@songhanshi
2021-08-24T00:47:23.000000Z
字数 3958
阅读 841
项目
1234
0-项目
版本
mysql运维
mysql 5.6 => 5.7redis-占数师
redis-server --version
Redis server v=4.0.10 sha=00000000:0 malloc=jemalloc-4.0.3 bits=64 build=9e1e501b91e06bf9redis-oa
2.6 其他运维告知 3.0.6kafka版本
offset保存位置不同
zookeeper环境:3.4.14-已跟线上版本一致
kafka单机环境(2.11-2.0.0版本)Kafka-外数(2.2.9)
org.springframework.kafka
spring-kafka
占数师
0-项目概述
背景:
针对app、微信等多种渠道的用户行为数据进行采集;将各类行为数据进行整合,与公司内线下数据、公司外数据结合;开展行为数据分析,提供相应数据分析功能和工具;提供相关业务功能和可视化展示页面。工程中用到的技术
- 总:
① 数据流


② 项目名称
data_generator: 生成测试数据(php)
dc_openresty:lua脚本
log_service:数据收集(重点)
realtime-task:flink实时写入(重点)
skynet-backend: web工程(重点)
das-api: 数据服务平台(重点)
zsh_docker:一键部署
③ 知识点:
lua脚本、filebeat、kafka、flink、impala、kudu、springboot、docker - 分:
① 客户端app+openresty
客户端app会将埋点数据加密后,请求dc-skynet.rong360.com下/prod/send_data接口上传数据。
nginx运行lua脚本获取数据,进行封装,写入log。脚本参见zsh_docker工程
② 日志收集+log-service
app端或者客户服务端打点数据过来后,会在日志收集系统中进行数据的简单校验和转换,同时添加用户标识id。定义转换为放入 kafka 的消息格式。
1> 数据收集
后台脚本不断扫描数据文件是否有新的写入 com\example\log_service\common\ThreadPoolExecutor.java
a.生产者不断扫描文件判断是否有新数据写入,如果有新数据写入将数据读取,并推送至阻塞队列中
b.消费者主线程不断监听阻塞队列,如果有数据将数据取出发送给消费线程池进行消费
c.消费线程负责数据处理、保存等
2> 日志数据的处理
1)日志消费分为sdk日志和nginx的log日志
2)Nginx日志消费com\example\log_service\common\NgConsumeService.java
a.数据的decode,unzip等操作,解析出json格式数据
b.Sdk日志消费 com\example\log_service\common\SdkConsumeService.java
将数据直接解析成json格式数据
c.Json格式处理 com\example\log_service\domain\impl\LogServiceImpl.java
3)数据存储,通过log4j日志插件将日志保存至文件中代码:
com\example\log_service\common\writelogs\LogFileOperator.java

③ filebeat:
数据推送到kafka。配置参考zsh_docker工程
④ realtime-task:
利用flink程序消费kafka,将数据存入kudu实时表。
⑤ skynet:
元数据、漏斗分析、用户分群、事件分析、后端推送消息(websocket)
⑥ das
1> 背景:
数据应用层在整个系统架构中承担了业务系统对数据层的访问逻辑。为适应各种业务的变化带来的数据应用层频繁开发新接口上线问题,数据应用层需要对现有的异构数据源(包括但不限于MySQL, Redis, Impala等)进行抽象,提供出公共数据服务接口,以应对业务应用层多变的数据查询需求。

⑦ 大数据端
1> 数据层交互架构图

2> 数仓架构图

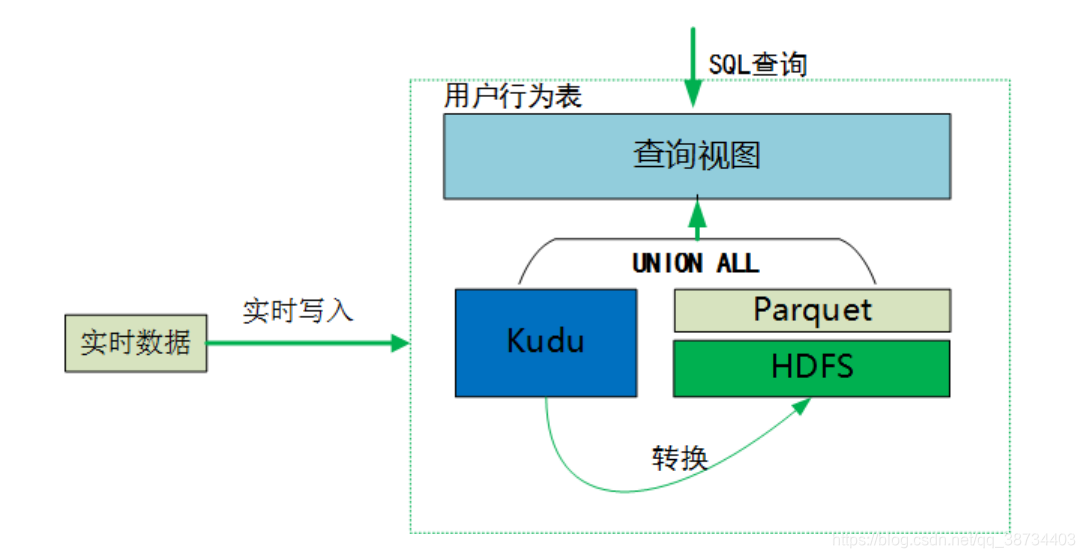
3> 查询方式
kudu表当天分区增量和hive历史数据做union all 建成视图,供外提供查询:
- 总:
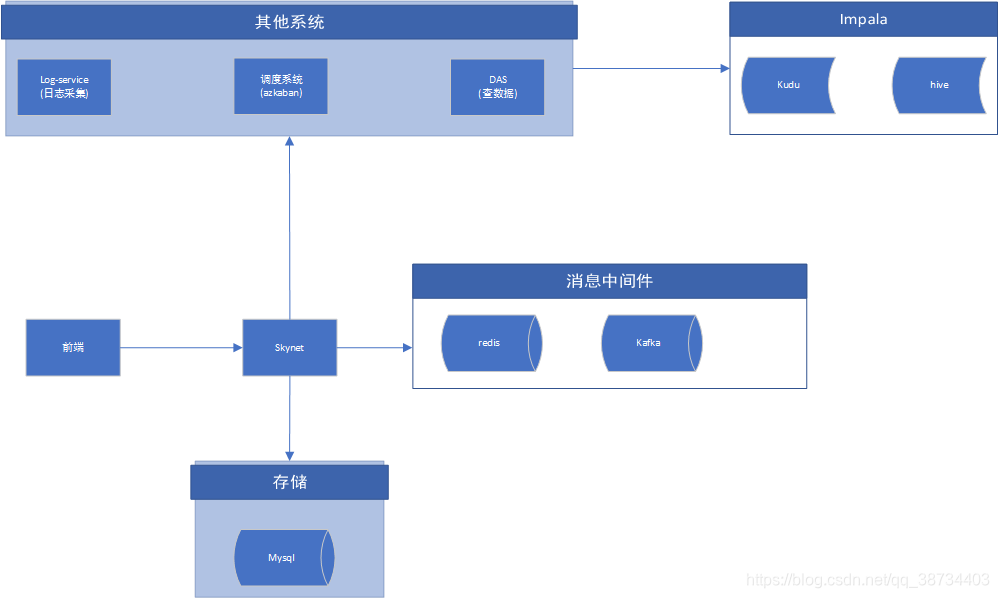
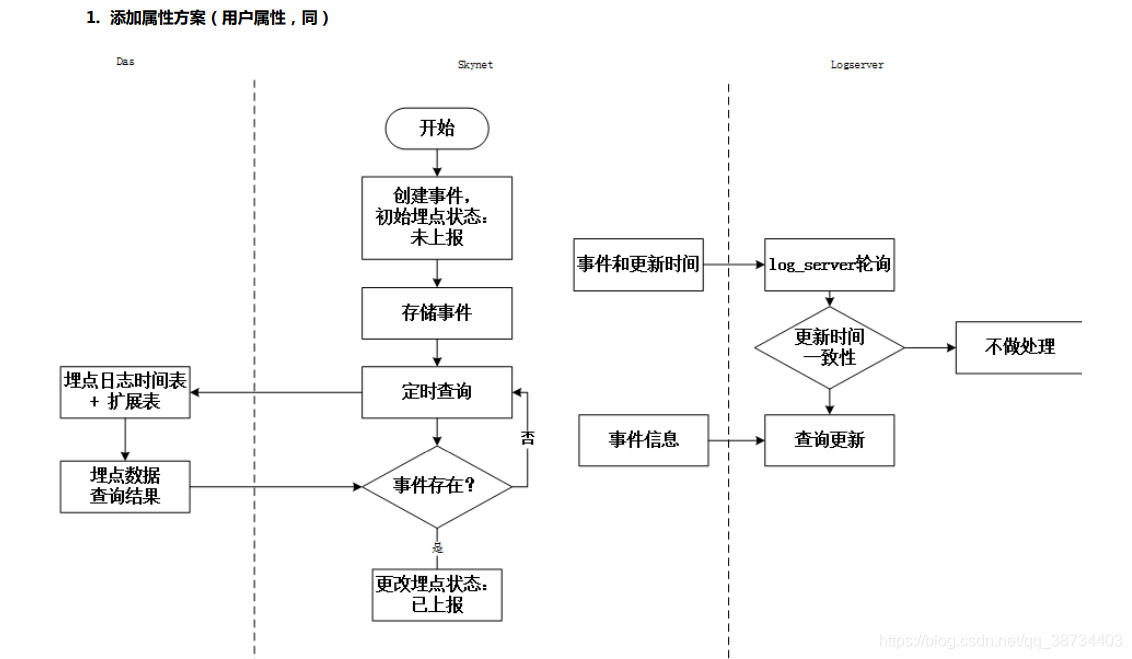
1-skynet结构
- 总:skynet:
元数据、漏斗分析、用户分群、事件分析、后端推送消息(websocket)
1> log-sevice
log-service需要知道收集日志的校验格式,而其所以来的元数据是在skynet一方维护,因此当skynet的元数据出现新增,删除,修改等变更之后需要将信息同步到log-service。
目前两者之间的通信方式是基于redis。
2>任务调度azkaban
由于DAS目前不提供DDL 操作以及插入等功能,在用户分群模块需要将符合条件的用户圈选出来。
目前使用SQL查询并插入的方式进行用户分群。其中会涉及到新建的情况
azkaban调度结束后,skynet通过轮训调度任务的方式进行获取状态,再通过DAS查询出具体的结果集。
3>消息推送websocket
对于一些异常操作的场景,如漏斗计算,需要等待大数据计算完结果之后,将消息推送到前端,目前使用websocket的方式实现。
4>技术栈
Spring Boot + Mybatis-plus + Websocket + Maven
- 事件分析:
① 需求:

② 实现
1)查询条件:skynet提供三个接口:
1> 获取所有事件
2> 获取单个事件相关指标
3> 获取多个事件指标公共的属性
2)查询:(异步、同步)

1> 按小时维度作时间窗口,进行缓存。
2> 单个页面的查询作为1个任务,按事件指标分为多个子任务。保存子任务的查询的条件。
3> 单个子任务查询完成后,保存结果到task_info表,若存在下一个子任务,则继续调用das接口进行查询。
4> 全部子任务查询完毕后,发送消息。
5> 若可从缓存中获取结果,则同步返回,否则走异步流程。
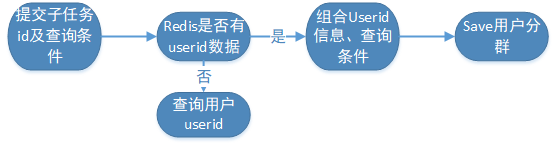
6> 若查询是和用户相关,则返回特殊标记及子任务id,以便后续进行“查看用户列表”和“添加分群”功能。
7> 消息处理流程,暂定与漏斗分析保持一致。
3)查看用户列表:通过sql模板调用接口查询用户(同步)。

4)添加分群(同步)
③ 大数据端
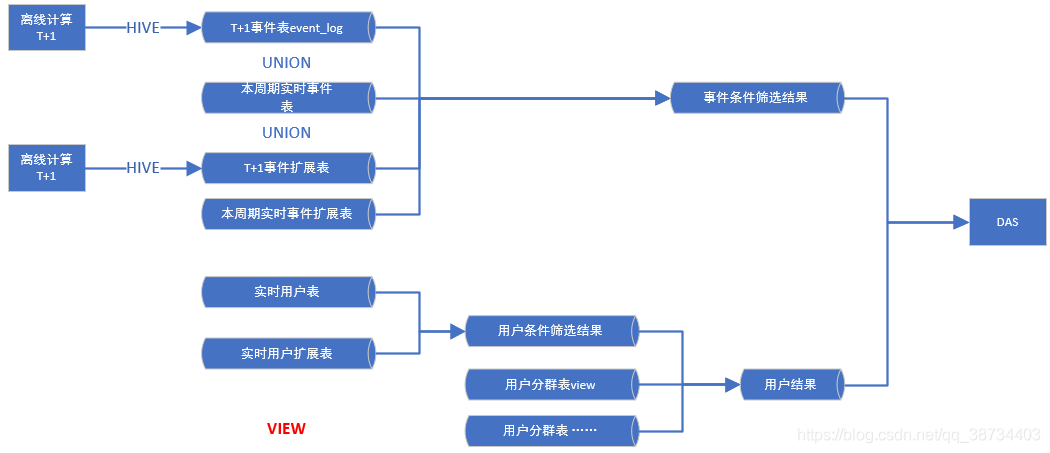
1 查询引擎:impala,中间结果表存储在:htp 库。das落地中间表关键字 htp.tmp_skynet_event_analysis_d (日表) _event_analysis_,格式:stored as parquet
2 数据表:
数据存储规范:kudu实时来源表,暂定存储周期三个月。
范围:最新全量用户表,最新全量用户扩展表,离线和实时事件表
中间表:无
4模板拼接:
1)逻辑,小于3个月的数据直接查询kudu的视图表,时间跨度大于3个月且包含实时数据的查询使用,离线+当周期的视图表,不包含本周期的实时数据且查询时间大于3个月直接查询离线表。
2)涉及到交叉表的数据展示,待das和前端评审确认
5 查询性能:预估分钟级
6 数据工作:离线流程开发,模板开发
7 页面必须默认事件
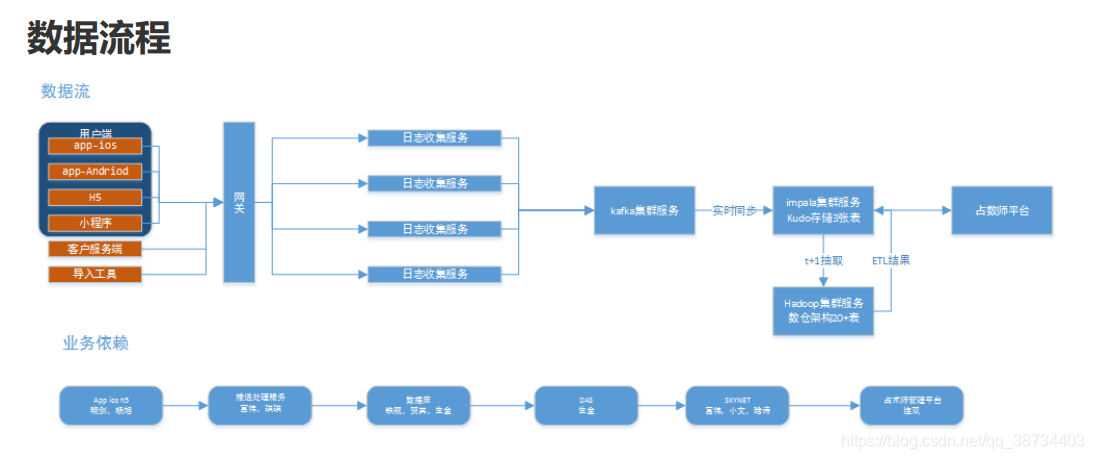
数据流程图:
2-元数据设计
1)需求
1> 元数据使用流程:

2> 元数据上下游关系
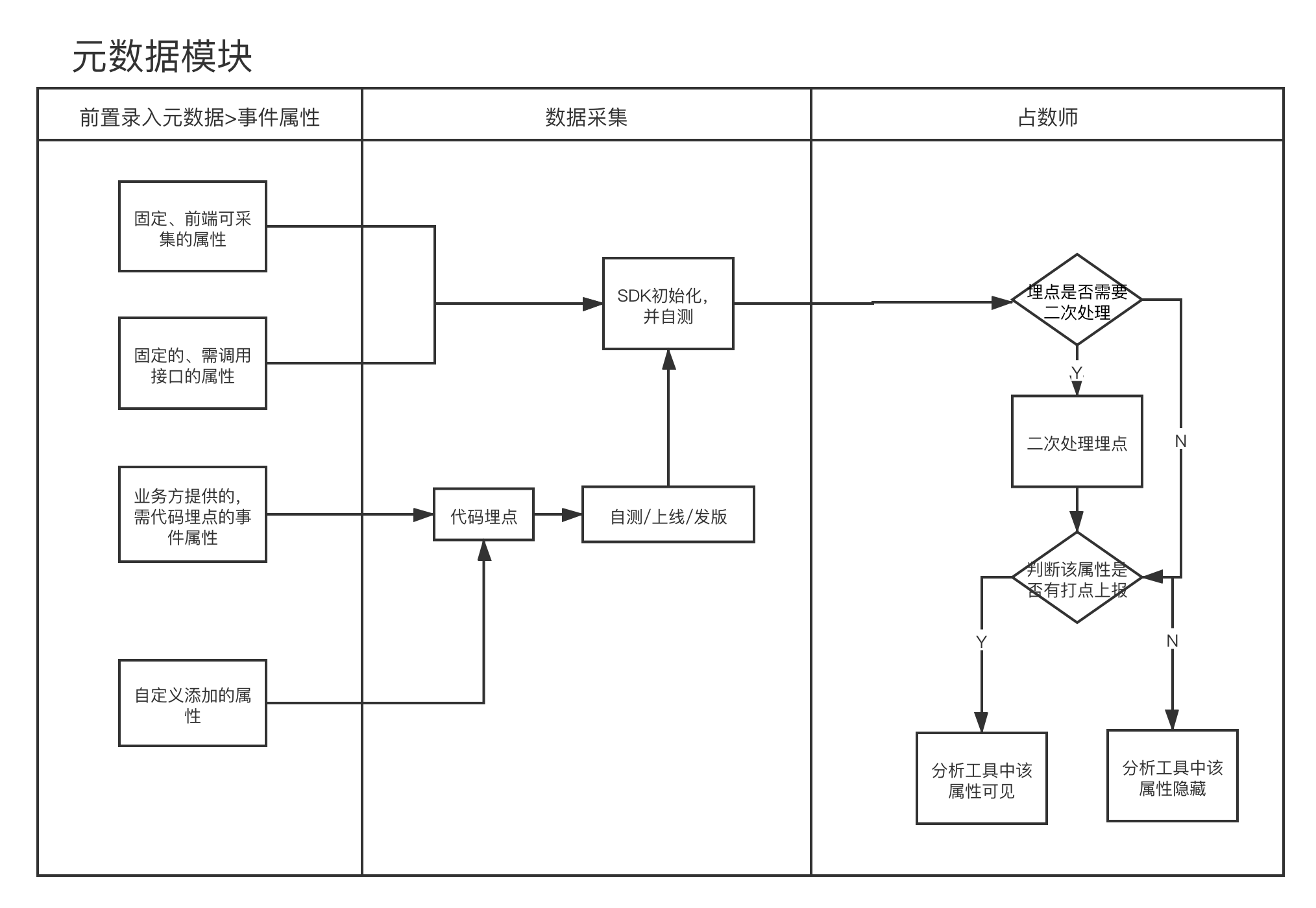
2)技术方案
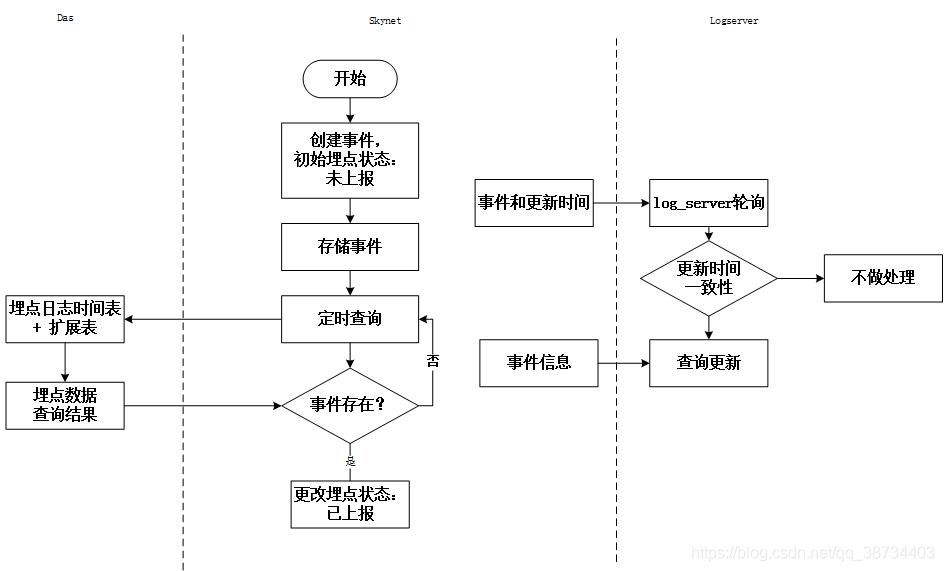
3)优化
使用zookeeper
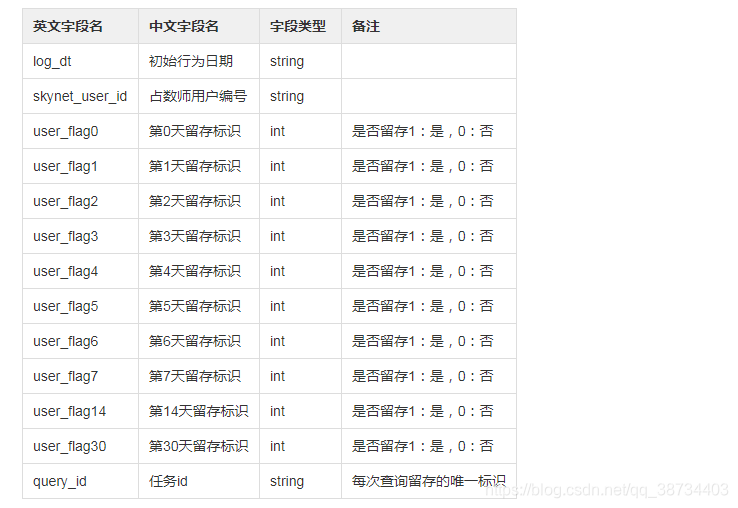
3-留存分析
留存分析需求
1)日留存中间表schema设计
a、log_dt,skynet_user_id 作为主键
b、表命名规则?krs.tmp_用户_时间戳?
外数
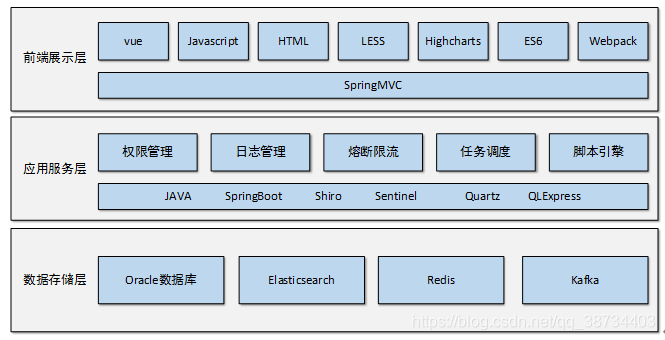
0-技术栈
前端:Vue + highChart
后端: Spring boot + MyBatis-Plus+ Quartz+ QLExpress + Shiro
数据库:Oracle
缓存+队列:Redis
监控+日志收集:Open-Falcon+Kibana
1-系统结构
功能
技术栈
数据流
调用
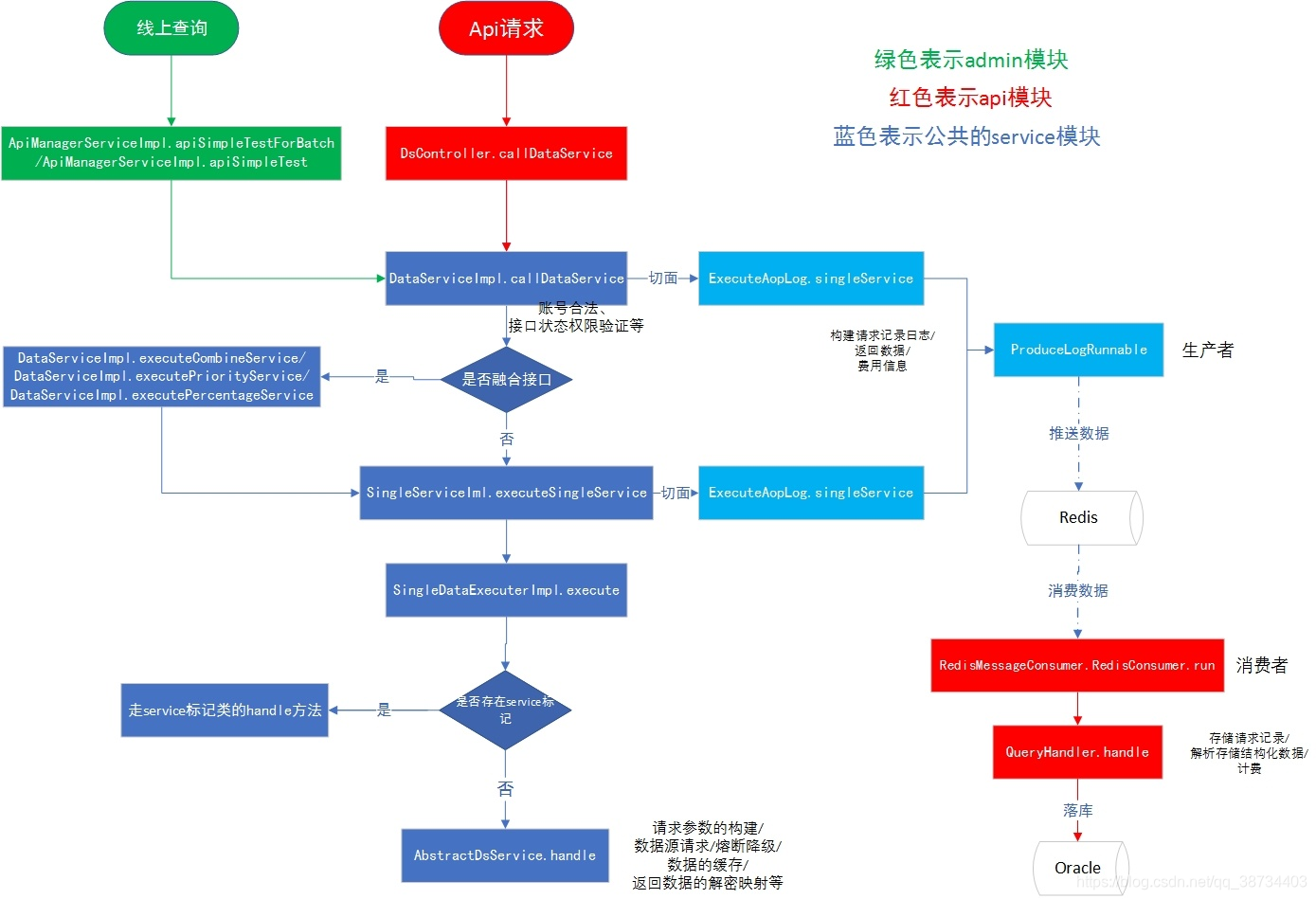
2-监控
- 监控

--用户配置监控后,按监控频率生成一个quartz定时任务,并保存监控配置到MonitorSetting表(MonitorSetting保存了监控频率,阈值,规则以及数据收集器)。quartz任务MonitorJob按crontab执行,获取数据收集器搜集数据,用搜集到的数据和MonitorSetting信息生成MonitorDataBean并offer到阻塞队列中。
--应用启动时,MonitorCommand中提交(默认两个)MonitorRunnable到线程池。MonitorRunnable循环poll阻塞队列中的MonitorDataBean,并根据MonitorDataBean的数据和报警规则判断是否触发报警。
时间戳
项目量级
- 20w数据
- 分表设计
Hbase
使用
// key = module_uniqName_subid_timestamp$rowkey = $data['model']."_".$data['md5'];//hbase2://co_protocol/protocol_timestamp_a4448a7f26968c0f66476c7527c2b946_1609810061453$rowkey = $data['model']."_".$data['md5']."_".intval(microtime(true)*1000);$column = array();$column['d:'.$data['model']] = $data['content'];$column['d:filetype'] = $data['filetype'];
rowkey(行主键) 列名 d:filetype 时间戳
- HBase表的存储结构模型,其中有4个字段。分别为Rowkey(主键)、Time Stamp(时间戳)、CF(列族)、CF:xx(列)。

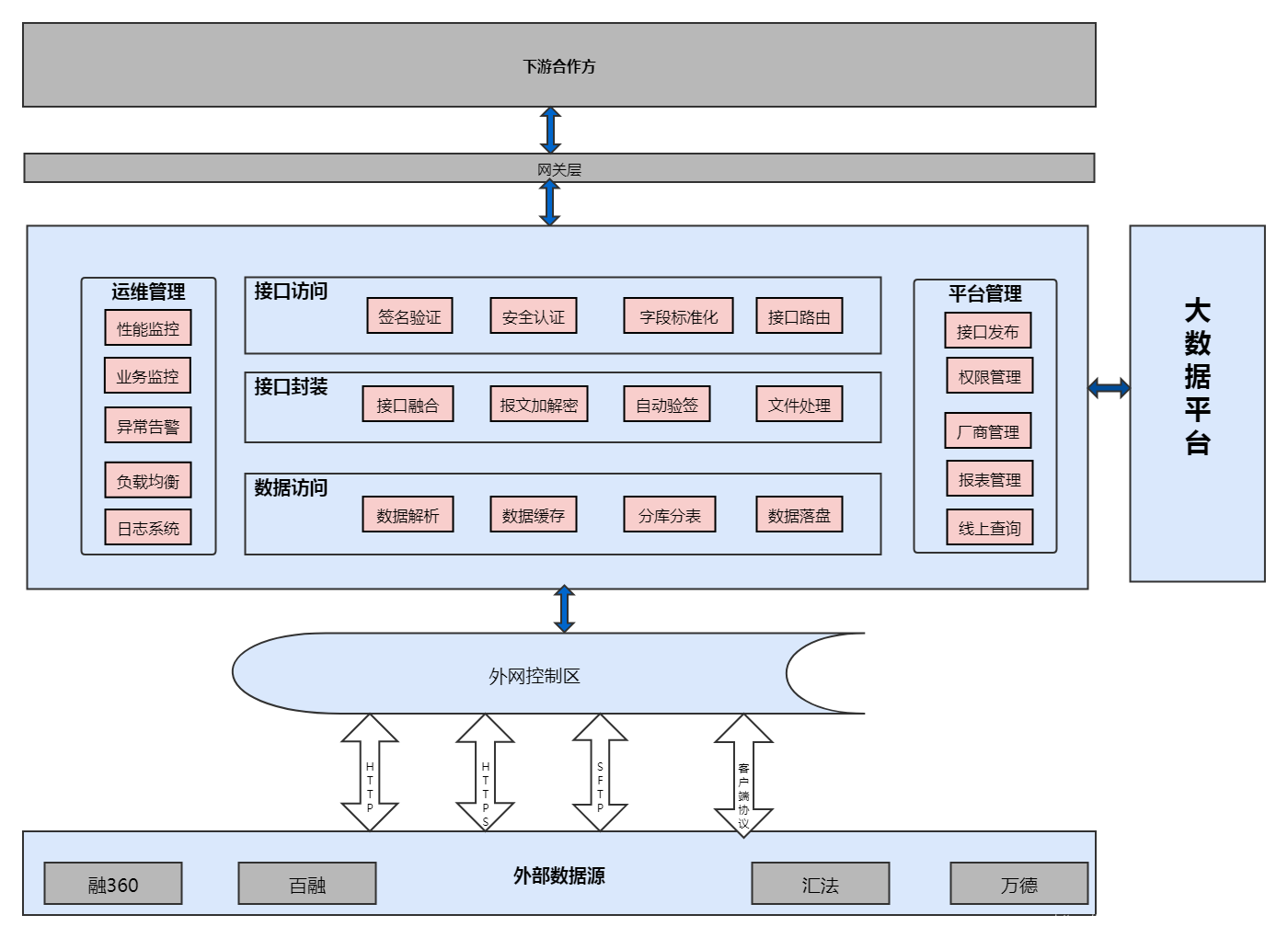
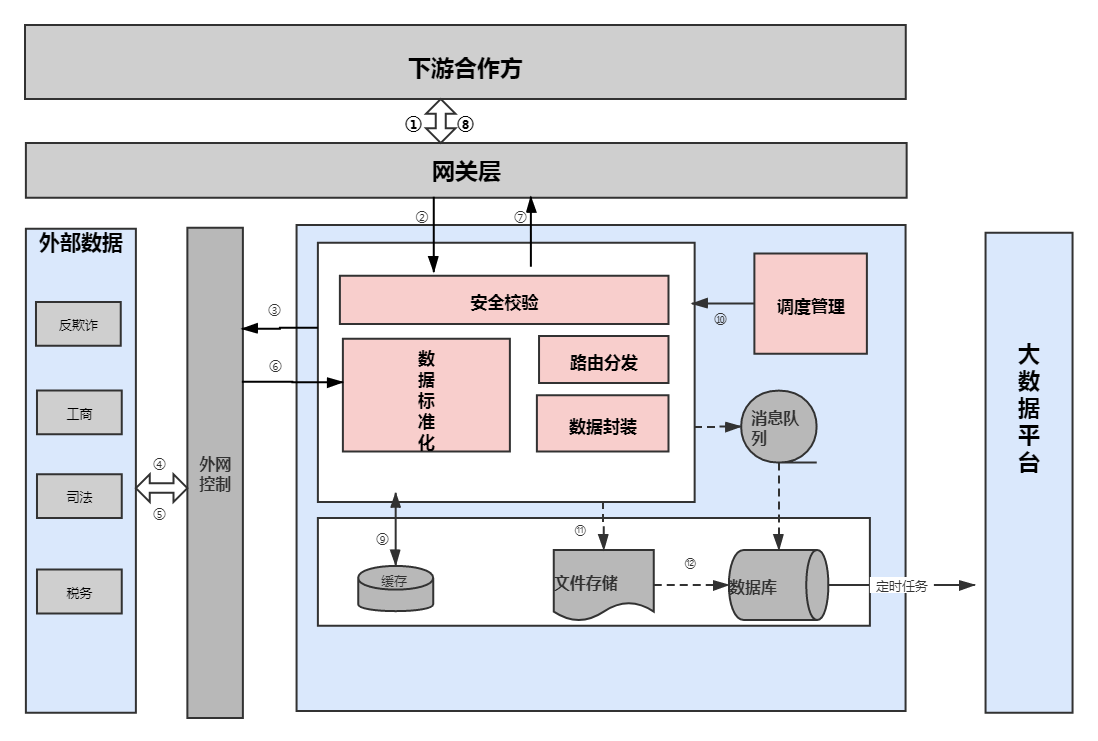
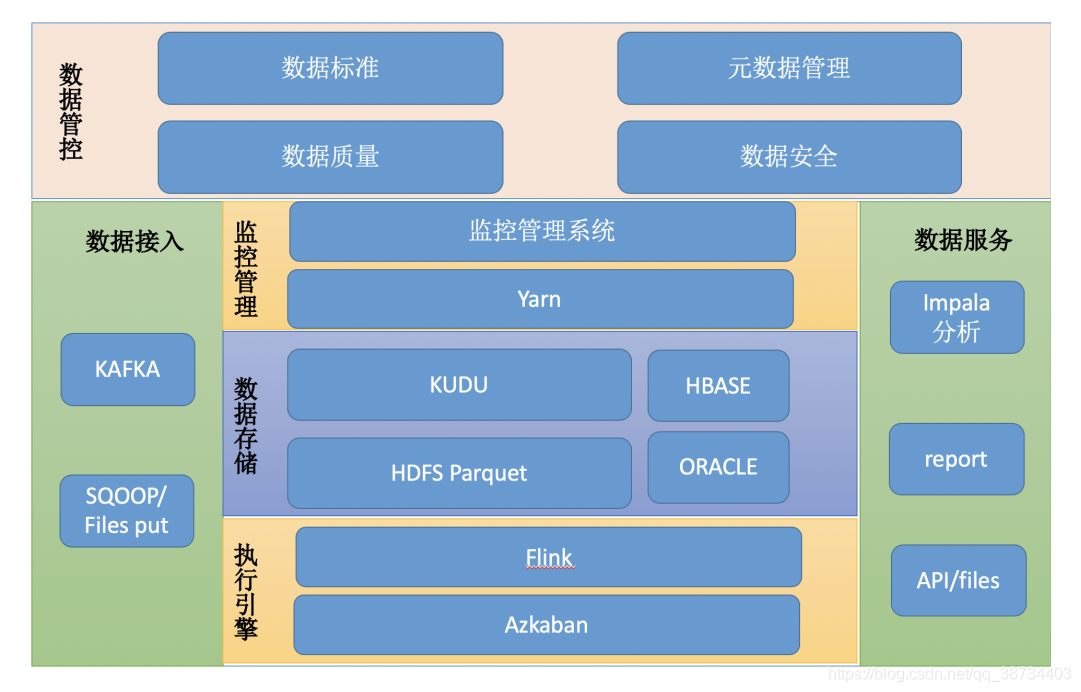
整体技术架构设计

大数据方向总体设计



外数:

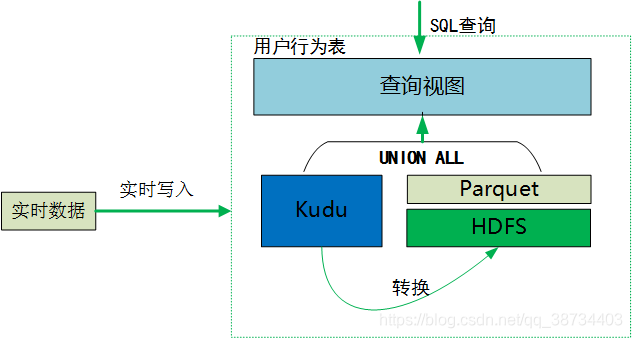
查询方式
kudu表当天分区增量和hive历史数据做union all 建成视图,供外提供查询: