@lancelot-vim
2016-05-08T15:03:47.000000Z
字数 3266
阅读 2145
贝叶斯估计
模式分类
@author lancelot-vim
类条件密度
贝叶斯分类方法的核心是后验概率的计算。贝叶斯公式告诉我们,如何根据类条件概率密度和各类别的先验概率来计算这个后验概率,加入你有数据集,那么根据贝叶斯公式:
这个公式告诉我们,我们需要用已有的数据确定类条件概率密度和先验概率,通常计算是很容易的,即频率等于概率balabala就可以算出这个概率值来,但是类条件概率密度并不是那么容易的,实际上,对于每个样本,仅仅只有同一类别的样本对于该类别的类条件密度是有意义的
比如说,如果,那么对于计算没有任何意义,因此通常只用确定,也就是说贝叶斯公式可以写为:
因此,我们处理的核心问题,实际上是根据一组训练样本,估计分布,简单记为,为
参数的分布
我们总是认为分布的形式是已知的,但是参数并不知道,实际上我们需要做的事,是根据数据的到最好的。
假如我们有一些先验知识,比如你对有点感觉,他大概等于多少,或者可能是多少(这个感觉可以很模糊,也可以基本不确定,这都不会造成问题),那么这个问题我们可以等价为是已知的,并且确定的,而的不确定问题(或者说你的先验的感觉),可以归纳成一个概率分布,整个概率便可以重新写成:
公式(1):
这个公式是贝叶斯估计的核心公式,他把类条件密度和后验概率相结合,将这个问题划归为一个优化后验概率密度的问题。假如这个后验密度在某个值附近形成一个尖峰(最后收敛到狄拉克雷函数),那么自然有,假如没有收敛,甚至可能形成了一个平均,that's fine,我们可以认为是一种概率意义上的加权平均值
高斯情况
我们考虑期望未知的情况,即: ,已知
我认为所有关于均值的知识全部包含在先验概率密度函数中,其中均已知
由于我们已经有很多样本,所以我们需要计算后验概率密度对先验知识产生的密度进行更新
公式(2):
其中,为依赖与样本集的归一化系数,
根据高斯分布密度函数,可以得到
其中
最后解得:
对于多变量情形,类似有
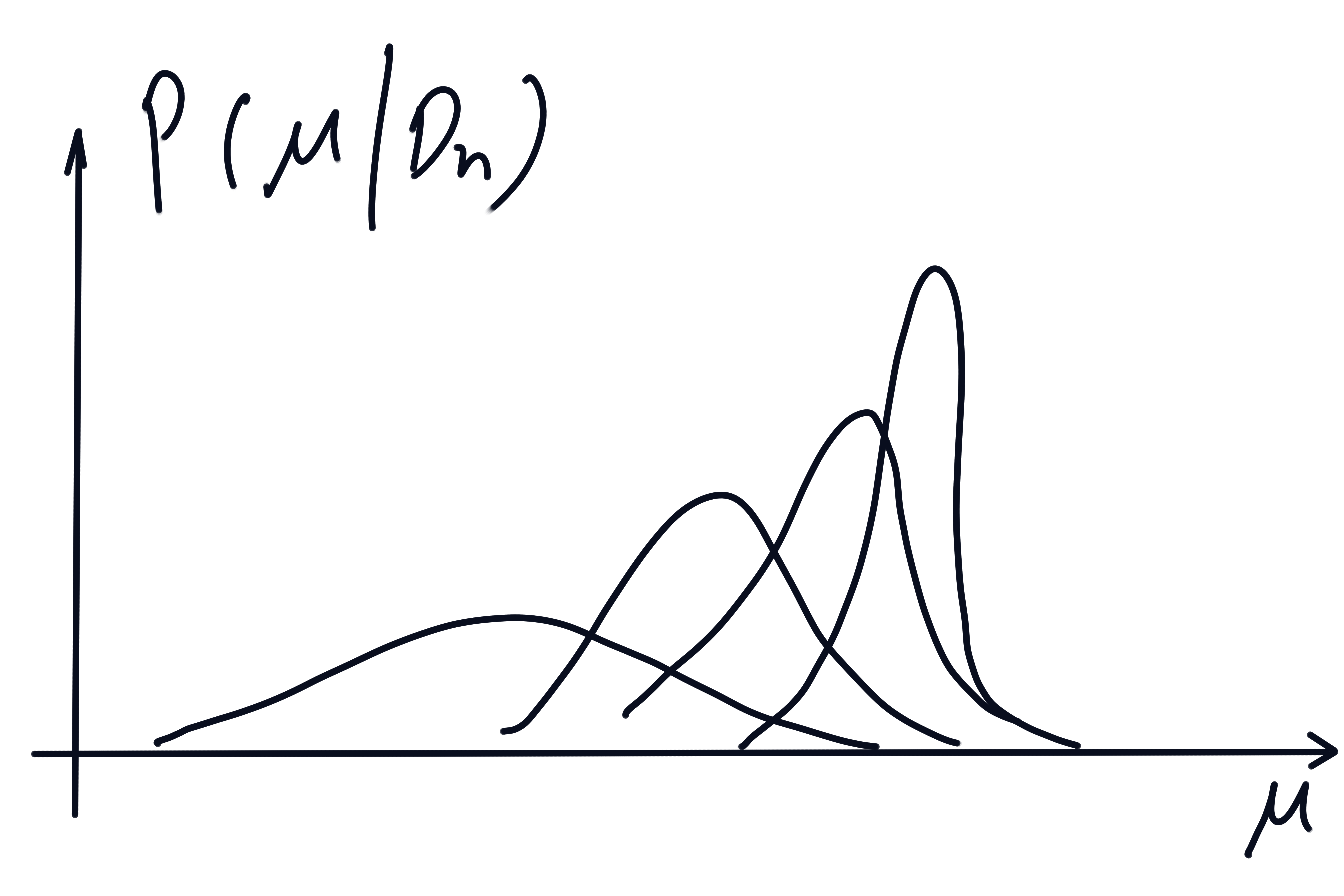
最后根据公式(1),实际上可以的到
贝叶斯参数估计一般理论
基本假设
- 条件概率是完全已知的,虽然参数值未知
- 参数的先验概率密度函数包含了我们对的所有先验知识
- 观测到的样本独立同分布
递归算法
记,由于样本独立同分布,可得
代入公式(2)得:
最大似然估计和贝叶斯估计的区别
对于先验概率能保证问题有解的问题下,最大似然估计和贝叶斯估计在训练样本趋于无穷大时候效果是一样的。
计算复杂度
最大似然估计是比较好的选择,因为最大似然估计只涉及到微分运算或梯度搜索,而贝叶斯估计需要复杂的多重积分
可理解性
最大似然估计比贝叶斯方法更容易理解,因为最大似然估计是基于设计者的设计和给出的样本的到的最佳解答,而贝叶斯方法的结果是许多可行解答的加权平均,可以反映出对多种可行解答的不确定程度
对先验知识的信任
最大死然估计得到的估计结果初始假设是一样的,但对于贝叶斯估计未必成立。通过使用全部中的信息,贝叶斯方法比最大似然方法能利用更多的信息,如果这些信息是可靠的,那么贝叶斯方法能得到更可靠的结果。而且,即使没有特定的先验知识请跨下,贝叶斯估计也能的到和最大似然估计相似的结果
下一篇: 充分估计量
