@songhanshi
2020-12-14T11:24:04.000000Z
字数 47008
阅读 770
redis
Java学习
资料地址
-
- 电子书:
书籍资料
- rky:《redis开发与运维》【1】
- rss:《redis设计与实现》【2】 http://redisbook.com/
redis
- 日志
Redis3.0之后在输出的日志开头会有M、S、C等标识,对应的含义是:M=当前为主节点日志,S=当前为从节点日志,C=子进程日志
1 初识redis
1-是什么
- redis简介?
- 一种基于键值对(key-value)的NoSQL数据库,
- 与很多键值对数据库不同的是,Redis中的值可以是由string(字符串)、hash(哈希)、list(列表)、set(集合)、zset(有序集合)、Bitmaps(位图)、 HyperLogLog、GEO(地理信息定位)等多种数据结构和算法组成,因此 Redis可以满足很多的应用场景,
- Redis会将所有数据都存放在内存中,使它的读写性能非常惊人。
- 还可以将内存的数据利用快照和日志的形式保存到硬盘上,这样在发生类似断电或者机器故障的时候,内存中的数据不会“丢失”。
- 除了上述功能以外,还提供了键过期、发布订阅、事务、流水线、Lua脚本等附加功能。
2-Redis的8个重要特性
redis特性
1)速度快
2)基于键值对的数据结构服务器
3)丰富的功能
4)简单稳定
5)客户端语言多
6)持久化
7)主从复制
8)高可用和分布式读写速度?
忽略机器性能上的差异,官方给出的数字是读写性能可以达到10万/秒。Redis速度非常快的原因?
- Redis的所有数据都是存放在内存中的,是最主要原因;
- Redis是用C语言实现的,一般来说C语言实现的程序“距离”操作系统更近,执行速度相对会更快。
- Redis使用了单线程架构,预防了多线程可能产生的竞争问题。
- 作者对于Redis源代码可以说是精打细磨,曾经有人评价Redis是少有的集性能和优雅于一身的开源代码
5种数据结构
- Redis的全称是REmote Dictionary Server
- 主要提供了5种数据结构:字符串、哈希、列表、集合、有序集合,同时在字符串的基础之上演变出了位图(Bitmaps)和HyperLogLog两种神奇的“数据结构”,并且随着LBS(Location Based Service,基于位置服务)的不断发展,Redis3.2版本中 加入有关GEO(地理信息定位)的功能。
除了5种数据结构,Redis还提供了许多额外的功能?
- 提供了键过期功能,可以用来实现缓存。
- 提供了发布订阅功能,可以用来实现消息系统。
- 支持Lua脚本功能,可以利用Lua创造出新的Redis命令。
- 提供了简单的事务功能,能在一定程度上保证事务特性。 * 提供了流水线(Pipeline)功能,这样客户端能将一批命令一次性传到 Redis,减少了网络的开销。
Redis可以做什么
1.缓存
缓存机制几乎在所有的大型网站都有使用,合理地使用缓存不仅可以加 快数据的访问速度,而且能够有效地降低后端数据源的压力。Redis提供了 键值过期时间设置,并且也提供了灵活控制最大内存和内存溢出后的淘汰策 略。可以这么说,一个合理的缓存设计能够为一个网站的稳定保驾护航。第 11章将对缓存的设计与使用进行详细说明。
2.排行榜系统
排行榜系统几乎存在于所有的网站,例如按照热度排名的排行榜,按照 发布时间的排行榜,按照各种复杂维度计算出的排行榜,Redis提供了列表 和有序集合数据结构,合理地使用这些数据结构可以很方便地构建各种排行 榜系统。
3.计数器应用
计数器在网站中的作用至关重要,例如视频网站有播放数、电商网站有 浏览数,为了保证数据的实时性,每一次播放和浏览都要做加1的操作,如 果并发量很大对于传统关系型数据的性能是一种挑战。Redis天然支持计数 功能而且计数的性能也非常好,可以说是计数器系统的重要选择。
4.社交网络
赞/踩、粉丝、共同好友/喜好、推送、下拉刷新等是社交网站的必备功 38
能,由于社交网站访问量通常比较大,而且传统的关系型数据不太适合保存 这种类型的数据,Redis提供的数据结构可以相对比较容易地实现这些功 能。
5.消息队列系统
消息队列系统可以说是一个大型网站的必备基础组件,因为其具有业务 解耦、非实时业务削峰等特性。Redis提供了发布订阅功能和阻塞队列的功 能,虽然和专业的消息队列比还不够足够强大,但是对于一般的消息队列功 能基本可以满足。redis为什么那么快?
正常情况下,Redis执行命令的速度非常快,官方给出的数字是读写性 能可以达到10万/秒,当然这也取决于机器的性能,但这里先不讨论机器性 能上的差异,只分析一下是什么造就了Redis除此之快的速度,可以大致归 纳为以下四点:
·Redis的所有数据都是存放在内存中的,表1-1是谷歌公司2009年给出的 各层级硬件执行速度,所以把数据放在内存中是Redis速度快的最主要原 因。
·Redis是用C语言实现的,一般来说C语言实现的程序“距离”操作系统更 近,执行速度相对会更快。
·Redis使用了单线程架构,预防了多线程可能产生的竞争问题。
·作者对于Redis源代码可以说是精打细磨,曾经有人评价Redis是少有的 集性能和优雅于一身的开源代码。
2. 数据结构
1-单线程架构
通过多个客户端命令调用的例子说明Redis单线程命令处理
机制,接着分析Redis单线程模型为什么性能如此之高。多个客户端命令调用的例子说明Redis单线程命令处理机制?
开启了三个redis-cli客户端同时执行命令。
// 客户端1设置一个字符串键值对:> set hello world// 客户端2对counter做自增操作:> incr counter// 客户端3对counter做自增操作:> incr counter
每次客户端调用都经历了发送命令、执行命令、返回结果三个过程。Redis客户端与服务端的模型可以简化如图:
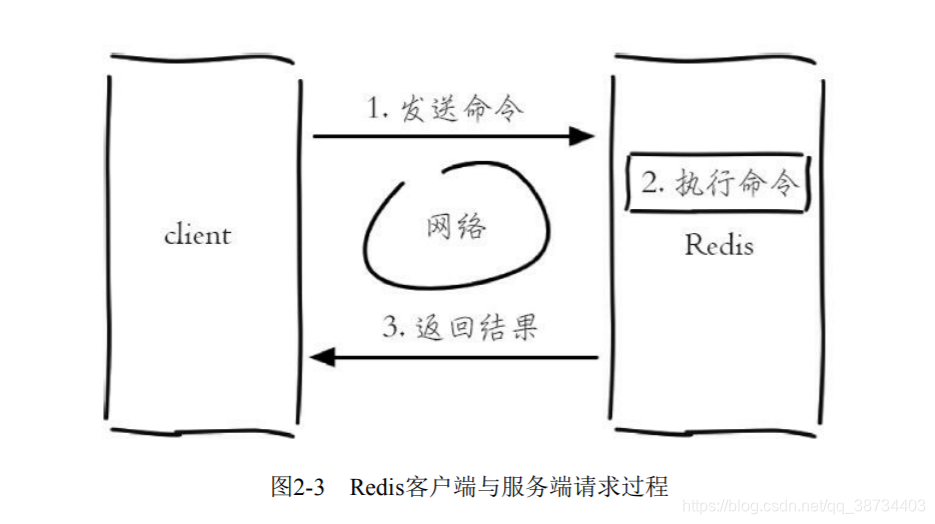
- 其中,第2步是重点要讨论的,因为Redis是单线程来处理命令的,所以一条命令从客户端达到服务端不会立刻被执行,所有命令都会进入一个队列中,然后逐个被执行。
- 所以上面3个客户端命令的执行顺序是不确定的,但是可以确定不会有两条命令被同时执行,所以两条incr命令无论怎么执行最终结果都是2,不会产生并发问题,这就是Redis单线程的基本模型。
- 但是像发送命令、返回结果、命令排队肯定不像描述的这么简单,Redis使用了I/O多路复用技术来解决I/O的问题,下一节将进行介绍。
为什么单线程还能这么快?
第一,纯内存访问,Redis将所有数据放在内存中,内存的响应时长大 约为100纳秒,这是Redis达到每秒万级别访问的重要基础。
第二,非阻塞I/O,Redis使用epoll作为I/O多路复用技术的实现,再加上 Redis自身的事件处理模型将epoll中的连接、读写、关闭都转换为事件,不在网络I/O上浪费过多的时间。如下图
第三,单线程避免了线程切换和竞态产生的消耗。非阻塞I/O
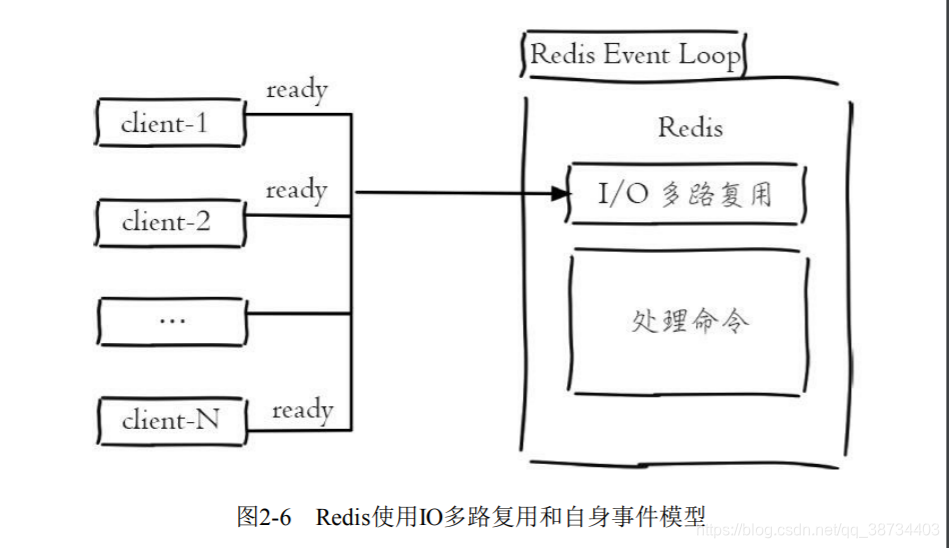
单线程的优缺点?
- 单线程能带来几个好处:
第一,单线程可以简化数据结构和算法的实现。
如果对高级编程语言熟悉的读者应该了解并发数据结构实现不但困难
而且开发测试比较麻烦。
第二,单线程避免了线程切换和竞态产生的消耗,对于服务端开发来说,锁和线程切换通常是性能杀手。 - 但是单线程会有一个问题:
对于每个命令的执行时间是有要求的。
如果某个命令执行过长,会造成其他命令的阻塞,对于Redis这种高性能的服务来说是致命的,所以Redis是面向快速执行场景的数据库。
- 单线程能带来几个好处:
2-内部编码
- 每种数据结构都有两种以上的内部编码实现,例如list数据结构包含了linkedlist和ziplist两种内部编码

数据结构
- 概述

1 long类型的整数
2 简单动态字符串|raw
|C字符串|SDS|SDS作用|SDS实现|和C的区别|为什么用SDS|||
关于C语言的字符串?
- C语言传统的字符串表示(以空字符结尾的字符数组,以下简称C字符串)
- Redis里面,C字符串只会作为字符串字面量(string literal)用在一些无须对字符串值进行修改的地方,比如打印日志:
redisLog(REDIS_WARNING,"Redis is now ready to exit, bye bye...");
redis构建的字符串?
- 简单动态字符串(simple dynamic string,SDS)的抽象类型;
- 用作Redis的默认字符串表示;
- 当Redis需要的不仅仅是一个字符串字面量,而是一个可以被修改的字符串值时,Redis就会使用SDS来表示字符串值,比如在Redis的数据库里面,包含字符串值的键值对在底层都是由SDS实现的。
SDS的应用?
- 1)用来保存数据库中的字符串值;
2)用作缓冲区(buffer):AOF模块中的AOF缓冲区,以及客户端状态中的输入缓冲区,都是由SDS实现的;
- 1)用来保存数据库中的字符串值;
SDS的实现?
- SDS的定义
1)每个sds.h/sdshdr结构表示一个SDS值:
struct sdshdr {// 记录buf数组中已使用字节的数量等于SDS所保存字符串的长度int len;// 记录buf数组中未使用字节的数量int free;// 字节数组,用于保存字符串char buf[];};
2)示例
·free属性的值为0,表示这个SDS没有分配任何未使用空间。
·len属性的值为5,表示这个SDS保存了一个五字节长的字符串。
·buf属性是一个char类型的数组,数组的前五个字节分别保存了'R'、'e'、'd'、'i'、's'五个字符,而最后一个字节则保存了空字符'\0'。


-- SDS遵循C字符串以空字符结尾的惯例,保存空字符的1字节空间不计算在SDS的len属性里面,并且为空字符分配额外的1字节空间,以及添加空字符到字符串末尾等操作,都是由SDS函数自动完成的,所以这个空字符对于SDS的使用者来说是完全透明的。遵循空字符结尾这一惯例的好处是,SDS可以直接重用一部分C字符串函数库里面的函数。
-- 上两个图展示的SDS的区别在于,这个SDS为buf数组分配了五字节未使用空间,所以它的free属性的值为5(图中使用五个空格来表示五字节的未使用空间)。- SDS的定义
SDS与C字符串的区别?
- 根据传统,C语言使用长度为N+1的字符数组来表示长度为N的字符串,并且字符数组的最后一个元素总是空字符'\0'。
- 1)常数复杂度获取字符串长度
-- C字符串:C字符串并不记录自身的长度信息,所以为了获取一个C字符串的长度,程序必须遍历整个字符串,对遇到的每个字符进行计数,直到遇到代表字符串结尾的空字符为止,这个操作的复杂度为O(N)。
-- SDS:和C字符串不同,因为SDS在len属性中记录了SDS本身的长度,所以获取一个SDS长度的复杂度仅为O(1)。
设置和更新SDS长度的工作是由SDS的API在执行时自动完成的,使用SDS无须进行任何手动修改长度的工作。
-- 总:通过使用SDS而不是C字符串,Redis将获取字符串长度所需的复杂度从O(N)降低到了O(1),这确保了获取字符串长度的工作不会成为Redis的性能瓶颈。 - 2)杜绝缓冲区溢出
-- 缓冲区溢出:C字符串不记录自身长度带来的另一个问题是容易造成缓冲区溢出(buffer overflow)。
例子,/strcat函数可以将src字符串中的内容拼接到dest字符串的末尾:
char *strcat(char *dest, const char *src);
-- C字符串:因为C字符串不记录自身的长度,所以strcat假定用户在执行这个函数时,已经为dest分配了足够多的内存,可以容纳src字符串中的所有内容,而一旦这个假定不成立时,就会产生缓冲区溢出。
-- SDS:与C字符串不同,SDS的空间分配策略完全杜绝了发生缓冲区溢出的可能性:当SDS API需要对SDS进行修改时,API会先检查SDS的空间是否满足修改所需的要求,如果不满足的话,API会自动将SDS的空间扩展至执行修改所需的大小,然后才执行实际的修改操作,所以使用SDS既不需要手动修改SDS的空间大小,也不会出现前面所说的缓冲区溢出问题。 - 3)减少修改字符串时带来的内存重分配次数
-- 现象:因为内存重分配涉及复杂的算法,并且可能需要执行系统调用,所以它通常是一个比较耗时的操作:
· 在一般程序中,如果修改字符串长度的情况不太常出现,那么每次修改都执行一次内存重分配是可以接受的。
· 但是Redis作为数据库,经常被用于速度要求严苛、数据被频繁修改的场合,如果每次修改字符串的长度都需要执行一次内存重分配的话,那么光是执行内存重分配的时间就会占去修改字符串所用时间的一大部分,如果这种修改频繁地发生的话,可能还会对性能造成影响。
-- C字符串:因为C字符串并不记录自身的长度,所以对于一个包含了N个字符的C字符串来说,这个C字符串的底层实现总是一个N+1个字符长的数组(额外的一个字符空间用于保存空字符)。因为C字符串的长度和底层数组的长度之间存在着这种关联性,所以每次增长或者缩短一个C字符串,程序都总要对保存这个C字符串的数组进行一次内存重分配操作:
· 如果程序执行的是增长字符串的操作,比如拼接操作(append),那么在执行这个操作之前,程序需要先通过内存重分配来扩展底层数组的空间大小——如果忘了这一步就会产生缓冲区溢出。
· 如果程序执行的是缩短字符串的操作,比如截断操作(trim),那么在执行这个操作之后,程序需要通过内存重分配来释放字符串不再使用的那部分空间——如果忘了这一步就会产生内存泄漏。
-- SDS:为了避免C字符串的这种缺陷,SDS通过未使用空间解除了字符串长度和底层数组长度之间的关联:在SDS中,buf数组的长度不一定就是字符数量加一,数组里面可以包含未使用的字节,而这些字节的数量就由SDS的free属性记录。 - 3)二进制安全
-- C字符串:C字符串中的字符必须符合某种编码(比如ASCII),并且除了字符串的末尾之外,字符串里面不能包含空字符,否则最先被程序读入的空字符将被误认为是字符串结尾,这些限制使得C字符串只能保存文本数据,而不能保存像图片、音频、视频、压缩文件这样的二进制数据。
-- SDS:虽然数据库一般用于保存文本数据,但使用数据库来保存二进制数据的场景也不少见,因此,为了确保Redis可以适用于各种不同的使用场景,SDS的API都是二进制安全的(binary-safe),所有SDS API都会以处理二进制的方式来处理SDS存放在buf数组里的数据,程序不会对其中的数据做任何限制、过滤、或者假设,数据在写入时是什么样的,它被读取时就是什么样。
这也是我们将SDS的buf属性称为字节数组的原因——Redis不是用这个数组来保存字符,而是用它来保存一系列二进制数据。
-- 总:通过使用二进制安全的SDS,而不是C字符串,使得Redis不仅可以保存文本数据,还可以保存任意格式的二进制数据。 - 4)兼容部分C字符串函数
-- 虽然SDS的API都是二进制安全的,但它们一样遵循C字符串以空字符结尾的惯例:这些API总会将SDS保存的数据的末尾设置为空字符,并且总会在为buf数组分配空间时多分配一个字节来容纳这个空字符,这是为了让那些保存文本数据的SDS可以重用一部分库定义的函数。
-- 总:通过遵循C字符串以空字符结尾的惯例,SDS可以在有需要时重用函数库,从而避免了不必要的代码重复。

未使用空间,SDS实现的空间预分配和惰性空间释放两种优化策略? - 减少修改字符串时带来的内存重分配次数
- ① 空间预分配
-- 空间预分配用于优化SDS的字符串增长操作:当SDS的API对一个SDS进行修改,并且需要对SDS进行空间扩展的时候,程序不仅会为SDS分配修改所必须要的空间,还会为SDS分配额外的未使用空间。
-- 其中,额外分配的未使用空间数量由以下公式决定:
· 如果对SDS进行修改之后,SDS的长度(也即是len属性的值)将小于1MB,那么程序分配和len属性同样大小的未使用空间,这时SDS len属性的值将和free属性的值相同。举个例子,如果进行修改之后,SDS的len将变成13字节,那么程序也会分配13字节的未使用空间,SDS的buf数组的实际长度将变成13+13+1=27字节(额外的一字节用于保存空字符)。
· 如果对SDS进行修改之后,SDS的长度将大于等于1MB,那么程序会分配1MB的未使用空间。
举个例子,如果进行修改之后,SDS的len将变成30MB,那么程序会分配1MB的未使用空间,SDS的buf数组的实际长度将为30MB+1MB+1byte。
-- 通过空间预分配策略,Redis可以减少连续执行字符串增长操作所需的内存重分配次数。
-- 在扩展SDS空间之前,SDSAPI会先检查未使用空间是否足够,如果足够的话,API就会直接使用未使用空间,而无须执行内存重分配。
-- 通过这种预分配策略,SDS将连续增长N次字符串所需的内存重分配次数从必定N次降低为最多N次。 - ② 惰性空间释放
-- 惰性空间释放用于优化SDS的字符串缩短操作:当SDS的API需要缩短SDS保存的字符串时,程序并不立即使用内存重分配来回收缩短后多出来的字节,而是使用free属性将这些字节的数量记录起来,并等待将来使用。
-- 通过惰性空间释放策略,SDS避免了缩短字符串时所需的内存重分配操作,并为将来可能有的增长操作提供了优化。
-- 与此同时,SDS也提供了相应的API,让我们可以在有需要时,真正地释放SDS的未使用空间,所以不用担心惰性空间释放策略会造成内存浪费。
- ① 空间预分配
解释为什么Redis要使用SDS而不是C字符串?
- 比起C字符串,SDS具有以下优点:
1)常数复杂度获取字符串长度。
2)杜绝缓冲区溢出。
3)减少修改字符串长度时所需的内存重分配次数。
4)二进制安全。
5)兼容部分C字符串函数。
- 比起C字符串,SDS具有以下优点:
3 链表-linkedlist
链表基本知识?
- 链表提供了高效的节点重排能力,以及顺序性的节点访问方式,并且可以通过增删节点来灵活地调整链表的长度。
- 作为一种常用数据结构,链表内置在很多高级的编程语言里面,因为Redis使用的C语言并没有内置这种数据结构,所以Redis构建了自己的链表实现。
- 链表在Redis中的应用非常广泛,比如列表键的底层实现之一就是链表。当一个列表键包含了数量比较多的元素,又或者列表中包含的元素都是比较长的字符串时,Redis就会使用链表作为列表键的底层实现。
- 作用:
-- integers列表键的底层实现就是一个链表,链表中的每个节点都保存了一个整数值。
-- 除了链表键之外,发布与订阅、慢查询、监视器等功能也用到了链表,Redis服务器本身还使用链表来保存多个客户端的状态信息,以及使用链表来构建客户端输出缓冲区(output buffer)
链表和链表节点的实现?
- 每个链表节点使用一个adlist.h/listNode结构来表示:
- 多个listNode可以通过prev和next指针组成双端链表
typedef struct listNode {// 前置节点struct listNode * prev;// 后置节点struct listNode * next;// 节点的值void * value;}listNode;

- 虽然仅仅使用多个listNode结构就可以组成链表,但使用adlist.h/list来持有链表的话,操作起来会更方便:
- 如下,list结构为链表提供了表头指针head、表尾指针tail,以及链表长度计数器len,而dup、free和match成员则是用于实现多态链表所需的类型特定函数:
· dup函数用于复制链表节点所保存的值;
· free函数用于释放链表节点所保存的值;
· match函数则用于对比链表节点所保存的值和另一个输入值是否相等。
typedef struct list {// 表头节点listNode * head;// 表尾节点listNode * tail;// 链表所包含的节点数量unsigned long len;// 节点值复制函数void *(*dup)(void *ptr);// 节点值释放函数void (*free)(void *ptr);// 节点值对比函数int (*match)(void *ptr,void *key);} list;

Redis的链表实现的特性可以总结如下:
- 双端:链表节点带有prev和next指针,获取某个节点的前置节点和后置节点的复杂度都是O(1)。
- 无环:表头节点的prev指针和表尾节点的next指针都指向NULL,对链表的访问以NULL为终点。
- 带表头指针和表尾指针:通过list结构的head指针和tail指针,程序获取链表的表头节点和表尾节点的复杂度为O(1)。
- 带链表长度计数器:程序使用list结构的len属性来对list持有的链表节点进行计数,程序获取链表中节点数量的复杂度为O(1)。
- 多态:链表节点使用void*指针来保存节点值,并且可以通过list结构的dup、free、match三个属性为节点值设置类型特定函数,所以链表可以用于保存各种不同类型的值。
4 字典-hashtable
字典的基本理论?
- 字典,又称为符号表(symbol table)、关联数组(associative array)或映射(map),是一种用于保存键值对(key-value pair)的抽象数据结构。
- 在字典中,一个键(key)可以和一个值(value)进行关联(或者说将键映射为值),这些关联的键和值就称为键值对。
- 字典中的每个键都是独一无二的,程序可以在字典中根据键查找与之关联的值,或者通过键来更新值,又或者根据键来删除整个键值对,等等。
- 字典经常作为一种数据结构内置在很多高级编程语言里面,但Redis所使用的C语言并没有内置这种数据结构,因此Redis构建了自己的字典实现。
- 字典在Redis中的应用相当广泛,比如Redis的数据库就是使用字典来作为底层实现的,对数据库的增、删、查、改操作也是构建在对字典的操作之上的。
- 除了用来表示数据库之外,字典还是哈希键的底层实现之一,当一个哈希键包含的键值对比较多,又或者键值对中的元素都是比较长的字符串时,Redis就会使用字典作为哈希键的底层实现。
- 除了用来实现数据库和哈希键之外,Redis的不少功能也用到了字典
字典的实现?
Redis的字典使用哈希表作为底层实现,一个哈希表里面可以有多个哈希表节点,而每个哈希表节点就保存了字典中的一个键值对。
接下来的三个小节将分别介绍Redis的哈希表、哈希表节点以及字典的实现。- 1)哈希表
-- Redis字典所使用的哈希表由dict.h/dictht结构定义:
---- table属性:是一个数组,数组中的每个元素都是一个指向dict.h/dictEntry结构的指针,每个dictEntry结构保存着一个键值对。
---- size属性:记录了哈希表的大小,也即是table数组的大小,而used属性则记录了哈希表目前已有节点(键值对)的数量。
---- sizemask属性:的值总是等于size-1,这个属性和哈希值一起决定一个键应该被放到table数组的哪个索引上面。
---- 展示了一个大小为4的空哈希表(没有包含任何键值对)。
typedef struct dictht {// 哈希表数组dictEntry **table;// 哈希表大小unsigned long size;// 哈希表大小掩码,用于计算索引值总是等于size-1unsigned long sizemask;// 该哈希表已有节点的数量unsigned long used;} dictht;

- 2)哈希表节点
哈希表节点使用dictEntry结构表示,每个dictEntry结构都保存着一个键值对:
---- key属性:保存着键值对中的键;
---- v属性:则保存着键值对中的值,其中键值对的值可以是一个指针,或者是一个uint64_t整数,又或者是一个int64_t整数。
---- next属性:是指向另一个哈希表节点的指针,这个指针可以将多个哈希值相同的键值对连接在一次,以此来解决键冲突(collision)的问题。
typedef struct dictEntry {// 键void *key;// 值union{void *val;uint64_tu64;int64_ts64;} v;// 指向下个哈希表节点,形成链表struct dictEntry *next;} dictEntry;

- 3)字典
Redis中的字典由dict.h/dict结构表示:
-- type属性和privdata属性是针对不同类型的键值对,为创建多态字典而设置的:
---- type属性:是一个指向dictType结构的指针,每个dictType结构保存了一簇用于操作特定类型键值对的函数,Redis会为用途不同的字典设置不同的类型特定函数。
---- privdata属性:则保存了需要传给那些类型特定函数的可选参数。
---- ht属性:是一个包含两个项的数组,数组中的每个项都是一个dictht哈希表,一般情况下,字典只使用ht[0]哈希表,ht[1]哈希表只会在对ht[0]哈希表进行rehash时使用。
除了ht[1]之外,另一个和rehash有关的属性就是rehashidx,它记录了rehash目前的进度,如果目前没有在进行rehash,那么它的值为-1。
-- 如图,普通状态下(没有进行rehash)的字典。
typedef struct dict {// 类型特定函数dictType *type;// 私有数据void *privdata;// 哈希表dictht ht[2];// rehash索引//当rehash不在进行时,值为-1in trehashidx; /* rehashing not in progress if rehashidx == -1 */} dict;// == type属性 ==typedef struct dictType {// 计算哈希值的函数unsigned int (*hashFunction)(const void *key);// 复制键的函数void *(*keyDup)(void *privdata, const void *key);// 复制值的函数void *(*valDup)(void *privdata, const void *obj);// 对比键的函数int (*keyCompare)(void *privdata, const void *key1, const void *key2);// 销毁键的函数void (*keyDestructor)(void *privdata, void *key);// 销毁值的函数void (*valDestructor)(void *privdata, void *obj);} dictType;

- 1)哈希表
哈希算法?
当要将一个新的键值对添加到字典里面时,程序需要先根据键值对的键计算出哈希值和索引值,然后再根据索引值,将包含新键值对的哈希表节点放到哈希表数组的指定索引上面。- Redis计算哈希值和索引值的方法如下:
#使用字典设置的哈希函数,计算键key的哈希值hash = dict->type->hashFunction(key);#使用哈希表的sizemask属性和哈希值,计算出索引值#根据情况不同,ht[x]可以是ht[0]或者ht[1]index = hash & dict->ht[x].sizemask;

空字典

当字典被用作数据库的底层实现,或者哈希键的底层实现时,Redis使用MurmurHash2算法来计算键的哈希值。- Redis计算哈希值和索引值的方法如下:
解决键冲突?
当有两个或以上数量的键被分配到了哈希表数组的同一个索引上面时,我们称这些键发生了冲突(collision)。
Redis的哈希表使用链地址法(separate chaining)来解决键冲突,每个哈希表节点都有一个next指针,多个哈希表节点可以用next指针构成一个单向链表,被分配到同一个索引上的多个节点可以用这个单向链表连接起来,这就解决了键冲突的问题。- 因为dictEntry节点组成的链表没有指向链表表尾的指针,所以为了速度考虑,程序总是将新节点添加到链表的表头位置(复杂度为O(1)),排在其他已有节点的前面。
一个包含两个键值对的哈希表
使用链表解决k2和k1的冲突


- 因为dictEntry节点组成的链表没有指向链表表尾的指针,所以为了速度考虑,程序总是将新节点添加到链表的表头位置(复杂度为O(1)),排在其他已有节点的前面。
rehash?
- 随着操作的不断执行,哈希表保存的键值对会逐渐地增多或者减少,为了让哈希表的负载因子(load factor)维持在一个合理的范围之内,当哈希表保存的键值对数量太多或者太少时,程序需要对哈希表的大小进行相应的扩展或者收缩。
- 扩展和收缩哈希表的工作可以通过执行rehash(重新散列)操作来完成,Redis对字典的哈希表执行rehash的步骤如下:
1)为字典的ht[1]哈希表分配空间,这个哈希表的空间大小取决于要执行的操作,以及ht[0]当前包含的键值对数量(也即是ht[0].used属性的值):
· 如果执行的是扩展操作,那么ht[1]的大小为第一个大于等于ht[0].used*2的2 n(2的n次方幂);
· 如果执行的是收缩操作,那么ht[1]的大小为第一个大于等于ht[0].used的2 n。
2)将保存在ht[0]中的所有键值对rehash到ht[1]上面:rehash指的是重新计算键的哈希值和索引值,然后将键值对放置到ht[1]哈希表的指定位置上。
3)当ht[0]包含的所有键值对都迁移到了ht[1]之后(ht[0]变为空表),释放ht[0],将ht[1]设置为ht[0],并在ht[1]新创建一个空白哈希表,为下一次rehash做准备。
rehash的步骤?
举个例子,假设程序要对图4-8所示字典的ht[0]进行扩展操作,那么程序将执行以下步骤:
-- 执行rehash之前的字典:

- 1)ht[0].used当前的值为4,4*2=8,而8(2 3)恰好是第一个大于等于4的2的n次方,所以程序会将ht[1]哈希表的大小设置为8。下图展示了ht[1]在分配空间之后,字典的样子。
-- 为字典的ht[1]哈希表分配空间

- 2)将ht[0]包含的四个键值对都rehash到ht[1],如图所示。
-- ht[0]的所有键值对都已经被迁移到ht[1]

- 3)释放ht[0],并将ht[1]设置为ht[0],然后为ht[1]分配一个空白哈希表,如图所示。至此,对哈希表的扩展操作执行完毕,程序成功将哈希表的大小从原来的4改为了现在的8。
-- 完成rehash之后的字典:

- 1)ht[0].used当前的值为4,4*2=8,而8(2 3)恰好是第一个大于等于4的2的n次方,所以程序会将ht[1]哈希表的大小设置为8。下图展示了ht[1]在分配空间之后,字典的样子。
哈希表的扩展与收缩?
- 当以下条件中的任意一个被满足时,程序会自动开始对哈希表执行扩展操作:
1)服务器目前没有在执行BGSAVE命令或者BGREWRITEAOF命令,并且哈希表的负载因子大于等于1。
2)服务器目前正在执行BGSAVE命令或者BGREWRITEAOF命令,并且哈希表的负载因子大于等于5。 其中哈希表的负载因子可以通过公式计算得出。
# 负载因子= 哈希表已保存节点数量/ 哈希表大小load_factor = ht[0].used / ht[0].size
例如,对于一个大小为4,包含4个键值对的哈希表来说,这个哈希表的负载因子为:
load_factor = 4 / 4 = 1- 又例如,对于一个大小为512,包含256个键值对的哈希表来说,这个哈希表的负载因子为:
load_factor = 256 / 512 = 0.5 - 根据BGSAVE命令或BGREWRITEAOF命令是否正在执行,服务器执行扩展操作所需的负载因子并不相同,这是因为在执行BGSAVE命令或BGREWRITEAOF命令的过程中,Redis需要创建当前服务器进程的子进程,而大多数操作系统都采用写时复制(copy-on-write)技术来优化子进程的使用效率,所以在子进程存在期间,服务器会提高执行扩展操作所需的负载因子,从而尽可能地避免在子进程存在期间进行哈希表扩展操作,这可以避免不必要的内存写入操作,最大限度地节约内存。
- 另一方面,当哈希表的负载因子小于0.1时,程序自动开始对哈希表执行收缩操作。
- 当以下条件中的任意一个被满足时,程序会自动开始对哈希表执行扩展操作:
渐进式rehash?
- 扩展或收缩哈希表需要将ht[0]里面的所有键值对rehash到ht[1]里面,但是,这个rehash动作并不是一次性、集中式地完成的,而是分多次、渐进式地完成的。
- 这样做的原因在于,如果ht[0]里只保存着四个键值对,那么服务器可以在瞬间就将这些键值对全部rehash到ht[1];但是,如果哈希表里保存的键值对数量不是四个,而是四百万、四千万甚至四亿个键值对,那么要一次性将这些键值对全部rehash到ht[1]的话,庞大的计算量可能会导致服务器在一段时间内停止服务。
- 因此,为了避免rehash对服务器性能造成影响,服务器不是一次性将ht[0]里面的所有键值对全部rehash到ht[1],而是分多次、渐进式地将ht[0]里面的键值对慢慢地rehash到ht[1]。
- 以下是哈希表渐进式rehash的详细步骤:
1)为ht[1]分配空间,让字典同时持有ht[0]和ht[1]两个哈希表。
2)在字典中维持一个索引计数器变量rehashidx,并将它的值设置为0,表示rehash工作正式开始。
3)在rehash进行期间,每次对字典执行添加、删除、查找或者更新操作时,程序除了执行指定的操作以外,还会顺带将ht[0]哈希表在rehashidx索引上的所有键值对rehash到ht[1],当rehash工作完成之后,程序将rehashidx属性的值增一。
4)随着字典操作的不断执行,最终在某个时间点上,ht[0]的所有键值对都会被rehash至ht[1],这时程序将rehashidx属性的值设为-1,表示rehash操作已完成。 - 渐进式rehash的好处在于它采取分而治之的方式,将rehash键值对所需的计算工作均摊到对字典的每个添加、删除、查找和更新操作上,从而避免了集中式rehash而带来的庞大计算量。
一次完整的渐进式rehash过程?
- 下图展示了一次完整的渐进式rehash过程,注意观察在整个rehash过程中,字典的rehashidx属性是如何变化的。
- 1)准备开始rehash

- 2)rehash索引0上的键值对

- 3)rehash索引1上的键值对

- 4)rehash索引2上的键值对

- 5)rehash索引3上的键值对

- 6)rehash执行完毕

渐进式rehash执行期间的哈希表操作?
- 因为在进行渐进式rehash的过程中,字典会同时使用ht[0]和ht[1]两个哈希表,所以在渐进式rehash进行期间,字典的删除(delete)、查找(find)、更新(update)等操作会在两个哈希表上进行。例如,要在字典里面查找一个键的话,程序会先在ht[0]里面进行查找,如果没找到的话,就会继续到ht[1]里面进行查找,诸如此类。
- 另外,在渐进式rehash执行期间,新添加到字典的键值对一律会被保存到ht[1]里面,而ht[0]则不再进行任何添加操作,这一措施保证了ht[0]包含的键值对数量会只减不增,并随着rehash操作的执行而最终变成空表。
4 跳跃表-skiplist
跳跃表基本理论?
- 跳跃表(skiplist)是一种有序数据结构,它通过在每个节点中维持多个指向其他节点的指针,从而达到快速访问节点的目的。
- 跳跃表支持平均O(logN)、最坏O(N)复杂度的节点查找,还可以通过顺序性操作来批量处理节点。
- 在大部分情况下,跳跃表的效率可以和平衡树相媲美,并且因为跳跃表的实现比平衡树要来得更为简单,所以有不少程序都使用跳跃表来代替平衡树。
- Redis使用跳跃表作为有序集合键的底层实现之一,如果一个有序集合包含的元素数量比较多,又或者有序集合中元素的成员(member)是比较长的字符串时,Redis就会使用跳跃表来作为有序集合键的底层实现。
- 和链表、字典等数据结构被广泛地应用在Redis内部不同,Redis只在两个地方用到了跳跃表,一个是实现有序集合键,另一个是在集群节点中用作内部数据结构,除此之外,跳跃表在Redis里面没有其他用途。本章将对Redis中的跳跃表实现进行介绍,并列出跳跃表的操作API。本章不会对跳跃表的基本定义和基础算法进行介绍,如果有需要的话,可以参考WilliamPugh关于跳跃表的论文《Skip Lists:A Probabilistic Alternative to Balanced Trees》,或者《算法:C语言实现(第1~4部分)》一书的13.5节。
跳跃表的实现?
- Redis的跳跃表由redis.h/zskiplistNode和redis.h/zskiplist两个结构定义;
-- 其中,
zskiplistNode结构:用于表示跳跃表节点;
zskiplist结构:则用于保存跳跃表节点的相关信息,比如节点的数量,以及指向表头节点和表尾节点的指针等等。 - zskiplist结构:位于图片最左边的,该结构包含以下属性:
-- header:指向跳跃表的表头节点。
-- tail:指向跳跃表的表尾节点。
-- level:记录目前跳跃表内,层数最大的那个节点的层数(表头节点的层数不计算在内)。
-- length:记录跳跃表的长度,也即是,跳跃表目前包含节点的数量(表头节点不计算在内)。 - zskiplistNode结构:位于zskiplist结构右方的是四个zskiplistNode结构,该结构包含以下属性:
-- 层(level):节点中用L1、L2、L3等字样标记节点的各个层,L1代表第一层,L2代表第二层,以此类推。每个层都带有两个属性:前进指针和跨度。前进指针用于访问位于表尾方向的其他节点,而跨度则记录了前进指针所指向节点和当前节点的距离。在上面的图片中,连线上带有数字的箭头就代表前进指针,而那个数字就是跨度。当程序从表头向表尾进行遍历时,访问会沿着层的前进指针进行。
-- 后退(backward)指针:节点中用BW字样标记节点的后退指针,它指向位于当前节点的前一个节点。后退指针在程序从表尾向表头遍历时使用。
-- 分值(score):各个节点中的1.0、2.0和3.0是节点所保存的分值。在跳跃表中,节点按各自所保存的分值从小到大排列。
-- 成员对象(obj):各个节点中的o1、o2和o3是节点所保存的成员对象。
注意表头节点和其他节点的构造是一样的:表头节点也有后退指针、分值和成员对象,不过表头节点的这些属性都不会被用到,所以图中省略了这些部分,只显示了表头节点的各个层。 - 如下,一个跳跃表:

- Redis的跳跃表由redis.h/zskiplistNode和redis.h/zskiplist两个结构定义;
zskiplistNode和zskiplist两个结构-zskiplistNode?
跳跃表节点的实现由redis.h/zskiplistNode结构定义:typedef struct zskiplistNode {// 层struct zskiplistLevel {// 前进指针struct zskiplistNode *forward;// 跨度unsigned int span;} level[];// 后退指针struct zskiplistNode *backward;// 分值double score;// 成员对象robj *obj;} zskiplistNode;
- 1)层
跳跃表节点的level数组可以包含多个元素,每个元素都包含一个指向其他节点的指针,程序可以通过这些层来加快访问其他节点的速度,一般来说,层的数量越多,访问其他节点的速度就越快。
每次创建一个新跳跃表节点的时候,程序都根据幂次定律(power law,越大的数出现的概率越小)随机生成一个介于1和32之间的值作为level数组的大小,这个大小就是层的“高度”。
图展示了三个高度为1层、3层和5层的节点,因为C语言的数组索引总是从0开始的,所以节点的第一层是level[0],而第二层是level[1],以此类推。

- 2)前进指针
每个层都有一个指向表尾方向的前进指针(level[i].forward属性),用于从表头向表尾方向访问节点。图5-3用虚线表示出了程序从表头向表尾方向,遍历跳跃表中所有节点的路径:
-- ① 迭代程序首先访问跳跃表的第一个节点(表头),然后从第四层的前进指针移动到表中的第二个节点。
-- ② 在第二个节点时,程序沿着第二层的前进指针移动到表中的第三个节点。
-- ③ 在第三个节点时,程序同样沿着第二层的前进指针移动到表中的第四个节点。
-- ④ 当程序再次沿着第四个节点的前进指针移动时,它碰到一个NULL,程序知道这时已经到达了跳跃表的表尾,于是结束这次遍历。

- 3)跨度
层的跨度(level[i].span属性)用于记录两个节点之间的距离:
· 两个节点之间的跨度越大,它们相距得就越远。
· 指向NULL的所有前进指针的跨度都为0,因为它们没有连向任何节点。
-- 初看上去,很容易以为跨度和遍历操作有关,但实际上并不是这样,遍历操作只使用前进指针就可以完成了,跨度实际上是用来计算排位(rank)的:在查找某个节点的过程中,将沿途访问过的所有层的跨度累计起来,得到的结果就是目标节点在跳跃表中的排位。
-- 举个例子,图5-4用虚线标记了在跳跃表中查找分值为3.0、成员对象为o3的节点时,沿途经历的层:查找的过程只经过了一个层,并且层的跨度为3,所以目标节点在跳跃表中的排位为3。

-- 再举个例子,图5-5用虚线标记了在跳跃表中查找分值为2.0、成员对象为o2的节点时,沿途经历的层:在查找节点的过程中,程序经过了两个跨度为1的节点,因此可以计算出,目标节点在跳跃表中的排位为2。

- 4)后退指针
-- 节点的后退指针(backward属性)用于从表尾向表头方向访问节点:跟可以一次跳过多个节点的前进指针不同,因为每个节点只有一个后退指针,所以每次只能后退至前一个节点。
-- 图5-6用虚线展示了如果从表尾向表头遍历跳跃表中的所有节点:程序首先通过跳跃表的tail指针访问表尾节点,然后通过后退指针访问倒数第二个节点,之后再沿着后退指针访问倒数第三个节点,再之后遇到指向NULL的后退指针,于是访问结束。

- 5)分值和成员
-- 节点的分值(score属性)是一个double类型的浮点数,跳跃表中的所有节点都按分值从小到大来排序。
-- 节点的成员对象(obj属性)是一个指针,它指向一个字符串对象,而字符串对象则保存着一个SDS值。
-- 在同一个跳跃表中,各个节点保存的成员对象必须是唯一的,但是多个节点保存的分值却可以是相同的:分值相同的节点将按照成员对象在字典序中的大小来进行排序,成员对象较小的节点会排在前面(靠近表头的方向),而成员对象较大的节点则会排在后面(靠近表尾的方向)。
-- 举个例子,在图5-7所示的跳跃表中,三个跳跃表节点都保存了相同的分值10086.0,但保存成员对象o1的节点却排在保存成员对象o2和o3的节点之前,而保存成员对象o2的节点又排在保存成员对象o3的节点之前,由此可见,o1、o2、o3三个成员对象在字典中的排序为o1<=o2<=o3。

zskiplistNode和zskiplist两个结构-zskiplist?
- 仅靠多个跳跃表节点就可以组成一个跳跃表,如图所示。

- 但通过使用一个zskiplist结构来持有这些节点,程序可以更方便地对整个跳跃表进行处理,比如快速访问跳跃表的表头节点和表尾节点,或者快速地获取跳跃表节点的数量(也即是跳跃表的长度)等信息,如图所示。
zskiplist结构的定义如下:
typedef struct zskiplist {// 表头节点和表尾节点structz skiplistNode *header, *tail;// 表中节点的数量unsigned long length;// 表中层数最大的节点的层数int level;} zskiplist;

-- header和tail指针分别指向跳跃表的表头和表尾节点,通过这两个指针,程序定位表头节点和表尾节点的复杂度为O(1)。
-- 通过使用length属性来记录节点的数量,程序可以在O(1)复杂度内返回跳跃表的长度。
-- level属性则用于在O(1)复杂度内获取跳跃表中层高最大的那个节点的层数量,注意表头节点的层高并不计算在内。- 仅靠多个跳跃表节点就可以组成一个跳跃表,如图所示。
6 整数集-intset
整数集的基本知识?
- 整数集合(intset)是集合键的底层实现之一,当一个集合只包含整数值元素,并且这个集合的元素数量不多时,Redis就会使用整数集合作为集合键的底层实现。
整数集合的实现
- 整数集合(intset)是Redis用于保存整数值的集合抽象数据结构,它可以保存类型为int16_t、int32_t或者int64_t的整数值,并且保证集合中不会出现重复元素。
- 每个intset.h/intset结构表示一个整数集合:
typedef struct intset {// 编码方式uint32_t encoding;// 集合包含的元素数量uint32_t length;// 保存元素的数组int8_t contents[];} intset;
-- contents数组:contents数组是整数集合的底层实现:整数集合的每个元素都是contents数组的一个数组项(item),各个项在数组中按值的大小从小到大有序地排列,并且数组中不包含任何重复项。
-- length属性:length属性记录了整数集合包含的元素数量,也即是contents数组的长度。- 虽然intset结构将contents属性声明为int8_t类型的数组,但实际上contents数组并不保存任何int8_t类型的值,contents数组的真正类型取决于encoding属性的值:
· 如果encoding属性的值为INTSET_ENC_INT16,那么contents就是一个int16_t类型的数组,数组里的每个项都是一个int16_t类型的整数值(最小值为-32768,最大值为32767)。
· 如果encoding属性的值为INTSET_ENC_INT32,那么contents就是一个int32_t类型的数组,数组里的每个项都是一个int32_t类型的整数值(最小值为-2147483648,最大值为2147483647)。
· 如果encoding属性的值为INTSET_ENC_INT64,那么contents就是一个int64_t类型的数组,数组里的每个项都是一个int64_t类型的整数值(最小值为-9223372036854775808,最大值为9223372036854775807)。
升级?
- 每当我们要将一个新元素添加到整数集合里面,并且新元素的类型比整数集合现有所有元素的类型都要长时,整数集合需要先进行升级(upgrade),然后才能将新元素添加到整数集合里面。
- 升级整数集合并添加新元素共分为三步进行:
1)根据新元素的类型,扩展整数集合底层数组的空间大小,并为新元素分配空间。
2)将底层数组现有的所有元素都转换成与新元素相同的类型,并将类型转换后的元素放置到正确的位上,而且在放置元素的过程中,需要继续维持底层数组的有序性质不变。
3)将新元素添加到底层数组里面。
7.压缩列表-ziplist
压缩列表的基本知识?
- 压缩列表(ziplist)是列表键和哈希键的底层实现之一。
- 应用:
1)当一个列表键只包含少量列表项,并且每个列表项要么就是小整数值,要么就是长度比较短的字符串,那么Redis就会使用压缩列表来做列表键的底层实现。
2)当一个哈希键只包含少量键值对,比且每个键值对的键和值要么就是小整数值,要么就是长度比较短的字符串,那么Redis就会使用压缩列表来做哈希键的底层实现。
压缩列表的构成?
- 压缩列表是Redis为了节约内存而开发的,是由一系列特殊编码的连续内存块组成的顺序型(sequential)数据结构。一个压缩列表可以包含任意多个节点(entry),每个节点可以保存一个字节数组或者一个整数值。
- 压缩列表的各个组成部分

- 各个组成部分的类型、长度以及用途:

压缩列表的构成-示例?
1)三个节点的
·列表zlbytes属性的值为0x50(十进制80),表示压缩列表的总长为80字节。
·列表zltail属性的值为0x3c(十进制60),这表示如果我们有一个指向压缩列表起始地址的指针p,那么只要用指针p加上偏移量60,就可以计算出表尾节点entry3的地址。
·列表zllen属性的值为0x3(十进制3),表示压缩列表包含三个节点。
2)五个节点的
·列表zlbytes属性的值为0xd2(十进制210),表示压缩列表的总长为210字节。
·列表zltail属性的值为0xb3(十进制179),这表示如果我们有一个指向压缩列表起始地址的指针p,那么只要用指针p加上偏移量179,就可以计算出表尾节点entry5的地址。
·列表zllen属性的值为0x5(十进制5),表示压缩列表包含五个节点。

压缩列表节点的构成?
- 每个压缩列表节点都由previous_entry_length、encoding、content三个部分组成:

- 每个压缩列表节点可以保存一个字节数组或者一个整数值
-- 字节数组:可以是以下三种长度的其中一种:
·长度小于等于63(2 6–1)字节的字节数组;
·长度小于等于16383(2 14–1)字节的字节数组;
·长度小于等于4294967295(2 32–1)字节的字节数组;
-- 整数值:则可以是以下六种长度的其中一种:
·4位长,介于0至12之间的无符号整数;
·1字节长的有符号整数;
·3字节长的有符号整数;
·int16_t类型整数;
·int32_t类型整数;
·int64_t类型整数。
- 每个压缩列表节点都由previous_entry_length、encoding、content三个部分组成:
对象
概述
- Redis用到的所有主要数据结构,如简单动态字符串(SDS)、双端链表、字典、压缩列表、整数集合等等。
- Redis并没有直接使用这些数据结构来实现键值对数据库,而是基于这些数据结构创建了一个对象系统,这个系统包含字符串对象、列表对象、哈希对象、集合对象和有序集合对象这五种类型的对象;
简化字符串对象,以下统一使用
- 使用了一个带有StringObject字样的格子来表示一个字符串对象,而StringObject字样下面的是字符串对象所保存的值

- 使用了一个带有StringObject字样的格子来表示一个字符串对象,而StringObject字样下面的是字符串对象所保存的值
对象的表示?
- Redis中的每个对象都由一个redisObject结构表示,该结构中和保存数据有关的三个属性分别是type属性、encoding属性和ptr属性
typedef struct redisObject {// 类型unsigned type:4;// 编码unsigned encoding:4;// 指向底层实现数据结构的指针void *ptr;// ...} robj;
- Redis中的每个对象都由一个redisObject结构表示,该结构中和保存数据有关的三个属性分别是type属性、encoding属性和ptr属性
type属性
- 记录了对象的类型,属性的值可以是如下常量:
REDIS_STRING(字符串对象)、
REDIS_LIST(列表对象)、
REDIS_HASH(哈希对象)、
REDIS_SET(集合对象)、
REDIS_ZSET(有序集合对象) - TYPE命令
对一个数据库键执行TYPE命令时,命令返回的结果为数据库键对应的值对象的类型,而不是键对象的类型; - 不同类型值对象的TYPE命令输出
对象type属性的值/对象/TYPE命令的输出
REDIS_STRING(字符串对象)string、
REDIS_LIST(列表对象)list、
REDIS_HASH(哈希对象)hash、
REDIS_SET(集合对象)set、
REDIS_ZSET(有序集合对象)zset
- 记录了对象的类型,属性的值可以是如下常量:
ptr指针和encoding属性
- 对象的ptr指针指向对象的底层实现数据结构,而这些数据结构由对象的encoding属性决定。
- encoding属性记录了对象所使用的编码,也即是说这个对象使用了什么数据结构作为对象的底层实现,这个属性的值可以是以下常量:
- 不同编码的对象所对应的OBJECT ENCODING命令输出。


1 string
string对象编码?
- 字符串对象的编码可以是int、raw或者embstr。
字符串对象编码?
- ① int
如果一个字符串对象保存的是整数值,并且这个整数值可以用long类型来表示,那么字符串对象会将整数值保存在字符串对象结构的ptr属性里面(将void*转换成long),并将字符串对象的编码设置为int;
- ② raw
如果字符串对象保存的是一个字符串值,并且这个字符串值的长度大于32字节,那么字符串对象将使用一个简单动态字符串(SDS)来保存这个字符串值,并将对象的编码设置为raw。

- ③ embstr
如果字符串对象保存的是一个字符串值,并且这个字符串值的长度小于等于32字节,那么字符串对象将使用embstr编码的方式来保存这个字符串值。

- ① int
embstr编码?
- embstr编码是专门用于保存短字符串的一种优化编码方式,这种编码和raw编码一样,都使用redisObject结构和sdshdr结构来表示字符串对象,但raw编码会调用两次内存分配函数来分别创建redisObject结构和sdshdr结构,而embstr编码则通过调用一次内存分配函数来分配一块连续的空间,空间中依次包含redisObject和sdshdr两个结构。

- embstr编码是专门用于保存短字符串的一种优化编码方式,这种编码和raw编码一样,都使用redisObject结构和sdshdr结构来表示字符串对象,但raw编码会调用两次内存分配函数来分别创建redisObject结构和sdshdr结构,而embstr编码则通过调用一次内存分配函数来分配一块连续的空间,空间中依次包含redisObject和sdshdr两个结构。
embstr编码的字符串对象来保存短字符串值的好处?
- 1) embstr编码将创建字符串对象所需的内存分配次数从raw编码的两次降低为一次。
- 2)释放embstr编码的字符串对象只需要调用一次内存释放函数,而释放raw编码的字符串对象需要调用两次内存释放函数。
3) 因为embstr编码的字符串对象的所有数据都保存在一块连续的内存里面,所以这种编码的字符串对象比起raw编码的字符串对象能够更好地利用缓存带来的优势。
笔记:**
保存long double类型表示的浮点数
- 可以用long double类型表示的浮点数在Redis中也是作为字符串值来保存的。
- 如果我们要保存一个浮点数到字符串对象里面,那么程序会先将这个浮点数转换成字符串值,然后再保存转换所得的字符串值。
总结并列出了字符串对象保存各种不同类型的值所使用的编码方式。

编码转换?
- int和embstr编码的字符串对象在条件满足的情况下,会被转换为raw编码的字符串对象。
- int变为raw
如对于int编码的字符串对象来说,如果我们向对象执行了一些命令,使得这个对象保存的不再是整数值,而是一个字符串值,那么字符串对象的编码将从int变为raw。 - embstr转换成raw
因为Redis没有为embstr编码的字符串对象编写任何相应的修改程序(只有int编码的字符串对象和raw编码的字符串对象有这些程序),所以embstr编码的字符串对象实际上是只读的。当我们对embstr编码的字符串对象执行任何修改命令时,程序会先将对象的编码从embstr转换成raw,然后再执行修改命令。因为这个原因,embstr编码的字符串对象在执行修改命令之后,总会变成一个raw编码的字符串对象。
2 list
列表对象的编码?
- 列表对象的编码可以是ziplist或者linkedlist。
- 1)ziplist
ziplist编码的列表对象使用压缩列表作为底层实现,每个压缩列表节点(entry)保存了一个列表元素。

- linkedlist
linkedlist编码的列表对象使用双端链表作为底层实现,每个双端链表节点(node)都保存了一个字符串对象,而每个字符串对象都保存了一个列表元素。

对象嵌套?
- 注意,linkedlist编码的列表对象在底层的双端链表结构中包含了多个字符串对象,这种嵌套字符串对象的行为在稍后介绍的哈希对象、集合对象和有序集合对象中都会出现,字符串对象是Redis五种类型的对象中唯一一种会被其他四种类型对象嵌套的对象。
编码转换?
- 使用ziplist编码
当列表对象可以同时满足以下两个条件时,列表对象使用ziplist编码:
1)列表对象保存的所有字符串元素的长度都小于64字节;
2)列表对象保存的元素数量小于512个;不能满足这两个条件的列表对象需要使用linkedlist编码。
以上两个条件的上限值是可以修改的,具体请看配置文件中关于list-max-ziplist-value选项和list-max-ziplist-entries选项的说明。 - 使用linkedlist编码
对于使用ziplist编码的列表对象来说,当使用ziplist编码所需的两个条件的任意一个不能被满足时,对象的编码转换操作就会被执行,原本保存在压缩列表里的所有列表元素都会被转移并保存到双端链表里面,对象的编码也会从ziplist变为linkedlist。
- 使用ziplist编码
3 hash
哈希对象的编码?
- 哈希对象的编码可以是ziplist或者hashtable。
- ziplist编码
ziplist编码的哈希对象使用压缩列表作为底层实现,每当有新的键值对要加入到哈希对象时,程序会先将保存了键的压缩列表节点推入到压缩列表表尾,然后再将保存了值的压缩列表节点推入到压缩列表表尾,因此:
·保存了同一键值对的两个节点总是紧挨在一起,保存键的节点在前,保存值的节点在后;
·先添加到哈希对象中的键值对会被放在压缩列表的表头方向,而后来添加到哈希对象中的键值对会被放在压缩列表的表尾方向。

- hashtable编码
hashtable编码的哈希对象使用字典作为底层实现,哈希对象中的每个键值对都使用一个字典键值对来保存:
·字典的每个键都是一个字符串对象,对象中保存了键值对的键;
·字典的每个值都是一个字符串对象,对象中保存了键值对的值。

编码转换?
- 当哈希对象可以同时满足以下两个条件时,哈希对象使用ziplist编码:
·哈希对象保存的所有键值对的键和值的字符串长度都小于64字节;
·哈希对象保存的键值对数量小于512个;不能满足这两个条件的哈希对象需要使用hashtable编码。 - 对于使用ziplist编码的列表对象来说,当使用ziplist编码所需的两个条件的任意一个不能被满足时,对象的编码转换操作就会被执行,原本保存在压缩列表里的所有键值对都会被转移并保存到字典里面,对象的编码也会从ziplist变为hashtable。
- 当哈希对象可以同时满足以下两个条件时,哈希对象使用ziplist编码:
4 set
集合对象的编码
集合对象的编码可以是intset或者hashtable。- intset编码
intset编码的集合对象使用整数集合作为底层实现,集合对象包含的所有元素都被保存在整数集合里面。

- hashtable编码
hashtable编码的集合对象使用字典作为底层实现,字典的每个键都是一个字符串对象,每个字符串对象包含了一个集合元素,而字典的值则全部被设置为NULL。

- intset编码
编码转换?
- 当集合对象可以同时满足以下两个条件时,对象使用intset编码:
·集合对象保存的所有元素都是整数值;
·集合对象保存的元素数量不超过512个。
不能满足这两个条件的集合对象需要使用hashtable编码。 - 对于使用intset编码的集合对象来说,当使用intset编码所需的两个条件的任意一个不能被满足时,就会执行对象的编码转换操作,原本保存在整数集合中的所有元素都会被转移并保存到字典里面,并且对象的编码也会从intset变为hashtable。
- 当集合对象可以同时满足以下两个条件时,对象使用intset编码:
5 zset
有序集合的编码
- 有序集合的编码可以是ziplist或者skiplist。
- ziplist编码
ziplist编码的压缩列表对象使用压缩列表作为底层实现,每个集合元素使用两个紧挨在一起的压缩列表节点来保存,第一个节点保存元素的成员(member),而第二个元素则保存元素的分值(score)。
压缩列表内的集合元素按分值从小到大进行排序,分值较小的元素被放置在靠近表头的方向,而分值较大的元素则被放置在靠近表尾的方向。


- skiplist编码
skiplist编码的有序集合对象使用zset结构作为底层实现,一个zset结构同时包含一个字典和一个跳跃表:
typedef struct zset {zskiplist *zsl;dict *dict;} zset;


有序集合元素同时被保存在字典和跳跃表中(上图)
为了展示方便,图在字典和跳跃表中重复展示了各个元素的成员和分值,但在实际中,字典和跳跃表会共享元素的成员和分值,所以并不会造成任何数据重复,也不会因此而浪费任何内存。- zset结构中的zsl跳跃表按分值从小到大保存了所有集合元素,每个跳跃表节点都保存了一个集合元素:跳跃表节点的object属性保存了元素的成员,而跳跃表节点的score属性则保存了元素的分值。通过这个跳跃表,程序可以对有序集合进行范围型操作,比如ZRANK、ZRANGE等命令就是基于跳跃表API来实现的。
除此之外,zset结构中的dict字典为有序集合创建了一个从成员到分值的映射,字典中的每个键值对都保存了一个集合元素:字典的键保存了元素的成员,而字典的值则保存了元素的分值。通过这个字典,程序可以用O(1)复杂度查找给定成员的分值,ZSCORE命令就是根据这一特性实现的,而很多其他有序集合命令都在实现的内部用到了这一特性。
有序集合每个元素的成员都是一个字符串对象,而每个元素的分值都是一个double类型的浮点数。值得一提的是,虽然zset结构同时使用跳跃表和字典来保存有序集合元素,但这两种数据结构都会通过指针来共享相同元素的成员和分值,所以同时使用跳跃表和字典来保存集合元素不会产生任何重复成员或者分值,也不会因此而浪费额外的内存。
为什么有序集合需要同时使用跳跃表和字典来实现?
- 在理论上,有序集合可以单独使用字典或者跳跃表的其中一种数据结构来实现,但无论单独使用字典还是跳跃表,在性能上对比起同时使用字典和跳跃表都会有所降低。举个例子,如果我们只使用字典来实现有序集合,那么虽然以O(1)复杂度查找成员的分值这一特性会被保留,但是,因为字典以无序的方式来保存集合元素,所以每次在执行范围型操作——比如ZRANK、ZRANGE等命令时,程序都需要对字典保存的所有元素进行排序,完成这种排序需要至少O(NlogN)时间复杂度,以及额外的O(N)内存空间(因为要创建一个数组来保存排序后的元素)。
- 另一方面,如果我们只使用跳跃表来实现有序集合,那么跳跃表执行范围型操作的所有优点都会被保留,但因为没有了字典,所以根据成员查找分值这一操作的复杂度将从O(1)上升为O(logN)。因为以上原因,为了让有序集合的查找和范围型操作都尽可能快地执行,Redis选择了同时使用字典和跳跃表两种数据结构来实现有序集合。
编码转换?
- 不能满足以上两个条件的有序集合对象将使用skiplist编码。(可修改条件上限)
·有序集合保存的元素数量小于128个;
·有序集合保存的所有元素成员的长度都小于64字节; - 对于使用ziplist编码的有序集合对象来说,当使用ziplist编码所需的两个条件中的任意一个不能被满足时,就会执行对象的编码转换操作,原本保存在压缩列表里的所有集合元素都会被转移并保存到zset结构里面,对象的编码也会从ziplist变为skiplist。
- 不能满足以上两个条件的有序集合对象将使用skiplist编码。(可修改条件上限)
3-应用场景
1. string
string类型应用场景?
1)缓存功能
比较典型的缓存使用场景,如图

-- 其中,Redis作为缓存层,MySQL作为存储层,绝大部分请求的数据都是从Redis中获取。由于Redis具有支撑高并发的特性,所以缓存通常能起到加速读写和降低后端压力的作用。//1)该函数用于获取用户的基础信息:UserInfo getUserInfo(long id){...}//2)首先从Redis获取用户信息:// 定义键userRedisKey = "user:info:" + id;// 从Redis获取值value = redis.get(userRedisKey);if (value != null) {// 将值进行反序列化为UserInfo并返回结果userInfo = deserialize(value);return userInfo;}//3)如果没有从Redis获取到用户信息,需要从MySQL中进行获取,并将结果回写到Redis,添加1小时(3600秒)过期时间:// 从MySQL获取用户信息userInfo = mysql.get(id);// 将userInfo序列化,并存入Redisredis.setex(userRedisKey, 3600, serialize(userInfo));// 返回结果return userInfo//总结:整个功能的伪代码如下:UserInfo getUserInfo(long id){userRedisKey = "user:info:" + idvalue = redis.get(userRedisKey);UserInfo userInfo;if (value != null) {userInfo = deserialize(value);} else {userInfo = mysql.get(id);if (userInfo != null)redis.setex(userRedisKey, 3600, serialize(userInfo));}return userInfo;}
2)计数
-- Redis作为计数的基础工具,可以实现快速计数、查询缓存的功能,同时数据可以异步落地到其他数据源。
-- 例如笔者所在团队的视频播放数系统就是使用Redis作为视频播放数计数的基础组件,用户每播放一次视频,相应的视频播放数就会自增1:long incrVideoCounter(long id) {key = "video:playCount:" + id;return redis.incr(key);}
-- 应用:实际上一个真实的计数系统要考虑的问题会很多:防作弊、按照不同维度计数,数据持久化到底层数据源等。
- 3)共享Session
现象:
一个分布式Web服务将用户的Session信息(例如用户登录信息)保存在各自服务器中,这样会造成一个问题,出于负载均衡的考虑,分布式服务会将用户的访问均衡到不同服务器上,用户刷新一次访问可能会发现需要重新登录,这个问题是用户无法容忍的。
解决:
为了解决这个问题,可以使用Redis将用户的Session进行集中管理,如
图,在这种模式下只要保证Redis是高可用和扩展性的,每次用户更新或者查询登录信息都直接从Redis中集中获取。


- 4)限速
很多应用出于安全的考虑,会在每次进行登录时,让用户输入手机验证
码,从而确定是否是用户本人。但是为了短信接口不被频繁访问,会限制用户每分钟获取验证码的频率,例如一分钟不能超过5次
(例如一些网站限制一个IP地址不能在一秒钟之内访问超过n次也可以采用类似的思路。)
//伪代码给出了基本实现思路:phoneNum = "138xxxxxxxx";key = "shortMsg:limit:" + phoneNum;// SET key value EX 60 NXisExists = redis.set(key,1,"EX 60","NX");if(isExists != null || redis.incr(key) <=5){// 通过}else{// 限速}
2. hash
哈希应用场景?
- 关系型数据表记录的两条用户信息,用户的属性作为表的列,每条用户信息作为行。
id name age city 1 tom 23 beijng 2 mike 30 tianjin - 将其用哈希类型存储

相比于使用字符串序列化缓存用户信息,哈希类型变得更加直观,并且在更新操作上会更加便捷。可以将每个用户的id定义为键后缀,多对fieldvalue对应每个用户的属性,类似如下伪代码:
UserInfo getUserInfo(long id){// 用户id作为key后缀userRedisKey = "user:info:" + id;// 使用hgetall获取所有用户信息映射关系userInfoMap = redis.hgetAll(userRedisKey);UserInfo userInfo;if (userInfoMap != null) {// 将映射关系转换为UserInfouserInfo = transferMapToUserInfo(userInfoMap);} else {// 从MySQL中获取用户信息userInfo = mysql.get(id);// 将userInfo变为映射关系使用hmset保存到Redis中redis.hmset(userRedisKey, transferUserInfoToMap(userInfo));// 添加过期时间redis.expire(userRedisKey, 3600);}return userInfo;}
不同
但是需要注意的是哈希类型和关系型数据库有两点不同之处:
-- 哈希类型是稀疏的,而关系型数据库是完全结构化的,例如哈希类型
每个键可以有不同的field,而关系型数据库一旦添加新的列,所有行都要为其设置值(即使为NULL)
-- 关系型数据库可以做复杂的关系查询,而Redis去模拟关系型复杂查询开发困难,维护成本高。
三种缓存方法-方案的实现方法和优缺点分析。
缓存用户信息:
1)原生字符串类型:每个属性一个键。set user:1:name tomset user:1:age 23set user:1:city beijing
优点:简单直观,每个属性都支持更新操作。
缺点:占用过多的键,内存占用量较大,同时用户信息内聚性比较差,
所以此种方案一般不会在生产环境使用。
2)序列化字符串类型:将用户信息序列化后用一个键保存。set user:1 serialize(userInfo)
优点:简化编程,如果合理的使用序列化可以提高内存的使用效率。
缺点:序列化和反序列化有一定的开销,同时每次更新属性都需要把全
部数据取出进行反序列化,更新后再序列化到Redis中。
3)哈希类型:每个用户属性使用一对field-value,但是只用一个键保
存。hmset user:1 name tomage 23 city beijing
优点:简单直观,如果使用合理可以减少内存空间的使用。
缺点:要控制哈希在ziplist和hashtable两种内部编码的转换,hashtable会消耗更多内存。
3. list
- list列表的使用场景?
消息队列
lpush+brpop命令组合即可实现阻塞队列,生产者客户端使用lrpush从列表左侧插入元素,多个消费者客户端使用brpop命令阻塞式的“抢”列表尾部的元素,多个客户端保证了消费的负载均衡和高可用性。

文章列表
每个用户有属于自己的文章列表,现需要分页展示文章列表。此时可以
考虑使用列表,因为列表不但是有序的,同时支持按照索引范围获取元素。1|每篇文章使用哈希结构存储,例如每篇文章有3个属性title、timestamp、content:
hmset acticle:1 title xx timestamp 1476536196 content xxxx...hmset acticle:k title yy timestamp 1476512536 content yyyy...
2|向用户文章列表添加文章,user:{id}:articles作为用户文章列表的键(key):
lpush user:1:acticles article:1 article3...lpush user:k:acticles article:5...
3|分页获取用户文章列表,例如下面伪代码获取用户id=1的前10篇文
章:articles = lrange user:1:articles 0 9for article in {articles}hgetall {article}
使用列表类型保存和获取文章列表会存在两个问题。
第一,如果每次分页获取的文章个数较多,需要执行多次hgetall操作,此时可以考虑使用Pipeline批量获取,或者考虑将文章数据序列化为字符串类型,使用mget批量获取。
第二,分页获取文章列表时,lrange命令在列表两端性能较好,但是如果列表较大,获取列表中间范围的元素性能会变差,此时可以考虑将列表做二级拆分,或者使用Redis3.2的quicklist内部编码实现,它结合ziplist和linkedlist的特点,获取列表中间范围的元素时也可以高效完成。
扩展?
实际上列表的使用场景很多,在选择时可以参考以下口诀:- lpush+lpop=Stack(栈)
- lpush+rpop=Queue(队列)
- lpsh+ltrim=Capped Collection(有限集合)
- lpush+brpop=Message Queue(消息队列)
4.set
标签?
- 集合类型比较典型的使用场景是标签(tag)。
- 例如一个用户可能对娱乐、体育比较感兴趣,另一个用户可能对历史、新闻比较感兴趣,这些兴趣点就是标签。有了这些数据就可以得到喜欢同一个标签的人,以及用户的共同喜好的标签,这些数据对于用户体验以及增强用户黏度比较重要。
- 例如一个电子商务的网站会对不同标签的用户做不同类型的推荐,比如对数码产品比较感兴趣的人,在各个页面或者通过邮件的形式给他们推荐最新的数码产品,通常会为网站带来更多的利益。
实现标签功能?
下面使用集合类型实现标签功能的若干功能。1|给用户添加标签
sadd user:1:tags tag1 tag2 tag5sadd user:2:tags tag2 tag3 tag5...sadd user:k:tags tag1 tag2 tag4...
2|给标签添加用户
sadd tag1:users user:1 user:3sadd tag2:users user:1 user:2 user:3...sadd tagk:users user:1 user:2...
开发注意问题:开发提示1:
用户和标签的关系维护应该在一个事务内执行,防止部分命令失败造成的数据不一致,有关如何将两个命令放在一个事务,参考事务以及Lua的使用方法。3|删除用户下的标签
srem user:1:tags tag1 tag5...
4|删除标签下的用户
srem tag1:users user:1srem tag5:users user:1...
3|和4|也是尽量放在一个事务执行。
- 5|计算用户共同感兴趣的标签可以使用sinter命令,来计算用户共同感兴趣的标签,如下代码所示:
sinter user:1:tags user:2:tags
- 开发注意问题:开发提示2:
前面只是给出了使用Redis集合类型实现标签的基本思路,实际上一个
标签系统远比这个要复杂得多,不过集合类型的应用场景通常为以下几种:
- sadd=Tagging(标签)
- spop/srandmember=Random item(生成随机数,比如抽奖)
- sadd+sinter=Social Graph(社交需求)
5-zset
zset的应用场景?
- 有序集合比较典型的使用场景就是排行榜系统。
- 例如视频网站需要对用户上传的视频做排行榜,榜单的维度可能是多个方面的:按照时间、按照播放数量、按照获得的赞数。
使用赞数这个维度,记录每天用户上传视频的排行榜。
主要需要实现以下4个功能:
(1)添加用户赞数
例如用户mike上传了一个视频,并获得了3个赞,可以使用有序集合的zadd和zincrby功能:zadd user:ranking:2016_03_15 mike 3
如果之后再获得一个赞,可以使用zincrby:
zincrby user:ranking:2016_03_15 mike 1
(2)取消用户赞数
由于各种原因(例如用户注销、用户作弊)需要将用户删除,此时需要
将用户从榜单中删除掉,可以使用zrem。
例如删除成员tom:zrem user:ranking:2016_03_15 mike
(3)展示获取赞数最多的十个用户
此功能使用zrevrange命令实现:zrevrangebyrank user:ranking:2016_03_15 0 9
(4)展示用户信息以及用户分数
此功能将用户名作为键后缀,将用户信息保存在哈希类型中,至于用户
的分数和排名可以使用zscore和zrank两个功能:hgetall user:info:tomzscore user:ranking:2016_03_15 mikezrank user:ranking:2016_03_15 mike
3 持久化
1-RDB
- 概念?
- RDB持久化是把当前进程数据生成快照保存到硬盘的过程
- 触发RDB持久化过程分为手动触发和自动触发。
触发机制
1-手动触发
手动触发--save命令?
- 阻塞当前Redis服务器,直到RDB过程完成为止,对于内存比较大的实例会造成长时间阻塞,线上环境不建议使用。
- 运行save命令对应的Redis日志如下:
* DB saved on disk
手动触发--bgsave命令?
- Redis进程执行fork操作创建子进程,RDB持久化过程由子进程负责,完成后自动结束。阻塞只发生在fork阶段,一般时间很短。
- 运行bgsave命令对应的Redis日志:
* Background saving started by pid 3151* DB saved on disk* RDB: 0 MB of memory used by copy-on-write* Background saving terminated with success
- save、bgsave对比?
- bgsave命令是针对save阻塞问题做的优化。
- 因此Redis内部所有的涉及RDB的操作都采用bgsave的方式,而save命令已经废弃。
2-自动触发
- Redis内部自动触发RDB的持久化机制的场景?
1)使用save相关配置,如“save m n”。表示m秒内数据集存在n次修改时,自动触发bgsave。
2)如果从节点执行全量复制操作,主节点自动执行bgsave生成RDB文件并发送给从节点(复制部分)。
3)执行debug reload命令重新加载Redis时,也会自动触发save操作。
4)默认情况下执行shutdown命令时,如果没有开启AOF持久化功能则
自动执行bgsave。
RDB运作流程
- bgsave触发的RDB持久化运作流程?

1)执行bgsave命令,Redis父进程判断当前是否存在正在执行的子进程,如RDB/AOF子进程,如果存在bgsave命令直接返回。
2)父进程执行fork操作创建子进程,fork操作过程中父进程会阻塞,通
过info stats命令查看latest_fork_usec选项,可以获取最近一个fork操作的耗时,单位为微秒。
3)父进程fork完成后,bgsave命令返回“Background saving started”信息并不再阻塞父进程,可以继续响应其他命令。
4)子进程创建RDB文件,根据父进程内存生成临时快照文件,完成后对原有文件进行原子替换。执行lastsave命令可以获取最后一次生成RDB的时间,对应info统计的rdb_last_save_time选项。
5)进程发送信号给父进程表示完成,父进程更新统计信息,具体见
info Persistence下的rdb_*相关选项。
文件处理
- RDB文件的处理?
- 保存:
--RDB文件保存在dir配置指定的目录下,文件名通过dbfilename配
置指定。
-- 可以通过执行config set dir{newDir}和config set dbfilename{newFileName}运行期动态执行,当下次运行时RDB文件会保存到新目录。
- 保存:
优缺点
RDB的优点?
- RDB是一个紧凑压缩的二进制文件,代表Redis在某个时间点上的数据
快照。
非常适用于备份,全量复制等场景。
比如每6小时执行bgsave备份,并把RDB文件拷贝到远程机器或者文件系统中(如hdfs),用于灾难恢复。 - Redis加载RDB恢复数据远远快于AOF的方式。
- RDB是一个紧凑压缩的二进制文件,代表Redis在某个时间点上的数据
RDB的缺点?
- RDB方式数据没办法做到实时持久化/秒级持久化。因为bgsave每次运行都要执行fork操作创建子进程,属于重量级操作,频繁执行成本过高。
- RDB文件使用特定二进制格式保存,Redis版本演进过程中有多个格式
的RDB版本,存在老版本Redis服务无法兼容新版RDB格式的问题。 - 针对RDB不适合实时持久化的问题,Redis提供了AOF持久化方式来解
决。
2-AOF
简介?
- AOF(append only file)持久化:
以独立日志的方式记录每次写命令,重启时再重新执行AOF文件中的命令达到恢复数据的目的。 - 主要作用
解决了数据持久化的实时性,目前已经是Redis持久化的主流方式。
- AOF(append only file)持久化:
使用?
- 开启:
开启AOF功能需要设置配置:appendonly yes,默认不开启。 - 文件名:
AOF文件名通过appendfilename配置设置,默认文件名是appendonly.aof。
保存路径同RDB持久化方式一致,通过dir配置指定。
- 开启:
AOF的工作流程?
AOF的工作流程操作:命令写入(append)、文件同步(sync)、文件重写(rewrite)、重启加载(load)。

流程如下:
1)所有的写入命令会追加到aof_buf(缓冲区)中。
2)AOF缓冲区根据对应的策略向硬盘做同步操作。
3)随着AOF文件越来越大,需要定期对AOF文件进行重写,达到压缩的目的。
4)当Redis服务器重启时,可以加载AOF文件进行数据恢复。AOF工作流-1命令写入?
- AOF命令写入的内容直接是文本协议格式。
// 如set hello world,在AOF缓冲区会追加如下文本:*3\r\n$3\r\nset\r\n$5\r\nhello\r\n$5\r\nworld\r\n
AOF为什么直接采用文本协议格式?
- 文本协议具有很好的兼容性。
- 开启AOF后,所有写入命令都包含追加操作,直接采用协议格式,避
免了二次处理开销。 - 文本协议具有可读性,方便直接修改和处理。
AOF为什么把命令追加到aof_buf中?
- Redis使用单线程响应命令,如果每次写AOF文件命令都直接追加到硬盘,那么性能完全取决于当前硬盘负载。
- 先写入缓冲区aof_buf中,还有另一个好处,Redis可以提供多种缓冲区
同步硬盘的策略,在性能和安全性方面做出平衡。
AOF工作流-2文件同步?
- Redis提供了多种AOF缓冲区同步文件策略,由参数appendfsync控制

- 系统调用write和fsync说明:
-- write操作会触发延迟写(delayed write)机制。Linux在内核提供页缓冲区用来提高硬盘IO性能。write操作在写入系统缓冲区后直接返回。同步硬盘操作依赖于系统调度机制,例如:缓冲区页空间写满或达到特定时间周期。同步文件之前,如果此时系统故障宕机,缓冲区内数据将丢失。
-- fsync针对单个文件操作(比如AOF文件),做强制硬盘同步,fsync将
阻塞直到写入硬盘完成后返回,保证了数据持久化。
-- 除了write、fsync,Linux还提供了sync、fdatasync操作,具体API说明参见:http://linux.die.net/man/2/write,http://linux.die.net/man/2/fsync,http://linux.die.net/man/2/sync - 配置值,always、everysec、no
-- 配置为always时,每次写入都要同步AOF文件,在一般的SATA硬盘
上,Redis只能支持大约几百TPS写入,显然跟Redis高性能特性背道而驰,不建议配置。
-- 配置为no,由于操作系统每次同步AOF文件的周期不可控,而且会加
大每次同步硬盘的数据量,虽然提升了性能,但数据安全性无法保证。
-- 配置为everysec,是建议的同步策略,也是默认配置,做到兼顾性能和数据安全性。理论上只有在系统突然宕机的情况下丢失1秒的数据。
- Redis提供了多种AOF缓冲区同步文件策略,由参数appendfsync控制
AOF工作流-3文件重写?
- 现象:
-- 随着命令不断写入AOF,文件会越来越大,为了解决这个问题,Redis
引入AOF重写机制压缩文件体积。
-- AOF重写降低了文件占用空间,除此之外,另一个目的是:更小的AOF
文件可以更快地被Redis加载。 - 概念:
AOF文件重写是把Redis进程内的数据转化为写命令同步到新AOF文件的过程。
- 现象:
重写后的AOF文件为什么可以变小?
1)进程内已经超时的数据不再写入文件。
2)旧的AOF文件含有无效命令,如del key1、hdel key2、srem keys、set a111、set a222等。重写使用进程内数据直接生成,这样新的AOF文件只保留最终数据的写入命令。
3)多条写命令可以合并为一个,如:lpush list a、lpush list b、lpush list c可以转化为:lpush list a b c。为了防止单条命令过大造成客户端缓冲区溢出,对于list、set、hash、zset等类型操作,以64个元素为界拆分为多条。AOF重写过程可以手动触发和自动触发?
- 手动触发:直接调用bgrewriteaof命令。
- 自动触发:根据auto-aof-rewrite-min-size和auto-aof-rewrite-percentage参数确定自动触发时机。
-- auto-aof-rewrite-min-size:表示运行AOF重写时文件最小体积,默认为64MB。
-- auto-aof-rewrite-percentage:代表当前AOF文件空间
(aof_current_size)和上一次重写后AOF文件空间(aof_base_size)的比值。
-- 自动触发时机=aof_current_size>auto-aof-rewrite-minsize&&(aof_current_size-aof_base_size)/aof_base_size>=auto-aof-rewritepercentage
其中aof_current_size和aof_base_size可以在info Persistence统计信息中查看。
AOF重写运行流程?

流程说明:
1)执行AOF重写请求。
如果当前进程正在执行AOF重写,请求不执行并返回如下响应:ERR Background append only file rewriting already in progress
如果当前进程正在执行bgsave操作,重写命令延迟到bgsave完成之后再
执行,返回如下响应:Background append only file rewriting scheduled
2)父进程执行fork创建子进程,开销等同于bgsave过程。
3.1)主进程fork操作完成后,继续响应其他命令。所有修改命令依然写
入AOF缓冲区并根据appendfsync策略同步到硬盘,保证原有AOF机制正确
性。
3.2)由于fork操作运用写时复制技术,子进程只能共享fork操作时的内
存数据。由于父进程依然响应命令,Redis使用“AOF重写缓冲区”保存这部
分新数据,防止新AOF文件生成期间丢失这部分数据。
4)子进程根据内存快照,按照命令合并规则写入到新的AOF文件。每
次批量写入硬盘数据量由配置aof-rewrite-incremental-fsync控制,默认为32MB,防止单次刷盘数据过多造成硬盘阻塞。
5.1)新AOF文件写入完成后,子进程发送信号给父进程,父进程更新
统计信息,具体见info persistence下的aof_*相关统计。
5.2)父进程把AOF重写缓冲区的数据写入到新的AOF文件。
5.3)使用新AOF文件替换老文件,完成AOF重写。AOF工作流-4重启加载?
- AOF和RDB文件都可以用于服务器重启时的数据恢复。
- Redis持久化文件加载流程:

流程说明:
1)AOF持久化开启且存在AOF文件时,优先加载AOF文件,打印如下
日志:
* DB loaded from append only file: 5.841 seconds
2)AOF关闭或者AOF文件不存在时,加载RDB文件,打印如下日志:
* DB loaded from disk: 5.586 seconds
3)加载AOF/RDB文件成功后,Redis启动成功。
4)AOF/RDB文件存在错误时,Redis启动失败并打印错误信息。文件校验
- 加载损坏的AOF文件时会拒绝启动,并打印如下日志:
# Bad file format reading the append only file: make a backup of your AOF file,then use ./redis-check-aof --fix <filename>
- 加载损坏的AOF文件时会拒绝启动,并打印如下日志:
内存
客户端
二、多机/高可用
- 概述:
- 复制功能是高可用Redis的基础,哨兵和集群都是在复制的基础上实现高可用的。
1. 复制
| 序号 | 主要内容 | 状态 |
|---|---|---|
| 1 | ||
| 2 | ||
| 3 | ||
| 4 | 复制的使用方式:如何建立或断开复制、安全性、只读等 | |
| 5 | 复制可支持的拓扑结构,以及每个拓扑结构的适用场景。 | |
| 6 | 复制的原理,包括:建立复制、全量复制、部分复制、心跳等 | |
| 7 | 复制过程中常见的开发和运维问题:读写分离、数据不一致、规 |
避全量复制等 |
1-基本概念
复制概念?
在分布式系统中为了解决单点问题,通常会把数据复制多个副本部署到其他机器,满足故障恢复和负载均衡等需求。Redis也是如此,它为我们提
供了复制功能,实现了相同数据的多个Redis副本。复制简介?
- 参与复制的Redis实例划分为主节点(master)和从节点(slave)。默认情况下,Redis都是主节点。
- 每个从节点只能有一个主节点,而主节点可以同时具有多个从节点。
- 复制的数据流是单向的,只能由主节点复制到从节点。
- slaveof本身是异步命令,执行slaveof命令时,节点只保存主节点信息后返回,后续复制流程在节点内部异步执行,
2-原理
1-复制过程
- 复制过程?
- 在从节点执行slaveof命令后,复制过程便开始运作
- 复制的完整流程,如图,大致分为6个过程:

① 保存主节点(master)信息。
执行slaveof后从节点只保存主节点的地址信息便直接返回,这时建立复制流程还没有开始;主节点的ip和port被保存下来,但是主节点的连接状态(master_link_status)是下线状态。
② 从节点(slave)内部通过每秒运行的定时任务维护复制相关逻辑,当定时任务发现存在新的主节点后,会尝试与该节点建立网络连接。
从节点会建立一个socket套接字,如图中从节点建立了一个端口为24555的套接字,专门用于接受主节点发送的复制命令。
如果从节点无法建立连接,定时任务会无限重试直到连接成功或者执行slaveof no one取消复制;


③ 发送ping命令。
连接建立成功后从节点发送ping请求进行首次通信,ping请求主要目的如下:
·检测主从之间网络套接字是否可用。
·检测主节点当前是否可接受处理命令。
如果发送ping命令后,从节点没有收到主节点的pong回复或者超时,比如网络超时或者主节点正在阻塞无法响应命令,从节点会断开复制连接,下次定时任务会发起重连;

④ 权限验证。
如果主节点设置了requirepass参数,则需要密码验证,从节点必须配置masterauth参数保证与主节点相同的密码才能通过验证;如果验证失败复制将终止,从节点重新发起复制流程。
⑤ 同步数据集。
主从复制连接正常通信后,对于首次建立复制的场景,主节点会把持有的数据全部发送给从节点,这部分操作是耗时最长的步;
⑥ 命令持续复制。当主节点把当前的数据同步给从节点后,便完成了复制的建立流程。接下来主节点会持续地把写命令发送给从节点,保证主从数据一致性。
2-数据同步
全量复制|部分复制|复制偏移量|复制积压缓冲区|主节点运行id|psync命令
基本概念
- Redis在2.8及以上版本使用psync命令完成主从数据同步,同步过程分为:全量复制和部分复制。
- 全量复制:
一般用于初次复制场景,Redis早期支持的复制功能只有全量复制,它会把主节点全部数据一次性发送给从节点,当数据量较大时,会对主从节点和网络造成很大的开销。 - 部分复制:用于处理在主从复制中因网络闪断等原因造成的数据丢失场景,当从节点再次连上主节点后,如果条件允许,主节点会补发丢失数据给从节点。因为补发的数据远远小于全量数据,可以有效避免全量复制的过高开销。
psync命令运行需要以下组件支持?
·主从节点各自复制偏移量。
·主节点复制积压缓冲区。
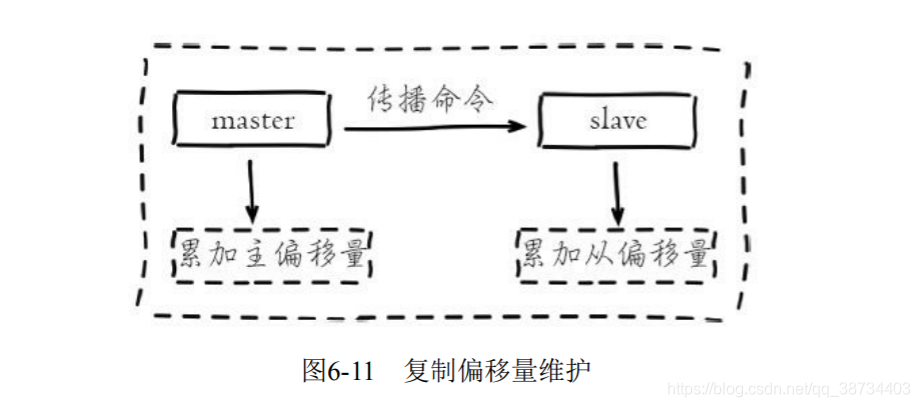
·主节点运行id。复制偏移量?
- 参与复制的主从节点都会维护自身复制偏移量。
- 主节点(master)在处理完写入命令后,会把命令的字节长度做累加记录;
- 从节点(slave)每秒钟上报自身的复制偏移量给主节点,因此主节点也会保存从节点的复制偏移量;
- 从节点在接收到主节点发送的命令后,也会累加记录自身的偏移量。
- 通过对比主从节点的复制偏移量,可以判断主从节点数据是否一致。
也会保存从节点的复制偏移量 - 问题分析:
通过主节点的统计信息,计算出master_repl_offset-slave_offset字节量,判断主从节点复制相差的数据量,根据这个差值判定当前复制的健康度。如果主从之间复制偏移量相差较大,则可能是网络延迟或命令阻塞等原因引起。
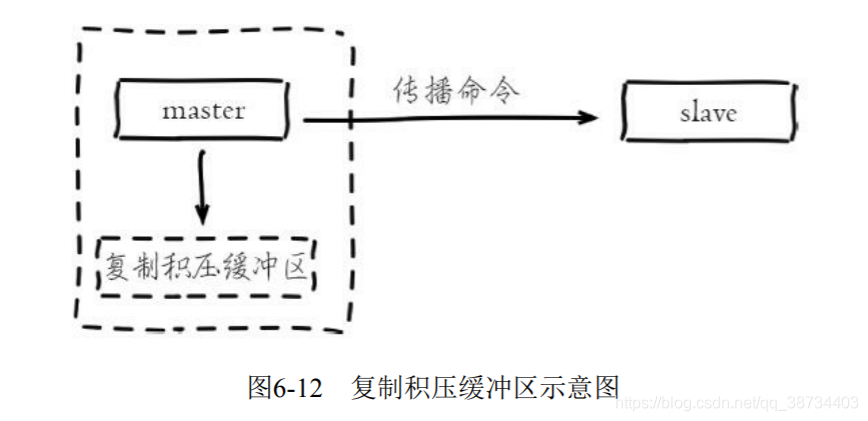
复制积压缓冲区?
- 复制积压缓冲区是保存在主节点上的一个固定长度的队列,默认大小为1MB,当主节点有连接的从节点(slave)时被创建,这时主节点(master)响应写命令时,不但会把命令发送给从节点,还会写入复制积压缓冲区;
- 由于缓冲区本质上是先进先出的定长队列,所以能实现保存最近已复制数据的功能,用于部分复制和复制命令丢失的数据补救。
主节点运行ID?
- 每个Redis节点启动后都会动态分配一个40位的十六进制字符串作为运行ID。
- 运行ID的主要作用是用来唯一识别Redis节点,比如从节点保存主节点的运行ID识别自己正在复制的是哪个主节点。
- 如果只使用ip+port的方式识别主节点,那么主节点重启变更了整体数据集(如替换RDB/AOF文件),从节点再基于偏移量复制数据将是不安全的,因此当运行ID变化后从节点将做全量复制。
- 可以运行info server命令查看当前节点的运行ID;
- 需要注意的是Redis关闭再启动后,运行ID会随之改变;
如何在不改变运行ID的情况下重启呢?
- 当需要调优一些内存相关配置,例如:hash-max-ziplist-value等,这些配
置需要Redis重新加载才能优化已存在的数据,这时可以使用debug reload命
令重新加载RDB并保持运行ID不变,从而有效避免不必要的全量复制。 - debug reload命令会阻塞当前Redis节点主线程,阻塞期间会生成本地RDB快照并清空数据之后再加载RDB文件。因此对于大数据量的主节点和无法容忍阻塞的应用场景,谨慎使用。
- 当需要调优一些内存相关配置,例如:hash-max-ziplist-value等,这些配
psync命令?
从节点使用psync命令完成部分复制和全量复制功能,命令格式:psync{runId}{offset},参数含义如下:
·runId:从节点所复制主节点的运行id。
·offset:当前从节点已复制的数据偏移量。psync命令运行流程?

流程说明:
1)从节点(slave)发送psync命令给主节点,参数runId是当前从节点保存的主节点运行ID,如果没有则默认值为,参数offset是当前从节点保存的复制偏移量,如果是第一次参与复制则默认值为-1。
2)主节点(master)根据psync参数和自身数据情况决定响应结果:
·如果回复+FULLRESYNC{runId}{offset},那么从节点将触发全量复制流程。
·如果回复+CONTINUE,从节点将触发部分复制流程。
·如果回复+ERR,说明主节点版本低于Redis2.8,无法识别psync命令,从节点将发送旧版的sync命令触发全量复制流程。全量复制?
- 全量复制是Redis最早支持的复制方式,也是主从第一次建立复制时必须经历的阶段。
- 触发全量复制的命令是sync(redis<2.8)和psync(redis>2.8);
- 此处psync全量复制流程,与2.8以前的sync全量复制机制基本一致。
- 流程说明:

1)发送psync命令进行数据同步,由于是第一次进行复制,从节点没有复制偏移量和主节点的运行ID,所以发送psync-1。
2)主节点根据psync-1解析出当前为全量复制,回复+FULLRESYNC响应。
3)从节点接收主节点的响应数据保存运行ID和偏移量offset。
4)主节点执行bgsave保存RDB文件到本地。
5)主节点发送RDB文件给从节点,从节点把接收的RDB文件保存在本地并直接作为从节点的数据文件。
需要注意,对于数据量较大的主节点,比如生成的RDB文件超过6GB以上时要格外小心。如果总时间超过repl-timeout所配置的值(默认60秒),从节点将放弃接受RDB文件并清理已经下载的临时文件,导致全量复制失败。针对数据量较大的节点,建议调大repl-timeout参数防止出现全量同步数据超时。
6)对于从节点开始接收RDB快照到接收完成期间,主节点仍然响应读写命令,因此主节点会把这期间写命令数据保存在复制客户端缓冲区内,当从节点加载完RDB文件后,主节点再把缓冲区内的数据发送给从节点,保证主从之间数据一致性。如果主节点创建和传输RDB的时间过长,对于高流量写入场景非常容易造成主节点复制客户端缓冲区溢出。默认配置为clientoutput-buffer-limit slave256MB64MB60,如果60秒内缓冲区消耗持续大于64MB或者直接超过256MB时,主节点将直接关闭复制客户端连接,造成全量同步失败。
-)对于主节点,当发送完所有的数据后就认为全量复制完成,但是对于从节点全
量复制依然没有完成,还有后续步骤需要处理。
7)从节点接收完主节点传送来的全部数据后会清空自身旧数据。
8)从节点清空数据后开始加载RDB文件,对于较大的RDB文件,这一步操作依然比较耗时。
对于线上做读写分离的场景,从节点也负责响应读命令。如果此时从节点正出于全量复制阶段或者复制中断,那么从节点在响应读命令可能拿到过期或错误的数据。对于这种场景,Redis复制提供了slave-serve-stale-data参数,默认开启状态。如果开启则从节点依然响应所有命令,对于无法容忍不一致的应用场景可以设置no来关闭命令执行。
9)从节点成功加载完RDB后,如果当前节点开启了AOF持久化功能,它会立刻做bgrewriteaof操作,为了保证全量复制后AOF持久化文件立刻可用。
显然,全量复制是一个非常耗时费力的操作。
- 它的时间开销主要包括:
·主节点bgsave时间。
·RDB文件网络传输时间。
·从节点清空数据时间。
·从节点加载RDB的时间。
·可能的AOF重写时间。 - 当数据量达到一定规模之后,由于全量复制过程中将进行多次持久化相关操作和网络数据传输,这期间会大量消耗主从节点所在服务器的CPU、内存和网络资源。
- 它的时间开销主要包括:
部分复制?
- 部分复制主要是Redis针对全量复制的过高开销做出的一种优化措施,
- 使用psync{runId}{offset}命令实现。
- 当从节点(slave)正在复制主节点
(master)时,如果出现网络闪断或者命令丢失等异常情况时,从节点会向主节点要求补发丢失的命令数据,如果主节点的复制积压缓冲区内存在这部分数据则直接发送给从节点,这样就可以保持主从节点复制的一致性。 - 补发的这部分数据一般远远小于全量数据,所以开销很小。
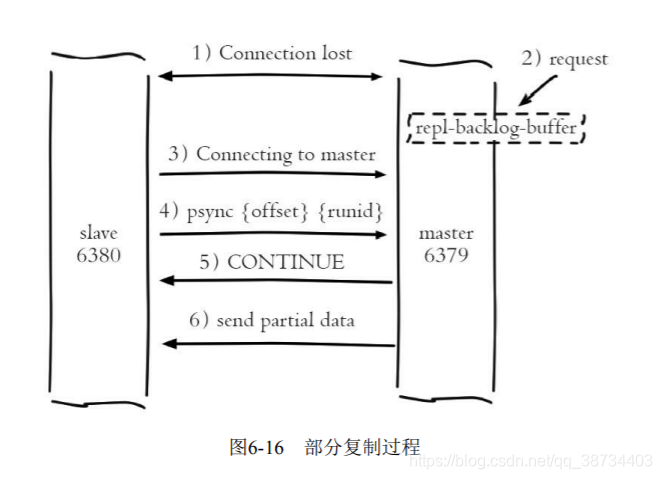
- 流程说明:
1)当主从节点之间网络出现中断时,如果超过repl-timeout(RDB文件从创建到传输完毕消耗的总时间)时间,主节点会认为从节点故障并中断复制连接;
2)主从连接中断期间主节点依然响应命令,但因复制连接中断命令无法发送给从节点,不过主节点内部存在的复制积压缓冲区,依然可以保存最近一段时间的写命令数据,默认最大缓存1MB。
3)当主从节点网络恢复后,从节点会再次连上主节点;
4)当主从连接恢复后,由于从节点之前保存了自身已复制的偏移量和主节点的运行ID。因此会把它们当作psync参数发送给主节点,要求进行部分复制操作
5)主节点接到psync命令后首先核对参数runId是否与自身一致,如果一致,说明之前复制的是当前主节点;之后根据参数offset在自身复制积压缓冲区查找,如果偏移量之后的数据存在缓冲区中,则对从节点发送+CONTINUE响应,表示可以进行部分复制。
6)主节点根据偏移量把复制积压缓冲区里的数据发送给从节点,保证主从复制进入正常状态;发送的数据量可以在主节点的日志获取;
3 运维中的问题
- 开发与运维中的问题?
基于复制的应用场景。
- 通过复制机制,数据集可以存在多个副本(从节点)。这些副本可以应用于读写分离、故障转移(failover)、实时备份等场景。但是在实际应用复制功能时,依然有一些坑需要跳过。
读写分离
- 对于读占比较高的场景,可以通过把一部分读流量分摊到从节点
(slave)来减轻主节点(master)压力,同时需要注意永远只对主节点执行写操作 - 当使用从节点响应读请求时,业务端可能会遇到如下问题:
·复制数据延迟。
·读到过期数据。
·从节点故障。
1)数据延迟
- 对于读占比较高的场景,可以通过把一部分读流量分摊到从节点
7. 哨兵
8. 集群
三、应用
34 缓存
| 序号 | 主要内容 | 状态 |
|---|---|---|
| 1 | 缓存的收益和成本分析 | |
| 2 | 缓存更新策略的选择和使用场景 | |
| 3 | 缓存粒度控制方法 | |
| 4 | 穿透问题优化 | |
| 5 | 无底洞问题优化 | × |
| 6 | 雪崩问题优化 | |
| 7 | 热点key重建优化 |
- 缓存概述?
- 缓存能够有效地加速应用的读写速度,同时也可以降低后端负载,对日常应用的开发至关重要。
- 但是将缓存加入应用架构后也会带来一些问题,本章将针对这些问题介绍缓存使用技巧和设计方案,包含如下内容:
·缓存的收益和成本分析。
·缓存更新策略的选择和使用场景。
·缓存粒度控制方法。
·穿透问题优化。
·无底洞问题优化。
·雪崩问题优化。
·热点key重建优化。
1-收益和成本分析
- 缓存的收益和成本?
-- 左侧为客户端直接调用存储层的架构,右侧为比较典型的缓存层+存储层架构;

-- 收益:
① 加速读写:因为缓存通常都是全内存的(例如Redis、Memcache),而存储层通常读写性能不够强悍(例如MySQL),通过缓存的使用可以有效地加速读写,优化用户体验。
② 降低后端负载:帮助后端减少访问量和复杂计算(例如很复杂的SQL语句),在很大程度降低了后端的负载。
-- 成本:
① 数据不一致性:缓存层和存储层的数据存在着一定时间窗口的不一致性,时间窗口跟更新策略有关。
② 代码维护成本:加入缓存后,需要同时处理缓存层和存储层的逻辑,增大了开发者维护代码的成本。
③ 运维成本:以Redis Cluster为例,加入后无形中增加了运维成本。
- 缓存的使用场景基本包含如下两种?:
① 开销大的复杂计算:以MySQL为例子,一些复杂的操作或者计算(例如大量联表操作、一些分组计算),如果不加缓存,不但无法满足高并发量,同时也会给MySQL带来巨大的负担。
② 加速请求响应:即使查询单条后端数据足够快(例如select*from table where id=),那么依然可以使用缓存,以Redis为例子,每秒可以完成数万次读写,并且提供的批量操作可以优化整个IO链的响应时间。
- 缓存的使用场景基本包含如下两种?:
2-更新策略的选择和使用场景。
- 缓存的缓存更新策略的选择和使用场景?
-- 缓存中的数据通常都是有生命周期的,需要在指定时间后被删除或更新,以保证缓存空间在一个可控的范围。
1)LRU/LFU/FIFO算法剔除
► 使用场景:用于缓存使用量超过了预设的最大值时候,如何对现有的数据进行剔除。例如Redis使用maxmemory-policy这个配置作为内存最大值后对于数据的剔除策略。
► 一致性:要清理哪些数据是由具体算法决定,开发人员只能决定使用哪种算法,所以数据的一致性是最差的。
► 维护成本:算法不需要开发人员自己来实现,通常只需要配置最大maxmemory和对应的策略即可。开发人员只需要知道每种算法的含义,选择适合自己的算法即可。
2)超时剔除
► 使用场景:超时剔除通过给缓存数据设置过期时间,让其在过期时间后自动删除,例如Redis提供的expire命令。如果业务可以容忍一段时间内,缓存层数据和存储层数据不一致,那么可以为其设置过期时间。在数据过期后,再从真实数据源获取数据,重新放到缓存并设置过期时间。例如一个视频的描述信息,可以容忍几分钟内数据不一致,但是涉及交易方面的业务,后果可想而知。
► 一致性:一段时间窗口内(取决于过期时间长短)存在一致性问题,即缓存数据和真实数据源的数据不一致。
► 维护成本:维护成本不是很高,只需设置expire过期时间即可,当然前提是应用方允许这段时间可能发生的数据不一致。
3)主动更新
► 使用场景:应用方对于数据的一致性要求高,需要在真实数据更新后,立即更新缓存数据。例如可以利用消息系统或者其他方式通知缓存更新。
► 一致性:一致性最高,但如果主动更新发生了问题,那么这条数据很可能很长时间不会更新,所以建议结合超时剔除一起使用效果会更好。
► 维护成本:维护成本会比较高,开发者需要自己来完成更新,并保证更新操作的正确性。
-- 应用建议
► 低一致性业务建议配置最大内存和淘汰策略的方式使用。
► 高一致性业务可以结合使用超时剔除和主动更新,这样即使主动更新出了问题,也能保证数据过期时间后删除脏数据。

- 缓存粒度控制方法。
-- 缓存全部数据和部分数据;

- 缓存粒度控制方法。
3-穿透问题优化。
redis的缓存穿透、缓存击穿、缓存雪崩原因现象和解决措施? |3
redis缓存穿透与解决措施? |3 (rky
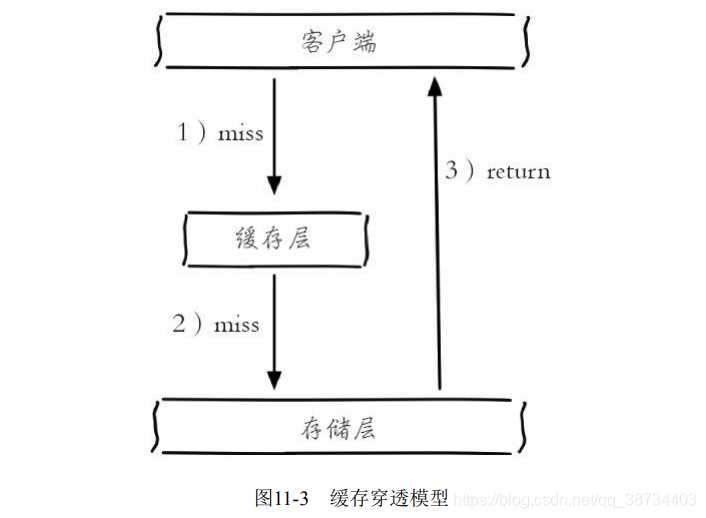
- 是什么?
指查询一个根本不存在的数据,缓存层和存储层都不会命中,通常出于容错的考虑,如果从存储层查不到数据则不写入缓存层,如图整个过程分为如下3步:
1)缓存层不命中。
2)存储层不命中,不将空结果写回缓存。
3)返回空结果。
- 后果:
► 导致不存在的数据每次请求都要到存储层去查询,失去了缓存保护后端存储的意义。
► 缓存穿透问题可能会使后端存储负载加大,由于很多后端存储不具备高并发性,甚至可能造成后端存储宕掉。通常可以在程序中分别统计总调用数、缓存层命中数、存储层命中数,如果发现大量存储层空命中,可能就是出现了缓存穿透问题。 - 基本原因有两个:
► 第一,自身业务代码或者数据出现问题;
► 第二,一些恶意攻击、爬虫等造成大量空命中。 - 解决缓存穿透问题:
1)缓存空对象
如图,当第2步存储层不命中后,仍然将空对象保留到缓存层中,之后再访问这个数据将会从缓存中获取,这样就保护了后端数据源。

▷ 缓存空对象会有两个问题:
① 空值做了缓存,意味着缓存层中存了更多的键,需要更多的内存空间(如果是攻击,问题更严重),比较有效的方法是针对这类数据设置一个较短的过期时间,让其自动剔除。
② 缓存层和存储层的数据会有一段时间窗口的不一致,可能会对业务有一定影响。
例如过期时间设置为5分钟,如果此时存储层添加了这个数据,那此段时间就会出现缓存层和存储层数据的不一致,此时可以利用消息系统或者其他方式清除掉缓存层中的空对象。
▷ 缓存空对象的实现代码:
String get(String key) {// 从缓存中获取数据String cacheValue = cache.get(key);// 缓存为空if (StringUtils.isBlank(cacheValue)) {// 从存储中获取String storageValue = storage.get(key);cache.set(key, storageValue);// 如果存储数据为空,需要设置一个过期时间(300秒)if (storageValue == null) {cache.expire(key, 60 * 5);}return storageValue;} else {// 缓存非空return cacheValue;}}
2)布隆过滤器拦截
► 如图,在访问缓存层和存储层之前,将存在的key用布隆过滤器提前保存起来,做第一层拦截。

► 场景:
例如:一个推荐系统有4亿个用户id,每个小时算法工程师会根据每个用户之前历史行为计算出推荐数据放到存储层中,但是最新的用户由于没有历史行为,就会发生缓存穿透的行为,为此可以将所有推荐数据的用户做成布隆过滤器。如果布隆过滤器认为该用户id不存在,那么就不会访问存储层,在一定程度保护了存储层。
► 实现:
有关布隆过滤器的相关知识,可以参考:https://en.wikipedia.org/wiki/Bloom_filter可以利用Redis的Bitmaps实现布隆过滤器,GitHub上已经开源了类似的方案,读者可以进行参考:https://github.com/erikdubbelboer/redis-lua-scaling-bloom-filter。
► 应用场景:
适用于数据命中不高、数据相对固定、实时性低(通常是数据集较大)的应用场景,代码维护较为复杂,但是缓存空间占用少。
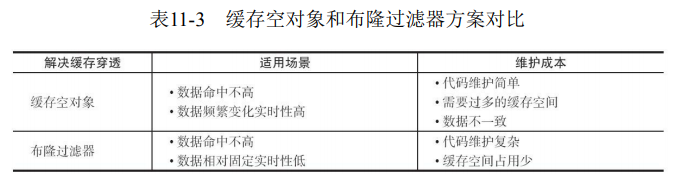
► 两种解决方法的对比(实际上这个问题是一个开放问题,有很多解决方法)
- 是什么?
4-无底洞问题优化。
5-雪崩
- redis缓存雪崩与解决措施?
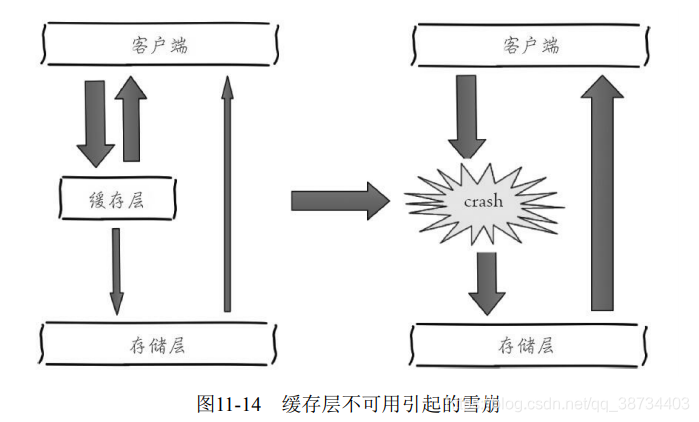
- 是什么?
由于缓存层承载着大量请求,有效地保护了存储层,但是如果缓存层由于某些原因不能提供服务,于是所有的请求都会达到存储层,存储层的调用量会暴增,造成存储层也会级联宕机的情况。缓存雪崩的英文原意是stampeding herd(奔逃的野牛),指的是缓存层宕掉后,流量会像奔逃的野牛一样,打向后端存储。
- 三个方面预防和解决缓存雪崩问题:
1)保证缓存层服务高可用性。
和飞机都有多个引擎一样,如果缓存层设计成高可用的,即使个别节点、个别机器、甚至是机房宕掉,依然可以提供服务,例如前面介绍过的Redis Sentinel和Redis Cluster都实现了高可用。
2)依赖隔离组件为后端限流并降级。
无论是缓存层还是存储层都会有出错的概率,可以将它们视同为资源。作为并发量较大的系统,假如有一个资源不可用,可能会造成线程全部阻塞(hang)在这个资源上,造成整个系统不可用。
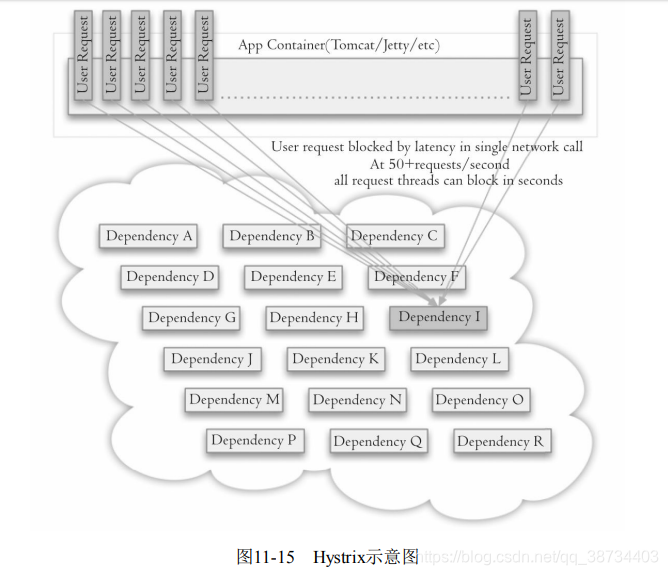
▷ 降级机制在高并发系统中是非常普遍的:比如推荐服务中,如果个性化推荐服务不可用,可以降级补充热点数据,不至于造成前端页面是开天窗。在实际项目中,我们需要对重要的资源(例如Redis、MySQL、HBase、外部接口)都进行隔离,让每种资源都单独运行在自己的线程池中,即使个别资源出现了问题,对其他服务没有影响。但是线程池如何管理,比如如何关闭资源池、开启资源池、资源池阀值管理,这些做起来还是
相当复杂的。这里推荐一个Java依赖隔离工具Hystrix(https://github.com/netflix/hystrix),如图。Hystrix是解决依赖隔离的利器,但是该内容已经超出本书的范围,同时只适用于Java应用,所以这里不会详细介绍。
3)提前演练。在项目上线前,演练缓存层宕掉后,应用以及后端的负载情况以及可能出现的问题,在此基础上做一些预案设定。
- 是什么?
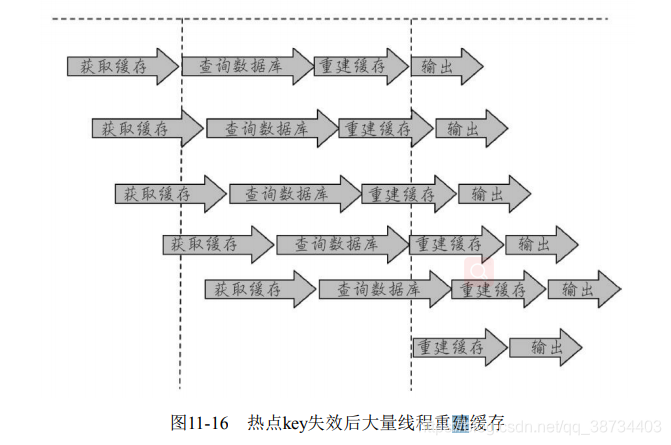
6-热点key重建(击穿
缓存策略的问题?
- 开发人员使用“缓存+过期时间”的策略既可以加速数据读写,又保证数据的定期更新,这种模式基本能够满足绝大部分需求。
- 但是有两个问题如果同时出现,可能就会对应用造成致命的危害:
① 当前key是一个热点key(例如一个热门的娱乐新闻),并发量非常大。
② 重建缓存不能在短时间完成,可能是一个复杂计算,例如复杂的SQL、多次IO、多个依赖等。 - 在缓存失效的瞬间,有大量线程来重建缓存,造成后端负载加大,甚至可能会让应用崩溃。
解决?:
- 要解决这个问题也不是很复杂,但是不能为了解决这个问题给系统带来更多的麻烦,所以需要制定如下目标:
·减少重建缓存的次数。
·数据尽可能一致。
·较少的潜在危险。 - 1)互斥锁(mutex key)
- 2)永远不过期
- 要解决这个问题也不是很复杂,但是不能为了解决这个问题给系统带来更多的麻烦,所以需要制定如下目标:
互斥锁(mutex key)解决缓存击穿?
- 此方法只允许一个线程重建缓存,其他线程等待重建缓存的线程执行完,重新从缓存获取数据即可,整个过程如图11-17所示。
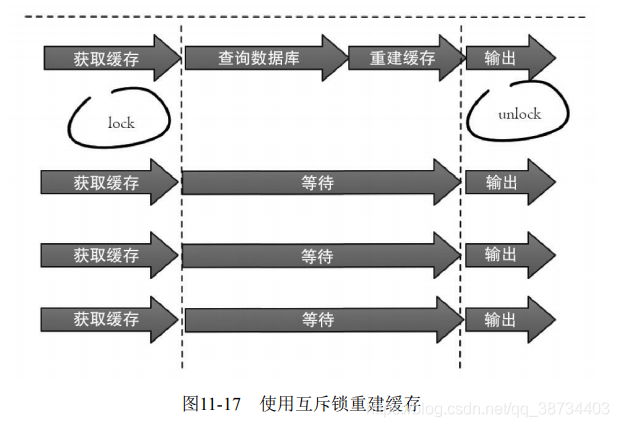
- 下面代码使用Redis的setnx命令实现上述功能:
String get(String key) {// 从Redis中获取数据String value = redis.get(key);// 如果value为空,则开始重构缓存if (value == null) {// 只允许一个线程重构缓存,使用nx,并设置过期时间exString mutexKey = "mutext:key:" + key;if (redis.set(mutexKey, "1", "ex 180", "nx")) {// 从数据源获取数据value = db.get(key);// 回写Redis,并设置过期时间redis.setex(key, timeout, value);// 删除key_mutexredis.delete(mutexKey);}// 其他线程休息50毫秒后重试else {Thread.sleep(50);get(key);}}return value;}
1)从Redis获取数据,如果值不为空,则直接返回值;否则执行下面的2.1)和2.2)步骤。
2.1)如果set(nx和ex)结果为true,说明此时没有其他线程重建缓存,那么当前线程执行缓存构建逻辑。
2.2)如果set(nx和ex)结果为false,说明此时已经有其他线程正在执行构建缓存的工作,那么当前线程将休息指定时间(例如这里是50毫秒,取决于构建缓存的速度)后,重新执行函数,直到获取到数据。- 此方法只允许一个线程重建缓存,其他线程等待重建缓存的线程执行完,重新从缓存获取数据即可,整个过程如图11-17所示。
永远不过期接缓存击穿?
- “永远不过期”包含两层意思:
-- 从缓存层面来看,确实没有设置过期时间,所以不会出现热点key过期后产生的问题,也就是“物理”不过期。
-- 从功能层面来看,为每个value设置一个逻辑过期时间,当发现超过逻辑过期时间后,会使用单独的线程去构建缓存。
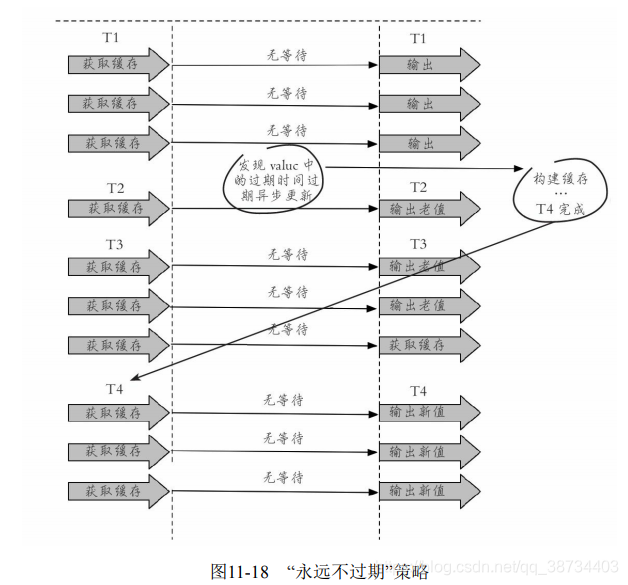
- 从实战看,此方法有效杜绝了热点key产生的问题,但唯一不足的就是重构缓存期间,会出现数据不一致的情况,这取决于应用方是否容忍这种不一致。
- 代码实现:
String get(final String key) {V v = redis.get(key);String value = v.getValue();// 逻辑过期时间long logicTimeout = v.getLogicTimeout();// 如果逻辑过期时间小于当前时间,开始后台构建if (v.logicTimeout <= System.currentTimeMillis()) {String mutexKey = "mutex:key:" + key;if (redis.set(mutexKey, "1", "ex 180", "nx")) {// 重构缓存threadPool.execute(new Runnable() {public void run() {String dbValue = db.get(key);redis.set(key, (dbvalue,newLogicTimeout));redis.delete(mutexKey);}});}}return value;}
- “永远不过期”包含两层意思:
缓存指标对比解决方案?
- 作为一个并发量较大的应用,在使用缓存时有三个目标:
第一,加快用户访问速度,提高用户体验。
第二,降低后端负载,减少潜在的风险,保证系统平稳。
第三,保证数据“尽可能”及时更新。下面将按照这三个维度对上述两种解决方案进行分析。 - 互斥锁(mutex key):这种方案思路比较简单,但是存在一定的隐患,如果构建缓存过程出现问题或者时间较长,可能会存在死锁和线程池阻塞的风险,但是这种方法能够较好地降低后端存储负载,并在一致性上做得比较好。
- “永远不过期”:这种方案由于没有设置真正的过期时间,实际上已经不存在热点key产生的一系列危害,但是会存在数据不一致的情况,同时代码复杂度会增大。

- 作为一个并发量较大的应用,在使用缓存时有三个目标:
