@lancelot-vim
2016-06-25T08:07:40.000000Z
字数 22762
阅读 3228
lsd-slam源码解读第四篇:tracking
lsd-slam
进入这一篇之前,我希望你已经很明白了lsd-slam的算法,这很重要,如果不明白算法,阅读后续的代码无异于阅读天书,如果不太明白算法,请先阅读我写的第三篇:lsd-slam源码解读第三篇:算法解析
LGSX
于是就进入了Tracking文件夹里的第一个类型LSGX,这里面有3个类,分别是LSG4,LSG6和LSG7,他们定义了4个参数6个参数以及7个参数的最小二乘法
我想值得注意的是这段代码:
inline void update(const Vector6& J, const float& res, const float& weight)
{
A.noalias() += J * J.transpose() * weight;
b.noalias() -= J * (res * weight);
error += res * res * weight;
num_constraints += 1;
}
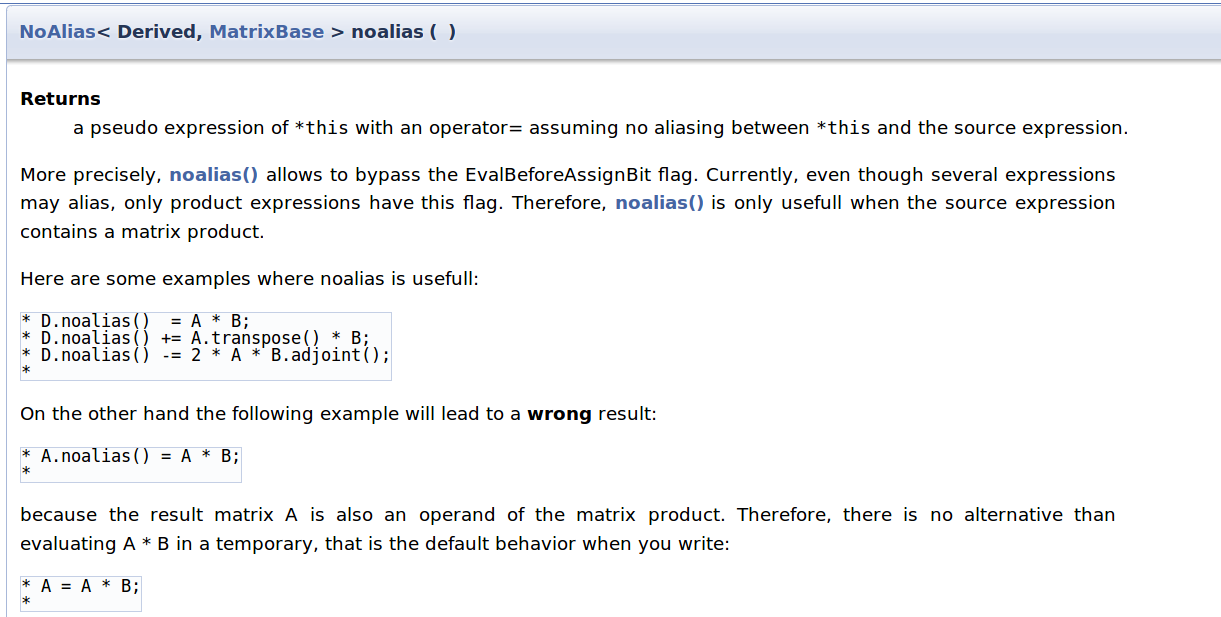
这里使用了Eigen库里面的noalias机制,下面是Eigen库的官方文档:
为了讲解这个用法,请看下面这段代码
#include <iostream>
#include <stdio.h>
#include <eigen3/Eigen/Dense>
using namespace std;
template <typename T>
class A {
public:
A() {printf("A()\n");}
~A() {printf("~A()\n");}
template <typename U>
A operator*(A<U>&){
A a;
return a;
}
};
int main()
{
A<int> a1,b1;
A<int> c1;
c1 = a1*b1;
Eigen::Matrix2f a, b, c;
c.noalias() = a * b;
a(0, 0) = 0;
a(0, 1) = 1;
a(1, 0) = 1;
a(1, 1) = 0;
b(0, 0) = 1;
b(0, 1) = 2;
b(1, 0) = 3;
b(1, 1) = 4;
c.noalias() = a * b;
std::cout << c << std::endl;
return 0;
}
这是程序运行结果:
A()
A()
A()
A()
~A()
3 4
1 2
~A()
~A()
~A()
什么意思呢?注意我自己写的模板类A,在main函数里面有一个乘法c1 = a1*b1;,这个会调用重载运算符,然后先构造一个对象,再拷贝,最后析构,这样对于大量使用继承的程序会大大影响效率(构造基类构造子类,析构基类,析构子类,而且如果有内存申请,拷贝,释放,效率会降低更多),那怎么办呢?Eigen使用了一种机制,让我们减少一次对象的构造,这个机制就是用noalias()调用,这样相当于吧运行a*b的结果直接拷贝到c里面,不再去构造中间对象
如何实现呢,其实由于要考虑到泛化,代码内部实现比较复杂,但原理实际上是写一个算法类,算法类中储存了算法的函数对象(仿函数)或者函数指针和储存算法运算的结果容器的引用或者指针,然后调用算法的时候,不再去构造那个复杂的数据结构,转而构造一个简单的算法类,将运行结果赋值给容器的引用或指针,从而降低内存开销
程序中调用noalias()函数,实际上返回的是一个NoAlias的对象,这个对象维护了真正的乘法(实际上为了泛化,还向下有调用,可能会查看的代码和文档链接:NoAlias.h, MatrixBase.h, NoAlias< Derived, MatrixBase > noalias(), EigenBase< Derived > Struct Template Reference)
TrackingReference
讲了一大堆Eigen库和c++模板语法的东西,如果没有理解,忘了它吧,这个和Tracking算法没太大关系,我只是为了表现一下我的c++语法功底,扯了扯题外话而已。
不知你还记不记得之前第三篇里面讲的Tracking,如果记得的话,那么应该很清楚第一个过程是是选择参考帧,程序里面体现的就是这个类了
class TrackingReference
{
public:
EIGEN_MAKE_ALIGNED_OPERATOR_NEW
/** Creates an empty TrackingReference with optional preallocation per level. */
TrackingReference();
~TrackingReference();
void importFrame(Frame* source);
Frame* keyframe;
boost::shared_lock<boost::shared_mutex> keyframeLock;
int frameID;
void makePointCloud(int level);
void clearAll();
void invalidate();
Eigen::Vector3f* posData[PYRAMID_LEVELS]; // (x,y,z)
Eigen::Vector2f* gradData[PYRAMID_LEVELS]; // (dx, dy)
Eigen::Vector2f* colorAndVarData[PYRAMID_LEVELS]; // (I, Var)
int* pointPosInXYGrid[PYRAMID_LEVELS]; // x + y*width
int numData[PYRAMID_LEVELS];
private:
int wh_allocated;
boost::mutex accessMutex;
void releaseAll();
};
void importFrame(Frame* source);
让我们来看第一个函数void importFrame(Frame* source);
void TrackingReference::importFrame(Frame* sourceKF)
{
boost::unique_lock<boost::mutex> lock(accessMutex);
keyframeLock = sourceKF->getActiveLock();
keyframe = sourceKF;
frameID=keyframe->id();
// reset allocation if dimensions differ (shouldnt happen usually)
if(sourceKF->width(0) * sourceKF->height(0) != wh_allocated)
{
releaseAll();
wh_allocated = sourceKF->width(0) * sourceKF->height(0);
}
clearAll();
lock.unlock();
}
前面几行是不难理解的,后面是一个判断,就是判断是否需要重置资源,如果宽度和高度的乘积和先前的高度与宽度的乘积一样大,那么就不用重新配置了,直接用先前的资源即可,如果不同,那么就释放先前左右的资源(请自行查看releaseAll()),然后把资源配置的记录记录成当前的配置数,最后再清空点云的记录数据numData(实际上就是令它等于0,请自行查看clearAll())
void makePointCloud(int level);
第二个重要的函数就是这个void makePointCloud(int level)了,代码如下
void TrackingReference::makePointCloud(int level)
{
assert(keyframe != 0);
boost::unique_lock<boost::mutex> lock(accessMutex);
if(numData[level] > 0)
return; // already exists.
int w = keyframe->width(level);
int h = keyframe->height(level);
float fxInvLevel = keyframe->fxInv(level);
float fyInvLevel = keyframe->fyInv(level);
float cxInvLevel = keyframe->cxInv(level);
float cyInvLevel = keyframe->cyInv(level);
const float* pyrIdepthSource = keyframe->idepth(level);
const float* pyrIdepthVarSource = keyframe->idepthVar(level);
const float* pyrColorSource = keyframe->image(level);
const Eigen::Vector4f* pyrGradSource = keyframe->gradients(level);
if(posData[level] == nullptr) posData[level] = new Eigen::Vector3f[w*h];
if(pointPosInXYGrid[level] == nullptr)
pointPosInXYGrid[level] = (int*)Eigen::internal::aligned_malloc(w*h*sizeof(int));;
if(gradData[level] == nullptr) gradData[level] = new Eigen::Vector2f[w*h];
if(colorAndVarData[level] == nullptr) colorAndVarData[level] = new Eigen::Vector2f[w*h];
Eigen::Vector3f* posDataPT = posData[level];
int* idxPT = pointPosInXYGrid[level];
Eigen::Vector2f* gradDataPT = gradData[level];
Eigen::Vector2f* colorAndVarDataPT = colorAndVarData[level];
for(int x=1; x<w-1; x++)
for(int y=1; y<h-1; y++)
{
int idx = x + y*w;
if(pyrIdepthVarSource[idx] <= 0 || pyrIdepthSource[idx] == 0) continue;
*posDataPT = (1.0f / pyrIdepthSource[idx]) * Eigen::Vector3f(fxInvLevel*x+cxInvLevel,fyInvLevel*y+cyInvLevel,1);
*gradDataPT = pyrGradSource[idx].head<2>();
*colorAndVarDataPT = Eigen::Vector2f(pyrColorSource[idx], pyrIdepthVarSource[idx]);
*idxPT = idx;
posDataPT++;
gradDataPT++;
colorAndVarDataPT++;
idxPT++;
}
numData[level] = posDataPT - posData[level];
}
我想前面几行都是不难理解的,无非就是先锁,然后判断有搞没搞过这一层,如果有就返回,没有就搞一下。要搞这一层,首先吧这一层的有用数据从关键帧里面取出来,即
int w = keyframe->width(level);
int h = keyframe->height(level);
float fxInvLevel = keyframe->fxInv(level);
float fyInvLevel = keyframe->fyInv(level);
float cxInvLevel = keyframe->cxInv(level);
float cyInvLevel = keyframe->cyInv(level);
const float* pyrIdepthSource = keyframe->idepth(level);
const float* pyrIdepthVarSource = keyframe->idepthVar(level);
const float* pyrColorSource = keyframe->image(level);
const Eigen::Vector4f* pyrGradSource = keyframe->gradients(level);
由于之前import的时候,可能没有把内存释放了(配置参数一样的情况),所以引入了4个判断,并考虑资源的分配
分配好之后,利用这些资源:
for(int x=1; x
for(int y=1; y
{
int idx = x + y*w;
if(pyrIdepthVarSource[idx] <= 0 || pyrIdepthSource[idx] == 0) continue;
*posDataPT = (1.0f / pyrIdepthSource[idx]) * Eigen::Vector3f(fxInvLevel*x+cxInvLevel,fyInvLevel*y+cyInvLevel,1);
*gradDataPT = pyrGradSource[idx].head<2>();
*colorAndVarDataPT = Eigen::Vector2f(pyrColorSource[idx], pyrIdepthVarSource[idx]);
*idxPT = idx;
posDataPT++;
gradDataPT++;
colorAndVarDataPT++;
idxPT++;
}
首先我们需要从关键帧中记录的位置数据和深度数据恢复点云,
然后记录像素梯度(回想看看第二章数据结构中讲过buildGradients,把像素梯度存储到了前两个维度),
然后把深度方差和可视化的上色部分记录成一个向量,
之后再循环遍历整个过程,将数据全部记录下来,
最后计算指针跳了多少位,即有多少个点云被记录了下来
SE3Tracker
这个类是Tracking算法的核心类,里面定义了和刚体运动相关的Traqcking所需要得数据和算法
int width, height;
// camera matrix
Eigen::Matrix3f K, KInv;
float fx,fy,cx,cy;
float fxi,fyi,cxi,cyi;
DenseDepthTrackerSettings settings;
// debug images
cv::Mat debugImageResiduals;
cv::Mat debugImageWeights;
cv::Mat debugImageSecondFrame;
cv::Mat debugImageOldImageSource;
cv::Mat debugImageOldImageWarped;
这几个定义的数据都很简单,其中DenseDepthTrackerSettings定义了一些Tracking相关的设定,比如最大迭代次数,认为收敛的阈值(百分比形式,有些数据认为98%收敛,有些是99%),还有huber距离所需参数等
SE3Tracker::SE3Tracker(int w, int h, Eigen::Matrix3f K)
{
width = w;
height = h;
this->K = K;
fx = K(0,0);
fy = K(1,1);
cx = K(0,2);
cy = K(1,2);
settings = DenseDepthTrackerSettings();
//settings.maxItsPerLvl[0] = 2;
KInv = K.inverse();
fxi = KInv(0,0);
fyi = KInv(1,1);
cxi = KInv(0,2);
cyi = KInv(1,2);
buf_warped_residual = (float*)Eigen::internal::aligned_malloc(w*h*sizeof(float));
buf_warped_dx = (float*)Eigen::internal::aligned_malloc(w*h*sizeof(float));
buf_warped_dy = (float*)Eigen::internal::aligned_malloc(w*h*sizeof(float));
buf_warped_x = (float*)Eigen::internal::aligned_malloc(w*h*sizeof(float));
buf_warped_y = (float*)Eigen::internal::aligned_malloc(w*h*sizeof(float));
buf_warped_z = (float*)Eigen::internal::aligned_malloc(w*h*sizeof(float));
buf_d = (float*)Eigen::internal::aligned_malloc(w*h*sizeof(float));
buf_idepthVar = (float*)Eigen::internal::aligned_malloc(w*h*sizeof(float));
buf_weight_p = (float*)Eigen::internal::aligned_malloc(w*h*sizeof(float));
buf_warped_size = 0;
debugImageWeights = cv::Mat(height,width,CV_8UC3);
debugImageResiduals = cv::Mat(height,width,CV_8UC3);
debugImageSecondFrame = cv::Mat(height,width,CV_8UC3);
debugImageOldImageWarped = cv::Mat(height,width,CV_8UC3);
debugImageOldImageSource = cv::Mat(height,width,CV_8UC3);
lastResidual = 0;
iterationNumber = 0;
pointUsage = 0;
lastGoodCount = lastBadCount = 0;
diverged = false;
}
以上是SE3Tracking的构造函数,初始化了相机,Tracking得配置参数,并给需要矫正的数据分配了内存,同时分配了深度,深度得方差,以及计算权重的内存,最后设置计数器为0,默认为没有diverged
float SE3Tracker::calcResidualAndBuffers
这个函数是优化相关的函数,参数共有8个,在后面可以看到,其他函数通过callOptimized这个宏调用了这个函数进行优化操作,例如:
callOptimized(calcResidualAndBuffers, (reference->posData[lvl], reference->colorAndVarData[lvl], SE3TRACKING_MIN_LEVEL == lvl ? reference->pointPosInXYGrid[lvl] : 0, reference->numData[lvl], frame, referenceToFrame, lvl, (plotTracking && lvl == SE3TRACKING_MIN_LEVEL)));
现在让我们开始来阅读这个函数的实现代码
首先,如果要可视化Tracking的迭代过程,那么第一步自然是把debug相关的参数都设置进去,否则直接进行下一步,这个操作是通过调用calcResidualAndBuffers_debugStart()实现的:
void SE3Tracker::calcResidualAndBuffers_debugStart()
{
if(plotTrackingIterationInfo || saveAllTrackingStagesInternal)
{
int other = saveAllTrackingStagesInternal ? 255 : 0;
fillCvMat(&debugImageResiduals,cv::Vec3b(other,other,255));
fillCvMat(&debugImageWeights,cv::Vec3b(other,other,255));
fillCvMat(&debugImageOldImageSource,cv::Vec3b(other,other,255));
fillCvMat(&debugImageOldImageWarped,cv::Vec3b(other,other,255));
}
}
然后判断是否可视化残差,如果需要可视化,那么初始化残差
if(plotResidual)
debugImageResiduals.setTo(0);
之后是本地化操作
int w = frame->width(level);
int h = frame->height(level);
Eigen::Matrix3f KLvl = frame->K(level);
float fx_l = KLvl(0,0);
float fy_l = KLvl(1,1);
float cx_l = KLvl(0,2);
float cy_l = KLvl(1,2);
Eigen::Matrix3f rotMat = referenceToFrame.rotationMatrix();
Eigen::Vector3f transVec = referenceToFrame.translation();
const Eigen::Vector3f* refPoint_max = refPoint + refNum;
const Eigen::Vector4f* frame_gradients = frame->gradients(level);
然后定义后续所要使用的变量
int idx=0;
float sumResUnweighted = 0;
bool* isGoodOutBuffer = idxBuf != 0 ? frame->refPixelWasGood() : 0;
int goodCount = 0;
int badCount = 0;
float sumSignedRes = 0;
float sxx=0,syy=0,sx=0,sy=0,sw=0;
float usageCount = 0;
然后是对所有的参考点进行操作:
首先是计算参参考点的空间位置相对于新的坐标系的空间位置的三维坐标,然后投影到图像上
Eigen::Vector3f Wxp = rotMat * (*refPoint) + transVec;
float u_new = (Wxp[0]/Wxp[2])*fx_l + cx_l;
float v_new = (Wxp[1]/Wxp[2])*fy_l + cy_l;
判断当前点是否投影到图像中,并标记
if(!(u_new > 1 && v_new > 1 && u_new < w-2 && v_new < h-2))
{
if(isGoodOutBuffer != 0)
isGoodOutBuffer[*idxBuf] = false;
continue;
}
然后差值得到亚像素精度级别的深度(注意深度的第三个维度是图像数据)
Eigen::Vector3f resInterp = getInterpolatedElement43(frame_gradients, u_new, v_new, w);
这是转化函数
inline Eigen::Vector3f getInterpolatedElement43(const Eigen::Vector4f* const mat, const float x, const float y, const int width)
{
int ix = (int)x;
int iy = (int)y;
float dx = x - ix;
float dy = y - iy;
float dxdy = dx*dy;
const Eigen::Vector4f* bp = mat +ix+iy*width;
return dxdy * *(const Eigen::Vector3f*)(bp+1+width)
+ (dy-dxdy) * *(const Eigen::Vector3f*)(bp+width)
+ (dx-dxdy) * *(const Eigen::Vector3f*)(bp+1)
+ (1-dx-dy+dxdy) * *(const Eigen::Vector3f*)(bp);
}
之后把图像数据做一次仿射操作,再算得亚像素坐标和当前像素坐标的差值
float c1 = affineEstimation_a * (*refColVar)[0] + affineEstimation_b;
float c2 = resInterp[2];
float residual = c1 - c2;
通过差值自适应算得weight以及相关值,它认为两个变换之间的像素值有个阈值5.0,小于5.0的时候等于1,如果大于5.0,那么依据比值5.0f / fabsf(residual)减小,也就是说,离得越远,权重越小
float weight = fabsf(residual) < 5.0f ? 1 : 5.0f / fabsf(residual);
sxx += c1*c1*weight;
syy += c2*c2*weight;
sx += c1*weight;
sy += c2*weight;
sw += weight;
然后判断这个点是好是坏,也是个自适应的阈值,这个阈值为一个最大的差异常数,加上梯度值乘以一个比例系数,即,MAX_DIFF_CONSTANT + MAX_DIFF_GRAD_MULT*(resInterp[0]*resInterp[0] + resInterp1*resInterp1),这个和残差比较,如果残差的平方小于它,那么认为这个点的估计比较好,然后再把这个判断赋值给isGoodOutBuffer[*idxBuf]
bool isGood = residual*residual / (MAX_DIFF_CONSTANT + MAX_DIFF_GRAD_MULT*(resInterp[0]*resInterp[0] + resInterp[1]*resInterp[1])) < 1;
if(isGoodOutBuffer != 0)
isGoodOutBuffer[*idxBuf] = isGood;
之后记录计算得到的这一帧改变的值,中间的乘法实际上是投影到图像坐标,即相机参数乘以差之后的梯度值,从而得到图像的改变值,点的第三个维度是z坐标,倒数正好是逆深度
*(buf_warped_x+idx) = Wxp(0);
*(buf_warped_y+idx) = Wxp(1);
*(buf_warped_z+idx) = Wxp(2);
*(buf_warped_dx+idx) = fx_l * resInterp[0];
*(buf_warped_dy+idx) = fy_l * resInterp[1];
*(buf_warped_residual+idx) = residual;
*(buf_d+idx) = 1.0f / (*refPoint)[2];
*(buf_idepthVar+idx) = (*refColVar)[1];
idx++;
之后再记录残差的平方和,以及误差值(带符号)
if(isGood)
{
sumResUnweighted += residual*residual;
sumSignedRes += residual;
goodCount++;
}
else
badCount++;
然后记录深度改变的比例,最后记录下来
float depthChange = (*refPoint)[2] / Wxp[2];
usageCount += depthChange < 1 ? depthChange : 1;
当然,循环的最后,代码也有debug选项,即如果设置了画图,就把他们可视化出来
if(plotTrackingIterationInfo || plotResidual)
{
// for debug plot only: find x,y again.
// horribly inefficient, but who cares at this point...
Eigen::Vector3f point = KLvl * (*refPoint);
int x = point[0] / point[2] + 0.5f;
int y = point[1] / point[2] + 0.5f;
if(plotTrackingIterationInfo)
{
setPixelInCvMat(&debugImageOldImageSource,getGrayCvPixel((float)resInterp[2]),u_new+0.5,v_new+0.5,(width/w));
setPixelInCvMat(&debugImageOldImageWarped,getGrayCvPixel((float)resInterp[2]),x,y,(width/w));
}
if(isGood)
setPixelInCvMat(&debugImageResiduals,getGrayCvPixel(residual+128),x,y,(width/w));
else
setPixelInCvMat(&debugImageResiduals,cv::Vec3b(0,0,255),x,y,(width/w));
}
循环结束之后,记录所有的改变值,以及计算迭代之后得到的相似变换系数,之后如果有debug,那么结束它,最后返回平均残差
buf_warped_size = idx;
pointUsage = usageCount / (float)refNum;
lastGoodCount = goodCount;
lastBadCount = badCount;
lastMeanRes = sumSignedRes / goodCount;
affineEstimation_a_lastIt = sqrtf((syy - sy*sy/sw) / (sxx - sx*sx/sw));
affineEstimation_b_lastIt = (sy - affineEstimation_a_lastIt*sx)/sw;
calcResidualAndBuffers_debugFinish(w);
return sumResUnweighted / goodCount;
trackFrame
SE3 trackFrame(TrackingReference* reference, Frame* frame, const SE3& frameToReference_initialEstimate)是特别重要的一个函数,接下来认真分析这个函数是如何实现的
boost::shared_lock<boost::shared_mutex> lock = frame->getActiveLock();
diverged = false;
trackingWasGood = true;
affineEstimation_a = 1; affineEstimation_b = 0;
if(saveAllTrackingStages)
{
saveAllTrackingStages = false;
saveAllTrackingStagesInternal = true;
}
if (plotTrackingIterationInfo)
{
const float* frameImage = frame->image();
for (int row = 0; row < height; ++ row)
for (int col = 0; col < width; ++ col)
setPixelInCvMat(&debugImageSecondFrame,getGrayCvPixel(frameImage[col+row*width]), col, row, 1);
}
以上部分是参数的一些配置和初始化,其中最后部分的setPixelInCvMat其实是为了可视化使用的,它将传入帧中的图片灰度化后设置到debugImageSecondFrame中,用于查看当前帧的数据数据图像数据
之后是Tracking部分,首先将初始估计记录下来(记录了参考帧到当前帧的刚度变换),然后定义一个6自由度矩阵的误差判别计算对象ls,定义cell数量以及最终的残差
Sophus::SE3f referenceToFrame = frameToReference_initialEstimate.inverse().cast<float>();
LGS6 ls;
int numCalcResidualCalls[PYRAMID_LEVELS];
int numCalcWarpUpdateCalls[PYRAMID_LEVELS];
float last_residual = 0;
之后进入循环,从Tracking的最高等级开始,向下计算
首先得到点云,然后使用callOptimized函数调用calcResidualAndBuffers,参数为后面括号里面的所有数据,这是调用的宏定义
#define callOptimized(function, arguments) function arguments
在这个函数中,把buf_warped相关的参数全部更新,并且更新了上次的相似变换参数等,详见calcResidualAndBuffers函数分析
在此之后,判断这个warp的好坏(如果改变的太多,已经超过了这一层图片的1%),那么我们认为差别太大,Tracking失败,返回一个空的SE3
if(buf_warped_size < MIN_GOODPERALL_PIXEL_ABSMIN * (width>>lvl)*(height>>lvl))
{
diverged = true;
trackingWasGood = false;
return SE3();
}
首先判断是否使用简单的仿射变换,如果使用了,那么把通过calcResidualAndBuffers函数更新的affineEstimation_a_lastIt以及affineEstimation_b_lastIt,赋值给仿射变换系数
if(useAffineLightningEstimation)
{
affineEstimation_a = affineEstimation_a_lastIt;
affineEstimation_b = affineEstimation_b_lastIt;
}
然后调用calcWeightsAndResidual得到误差,并记录调用次数
float lastErr = callOptimized(calcWeightsAndResidual,(referenceToFrame));
numCalcResidualCalls[lvl]++;
calcWeightsAndResidual函数相对简单,我不想过多阐述,请自行研究代码
float SE3Tracker::calcWeightsAndResidual(
const Sophus::SE3f& referenceToFrame)
{
float tx = referenceToFrame.translation()[0];
float ty = referenceToFrame.translation()[1];
float tz = referenceToFrame.translation()[2];
float sumRes = 0;
for(int i=0;i<buf_warped_size;i++)
{
float px = *(buf_warped_x+i); // x'
float py = *(buf_warped_y+i); // y'
float pz = *(buf_warped_z+i); // z'
float d = *(buf_d+i); // d
float rp = *(buf_warped_residual+i); // r_p
float gx = *(buf_warped_dx+i); // \delta_x I
float gy = *(buf_warped_dy+i); // \delta_y I
float s = settings.var_weight * *(buf_idepthVar+i); // \sigma_d^2
// calc dw/dd (first 2 components):
float g0 = (tx * pz - tz * px) / (pz*pz*d);
float g1 = (ty * pz - tz * py) / (pz*pz*d);
// calc w_p
float drpdd = gx * g0 + gy * g1; // ommitting the minus
float w_p = 1.0f / ((cameraPixelNoise2) + s * drpdd * drpdd);
float weighted_rp = fabs(rp*sqrtf(w_p));
float wh = fabs(weighted_rp < (settings.huber_d/2) ? 1 : (settings.huber_d/2) / weighted_rp);
sumRes += wh * w_p * rp*rp;
*(buf_weight_p+i) = wh * w_p;
}
return sumRes / buf_warped_size;
}
然后是调用LM算法更新参数,首先我们来看看SE3Tracker::calculateWarpUpdate函数
首先现将ls参数初始化成默认值
ls.initialize(width*height);
然后本地化参数
float px = *(buf_warped_x+i);
float py = *(buf_warped_y+i);
float pz = *(buf_warped_z+i);
float r = *(buf_warped_residual+i);
float gx = *(buf_warped_dx+i);
float gy = *(buf_warped_dy+i);
然后计算误差向量
float z = 1.0f / pz;
float z_sqr = 1.0f / (pz*pz);
Vector6 v;
v[0] = z*gx + 0;
v[1] = 0 + z*gy;
v[2] = (-px * z_sqr) * gx +
(-py * z_sqr) * gy;
v[3] = (-px * py * z_sqr) * gx +
(-(1.0 + py * py * z_sqr)) * gy;
v[4] = (1.0 + px * px * z_sqr) * gx +
(px * py * z_sqr) * gy;
v[5] = (-py * z) * gx +
(px * z) * gy;
最后更新到ls参数中,得到最小二乘法方程
ls.update(v, r, *(buf_weight_p+i));
回到Tracking,让我们继续看LM算法的迭代,首先更新ls中的参数,然后记录更新次数,并记录是第几次迭代
callOptimized(calculateWarpUpdate,(ls));
numCalcWarpUpdateCalls[lvl]++;
iterationNumber = iteration;
然后最小二乘法方程
// solve LS system with current lambda
Vector6 b = -ls.b;
Matrix6x6 A = ls.A;
for(int i=0;i<6;i++) A(i,i) *= 1+LM_lambda;
Vector6 inc = A.ldlt().solve(b);
得到最优解后,计算新的变换矩阵
Sophus::SE3f new_referenceToFrame = Sophus::SE3f::exp((inc)) * referenceToFrame;

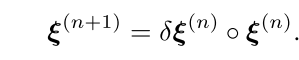
实际上上面两步就是在计算论文中这个过程,只不过写成了线性方程求解的形式
之后再次调用calcResidualAndBuffers计算warpedbuffer以及残差值,然后再次进行前面同样的操作
callOptimized(calcResidualAndBuffers, ...); //看源码的输入,太长了,我省略不写了
if(buf_warped_size < MIN_GOODPERALL_PIXEL_ABSMIN* (width>>lvl)*(height>>lvl))
{
diverged = true;
trackingWasGood = false;
return SE3();
}
float error = callOptimized(calcWeightsAndResidual,(new_referenceToFrame));
numCalcResidualCalls[lvl]++;
之后判断误差是否变小,如果变小,那么接受刚刚的修正,否则判断是否已经小于最小步长,如果已经小于,直接跳出所有循环,否则改变LM_lambda的值,重新进行while循环
if(error < lastErr)
...
else
{
if(enablePrintDebugInfo && printTrackingIterationInfo)
{
printf("(%d-%d): REJECTED increment of %f with lambda %.1f, (residual: %f -> %f)\n",
lvl,iteration, sqrt(inc.dot(inc)), LM_lambda, lastErr, error);
}
if(!(inc.dot(inc) > settings.stepSizeMin[lvl]))
{
if(enablePrintDebugInfo && printTrackingIterationInfo)
{
printf("(%d-%d): FINISHED pyramid level (stepsize too small).\n",
lvl,iteration);
}
iteration = settings.maxItsPerLvl[lvl];
break;
}
if(LM_lambda == 0)
LM_lambda = 0.2;
else
LM_lambda *= std::pow(settings.lambdaFailFac, incTry);
}
接受之后的操作:
首先是仿射系数修正,然后是判断是否收敛,如果收敛了就跳出跌打循环(把迭代次数置于最大值),之后更新误差,然后更新LM_lambda值,结束while的循环,进行下一次迭代
referenceToFrame = new_referenceToFrame;
if(useAffineLightningEstimation)
{
affineEstimation_a = affineEstimation_a_lastIt;
affineEstimation_b = affineEstimation_b_lastIt;
}
// converged?
if(error / lastErr > settings.convergenceEps[lvl])
{
if(enablePrintDebugInfo && printTrackingIterationInfo)
{
printf("(%d-%d): FINISHED pyramid level (last residual reduction too small).\n",
lvl,iteration);
}
iteration = settings.maxItsPerLvl[lvl];
}
last_residual = lastErr = error;
if(LM_lambda <= 0.2)
LM_lambda = 0;
else
LM_lambda *= settings.lambdaSuccessFac;
break;
迭代计算之后是保存状态
saveAllTrackingStagesInternal = false;
lastResidual = last_residual;
trackingWasGood = !diverged
&& lastGoodCount / (frame->width(SE3TRACKING_MIN_LEVEL)*frame->height(SE3TRACKING_MIN_LEVEL)) > MIN_GOODPERALL_PIXEL
&& lastGoodCount / (lastGoodCount + lastBadCount) > MIN_GOODPERGOODBAD_PIXEL;
if(trackingWasGood)
reference->keyframe->numFramesTrackedOnThis++;
然后更新传入帧的属性,记录误差,到参考帧的变换,以及参考帧的信息,最后返回当前帧到参考帧的变换
frame->initialTrackedResidual = lastResidual / pointUsage;
frame->pose->thisToParent_raw = sim3FromSE3(toSophus(referenceToFrame.inverse()),1);
frame->pose->trackingParent = reference->keyframe->pose;
return toSophus(referenceToFrame.inverse());
我想在理解SE3Tracker::trackFrame函数后SE3Tracker::trackFrameOnPermaref已经很简单了他们的区别在于一个用于精确计算,一个用于快速计算,前者是在每次计算的时候,重新计算了点云,使得整个计算更加精确,但是需要付出计算点云的开销,后面那个直接使用每一帧原来存储的点云信息,效率明显更高,但是会付出精度的代价,具体程序请自行阅读
SE3Tracker::checkPermaRefOverlap
首先韩式本地化参数
Sophus::SE3f referenceToFrame = referenceToFrameOrg.cast<float>();
boost::unique_lock<boost::mutex> lock2 = boost::unique_lock<boost::mutex>(reference->permaRef_mutex);
int w2 = reference->width(QUICK_KF_CHECK_LVL)-1;
int h2 = reference->height(QUICK_KF_CHECK_LVL)-1;
Eigen::Matrix3f KLvl = reference->K(QUICK_KF_CHECK_LVL);
float fx_l = KLvl(0,0);
float fy_l = KLvl(1,1);
float cx_l = KLvl(0,2);
float cy_l = KLvl(1,2);
Eigen::Matrix3f rotMat = referenceToFrame.rotationMatrix();
Eigen::Vector3f transVec = referenceToFrame.translation();
const Eigen::Vector3f* refPoint_max = reference->permaRef_posData + reference->permaRefNumPts;
const Eigen::Vector3f* refPoint = reference->permaRef_posData;
之后进入循环,先计算图像上的坐标
Eigen::Vector3f Wxp = rotMat * (*refPoint) + transVec;
float u_new = (Wxp[0]/Wxp[2])*fx_l + cx_l;
float v_new = (Wxp[1]/Wxp[2])*fy_l + cy_l;
判断是否在图像内部,如果在,记录到usageCount中
if((u_new > 0 && v_new > 0 && u_new < w2 && v_new < h2))
{
float depthChange = (*refPoint)[2] / Wxp[2];
usageCount += depthChange < 1 ? depthChange : 1;
}
最后得到pointUsage,并返回
pointUsage = usageCount / (float)reference->permaRefNumPts;
return pointUsage;
这个函数介绍完毕之后,我想SE3Tracking类就介绍的差不多了,它主要是用来计算当前帧和参考帧之间的刚体变换,以及检测Tracking是否足够好的一个很大的类,其中Tracking提供了两个方法,一个精确但速度慢一些,一个快,但精度低一些,他们内部都维护了Weighted Gauss-Newton Optimization优化方法,设置了大量检测的阈值,并且涉及到大量的坐标变换(图像之间的投影,世界坐标向图像即投影,两帧之间的坐标转换关系等),这无疑是一个特别核心的类,理解了这个类之后,其实Sim3Tracking和这个类是几乎完全一样的,读者可以试图自己分析它的实现,来进一步掌握Tracking类的实现方法
Relocalizer
在介绍Tracking的核心类之后,我们最后介绍一下,假如Tracking失败了,那么它应该做的操作,即Relocalizer(重定位)
在论文里面,并没有提及Relocalizer的事,我希望能够通过代码,介绍一下这部分是如何处理的
void start(std::vector > &allKeyframesList)
首先是这个函数,进入之后先清空之前记录的假如丢失后,给重新找回机制分配的那些帧(KFForReloc,本文把他叫做找回参考帧)
// make KFForReloc List
KFForReloc.clear();
然后把传入的那些keyFrame压入KFForReloc中,并打乱顺序
for(unsigned int k=0;k < allKeyframesList.size(); k++)
{
// insert
KFForReloc.push_back(allKeyframesList[k]);
// swap with a random element
int ridx = rand()%(KFForReloc.size());
Frame* tmp = KFForReloc.back();
KFForReloc.back() = KFForReloc[ridx];
KFForReloc[ridx] = tmp;
}
初始化nextRelocIDx,以及最大的找回参考帧ID,然后打开找回线程
nextRelocIDX=0;
maxRelocIDX=KFForReloc.size();
hasResult = false;
continueRunning = true;
isRunning = true;
// start threads
for(int i=0;i<RELOCALIZE_THREADS;i++)
{
relocThreads[i] = boost::thread(&Relocalizer::threadLoop, this, i);
running[i] = true;
}
void threadLoop(int idx)
这个函数是找回线程中运行的函数,也是这个类的核心函数
首先初始化了一个SE3Tracker的对象,调用构造函数时传入了帧的宽度,高度以及相机矩阵
之后自然是线程锁,然后判断是否是可以运行(这个成员用于stop),如果可以,那么进入循环
if(!multiThreading && idx != 0) return;
SE3Tracker* tracker = new SE3Tracker(w,h,K);
boost::unique_lock<boost::mutex> lock(exMutex);
while(continueRunning)
然后做在不越界的条件下抽取一帧,nextRelocIDX自加
Frame* todo = KFForReloc[nextRelocIDX%KFForReloc.size()];
nextRelocIDX++;
由于对关键帧都有插入操作(插入到之前的帧中),所以它自然有相邻的帧,我们把它周围的帧叫做它的邻近帧,为了重定位足够好而且足够快,我们在选择帧之后,判断它的邻近帧是不是足够多(因为实际上可能它只和一两个帧连起来,这种帧用来重定位并不那么好)
if(todo->neighbors.size() <= 2) continue;
满足要求之后,把当前的参考帧作为需要找回帧,调用trackFrameOnPermaref函数,快速地找到这一帧到找回帧的坐标转换关系,然后计算这个tracking的分数(看他好不好,通过平均分乘以匹配上的好的匹配个数,所有的匹配个数)
SE3 todoToFrame = tracker->trackFrameOnPermaref(todo, myRelocFrame.get(), SE3());
// try neighbours
float todoGoodVal = tracker->pointUsage * tracker->lastGoodCount / (tracker->lastGoodCount+tracker->lastBadCount);
如果这个匹配比较好,那么继续后续工作
之后查看附近帧的匹配情况,首先还是初始化
int numGoodNeighbours = 0;
int numBadNeighbours = 0;
float bestNeightbourGoodVal = todoGoodVal;
float bestNeighbourUsage = tracker->pointUsage;
Frame* bestKF = todo;
SE3 bestKFToFrame = todoToFrame;
然后遍历整个附近帧(c++11新语法)
for(Frame* nkf : todo->neighbors)
得到当前帧到附近帧的变换,然后再快速Tracking,之后判断Tracking是否足够好,并且判断是否比最好的那个匹配更好,如果匹配更好,那么更新最好的匹配
SE3 nkfToFrame_init = se3FromSim3((nkf->getScaledCamToWorld().inverse() * todo->getScaledCamToWorld() * sim3FromSE3(todoToFrame.inverse(), 1))).inverse();
SE3 nkfToFrame = tracker->trackFrameOnPermaref(nkf, myRelocFrame.get(), nkfToFrame_init);
float goodVal = tracker->pointUsage * tracker->lastGoodCount / (tracker->lastGoodCount+tracker->lastBadCount);
if(goodVal > relocalizationTH*0.8 && (nkfToFrame * nkfToFrame_init.inverse()).log().norm() < 0.1)
numGoodNeighbours++;
else
numBadNeighbours++;
if(goodVal > bestNeightbourGoodVal)
{
bestNeightbourGoodVal = goodVal;
bestKF = nkf;
bestKFToFrame = nkfToFrame;
bestNeighbourUsage = tracker->pointUsage;
循环完毕之后,判断是否邻近帧的匹配比较好,如果比较好,那么表明已经找到,停止查找
if(numGoodNeighbours > numBadNeighbours || numGoodNeighbours >= 5)
{
// set everything to stop!
continueRunning = false;
lock.lock();
resultRelocFrame = myRelocFrame;
resultFrameID = myRelocFrame->id();
resultKF = bestKF;
resultFrameToKeyframe = bestKFToFrame.inverse();
resultReadySignal.notify_all();
hasResult = true;
lock.unlock();
}
最后把数据锁上,避免再次访问到这一个召回参考帧
lock.lock();
其他函数都比较简单,请读者自行查看,至此,Tracking模块的源码解析全部结束,想要真正了解代码,我觉得还需要多阅读论文,把代码和论文相互印证,理解其含义,并且程序中有很多小技巧,希望读者仔细体会
