,要求变化后这个单词仍在词典中,要求最少操作次数,使得A能变成B。
例如DAMP->LAMP->LIMP->LIME->LIKE。
对于n个单词,若修改一步能到达连一条无向边
求最短路即可
注意无边权的最短路可以宽搜跑(复杂度宽搜<=SPFA)
并查集
int getf(int k) {return f[k]==k?f[k]:f[k]=getf(f[k]);}
学校门口有n个点(1~n),要种一堆树。种m次,每次在li~ri种一棵树。每次种完树后求有多少点还没种上树。n,m<=10000000。
线段树裸题,1kw会爆
并查集实现:
用f[i]表示从i开始向右最近的还没有种过树的
for(i=getf(i);i<=r;i=getf(i+1)){++ans;f[i]=getf(i+1);}
复杂度近似线性
给一个n节点的树,一开始边权为0,每次将一条链上的边权->1,求每次操作边权之和
树剖,复杂度
树上的并查集维护:
f[i]表示链i向上最近的没有被变成1的边
for(i=getf(i);i<=r;i=getf(i+1)){++ans;f[i]=getf(fa[i]);}
还需要LCA。
最小生成树
Kruskal:边权排序,不成环加入,并查集维护
int cmp(node i,node j) {return i.z<j.z;}for (i=1; i<=m; i++) cin>>t[i].u>>t[i].v>>t[i].z;sort(t+1,t+m+1,cmp);for (i=1; i<=m; i++)if (getf(t[i].u)!=getf(t[i].v)){f[getf(t[i].u)]=getf(t[i].v);ans+=t[i].z;}cout<<ans;
找一个最大边权最小的最小生成树->反着取
次小生成树
严格次小生成树
生成树计数
最优比率生成树
以上NOIP并不会考
打水 一个村庄有n个点,(i,j)之间都可以花费a[i][j]的代价造一条路径(有a[i][j]=a[j][i]),村民们想在这n个点选择若干点挖水井,第i个点挖水井的代价为w[i],构造一个方案使得代价最小的情况下村民们都有水喝。
一个点打通=虚拟点相连,也就是变成连通图,然后虚拟点连一条w的边,跑一遍最小生成树
二分图
如果一个无向图G中V能分成两个点集A与B,且位于A中的顶点互相之间没有边,位于B中的顶点互相之间没有边,则称这个图为二分图。
如果不存在奇环就是二分图。
从一个点出发,染色。
判断
DFS判断:一开始令颜色为0,用颜色1表示点i染成黑色,2表示染成白色,0表示未被染色。
vector <int> v[N];void dfs(int x,int y){col[x]=y;for (int i=0; i<v[x].size(); i++){if (!col[v[x][i]]) dfs(v[x][i],3-y);//没有被染过则染色成3-iif (col[v[x][i]]==col[x]) FLAG=true;//颜色相同,有奇环}}for (i=1; i<=n; i++) col[i]=0;for (i=1; i<=n; i++) if (!col[i]) dfs(i,1);if (FLAG) cout<<"NO"; else cout<<"YES";
并查集判断:将每个点A裂成两个点A与A’。若A与B之间存在边,则连一条A与B’的边,A’与B的边。若此时A与A’连通,或者B与B’连通,则该图不是二分图。(若连通则必然出现了奇环)利用并查集实现即可。
int getf(int k) {return f[k]==k?f[k]:f[k]=getf(f[k]);}for (i=1; i<=n; i++) p[i][0]=++cnt,p[i][1]=++cnt;for (i=1; i<=cnt; i++) f[i]=i;for (i=1; i<=m; i++){u-vf[getf(p[u][0])]=getf(p[v][1]);f[getf(p[u][1])]=getf(p[v][0]);if (getf(p[u][0])==getf(p[u][1]) || getf(p[v][0])==getf(p[v][1])) FLAG=true;}if (FLAG) puts("NO"); else puts("YES");
关押罪犯 二分答案判断是否是二分图或者一次从小到大加边,并依次判断能否构成二分图。
最大匹配 匈牙利(白学)算法
我tm只知道贵圈真乱
这里完全没有听懂...
bool dfs(int x){for (int i=0; i<v[x].size(); i++)if (!V[v[x][i]]){r++; st[r]=v[x][i];V[v[x][i]]=true;if (!p[v[x][i]]){p[v[x][i]]=x;return true;} elseif (dfs(p[v[x][i]])){p[v[x][i]]=x;return true;}}return false;}for (i=1; i<=|A|; i++){for (int j=1; j<=r; j++) V[st[j]]=false; r=0;if (dfs(i)) ans++;}cout<<ans<<endl;
复杂度O(nm)
再来看下午的题。
给定n个奇数,拆成二进制,只保留其中一位,求最大抑或和。
这个东西完全没有听懂...所以直接放hzk神犇的了:

搜索树
对一个图从某一点开始进行深度优先搜索。
搜索到的边构成的树称为搜索树。
在这棵树上的边称为树边,其余边称为非树边。
性质:对图求搜索树时,非树边连接的两个端点在搜索树中一定是其中一个点是另一个点的祖先。
因此对一个图,这么搜在有些题目中是有用的。
强联通分量
无向图
就是连通块
有向图的Tarjan算法
定义一个DFN为时间戳,即第几次被DFS到的
LOW[i]表示i与i的所有子孙能访问到的最小时间戳
void dfs(int x){DFN[x]=++Time;LOW[x]=DFN[x];//能访问到自己st[++r]=x;//栈V[x]=true;//表示在栈中,避免非连通更新(如6->2)的情况int R=r;for(int i=0;i<v[x].size();++i){if(!DFN[v[x][i]]){//未被访问过,先访问dfs(v[x][i]);LOW[x]=min(LOW[x],LOW[v[x][i]]);}LOW[x]=min(LOW[x],DFN[v[x][i]])}if(LOW[x]==DFN[x]){cnt++;//第cnt个强联通分量for(int i=R;i<=r;++i)p[st[i]]==cnt;r=R-1;//清空栈}}LOW[x]==DFN[x]->出现强联通分量维护一个栈
//缩点for (i=1; i<=m; i++)if (p[u[i]]!=p[v[i]])add(p[u[i]],p[v[i]]);
例 受欢迎的牛
牛群中有一个规定,若A认为B受欢迎,B认为C受欢迎,则A也会认为C受欢迎。
求存在多少牛被每头牛都认为是受欢迎的。
给定牛的头数n以及初始时所有m对形如Ai认为Bi受欢迎。
n<=50000,m<=100000。
Tarjan+缩点,变成拓扑图
缩点之后,若两个点出度为0那么互相不受对方欢迎
如果只有一个点出度为0,这个点一定被所有点都认为受欢迎。
答案就是这个点缩点前牛的个数。
割点
我们称一个点u为这个图的割点,当且仅当删去这个点以及与该点连接的所有边后,这个图不连通。
对该图进行一次Tarjan算法(这里注意在搜索树中把无向边当做有向边看。即LOW[u]=min(LOW[u],DFN[v])(v是u的祖先)的条件变为(v是u的祖先且v不是u的父亲))这样之后枚举搜索树上的所有边(u,v),若存在LOW[v]>=DNF[u],则u是割点。
这个的原理解释不清...这贴一张图吧
2-SAT
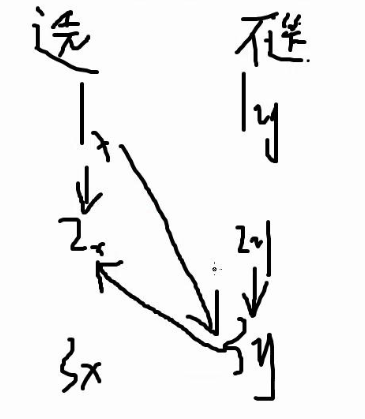
m个二元组,存在或者,判断是否有矛盾。
将每一点列成
x表示选,y表示不选
例如:
1.如果选了ai,则bi必须选择 1 1 2
2.如果没选ai,则bi必须不选 2 2 3
3.如果选了ai,则bi必须不选 3 1 3
4.如果没选ai,则bi必须选择 4 3 2
判断是否有矛盾
构完图之后,做一次Tarjan,判断是否有x,y在同一个强联通分量中,如果不在就说明是合法的。
例题
T1
给定一个n个点,m条边的图。要在这n个点选择若干点建造避难所,使得无论哪个点爆炸,每个点上的人都能逃到这个避难所去。
求最少避难所个数,以及在这个前提下的方案总数。
求出所有割点,将其它连通块缩点。
对接下来所有点,如果和多个割点相连就不管,只和一个点相连就需要建一个。
然后把点还原为连通块,需要一波乘法原理。
T2
老板给员工发工资,工资由初始工资与奖金组成。初始工资为888元,奖金为任意非负整数。有些员工比较奇怪,认为自己的工资需要比别人的工资高,老板要在满足每个人的前提下分出的钱最少。保证有解。求至少多少钱。n,m<=50000。
拓扑排序裸题。
一个点是连向它的点的最大值+1。
T3
一幢大楼有n层,有个电梯,第i层的电梯能让人上升k[i]或者下降k[i],但不能超过n或者低于1。求至少按几次电梯,才能从a走到b。
以k[i]为边建图,BFS。
T4
给定一个n个点m条带权边的图。
定义一条路径的值为这条路径上经过的边的最小值。
有Q组询问,每组询问形如x到y所有路径的最大值。
n,m,Q<=30000。
由于求最小,先跑最小生成树。
然后用一下倍增LCA。
复杂度O(nlogn)
T5
我们定义一张图的最短路为任意两点的最短路之和。
给定一个无权无向图,求每条边被删除时的图的最短路。
n<=100,m<=3000。
从1点开始BFS,可以对每个点求出最短路,构一颗最短路树,复杂度是O(nm)
如果删的边不在树上就不会有影响。
如果在树上,重新BFS再求最短路。这个操作是O(nm)
其它边是O(1)的,
而对于所有的n个点,复杂度
D5题解
标签(空格分隔): 题解 爆零
届不到的数
神奇的集合有个集合
30
暴搜
60
老师也不知道怎么做
100
直观想法先排个序,先考虑小的数字
考虑前缀集合与下一个元素的关系
下一个就是当前能找到的最小数字,如果下一个数永远大于能拼出来的数,那么一定不能拼出来。
因此排序之,如果前缀和+1比下一个元素大就符合条件。
整除
30
枚举一下
60
O,每次找一个不同的答案
for(int i=1;i<=n;++i){int a=n/i;int b=n/a;//最大的能够得到该值的东西i=b;//跳过重复}
100
先打一个表,观察一下
10 5 3 2 1
分两段,找出分界点。
就会跳过去,因此把这个解出来可以得到一个O(1)的算法。
也可以二分,不过很多坑,并不是完全单调的。也可以按上面那个式子二分,通个分乱搞。
T3
100 输出样例
这个评测机不错,我喜欢.jpg
30 60
暴搜
100
Meet in the Middle思想
问题可以根据左边的信息搞出来右边的信息,将一一对应的搜索变成一块一块的
搜索时为Q<钻石,钱,概率>
分成两堆。先暴搜第一堆,然后按钻石数量分块。
于是第一堆结果为的话,由于钻石数必须严格为k,那么我们要的第二堆就是,其中r>=m。如果按m排个序,从大到小找符合的结果,最后的q就是将这些对应的c全部加起来。这里用一个前缀和预处理。
也就是说,我们这种方式,可以将求第二堆的结果的复杂度大量缩减。
代码是啥意思...懵逼状
数学
标签(空格分隔): 数学
模P意义下运算
加减乘除都一样
快速幂
//求a^b%p//递归int ksm(int a,int b,int p){if(b==0) return l%p;int c=ksm(a,b>>1,p);c=c*1LL*c%p;if(b&1) c=c*a%p;return c;}//非递归int ksm(int a,int b,int p){int ret=l%p;while(b){if(b&1) ret=ret*a%p;b>>=1;a=a*a%p;}return ret;}
快速乘法
int ksc(int a,int b,int p){int ret=0;while(b){if(b&1) ret=(ret+a)%p;b>>=1;a=(a+a)%p;}return ret;}
例题
NOIP2013 转圈游戏 P1965
n 个小伙伴(编号从 0 到 n-1)围坐一圈玩游戏。按照顺时针方向给 n 个位置编号,从0 到 n-1。最初,第 0 号小伙伴在第 0 号位置,第 1 号小伙伴在第 1 号位置,……,依此类推。游戏规则如下:每一轮第 0 号位置上的小伙伴顺时针走到第 m 号位置,第 1 号位置小伙伴走到第 m+1 号位置,……,依此类推,第n − m号位置上的小伙伴走到第 0 号位置,第n-m+1 号位置上的小伙伴走到第 1 号位置,……,第 n-1 号位置上的小伙伴顺时针走到第m-1 号位置。
现在,一共进行了 10^k轮,请问 x 号小伙伴最后走到了第几号位置。
快速幂裸题。
素数
判断
枚举法
Miller-Rabin定理
算数基本定理
筛法
O(nloglogn)筛
bool vis[100000];for(int i=2;i<=n;++i){is(!vis[i]){for(int j=i;j*i<=n;++j)vis[j*i]=1;}}
比较好写,但是有重复
欧拉筛(O(n)筛)
int mindiv[],prime[],tot;for(int i=2;i<=n;++i){if(!mindiv[i]) mindiv[i]=i,prime[tot++]=i;for(int j=0;prime[j]*i<=n;++j){mindiv[prime[j]*i]=prime[j];if(prime[j]==mindiv[i]) break;}}
保证被最小因子筛掉。
具体证明请见hzk大佬的Note吧...
gcd
gcd(a,b)=gcd(a,a-b)(更相减损术)
gcd(a,b)=gcd(b,a%b)(辗转相除法)
因此求gcd:
int gcd(int a,int b){return b==0?a:gcd(b,a%b);}
可以预处理
lcm
与分解质因数的结合:
,
那么,
由此也可以判断是否整除.
费马小定理
如果p不是素数请使用欧拉定理
可以用来算逆元
//以下所有运算都在取模意义下
因此逆元为
要求很多需要预处理
首先预处理出一个f数组,表示n!的逆元
那么有这样的关系:,即
而对于任意一个数n,有这样的性质:
由此可以O(n)的处理出逆元。
这个东西的证明:
https://margatroid.xyz/2017-10-04-Wilson-theorem/
一个神犇的blog
实现:
int f[],inv[];f[0]=1;for(int i=1;i<=n;++i) f[i]=f[i-1]*i%p;int t=ksm(f[n],p-2,p);//快速幂,也可以exgcdfor(int i=n;i>=1;--i){inv[i]=t*f[i-1]%p;t=t*i%p;}
exgcd
//这里没有听懂老师讲的...所以接下来的内容可能并不是笔记
裴蜀定理
若a,b 是整数, 且(a,b)=d,那么对于任意的整数x,y,ax+by 都一定是d
的倍数,特别地,一定存在整数x,y,使ax+by=d 成立。
exgcd
EXgcd用于解决这样一类问题:
已知(a,b),求解一组(p,q),使得pa+qb=gcd(a,b).
解是一定存在的,根据是数论中的某个相关定理。
那么怎么求呢?
pa+qb=gcd(a,b)=gcd(b,a%b)=pb+q(a%b)=pb+q(a-a/b*b)=qa+(p-a/b*q)b
显然p、q都是单调递减的。而我们在无数次的gcd过程中,b的值最终变成0,即p*a=a,显然此时p=1,q=0是一组解。那么我们有没有办法逆推回去?答案是肯定的。
接下来的代码,就是递归的求解一组x,y
int exgcd(int a,int b,int &x,int &y){int t;if(!b) {x=1;y=0;return a;}t=exgcd(b,a%b,y,x);y-=(a/b)*x;return t;}
解不定方程和线性同余方程
- 对于方程ax+by=c,该方程有整数解的充要条件是c%gcd(a,b)=0
方程ax+by=gcd(a,b)的解为
方程ax+by=c若有整数解,则其整数解为方程ax+by=gcd(a,b)的解乘
- 当t=时x为最小正整数解,此时x=(x%t+t)%t
这几条定律是我们解不定方程的依据。
而方程axc(mod b)ax+by=c,直接上Exgcd就好辣
求逆元
void exgcd(int a,int b,int c,int &x,int &y){if(a==0){x=0,y=c/b;return;}else{int tx,ty;exgcd(b%a,a,tx,ty);x=ty-(b/a)*tx;y=tx;return;}}
例题
POJ1061 青蛙的约会
两只青蛙在网上相识了,它们聊得很开心,于是觉得很有必要见一面。它们很高兴地发现它们住在同一条纬度线上,于是它们约定各自朝西跳,直到碰面为止。可是它们出发之前忘记了一件很重要的事情,既没有问清楚对方的特征,也没有约定见面的具体位置。不过青蛙们都是很乐观的,它们觉得只要一直朝着某个方向跳下去,总能碰到对方的。但是除非这两只青蛙在同一时间跳到同一点上,不然是永远都不可能碰面的。为了帮助这两只乐观的青蛙,你被要求写一个程序来判断这两只青蛙是否能够碰面,会在什么时候碰面。我们把这两只青蛙分别叫做青蛙A和青蛙B,并且规定纬度线上东经0度处为原点,由东往西为正方向,单位长度1米,这样我们就得到了一条首尾相接的数轴。设青蛙A的出发点坐标是x,青蛙B 的出发点坐标是y。青蛙A一次能跳m米,青蛙B一次能跳n米,两只青蛙跳一次所花费的时间相同。纬度线总长L米。现在要你求出它们跳了几次以后才会碰面。
根据小学数学,我们轻而易举的列出来这么一个方程,t为时间,p为圈数:
(x+m·t)-(y+n·t)=p·L
显然用exgcd能求出来t,p。为了方便代,我们不妨先整理一下:
(n-m)t+pL=x-y
要求条件:(x-y)%gcd(n-m,L)=0
最小正整数解:t=(t%m+m%t,其中m=
标程:
#include<iostream>#include<cstdio>#include<algorithm>#include<cstring>//by zrt//problem:using namespace std;typedef long long LL;const int inf(0x3f3f3f3f);const double eps(1e-9);LL x0,y0,m,n,L;void exgcd(LL a,LL b,LL& x,LL& y,LL& d){if(b){exgcd(b,a%b,x,y,d);x-=(a/b)*y;swap(x,y);}else{d=a;x=1;y=0;}}int main(){#ifdef LOCALfreopen("in.txt","r",stdin);freopen("out.txt","w",stdout);#endifscanf("%lld%lld%lld%lld%lld",&x0,&y0,&m,&n,&L);LL x,y,a,b,c;a=m-n;b=L;c=y0-x0;LL gcd;exgcd(a,b,x,y,gcd);if(c%gcd){puts("Impossible");goto ed;}else{x=c/gcd*x;x=(x%L+L)%L;printf("%lld\n",x);}ed:return 0;}
中国剩余定理
公式法
令,
那么
拉格朗日插值法
用exgcd两两合并
首先提取前两个式子,那么
相减,
解出来一组求出来x
可以形成一个新的式子
这里并不需要互素。
POJ 1006 Biorhythms
人自出生起就有体力,情感和智力三个生理周期,分别为23,28和33天。一个周期内有一天为峰值,在这一天,人在对应的方面(体力,情感或智力)表现最好。通常这三个周期的峰值不会是同一天。现在给出三个日期,分别对应于体力,情感,智力出现峰值的日期。然后再给出一个起始日期,要求从这一天开始,算出最少再过多少天后三个峰值同时出现。
列出三个类似(k-x)%23=0的式子。
联立即可。
标程:
#include<cstdio>#include<algorithm>#include<cstring>//by zrt//problem:using namespace std;const int inf=(1<<30);typedef long long LL;const double eps=1e-8;int M=21252;void exgcd(LL a,LL b,LL&d,LL&x,LL&y){if(!b) d=a,x=1,y=0;else{exgcd(b,a%b,d,y,x);y-=(a/b)*x;}}LL R1,R2,R3;int p,e,i,D;int main(){#ifdef LOCALfreopen("in.txt","r",stdin);freopen("out.txt","w",stdout);#endifLL y,d;exgcd(M/23,23,d,R1,y);exgcd(M/28,28,d,R2,y);exgcd(M/33,33,d,R3,y);R1=(M/23*R1)%M;R2=(M/28*R2)%M;R3=(M/33*R3)%M;int tt=0;while(scanf("%d%d%d%d",&p,&e,&i,&D),~p){printf("Case %d: the next triple peak occurs in ",++tt);LL ans=(R1*p+R2*e+R3*i-D)%M;ans=(ans+M)%M;if(ans==0){printf("%d days.\n",M);}else printf("%lld days.\n",ans);}return 0;}
欧拉定理
剩余系与简系
剩余系:i的剩余系是1~i-1
简系:i的简系是剩余系中与p互素的部分
欧拉定理
欧拉函数的筛法
这一性质称为积性
而,因此可以线性筛出欧拉函数
void getphi(){int i,j;phi[1]=1;for(i=2;i<=40000;++i){if(!notprime[i]){prime[++cnt]=i;phi[i]=i-1;}for(j=1;j<=cnt;++j){if(i*prime[j]>0) break;notprime[i*prime[j]]=1;if(i%prime[j]==0){phi[i*prime[j]]=phi[i]*prime[j];break;}else{phi[i*prime[j]]=phi[i]*(prime[j]-1);}}}}
经典数学问题
余数之和
求
原式=
不妨回想一下我们上午的那道题。这个东西其实可以分成段,并且某一段区间这个值是相同的。
比如说,在[L,R],=k,那么这一段区间的余数之和就是,这个值可以用等差数列的公式搞一下。
而想要求这个东西也比较简单,R=X/L,这是因为这一段区间值其实是确定的。
Pick定理
一个格点多边形面积为内部格点数量+边上格点数量的一半-1
证明可以分割归纳。
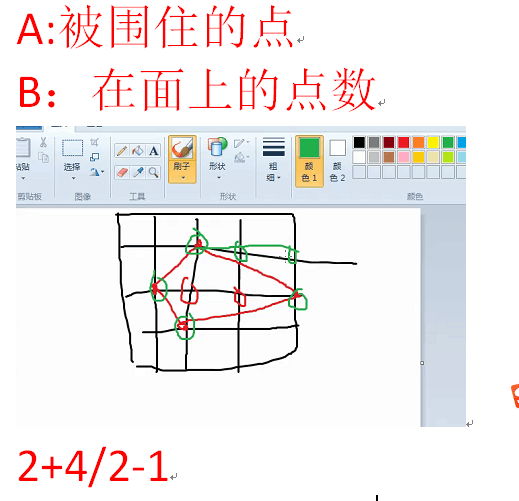
P2954
问内部的格点数量
海伦公式或者余弦定理求面积
关键是求边上的点
如果说长为a,宽为b,那么
这是因为每次的增长其实是在一条直线上,而gcd(a,b)其实是第一个交点的出现的位置。因此我们其实是求最小化的东西。
因此每边上有个整点。
矩阵乘法与矩阵快速幂
for(int i=1;i<=n;++i)for(int j=1;j<=n;++j)for(int k=1;k<=n;++k)c[i][j]+=a[i][k]*b[k][j];
由此可以快速求一个递推式
矩阵快速幂=矩阵乘法+快速幂
例 斐波那契数列快速求值
对斐波那契数列,
ksm即可
标程:
#include<iostream>#include<cstdio>#include<algorithm>#include<cstring>//by zrt//problem:using namespace std;typedef long long LL;const int inf(0x3f3f3f3f);const double eps(1e-9);LL x0,y0,m,n,L;void exgcd(LL a,LL b,LL& x,LL& y,LL& d){if(b){exgcd(b,a%b,x,y,d);x-=(a/b)*y;swap(x,y);}else{d=a;x=1;y=0;}}int main(){#ifdef LOCALfreopen("in.txt","r",stdin);freopen("out.txt","w",stdout);#endifscanf("%lld%lld%lld%lld%lld",&x0,&y0,&m,&n,&L);LL x,y,a,b,c;a=m-n;b=L;c=y0-x0;LL gcd;exgcd(a,b,x,y,gcd);if(c%gcd){puts("Impossible");goto ed;}else{x=c/gcd*x;x=(x%L+L)%L;printf("%lld\n",x);}ed:return 0;}
分治乘法
例如,
对于,(a + b)(c + d) = ac + ad + bc + bd
然后求出ad+bc可以求得结果
这样分治一下可以快一点
组合数
《组合数学》
求法:
C[n][m]=C[n-1][m]+C[n-1][m-1]
Lucas定理 C[n][m]%p=C[n%p][m%p]*C[n/p][m/p]
因此C[abcde][fghij]=C[a][f]*C[b][g]*C[c][h]*C[d][i]*C[e][j]
D6题解
标签(空格分隔): 题解
T1
考虑相邻元素的大小关系,是递增的。
如果相邻的两个不对判一下。
比较糟的是一个大的后面连上一个递增的,特判一下即可。
也可以直接判断删除一个元素之后是否有序
#include <cstdio>#include <cstring>#include <algorithm>using namespace std;int n;int a[1000005];bool check(int pos){//判断删除一个后是否有序for(int i=1;i<n;i++){if(i == pos || i+1 == pos) continue;if(a[i]>a[i+1]) return 0;}if(pos >=2 && pos<n&& a[pos-1] > a[pos+1]) return 0;return 1;}int main(){freopen("sort.in","r",stdin);freopen("sort.out","w",stdout);scanf("%d",&n);for(int i=1;i<=n;i++) scanf("%d",&a[i]);bool no = 0;for(int i=1;i<n;i++){if(a[i]>a[i+1]){if( check(i) || check(i+1) ){break;}else{no = 1;break;}}}if(no) puts("NO");else puts("YES");return 0;}
T2
解同余方程组
30%
用昨天的公式,
60%
用昨天的公式,exgcd求逆元
100%
需要合并
联立,
然后exgcd(a1,-a2,k1,k2)
解出来x,y后解出k1k2使之成立
而这个x就是同时满足上面两个式子的东西
合并之后可以得到 x%(a1a2)=x0
标程:
#include <cstdio>#include <cstring>#include <algorithm>#include <cassert>#include <cmath>using namespace std;typedef long long LL;int a[4],b[4];LL A,B;LL gcd(LL a,LL b){return b==0?a:gcd(b,a%b);}LL lcm(LL a,LL b){return a/gcd(a,b)*b;}LL exgcd(LL a,LL b,LL &x,LL &y){LL t;if(!b) {x=1;y=0;return a;}t=exgcd(b,a%b,y,x);y-=(a/b)*x;return t;}LL mulmod(LL a,LL b,LL p){LL ret = 0;while(b){if(b&1) ret=(ret+a)%p;b>>=1;a=(a+a)%p;}return ret;}void merge(LL a,LL b){LL k1,k2;LL g = exgcd(A,-a,k1,k2);LL M = lcm(A,a);// assert(abs((B-b)/g*1.*k1)<=1e18);k1 = mulmod((B-b)/g,k1,M);// assert(abs(k1*1.*A)<=1e18);LL x = B-mulmod(k1,A,M);// printf("# %.3f\n",k1*1.*A);// assert(x+k1*A == B);// assert(x+(B-b)/g*k2*a == b);// printf("# %lld %lld %lld %lld\n",x,k1,A,B);assert(((x%A)+A)%A == B);x = ((x%M)+M)%M;assert(x%A == B);assert(x%a == b);A=M;B=x;}int main(){freopen("mod.in","r",stdin);freopen("mod.out","w",stdout);for(int i=0;i<4;i++) scanf("%d%d",&a[i],&b[i]);A=1,B=0;for(int i=0;i<4;i++){merge(a[i],b[i]);}// printf("# %lld\n",A);printf("%lld\n",B);return 0;}
顺便推销一波神奇的大数翻倍法
T3
回文串长度是可以二分的。
首先预处理,奇数以某一个字符为中心,偶数以某一个空隙为中心。
本质不同的回文串最多有O(n)个,通过hash记下答案可以求出来包含多少回文串。
#include <cstdio>#include <cstring>#include <algorithm>#include <map>using namespace std;typedef unsigned long long ULL;typedef long long LL;char s[10005];ULL h[10005],rh[10005],pw[10005];int L;ULL hs(int l,int r){return h[r]-h[l-1]*pw[r-l+1];}ULL rhs(int l,int r){return rh[l] - rh[r+1]*pw[r-l+1];}struct N{int a[26];bool ok(){int b[26];for(int i=0;i<26;i++) b[i]=a[i];sort(b,b+26);for(int i=0;i<25;i++){if(b[i]>0&& b[i] == b[i+1]) return true;}return false;}void clear(){memset(a,0,sizeof a);}};LL ans=0;map<ULL,LL> num;map<ULL,N> A;//奇数void solve_odd(){//二分判断是否出便捷,判断标准为正反读是否一样for(int i=1;i<=L;i++){int l = 1,r = min(i,L-i+1)+1;while(r-l>1){int mid = (l+r)/2;if(hs(i-mid+1,i+mid-1)== rhs(i-mid+1,i+mid-1)) l=mid;else r=mid;}int p=l;int tmp = p;while(tmp>=1&&num.find(hs(i-tmp+1,i+tmp-1))==num.end()) tmp--;//两边删直到取出算过的东西为止 ,hash判断LL sum = 0;N st;st.clear();if(tmp>=1){sum=num[hs(i-tmp+1,i+tmp-1)];st = A[hs(i-tmp+1,i+tmp-1)];}while(tmp<p){st.a[s[i+tmp]-'a']+= (tmp == 0?1:2);if(st.ok()) sum++;num[hs(i-tmp,i+tmp)] = sum;A[hs(i-tmp,i+tmp)] = st;tmp++;}ans+=sum;// printf("# %d %lld\n",i,sum);}}//偶数void solve_even(){A.clear();num.clear();for(int i=1;i<L;i++){// printf("### %d\n",i);int l = 1,r = min(i,L-i)+1;while(r-l>1){int mid = (l+r)/2;if(hs(i-mid+1,i+mid)== rhs(i-mid+1,i+mid)) l=mid;else r=mid;}int p=l;int tmp = p;while(tmp>=1&&num.find(hs(i-tmp+1,i+tmp))==num.end()) tmp--;LL sum = 0;N st;st.clear();// printf("## %d\n",p);if(tmp>=1){sum=num[hs(i-tmp+1,i+tmp)];st = A[hs(i-tmp+1,i+tmp)];}while(tmp<p){// printf("# %d %lld\n",tmp,sum);st.a[s[i+tmp+1]-'a']+= 2;if(st.ok()) sum++;num[hs(i-tmp,i+tmp+1)] = sum;A[hs(i-tmp,i+tmp+1)] = st;tmp++;}ans+=sum;// printf("# %d %lld\n",i,sum);}}int main(){freopen("str.in","r",stdin);freopen("str.out","w",stdout);scanf("%s",s+1);L=strlen(s+1);s[0]='#';pw[0]=1;for(int i=1;i<=L;i++) pw[i] = pw[i-1]*13131 ;for(int i=1;i<=L;i++) h[i] = h[i-1]*13131 + s[i];//正着求hashfor(int i=L;i>=1;i--) rh[i] = rh[i+1]*13131 + s[i];//反着求solve_odd();solve_even();printf("%lld\n",ans);fclose(stdout);return 0;}
字符串
标签(空格分隔): 字符串
事先声明,本Note并不是用来学习的。
因为后面的东西在下也没有听懂。
如果有什么建议的话欢迎指正吧。
hash
hash就是一个字符串到整数的映射,可以快速比较字符串是否相等
比较整数是O(1)的,可以快速比较
hash相等的两个字符串大概率相等,不等的话一定不等(准确判否)
RK-hash
将字符串看做base进制大整数。
例如,小写字母可以看做一个27进制的数字
每一位乘进制+当前这位,同时进行取模。
hash[i]=(hash[i-1]*base+s[i])%p
base可以随便取,31 131 13131是比较好的。
并且最好不要前导0。
p最好是longlong范围内的一个素数,如1e18+9 23333333333333333
也可以unsinged long long 自动溢出,不过有可能被卡掉。
也可以多取几个素数,提高正确率。
用map维护即可
取出s中[L,R]的hash
//以下所有运算都是在模大质数意义下进行。
首先取出hash[R]、hash[L-1]
然后在hash[L-1]对齐相减
hash[L,R]=hash[R]-hash[L-1]*pow(base,r-l+1)
由于幂只与区间长度有关,所以可以预处理。这样查询区间hash也是O(1)的。
hash合并
知道B的长度L,在A后面补位
hash[A+B]=hash[A]*pow(base,L)%p+hash[B]
求最长公共前缀(LCP)
二分查找前缀的hash值,log复杂度
判断字典序大小
求出LCP比较后一位即可
哈希表
用一个链表,O(1)查询
vector<ULL> v[1005];v[h%q].push_back(h);
X-Or版本 RK-hash
hash[i]=(hash[i-1]*base^s[i])%p
无法利用前缀和性质,但可以避免被卡
POJ2758
给定一个字符串, 要求维护两种操作:在字符串中插入一个字符,询问某两个位置开始的最长公共前缀。插入操作<=200, 字符串长度<=5w, 查询操作<=2w。
插入字符直接重构即可
查询是裸LCP
下面的可以当做LCP模板
#include<cstdio>#include<algorithm>#include<cstring>using namespace std;int L,cc;char s[55005];char tmps[10];int c[55005];unsigned long long hash[55005];unsigned long long pow[55005];int main(){// freopen("data.in","r",stdin);pow[0]=1;for(int i=1;i<55005;i++) pow[i]=pow[i-1]*131;scanf("%s",s+1);cc=L=strlen(s+1);//s 1..Lfor(int i=1;i<=L;i++) {c[i]=c[i-1]+1;}for(int i=1;i<=L;i++){hash[i]=hash[i-1]*131+s[i]-'a'+1;}// add(2,1);// printf("%d %d\n",getpos(1),getpos(3));int n;scanf("%d",&n);while(n--){scanf("%s",tmps);/// putchar('#');// for(int i=1;i<=cc;i++){//// printf(" %d",c[i]);//// }// puts("");if(tmps[0]=='I'){scanf("%s",tmps);int pos;scanf("%d",&pos);if(pos>L){s[L+1]=tmps[0];hash[L+1]=hash[L]*131+s[L+1]-'a'+1;}else{for(int i=L;i>=pos;i--) s[i+1]=s[i];s[pos]=tmps[0];for(int i=pos;i<=L+1;i++) hash[i]=hash[i-1]*131+s[i]-'a'+1;int initpos=lower_bound(c+1,c+1+cc,pos)-c;for(int i=initpos;i<=cc;i++){c[i]++;}}L++;}else{int x,y;scanf("%d%d",&x,&y);x=c[x];y=c[y];int l=0,r=min(L-x,L-y)+2,mid;while(r-l>1){mid=(l+r)/2;if(hash[x+mid-1]-hash[x-1]*pow[mid]==hash[y+mid-1]-hash[y-1]*pow[mid]) l=mid;else r=mid;}printf("%d\n",l);}}return 0;}
BZOJ3555
N个长度为L的字符串,问有多少对只有一位不同。
对N个字符串求整串hash
然后不考虑某一类看有多少相同也就是删去某一位
用一个map来存储
#include<cstdio>#include<cstring>#include<algorithm>#include<map>using namespace std;int n,m,k;long long ans;typedef unsigned long long llu;char s[30005][205];llu hash[30005];map<llu,int> mp;llu pow[205];int main(){scanf("%d%d%d",&n,&m,&k);pow[0]=1;for(int i=1;i<=m;i++) pow[i]=pow[i-1]*13131;for(int i=0;i<n;i++){scanf("%s",s[i]);}for(int i=0;i<n;i++){for(int j=0;j<m;j++){hash[i]=hash[i]*13131+s[i][j];}}for(int p=0;p<m;p++){mp.clear();for(int i=0;i<n;i++){llu h=hash[i]-s[i][p]*pow[m-p-1];mp[h]++;}for(map< llu ,int>::iterator it=mp.begin();it!=mp.end();it++){if(it->second){ans+=it->second*(it->second-1)/2;}}}printf("%lld\n",ans);return 0;}
KMP
朴素匹配算法
一位一位的匹配
O(nm)
KMP匹配
//这个东西的原理由于在下水平有限真的说不清..所以实在不行的话就背代码吧
//hzk神犇讲的要好多了..ORZ!
用nxt数组表示最长的后缀=前缀位置
例如
序:12345678
字:abcababc
值:00012123
预处理nxt时,假设nxt[L]是处理完毕的。处理nxt[L+1]时,首先试图加一个元素上去,看能不能行,否则我们就不断的取nxt直到符合条件。
假设模式串[L,k]与主串[i,j]是可以匹配的,并且在j处不相等。现在模式串向后错一位,而我们现在要匹配[L+1],对应的是[i+1],由上可知[L+1,k]与[i+1,j]可匹配,因此我们通过nxt这个数组变换一下,就可以将匹配的后缀转化为前缀,跳过一部分继续匹配。
模板:
串为s,tint j=0;for(int i=2;i<=m;i++){while(j&&s[i]!=s[j+1]) j=nxt[j];if(s[i]==s[j+1]) j++;nxt[i]=j;}char t[]; nint j =0;for(int i=1;i<=n;i++){while(j && t[i]!=s[j+1]) j=nxt[j];if(t[i] == s[j+1]) j++;if(j==m){//...j=nxt[j];}}
由于后缀=前缀没有二分性质,只能递推求得。
所以不能hash。
最小循环节
长度为len-next[len]
如果l整除len-next[len]那么说明这个串可以完整被分成循环节。
否则就有l%(len-next[len])是除去循环节的部分。
POJ2752
求所有x使得串的长度为x的前缀和x的后缀相等。
不停取nxt即可。
#include<cstdio>#include<algorithm>#include<cstring>//by zrt//problem:using namespace std;char s[400005];int nxt[400005];int num[400005];int tot;int main(){#ifdef LOCALfreopen("in.txt","r",stdin);freopen("out.txt","w",stdout);#endifwhile(~scanf("%s",s)){int j=-1;nxt[0]=j;int l=strlen(s);for(int i=1;i<l;i++){while((~j)&&s[j+1]!=s[i]) j=nxt[j];if(s[i]==s[j+1]) j++;nxt[i]=j;}tot=0;for(int i=l-1;~i;i=nxt[i])num[++tot]=i+1;for(int i=tot;i;i--){printf("%d ",num[i]);}putchar('\n');}return 0;}
BZOJ3670
求num数组一一对于字符串S的前i个字符构成的子串,既是它的后缀同时又是它的前缀,并且该后缀与该前缀不重叠,将这种字符串的数量记作num[i]。
卡着不重叠的界来递推,一旦超范围就强制搞回去。
#include<cstdio>#include<cstring>#include<algorithm>using namespace std;int n;int l;const int MAXN=1000005;char s[MAXN];int nxt[MAXN];int num[MAXN];int sum[MAXN];const int mod=1e9+7;void solve(){nxt[1]=0;int L=strlen(s+1);int j=0;for(int i=2;i<=L;i++){while(j&&s[j+1]!=s[i]) j=nxt[j];if(s[j+1]==s[i]) j++;nxt[i]=j;}memset(sum,0,sizeof sum);memset(num,0,sizeof num);sum[0]=1;for(int i=1;i<=L;i++) sum[i]=sum[nxt[i]]+1;j=0;for(int i=2;i<=L;i++){while(j&&s[j+1]!=s[i]) j=nxt[j];if(s[j+1]==s[i]) j++;while(j>i/2) j=nxt[j];//防止超过i/2导致重叠num[i]=sum[j]-1;}// for(int i=1;i<=L;i++) printf("%d ",num[i]);// puts("");long long ans=1;for(int i=1;i<=L;i++) ans=ans*(num[i]+1)%mod;printf("%lld\n",ans);}int main(){scanf("%d",&n);for(int i=0;i<n;i++){scanf("%s",s+1);solve();}return 0;}
D6T3
见题解
Manachar
hash:O(nlogn)
abba aba
偶数中心在空隙,奇数中心为某一字符
可以加一个符号将偶数变成奇数,如
#a#b#b#a#,回文串半径成为两倍
预处理一个数组表示能扩展的半径
abcbaabcba
1131111311
//暴力for(int i=1;i<=L;++i){r[i]=1;while(s[i-r[i]]==s[i+r[i]]) r[i]++}在边上加一个边界可以判断结束,最坏O(n^2)
如果我们要拓展i,我们找到i关于id的对称点(2id-i),该点的回文半径是已知的。
例如,
abacabac
12345678
求6处的b时,id=3,所以对称为2处的b。因此r[i]初值为r[2id-i],但观察发现其实还是能扩展的,所以还需要继续暴力。
int mx=max{i+r[i]-1}//能够达到最靠右的元素int id;//mx取到最大值时取到的ifor(int i=1;i<=L;++i){r[i]=min(r[2id-i],mx-i);//有可能超过半径while(s[i-r[i]]==s[i+r[i]]) r[i]++;if(i+r[i]-1>mx) mx=i+r[i]-1,id=i;}复杂度O(n).
BZOJ2342
第一段正hash=第二段反hash=第三段正hash=第四段反hash
也可以在manachar r[i]++处加一个check函数判断是否是双回文
BZOJ3676
由于回文串删掉两边仍是回文串,所以其实可以建一棵树。
查询字符串出现次数,然后可以打一个+1标记
打完以后再从叶到根push一遍,得到了所有回文串对应的出现次数
以hash来建树。
exKMP
a串的后缀与b串LCP
先求b串后缀与自己的LCP
//暴力for(int i=1;i<=n;++i){p[i]=0;while(b[i+p[i]]==b[p[i]+1]) ++p[i];}
。。。没听懂,我腿裙吧.jpg
for(int i=1;i<=n;++i){p[i]=min(mx-i,p[i-id]);while(b[i+p[i]]==b[p[i]+1]) ++p[i];if(i+p[i]>mx){id=i;mx=i+p[i];}}
tyvj1068
给你两个串A,B,可以得到从A的任意位开始的子串和B匹配的长度。
给定K个询问,对于每个询问给定一个x,求出匹配长度恰为x的位置有多少个。
模板题
#include<bits/stdc++.h>using namespace std;int n,m,k;char sa[210005],sb[210005];int p[200005],q[200005];int ans[200005];int main(){scanf("%d%d%d%s%s",&n,&m,&k,sa,sb);//calc sbint mx=0,id=0;p[0]=m;for(int i=1;i<m;i++){if(i<=mx){p[i]=min(mx-i,p[i-id]);}while(sb[i+p[i]]&&sb[i+p[i]]==sb[p[i]]) p[i]++;if(i+p[i]>mx){mx=i+p[i];id=i;}}mx=0,id=0;for(int i=0;i<n;i++){if(i<=mx){q[i]=min(mx-i,p[i-id]);}while(sa[i+q[i]]&&sb[q[i]]&&sa[i+q[i]]==sb[q[i]]) q[i]++;if(i+q[i]>mx){mx=i+q[i];id=i;}}for(int i=0;i<n;i++) ans[q[i]]++;for(int i=0,x;i<k;i++){scanf("%d",&x);printf("%d\n",ans[x]);}return 0;}
Trie树
每个节点代表一个串
int trie[100000][26];int tot;void insert(char* s){int p=0;for(int i=0;s[i];++i){if(trie[p][s[i]-'a') id=trie[p][s[i]-'a'];else id=trie[p][s[i]-'a']=++tot;}flag[p]++;//记录以p结尾的有几个}
比较
直接插入,DFS,遇见flag>0的就输出来
LCP
两个点的LCA的深度是LCP
POJ3764
已知数组a,求max{a[i]^a[j]}
对每个a[i],找一个抑或最大的a[j]
由于1^1=0,1^0=1,0^0=0
将每个数变成二进制串,将所有的串建成Trie树,从根开始走,然后贪心,优先为1。
AC自动机
把Trie树上不存在的孩子用它fail节点的孩子补出来。
fail节点的概念与KMP的next类似,可以用一次bfs来求出。
若trie[i][x]存在,则fail[trie[i][x]]=trie[fail[i]][x]。
否则,trie[i][x]=trie[fail[i]][x]。
这啥玩意啊.jpg
hdu2222
多模式串匹配模板题。
#include<cstdio>#include<cstring>#include<algorithm>#include<queue>//by zrt//problem:using namespace std;int tt;int n;int pos;int nxt[500005][26];int fail[500005];int flag[500005],ok[500005];int newnode(){memset(nxt[pos],0,sizeof nxt[pos]);fail[pos]=flag[pos]=ok[pos]=0;return pos++;}char s[1000005];void insert(char*s){int p=0;for(int i=0;s[i];i++){p=nxt[p][s[i]-'a']?nxt[p][s[i]-'a']:nxt[p][s[i]-'a']=newnode();}flag[p]++;}queue<int> q;void makefail(){q.push(0);while(!q.empty()){int x=q.front();q.pop();for(int i=0;i<26;i++){if(nxt[x][i]){q.push(nxt[x][i]);if(x)fail[nxt[x][i]]=nxt[fail[x]][i];}else nxt[x][i]=nxt[fail[x]][i];}}}bool vis[500005];int find(char*s){memset(vis,0,sizeof vis);int p=0;int ans=0;for(int i=0;s[i];i++){p=nxt[p][s[i]-'a'];for(int j=p;j;j=fail[j]){if(vis[j]) break;vis[j]=1;if(flag[j]) ok[j]=1;}}for(int i=1;i<pos;i++) if(ok[i]) ans+=flag[i];return ans;}int main(){#ifdef LOCALfreopen("in.txt","r",stdin);freopen("out.txt","w",stdout);#endifscanf("%d",&tt);while(tt--){pos=1;memset(nxt[0],0,sizeof nxt[0]);scanf("%d",&n);for(int i=0;i<n;i++){scanf("%s",s);insert(s);}makefail();scanf("%s",s);printf("%d\n",find(s));}return 0;}
bzoj2938/hzwer5049
二进制病毒审查委员会最近发现了如下的规律:某些确定的二进制串是病毒的代码。如果某段代码中不存在任何一段病毒代码,那么我们就称这段代码是安全的。现在委员会已经找出了所有的病毒代码段,试问,是否存在一个无限长的安全的二进制代码。
示例:
例如如果{011, 11, 00000}为病毒代码段,那么一个可能的无限长安全代码就是010101…。如果{01, 11, 000000}为病毒代码段,那么就不存在一个无限长的安全代码。
任务:
请写一个程序:
读入病毒代码;
判断是否存在一个无限长的安全代码;
将结果输出
如果Trie图中存在环就能生成无限长代码。否则就挂了。
找环拓扑即可。
D7题解
标签(空格分隔): 题解 爆零
T1
60
暴力
另外20
简单的容斥
100
容斥硬搞
暴力枚举一下,求一个lcm然后算一算
#include<iostream>#include<algorithm>#include<cstdio>#include<cstring>#include<cmath>#include<cstdlib>using namespace std;typedef long long ll;typedef long double ld;typedef pair<int,int> pr;const double pi=acos(-1);#define rep(i,a,n) for(int i=a;i<=n;i++)#define per(i,n,a) for(int i=n;i>=a;i--)#define Rep(i,u) for(int i=head[u];i;i=Next[i])#define clr(a) memset(a,0,sizeof a)#define pb push_back#define mp make_pair#define putk() putchar(' ')ld eps=1e-9;ll pp=1000000007;ll mo(ll a,ll pp){if(a>=0 && a<pp)return a;a%=pp;if(a<0)a+=pp;return a;}ll powmod(ll a,ll b,ll pp){ll ans=1;for(;b;b>>=1,a=mo(a*a,pp))if(b&1)ans=mo(ans*a,pp);return ans;}ll gcd(ll a,ll b){return (!b)?a:gcd(b,a%b);}ll read(){ll ans=0;char last=' ',ch=getchar();while(ch<'0' || ch>'9')last=ch,ch=getchar();while(ch>='0' && ch<='9')ans=ans*10+ch-'0',ch=getchar();if(last=='-')ans=-ans;return ans;}void put(ll a){if(a<0)putchar('-'),a=-a;int top=0,q[20];while(a)q[++top]=a%10,a/=10;top=max(top,1);while(top--)putchar('0'+q[top+1]);}//headll ans=0;int n,m,a[25];ll Gcd(ll a,ll b){if(!b)return a;return gcd(b,a%b);}void dfs(int dep,ll t,int flag){if(t>n)return;if(dep==m+1){ans+=n/t*flag;return;}dfs(dep+1,t,flag);dfs(dep+1,t/Gcd(t,a[dep])*a[dep],-flag);}int main(){n=read();m=read();rep(i,1,m)a[i]=read();dfs(1,1,1);cout<<ans<<endl;return 0;}
T2
30
取出,排序,中位数即可,然后再排个序
60
固定左端点
新出现一个区间就用下一个元素插排O(n)更新一下
最后求k大
80
求第k大可以二分答案。
以中位数>=k的区间个数有多少来二分
那么大于等于k设置为1,否则设置为-1.如果这些和加起来大于等于0,就说明这个区间的中位数是>=k的。
暴力统计每个区间的总和即可
100
考虑上述做法,相当于统计S[R]>S[L-1]的对数。
其实相当于求顺序对。用树状数组维护即可。
#include<iostream>#include<algorithm>#include<cstdio>#include<cstring>#include<cmath>#include<cstdlib>using namespace std;typedef long long ll;typedef long double ld;typedef pair<int,int> pr;const double pi=acos(-1);#define rep(i,a,n) for(int i=a;i<=n;i++)#define per(i,n,a) for(int i=n;i>=a;i--)#define Rep(i,u) for(int i=head[u];i;i=Next[i])#define clr(a) memset(a,0,sizeof a)#define pb push_back#define mp make_pair#define fi first#define sc secondld eps=1e-9;ll pp=1000000007;ll mo(ll a,ll pp){if(a>=0 && a<pp)return a;a%=pp;if(a<0)a+=pp;return a;}ll powmod(ll a,ll b,ll pp){ll ans=1;for(;b;b>>=1,a=mo(a*a,pp))if(b&1)ans=mo(ans*a,pp);return ans;}ll read(){ll ans=0;char last=' ',ch=getchar();while(ch<'0' || ch>'9')last=ch,ch=getchar();while(ch>='0' && ch<='9')ans=ans*10+ch-'0',ch=getchar();if(last=='-')ans=-ans;return ans;}//head#define N 110000int a[N],b[N],c[N],d[N],e[N],n,m;ll k;int lowbit(int x){return x&(-x);}int bin(int k){int l=1,r=m;while(l<r){int mid=(l+r)/2;if(k<=d[mid])r=mid;else l=mid+1;}return l;}void add(int x){for(;x<=m;x+=lowbit(x))e[x]++;}int find(int x){int ans=0;for(;x;x-=lowbit(x))ans+=e[x];return ans;}ll check(int k){c[0]=0;rep(i,1,n)c[i]=c[i-1]+(a[i]>=k);rep(i,0,n)c[i]=c[i]*2-i,d[i+1]=c[i];sort(d+1,d+n+2);d[0]=1;rep(i,2,n+1)if(d[i]!=d[d[0]])d[++d[0]]=d[i];m=d[0];ll ans=0;rep(i,0,n)c[i]=bin(c[i]);rep(i,0,m)e[i]=0;rep(i,0,n)if(i&1)add(c[i]);else ans+=find(c[i]-1);rep(i,0,m)e[i]=0;rep(i,0,n)if((i&1)==0)add(c[i]);else ans+=find(c[i]-1);return ans;}int main(){n=read();k=read();rep(i,1,n)a[i]=read(),b[i]=a[i];sort(b+1,b+n+1);b[0]=1;rep(i,2,n)if(b[i]!=b[b[0]])b[++b[0]]=b[i];int l=1,r=b[0];while(l<r){int mid=(l+r)/2+1;ll tt=check(b[mid]);if(tt==k){cout<<b[mid]<<endl;return 0;}if(check(b[mid])>k)l=mid;else r=mid-1;}cout<<b[l]<<endl;return 0;}
T3
30
枚举每个区间,排序,求前缀和,爆算一下
60
枚举区间,右端点递增,插入排序,然后前缀和维护
80
一个数字在所有区间被统计的次数总和就是小于它的区间个数总和
对于j来说,比k小的数的下标有
那么这些东西的贡献,在(n-j+1)个区间中,贡献总和就是
也就是求出所有比k小的数的位置的下标总和
对于t在k右边,反过来求即可。
枚举比它小的数可以暴力一下,总复杂度
100
我们的操作是查询比它小的下标总和,将这个数存入数组中。
可以用树状数组来维护,也可以归并排序。
#include<iostream>#include<algorithm>#include<cstdio>#include<cstring>#include<cmath>#include<cstdlib>using namespace std;typedef long long ll;typedef long double ld;typedef pair<int,int> pr;const double pi=acos(-1);#define rep(i,a,n) for(int i=a;i<=n;i++)#define per(i,n,a) for(int i=n;i>=a;i--)#define Rep(i,u) for(int i=head[u];i;i=Next[i])#define clr(a) memset(a,0,sizeof a)#define pb push_back#define mp make_pair#define fi first#define sc secondld eps=1e-9;ll pp=1000000007;ll mo(ll a,ll pp){if(a>=0 && a<pp)return a;a%=pp;if(a<0)a+=pp;return a;}ll powmod(ll a,ll b,ll pp){ll ans=1;for(;b;b>>=1,a=mo(a*a,pp))if(b&1)ans=mo(ans*a,pp);return ans;}ll read(){ll ans=0;char last=' ',ch=getchar();while(ch<'0' || ch>'9')last=ch,ch=getchar();while(ch>='0' && ch<='9')ans=ans*10+ch-'0',ch=getchar();if(last=='-')ans=-ans;return ans;}//head#define N 1100000pr a[N];int c1[N],c2[N],n;ll A,B,C;int lowbit(int x){return x&(-x);}void add(int *c,int x,int w){c[0]+=w;if(c[0]>=pp)c[0]-=pp;for(;x<=n;x+=lowbit(x)){c[x]=c[x]+w;if(c[x]>=pp)c[x]-=pp;}}int find(int *c,int x){int ans=0;for(;x;x-=lowbit(x)){ans+=c[x];if(ans>=pp)ans-=pp;}return ans;}int main(){cin>>n>>a[1].fi>>A>>B>>C;a[1].sc=1;rep(i,2,n){a[i].sc=i;a[i].fi=(a[i-1].fi*A+B)%C;}sort(a+1,a+n+1);ll ans=0;rep(i,1,n){int t1=find(c1,a[i].sc);int t2=c2[0]-find(c2,a[i].sc-1);t2=(t2+pp)%pp;int t3=(1ll*t1*(n-a[i].sc+1)+1ll*t2*a[i].sc)%pp;t3=(t3+1ll*a[i].sc*(n-a[i].sc+1))%pp;ans=(ans+1ll*t3*a[i].fi)%pp;add(c1,a[i].sc,a[i].sc);add(c2,a[i].sc,n-a[i].sc+1);}cout<<ans<<endl;return 0;}
基础算法
标签(空格分隔): 二分 贪心
二分
POJ2976
给出n个物品,每个物品有两个属性a和b,选择n-k个元素,询问sum{ai}/sum{bi}的最大值。
分数规划
等价于
令,可以通过这个二分答案
第k大区间2
定义一个区间的值为其中所有数的平均数。
现给出n个数,求将所有区间的值排序后,第K大的值为多少。
求第k大一般二分。
分数规划
二分答案,等价于找多少区间>=k
[L,R]>=k等价于
等价于
如果存在这样的区间,那么就是所求。
求一遍的前缀和,相当于求顺序对的个数
POJ2728
给定一张图,每条边有一个收益值和一个花费值,求一个生成树,要求花费/收益最小,输出这个值
分数规划
即
即
跑一遍最大生成树,即从大到小Kruskal即可
POJ3621
给定一张图,边上有花费,点上有收益,点可以多次经过,但是收益不叠加,边也可以多次经过,但是费用叠加。求一个环使得收益和/花费和最大,输出这个比值。
分数规划
将环边权取负,等价于求负权圈
所有点入队列,跑SPFA,如果进入m次就有负权圈。
第k大区间3
定义一个区间的值为其众数出现的次数。
现给出n个数,求将所有区间的值排序后,第K大的值为多少。
终于tm的不是分数规划
枚举左右边界,然后暴力的统计一下
建桶,维护一个max,就可以求出众数的出现次数。
首先确定左端点,右端点每次加1
由[L,R]转化为[L,R+1]是O(1)的,因为可以直接将下一个数扔到桶里。这样就是
枚举右端点,数多少左端点满足条件
如果[L,R]合法,那么[L-k,R]与[L,R+t]均是合法的
可以记录一下i上一次出现的位置,如果该位置合法,那么[i-k,R]就是合法的。
当检验t时令L=0,当R扫到一个数,找出这个数t次前出现的位置,
用这个数字更新L,那么这个区间就是合法的。
可以以权值为第一关键字、位置为第二关键字进行排序,就可以O(1)找出t次前出现的位置查询。
NOIP2015 跳石头(Luogu P2678)
一年一度的“跳石头”比赛又要开始了!
这项比赛将在一条笔直的河道中进行,河道中分布着一些巨大岩石。组委会已经选择好了两块岩石作为比赛起点和终点。在起点和终点之间,有 N 块岩石(不含起点和终点的岩石)。在比赛过程中,选手们将从起点出发,每一步跳向相邻的岩石,直至到达终点。
为了提高比赛难度,组委会计划移走一些岩石,使得选手们在比赛过程中的最短跳跃距离尽可能长。由于预算限制,组委会至多从起点和终点之间移走 M块岩石(不能移走起点和终点的岩石)。
二分最短距离
把离岸边的扔掉,再去找下一个,那么对于下一块,优先选择下一块扔(我真的说不清..),所以这么贪一下就行,可以得到最小的需要去除的数量。
由此可以写出check()函数。
NOIP2010 关押罪犯
有两个监狱,N个犯人,M对关系,每对关系描述一对犯人如果在一个监狱将会产生一个冲突值。任意安排犯人的分配,使得产生的最大冲突值最小
二分k,判断冲突关系前k大的矛盾能不能解决。
判断矛盾可以染色,a编1,矛盾编0,矛盾的矛盾编0...BFS一下判断矛盾
贪心
哈夫曼树
总之先贴一下
http://blog.csdn.net/shuangde800/article/details/7341289
NOI2015 荷马史诗
相当于每次能合并k堆果子
不求立刻理解..那您列出来干什么啊orzzzzz
阿狸和桃子的游戏
有一个有点权有边权的图,然后两个人分别给每个点染色。对于一个点的点权将会赐予染了这个点的人。对于一条边的边权,若它连接的两个点被同一个人染了,那么边权会赐予这个人。它们两个人都想让自己的分数减去对方的分数尽可能多。输出最终双方的分数差。
将边权剖开加诸两端,不会影响结果。
一个人选最大,一个人选比较小的
读入时处理一下排个序就好了。
Usaco2007 Novtanning
奶牛们计划着去海滩上享受日光浴。为了避免皮肤被阳光灼伤,所有C(1 <= C <= 2500)头奶牛必须在出门之前在身上抹防晒霜。第i头奶牛适合的最小和最 大的SPF值分别为min和max()。如果某头奶牛涂的防晒霜的SPF值过小,那么阳光仍然能 把她的皮肤灼伤;如果防晒霜的SPF值过大,则会使日光浴与躺在屋里睡觉变得 几乎没有差别。为此,奶牛们准备了一大篮子防晒霜,一共L(1 <= L <= 2500)瓶。第i瓶 防晒霜的SPF值为。瓶子的大小也不一定相同,第i瓶防晒霜可供头奶牛使用。当然,每头奶牛只能涂某一个瓶子里的防晒霜 ,而不能把若干个瓶里的混合着用。 请你计算一下,如果使用奶牛们准备的防晒霜,最多有多少奶牛能在不被灼 伤的前提下,享受到日光浴的效果?
只有上限,将最弱的给上限最小的,也就是限制比较强的。
现在我们有了下限之后,对于某一瓶,可以先找出满足限制的所有奶牛,那么下限就已经无效了。此时再考虑这个最优策略即可。
某年国家集训队互测 特技飞行
神犇航空开展了一项载客特技飞行业务。每次飞行长N个单位时间,每个单位时间可以进行一项特技动作,可选的动作有K种,每种动作有一个刺激程度Ci。如果连续进行相同的动作,乘客会感到厌倦,所以定义某次动作的价值为(距上次该动作的时间)*Ci,若为第一次进行该动作,价值为0。安排一种方案,使得总价值最大。
每个动作最多有两次,例如,1时刻、5时刻等价于1 3 5时刻,刺激不会变多
分配间隔时间时,给C_i大的分配时间多,所以排个序,大的尽量扔两边,贪就好了。
矩形切割
出于某些方面的需求,我们要把一块N×M的木板切成一个个1×1的小方块。 对于一块木板,我们只能从某条横线或者某条竖线(要在方格线上),而且这木板是不均匀的,从不同的线切割下去要花不同的代价。而且,对于一块木板,切割一次以后就被分割成两块,而且不能把这两块木板拼在一起然后一刀切成四块,只能两块分别再进行一次切割。现在,给出从不同的线切割所要花的代价,求把整块木板分割成1×1块小方块所需要耗费的最小代价。
对某一组横切和纵切,优先切代价大的那条,让代价小的切两遍
然后按权值从大到小排个序,按这个切就好。
Usaco2007 Jan Protecting the Flowers
约翰留下他的N(<=100000)只奶牛上山采木.他离开的时候,她们像往常一样悠闲地在草场里吃草.可是,当他回来的时候,他看到了一幕惨剧:牛们正躲在他的花园里,啃食着他心爱的美丽花朵!为了使接下来花朵的损失最小,约翰赶紧采取行动,把牛们送回牛棚.牛们从1到N编号.第i只牛所在的位置距离牛棚Ti(1≤Ti<2000000)分钟的路程,而在约翰开始送她回牛棚之前,她每分钟会啃食Di(1≤Di≤100)朵鲜花.无论多么努力,约翰一次只能送一只牛回棚.而运送第第i只牛事实上需要2Ti分钟,因为来回都需要时间.写一个程序来决定约翰运送奶牛的顺序,使最终被吞食的花朵数量最小.
除法为最优策略。
yy一下就出来了。
当然也可以严格的算:
判断需要交换与不需要交换
如果不交换,那么
整理得
NOIP2012 国王游戏
同上
前缀和
区间修改
给定n个数ai,有m次操作,每个操作是给al~ar增加一个数k。
最终输出操作完后的这n个数的值。
要求一个O(n+m)的做法。
s[l]+=k,s[r+1]-=k
还原时a[i]=a[i-1]+s[i]
Meet int the middle
见《搜索的奇技淫巧》
背包
一个容量为m的背包,有n个物品,第i个物品的体积为wi,价值为ci。
选择若干物品,使得体积总和不超过m的情况下价值总和最大。
n<=40。
分成两半,然后拼起来
第一部分枚举出来种情况,按体积排序。
对每一个w,二分查找找出前一半体积总和<=m-w价值最大的情况。
用前缀和维护即可。
类似于前天的T3
K-thNumber
有n个数,共有2^n个子集,一个子集的值看做其所有数的和。求这2^n个子集中第K大的子集。n<=35。
第k大->二分
分成两半,对第一半枚举所有的总和,并且排序。
后一半,取答案是w,然后用二分答案t,使得拼起来的子集是前面和后面的拼接。然后在第一表中看有多少是t-w的,和t比较。
分块
RMQ分块解法
预处理块
询问段区间最小值就是包含段的最小值与单另部分最小值。
复杂度
分块维护区间加
类似线段树的lazytag
分块维护区间开平方、区间和
每个数字最多只能被开5次,会变成1.
对所有不是1的暴力开,否则不管。
由于最多有5次,相当于单点修改区间求和。
分块维护即可。
想要找见[L,R]中有多少1,可以用并查集维护。
并查集fa为左边第一个不是1的位置,如果变成1就连向左边的位置。
如果R的根节点比L大,那么这一区间就是1.(没怎么听懂)
整体二分
RMQ
给定n个数,有Q次询问,每次询问一段区间的最小值。
对于跨mid的询问,可以求出[L,mid][mid,R]的最小值
否则可以递归的找前缀最小值,复杂度O(logn)
倍增
RMQ
a[i][j]=max(a[i][j-1],a[i+1<<(j-1)+1][j])
查询是O(1)的,跨区间可以直接搞
难题选讲
标签(空格分隔): 难题
数学
Cirno的完美算数教室
baka数:只含有2和9两种数字
问一个区间中有多少个数能被baka数整除
容斥乱搞
treecut
给定一棵n个节点的树,从1到n标号。选择k个点,你需要选择一些边使得这k个点通过选择的边联通,目标是使得选择的边数最少。
现需要计算对于所有选择k个点的情况最小选择边数的总和为多少。
如果判断是否需要砍掉一条边,只需要判断是否有点在两部分,如果有那么这条边必须被选择。
判断这条边下面包含的子树个数是否是0或者k。
共有种情况,算出都不在,两种情况,一种是k个点都在这条边的下方个点之中,一个是都在个点之中,也就是
枚举每一条边,可以求得结果。
求和
给出一个N(),使用一些2的若干次幂的数相加来求之.问有多少种方法
1) 1+1+1+1+1+1+1
2) 1+1+1+1+1+2
3) 1+1+1+2+2
4) 1+1+1+4
5) 1+2+2+2
6) 1+2+4
2n情况和2n+1一样,求2n即可
是错误的。
在拼8的时候相当于4的方案+7的方案,这是因为除以2以后因数缩小一半但是并没有什么卵用,方案数不变。
因此s[i]=s[i-1](i为奇数),s[i]=s[i-1]+s[i>>1](i为偶数)
字符串
相似子串
两个字符串相似定义为:
1.两个字符串长度相等
2.两个字符串对应位置上有且仅有至多一个位置所对应的字符不相同
给定一个字符串,每次询问两个子串在给定的规则下是否相似。给定的规则指每次给出一些等价关系,如’a'=’b',‘b'=’c'等,注意这里的等价关系具有传递性,即若‘a'=’b',‘b'=’c',则‘a'=’c'。
1<=|s|,询问次数<=300000
两个串只有一位不同,则hash差为
预先存出这些数字,可以判断是否在允许范围内
不保险可以多取几个质数
如果没有只有一个不同的限制条件,
我们知道如果标记一下两个串中某一对相等关系的位置
首先考虑某一个字母,该字母标记为1,否则为0.
这样求得的两个串的hash完全相同的话,这两个串中a的位置是完全相同的。
同样对b求hash,如果两串hash总和相同,那么就符合这一组等价关系。
依次搞即可
队列变换
求与一个字符串所有循环同构的字符串中,字典序最小的字符串
a.size()<=100000
循环同构:每次将第一个放到最后一个
如果字符串长度<=2000,那么暴力的枚举一次即可。
仍然暴力的枚举,二分+hash找到最大LCP,比较大小,O(nlogn)
矩阵模板
给定一个M行N列的01矩阵,以及Q个A行B列的01矩阵,你需要求出这Q个矩阵哪些在原矩阵中出现过。所谓01矩阵,就是矩阵中所有元素不是0就是1。
n,m<=1000, a,b<=100
如果是一维的,求一下hash然后判断一下即可。
对于二维,我们不妨求出以(0,0)为左上角、(a,b)为右下角的子矩阵的hash。这样对于一个子矩阵的hash可以类似前缀和的做法求出。
而二维hash,假定base=31,
| n | .. | 3 | 2 | 1 |
|---|---|---|---|---|
| ... | ... | ... | ... | ... |
| ... | ... | ... | ... | |
| ... | ... | ... | ... | |
| .. | 31 | 1 |
然后以算出来的结果竖着做hash,可以表示每一个矩阵的hash
知道(0,0,a,b),要求(c,d,a,b)
先减去,同理减去两块,就可以求出。
DP
逆序对数列
对于一个数列{ai},如果有iaj,那么我们称ai与aj为一对逆序对数。若对于任意一个由1~n自然数组成的数列,可以很容易求出有多少个逆序对数。那么逆序对数为k的这样自然数数列到底有多少个?
f[i][j]表示1~i中有多少排列方式使得逆序对数为j
i+1加入后,如果这个数放在末尾逆序对数不变,放在最前面逆序对个数变成j+i,同理可以插入到某个位置。
所以f[i][j]可以向f[i+1][j]到f[i+1][j+i]转移
那么反过来,
对f[i-1]这一维维护一个前缀和,就可以快速的转移。
玩具取名
Description
某人有一套玩具,并想法给玩具命名。首先他选择WING四个字母中的任意一个字母作为玩具的基本名字。然后他会根据自己的喜好,将名字中任意一个字母用“WING”中任意两个字母代替,使得自己的名字能够扩充得很长。现在,他想请你猜猜某一个很长的名字,最初可能是由哪几个字母变形过来的
Input
第一行四个整数W、I、N、G。表示每一个字母能由几种两个字母所替代。接下来W行,每行两个字母,表示W可以用这两个字母替代。接下来I行,每行两个字母,表示I可以用这两个字母替代。接下来N行,每行两个字母,表示N可以用这两个字母替代。接下来G行,每行两个字母,表示G可以用这两个字母替代。最后一行一个长度不超过Len的字符串。表示这个玩具的名字。
a[i]=a[i-1]+s[i]
f[i][j]['w']表示第i个字符到第j个字符能否由字符w扩展出来
w->in,如果f[i][k]['i'],f[k+1][j]['n'],两个融合一下就是f[i][j]['w']
复杂度
硬币购物
一共有4种硬币。面值分别为c1,c2,c3,c4。某人去商店买东西,去了tot次。每次带di枚ci硬币,买si的价值的东西。请问每次有多少种付款方法。
tot,si<=100000
如果没有限制d,那么预处理一个f[i],表示所有情况。
那么对于不合法方案,第一枚硬币超过枚,
减去f[s[i]-(d1+1)*c1]...这四种情况,然后其实这是个容斥。
手动容斥硬搞或者dfs的搞都可以。
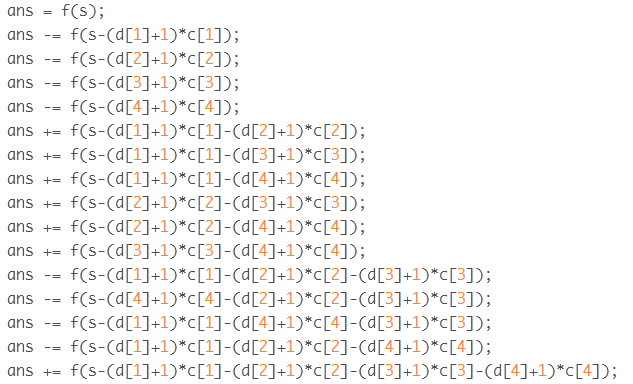
//感谢cyxdalao的代码
送外卖
有一个送外卖的,他手上有n份订单,他要把n份东西,分别送达n个不同的客户的手上。n个不同的客户分别在1~n个编号的城市中。送外卖的从0号城市出发,然后n个城市都要走一次(一个城市可以走多次),最后还要回到0点(他的单位),请问最短时间是多少。现在已知任意两个城市的直接通路的时间。
n<=15
dp[i][j]表示i号点的状态
例如,dp[4][13]表示在4这个点处,13=(1101)(2),第二个点没走过,其它都走过。将dp预处理为INF,然后让dp[0][1]=0
如果存在一条i到k长度为z的边,那么就可以转移:表示包括进去k这个点。
用dp[0][1]扔到SPFA队列中不断更新其它信息,最后答案就是
混乱的奶牛
Farmer John的N(4 <= N <= 16)头奶牛中的每一头都有一个唯一的编号(1 <= S_i <= 25,000).奶牛为她们的编号感到骄傲,所以每一头奶牛都把她的编号刻在一个金牌上, 并且把金牌挂在她们宽大的脖子上.奶牛们对在挤奶的时候被排成一支”混乱”的队伍非常反感.如果一个队伍里任意两头相邻的奶牛的编号相差超过K (1 <= K <= 3400), 它就被称为是混乱的. 比如说,当N = 6, K = 1时, 1, 3, 5, 2, 6, 4 就是一支”混乱”的队伍,但是1,3,6,5,2,不是(因为5和6只相差1).那么,有多少种能够使奶牛排成”混乱”的队伍的方案呢?
dp[i][j]表示最后一个数字是i,哪些数字被使用过压缩为j
for(int t=0;t<=n;++t){if(((j>>t)&1)==0)//第t维没有使用过if(fabs(t-j)>k)dp[t][j|(1<<t)]+=dp[i][j];}cout<<dp[i][(1<<k)-1];
牧场安排
Farmer John新买了一块长方形的牧场,这块牧场被划分成M列N行(1<=M<=12; 1<=N<=12),每一格都是一块正方形的土地。FJ打算在牧场上的某几格土地里种上美味的草,供他的奶牛们享用。遗憾的是,有些土地相当的贫瘠,不能用来放牧。并且,奶牛们喜欢独占一块草地的感觉,于是FJ不会选择两块相邻的土地,也就是说,没有哪两块草地有公共边。当然,FJ还没有决定在哪些土地上种草。 作为一个好奇的农场主,FJ想知道,如果不考虑草地的总块数,那么,一共有多少种种植方案可供他选择。当然,把新的牧场荒废,不在任何土地上种草,也算一种方案。请你帮FJ算一下这个总方案数。
思考能否根据上一行信息确定下一行,例如1010->0101不能1000
判断一下能否转移即可,即dp[i][j]->dp[i+1][k]是否合法,
比如说,,k枚举0~15,符合条件就是可以转移的。
初始状态为.
互不侵犯
在N×N的棋盘里面放K个国王,使他们互不攻击,共有多少种摆放方案。国王能攻击到它上下左右,以及左上左下右上右下八个方向上附近的各一个格子,共8个格子。n<=9
dp[i][j][t]表示前i行放入j个国王,第i行状态为t
枚举下一行状态即可。
结果就是dp[N][k]
集合选数
《集合论与图论》这门课程有一道作业题,要求同学们求出{1,2,3,4,5}的所有满足以下条件的子集:若x在该子集中,则2x和3x不能在该子集中。同学们不喜欢这种具有枚举性 质的题目,于是把它变成了以下问题:对于任意一个正整数n≤100000,如何求出{1, 2,…, n} 的满足上述约束条件的子集的个数(只需输出对 1,000,000,001 取模的结果),现在这个问题就交给你了。
a影响的数字是与
例如,1 2 3 4 5 6 7 8 9 10
分为两类:1 2 3 4 6 8 9、5 10、7
将这三类拼接起来,然后乘法原理
对于每一类:
..
4 ..
2 6 ..
1 3 9 ..
设计这样的形式。横着差3倍,竖着差2倍如果两个数不相邻,一定是合法的方案。
由于与都比较小,就相当于在一个矩阵中选不相邻的数的计数。也就是普通的状压dp。
windy数
windy定义了一种windy数。不含前导零且相邻两个数字之差至少为2的正整数被称为windy数。 windy想知道,在A和B之间,包括A和B,总共有多少个windy数?
每100w个预处理一次,打个表,可以在规定时间算出来。
正解:
区间减满足,相当于只求上限,即1~B-1~A
统计长度8位的合法情况
dp[i][j]第i位数字上一位数字为j,合法情况有多少。
例如,对1536,我们考虑的就是1000~1536多少合法
第一位不考虑,第二位为3、4打头的,然后统计152、151、150打头的...这样的方案数。这样可以考虑所有情况。
前三位的在之前的dp中已经求了一次,直接加上即可。
图论
欧拉图
能一笔画的图。
对于一个连通图判断每一点度数是不是偶数,如果只有两个或0个是奇数就是欧拉图。如果是两个奇数那么就是起点和终点。
DFS输出欧拉回路:向其它层搜索,如果一个点的所有边都被访问过那么就输出这个点,然后回溯。
舒适的路线
Z小镇附近共有N个景点(编号为1,2,3,…,N),这些景点被M条道路连接着,所有道路都是双向的,两个景点之间可能有多条道路。也许是为了保护该地的旅游资源,Z小镇有个奇怪的规定,就是对于一条给定的公路Ri,任何在该公路上行驶的车辆速度必须为Vi。频繁的改变速度使得游客们很不舒服,因此大家从一个景点前往另一个景点的时候,都希望选择行使过程中最大速度和最小速度的比尽可能小的路线,也就是所谓最舒适的路线。
固定路线最大值,然后加边,判断是否联通用并查集维护。
星球大战
很久以前,在一个遥远的星系,一个黑暗的帝国靠着它的超级武器统治者整个星系。某一天,凭着一个偶然的机遇,一支反抗军摧毁了帝国的超级武器,并攻下了星系中几乎所有的星球。这些星球通过特殊的以太隧道互相直接或间接地连接。 但好景不长,很快帝国又重新造出了他的超级武器。凭借这超级武器的力量,帝国开始有计划地摧毁反抗军占领的星球。由于星球的不断被摧毁,两个星球之间的通讯通道也开始不可靠起来。现在,反抗军首领交给你一个任务:给出原来两个星球之间的以太隧道连通情况以及帝国打击的星球顺序,以尽量快的速度求出每一次打击之后反抗军占据的星球的连通快的个数。(如果两个星球可以通过现存的以太通道直接或间接地连通,则这两个星球在同一个连通块中)。
要求的是一棵树的摧毁,很难搞,可以倒着来,也就是一棵树的重建。
并查集维护即可。
飞行路线
Alice和Bob现在要乘飞机旅行,他们选择了一家相对便宜的航空公司。该航空公司一共在n个城市设有业务,设这些城市分别标记为0到n-1,一共有m种航线,每种航线连接两个城市,并且航线有一定的价格。Alice和Bob现在要从一个城市沿着航线到达另一个城市,途中可以进行转机。航空公司对他们这次旅行也推出优惠,他们可以免费在最多k种航线上搭乘飞机。那么Alice和Bob这次出行最少花费多少?
2<=n<=10000,1<=m<=50000,0<=k<=10.
k=1时,在跑SPFA时,要松弛dist[i][1],那么可以转换到dist[i][0]与dist[i][1]表示这一段不使用或使用免费机会。而对dist[i][0],只能转移到dist[j][1]。
推广时,可以用第二维维护还剩下几次免费机会。
这种思路叫做裂点。
架设电话线
Farmer John打算将电话线引到自己的农场,但电信公司并不打算为他提供免费服务。于是,FJ必须为此向电信公司支付一定的费用。
FJ的农场周围分布着N(1 <= N <= 1,000)根按1..N顺次编号的废弃的电话线杆,任意两根电话线杆间都没有电话线相连。一共P(1 <= P <= 10,000)对电话线杆间可以拉电话线,其余的那些由于隔得太远而无法被连接。
第i对电话线杆的两个端点分别为、,它们间的距离为 (1 <=<= 1,000,000)。数据中保证每对{,}最多只出现1次。编号为1的电话线杆已经接入了全国的电话网络,整个农场的电话线全都连到了编号为N的电话线杆上。也就是说,FJ的任务仅仅是找一条将1号和N号电话线杆连起来的路径,其余的电话线杆并不一定要连入电话网络。
经过谈判,电信公司最终同意免费为FJ连结K(0 <= K < N)对由FJ指定的电话线杆。对于此外的那些电话线,FJ需要为它们付的费用,等于其中最长的电话线的长度(每根电话线仅连结一对电话线杆)。如果需要连结的电话线杆不超过K对,那么FJ的总支出为0。
请你计算一下,FJ最少需要在电话线上花多少钱。
考虑裂点的做法。如果使用免费机会就不计入max,否则求一次最大值,与上一道题类似。但是这样会T。
如果二分答案t,使得大于t的免费,小于t的收费,也就是判断一条路径边权>=t的数量<=k。对大于t的新建1,否则新建0,然后跑一次最短路,也就是至少要经过几条边权>t的边。
墨墨的等式
墨墨突然对等式很感兴趣,他正在研究a1x1+a2y2+…+anxn=B存在非负整数解的条件,他要求你编写一个程序,给定N、{an}、以及B的取值范围,求出有多少B可以使等式存在非负整数解。
N≤12,0≤ai≤5*10^5,1≤BMin≤BMax≤10^12
满足区间减性质,只考虑上限。
跑SPFA,dist[0]设为0,其余设为无穷。那么转移,如果费用是1否则是0.
这是因为将所有数字按取模分类,存在正整数解,那么是合法的。而寻找每一类最小的,就是最短路可以求出的东西。也就相当于类与类之间求最短路。
其它
理想的正方形
有一个a*b的整数组成的矩阵,现请你从中找出一个n*n的正方形区域,使得该区域所有数中的最大值和最小值的差最小。
确定上边和下边的位置后该正方形是确定的。
预处理每个端点向上和向右最大的值,也就是单调队列。
求出以每一个点为右端点,然后两次求单调队列。
(没听懂
也可以二维st表。
f[i][j][k]表示以[i][j]为右端点,向上、向左个长度的矩阵最小值。
普通的倍增转移即可。查询时可以将一块转化为4块,这样也是O(1)的。
上升序列
对于一个给定的S={a1,a2,a3,…,an},若有P={ax1,ax2,ax3,…,axm},满足(x1 < x2 < … < xm)且( ax1 < ax2 < … < axm)。那么就称P为S的一个上升序列。如果有多个P满足条件,那么我们想求字典序最小的那个。任务给出S序列,给出若干询问。对于第i个询问,求出长度为Li的上升序列,如有多个,求出字典序最小的那个(即首先x1最小,如果不唯一,再看x2最小……),如果不存在长度为Li的上升序列,则打印Impossible.
如果k时符合条件的点,那么就是判断是否存在Li的序列。
可以预处理时逆着求LIS,然后得到每个顶点的最长上升序列值。
判断一下即可,然后取比较小的,就得到了第一个数。
对第二个数,找一个> Li-1且在上一个数的后面的大于ai数,扫一遍。
,会T。
所有数字按字典序排序,然后找第一个,从这个位置开始找第二个。
然后检验合法性,这样可以贪心的往下找。
例如,1 2 3 4预处理结果为2 2 1 1,排序后结果为1 2 3 4
如果长度为2,那么1的结果是2是符合条件的,然后去扫,2不符合,3符合,3就一定是所求。
后记
于是八天就这么结束了。
感谢各位的支持,以及感谢hzk大佬,没有您的话我真的坚持不到现在。
作为一名蒟蒻,许多东西没有学过,许多东西不会写。想要做这个笔记,初衷其实只是为了强制自己不要溜神,尽力听懂,及时提问。虽然最后还是有很多没有搞明白的东西,orzzz。
出于这样一种自私的目的,这种蒟蒻笔记的价值并不算大。如果能在各位神犇复习的时候提供一点点微漠的帮助,就是在下的荣幸。
如果有什么错误或者想要补充的东西的话请尽管联系在下。在下会怀揣着犬马惧怖之情听取您的意见的。在下的qq:1614868321
最后祝愿各位NOIP能考出好成绩。
(在下的blog:blog.csdn.com/lirewriter 相当辣鸡的博客,请无视就好)
