@songhanshi
2021-02-25T09:00:08.000000Z
字数 216883
阅读 1176
编程
博客
◆
•
■
➽
■
▶
►
●
▻
☛
♥
✯
▍
Typora 编辑器
题: https://blog.csdn.net/zoucanfa/article/details/79559869
- 编程
- ※ 1Basis ※
- ※ 2-JVM(Java Virtual Machine)※
- ※ 3-并发编程 ※
- ※ 4-mysql
- ※ 5-Redis
- ※ 6-网络
- ※ 7-Linux|os
- ※ 8-mybatis
- ※ 9-Spring
- ※ 0-data structure
- ※ 项目 ※
- ※ 场景 ※
- xm
※ 1Basis ※
1-基础
Java特性,然后解释?
- ans:跨平台、面向对象、多线程、分布式、简单、安全、健壮、高性能
- 8大特性
1)跨平台/可移植性-
Java在设计时就很注重移植和跨平台性。
比如:Java的int永远都是32位。不像C++可能是16,32,可能是根据编译器厂商规定的变化。程序的移植就会非常麻烦。
3)面向对象
面向对象是一种程序设计技术,非常适合大型软件的设计和开发。由于C++为了照顾大量C语言使用者而兼容了C,使得自身仅仅成为了带类的C语言,多少影响了其面向对象的彻底性!
Java则是完全的面向对象语言。
7)多线程
多线程的使用可以带来更好的交互响应和实时行为。 Java多线程的简单性是Java成为主流服务器端开发语言的主要原因之一。
6)分布式
Java是为Internet的分布式环境设计的,因为它能够处理TCP/IP协议。事实上,通过URL访问一个网络资源和访问本地文件是一样简单的。Java还支持远程方法调用(RMI,Remote Method Invocation),
使程序能够通过网络调用方法。
4)简单性
Java就是C++语法的简化版,我们也可以将Java称之为“C++-”。跟我念“C加加减”,指的就是将C++的一些内容去掉;比如:头文件,指针运算,结构,联合,操作符重载,虚基类等等。
同时,由于语法基于C语言,因此学习起来完全不费力。
2)安全性
Java适合于网络/分布式环境,为了达到这个目标,在安全性方面投入了很大的精力,使Java可以很容易构建防病毒,防篡改的系统。
8)健壮性
Java是一种健壮的语言,吸收了C/C++语言的优点,但去掉了其影响程序健壮性的部分(如:指针、内存的申请与释放等)。Java程序不可能造成计算机崩溃。即使Java程序也可能有错误。
如果出现某种出乎意料之事,程序也不会崩溃,而是把该异常抛出,再通过异常处理机制加以处理。
5)高性能
Java最初发展阶段,总是被人诟病“性能低”;客观上,高级语言运行效率总是低于低级语言的,这个无法避免。Java语言本身发展中通过虚拟机的优化提升了几十倍运行效率。
比如,通过JIT(JUST IN TIME)即时编译技术提高运行效率。 将一些“热点”字节码编译成本地机器码,并将结果缓存起来,在需要的时候重新调用。这样的话,使Java程序的执行效率大大提高,
某些代码甚至接待C++的效率。因此,Java低性能的短腿,已经被完全解决了。业界发展上,我们也看到很多C++应用转到Java开发,很多C++程序员转型为Java程序员。
参考:https://zhuanlan.zhihu.com/p/61995019
面向对象的理解? 什么是面向对象?/面向对象概念的理解?/面向对象三大特性? |3
- ans:封装、多态、继承
- 理解:对现实世界万物的抽象建模。
任何物体具有相同属性和行为特征的对象都可以归类,任何个体对象又是类的实例。 - 核心思想:封装、继承和多态。
- 封装。是将一类事物的属性和行为抽象成一个类,使代码模块化。
- 继承。基于已有的类的定义为基础,构建新的类,已有的类称为父类,新构建的类称为子类,子类能调用父类的非private修饰的成员,同时还可以自己添加一些新的成员,扩充父类,甚至重写父类已有的方法,更其表现符合子类的特征。
- 多态。方法的重写、重载与动态连接构成多态性。
面向对象好处,体现在哪?
- 易维护、质量高、效率高、易扩展
-- 将对象进行分类,分别封装它们的数据和可以调用的方法,方便了函数、变量、数据的管理,方便方法的调用(减少重复参数等),尤其是在编写大型程序时更有帮助。
-- 用面向对象的编程可以把变量当成对象进行操作,让编程思路更加清晰简洁,而且减少了很多冗余变量的出现 - 好处
- 易维护、质量高、效率高、易扩展
多态是什么?怎样实现多态?
- 多态:多态是同一个行为具有多个不同表现形式的能力。
如,按下 F1 键,不同的软件界面,出现不同的功能 - 实现:重写、接口、抽象类和抽象方法
https://www.runoob.com/java/java-polymorphism.html
- 多态:多态是同一个行为具有多个不同表现形式的能力。
重写和重载的区别 |2
- 重写(Overriding)是子类对父类的允许访问的方法的实现过程进行重新编写, 返回值和形参都不能改变。参数列表和返回类型都不可修改。
- 重载(overloading)是在一个类里面,方法名字相同,而参数不同。返回类型可以相同也可以不同。
- 重写重载是java多态性的不同表现,重写是父类与子类之间多态性的一种表现,重载是一类中多态性的一种表现。
JDK 各个版本的特性?
8-12: https://www.cnblogs.com/junrong624/p/11596191.html
5-10: https://blog.csdn.net/pursue_vip/article/details/78692584jdk1.8新特性?
https://www.runoob.com/java/java8-new-features.html- Lambda表达式
- 函数式接口
- 方法引用和构造器调用
- Stream API
- 接口可以添加默认方法和静态方法,也就是定义不需要实现类实现的方法
- 新的时间日期(Date/Time)相关的API
- 重复注解,同一个注解可以使用多次
- 引入Optional来避免空指针
- 新增jdeps命令行,来分析类、目录、jar包的类依赖层级关系
- JVM使用MetaSpace代替了永久代(PermGen Space)
https://www.cnblogs.com/junrong624/p/11596191.html
Lambda表达式?
stream api?
计算日期差?
- 总:https://blog.csdn.net/sy793314598/article/details/79544796
- J8:https://blog.csdn.net/hspingcc/article/details/73332526
1)Period
2)Duration
3)ChronoUnit
Java编译和执行的缺点?
- 优点
编译执行是指把代码先编译成机器码。编译后的机器码具有平台相关性,运行速度快。 - 缺点
编译的过程(检查词法,语法代码优化,生成可执行文件)需要花费时间。
编译后按顺序运行,如果编译中有任何异常,都无法继续运行。
- 优点
抽象类和接口的区别? |3
- 抽象类:
• abstract修饰;
• 抽象类不能实例化,即不能使用new关键字来实例化对象;
• 含有抽象方法(使用abstract关键字修饰的方法)的类是抽象类,必须使用abstract关键字修饰;
• 抽象类可以含有抽象方法,也可以不包含抽象方法,抽象类中可以有具体的方法;
• 如果一个子类实现了父类(抽象类)的所有抽象方法,那么该子类可以不必是抽象类,否则就是抽象类;
• 抽象类中的抽象方法只有方法体声明,没有具体实现; - 接口:
• interface修饰;
• 接口不能被实例化;
• 一个类只能继承一个类,但是可以实现多个接口;
• 接口中方法均为抽象方法;
• 接口中不能包含实例域或静态方法(静态方法必须实现,接口中方法是抽象方法,不能实现)
https://blog.csdn.net/qq_38734403/article/details/105712449
- 抽象类:
类和接口区别?
1)接口里所有的属性和方法都只能是静态的和public的
2)接口中的方法不能有方法体
3)接口不属能实例化对象
4)接口只能用implements实现,而不能用extends继承,但是接口继承接口时要用extends
5)一个类可以实现多个接口,只能继承一个类
6)实现接口的类必须要实现接口中的方法,但继承类可以不重写父类中的方法
7)接口的关键字是interface,类是class空间复杂度,时间复杂度?
- 时间复杂度:算法执行语句的次数。
- 空间复杂度:是对一个算法在运行过程中临时占用存储空间的度量
写出查找网页中所有图片地址的正则表达式
异常怎么用的,项目里哪些地方用到了异常,有没有用过ExceptionResover
- 异常:是程序运行过程中发生的事件,该事件可以中断程序指令的正常执行流程。
- 常见:空指针异常、下标越界异常等
https://blog.csdn.net/woshi2512901978/article/details/8515464
exception的根类是哪个类?1/0是哪类异常?
- 异常分成两种,Error和Exception。所有Exception的父类都是java.lang.Throwable。
http://wenda.tianya.cn/question/15976cc8f0b695f6 - 1/0异常:ArithmeticException: / by zero
- 异常分成两种,Error和Exception。所有Exception的父类都是java.lang.Throwable。
栈和队列的区别?
1)栈和队列- 栈是先进后出,队列是先进先出。
- 插入和删除操作:栈在一端,队列在两端。
- 栈只允许在表尾一端进行插入和删除,
队列只允许在表尾一端进行插入,在表头一端进行删除。
链表和数组的优缺点及适用场景?
1)特点- 数组:在内存中是一块连续的区域。
- 链表:在内存中可以存在任何地方,不要求连续。
2)优缺点
- 数组:优点:随机访问性强;查找速度快。
缺点:插入和删除效率低;内存空间要求高,必须有足够的连续内存空间;数组大小固定,不能动态拓展 - 链表:优:插入删除速度快;内存利用率高;大小没有固定,拓展很灵活。
缺:不能随机查找,必须从第一个开始遍历,查找效率低
3)区别:
- 链表适合插入删除,数组适合查询
深拷贝和浅拷贝,举例说明
1)浅拷贝:- 属性是基本类型,拷贝的就是基本类型的值;
- 属性是引用类型(内存地址),拷贝的就是内存地址,因此如果其中一个对象改变了这个地址,就会影响到另一个对象。
2)深拷贝:clone
- 会拷贝所有的属性,并拷贝属性指向的动态分配的内存。当对象和它所引用的对象一起拷贝时即发生深拷贝。深拷贝相比于浅拷贝速度较慢并且花销较大。
泛型
反射了解吗,JDK 中具体哪里用了,优点及缺点
https://blog.csdn.net/huangliniqng/article/details/88554510
2-设计模式
大纲
|单例模式|工厂模式|生产者消费者|||||设计模式?
① 单例模式。
② 工厂模式。
③ 生产者消费者写出你熟悉的三种设计模式及UML图
UML图画法:https://blog.csdn.net/js_tengzi/article/details/90143246
设计模式UML:https://www.cnblogs.com/ningskyer/articles/3615312.html- 单例模式:https://blog.csdn.net/It_sharp/article/details/82147111
- 工厂模式:
- 消费者生产者模式:
单例几种实现
- 5种实现方式:饿汉、懒汉、双重校验锁、静态内部类和枚举
- 单例代码
https://blog.csdn.net/qq_38734403/article/details/106976266
单例模式的线程安全问题
- 设计模式,具体问了单例的 DCL(双重检查锁定DCL(double-checked locking) )
- 单例模式都有什么,都是否线程安全,可以怎么改进?(从synchronized到双重检验锁到枚举 Enum)
- 单例模式,然后面试官问指令重排。
设计模式用过哪些?写一个单例吧
模板模式
简单工厂 问题:依赖关系的解除,一个是if else。
3-JDK源码解析
1-Object
|object源码解析 |
Object类都有哪些方法? |2
- 1)clone方法
保护方法,实现对象的浅复制,只有实现了Cloneable接口才可以调用该方法,否则抛出CloneNotSupportedException异常。
主要是JAVA里除了8种基本类型传参数是值传递,其他的类对象传参数都是引用传递,有时候不希望在方法里讲参数改变,这是就需要在类中复写clone方法。 - 2)getClass方法
final方法,获得运行时类型。 - 3)toString方法
该方法用得比较多,一般子类都有覆盖。 - 4)finalize方法
该方法用于释放资源。因为无法确定该方法什么时候被调用,很少使用。 - 5)equals方法
该方法是非常重要的一个方法。一般equals和==是不一样的,但是在Object中两者是一样的。子类一般都要重写这个方法。 - 6)hashCode方法
该方法用于哈希查找,可以减少在查找中使用equals的次数,重写了equals方法一般都要重写hashCode方法。这个方法在一些具有哈希功能的Collection中用到。
一般必须满足obj1.equals(obj2)==true。可以推出obj1.hash-Code()==obj2.hashCode(),但是hashCode相等不一定就满足equals。不过为了提高效率,应该尽量使上面两个条件接近等价。
如果不重写hashcode(),在HashSet中添加两个equals的对象,会将两个对象都加入进去。 - 7)wait方法
wait方法就是使当前线程等待该对象的锁,当前线程必须是该对象的拥有者,也就是具有该对象的锁。wait()方法一直等待,直到获得锁或者被中断。wait(long timeout)设定一个超时间隔,如果在规定时间内没有获得锁就返回。
调用该方法后当前线程进入睡眠状态,直到以下事件发生。
① 其他线程调用了该对象的notify方法。
② 其他线程调用了该对象的notifyAll方法。
③ 其他线程调用了interrupt中断该线程。
④ 时间间隔到了。
此时该线程就可以被调度了,如果是被中断的话就抛出一个InterruptedException异常。 - 8)notify方法
该方法唤醒在该对象上等待的某个线程。 - 9)notifyAll方法
该方法唤醒在该对象上等待的所有线程。
https://www.cnblogs.com/wxywxy/p/6740277.html
- 1)clone方法
介绍下hashcode和euqals。 |3
== 与 equals的区别 |2
你重写过hashcode和equals么,要注意什么
注意:https://blog.csdn.net/Mountain_YS/article/details/82151451equals和==的区别,两个String之间判别,两个Integer之间判别?[note][3]
1)String引用型数据类型字符串比较之中“==”和equals()的区别:- ==:比较的是两个字符串内存地址(堆内存)的数值是否相等,属于数值比较;
- equals():比较的是两个字符串的内容(地址值),属于内容比较
- 基本类型通过==比较的是他们的值大小,而引用类型比较的是他们的引用地址
String s1 = “Hello”;String s2 = “Hello”;String s3 = new String(“hello”);String s4 = s3; //引用传递s1 == s2 //trues1 == s3 //falses1 == s4 //falses3 == s4 //trues1.equals(s3) //trues1.equals(s4) //trues3.equals(s4) //true
2-引用类型
|基础源码解析|
1-基本类型
Java的基本数据类型? |2
- 8种类型
1)四种整数类型(byte、short、int、long)
2)两种浮点数类型(float、double)
3)一种字符类型(char)
4)一种布尔类型(boolean) - 类型转换:
自动转换:byte-->short-->int-->long-->float-->double - 强制转换:①会损失精度,产生误差,小数点以后的数字全部舍弃。②容易超过取值范围。
- 记忆:
8位:Byte(字节型) 16位:short(短整型)、char(字符型) 32位:int(整型)、float(单精度型/浮点型)
64位:long(长整型)、double(双精度型)
boolean(布尔类型
https://blog.csdn.net/pcwl1206/article/details/80766174 - 8中基本数据类型的包装类除了Character和Boolean没有继承该类外,剩下的都继承了 Number 类,该类的方法用于各种数据类型的转换。
- 8种类型
汉字占几个char,int和long分别是多少位
- 汉字
UTF-8编码长度:3、GBK编码长度:2、GB2312编码长度:2
https://www.cnblogs.com/xhlwjy/p/11398606.html - int和long
byte:2个字节 16位
char:2个字节 16位
short :2个字节 16位
int :4个字节 32位
long:8个字节 64位
float:4个字节 32 位
double :8个字节 64位
https://www.cnblogs.com/150643com/p/10273377.html
- 汉字
int的默认值?
- byte,short,int类型的默认值为0
- float,double默认值为0.0
- char等价于short其默认值也为0
- boolean的默认值为false。
- java中基本类型的默认值是0,引用类型会默认为null。
https://www.cnblogs.com/hawk-li/p/10755182.html
int和Integer的区别
3-Integer
|Integer的源码解析|[浅谈In]|
为什么在接口设计的时候推荐使用包装类型而不推荐使用基本数据类型?
- 传递基本类型:出方法外,参数还是原值
如,参数2个int值 a,b交换数值,是在函数里面他们值是交换的,但是出了函数,还是原来各自的值。
因为对于基本类型,java是把值传进去了,比如原来的a是某个元素的属性,比如是5,只是把5这个数复制一份传过去了,这5只是个数字,并不指向a的属性,你的改动是不会影响到a的属性的对非基本类型,在函数里的更改可以影响外面是因为直接把那个对象传进去了,改的是那个对象 - 其他:
1)Java是一个面向对象的语言,然而基本数据类型不具备面向对象的属性。当我们把基本数据类型包装成包装类型后,基本数据类型就具备了面向对象的属性。
-- 在ArrayList 、HashMap这些容器来传输数据是,基本类型int和double是传输不进去的,因为容器都是装泛型(object类型)的,所以需要转为包装类型进行传输。
-- 每一个基本类型都有对应的包装类型
2)Integer包装数据类型中缓存了最大值和最小值
对于自动装箱的int数据类型,会存在在方法区的缓冲区中保留,再次使用的时候直接引用。这里使用的是通过空间换时间的策略,减少了对象创建的过程,因此,如果是数值相同的Integer类型,地址也相同,代码演示。而new出来的对象,实际的存在于堆中,地址不相同。
- 传递基本类型:出方法外,参数还是原值
Integer(1)数据都存在哪儿?
- 基本数据类型和引用数据类型的区别主要在存储方式上:
• 基本数据类型在被创建时,在栈上给其划分一块内存,将数值直接存储在栈上;
• 引用数据类型在被创建时,首先要在栈上给其引用(句柄)分配一块内存,而对象的具体信息都存储在堆内存上,然后由栈上面的引用指向堆中对象的地址。 - new integer是创建一个对象 ,对象存在虚拟机堆中;
- integer a =1,常量池中,即在方法区中。
https://zhidao.baidu.com/question/1388492174848317980.html
- 基本数据类型和引用数据类型的区别主要在存储方式上:
Integer类型的变量能否==int类型变量,能否作比较,什么时候不能作比较。
Integer a =new Integer(7);Integer b=7; a==b
谁实现int装包的,是List吗不是list
- 自动装箱时编译器调用valueOf将原始类型值转换成对象
- 自动拆箱时,编译器通过调用类似intValue(),doubleValue()这类xxxValue()的方法将对象转换成原始类型值。
- 缓存策略:如果i值在-128和127之间则直接从IntegerCache.cache缓存中获取指定数字的包装类;不存在则new出一个新的包装类。除double和float的自动装箱外。原因:缓存的这些对象都是经常使用到的(如字符、-128至127之间的数字),防止每次自动装箱都创建一此对象的实例。
源码:https://www.jb51.net/article/111847.htm
拆装箱
- 把Integer类型赋值给int类型。此时,int类型变量的值会自动装箱成Integer类型,然后赋给Integer类型的引用,这里底层就是通过调用valueOf()这个方法来实现所谓的装箱的。
- 把int类型赋值给Integer类型。此时,Integer类型变量的值会自动拆箱成int类型,然后赋给int类型的变量,这里底层则是通过调用intValue()方法来实现所谓的拆箱的。
包装类型和基本类型的比较问题。
- 整型包装类的值一定要使用 equals 方法进行判断
- 浮点数的对比:1)指定一个误差范围或2)使用 BigDecimal 来定义值,再进行浮点数的运算操作
https://www.cnblogs.com/angryprogrammer/p/11934415.html
https://blog.csdn.net/czr11616/article/details/88188651
3-String
1.string,stringbuilder,stringbuffer的区别
String不可变的原因 |2
- String类被final修饰,表示不可被继承。
- String的成员变量char[] value被final修饰,初始化后不可更改引用。
- String的成员变量value访问修饰符为private,不对外界提供修改value数组值的方法。
为什么String用char数组存储?
- 看原理
3-集合概况
|基础源码解析|
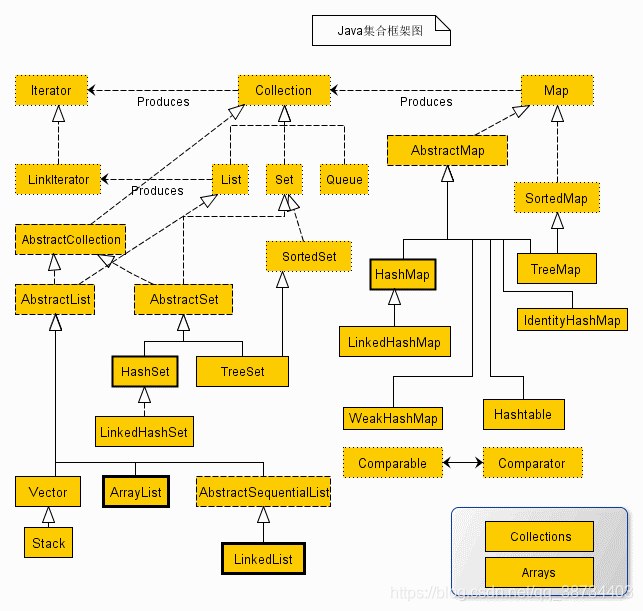
集合框架概述? /集合架构/集合体系
- 参考
- Java 集合框架主要包括2种类型的容器:
① 集合(Collection):存储一个元素集合;
② 图(Map):存储键/值对映射。
Collection 接口又有 3种子类型,List、Set和Queue,再下面是一些抽象类,最后是具体实现类,常用的有 ArrayList、LinkedList、HashSet、LinkedHashSet、HashMap、LinkedHashMap 等等。
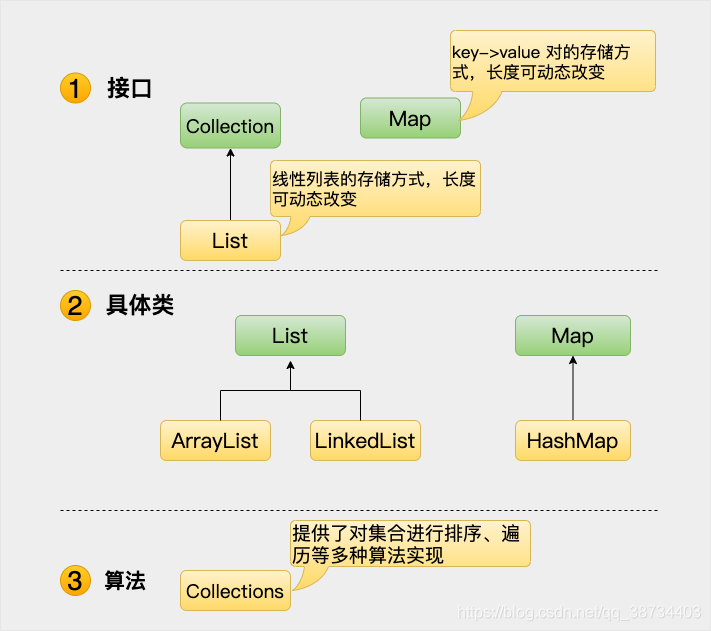
- 集合框架内容包含:
集合框架是一个用来代表和操纵集合的统一架构。所有的集合框架都包含如下内容:
• 接口:是代表集合的抽象数据类型。
例如Collection、List、Set、Map等。之所以定义多个接口,是为了以不同的方式操作集合对象
• 实现(类):是集合接口的具体实现。从本质上讲,它们是可重复使用的数据结构,例如:ArrayList、LinkedList、HashSet、HashMap。
• 算法:是实现集合接口的对象里的方法执行的一些有用的计算,例如:搜索和排序。这些算法被称为多态,那是因为相同的方法可以在相似的接口上有着不同的实现。 - 除了集合,该框架也定义了几个Map接口和类。Map 里存储的是键/值对。尽管Map不是集合,但是它们完全整合在集合中。
- java集合框架位于java.util包中,所以当使用集合框架的时候需要进行导包。
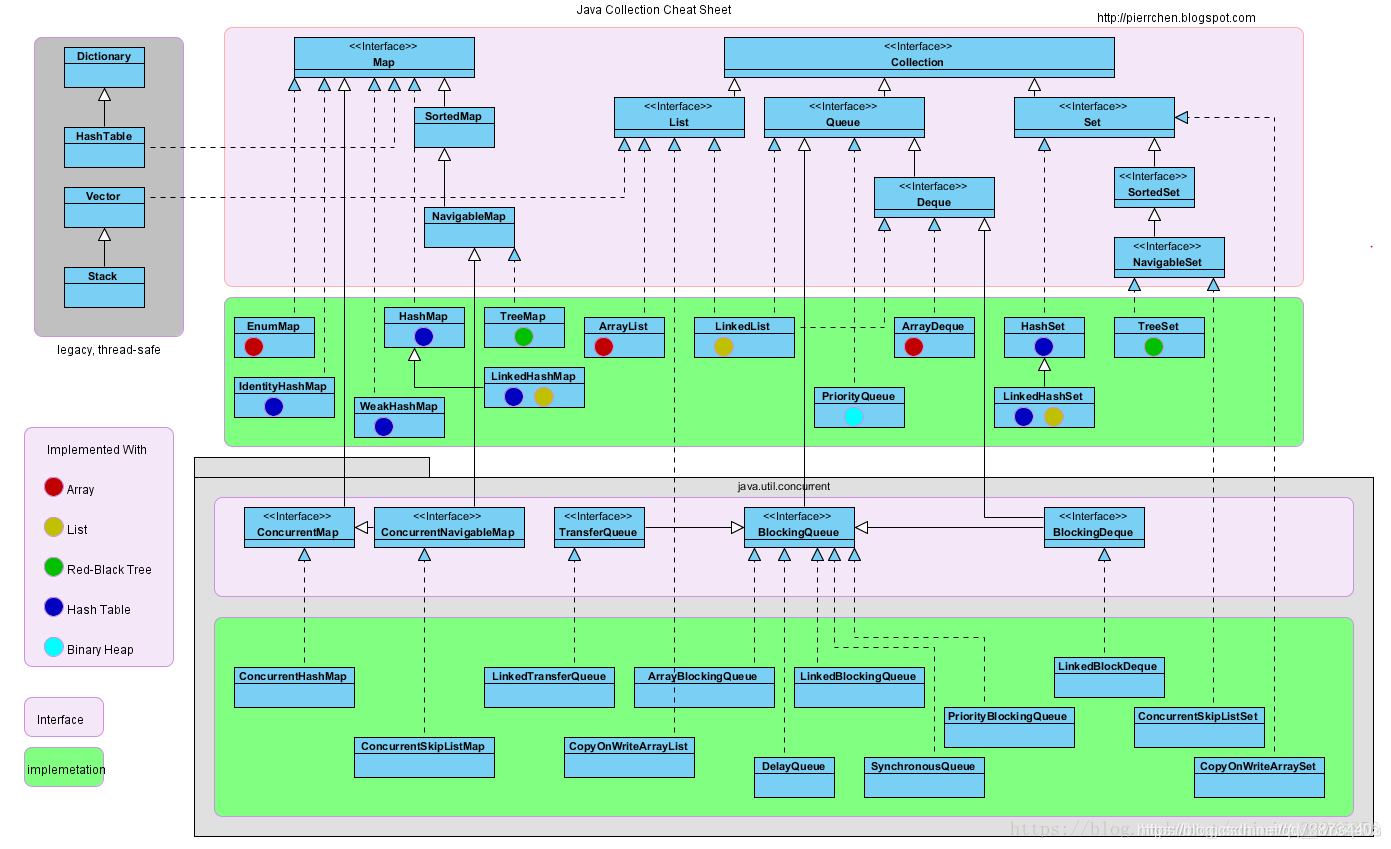
了解哪些List,哪些Map?
接口 实现类 List ArrayList、LinkedList Set HashSet、TreeSet、LinkedHashSet Map HashMap、TreeMap、LinkedHashMap 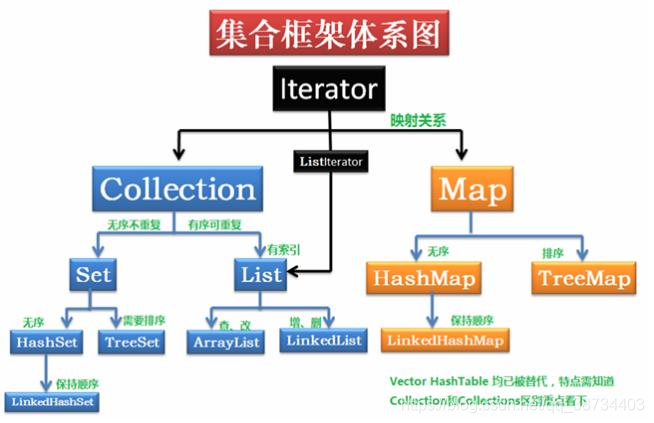
集合类介绍?
- List 不唯一,有序
- Set 唯一,无序
- Map 键值对,key到value的映射
- Key 唯一 无序
- value 不唯一 无序
你知道的集合,哪些是线程安全的?
- 线程安全的集合:
Vector | HashTable | StringBuffer - 非线程安全的:
ArrayList|LinkedList|HashMap|HashSet|TreeMap|TreeSet|StringBulider
- 线程安全的集合:
1-List
|1.8Arrays源码||1.8LinkedList源码|
list集合下有哪些?

Arraylist 与 LinkedList 区别? |7
- 1> 是否保证线程安全:ArrayList和LinkedList都是不同步的,也就是不保证线程安全;
- 2> 底层数据结构: Arraylist 底层使用的是 Object[]数组;LinkedList底层使用的是 双向链表数据结构(JDK1.6 之前为循环链表,JDK1.7 取消了循环。注意双向链表和双向循环链表的区别,下面有介绍到!)
- 3> 插入和删除是否受元素位置的影响: ①ArrayList采用数组存储,所以插入和删除元素的时间复杂度受元素位置的影响。 比如:执行add(E e)方法的时候,ArrayList会默认在将指定的元素追加到此列表的末尾,这种情况时间复杂度就是O(1)。但是如果要在指定位置i插入和删除元素的话(add(int index, E element))时间复杂度就为 O(n-i)。因为在进行上述操作的时候集合中第 i 和第 i 个元素之后的(n-i)个元素都要执行向后位/向前移一位的操作。
②LinkedList 采用链表存储,所以对于add(E e)方法的插入,删除元素时间复杂度不受元素位置的影响,近似 O(1),如果是要在指定位置i插入和删除元素的话((add(int index, E element)) 时间复杂度近似为o(n))因为需要先移动到指定位置再插入。 - 4> 是否支持快速随机访问: LinkedList 不支持高效的随机元素访问,而 ArrayList 支持。快速随机访问就是通过元素的序号快速获取元素对象(对应于get(int index)方法)。
- 5> 内存空间占用: ArrayList 的空 间浪费主要体现在在 list 列表的结尾会预留一定的容量空间,而 LinkedList 的空间花费则体现在它的每一个元素都需要消耗比 ArrayList 更多的空间(因为要存放直接后继和直接前驱以及数据)。
ArrayList
ArrayList源码实现? |2
- ArrayList 是一个用数组实现的集合,支持随机访问,元素有序且可以重复。
public class ArrayList<E> extends AbstractList<E>implements List<E>, RandomAccess, Cloneable, java.io.Serializable

- 实现
①、实现 RandomAccess 接口
②、实现 Cloneable 接口
③、实现 Serializable 接口
④、实现 List 接口
这个接口是 List类集合的上层接口,定义了实现该接口的类都必须要实现的一组方法,如下所示,下面我们会对这一系列方法的实现做详细介绍。

字段属性
//集合的默认大小private static final int DEFAULT_CAPACITY = 10;//空的数组实例private static final Object[] EMPTY_ELEMENTDATA = {};//这也是一个空的数组实例,和EMPTY_ELEMENTDATA空数组相比是用于了解添加元素时数组膨胀多少private static final Object[] DEFAULTCAPACITY_EMPTY_ELEMENTDATA = {};//存储 ArrayList集合的元素,集合的长度即这个数组的长度//1、当 elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA 时将会清空 ArrayList//2、当添加第一个元素时,elementData 长度会扩展为 DEFAULT_CAPACITY=10transient Object[] elementData;//表示集合的长度private int size;
构造函数
public ArrayList(){}public ArrayList(int initialCapacity){}
- ArrayList 是一个用数组实现的集合,支持随机访问,元素有序且可以重复。
新建一个ArrayList会分配内存吗?
- 新建ArrayList的时候,JVM为其分配一个默认或指定大小的连续内存区域(封装为数组)
ArrayList数据结构?
ArrayList 的底层是数组队列,相当于动态数组。与Java中的数组相比,它的容量能动态增长。内存够用情况下ArrayList插入10w条数据?优化?
- 插入
扩容
ArrayList扩容的时机
- 随着不断添加元素,数组大小增加,当数组的大小大于初始容量的时候(比如初始为10,当添加第11个元素的时候),就会进行扩容,新的容量为旧的容量的1.5倍。扩容规则:((旧容量 * 3) / 2) + 1
- 扩容方式
扩容的时候,会以新的容量建一个原数组的拷贝,修改原数组,指向这个新数组,原数组被抛弃,会被GC回收。
ArrayList底层,依次删除List中的所有元素应该怎么删除?
循环中的剔除掉Arraylist中的元素安全吗?
ArrayList什么时候缩容trimToSize()
- 如果需要存储的数量刚好达到扩容而又没有更多的数据需要存储,剩下的空间岂不浪费掉了?
类似场景:系统启动,初始化一些数据到ArrayList中缓存起来,这些数据比较多(几千个元素)但是根据业务场景是不会变的。那么我想是不是也会出现如上空间浪费的问题呢? - java.util.ArrayList.trimToSize()方法修整此ArrayList实例的是列表的当前大小的容量。
- 调用Arrays.copyOf将容量减少到和元素数量一样大。
Arrays.copyOf(elementData, size);
https://blog.csdn.net/zhang_zhenwei/article/details/90717884
- 如果需要存储的数量刚好达到扩容而又没有更多的数据需要存储,剩下的空间岂不浪费掉了?
7.arraylist是线程安全的吗?如何实现线程安全
- 什么时候用ArrayList或者List
LinkedList
linkedlist是单向的还是双向的,为什么这么设计
LinkedList底层,依次删除List中的所有元素应该怎么删除?
Linkedlist 数据结构 扩容
LinkedList插入int如何实现
- 装箱~~
linkedlist的介绍
- LinkedList是一个继承于AbstractSequentialList的双向链表。也可以被当作堆栈、队列或双端队列进行操作。
LinkedList 实现 List 接口,能进行队列操作。
Queue<String> queue = new LinkedList<>();
LinkedList 实现 Deque接口,即能将LinkedList当作双端队列使用。
Deque<String> deque = new LinkedList<>();
ArrayList底层是由数组支持,而LinkedList 是由双向链表实现的,其中的每个对象包含数据的同时还包含指向链表中前一个与后一个元素的引用。
https://www.cnblogs.com/msymm/p/9872912.html
代码题:List转化为Map
/*** 用于把List<Object>转换成Map<String,Object>形式,便于存入缓存* @param keyName 主键属性* @param list 集合* @return 返回对象*/private <T> Map<String, T> listToMap(String keyName, List<T> list){Map<String, T> map = new HashMap<String, T>();try {for (T l : list) {PropertyDescriptor pd = new PropertyDescriptor(keyName, l.getClass());Method method = pd.getReadMethod();// 获得get方法Object obj = method.invoke(l);// 执行get方法返回一个Objectmap.put(obj.toString(), l);}return map;} catch (Exception e) {System.out.println("Convert List to Map failed");e.printStackTrace();}return null;}
2-Map
Map的内部实现
- Map只是一个接口,并没有实现,具体的实现由HashMap、HashTable
map了解吗,说说hashmap,hashtable,treemap?
HashMap
|HashMap1.8源码解析|源码1|ms经验|源码解析2|
HashMap源码/底层实现? |4
HashMap实现原理
- 遇到冲突时,HashMap是采用的链地址法来解决;
- JDK1.6、JDK1.7
采用位桶数组+链表实现,数组是HashMap的主体,链表则是主要为了解决哈希冲突而存在的(“拉链法”解决冲突). - JDK1.8
采用位桶数组+链表+红黑树实现,在解决哈希冲突时有了较大的变化,当链表长度大于阈值(默认为8),将链表转换为红黑树,这样大大减少了查找时间。
1-定义及字段属性
HashMap源码:HashMap1.8源码解析
- HashMap定义:
• 遇到冲突时,HashMap是采用的链地址法来解决;
• 在JDK1.7中,HashMap是由数组+链表构成的;
• 在JDK1.8中,HashMap是由数组+链表+红黑树构成,新增了红黑树作为底层数据结构,结构变得复杂了,但是效率也变的更高效。
• JDK1.8 中 HashMap是如何实现的。

- 1)HashMap的定义
• HashMap 是一个散列表,它存储的内容是键值对(key-value)映射,而且 key 和 value 都可以为 null。
public class HashMap<K,V> extends AbstractMap<K,V> implements Map<K,V>, Cloneable, Serializable {...}

• 1> 首先该类实现了一个Map接口,该接口定义了一组键值对映射通用的操作。储存一组成对的键-值对象,提供key(键)到value(值)的映射,Map中的key不要求有序,不允许重复。value同样不要求有序,但可以重复。
• 2> 但是我们发现该接口方法有很多,我们设计某个键值对的集合有时候并不像实现那么多方法,那该怎么办?
JDK 还为我们提供了一个抽象类 AbstractMap ,该抽象类继承Map接口,所以如果我们不想实现所有的 Map 接口方法,就可以选择继承抽象类 AbstractMap 。
• 但是我们发现HashMap类即继承了AbstractMap 接口,也实现了Map接口,这样做难道不是多此一举?后面我们会讲的LinkedHashSet集合也有这样的写法。
是的.
• 3> HashMap集合还实现了Cloneable接口以及 Serializable接口,分别用来进行对象克隆以及将对象进行序列化。- HashMap定义:
字段属性
//序列化和反序列化时,通过该字段进行版本一致性验证private static final long serialVersionUID = 362498820763181265L;//默认 HashMap 集合初始容量为16(必须是 2 的倍数)static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16//集合的最大容量,如果通过带参构造指定的最大容量超过此数,默认还是使用此数static final int MAXIMUM_CAPACITY = 1 << 30;//默认的填充因子static final float DEFAULT_LOAD_FACTOR = 0.75f;//当桶(bucket)上的结点数大于这个值时会转成红黑树(JDK1.8新增)static final int TREEIFY_THRESHOLD = 8;//当桶(bucket)上的节点数小于这个值时会转成链表(JDK1.8新增)static final int UNTREEIFY_THRESHOLD = 6;/**(JDK1.8新增)* 当集合中的容量大于这个值时,表中的桶才能进行树形化 ,否则桶内元素太多时会扩容,* 而不是树形化 为了避免进行扩容、树形化选择的冲突,这个值不能小于 4 * TREEIFY_THRESHOLD*/static final int MIN_TREEIFY_CAPACITY = 64;// **注意:后面三个字段是JDK1.8新增的,主要是用来进行红黑树和链表的互相转换。**// ------------------------------------------------------------------------/*** 初始化使用,长度总是 2的幂*/transient Node<K,V>[] table;/*** 保存缓存的entrySet()*/transient Set<Map.Entry<K,V>> entrySet;/*** 此映射中包含的键值映射的数量。(集合存储键值对的数量)*/transient int size;/*** 跟前面ArrayList和LinkedList集合中的字段modCount一样,记录集合被修改的次数* 主要用于迭代器中的快速失败*/transient int modCount;/*** 调整大小的下一个大小值(容量*加载因子)。capacity * load factor*/int threshold;/*** 散列表的加载因子。*/final float loadFactor;
① Node[] table
-- HashMap是由数组+链表+红黑树组成,table字段就是数组。
-- 初始化长度默认是DEFAULT_INITIAL_CAPACITY= 16。
② size
集合中存放key-value的实时对数。
③ loadFactor
-- 装载因子,是用来衡量HashMap满的程度;
-- HashMap的实时装载因子的计算:size/capacity,而不是占用桶的数量去除以capacity。capacity 是桶的数量,也就是table的长度length。
-- 默认的负载因子0.75 是对空间和时间效率的一个平衡选择,建议大家不要修改,除非在时间和空间比较特殊的情况下,如果内存空间很多而又对时间效率要求很高,可以降低负载因子loadFactor的值;相反,如果内存空间紧张而对时间效率要求不高,可以增加负载因子 loadFactor 的值,这个值可以大于1。
④ threshold
计算公式:capacity*loadFactor。
这个值是当前已占用数组长度的最大值。过这个数目就重新resize(扩容),扩容后的HashMap容量是之前容量的两倍为什么HashMap的加载因子是0.75?
https://zhuanlan.zhihu.com/p/149687607
2-构造函数
5)构造函数
① 默认无参构造函数
无参构造器,初始化散列表的加载因子为0.75/*** 默认构造函数,初始化加载因子loadFactor = 0.75*/public HashMap() {this.loadFactor = DEFAULT_LOAD_FACTOR;}
② 指定初始容量的构造函数
/**** @param initialCapacity 指定初始化容量* @param loadFactor 加载因子 0.75*/public HashMap(int initialCapacity, float loadFactor) {//初始化容量不能小于 0 ,否则抛出异常if (initialCapacity < 0)throw new IllegalArgumentException("Illegal initial capacity: " + initialCapacity);//如果初始化容量大于2的30次方,则初始化容量都为2的30次方if (initialCapacity > MAXIMUM_CAPACITY)initialCapacity = MAXIMUM_CAPACITY;//如果加载因子小于0,或者加载因子是一个非数值,抛出异常if (loadFactor <= 0 || Float.isNaN(loadFactor))throw new IllegalArgumentException("Illegal load factor: " + loadFactor);this.loadFactor = loadFactor;this.threshold = tableSizeFor(initialCapacity);}// 返回大于等于initialCapacity的最小的二次幂数值。// >>> 操作符表示无符号右移,高位取0。// | 按位或运算static final int tableSizeFor(int cap) {int n = cap - 1;n |= n >>> 1;n |= n >>> 2;n |= n >>> 4;n |= n >>> 8;n |= n >>> 16;return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;}
3-hash
哈希表
• Hash表也称为散列表,也有直接译作哈希表;
• Hash表是一种根据关键字值(key-value)而直接进行访问的数据结构。也就是说它通过把关键码值映射到表中的一个位置来访问记录,以此来加快查找的速度。
• 查找
哈希表通过把关键码值映射到表中一个位置来访问记录,以加快查找的速度。这个映射函数叫做散列函数,存放记录的数组叫做散列表,只需要O(1)的时间级。

• 问题①:为什么要有散列函数?
散列函数的存在能够帮助我们更快的确定key和value的映射关系,试想一下,如果没有汉字和拼音的转换规则(或者汉字和偏旁部首的),给你一个汉字,你该如何从字典中找到该汉字?我想除了遍历整部字典,你没有什么更好的办法。
• 问题②:多个key通过散列函数会得到相同的值,这时候怎么办?
哈希冲突:
① 开放地址法:
当我们遇到冲突了,这时候通过另一种函数再计算一遍,得到相应的映射关系。比如对于汉语字典,一个字 “余”,拼音是“yu”,我们将其放在页码为567(假设在该位置),这时候又来了一个汉字“于”,拼音也是“yu”,那么这时候我们要是按照转换规则,也得将其放在页码为567的位置,但是我们发现这个页码已经被占用了,这时候怎么办?我们可以在通过另一种函数,得到的值加1。那么汉字"于"就会被放在576+1=577的位置。
② 链地址法:
-- 我们可以将字典的每一页都看成是一个子数组或者子链表,当遇到冲突了,直接往当前页码的子数组或者子链表里面填充即可。那么我们进行同音字查找的时候,可能需要遍历其子数组或者子链表。
-- 对于开放地址法,可能会遇到二次冲突,三次冲突,所以需要良好的散列函数,分布的越均匀越好。对于链地址法,虽然不会造成二次冲突,但是如果一次冲突很多,那么会造成子数组或者子链表很长,那么我们查找所需遍历的时间也会很长。HashMap中的hash函数?Hash算法(扰动函数) |3
HashMap中的哈希算法:确定哈希桶数组索引位置
static final int hash(Object key) {int h;return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);}// 使用:这一步是在后面添加元素putVal()方法中进行位置的确定i = (table.length - 1) & hash(key);
散列函数来确定索引的位置。
散列函数设计的越好,使得元素分布的越均匀。HashMap是数组+链表+红黑树的组合,我们希望在有限个数组位置时,尽量每个位置的元素只有一个,那么当我们用散列函数求得索引位置的时候,能马上知道对应位置的元素是不是想要的,而不是要进行链表的遍历或者红黑树的遍历,这会大大优化我们的查询效率。
哈希表
哈希表hashmap哈希冲突的解决方式?
- 拉链法
hashmap容量为什么是2的幂次
- get方法中,使用 (n - 1) & hash实际上是计算出 key 在 tab 中索引位置
- n 永远是2的次幂,n-1的二进制永远都是尾端以连续1的形式表示,当(n - 1) & hash 会保留hash中 后 x 位的 1
https://blog.csdn.net/weixin_38405253/article/details/104230889 - 不是2幂次就会造成分布不均匀了,增加了碰撞的几率,减慢了查询的效率,造成空间的浪费。
https://www.cnblogs.com/aotemanzhifu/p/9192373.html
4-put
HashMap的put过程?
代码
//hash(key)就是上面讲的hash方法,对其进行了第一步和第二步处理public V put(K key, V value) {return putVal(hash(key), key, value, false, true);}/**** @param hash 索引的位置* @param key 键* @param value 值* @param onlyIfAbsent true 表示不要更改现有值* @param evict false表示table处于创建模式* @return*/final V putVal(int hash, K key, V value, boolean onlyIfAbsent,boolean evict) {Node<K,V>[] tab; Node<K,V> p; int n, i;//如果table为null或者长度为0,则进行初始化//resize()方法本来是用于扩容,由于初始化没有实际分配空间,这里用该方法进行空间分配,后面会详细讲解该方法if ((tab = table) == null || (n = tab.length) == 0)n = (tab = resize()).length;//注意:这里用到了前面讲解获得key的hash码的第三步,取模运算,下面的if-else分别是 tab[i] 为null和不为nullif ((p = tab[i = (n - 1) & hash]) == null)tab[i] = newNode(hash, key, value, null);//tab[i] 为null,直接将新的key-value插入到计算的索引i位置else {//tab[i] 不为null,表示该位置已经有值了Node<K,V> e; K k;if (p.hash == hash &&((k = p.key) == key || (key != null && key.equals(k))))e = p;//节点key已经有值了,直接用新值覆盖//该链是红黑树else if (p instanceof TreeNode)e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);//该链是链表else {for (int binCount = 0; ; ++binCount) {if ((e = p.next) == null) {p.next = newNode(hash, key, value, null);//链表长度大于8,转换成红黑树if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1sttreeifyBin(tab, hash);break;}//key已经存在直接覆盖valueif (e.hash == hash &&((k = e.key) == key || (key != null && key.equals(k))))break;p = e;}}if (e != null) { // existing mapping for keyV oldValue = e.value;if (!onlyIfAbsent || oldValue == null)e.value = value;afterNodeAccess(e);return oldValue;}}++modCount;//用作修改和新增快速失败if (++size > threshold)//超过最大容量,进行扩容resize();afterNodeInsertion(evict);return null;}
流程:
①、判断键值对数组 table 是否为空或为null,否则执行resize()进行扩容;
②、根据键值key计算hash值得到插入的数组索引i,如果table[i]==null,直接新建节点添加,转向⑥,如果table[i]不为空,转向③;
③、判断table[i]的首个元素是否和key一样,如果相同直接覆盖value,否则转向④,这里的相同指的是hashCode以及equals;
④、判断table[i] 是否为treeNode,即table[i] 是否是红黑树,如果是红黑树,则直接在树中插入键值对,否则转向⑤;
⑤、遍历table[i],判断链表长度是否大于8,大于8的话把链表转换为红黑树,在红黑树中执行插入操作,否则进行链表的插入操作;遍历过程中若发现key已经存在直接覆盖value即可;
⑥、插入成功后,判断实际存在的键值对数量size是否超过了最大容量threshold,如果超过,进行扩容。
⑦、如果新插入的key不存在,则返回null,如果新插入的key存在,则返回原key对应的value值(注意新插入的value会覆盖原value值)- 图示

put过程图
Hashmap的原理,增的情况后端数据结构如何位移
hashMap怎么获取有几个元素,底层实现是什么
- 代码
public int size() {return size;}// 计算if (++size > threshold)//超过最大容量,进行扩容 -58resize(); -59
数组上有5个元素,而某个链表上有3个元素,问此HashMap的 size 是多大?
分析第58,59 行代码,很容易知道,只要是调用put()方法添加元素,那么就会调用 ++size(这里有个例外是插入重复key的键值对,不会调用,但是重复key元素不会影响size),所以,上面的答案是 7。为什么在1.8中链表大于8时会转红黑树? |2
因为泊松分布,拉链法哈希冲突累积到七个元素后,通过泊松分布计算得到第八个冲突元素出现的概率极低,几乎不可能出现,但只要出现了就树形化提高查询效率(前提是数组长度已经到了64,否则先扩容)
红黑树:https://blog.csdn.net/tanrui519521/article/details/80980135
- 为什么要用红黑树?而不用平衡二叉树? |2
- 在Java 8之前的实现中是用链表解决冲突的,在产生碰撞的情况下,进行get时,两步的时间复杂度是O(1)+O(n)。因此,当碰撞很厉害的时候n很大,O(n)的速度显然是影响速度的。
- 因此在Java 8中,利用红黑树替换链表,这样复杂度就变成了O(1)+O(logn)了,这样在n很大的时候,能够比较理想的解决这个问题
5-resize
扩容机制
先介绍 JDK1.7的扩容源码,便于理解,然后在介绍JDK1.8的源码。
//参数 newCapacity 为新数组的大小void resize(int newCapacity) {Entry[] oldTable = table;//引用扩容前的 Entry 数组int oldCapacity = oldTable.length;if (oldCapacity == MAXIMUM_CAPACITY) {//扩容前的数组大小如果已经达到最大(2^30)了threshold = Integer.MAX_VALUE;///修改阈值为int的最大值(2^31-1),这样以后就不会扩容了return;}Entry[] newTable = new Entry[newCapacity];//初始化一个新的Entry数组transfer(newTable, initHashSeedAsNeeded(newCapacity));//将数组元素转移到新数组里面table = newTable;threshold = (int)Math.min(newCapacity * loadFactor, MAXIMUM_CAPACITY + 1);//修改阈值}void transfer(Entry[] newTable, boolean rehash) {int newCapacity = newTable.length;for (Entry<K,V> e : table) {//遍历数组while(null != e) {Entry<K,V> next = e.next;if (rehash) {e.hash = null == e.key ? 0 : hash(e.key);}int i = indexFor(e.hash, newCapacity);//重新计算每个元素在数组中的索引位置e.next = newTable[i];//标记下一个元素,添加是链表头添加newTable[i] = e;//将元素放在链上e = next;//访问下一个 Entry 链上的元素}}}
JDK1.7中首先是创建一个新的大容量数组,然后依次重新计算原集合所有元素的索引,然后重新赋值。如果数组某个位置发生了hash冲突,使用的是单链表的头插入方法,同一位置的新元素总是放在链表的头部,这样与原集合链表对比,扩容之后的可能就是倒序的链表了。
1.8源码
final Node<K,V>[] resize() {Node<K,V>[] oldTab = table;int oldCap = (oldTab == null) ? 0 : oldTab.length;//原数组如果为null,则长度赋值0int oldThr = threshold;int newCap, newThr = 0;if (oldCap > 0) {//如果原数组长度大于0// 超过最大值就不再扩充了,就只好随你碰撞去吧if (oldCap >= MAXIMUM_CAPACITY) {//数组大小如果已经大于等于最大值(2^30)threshold = Integer.MAX_VALUE;//修改阈值为int的最大值(2^31-1),这样以后就不会扩容了return oldTab;}//原数组长度大于等于初始化长度16,并且原数组长度扩大1倍也小于2^30次方// 没超过最大值,就扩充为原来的2倍else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&oldCap >= DEFAULT_INITIAL_CAPACITY)newThr = oldThr << 1; // 阀值扩大2倍}else if (oldThr > 0) //旧阀值大于0,则将新容量直接等于就阀值newCap = oldThr;else {//阀值等于0,oldCap也等于0(集合未进行初始化)newCap = DEFAULT_INITIAL_CAPACITY;//数组长度初始化为16newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);//阀值等于16*0.75=12}//计算新的阀值上限if (newThr == 0) {float ft = (float)newCap * loadFactor;newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?(int)ft : Integer.MAX_VALUE);}threshold = newThr;@SuppressWarnings({"rawtypes","unchecked"})Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];table = newTab;if (oldTab != null) {//把每个bucket都移动到新的buckets中for (int j = 0; j < oldCap; ++j) {Node<K,V> e;if ((e = oldTab[j]) != null) {oldTab[j] = null;//元数据j位置置为null,便于垃圾回收if (e.next == null)//数组没有下一个引用(不是链表)newTab[e.hash & (newCap - 1)] = e;else if (e instanceof TreeNode)//红黑树((TreeNode<K,V>)e).split(this, newTab, j, oldCap);else { // preserve orderNode<K,V> loHead = null, loTail = null;Node<K,V> hiHead = null, hiTail = null;Node<K,V> next;do {next = e.next;//原索引if ((e.hash & oldCap) == 0) {if (loTail == null)loHead = e;elseloTail.next = e;loTail = e;}//原索引+oldCapelse {if (hiTail == null)hiHead = e;elsehiTail.next = e;hiTail = e;}} while ((e = next) != null);//原索引放到bucket里if (loTail != null) {loTail.next = null;newTab[j] = loHead;}//原索引+oldCap放到bucket里if (hiTail != null) {hiTail.next = null;newTab[j + oldCap] = hiHead;}}}}}return newTab;}
相比于JDK1.7,1.8使用的是2次幂的扩展(指长度扩为原来2倍),所以,元素的位置要么是在原位置,要么是在原位置再移动2次幂的位置。我们在扩充HashMap的时候,不需要像JDK1.7的实现那样重新计算hash,只需要看看原来的hash值新增的那个bit是1还是0就好了,是0的话索引没变,是1的话索引变成“原索引+oldCap”
6-线程安全
|线程不安全|
HashMap线程安全吗?为什么不安全?不安全怎么办? |3
hashMap1.8有什么改动
如何resize,最后细节到是否覆盖旧值的参数
HashMap在并发情况下发生resize会出现什么问题?
举例说明hashmap1.7循环依赖的产生
如何优化使得HashMap线程安全/如何实现线程安全的hashmap?
7-remove
删除元素小于8?
6Hashmap的原理,删的情况后端数据结构如何位移
- 删:当遍历Map需要删除的时候,不可以for循环遍历,否则会产生并发修改异常CME,只能使用迭代器iterator.remove()来删除元素,或者使用线程安全的concurrentHashMap来删除Map中删除元素(concurrentHashMap和迭代器Iterator遍历删除)
https://www.cnblogs.com/zhangnf/p/HashMap.html
- 删:当遍历Map需要删除的时候,不可以for循环遍历,否则会产生并发修改异常CME,只能使用迭代器iterator.remove()来删除元素,或者使用线程安全的concurrentHashMap来删除Map中删除元素(concurrentHashMap和迭代器Iterator遍历删除)
8-get
查找元素
①、通过 key 查找 value
首先通过 key 找到计算索引,找到桶位置,先检查第一个节点,如果是则返回,如果不是,则遍历其后面的链表或者红黑树。其余情况全部返回 null。public V get(Object key) {Node<K,V> e;return (e = getNode(hash(key), key)) == null ? null : e.value;}final Node<K,V> getNode(int hash, Object key) {Node<K,V>[] tab; Node<K,V> first, e; int n; K k;if ((tab = table) != null && (n = tab.length) > 0 &&(first = tab[(n - 1) & hash]) != null) {//根据key计算的索引检查第一个索引if (first.hash == hash && // always check first node((k = first.key) == key || (key != null && key.equals(k))))return first;//不是第一个节点if ((e = first.next) != null) {if (first instanceof TreeNode)//遍历树查找元素return ((TreeNode<K,V>)first).getTreeNode(hash, key);do {//遍历链表查找元素if (e.hash == hash &&((k = e.key) == key || (key != null && key.equals(k))))return e;} while ((e = e.next) != null);}}return null;}
②、判断是否存在给定的 key 或者 value
public boolean containsKey(Object key) {return getNode(hash(key), key) != null;}public boolean containsValue(Object value) {Node<K,V>[] tab; V v;if ((tab = table) != null && size > 0) {//遍历桶for (int i = 0; i < tab.length; ++i) {//遍历桶中的每个节点元素for (Node<K,V> e = tab[i]; e != null; e = e.next) {if ((v = e.value) == value ||(value != null && value.equals(v)))return true;}}}return false;}
- 22
- HashMap并没有直接提供getNode接口给用户调用,而是提供的get函数,而get函数就是通过getNode来取得元素的。
- get(key)方法时获取key的hash值,计算hash&(n-1)得到在链表数组中的位置first=tab[hash&(n-1)],先判断first的key是否与参数key相等,不等就遍历后面的链表找到相同的key值返回对应的Value值即可
https://blog.csdn.net/tuke_tuke/article/details/51588156
https://www.cnblogs.com/leesf456/p/5242233.html
9-遍历
如何遍历hashmap
equals()和hashCode()的都有什么作用?-
通过对key的hashCode()进行hashing,并计算下标( n-1 & hash),从而获得buckets的位置。如果产生碰撞,则利用key.equals()方法去链表或树中去查找对应的节点如果HashMap的大小超过了负载因子(load factor)定义的容量,怎么办?-
如果超过了负载因子(默认0.75),则会重新resize一个原来长度两倍的HashMap,并且重新调用hash方法。
TreeMap
LinkedHashMap
3-Set
Set类怎么保证唯一的,add方法底层实现
HashSet
|源码解析|
hashset实现原理?
- 源码解析
- 基于HashMap实现的,HashSet底层使用HashMap来保存所有元素,相关HashSet的操作,基本上都是直接调用底层HashMap的相关方法来完成,
- https://blog.csdn.net/guoweimelon/article/details/50804799
https://blog.csdn.net/zhaojie181711/article/details/80480421
重复set
往set里面put一个学生对象,然后将这个学生对象的学号改了,再put进去,可以放进set么?并讲出为什么- 不可以放进,hashcode不变
https://www.cnblogs.com/Spades7/p/8206671.html
- 不可以放进,hashcode不变
假设现在一个学生类,有学号和姓名,我现在hashcode方法重写的时候,只将学号参与计算,会出现什么情况?
1)可能有相同hashcode,但不是一个对象
2)只要 hashcode 不相等就玩儿完,不用再去调用复杂的 equals 了。提升容器使用效率。
2)equals()和hashCode()有一个契约:- 如果两个对象相等的话,它们的hashcode必须相等;
- 但如果两个对象的hashcode相等的话,这两个对象不一定相等。
https://blog.csdn.net/pigcircle_1988/article/details/84911272
hashset为什么不是线程安全的,描述场景
2) hashSet
- hashSet的底层:hashMap 16,0.75
- 你确定hashSet的底层?肯定是,add,
hashSet的add由hashmap的普通实现,只管key,value设置为present常数
LinkedHashSet
2-迭代器
5.迭代器和for循环的区别
- 集合类用了那些设计模式
6-collections
Arrays工具类怎么用?
collections有哪些?
5-集合区别
数组和集合的区别
Vector与list区别
collection与collections区别
- Collection:
-- 集合类的上层接口。
-- Interface,包含了一些集合的基本操作。
-- Set接口和List接口的父接口 - Collections:
-- 集合框架的帮助类,
-- 包含一些对集合的排序,搜索以及序列化的操作。
-- 本质,Collections是一个类
https://blog.csdn.net/zlczsw/article/details/100118405
https://www.cnblogs.com/jxxblogs/p/11547898.html
- Collection:
List与Set的区别? |2
(List有序可重复、Set无序且不可重复)- 两个接口都是继承自Collection:
① List可重复,Set中不允许重复;
② List是有序集合,会保留元素插入时的顺序,Set是无序集合。
③ List可以通过下标来访问,而Set不能。
https://www.cnblogs.com/helloworldcode/p/12122072.html
- 两个接口都是继承自Collection:
List、Vector区别
- java中,collection集合中是有List和vector(都是接口)
- List是在jdk1.2以后推出的,而Vector是在jdk1.0推出的
- List采用的是异步处理方式,性能高,而Vector采用的是同步处理方式,性能低
- List属于非线程安全,Vector属于线程安全
Arraylist与Vector区别
- ArrayList 是 List 的主要实现类,底层使用Object[]存储,适用于频繁的查找工作,线程不安全 ;
- Vector 是 List 的古老实现类,底层使用 Object[] 存储,线程安全的。
HashMap与HashTable区别
- HashMap
-- 线程不安全;
-- 是一个接口,是 Map的一个子接口,
-- 是将键映射到值得对象,不允许键值重复,允许空键和空值;
-- 非线程安全, HashMap的效率要较 HashTable 的效率高一些. - HashTable
-- 线程安全的集合;
-- 不允许 null 值作为一个 key 值或者 Value 值; - HashTable 是 sychronize(同步化),多个线程访问时不需要自己为它的方法实现同步,而HashMap在被多个线程访问的时候需要自己为它的方法实现同步;
- HashMap
※ 2-JVM(Java Virtual Machine)※
-- jvm学习:https://www.zybuluo.com/songhanshi/note/1733752
配置过java启动设置吗
没有,我只用过-xms等指令改过JVM参数,和jinfo看参数
-XMX -XSS -XMN说说对象创建到消亡的过程
https://blog.csdn.net/u012312373/article/details/46718911
https://blog.csdn.net/qq_25005909/article/details/78981512
JMM规定了内存主要划分为主内存和工作内存两种。此处的主内存和工作内存跟JVM内存划分(堆、栈、方法区)是在不同的层次上进行的,如果非要对应起来,主内存对应的是Java堆中的对象实例部分,工作内存对应的是栈中的部分区域,从更底层的来说,主内存对应的是硬件的物理内存,工作内存对应的是寄存器和高速缓存。
1. 线程的工作内存指的是什么,在内存的哪个地方
* JVM将内存组织为主内存和工作内存两个部分。
* 主内存主要包括本地方法区和堆。每个线程都有一个工作内存,主要包括两个部分,一个是属于该线程私有的栈和对主存部分变量拷贝的寄存器(包括程序计数器PC和cup工作的高速缓存区)。
① 所有的变量都存储在主内存中,对于所有线程都是共享的。
② 每条线程都有自己的工作内存,工作内存中保存的是主存中某些变量的拷贝,线程对变量的所有操作都必须在工作内存中进行,而不能直接读写主内存中的变量。
③ 线程之间无法直接访问对方的工作内存中的变量,线程间变量的传递均需要通过主内存来完成。
待完善:https://aalion.github.io/2019/12/08/concurrency12/
https://www.jianshu.com/p/679ad52eca05
一、概述
JRE和JDK的区别?
- JDK(Java Development Kit)
-- Java程序设计语言、Java虚拟机、Java类库这三部分统称为JDK,
广义上JDK常来代指整个Java技术体系;
-- Java的开发工具,提供了编译和运行Java程序所需的各种资源和工具;
-- 不仅可以开发Java程序,也同时拥有了运行Java程序的平台; - JRE(Java Runtime Enviroment)
-- Java运行环境,包括:虚拟机+java的核心类库;
-- 只能运行Java程序,不包含开发工具(编译器、调试器等)。
- JDK(Java Development Kit)
JVM了解么?
- 是什么
虚拟机是一种抽象化的计算机,通过在实际的计算机上仿真模拟各种计算机功能来实现。Java虚拟机有自己完善的硬体架构,如处理器、堆栈、寄存器等,还具有相应的指令系统。Java虚拟机屏蔽了与具体操作系统平台相关的信息,使得Java程序只需生成在Java虚拟机上运行的目标代码(字节码),就可以在多种平台上不加修改地运行。 - 系统
一个Java虚拟机实例在运行过程中有三个子系统来保障它的正常运行,分别是类加载器子系统, 执行引擎子系统和垃圾收集子系统。
- 是什么
主流:HotSpot VM
- Sun/OracleJDK和OpenJDK中的默认Java虚拟机,也是目前使用范围最广的Java虚拟机。
- HotSpot虚拟机中含有两个即时编译器
-- 编译耗时短但输出代码优化程度较低的客户端编译器(简称为C1)
-- 编译耗时长但输出代码优化质量也更高的服务端编译器(简称为C2)
-- 在分层编译机制下与解释器互相配合来共同构成HotSpot虚拟机的执行子系统
二、自动内存管理
2. Java内存区域与内存溢出异常
1- Java内存区域
JVM的内存模型可以说下吗?
(说一下Java虚拟机内存区域划分、各区域的介绍、1.8&1.7版本迭代)Java虚拟机内存的各个区域?
Java虚拟机在执行Java程序的过程中会把它所管理的内存划分为若干个不同的数据区域。(运行时数据区域,强调对内存空间的划分- 程序计数器(线程隔离
- Java虚拟机栈(线程隔离
- 本地方法栈(线程隔离
- Java堆(线程共享
- 方法区(线程共享

-- 灰色:线程私有,几乎不存在垃圾回收
-- 橘色:GC的作用区域需要有垃圾回收。
JVM内存区域和Java内存模型
https://www.cnblogs.com/czwbig/p/11127124.html (图、解释)
https://jingyan.baidu.com/article/4f34706e623281e387b56d84.html
Java虚拟机内存的各个区域-分
【1】程序计数器?- 空间较小
- 线程私有,生命周期与线程相同;
- 当前线程所执行的字节码的行号指示器;
- 字节码解释器工作时就是通过改变这个计数器的值来选取下一条需要执行的字节码指令,是程序控制流的指示器;
- 辅助完成分支、循环、跳转、异常处理、线程恢复等基础功能;
- 线程切换后能恢复到正确的执行位置,每条线程都需要有一个独立的程序计数器;
- 线程Java方法,这个计数器记录的是正在执行的虚拟机字节码指令的地址,
执行的是本地(Native)方法,这个计数器值则应为空(Undefined) - 唯一无OutOfMemoryError情况的
【2】 Java虚拟机栈? - 线程私有,生命周期与线程相同,同程序计数器
- 作用:
描述的是Java方法执行的线程内存模型:每个方法被执行的时候,Java虚拟机都会同步创建一个栈帧用于存储数据。每一个方法被调用直至执行完毕的过程,就对应着一个栈帧在虚拟机栈中从入栈到出栈的过程。 - 存储:
栈帧(Stack Frame)存储:局部变量表、操作数栈、动态连接、方法出口等信息;
局部变量表存储:
① 编译期可知的各种Java虚拟机基本数据类型(boolean、byte、char、short、int、float、long、double);
② 对象引用(reference类型,它并不等同于对象本身,可能是一个指向对象起始地址的引用指针,也可能是指向一个代表对象的句柄或者其他与此对象相关的位置);
③ returnAddress类型(指向了一条字节码指令的地址).
局部变量表存储空间:
局部变量表中的存储空间以局部变量槽(Slot)来表示,其中64位长度的long和double类型的数据会占用两个变量槽,其余的数据类型只占用一个 - 异常:
StackOverflowError异常:如果线程请求的栈深度大于虚拟机所允许的深度
OutOfMemoryError异常:如果Java虚拟机栈容量可以动态扩展,当栈扩展时无法申请到足够的内存时
【3】本地方法栈 - 与虚拟机栈作用相似,
- 与虚拟机栈区别:
-- 虚拟机栈为虚拟机执行Java方法(也就是字节码)服务
-- 本地方法栈则是为虚拟机使用到的本地(Native) 方法服务。 - 异常:
与虚拟机栈一样,本地方法栈也会在栈深度溢出或者栈扩展失败时分别抛出StackOverflowError和OutOfMemoryError异常。
【4】Java堆(Java Heap) - 虚拟机所管理的内存中空间最大的,所有线程共享的一块内存区域,在虚拟机启动时创建;
- 存储:对象实例(几乎所有;
- 垃圾收集器管理的内存区域;
- 分配内存的角度看,所有线程共享的Java堆中可以划分出多个线程私有的分配缓冲区 (TLAB),以提升对象分配时的效率;
- Java堆可被实现成固定大小的或可扩展的,当前主流的Java虚拟机都是按照可扩展来实现的(通过参数-Xmx和-Xms设定);
- 异常:
OutOfMemoryError异常:如果在Java堆中没有内存完成实例分配,且堆也无法再扩展时,Java虚拟机将会抛出OutOfMemoryError异常。
【5】方法区(Method Area) - 堆的一个逻辑部分
- 存储:已被虚拟机加载的类型信息、常量、静态变量、即时编译器编译后的代码缓存等数据。(字符串常量池?
- 永久代概念:用永久代来实现方法区
- JDK6,逐步改为采用本地内存(Native Memory)来实现方法区
- JDK8,完全废弃永久代的概念,改用与JRockit、J9一样在本地内存中实现的元空间(Meta- space)来代替。
- OutOfMemoryError异常:方法区无法满足新的内存分配需求时
【5.1】方法区-运行时常量池(Runtime Constant Pool) - 方法区的一部分
- 存储:编译期生成的各种字面量与符号引用、由符号引用翻译出来的直接引用
-- Class文件中除了有类的版本、字段、方法、接口等描述信息外,还有一项信息是常量池表,用于存放编译期生成的各种字面量与符号引用,这部分内容将在类加载后存放到方法区的运行时常量池中。
-- 除了保存Class文件中描述的符号引用外,还会把由符号引用翻译出来 的直接引用也存储在运行时常量池中 - 异常:
和方法区一样受方法区内存的限制,当常量池无法再申请到内存时会抛出OutOfMemoryError异常。
【6】直接内存 - 非虚拟机运行时数据区的一部分以及非内存区域
- 放这里的原因:这部分内存也被频繁地使用,也可能导致OutOfMemoryError异常
- OutOfMemoryError异常:各个内存区域总和大于物理内存限制
常量池、运行时常量池、字符串常量池中都存储的什么
- ans:常量池 .class文件的一部分,字面量和符号引用 |运行时常量池 方法区 加载后的常量池数据 |字符串常量池 方法区 是一组指针指向堆中的String对象的内存地址
- 常量池、运行时常量池、字符串常量池
- 字符串常量池(一组指针指向Heap中的String对象的内存地址)
:为避免每次都创建相同的字符串对象及内存分配,JVM内部对字符串对象的创建的优化
内存模型,堆和栈都有什么?
(问法不够准确,此处只问内存模型,应该是JMM,后面又问到堆栈应该是想问JVM内存,先按照JVM的角度回答,持续关注...)- 经常有人把Java内存区域笼统地划分为堆内存(Heap)和栈内存(Stack),这种划分方式直接继承自传统的C、C++程序的内存布局结构,在Java语言里就显得有些粗糙了,实际的内存区域划分要比这更复杂。不过这种划分方式的流行也间接说明了程序员最关注的、与对象内存分配关系最密切的区域是“堆”和“栈”两块。其中,“堆”在稍后笔者会专门讲述,而“栈”通常就是指这里讲的虚拟机栈,或者更多的情况下只是指虚拟机栈中局部变量表部分。
- 堆:对象实例;
- 栈:局部变量表、操作数栈、动态连接、方法出口等信息(z-详细见上)
JVM堆内存划分
(Java垃圾回收:- 永久代(方法区
- 老年代(堆
- 新生代(堆
-Eden区
-From Survivor
-To Survivor - 无论是哪个区域,存储的都只能是对象的实例,将Java 堆细分的目的只是为了更好地回收内存,或者更快地分配内存。
http://www.shaoqun.com/a/99944.html
2- 对象创建过程
new一个对象? -jvm3
- Java虚拟机遇到一条字节码new指令
- 首先将去检查这个指令的参数是否能在常量池中定位到一个类的符号引用,并且检查这个符号引用代表的类是否已被加载、解析和初始化过。如果没有,那必须先执行相应的类加载过程;
- 在类加载检查通过后,接下来虚拟机将为新生对象分配内存。
对象所需内存的大小在类加载完成后便可完全确定,为对象分配空间的任务实际上便等同于把一块确定大小的内存块从Java堆中划分出来。 - 内存分配完成之后,虚拟机必须将分配到的内存空间(但不包括对象头)都初始化为零值,如果使用了TLAB的话,这一项工作也可以提前至TLAB分配时顺便进行。
- 接下来,Java虚拟机还要对对象进行必要的设置
-- 例如这个对象是哪个类的实例、如何才能找到类的元数据信息、对象的哈希码(实际上对象的哈希码会延后到真正调用Object::hashCode()方法时才计算)、对象的GC分代年龄等信息。这些信息存放在对象的对象头(Object Header)之中。
-- 根据虚拟机当前运行状态的不同,如是否启用偏向锁等,对象头会有不同的设置方式。 - 虚拟机的视角,新的对象已经产生。
- Java程序的视角,对象创建才刚刚开始。
-- 构造函数,即Class文件中的()方法还没有执行,所有的字段都为默认的零值,对象需要的其他资源和状态信息也还没有按照预定的意图构造好。
-- 一般来说(由字节码流中new指令后面是否跟随invokespecial指令所决定,Java编译器会在遇到new关键字的地方同时生成这两条字节码指令,但如果直接通过其他方式产生的则不一定如此),new指令之后会接着执行()方法,按照程序员的意愿对对象进行初始化,这样一个真正可用的对象才算完全被构造出来。
jvm怎么知道对象属于哪个类?
- jvm3:对象头信息:用于存储对象自身的运行时数据,如哈希码(HashCode)、GC分代年龄、锁状态标志、线程持有的锁、偏向线程ID、偏向时间戳等,即“Mark Word”。、
以及另外一部分是类型指针,即对象指向它的类型元数据的指针,Java虚拟机通过这个指针来确定该对象是哪个类的实例。 - 推断:由对象头的类型指针获取。
- jvm3:对象头信息:用于存储对象自身的运行时数据,如哈希码(HashCode)、GC分代年龄、锁状态标志、线程持有的锁、偏向线程ID、偏向时间戳等,即“Mark Word”。、
3- OOM
|OutOfMemoryError异常-内存溢出异常|
堆溢出?
- 概念:
Java堆用于存储对象实例,只要不断地创建对象,并且保证GC Roots到对象之间有可达到路径来避免垃圾回收机制清除这些对象,那么在对象数量达到最大堆的容量限制后就会产生内存溢出异 - 原因:
大量对象占据了堆空间,而这些对象都持有强引用,导致无法回收,当对象大小之和大于由-Xmx参数指定的堆空间大小时,溢出错误就自然而然地发生了。(jvms) - 例子:
① 内存中加载的数据量过于庞大,如一次从数据库取出过多数
② 集合类中有对对象的引用,使用完后未清空,使得JVM不能回
③ 代码中存在死循环或循环产生过多重复的对象实体;
- 概念:
栈溢出? (HotSpot-虚拟机栈和本地方法栈)
- 概念:在《Java虚拟机规范》中描述了两种异常:
1)如果线程请求的栈深度大于虚拟机所允许的最大深度,将抛出StackOverflowError异常。
2)如果虚拟机的栈内存允许动态扩展,当扩展栈容量无法申请到足够的内存时,将抛出 OutOfMemoryError异常。 - 原因:
HotSpot虚拟机不支持扩展支持栈的动态扩展,只会在创建线程申请内存时就因无法获得足够内存而出现OutOfMemoryError异常,也只会因为栈容量无法容纳新的栈帧而导致StackOverflowError异常。(jvm3) - 当线程请求的栈深度超过虚拟机允许的栈深度时,便会抛出StackOverFlowError
-- -Xss设置的参数是针对每一个栈的,而非JVM所有线程栈内存总大小。
-- 每个方法的调用将创建一个栈帧。每一个方法调用时,都会创建一个栈帧,用于存储局部变量表、操作数栈、动态链接、方法出口等信息。
-- SUM(每个栈帧大小)>栈大小发生栈溢出
- 概念:在《Java虚拟机规范》中描述了两种异常:
调整栈内存jvm参数知道吗?常用的jvm参数有那些?
- 栈的参数配置
指令 作用 -Xss 指定线程的栈大小。栈是每个线程私有的内存空间。 递归10w次会出现什么?(OOM)
- 问题:栈溢出
- 原因:
-- 栈先进后出,方法压栈运行,递归过程先入的不能出栈,会存在栈空间中,这样就容易导致栈满而溢出。
-- 线程内部的每个方法调用会创建一个栈帧,所以如果“栈帧的数量*每个栈帧的大小>栈大小”时便会发生“栈溢出”。
-- 每当你调用一个方法,在这个方法执行前都会将之前的内存地址(也就是调用点)入栈,等被调用的方法执行完将地址出栈,程序根据这个数据返回调用点。
若递归调用次数太多,就会只入栈不出栈,于是堆栈就被压爆了,此为栈溢出。
递归函数调用的太深,需要太多的内存,递归里用到的局部变量存储在堆栈中,堆栈的访问效率高,速度快,但空间有限,递归太多变量需要一直入栈而不出栈,导致需要的内存空间大于堆栈的空间。 - 解决:可以考虑采取循环的方式来解决,将需要的数据在关键的调用点保存下来使用。即用自己的数据保存方法来代替系统递归调用产生的栈数据。
- 注:操作系统分配给一个进程的栈空间是2M,堆空间在32位机器上是4G。如果进程的栈空间使用超过了2M就会栈溢出,堆使用超过4G就会堆溢出。
栈溢出异常,通过什么方式来解决?
- HotSpot虚拟机不支持扩展支持栈的动态扩展
- 解决
-- 1)代码层面
将递归改为循环或保存数据(降低层次,或变量设为全局变量,这样它会被存在堆里(或其它地方))
-- 2)线上临时解决办法或者1)无法解决
重新调整JVM参数-Xss,重启应用
如-Xss将thread stack size变为2m - 如何设置
-- 首先,操作系统分配给每个进程的内存是有限制的。那么:
可用的栈内存=进程最大内存-堆内存-方法区内存-程序计数器内存-虚拟机本身耗费内存
-- 而栈是线程私有的,那么可以认为:
程序可建立的线程数量=可用栈内存/栈大小
-- 这样当栈大小设置太大时,就会导致创建的线程数量太少。这样在多线程的情况下便可能发生“内存溢出”情况。
-- 在x64位Linux操作系统上,JVM默认的栈大小为1024kb。
由于我们线上的程序要支持高并发场景,所以栈的大小设置为256kb,这里仅供参考。
怎么让方法区溢出?
- “永久代(Perm)”(jdk1.6/1.7),“元空间(meta-space)”(jdk1.8)用来实现方法区
jvms:一个系统不断产生新的类,而没有回收,最终可能导致永久区溢出。
// jdk1.6 -XX:MaxPermSize=5mpublic class PermOOM{public static void main(String[] args) {try {for (int i = 0; i <100000 ; i++) {// 每次循环都生成一个新的类(是类,而非对象实例)CglibBean bean = new CglibBean("geym.jvm.ch3.perm.bean"+i,new HashMap());}}catch (Error e){e.printStackTrace();}}}// 结果// Exception in thread "main" java.lang.OutOfMemoryError: PermGen space
解决永久区溢出,从以下几个方面考虑(jvms)
-- 增加MaxPermSize的值
-- 减少系统需要的类的数量
-- 使用ClassLoader合理地装载各个类,并定期进行回收
遇到过的OOM?
- 不断创建对象可以导致堆溢出 - 堆
- 递归调用可以导致栈溢出 - 栈
- 堆
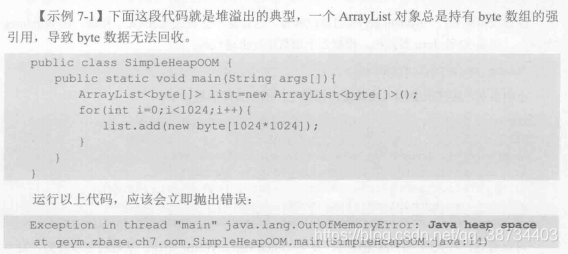
- 栈
递归|单线程|多线程
OOM 如何排查以及优化/OOM问题怎么定位(线上?) -P50
常规的处理方法(jvm3)- 首先通过内存映像分析工具对Dump出来的堆转储快照进行分析。
第一步首先应确认内存中导致OOM的对象是否是必要的,也就是要先分清楚到底是出现了内存泄漏(Memory Leak)还是内存溢出(Memory Overflow)。 - 如果是内存泄漏,可进一步通过工具查看泄漏对象到GC Roots的引用链,找到泄漏对象是通过怎样的引用路径、与哪些GC Roots相关联,才导致垃圾收集器无法回收它们,根据泄漏对象的类型信息以及它到GC Roots引用链的信息,一般可以比较准确地定位到这些对象创建的位置,进而找出产生内存泄漏的代码的具体位置。
- 如果不是内存泄漏,换句话说就是内存中的对象确实都是必须存活的,那就应当检查Java虚拟机的堆参数(-Xmx与-Xms)设置,与机器的内存对比,看看是否还有向上调整的空间。再从代码上检查是否存在某些对象生命周期过长、持有状态时间过长、存储结构设计不合理等情况,尽量减少程序运行期的内存消耗。
- 排查流程
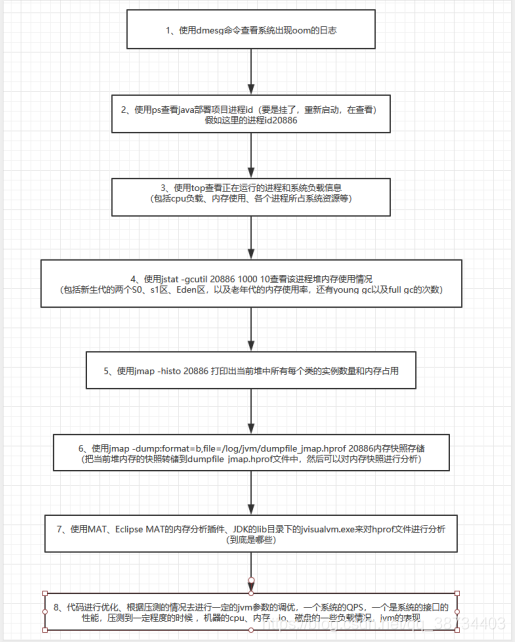
- 流程:https://www.cnblogs.com/c-xiaohai/p/12489336.html
https://blog.csdn.net/ywlmsm1224811/article/details/91866707
https://blog.csdn.net/wx1528159409/article/details/93530352#%E6%8E%92%E6%9F%A5%EF%BC%9A
2)优化: - 使用更小的图片
- StringBuilder来替代频繁的“+”
https://blog.csdn.net/weixin_41101173/article/details/79716332
- 首先通过内存映像分析工具对Dump出来的堆转储快照进行分析。
Java会不会内存泄露?怎样会泄露?
Java 内存泄漏问题,解释一下什么情况下会出现?
- Java使用的内存种类包含三种,这三种类型的内存都可能发生内存泄漏。
• 堆内存泄漏,如果JVM 不能在java 堆中获得更多内存来分配更多java 对象,将会抛出java堆内存不足(java OOM) 错误。如果java 堆充满了活动对象,并且JVM 无法再扩展java 堆,那么它将不能分配更多java 对象。更多情况是程序设计有问题,生成的对象占用过多的堆内存造成堆内存泄漏。
• 本地内存泄漏, 如果JVM 无法获得更多本地内存,它将抛出本地OOM错误。当进程用到的内存到达操作系统的最大限值,或者当计算机用完RAM 和交换空间时,通常会发生这种情况。当发生这种情况时,JVM处于本地内存OOM状态,此时虚拟机会打印相关信息并退出。本地内存泄漏根本原因是Java调用本地库或方法,这些本地库中的API有内存泄漏。
• 加载类(字节码)的Perm内存不足.即指定的Permsize不足以加载系统运行使用的.class字节码文件,就发发生Perm内存不足的错误。
- Java使用的内存种类包含三种,这三种类型的内存都可能发生内存泄漏。
3. 垃圾回收
垃圾回收,堆区为什么那么分
- 不过无论从什么角度,无论如何划分,都不会改变Java堆中存储内容的共性,无论是哪个区域,存储的都只能是对象的实例,将Java堆细分的目的只是为了更好地回收内存,或者更快地分配内存。(jvm3)
Java垃圾回收简单讲一下,里面的算法?
- 判断对象?标记算法?回收算法?收集器?
1-判断对象死亡
JVM 垃圾回收的是如何确定垃圾?
- 什么是垃圾
简单的说就是内存中已经不再被使用到的空间就是垃圾。
Person p = null;
- 什么是垃圾
java垃圾回收,如何判断一个对象需要回收
- 引用计数算法
- 可达性分析算法
具体:https://blog.csdn.net/weixin_38569499/article/details/85645517
引用计数算法 和 可达性分析算法
- 引用计数算法
在对象中添加一个引用计数器,每当有一个地方引用它时,计数器值就加一;
当引用失效时,计数器值就减一;任何时刻计数器为零的对象就是不可能再被使用的 - 优点
会占用了一些额外的内存空间来进行计数,原理简单,判定效率也很高,在大多数情况下它都是一个不错的算法。 缺点
必须要配合大量额外处理才能保证正确地工作,如单纯的引用计数就很难解决对象之间相互循环引用的问题。Object a = new Object();Object b = new Object();a=b;b=a;a=b=null; //这样就导致gc无法回收他们。
可达性分析算法
通过一系列称为“GC Roots”的根对象作为起始节点集,从这些节点开始,根据引用关系向下搜索,搜索过程所走过的路径称为“引用链”(Reference Chain),如果某个对象到GC Roots间没有任何引用链相连,或者用图论的话来说就是从GC Roots到这个对象不可达时,则证明此对象是不可能再被使用的。
缺点:实现比较复杂、需要分析大量数据,消耗大量时间、分析过程需要GC停顿(引用关系不能发生变化),即停顿所有Java执行线程(称为"Stop The World",是垃圾回收重点关注的问题)。
- 引用计数算法
是否知道什么是GC Roots?(jvm3)
- 固定可作为GC Roots的对象:
-- 在虚拟机栈(栈帧中的本地变量表)中引用的对象,譬如各个线程被调用的方法堆栈中使用到的参数、局部变量、临时变量等。
-- 在方法区中类静态属性引用的对象,譬如Java类的引用类型静态变量。
-- 在方法区中常量引用的对象,譬如字符串常量池(String Table)里的引用。
-- 在本地方法栈中JNI(即通常所说的Native方法)引用的对象。
-- Java虚拟机内部的引用,如基本数据类型对应的Class对象,一些常驻的异常对象(比如NullPointExcepiton、OutOfMemoryError)等,还有系统类加载器。
-- 所有被同步锁(synchronized关键字)持有的对象。
-- 反映Java虚拟机内部情况的JMXBean、JVMTI中注册的回调、本地代码缓存等。 - 临时GC Roots
-- 根据用户所选用的垃圾收集器以及当前回收的内存区域不 同,还可以有其他对象“临时性”地加入,共同构成完整GC Roots集合。
-- 如后文将会提到的分代收集和局部回收(Partial GC),如果只针对Java堆中某一块区域发起垃圾收集时(如最典型的只针对新生代的垃圾收集),必须考虑到内存区域是虚拟机自己的实现细节(在用户视角里任何内存区域都是不 可见的),更不是孤立封闭的,所以某个区域里的对象完全有可能被位于堆中其他区域的对象所引用,这时候就需要将这些关联区域的对象也一并加入GCRoots集合中去,才能保证可达性分析的正确性。
- 固定可作为GC Roots的对象:
哪些对象可以作为gcroot(jvm2)
- 1)虚拟机栈(栈帧中的本地变量表)中引用的对象
- 2)方法区中类静态属性引用的对象
- 3)方法区中常量引用的对象
- 4)本地方法栈中JNI(即Native方法)引用的对象
public class GCRootDemo{private static GCRootDemo2 t2;//第2种,static静态,一份全部实例变量共用?被加载进方法区,// Java7方法区为永久代;GCRootDemo2其他对象private static final GCRootDemo3 t3 = new GCRootDemo3(8);//static final常量引用public static void m1(){GCRootDemo t1 = new GCRootDemo();//第1种:m1方法在栈中,t1为方法中的局部变量System.gc();System.out.println("第一次GC完成");}public static void main(String[] args) {m1();}}
引用?
- ~
强引用:只有强引用还存在,GC就永远不会收集被引用的对象。
软引用:不占空间,gc不回收
弱引用:WeakReference 调用gc直接回收 ★
虚引用:PhantomReference 与队列结合使用,get不到 - 强引用:最传统的“引用”的定义,是指在程序代码之中普遍存在的引用赋值,即类似“Object obj=new Object()”这种引用关系。无论任何情况下,只要强引用关系还存在,垃圾收集器就永远不会回收掉被引用的对象。
- 软引用:用来描述一些还有用,但非必须的对象。只被软引用关联着的对象,在系统将要发生内存溢出异常前,会把这些对象列进回收范围之中进行第二次回收,如果这次回收还没有足够的内存,才会抛出内存溢出异常。在JDK1.2版之后提供了SoftReference类来实现软引用。
- 弱引用:也是用来描述那些非必须对象,但是它的强度比软引用更弱一些,被弱引用关联的对象只能生存到下一次垃圾收集发生为止。当垃圾收集器开始工作,无论当前内存是否足够,都会回收掉只被弱引用关联的对象。在JDK1.2版之后提供了WeakReference类来实现弱引用。
- 虚引用:也称为“幽灵引用”或者“幻影引用”,是最弱的一种引用关系。一个对象是否有虚引用的存在,完全不会对其生存时间构成影响,也无法通过虚引用来取得一个对象实例。为一个对象设置虚引用关联的唯一目的只是为了能在这个对象被收集器回收时收到一个系统通知。在JDK1.2版之后提供 了PhantomReference类来实现虚引用。
- ~
判断一个对象生存还是死亡?
- 第一次标记
如果对象进行可达性分析算法之后没发现与GC Roots相连的引用链,那它将会第一次标记并且进行一次筛选。
筛选条件:判断此对象是否有必要执行finalize()方法。
筛选结果:当对象没有覆盖finalize()方法、或者finalize()方法已经被JVM执行过,则判定为可回收对象。如果对象有必要执行finalize()方法,则被放入F-Queue队列中。稍后在JVM自动建立、低优先级的Finalizer线程(可能多个线程)中触发这个方法; - 第二次标记
GC对F-Queue队列中的对象进行二次标记。
如果对象在finalize()方法中重新与引用链上的任何一个对象建立了关联,那么二次标记时则会将它移出“即将回收”集合。如果此时对象还没成功逃脱,那么只能被回收了。 - finalize() 方法
finalize()是Object类的一个方法、一个对象的finalize()方法只会被系统自动调用一次,经过finalize()方法逃脱死亡的对象,第二次不会再调用;
https://www.cnblogs.com/chenpt/p/9797126.html
- 第一次标记
2-垃圾收集算法
4.jvm卡表(Card Table)?
安全区域(Safe Region),记忆集
垃圾回收算法有哪些
- 标记-清除
- 复制
- 标记-整理
- 分代收集算法
垃圾回收算法,为什么老年代和新生代不同
- 存活周期不同
1)弱分代假说(Weak Generational Hypothesis):绝大多数对象都是朝生夕灭的。 2)强分代假说(Strong Generational Hypothesis):熬过越多次垃圾收集过程的对象就越难以消亡。
- 存活周期不同
垃圾收集算法新生代和老年代分别用什么算法
- 回收新生代:大多使用复制算法
- 回收老年代:使用“标记-清理”或“标记-整理”算法
如果对象大部分都是存活的,少部分需要清除,用什么算法
- 新生代中,每次垃圾收集时都发现有大批对象死去,只有少量存活,那就选用复制算法,只需要付出少量存活对象的复制成本就可以完成收集。
- 老年代中,因为对象存活率高、没有额外空间对它进行分配担保,就必须使用“标记-清理”或“标记-整理”算法来进行回收。
名词概念
- 部分收集(Partial GC):指目标不是完整收集整个Java堆的垃圾收集,又分为:
■ 新生代收集(Minor GC/Young GC):指目标只是新生代的垃圾收集。
■ 老年代收集(Major GC/Old GC):指目标只是老年代的垃圾收集。目前只有CMS收集器会有单独收集老年代的行为。另外请注意“Major GC”这个说法现在有点混淆,在不同资料上常有不同所指, 读者需按上下文区分到底是指老年代的收集还是整堆收集。
■ 混合收集(Mixed GC):指目标是收集整个新生代以及部分老年代的垃圾收集。目前只有G1收集器会有这种行为。 - 整堆收集(Full GC):收集整个Java堆和方法区的垃圾收集。
- 部分收集(Partial GC):指目标不是完整收集整个Java堆的垃圾收集,又分为:
说说GC的流程
什么时候对象会到老年代,老年代的更新机制

- 分配
默认的,Edem : from : to = 8 : 1 : 1 ( 可以通过参数 –XX:SurvivorRatio 来设定 ) - 过程
当对象在 Eden 出生后,在经过一次 Minor GC 后,如果对象还存活,并且能够被另外一块 Survivor 区域所容纳( 上面已经假设为 from 区域,这里应为 to 区域,即 to 区域有足够的内存空间来存储 Eden 和 from 区域中存活的对象 ),则使用复制算法将这些仍然还存活的对象复制到另外一块 Survivor 区域 ( 即 to 区域 ) 中,然后清理所使用过的 Eden 以及 Survivor 区域 ( 即 from 区域 ),并且将这些对象的年龄设置为1,以后对象在 Survivor 区每熬过一次 Minor GC,就将对象的年龄 + 1,当对象的年龄达到某个值时 ( 默认是 15 岁,可以通过参数 -XX:MaxTenuringThreshold 来设定 ),这些对象就会成为老年代。
但这也不是一定的,对于一些较大的对象 ( 即需要分配一块较大的连续内存空间 ) 则是直接进入到老年代。 - JVM 每次只会使用 Eden 和其中的一块 Survivor 区域来为对象服务,所以无论什么时候,总是有一块 Survivor 区域是空闲着的。 如此往复
http://www.shaoqun.com/a/99944.html
https://blog.csdn.net/yangyang12345555/article/details/79257171
- 分配
3-回收器
垃圾回收器了解吗?
- 是什么?有哪些?做什么?
为何需要垃圾回收?
- Java垃圾收集机制为避免出现内存溢出异常。
有哪些gc收集器?
- 7个回收器
新生代收集器:Serial、ParNew、Parallel Scavenge
老年代收集器:CMS、Serial Old、Parallel Old
整堆收集器: G1
https://www.cnblogs.com/chenpt/p/9803298.html
易懂:https://blog.csdn.net/weixin_43228814/article/details/88934939
https://blog.csdn.net/qq_35246620/article/details/80522720
- 7个回收器
垃圾回收器在哪块?
- Java堆
- 收集器应该将Java堆划分出不同的区域,然后将回收对象依据其年龄(年龄即对象熬过垃圾收集过程的次数)分配到不同的区域之中存储。
- 在JVM体系结构中,与垃圾回收相关的两个主要组件是堆内存和垃圾回收器。堆内存是内存数据区,用来保存运行时的对象实例。垃圾回收器也会在这里操作。
垃圾回收器(CMS)详细过程。哪个阶段出现STW?
- 运作过程的四个步骤?
1)初始标记(CMS initial mark)
2)并发标记(CMS concurrent mark)
3)重新标记(CMS remark)
4)并发清除(CMS concurrent sweep) - 初始标记、重新标记:这两个步骤仍然需要“Stop The World”。
- 初始标记:仅仅只是标记一下GC Roots能直接关联到的对象,速度很快;
- 并发标记阶段:就是从GC Roots的直接关联对象开始遍历整个对象图的过程,这个过程耗时较长但是不需要停顿用户线程,可以与垃圾收集线程一起并发运行;
- 重新标记阶段:为修正并发标记期间,因用户程序继续运作而导致标记产生变动的那一部分对象的标记记录,这个阶段的停顿时间通常会比初始标记阶段稍长一些,但也远比并发标记阶段的时间短;
- 并发清除阶段:清理删除掉标记阶段判断的已经死亡的对象,由于不需要移动存活对象,所以这个阶段也是可以与用户线程同时并发的。
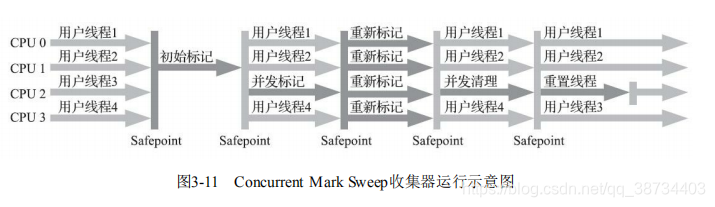
- 运作过程的四个步骤?
垃圾收集器CMS出现问题了怎么办?
- 1)promotion failed – concurrent mode failure
Minor GC后, 救助空间容纳不了剩余对象,将要放入老年带,老年带有碎片或者不能容纳这些对象,就产生了concurrent mode failure, 然后进行stop-the-world的Serial Old收集器。
-- 解决办法:-XX:UseCMSCompactAtFullCollection -XX:CMSFullGCBeforeCompaction=5 或者调大新生代或者救助空间 - 2)concurrent mode failure
CMS是和业务线程并发运行的,在执行CMS的过程中有业务对象需要在老年带直接分配,例如大对象,但是老年带没有足够的空间来分配,所以导致concurrent mode failure, 然后需要进行stop-the-world的Serial Old收集器。
-- 解决办法:+XX:CMSInitiatingOccupancyFraction,调大老年带的空间,+XX:CMSMaxAbortablePrecleanTime - 总结一句话:使用标记整理清除碎片和提早进行CMS操作。
- 两个问题:promotion failed和concurrent mode failure
- 解决:
第一个,可以让CMS在进行一定次数的Full GC的时候进行一次标记整理算法。
第二个,调低触发CMS GC执行的阀值。
https://my.oschina.net/hosee/blog/674181
- 1)promotion failed – concurrent mode failure
4-内存分配与回收策略
java内存管理?
- Java技术体系的自动内存管理,最根本的目标是自动化地解决两个问题
自动给对象分配内存以及自动回收分配给对象的内存。
- Java技术体系的自动内存管理,最根本的目标是自动化地解决两个问题
什么时候对象会到老年代,老年代的更新机制?
- 大对象直接进入老年代
-- 大对象就是指需要大量连续内存空间的Java对象,最典型的大对象便是那种很长的字符串,或者元素数量很庞大的数组
-- 避免大对象的原因:
在分配空间时,容易导致内存明明还有不少空间时就提前触发垃圾收集,以获取足够的连续空间才能安置好它们,而当复 制对象时,大对象就意味着高额的内存复制开销。
-- HotSpot中-XX:PretenureSizeThreshold
指定大于该设置值的对象直接在老年代分配,避免在Eden区及两个Survivor区之间来回复制,产生大量的内存复制操作。 - 长期存活的对象将进入老年代
-- 虚拟机给每个对象定义了一个对 象年龄(Age)计数器,存储在对象头中。
-- 对象通常在Eden区里诞生,如果经过第一次 Minor GC后仍然存活,并且能被Survivor容纳的话,该对象会被移动到Survivor空间中,并且将其对象年龄设为1岁。对象在Survivor区中每熬过一次Minor GC,年龄就增加1岁,当它的年龄增加到一定程度(默认为15),就会被晋升到老年代中。
-- -XX: MaxTenuringThreshold设置:对象晋升老年代的年龄阈值。 - 动态对象年龄判定
-- HotSpot虚拟机并不是永远要求对象的年龄必须达到-XX:MaxTenuringThreshold才能晋升老年代,如果在Survivor空间中相同年龄所有对象大小的总和大于Survivor空间的一半,年龄大于或等于该年龄的对象就可以直接进入老年代,无须等到-XX:MaxTenuringThreshold中要求的年龄。
-- -XX:MaxTenuringThreshold=15
-- 同年龄的,满足同年对象达到Survivor空间一半的规则
- 大对象直接进入老年代
操作系统层面是怎么分配内存的 91
https://blog.csdn.net/qq_32635069/article/details/74838187
4. 监控、故障处理工具
1-jstack((Stack Trace for Java))
- jstack原理
1)jstack定义-P111
- jstack用于生成java虚拟机当前时刻的线程快照
- 线程快照是当前java虚拟机内每一条线程正在执行的方法堆栈的集合,
- 生成线程快照的主要目的是定位线程出现长时间停顿的原因,如线程间死锁、死循环、请求外部资源导致的长时间等待等。
- 线程出现停顿的时候通过jstack来查看各个线程的调用堆栈,就可以知道没有响应的线程到底在后台做什么事情,或者等待什么资源。
2)实现 -P110 !!!
JDK 1.5中,java.lang.Thread类新增了一个getAllStackTraces()方法用于获取虚拟机中所有线程的StackTraceElement对象。使用这个方法可以通过简单的几行代码就完成jstack的大部分功能,在实际项目中不妨调用这个方法做个管理员页面,可以随时使用浏览器来查看线程堆栈。
3)使用
jstack [ option ] pid 如,jstack -l 3500
-l 长列表. 打印关于锁的附加信息。
4)jsp(JVM Process Status Tool)
可以列出正在进行的虚拟机进程,并显示虚拟机执行主类名称以及这些进程的本地虚拟机进程唯一ID(LVMID)---对应3)的pid
如,jsp -l
三、虚拟机执行子系统
6. .class文件
7. 虚拟机类加载机制
- java虚拟机类加载机制?
- jvm3:Java虚拟机把描述类的数据从Class文件加载到内存,并对数据进行校验、转换解析和初始化,最终形成可以被虚拟机直接使用的Java类型,这个过程被称作虚拟机的类加载机制。
1-时机
类加载的顺序?
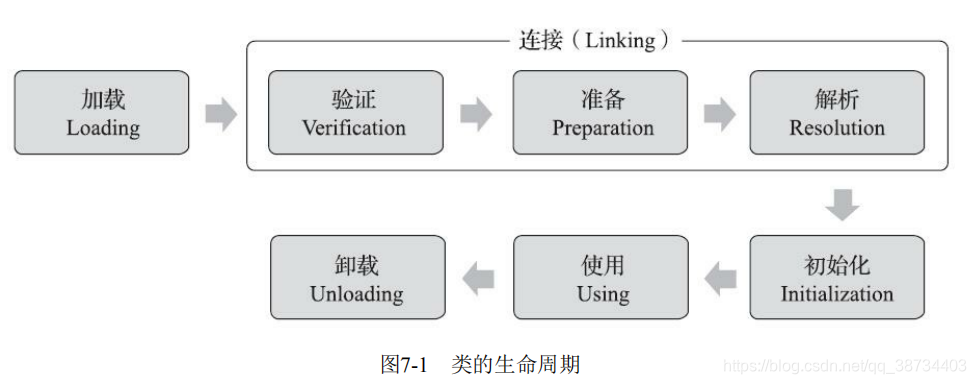
- 一个类从被加载到虚拟机内存中开始,到卸载出内存为止,它的整个生命周期将会经历加载(Loading)、验证(Verification)、准备(Preparation)、解析(Resolution)、初始化(Initialization)、使用(Using)和卸载(Unloading)七个阶段;
- 其中,验证、准备、解析三个部分统称为连接(Linking)。
- 加载、验证、准备、初始化和卸载这五个阶段的顺序是确定的,类的加载过程必须按照这种顺序按部就班地开始;
- 解析阶段:在某些情况下可以在初始化阶段之后再开始,这是为了支持Java语言的运行时绑定特性(也称为动态绑定或晚期绑定)。
- “开始”强调这些阶段通常都是互相交叉地混合进行的,会在一个阶段执行的过程中调用、激活另一个阶段。
- 七个阶段的发生顺序如图:
有哪些操作会触发类加载?
- 《Java虚拟机规范》中并没有对在什么情况下需要开始类加载过程的第一个阶段“加载”进行强制约束。但对于初始化阶段,则严格规定了有且只有六种情况必须立即对类进行“初始化”(而加载、验证、准备自然需要在此之前开始):
- 对一个类型进行主动引用,“有且只有”这六种场景中的行为称为。除此之外的所有引用类型的方式都不会触发初始化,称为被动引用;
- 【主动引用】
1)遇到new、getstatic、putstatic或invokestatic这四条字节码指令时,如果类型没有进行过初始化,则需要先触发其初始化阶段。能够生成这四条指令的典型Java代码场景有:
-- 使用new关键字实例化对象的时候。
-- 读取或设置一个类型的静态字段(被final修饰、已在编译期把结果放入常量池的静态字段除外)的时候。
-- 调用一个类型的静态方法的时候。
2)使用java.lang.reflect包的方法对类型进行反射调用的时候,如果类型没有进行过初始化,则需要先触发其初始化。
3)当初始化类的时候,如果发现其父类还没有进行过初始化,则需要先触发其父类的初始化。
4)当虚拟机启动时,用户需要指定一个要执行的主类(包含main()方法的那个类),虚拟机会先初始化这个主类。
5)当使用JDK 7新加入的动态语言支持时,如果一个java.lang.invoke.MethodHandle实例最后的解析结果为REF_getStatic、REF_putStatic、REF_invokeStatic、REF_newInvokeSpecial四种类型的方法句柄,并且这个方法句柄对应的类没有进行过初始化,则需要先触发其初始化。
6)当一个接口中定义了JDK8新加入的默认方法(被default关键字修饰的接口方法)时,如果有这个接口的实现类发生了初始化,那该接口要在其之前被初始化。 - 【被动引用】
1)通过子类引用父类的静态字段,不会导致子类初始化
2)通过数组定义来引用类,不会触发此类的初始化
3)常量在编译阶段会存入调用类的常量池中,本质上没有直接引用到定义常量的类,因此不会触发定义常量的 类的初始化 - 图示:https://blog.csdn.net/L_Mr_l/article/details/81909995
2-过程
类加载过程?
- 概念:
Java虚拟机中类加载的全过程,即加载、验证、准备、解析和初始化这五 个阶段所执行的具体动作。 - 1)加载
加载阶段,Java虚拟机需要完成以下三件事情:
① 通过一个类的全限定名来获取定义此类的二进制字节流。
② 将这个字节流所代表的静态存储结构转化为方法区的运行时数据结构。
③ 在内存中生成一个代表这个类的java.lang.Class对象,作为方法区这个类的各种数据的访问入口。 - 2)验证
验证是连接阶段的第一步,这一阶段的目的是确保Class文件的字节流中包含的信息符合《Java虚拟机规范》的全部约束要求,保证这些信息被当作代码运行后不会危害虚拟机自身的安全。
① 文件格式验证
② 元数据验证
③ 字节码验证
④ 符号引用验证 - 3)准备
准备阶段是正式为类中定义的变量(即静态变量,被static修饰的变量)分配内存并设置类变量初始值的阶段。
这些变量所使用的内存都应当在方法区中进行分配,但必须注意到方法区 本身是一个逻辑上的区域,在JDK7及之前,HotSpot使用永久代来实现方法区时,实现是完全符合这种逻辑概念的;而在JDK8及之后,类变量则会随着Class对象一起存放在Java堆中,这时候“类变量在方法区”就完全是一种对逻辑概念的表述了。 - 4)解析
Java虚拟机将常量池内的符号引用替换为直接引用的过程。
-- 符号引用(Symbolic References):
符号引用以一组符号来描述所引用的目标,符号可以是任何形式的字面量,只要使用时能无歧义地定位到目标即可。
-- 直接引用(Direct References):
直接引用是可以直接指向目标的指针、相对偏移量或者是一个能间接定位到目标的句柄。
① 类或接口的解析
② 字段解析
② 方法解析
③ 接口方法解析 - 5)初始化
初始化阶段就是执行类构造器()方法的过程。
- 概念:
详细说说类加载的过程,静态代码块执行在哪个阶段?
静态代码块在初始化阶段执行
https://blog.csdn.net/qq_36839438/article/details/106738514
https://blog.csdn.net/qq_38159458/article/details/105865964
3-类加载器
类加载器的4个种类
1)启动类加载器:这个类加载器负责放在目录中的,或者被-Xbootclasspath参数所指定的路径中的,并且是虚拟机识别的类库。用户无法直接使用。
2)扩展类加载器:这个类加载器由AppClassLoader\lib\ext由sun.misc.Launcher实现。是ClassLoader中getSystemClassLoader()方法的返回值。它负责用户路径(ClassPath)所指定的类库。用户可以直接使用。如果用户没有自己定义类加载器,默认使用这个。
4)自定义加载器:用户自己定义的类加载器。双亲委派模型
双亲委派模型:- 定义:上述4种展示的类加载之间的层次关系称为xxx。
- 优点:Java类随着它的类加载器一起具备了一种带有优先级的层次关系。
- 双亲委托模型的工作过程是:如果一个类加载器(ClassLoader)收到了类加载的请求,它首先不会自己去尝试加载这个类,而是把这个请求委托给父类加载器去完成,每一个层次的类加载器都是如此,因此所有的加载请求最终都应该传送到顶层的启动类加载器中,只有当父类加载器反馈自己无法完成这个加载请求(它的搜索范围中没有找到所需要加载的类)时,子加载器才会尝试自己去加载。
https://blog.csdn.net/qq_35758236/article/details/81115320
为啥要双亲加载
- 使用双亲委托机制的好处是:能够有效确保一个类的全局唯一性,当程序中出现多个限定名相同的类时,类加载器在执行加载时,始终只会加载其中的某一个类。
双亲委派机制,怎么打破
tomcat
四、程序编译与代码优化
- 说一说为什么要有JIT
JIT是经过一系列的分析和热点代码探测技术,对一部分class字节码编译成机器语言,以此提高性能,而解释器就是执行一句class字节码,就翻译成一句机器语言。JIT的存在,减少对热点代码的重复翻译。
https://www.jianshu.com/p/ae0d47e770f0
https://www.cnblogs.com/xuyatao/p/6914769.html
JVM堆上会不会产生线程安全问题 pP48
- 对象的内存分配过程中,主要是对象的引用指向这个内存区域,然后进行初始化操作。Java堆确定出一块内存区域,用于给新建对象分配内存。
- 在并发场景中,如果两个线程先后把对象引用指向了同一个内存区域,如何内存分配过程的线程安全性?
- 一般有两种解决方案:
1、对分配内存空间的动作做同步处理,采用CAS机制,配合失败重试的方式保证更新操作的原子性。
2、每个线程在Java堆中预先分配一小块内存,然后再给对象分配内存的时候,直接在自己这块"私有"内存中分配,当这部分区域用完之后,再分配新的"私有"内存。
方案1在每次分配时都需要进行同步控制,这种是比较低效的。
方案2是HotSpot虚拟机中采用的,这种方案被称之为TLAB分配,即Thread Local Allocation Buffer。这部分Buffer是从堆中划分出来的,但是是本地线程独享的。
TLAB时线程独享的,但是只是在“分配”这个动作上是线程独占的,至于在读取、垃圾回收等动作上都是线程共享的。
https://juejin.im/post/5d4250def265da03ab422c79
那比如你在项目里写了一个Class A,然后在某一个jar包里也有一个Class A,比如com.a.A,那么这两个class你觉得哪个先被加载,会出现什么问题(不会,求了答案,告诉我说他也不清楚,就是考考我对这块有没有自己的理解😑)
字节码是什么?
字节码:Java程序无须重新编译便可在多种不同的计算机上运行。
字节码(Byte-code)是一种包含执行程序,由一序列 op 代码/数据对组成的二进制文件,是一种中间码。 javap -c
※ 3-并发编程 ※
一、预备知识
| 进程线程 | 一致性 |
|---|
一个进程是怎么跑起来的?
- 程序如何运行:程序(源文件)在硬盘上,需要把程序加载进内存,然后由CPU去执行相应的指令去操作寄存器中的数据(从内存中装载进来),比如加减乘除什么的。
- 写->硬盘;运行->内存;指令操作->cpu寄存器
操作系统进程间通信(IPC)?
进程间数据共享吗,为什么
- 为什么:多个进程同时修改数据共享的那个数据时,会出现数据不安全性,解决办法是加锁;
- 实现:
-- ① multiprocessing.Manager模块、② multiprocessing.Queue(代码启动的进程子进程之间)、
-- 跨电脑、跨代码的进程间通信:
③ 消息中间件:kafak(大数据的消息中间件)、rebbitmq、memcache
线程进程(协程)区别? |3 结合具体的操作系统windows/mac/linux?
- jg:从JVM的角度来说一下线程和进程之间的关系,下图:
一个进程中可以有多个线程,多个线程共享进程的堆和方法区 (JDK1.8 之后的元空间)资源,但是每个线程有自己的程序计数器、虚拟机栈 和本地方法栈。 - 总结:
-- 线程是进程划分成的更小的运行单位,一个进程在其执行的过程中可以产生多个线程。
-- 线程和进程最大的不同在于基本上各进程是独立的,而各线程则不一定,因为同一进程中的线程极有可能会相互影响。
-- 线程执行开销小,但不利于资源的管理和保护;而进程正相反。

- jg:从JVM的角度来说一下线程和进程之间的关系,下图:
缓存一致性问题?
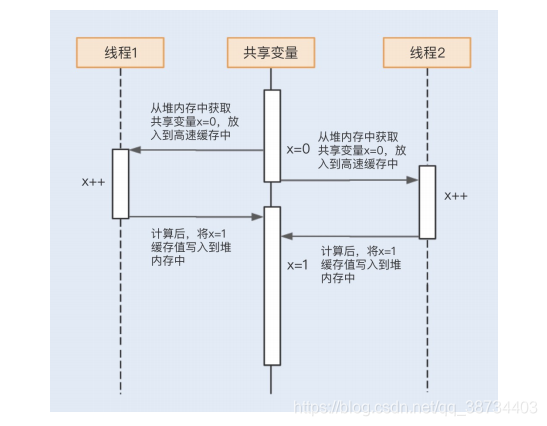
假设有两个线程(线程 1 和线程 2)分别执行下面的方法,x 是共享变量:
public class Example {int x = 0;public void count() {x++; //1System.out.println(x)//2}}
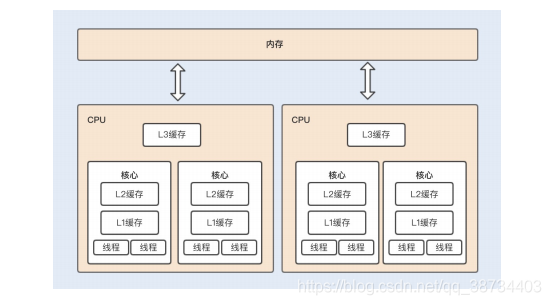
多核CPU:
如果是多核CPU运行多线程,每个核都有一个L1缓存,如果多个线程运行在不同的内核上访问共享变量时,每个内核的 L1 缓存将会缓存一份共享变量。
- 1,1 的运行结果:
有没有了解过缓存一致性协议,CPU-Cache角度?
- 解决缓存不一致问题
- 是一种广泛使用的支持写回策略的缓存一致性协议,该协议被应用在Intel奔腾系列的CPU中;
-- MESI分别代表缓存行数据所处的四种状态,通过对这四种状态的切换,来达到对缓存数据进行管理的目的。
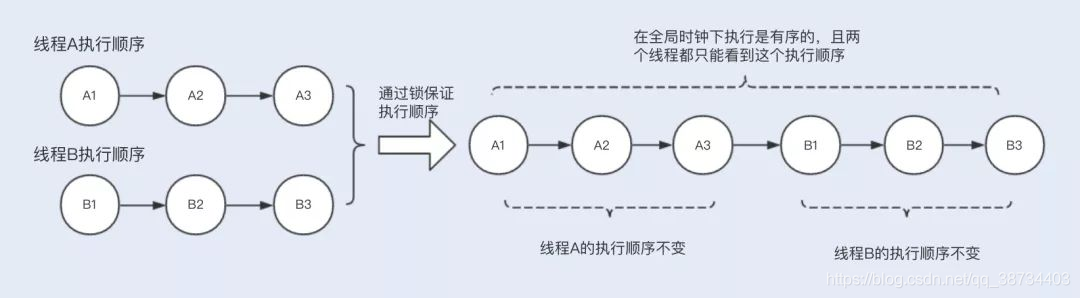
什么是强一致性?
结合Happens-before规则,可以将一致性分为以下几个级别:- 严格一致性(强一致性):所有的读写操作都按照全局时钟下的顺序执行,且任何时刻线程读取到的缓存数据都是一样的,Hashtable 就是严格一致性;
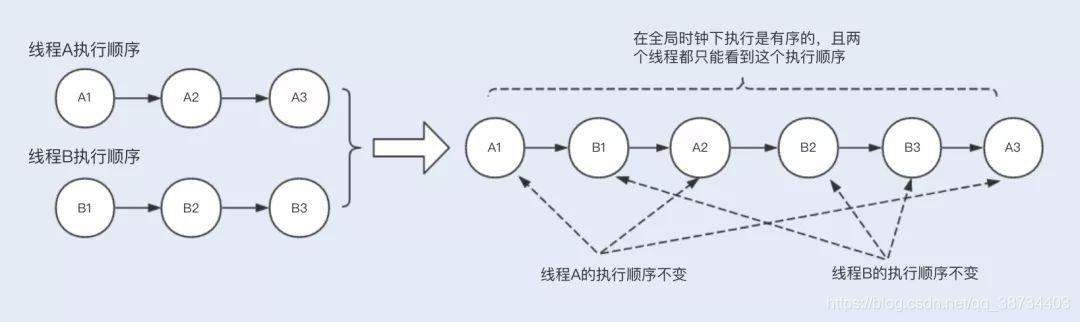
- 顺序一致性:多个线程的整体执行可能是无序的,但对于单个线程而言执行是有序的,要保证任何一次读都能读到最近一次写入的数据,volatile可以阻止指令重排序,所以修饰的变量的程序属于顺序一致性;
- 弱一致性:不能保证任何一次读都能读到最近一次写入的数据,但能保证最终可以读到写入的数据,单个写锁+无锁读,就是弱一致性的一种实现。
- 严格一致性(强一致性):所有的读写操作都按照全局时钟下的顺序执行,且任何时刻线程读取到的缓存数据都是一样的,Hashtable 就是严格一致性;
二、并发理论基础
1. 线程安全
| 线程安全的问题 | 线程安全的概念 | 实现线程安全的方法 |
|---|
Java并发中会遇到那些问题?
- ans:安全、活跃、性能
- 1-安全性:
-- 问题:会出现原子性问题、可见性问题和有序性问题线程不安全问题。
-- 有多个线程会同时读写同一数据,需要一一考虑原子性问题、可见性问题和有序性问题
-- 数据竞争:当多个线程同时访问同一数据,并且至少有一个线程会写这个数据的时候,如果我们不采取防护措施,那么就会导致并发Bug
-- 竞态条件:指的是程序的执行结果依赖线程执行的顺序
-- 解决:锁 - 2-活跃性:
-- 概念:指的是某个操作无法执行下去。
-- 活跃性问题:死锁、活锁、饥饿
① 死锁:发生“死锁”后,线程会互相等待,而且会一直等待下去,技术上表现形式是线程永久地“阻塞”了。
② 活锁:线程没发生阻塞,但仍存在执行不下去的情况。
解决:尝试等待等待一个随机时间
③ 饥饿:指的是线程因无法访问所需资源而无法执行下去的情况。
三种解决方案:
一是保证资源充足,二是公平地分配资源,三就是避免持有锁的线程长时间执行。
-- 一、三的适用场景比较有限,因为很多场景下,资源的稀缺无法解决的,持有锁的线程执行的时间也很难缩短。
-- 公平地分配资源
并发编程里,主要使用公平锁,一种先来后到的方案,线程的等待是有顺序的,排在等待队列前面的线程会优先获得资源。 - 3-性能问题
-- 衡量标准:吞吐量、延迟和并发量
-- 尽量减少串行
-- 避免锁带来的性能问题
什么是线程安全问题?
1)《深入理解Java虚拟机》原文:
当多个线程访问同一个对象时,如果不用考虑这些线程在运行时环境下的调度和交替运行,也不需要进行额外的同步,或者在调用方进行任何其他的协调操作,调用这个对象的行为都可以获取正确的结果,那这个对象是线程安全的。
2)线程安全的问题原因
一般是主内存和工作内存数据不一致性、重排序导致。
3)例子
① 数据不一致
在i++一组指令执行过程中,cpu是有可能切换线程的,如果在当前线程t1被挂起之后其他线程修改了这个对象的a属性值,那么恢复线程执行时t1线程将会覆盖其他线程已经修改过的值。
https://blog.csdn.net/yongjie910203/article/details/79763382
② 指令重排java线程安全都体现在哪些方面
- ans:原子性、可见性、有序性
- 原子性:提供互斥访问,同一时刻只能有一个线程对数据进行操作,(atomic,synchronized);
- 可见性:一个线程对主内存的修改可以及时地被其他线程看到,(synchronized,volatile);
- 有序性:一个线程观察其他线程中的指令执行顺序,由于指令重排序,该观察结果一般杂乱无序,(happens-before原则)。
说说怎么理解线程安全
优:从底层CPU开始说怎么保证线程安全(三个方式) |2
- 不在线程之间共享变量
- 使变量修改为不可变的变量(final类型)
- 访问共享变量时加上同步
- 有共享变量可以通过什么方式来保证线程安全?
- Java是如何保证其安全性的?
答了C语言手动内存管理和JVM GC保证一定程度上的内存安全、内存不泄露
线程安全怎么实现
1)互斥同步(/阻塞同步)
同步:共享数据在同一个时刻只被一条(/一些|信号量)线程使用。
互斥:实现同步的一种手段,互斥实现方式主要是临界区(Critical Section)、互斥量(Mutex)和信号量(Semaphore)
Java中实现:synchronized关键字、JUC中的重入锁(ReentrantLock)
问题:线程阻塞和唤醒所带来的性能问题
2)非阻塞同步
3)无同步方案
Java中实现:可重入代码、线程本地存储java线程间通信? |2
- 线程间通信的模型有两种:共享内存和消息传递
- 共享内存:volatile 关键字、synchronized关键字同步、JUC工具类 CountDownLatch
- 消息传递:Object类的wait() 和 notify() 方法
待完善:https://aalion.github.io/2019/12/28/concurrency11/
https://blog.csdn.net/jisuanji12306/article/details/86363390
https://www.cnblogs.com/lgyxrk/p/10404839.html
说说java保证线程间同步的方法 | 2
使用同步方法 public synchronized void save(){}
使用同步代码块synchronized(object){}
使用特殊域变量(volatile)实现线程同步
使用重入锁ReetrantLock实现线程同步
使用局部变量实现线程同步 ThreadLocal
使用阻塞队列实现线程同步 LinkedBlockingQueue
使用原子变量实现线程同步AtomicInteger
线程间的同步的方式有哪些呢?
🙋 :线程同步是两个或多个共享关键资源的线程的并发执行。应该同步线程以避免关键的资源使用冲突。操作系统一般有下面三种线程同步的方式:
互斥量(Mutex):采用互斥对象机制,只有拥有互斥对象的线程才有访问公共资源的权限。因为互斥对象只有一个,所以可以保证公共资源不会被多个线程同时访问。比如 Java 中的 synchronized 关键词和各种 Lock 都是这种机制。
信号量(Semphares) :它允许同一时刻多个线程访问同一资源,但是需要控制同一时刻访问此资源的最大线程数量
事件(Event) :Wait/Notify:通过通知操作的方式来保持多线程同步,还可以方便的实现多线程优先级的比较操单例模式?哪种单例模式最好?
单例模式双重检验的问题?
2. JMM
|并发知识|
0-JMM
Java内存模型(Java Memory Model,JMM) -P39
1) Java线程间的通信采用的是共享Java内存模型(简称JMM),JMM决定一个线程对共享变量的写入何时对另一个线程可见.
2) Java内存模型
- JMM本身是一种抽象的概念,并不真实存在,它描述的是一组规则或规范,通过这组规范定义了程序中各个变量(包括实例字段,静态字段和构成数组对象的元素)的访问方式。
- JMM三大特性:可见性、原子性、有序性
- Java内存模型把内存分成了两部分:线程栈区和堆区
JVM中运行的每个线程都拥有自己的线程栈,线程栈包含了当前线程执行的方法调用相关信息,我们也把它称作调用栈。线程栈还包含了当前方法的所有本地变量信息。
堆区包含了Java应用创建的所有对象信息,不管对象是哪个线程创建的,其中的对象包括原始类型的封装类(如Byte、Integer、Long等等)。不管对象是属于一个成员变量还是方法中的本地变量,它都会被存储在堆区。
谈谈JMM(sxt2) 参考:volitile部分
- JMM(Java内存模型,Java Memory Model)本身是一种抽象的概念并不真实存在,它描述的是一组规则或规范,通过这组规范定义了程序中各个变量(包括实例字段,静态字段和构成数组对象的元素)的访问方式。
- JMM三大特性:为线程安全得到保证
① 可见性:主内存有更改,工作内存第一时间被通知改变
② 原子性:
③ 有序性 - JMM关于同步的规定
1、线程解锁前,必须把共享变量的值刷新回主内存;
2、线程加锁前,必须读取主内存的最新值到自己的工作内存;
3、加锁解锁是同一把锁; - 由于JVM运行程序的实体是线程,而每个线程创建时JVM都会为其创建一个工作内存(有些地方称为栈空间),工作内存是每个线程的私有数据区域,而Java内存模型中规定所有的变量都存储在主内存,主内存是共享内存区域,所有的线程都可以访问,但线程对变量的操作(读取赋值等)必须在工作内存中进行,首先要将变量从主内存拷贝到自己的工作内存空间,然后对变量进行操作,操作完成后在将变量写回主内存,不能直接操作主内存中的变量,各个线程的工作内存中存储着主内存中的变量副本拷贝,因此不同的线程间无法访问对方的工作内存,线程间的通信必须通过主内存来完成。

- 注:存储 硬盘<内存(<缓存Cache) 主内存、线程自己的工作内存
1-volatile
说说volatile?(sxt2)
- volatile是Java提供的轻量级的同步机制(轻量级synchronized)
- 三个特性:① 保证内存可见性 ② 不保证原子性 ③ 禁止指令重排序
(Volatile 变量具有 synchronized 的可见性特性,但是不具备原子特性。防止指令重排。) - Ⅰ 可见性
1.① 保证内存可见性(sxt2)volatile有什么特点,怎么保证可见性的
volatile可以保证可见性,及时通知其他线程,主物理内存的值已被修改。 - 可见性的保证是基于 CPU 的内存屏障指令, 抽象为 happens-before 原则,确保一个线程的修改能对其他线程是可见的。
- volatile保证了修饰的共享变量在转换为汇编语言时,会加上一个以lock为前缀的指令,当CPU发现这个指令时,立即会做两件事情:
将当前内核中线程工作内存中该共享变量刷新到主存;
通知其他内核里缓存的该共享变量内存地址无效; - happens-before
① 作用:指定两个操作之间的执行顺序。即:如果A线程的写操作a与B线程的读操作b之间存在happens-before关系,尽管a操作和b操作在不同的线程中执行,但JMM向程序员保证a操作将对b操作可见。
②示例:A happens-before B: A操作的结果将对B可见,且A的执行顺序排在B之前。
另一个线程改动了变量(volatile修饰的),先写到工作内存还是主内存
- volatile修饰的变量在被修改后会处理器直接将结果stroe和write进主内存,同时使得其他线程的工作内存缓存失效,实现可见性
https://www.sohu.com/a/399318783_120591934
- volatile修饰的变量在被修改后会处理器直接将结果stroe和write进主内存,同时使得其他线程的工作内存缓存失效,实现可见性
Ⅱ 非原子性
② 不保证原子性(sxt2)
1) 不保证原子性,会出现写丢失(写覆盖),线程太快
2)i++在多线程下是非线程安全的,如何不加synchronized解决?- volatile 的一个重要作用就是和 CAS 结合,保证了原子性,详细的可以参见 java.util.concurrent.atomic 包下的类,比如 AtomicInteger。
https://blog.csdn.net/weixin_40460171/article/details/106473323 - jdk1.8的并发包来说,底层基本上就是通过Usafe和CAS机制来实现的。
https://baijiahao.baidu.com/s?id=1647621616629561468&wfr=spider&for=pc
- volatile 的一个重要作用就是和 CAS 结合,保证了原子性,详细的可以参见 java.util.concurrent.atomic 包下的类,比如 AtomicInteger。
volatile不保证原子性的原因
- i++被拆分3个指令:(字节码)Ⅰ 执行getfield拿到原始n;Ⅱ 执行iadd进行加1;Ⅲ 执行putfile写吧累加后的值写回
- 写覆盖:拷贝回自己的内存空间,每个人都拿到0,写回到主内存时,线程1写回到的时候被挂起了,线程2歘的写回了。然后线程1恢复后又写回了一遍,把原来的1给覆盖了。
- 解决:AtomicInteger 保证原子性
addAndget[++i]、getAndAdd[i++]
decrementAndGet、getAndDecrement【加1】
Ⅲ 禁止指令重排
③ 禁止指令重排序(sxt2)- 为了提高性能,编译器和处理器常常会对指令进行重排序。一般分为如下3种:

- 处理器在进行指令重排时,必须考虑指令之间的数据依赖(数据依赖不可重排)
- 重排示例2
多线程环境中线程交替执行,由于编译器优化重排的存在,两个线程中使用的变量能否保证一致性是无法确定的,结果无法预测。
public class Test{int a = 0;boolean flag = flse;public void method1(){a = 1; // 这两个语句会发生编译器重排flag = true;}public void method2(){if(flag){a = a + 5;sout("retVale:" + a);}}}
- 为了提高性能,编译器和处理器常常会对指令进行重排序。一般分为如下3种:
volatile如何禁止指令重排(sxt2)
- volatile实现进制指令重排优化,从而避免多线程环境下程序出现乱序执行的现象。
- 首先了解一个概念,内存屏障(Memory Barrier)又称内存栅栏,是一个CPU指令,它的作用有两个:
① 保证特定操作的顺序
② 保证某些变量的内存可见性(利用该特性实现volatile的内存可见性)
由于编译器和处理器都能执行指令重排的优化,如果在指令间插入一条Memory Barrier则会告诉编译器和CPU,不管什么指令都不能和这条Memory Barrier指令重排序,也就是说 通过插入内存屏障禁止在内存屏障前后的指令执行重排序优化。 内存屏障另外一个作用是刷新出各种CPU的缓存数,因此任何CPU上的线程都能读取到这些数据的最新版本。(注,即可见性)

即就是过在Volatile的写和读的时候,加入屏障,防止出现指令重排的
(
在每个volatile写操作的前面插入一个StoreStore屏障;
在每个volatile写操作的后面插入一个StoreLoad屏障;
在每个volatile读操作的后面插入一个LoadLoad屏障;
在每个volatile读操作的后面插入一个LoadStore屏障。
注意:volatile写是在前面和后面分别插入内存屏障,而volatile读操作是在后面插入两个内存屏障
) - 线程安全获得保证
① 工作内存与主内存同步延迟现象导致的可见性问题
可通过synchronized或volatile关键字解决,他们都可以使一个线程修改后的变量立即对其它线程可见
② 对于指令重排导致的可见性问题和有序性问题
可以使用volatile关键字解决,因为volatile关键字的另一个作用就是禁止重排序优化
Ⅳ 怎么用
volatile在哪里使用(sxt2)
volatile 常用于多线程环境下的单次操作(单次读或者单次写)。
1) 双重检测(Double Check Lock,DCL):(https://blog.csdn.net/qq_38734403/article/details/106976266)- 问题:DCL机制不一定线程安全,原因是有指令重排序的存在,加入volatile可以禁止指令重排。
- instance = new SingletonDemo();可以分为以下3步骤完成(伪代码)
memory = allocate(); //1.分配对象内存空间instance(memory); //2.初始化对象instance = memory; //3.设置instance指向刚分配的内存地址,此时instance != null
步骤2和步骤3***不存在数据依赖关系*,而且无论重排前还是重排后程序的执行结果在单线程中没有改变,因此这种重排优化是允许的。
memory = allocate(); //1.分配对象内存空间instance = memory; //3.设置instance指向刚分配的内存地址,此时instance != null,但是对象还没有初始化完成!instance(memory); //2.初始化对象
但是指令重排只会保证穿行语义的执行的一致性(单线程),但并不会关心多线程间的语义一致性。所以当一条线程访问instance不为null时,由于instance实例未必已初始化完成,也就造成了线程安全问题。
volatile的特性? |2
- 三个特性:① 保证内存可见性 ② 不保证原子性 ③ 禁止指令重排序
Volatile实现原理/底层实现? &作用
- 可见性的保证是基于 CPU 的内存屏障指令,抽象为happens-before原则
- volatile的一个重要作用就是和 CAS 结合,保证了原子性
- Volatile的写和读的时候,加入屏障,防止出现指令重排
怎么保证可见性的?
- 如上
禁止重排序的场景?
- volatile 常用于多线程环境下的单次操作(单次读或者单次写)。
单例模式中volatile的作用?
- 禁止指令重排。
共享变量 long a当两个线程来读a的时候会发生什么?
- long存储的前32bit和后32bit可能不是同时更新
- volatile 除了保证可见性和有序性, 还解决了 long 类型和 double 类型数据的 8 字节赋值问题.
虚拟机规范中允许对 64 位数据类型, 分为 2 次 32 位的操作来处理, 当读取一个非 volatile 类型的 long 变量时,如果对该变量的读操作和写操作不在同一个线程中执行, 那么很有可能会读取到某个值得高 32 位和另一个值得低 32 位.
详细:
2-synchronized
volatile和synchronized的区别?
区别Synchronized 和 lock的区别?
见-Lock&Condition部分synchronized怎么用:答:四种用法,
- synchronized是是一种同步锁:
1)修饰一个代码块,被修饰的代码块称为同步语句块,其作用的范围是大括号{}括起来的代码,作用的对象是调用这个代码块的对象;
2)修饰一个方法,被修饰的方法称为同步方法,其作用的范围是整个方法,作用的对象是调用这个方法的对象;
3)修饰一个静态的方法,其作用的范围是整个静态方法,作用的对象是这个类的所有对象;
4)修饰一个类,其作用的范围是synchronized后面括号括起来的部分,作用主的对象是这个类的所有对象。 - 各种修饰实现例子
- synchronized是是一种同步锁:
synchronize(A.class)什么情况?会不会竞争锁?
- 修饰一个类
修饰静态方法时锁的是什么资源?答:类
1)当synchronized修饰一个static方法时,多线程下,获取的是类锁(即Class本身,注意:不是实例),
作用范围是整个静态方法,作用的对象是这个类的所有对象。
2)当synchronized修饰一个非static方法时,多线程下,获取的是对象锁(即类的实例对象),
作用范围是整个方法,作用对象是调用该方法的对象
3)类锁和对象锁区别- 类锁和对象锁,一个是类的Class对象的锁,一个是类的实例的锁。
- 对于普通同步方法,锁是当前实例对象。
- 对于静态同步方法,锁是当前类的Class对象。
- 对于同步方法块,锁是Synchonized括号里配置的对象。
synchornized的底层原理? |3
- ⭐参考-很底层
- Java虚拟机中的同步(Synchronization)基于进入和退出管程(Monitor)对象实现,无论是显式同步还是隐式同步都是如此。
-- 显式同步-同步代码块:有明确的 monitorenter 和 monitorexit 指令,即同步代码块
-- 隐式同步-同步方法:synchronized修饰的同步方法是Java中同步用的最多;由方法调用指令读取运行时常量池中方法的ACC_SYNCHRONIZED标志来隐式实现的
(1)synchronized同步代码块:synchronized关键字经过编译之后,会在同步代码块前后分别形成monitorenter和monitorexit字节码指令,在执行monitorenter指令的时候,首先尝试获取对象的锁,如果这个锁没有被锁定或者当前线程已经拥有了那个对象的锁,锁的计数器就加1,在执行monitorexit指令时会将锁的计数器减1,当减为0的时候就释放锁。如果获取对象锁一直失败,那当前线程就要阻塞等待,直到对象锁被另一个线程释放为止。
(2)同步方法:方法级的同步是隐式的,无须通过字节码指令来控制,JVM可以从方法常量池的方法表结构中的ACC_SYNCHRONIZED访问标志得知一个方法是否声明为同步方法。当方法调用的时,调用指令会检查方法的ACC_SYNCHRONIZED访问标志是否被设置,如果设置了,执行线程就要求先持有monitor对象,然后才能执行方法,最后当方法执行完(无论是正常完成还是非正常完成)时释放monitor对象。在方法执行期间,执行线程持有了管程,其他线程都无法再次获取同一个管程。
https://blog.csdn.net/javazejian/article/details/72828483
(3) Synchronized 修饰方法如何实现锁原理 - JVM 中的同步是基于进入和退出管程(Monitor)对象实现的。每个对象实例都会有一个Monitor,Monitor可以和对象一起创建、销毁。Monitor 是由 ObjectMonitor 实现,而ObjectMonitor 是由 C++ 的 ObjectMonitor.hpp 文件实现。
- 当多个线程同时访问一段同步代码时,多个线程会先被存放在 EntryList 集合中,处于block状态的线程,都会被加入到该列表。接下来当线程获取到对象的 Monitor 时,Monitor 是依靠底层操作系统的 Mutex Lock 来实现互斥的,线程申请 Mutex 成功,则持有该 Mutex,其它线程将无法获取到该 Mutex。如果线程调用 wait() 方法,就会释放当前持有的 Mutex,并且该线程会进入 WaitSet 集合中,等待下一次被唤醒。如果当前线程顺利执行完方法,也将释放 Mutex。

synchronized在1.6之后的改动?
- JDK1.6 对锁的实现引入了大量的优化,如偏向锁、轻量级锁、自旋锁、适应性自旋锁、锁消除、锁粗化等技术来减少锁操作的开销。
- 锁主要存在四种状态,依次是:无锁状态、偏向锁状态、轻量级锁状态、重量级锁状态,他们会随着竞争的激烈而逐渐升级。注意锁可以升级不可降级,这种策略是为了提高获得锁和释放锁的效率。
JDK1.8是如何对synchronzied进行优化的 |2
synchronized怎么实现线程安全的
同步方法、同步代码块 + 原理
https://www.jianshu.com/p/7ddb0956590c
不一定安全:https://www.cnblogs.com/liyunfeng17/p/10891293.htmlsynchronized可重入实现
定义:
synchronized是可重入锁:
当一个线程再次请求自己持有对象锁的临界资源时,这种情况属于重入锁。
在java中synchronized是基于原子性的内部锁机制,是可重入的,因此在一个线程调用synchronized方法的同时在其方法体内部调用该对象另一个synchronized方法,也就是说一个线程得到一个对象锁后再次请求该对象锁,是允许的,这就是synchronized的可重入性。需要特别注意另外一种情况,当子类继承父类时,子类也是可以通过可重入锁调用父类的同步方法。
实现:
synchronized是基于monitor实现的,因此每次重入,monitor中的计数器仍会加1。
每个锁关联一个线程持有者和一个计数器。当计数器为0时表示该锁没有被任何线程持有,那么任何线程都都可能获得该锁而调用相应方法。当一个线程请求成功后,JVM会记下持有锁的线程,并将计数器计为1。此时其他线程请求该锁,则必须等待。而该持有锁的线程如果再次请求这个锁,就可以再次拿到这个锁,同时计数器会递增。当线程退出一个synchronized方法/块时,计数器会递减,如果计数器为0则释放该锁。还知道哪些加锁方式(重入锁)和 Synchronized 有哪些不同?
- java中常用的可重入锁
① synchronized
② java.util.concurrent.locks.ReentrantLock - 区别-见-Lock部分
- java中常用的可重入锁
锁升级
对象头
- 对象实例在堆内存中被分为了三个部分:对象头、实例数据和对齐填充。
- Java 对象头由 Mark Word、指向类的指针以及数组长度三部分组成。
- 锁升级功能主要依赖于 Mark Word 中的锁标志位和释放偏向锁标志位,
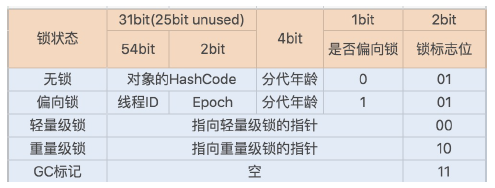
偏向锁
- 偏向锁主要用来优化同一线程多次申请同一个锁的竞争。
- 偏向锁的作用就是,
当一个线程再次访问这个同步代码或方法时,该线程只需去对象头的Mark Word 中去判断一下是否有偏向锁指向它的 ID,无需再进入 Monitor去竞争对象了。当对象被当做同步锁并有一个线程抢到了锁时,锁标志位还是 01,“是否偏向锁”标志位设置为 1,并且记录抢到锁的线程 ID,表示进入偏向锁状态。 - 升级
一旦出现其它线程竞争锁资源时,偏向锁就会被撤销。偏向锁的撤销需要等待全局安全点,暂停持有该锁的线程,同时检查该线程是否还在执行该方法,如果是,则升级锁,反之则被其它线程抢占。 - 在高并发场景下,当大量线程同时竞争同一个锁资源时,偏向锁就会被撤销,发生stop the word 后, 通过添加 JVM参数关闭偏向锁来调优系统性能,
-XX:-UseBiasedLocking // 关闭偏向锁(默认打开)
或
-XX:+UseHeavyMonitors // 设置重量级锁
轻量级锁
- 概念
当有另外一个线程竞争获取这个锁时,由于该锁已经是偏向锁,当发现对象头 Mark Word中的线程 ID 不是自己的线程ID,就会进行 CAS操作获取锁,如果获取成功,直接替换Mark Word 中的线程 ID 为自己的ID,该锁会保持偏向锁状态;如果获取锁失败,代表当
前锁有一定的竞争,偏向锁将升级为轻量级锁。 - 场景
轻量级锁适用于线程交替执行同步块的场景,绝大部分的锁在整个同步周期内都不存在长时间的竞争。
- 概念
自旋锁与重量级锁
- 前提
轻量级锁CAS抢锁失败,线程将会被挂起进入阻塞状态。如果正在持有锁的线程在很短的时间内释放资源,那么进入阻塞状态的线程无疑又要申请锁资源。 - 自旋次数
从 JDK1.7 开始,自旋锁默认启用,自旋次数由 JVM 设置决定,不建议设置的重试次数过多,因为 CAS重试操作意味着长时间地占用 CPU。 - 重量级锁
自旋锁重试之后如果抢锁依然失败,同步锁就会升级至重量级锁,锁标志位改为 10。在这个状态下,未抢到锁的线程都会进入 Monitor,之后会被阻塞在 _WaitSet 队列中。 - 在锁竞争不激烈且锁占用时间非常短的场景下,自旋锁可以提高系统性能。一旦锁竞争激烈或锁占用的时间过长,自旋锁将会导致大量的线程一直处于 CAS 重试状态,占用 CPU 资源,反而会增加系统性能开销。所以自旋锁和重量级锁的使用都要结合实际场景。
- 前提
其他锁优化
1)动态编译实现锁消除 / 锁粗化
除了锁升级优化,Java 还使用了编译器对锁进行优化。- JIT 编译器在动态编译同步块的时候,借助了一种被称为逃逸分析的技术
- JIT 编译器在编译这个同步块的时候不会生成 synchronized 所表示的锁的申请与释放的机器码,即消除了锁的使用。
- JIT 编译器将会把这几个同步块合并为一个大的同步块,从而避免一个线程“反
复申请、释放同一个锁“所带来的性能开销。
2) 减小锁粒度 - 将一个数组和队列对象拆成多个小对象,来降低锁竞争,提升并行
度。 - 最经典的减小锁粒度的案例就是 JDK1.8 之前实现的 ConcurrentHashMap 版本。
- ConcurrentHashMap 就很很巧妙地使用了分段锁 Segment 来降低锁资源竞争。
锁升级过程?(具体实现) |4
- 锁一共有4种状态,级别从低到高依次是:无锁状态、偏向锁状态、轻量级锁状态和重量级锁状态,这几个状态会随着竞争情况逐渐升级。锁可以升级但不能降级,意味着偏向锁升级成轻量级锁后不能降级成偏向锁。
- 这种锁升级却不能降级的策略,目的是为了提高获得锁和释放锁的效率。
- 升级:
1) 线程A在进入同步代码块前,先检查MarkWord中的线程ID是否与当前线程ID一致,如果一致(还是线程A获取锁对象),则无需使用CAS来加锁、解锁。
2) 如果不一致,再检查是否为偏向锁,如果不是,则自旋等待锁释放。
3) 如果是,再检查该线程是否存在(偏向锁不会主动释放锁),如果不在,则设置线程ID为线程A的ID,此时依然是偏向锁。
4) 如果还在,则暂停该线程,同时将锁标志位设置为00即轻量级锁(将MarkWord复制到该线程的栈帧中并将MarkWord设置为栈帧中锁记录)。线程A自旋等待锁释放。
5) 如果自旋次数到了该线程还没有释放锁,或者该线程还在执行,线程A还在自旋等待,这时又有一个线程B过来竞争这个锁对象,那么这个时候轻量级锁就会膨胀为重量级锁。重量级锁把除了拥有锁的线程都阻塞,防止CPU空转。
6)如果该线程释放锁,则会唤醒所有阻塞线程,重新竞争锁。
https://blog.csdn.net/dh798417147/article/details/102515788
https://www.jb51.net/article/186708.htm
重量级锁和之前的锁的本质区别?
- 概念+过程
- 区别
3-final
final、finally、finalize区别?
- final
final修饰类,表示该类不可以被继承
final修饰变量,表示该变量不可以被修改,只允许赋值一次
final修饰方法,表示该方法不可以被重写 - finally
finally是java保证代码一定要被执行的一种机制。
比如try-finally或try-catch-finally,用来关闭JDBC连接资源,用来解锁等等 - finalize
finalize是Object的一个方法,它的目的是保证对象在被垃圾收集前完成特定资源的回收。
不过finalize已经不推荐使用,JDK9已经标记为过时。
- final
final可以修饰方法嘛?
final修饰基础类型与引用的区别?
volatile和final的共同点
- 首先:对于一些需要快速读写的数据,可以从内存读取到CPU的寄存器中操作
- final 关键字声明的变量,会被CPU添加到寄存器中,读写都很快速
- volatile 它是被设计用来修饰被不同线程访问和修改的变量, 禁止把该变量放到CPU的寄存器中,防止多线程访问出现错乱问题
1、JMM保证final变量初始化时的有序性、禁止编译器和处理器重排序。
2、final作为不可变对象,正确初始化后(没有this逃逸),能够保障可见性。
3、volatile能够保障单次操作的原子性
4、volatile能够保障变量的可见性
3-锁机制
1. 锁(总)
分布式锁
分布式锁一般有三种实现方式:1.数据库锁;2.基于Redis的分布式锁;3. 基于ZooKeeper的分布式锁。线程同步的方式?
① synchronized
② Condition
③ CountDownLatch、CyclicBarrierjava锁及实现
- volatile、synchronized、CAS
- 锁-是为了解决并发操作引起的脏读、数据不一致的问题。
https://www.jianshu.com/p/e674ee68fd3f
java锁机制
1) 所熟知的Java锁机制无非就是Sychornized 锁 和 Lock锁 (对象头知识,偏向锁,轻量级锁,重量级锁)- Lock 同步锁是基于 Java 实现的,而 Synchronized是基于底层操作系统的 Mutex Lock实现的,每次获取和释放锁操作都会带来用户态和内核态的切换,从而增加系统性能开销。
https://www.jianshu.com/p/e674ee68fd3f
2) 在 Java 多线程编程当中,提供了多种实现 Java 线程安全的方式: - 最简单的方式,使用 Synchronization 关键字
- 使用 java.util.concurrent.atomic 包中的原子类,例如 AtomicInteger
- 使用 java.util.concurrent.locks 包中的锁
- 使用线程安全的集合 ConcurrentHashMap
- 使用 volatile 关键字,保证变量可见性(直接从内存读,而不是从线程 cache 读
https://www.cnblogs.com/theworld/p/12056452.html
https://www.jianshu.com/p/e674ee68fd3f
- Lock 同步锁是基于 Java 实现的,而 Synchronized是基于底层操作系统的 Mutex Lock实现的,每次获取和释放锁操作都会带来用户态和内核态的切换,从而增加系统性能开销。
都有什么锁?说说乐观锁悲观锁是什么,怎么实现,volatile关键字,CAS,AQS原理及实现。
1)锁的分类:- 公平锁、非公平锁
- 互斥锁、读写锁
- 乐观锁、悲观锁
synchronized,retreenLock, ReadWriteLock
4)CAS,AQS原理及实现
锁的应用
使用锁保证线程安全
2. 死锁
死锁编码及定位分析(sxt2)
死锁
1)概念- 死锁是指多个进程循环等待彼此占有的资源而无限期的僵持等待下去的局面。
- 即A使用A资源并等待使用B资源,B使用B资源并等待使用A资源
2)必要条件 - 互斥条件、不可抢占条件、占有且等待条件、循环等待条件
3)死锁处理
一般有死锁的预防、死锁避免、死锁的检测与恢复三种方法。
详见:https://blog.csdn.net/zhang123bl/article/details/89850646
4)死锁示例? |写一个死锁的例子?
/*** 开启了两个线程threadA, threadB,* 其中threadA占用了resource_A, 并等待被threadB释放的resource _B* threadB占用了resource _B正在等待被threadA释放的resource _A* 因此threadA,threadB出现线程安全的问题,形成死锁。*/public class D011_DeadLockDemo {private static String resourceA ="A";private static String resourceB="B";public static void main(String[] args) {deadLock();}public static void deadLock(){Thread threadA = new Thread(new Runnable() {@Overridepublic void run() {synchronized(resourceA){System.out.println("get resource A");try {Thread.sleep(3000);synchronized(resourceB){System.out.println("get resource B");}} catch (InterruptedException e) {e.printStackTrace();}}}});Thread threadB = new Thread(new Runnable() {@Overridepublic void run() {synchronized (resourceB){System.out.println("get resource B");synchronized (resourceA){System.out.println("get resource A");}}}});threadA.start();threadB.start();}}
死锁是什么(sxt2)
1)产生死锁主要的原因
① 系统资源不足、② 进程运行推进的顺序不合适、③ 资源分配不当
2) 代码、class HoldLockThread implements Runnable{private String lockA;private String lockB;public HoldLockThread(String lockA, String lockB) {this.lockA = lockA;this.lockB = lockB;}@Overridepublic void run() {synchronized (lockA){System.out.println(Thread.currentThread().getName() + "\t 自己持有" + lockA + "\t 尝试获得" + lockB);try { TimeUnit.SECONDS.sleep(2); } catch (InterruptedException e) { e.printStackTrace(); }synchronized (lockB){System.out.println(Thread.currentThread().getName() + "\t 自己持有" + lockA + "\t 尝试获得" + lockB);}}}}public class DeadLockDemo {public static void main(String[] args) {String lockA = "lockA";String lockB = "lockB";new Thread(new HoldLockThread(lockA,lockB) ,"ThreadAAA").start();new Thread(new HoldLockThread(lockB,lockA) ,"ThreadBBB").start();}}
打印:
打印ThreadAAA 自己持有:lockA 尝试获得:lockBThreadBBB 自己持有:lockB 尝试获得:lockA
死锁怎么定位。
3) 解决(sxt2)
① jps 定位进程号
② jstack 找到死锁查看
linux ps -ef|grep XXxxxx ls -l
windows jps=java ps 只查看java jps -l

有没有遇到过死锁,咋解决的
解决死锁问题的方法是:一种是用synchronized,一种是用Lock显式锁实现。
线程排查
- 排查CPU占满的Java线程
产生CPU100%的原因:某一程序一直占用CPU是导致CPU100%的原因,大概有以下几种情况:
1)Java 内存不够或溢出导致GC overhead问题, GC overhead 导致的CPU 100%问题;
2)死循环问题. 如常见的HashMap被多个线程并发使用导致的死循环, 或者死循环;
3)某些操作一直占用CPU
步骤:
1)jps 获取Java**进程的PID。
2)top -Hp PID 查看对应进程的哪个线程**占用CPU过高。该进程内最耗费CPU的线程
3)echo "obase=16;PID" | bc 将线程的PID转换为16进制,大写转换为小写。
4)jstack pid >> java.txt 导出CPU占用高进程的线程栈
jstack 2444 >stack.txt或者jstack 进程id | grep 16进制线程id
在Java.txt中查找转换成为16进制的线程PID。找到对应的线程栈。
辅助
命令参考
grep "99b" stack.txt -A 25
grep -C 5 foo file 显示file文件里匹配foo字串那行以及上下5行
grep -B 5 foo file 显示foo及前5行
grep -A 5 foo file 显示foo及后5行
对线程状态进行分析。
新建( new )、可运行( runnable )、运行( running )、阻塞( block )、死亡( dead )
4-Java线程
生命周期--- 存疑
线程状态如下所示:
1) 死锁,Deadlock(重点关注)
2) 执行中,Runnable
3) 等待资源,Waiting on condition(重点关注,等待什么资源)
4) 等待获取监视器,Waiting on monitor entry(重点关注)
5) 暂停,Suspended
6) 对象等待中,Object.wait() 或 TIMED_WAITING
7) 阻塞,Blocked(重点关注)
8) 停止,Parked
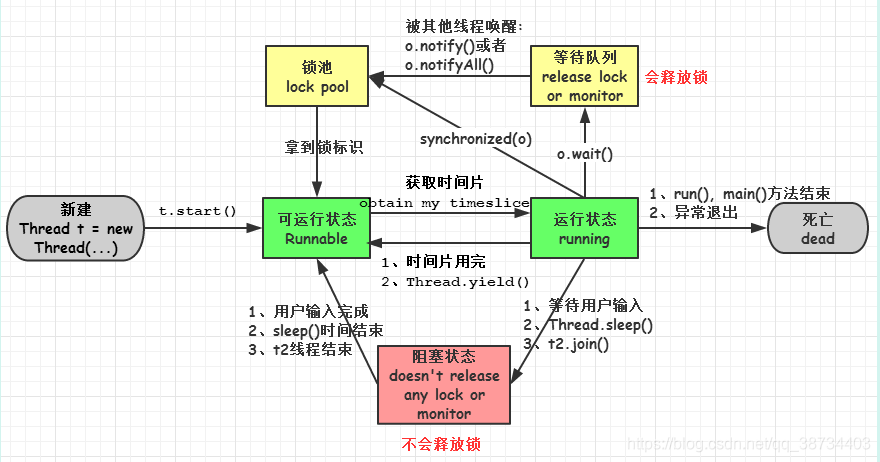
Java线程的状态? |3
- Java语言中线程共有六种状态,分别是:
1)NEW(初始化状态)
2)RUNNABLE(可运行 / 运行状态)
3)BLOCKED(阻塞状态)
4)WAITING(无时限等待)
5)TIMED_WAITING(有时限等待)
6)TERMINATED(终止状态) - 在操作系统层面,Java线程中的BLOCKED、WAITING、TIMED_WAITING是一种状态,即休眠状态。Java线程处于这三种状态之一,那么这个线程就永远没有CPU的使用权。
- 所以Java线程的生命周期可以简化为下图:
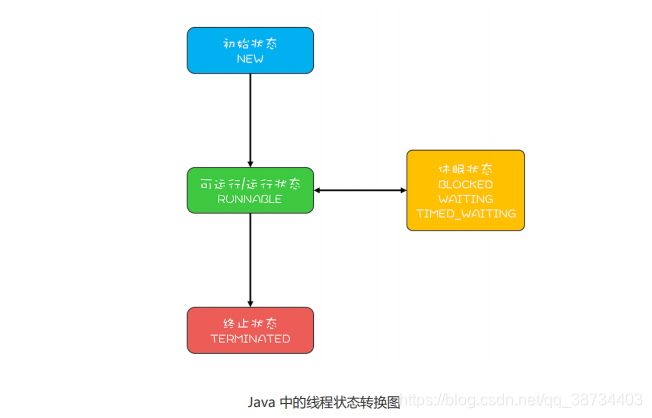
- 其中,BLOCKED、WAITING、TIMED_WAITING可以理解为线程导致休眠状态的三种原因。
- Java语言中线程共有六种状态,分别是:
线程的状态及转换方式?
- RUNNABLE与BLOCKED的状态转换
-- RUNNABLE转BLOCKED:一种场景会触发,线程等待synchronized的隐式锁。
-- BLOCKED转RUNNABLE:当等待的线程获得synchronized隐式锁时,就又会从BLOCKED转换到RUNNABLE状态。 - RUNNABLE与WAITING的状态转换
三种场景会触发:
① 获得synchronized隐式锁的线程,调用无参数的 Object.wait() 方法。
② 调用无参数的Thread.join()方法。其中的join()是一种线程同步方法,例如有一个线程对象threadA,当调用A.join()的时候,执行这条语句的线程会等待threadA执行完,而等待中的这个线程,其状态会从 RUNNABLE 转换到 WAITING。当线程 thread A 执行完,原来等待它的线程又会从 WAITING 状态转换到 RUNNABLE。
③ 调用 LockSupport.park() 方法。调用LockSupport.park()方法,当前线程会阻塞,线程的状态会从 RUNNABLE 转换到 WAITING。调用 LockSupport.unpark(Thread thread) 可唤醒目标线程,目标线程的状态又会从 WAITING 状态转换到 RUNNABLE。 - RUNNABLE与TIMED_WAITING的状态转换?
五种场景会触发:
① 调用带超时参数的 Thread.sleep(long millis) 方法;
② 获得synchronized 隐式锁的线程,调用带超时参数的 Object.wait(long timeout) 方法;
③ 调用带超时参数的 Thread.join(long millis) 方法;
④ 调用带超时参数的 LockSupport.parkNanos(Object blocker, long deadline) 方法;
⑤ 调用带超时参数的 LockSupport.parkUntil(long deadline) 方法。 - NEW到RUNNABLE状态?
Java刚创建出来的Thread对象就是NEW状态。
从NEW状态转换到RUNNABLE状态,只要调用线程对象的start()方法就可以 - 从RUNNABLE到TERMINATED状态?
-- 线程执行完run()方法后,会自动转换到TERMINATED状态,当然如果执行run()方法的时候异常抛出,也会导致线程终止。
-- 强制中断run()方法的执行,调用 interrupt()方法。
- RUNNABLE与BLOCKED的状态转换
阻塞和等待的区别?
- 定义+何时触发?
- BLOCKED:一个线程因为等待临界区的锁被阻塞产生的状态
- WAITING:一个线程进入了锁,但是需要等待其他线程执行某些操作。时间不确定
sleep和wait有什么区别?
- 对于sleep()方法,我们首先要知道该方法是属于Thread类中的。而wait()方法,则是属于Object类中的。
Thread类的方法:sleep(),yield()等
Object的方法:wait()和notify()等 - sleep()方法导致了程序暂停执行指定的时间,让出cpu该其他线程,但是他的监控状态依然保持者,当指定的时间到了又会自动恢复运行状态。
在调用sleep()方法的过程中,线程不会释放对象锁。 - 而当调用wait()方法的时候,线程会放弃对象锁,进入等待此对象的等待锁定池,只有针对此对象调用notify()方法后本线程才进入对象锁定池准备
获取对象锁进入运行状态。 - 参考:https://www.cnblogs.com/hongten/p/hongten_java_sleep_wait.html
- 对于sleep()方法,我们首先要知道该方法是属于Thread类中的。而wait()方法,则是属于Object类中的。
2-单线程
线程实现的3种方式? |3
1)通过继承Thread类,重写run方法;
2)通过实现runable接口;
3)通过实现callable接口。(和Future)
④ 线程池获取:ThreadPoolExecutorpublic class CreateThreadDemo {public static void main(String[] args) {//1.继承ThreadThread thread = new Thread() {@Overridepublic void run() {System.out.println("继承Thread");super.run();}};thread.start();//2.实现runable接口Thread thread1 = new Thread(new Runnable() {@Overridepublic void run() {System.out.println("实现runable接口");}});thread1.start();//3.实现callable接口ExecutorService service = Executors.newSingleThreadExecutor();Future<String> future = service.submit(new Callable() {@Overridepublic String call() throws Exception {return "通过实现Callable接口";}});try {String result = future.get();System.out.println(result);} catch (InterruptedException e) {e.printStackTrace();} catch (ExecutionException e) {e.printStackTrace();}}}
继承Thread和实现Runnable接口的区别,这两者的继承关系
- 实现:通过继承Thread类,重写Thread的run()方法,将线程运行的逻辑放在其中;通过实现Runnable接口,实例化Thread类
- 如果一个类继承Thread,则不适合资源共享。但是如果实现了Runable接口的话,则很容易的实现资源共享。继承Thread是多个线程分别完成自己的任务,实现了Runable是多个线程共同完成一个任务。
实现Runnable接口比继承Thread类所具有的优势:
1):适合多个相同的程序代码的线程去处理同一个资源
2):java只能单继承,可以避免java中的单继承的限制
3):增加程序的健壮性,代码可以被多个线程共享,代码和数据独立,
4)如果只想重写 run() 方法,而不重写其他 Thread 方法,那么应使用 Runnable 接口
https://www.cnblogs.com/CryOnMyShoulder/p/8028122.html
Callable和Runnable的区别?
- Runnable vs Callable
-- Runnable自 Java 1.0 以来一直存在,但Callable仅在 Java 1.5中引入,目的就是为了来处理Runnable不支持的用例。
-- Runnable 接口不会返回结果或抛出检查异常,但是Callable接口可以。所以,如果任务不需要返回结果或抛出异常推荐使用 Runnable 接口,这样代码看起来会更加简洁。 - 工具类 Executors 可以实现 Runnable 对象和 Callable对象之间的相互转换。(Executors.callable(Runnable task)或 Executors.callable(Runnable task,Object resule))。
// ① Runnable.java@FunctionalInterfacepublic interface Runnable {/** 被线程执行,没有返回值也无法抛出异常*/public abstract void run();}// ② Callable.java@FunctionalInterfacepublic interface Callable<V> {/**计算结果,或在无法这样做时抛出异常。* @return 计算得出的结果 @throws 如果无法计算结果,则抛出异常*/V call() throws Exception;}
- Runnable vs Callable
创建线程的方式:延伸至优劣,底层实现
- 优劣
采用继承Thread类方式:
(1)优点:编写简单,如果需要访问当前线程,无需使用Thread.currentThread()方法,直接使用this,即可获得当前线程。
(2)缺点:因为线程类已经继承了Thread类,所以不能再继承其他的父类。
采用实现Runnable接口方式:
(1)优点:线程类只是实现了Runable接口,还可以继承其他的类。在这种方式下,可以多个线程共享同一个目标对象,所以非常适合多个相同线程来处理同一份资源的情况,从而可以将CPU代码和数据分开,形成清晰的模型,较好地体现了面向对象的思想。
(2)缺点:编程稍微复杂,如果需要访问当前线程,必须使用Thread.currentThread()方法。
https://blog.csdn.net/Touch_2011/article/details/6891026
- 优劣
run和start的区别
- 调用start方法实现多线程,而调用run方法没有实现多线程
- 一般会在run实现方法体,
- run还是在主线程中执行,会和调用普通方法一样,按照顺序执行,不会进入run里的代码块。
- start方法,则会在主线程中重新创建一个新的线程,等得到cpu的时间段后则会执行所对应的run方法体的代码。
https://blog.csdn.net/QQ2899349953/article/details/81772104
三、工具类
1. JUC
JUC
- 是什么?
Java5提供java.util.concurrent在并发编程中使用的工具类。 - 干什么?
用于定义类似于线程的自定义子系统,包括线程池,异步IO和轻量级任务框架 - 还提供了设计用于多线程上下文中的 Collection 实现等;
- 是什么?
JUC下的组件讲讲
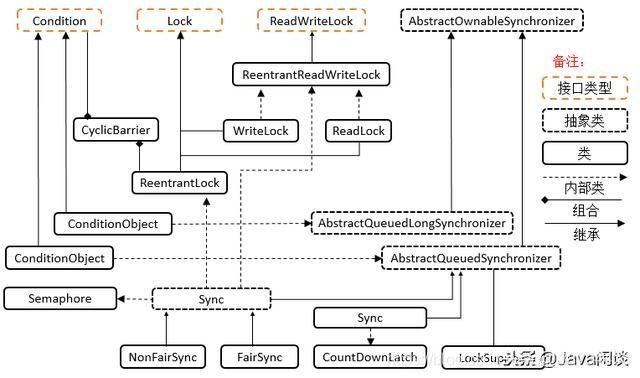
JUC下的automic包
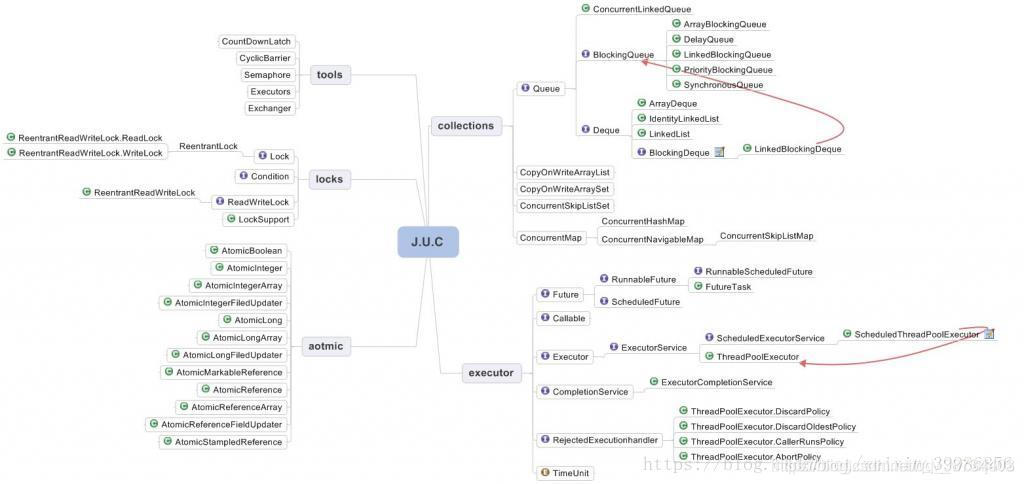
volatile,synchronized,reentrantLock的区别
2. Lock&Condition
Java SDK 并发包通过Lock和Condition两个接口来实现管程,其中 Lock用于解决互斥问题,Condition用于解决同步问题。
synchronized和lock有什么区别?用新的lock有什么好处?举例说明(sxt2)
1、原始构成
synchronized 是关键字属于 JVM 层面,
monitorenter(底层是通过 monitor 对象来完成, 其实 wait/notify 等方法也依赖于 monitor 对象只有在同步块或方法中才能调 wait/notify 等方法)
monitorexit
Lock 是具体类(java.util.concurrent.locks.Lock)是 api 层面的锁
2、使用方法
synchronized 不需要用户去手动释放锁,当 synchronized 代码执行完后系统会自动让线程释放对锁的占用
ReentrantLock 则需要用户去手动释放锁若没有主动释放锁,就有可能导致出现死锁现象。
需要 lock() 和 unlock() 方法配合 try / finally 语句块来完成。
3、等待是否可中断
synchronized 不可中断,除非抛出异常或者正常运行完成
ReentrantLock 可中断,1、设置超时方法 tryLock(long timeout, TimeUnit unit)
2、lockInterruptibly() 放代码块这,调用 interrupt() 方法可中断
4、加锁是否公平
synchronized 非公平锁
ReentrantLock 两者都可以,默认非公平锁,构造方法可以传入 boolean 值,true 为公平锁,false 为非公平锁
5、锁绑定多个条件 Condition
synchronized 没有
ReentrantLock 用来实现分组唤醒需要唤醒的线程们,可以精确唤醒,而不是像 synchronized 要么随机唤醒一个线程要么唤醒全部线程。
代码synchonrized和reenterLock区别与联系,实现方式是什么? |4
- 谈谈 synchronized 和 ReentrantLock 的区别
1)两者都是可重入锁
“可重入锁” 指的是自己可以再次获取自己的内部锁。比如一个线程获得了某个对象的锁,此时这个对象锁还没有释放,当其再次想要获取这个对象的锁的时候还是可以获取的,如果不可锁重入的话,就会造成死锁。同一个线程每次获取锁,锁的计数器都自增1,所以要等到锁的计数器下降为 0 时才能释放锁。
2)synchronized 依赖于 JVM 而 ReentrantLock 依赖于 API
synchronized 是依赖于 JVM 实现的,前面我们也讲到了 虚拟机团队在 JDK1.6 为 synchronized 关键字进行了很多优化,但是这些优化都是在虚拟机层面实现的,并没有直接暴露给我们。ReentrantLock 是 JDK 层面实现的(也就是 API 层面,需要 lock() 和 unlock() 方法配合 try/finally 语句块来完成),所以我们可以通过查看它的源代码,来看它是如何实现的。
3)ReentrantLock 比 synchronized 增加了一些高级功能
相比synchronized,ReentrantLock增加了一些高级功能。主要来说主要有三点:
-- 等待可中断 : ReentrantLock提供了一种能够中断等待锁的线程的机制,通过 lock.lockInterruptibly() 来实现这个机制。也就是说正在等待的线程可以选择放弃等待,改为处理其他事情。
-- 可实现公平锁 : ReentrantLock可以指定是公平锁还是非公平锁。而synchronized只能是非公平锁。所谓的公平锁就是先等待的线程先获得锁。ReentrantLock默认情况是非公平的,可以通过 ReentrantLock类的ReentrantLock(boolean fair)构造方法来制定是否是公平的。
-- 可实现选择性通知(锁可以绑定多个条件): synchronized关键字与wait()和notify()/notifyAll()方法相结合可以实现等待/通知机制。ReentrantLock类当然也可以实现,但是需要借助于Condition接口与newCondition()方法。
- 谈谈 synchronized 和 ReentrantLock 的区别
lock怎么知道有没有拿到锁?
AQS(AbstractQueuedSynchronizer)
AQS原理及实现? |3
- 类在java.util.concurrent.locks包下面
- 概念
AQS是一个用来构建锁和同步器的框架,使用AQS能简单且高效地构造出应用广泛的大量的同步器,比如我们提到的ReentrantLock,Semaphore,其他的诸如ReentrantReadWriteLock,SynchronousQueue,FutureTask等等皆是基于AQS的。当然,我们自己也能利用AQS非常轻松容易地构造出符合我们自己需求的同步器。 - AQS核心思想是,如果被请求的共享资源空闲,则将当前请求资源的线程设置为有效的工作线程,并且将共享资源设置为锁定状态。如果被请求的共享资源被占用,那么就需要一套线程阻塞等待以及被唤醒时锁分配的机制,这个机制AQS是用CLH队列锁实现的,即将暂时获取不到锁的线程加入到队列中。
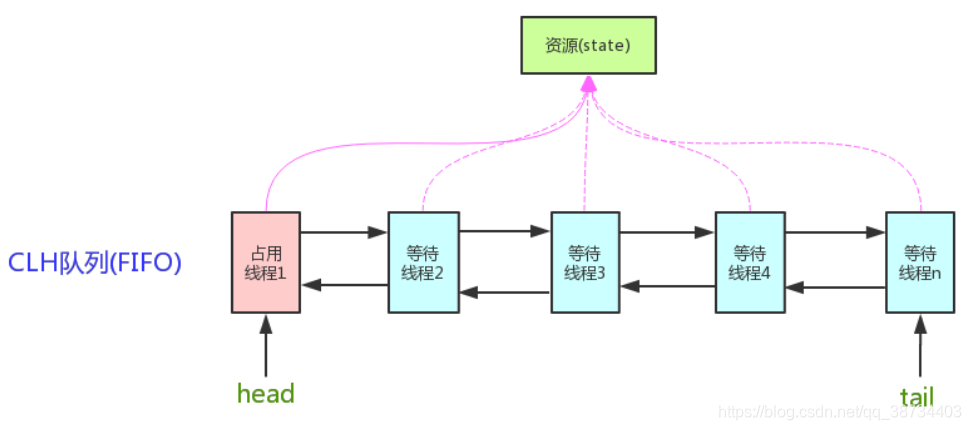
- AQS 对资源的共享方式
AQS定义两种资源共享方式
① Exclusive(独占):只有一个线程能执行,如ReentrantLock。又可分为公平锁和非公平锁:
*公平锁:按照线程在队列中的排队顺序,先到者先拿到锁
*非公平锁:当线程要获取锁时,无视队列顺序直接去抢锁,谁抢到就是谁的
② Share(共享):多个线程可同时执行,如Semaphore/CountDownLatch。Semaphore、CountDownLatch、 CyclicBarrier、ReadWriteLock 我们都会在后面讲到。
ReentrantReadWriteLock 可以看成是组合式,因为ReentrantReadWriteLock也就是读写锁允许多个线程同时对某一资源进行读。
不同的自定义同步器争用共享资源的方式也不同。自定义同步器在实现时只需要实现共享资源 state 的获取与释放方式即可,至于具体线程等待队列的维护(如获取资源失败入队/唤醒出队等),AQS已经在顶层实现好了。 - AQS底层使用了模板方法模式
同步器的设计是基于模板方法模式的,如果需要自定义同步器一般的方式是这样(模板方法模式很经典的一个应用):
使用者继承AbstractQueuedSynchronizer并重写指定的方法。(这些重写方法很简单,无非是对于共享资源state的获取和释放)
将AQS组合在自定义同步组件的实现中,并调用其模板方法,而这些模板方法会调用使用者重写的方法。
这和我们以往通过实现接口的方式有很大区别,这是模板方法模式很经典的一个运用。
AQS使用了模板方法模式,自定义同步器时需要重写下面几个AQS提供的模板方法:
isHeldExclusively()//该线程是否正在独占资源。只有用到condition才需要去实现它。tryAcquire(int)//独占方式。尝试获取资源,成功则返回true,失败则返回false。tryRelease(int)//独占方式。尝试释放资源,成功则返回true,失败则返回false。tryAcquireShared(int)//共享方式。尝试获取资源。负数表示失败;0表示成功,但没有剩余可用资源;正数表示成功,且有剩余资源。tryReleaseShared(int)//共享方式。尝试释放资源,成功则返回true,失败则返回false。
默认情况下,每个方法都抛出 UnsupportedOperationException。 这些方法的实现必须是内部线程安全的,并且通常应该简短而不是阻塞。AQS类中的其他方法都是final ,所以无法被其他类使用,只有这几个方法可以被其他类使用。
*以ReentrantLock为例,state初始化为0,表示未锁定状态。A线程lock()时,会调用tryAcquire()独占该锁并将state+1。此后,其他线程再tryAcquire()时就会失败,直到A线程unlock()到state=0(即释放锁)为止,其它线程才有机会获取该锁。当然,释放锁之前,A线程自己是可以重复获取此锁的(state会累加),这就是可重入的概念。但要注意,获取多少次就要释放多么次,这样才能保证state是能回到零态的。
*再以CountDownLatch以例,任务分为N个子线程去执行,state也初始化为N(注意N要与线程个数一致)。这N个子线程是并行执行的,每个子线程执行完后countDown()一次,state会CAS(Compare and Swap)减1。等到所有子线程都执行完后(即state=0),会unpark()主调用线程,然后主调用线程就会从await()函数返回,继续后余动作。
*一般来说,自定义同步器要么是独占方法,要么是共享方式,他们也只需实现tryAcquire-tryRelease、tryAcquireShared-tryReleaseShared中的一种即可。但AQS也支持自定义同步器同时实现独占和共享两种方式,如ReentrantReadWriteLock。基于AQS实现的lock?
可重入锁和非可重入锁? 可重入锁(又名递归锁)|2
- ReentrantLock/Synchronized就是一个典型的可重入锁。
- 最大作用:避免死锁
- 什么是可重入锁?
-- ReentrantLock,这个翻译叫可重入锁。所谓可重入锁,顾名思义,指的是线程可以重复获取同一把锁。
-- 同一个线程外层函数获得锁之后,内层递归函数仍然能够获取该锁的代码,在同一个线程在外层方法获取锁的时候,在进入内层方法会自动获取锁
-- 如下代码,当线程 T1 执行到 ①处时,已经获取到了锁 rtl ,当在 ① 处调用get() 方法时,会在 ② 再次对锁 rtl执行加锁操作。
此时,如果锁 rtl 是可重入的,那么线程T1可以再次加锁成功;如果锁 rtl 是不可重入的,那么线程 T1 此时会被阻塞。
class X {private final Lock rtl = new ReentrantLock();int value;public int get() {// 获取锁rtl.lock(); ②try {return value;} finally {// 保证锁能释放rtl.unlock();}}public void addOne() {// 获取锁rtl.lock();try {value = 1 + get(); ①} finally {// 保证锁能释放rtl.unlock();}}}
公平锁、非公平锁(sxt2)
- 是什么
- 公平锁:是指多个线程按照申请锁的顺序来获取锁,满足FIFO。
- 非公平:是指多个线程获取锁的顺序并不是按照申请锁的顺序,有可能后申请的线程比现申请的线程优先获得锁,在高并发的情况下,有可能会造成优先级反战或者饥饿现象
- 区别
- 公平锁:就是很公平,在并发环境中,每个线程获取锁时会查看此锁维护的等待队列,如果为空,或者当前线程是等待队列的第一个,就占有锁,否则加入等待队列,以后会按照FIFO的规则从队列中取到自己
- 非公平锁:比较粗鲁,上来就尝试占有锁,如果尝试失败,在采用类似公平锁的方式(非公平锁的优点在于吞吐量比公平锁大)
- 其他
Syschronized而言,也是非公平锁(类似lock) ReentrantLock实现公平和非公平锁
//方法1:无参构造函数:默认非公平锁public ReentrantLock() {sync = new NonfairSync(); // 非公平锁}// 方法2:true时为公平锁,false时为非公平锁public ReentrantLock(boolean fair) {sync = fair ? new FairSync() : new NonfairSync();}
ReentrantLock的创建可以制定构造函数的boolean类型来得到公平锁或非
公平锁和非公平锁区别?为什么公平锁效率低?
ReentrantLock的Condition的特性? -- 存疑?
- -- Lock 和 Condition实现的管程,线程等待和通知需要调用await()、signal()、signalAll(),语义和wait()、notify()、notifyAll()是相同的。
-- 区别是,Lock&Condition实现的管程里只能使用前面的await()、signal()、signalAll(),而后面的wait()、notify()、notifyAll() 只有在 synchronized实现的管程里才能使用。
-- 如果一不小心在Lock&Condition实现的管程里调用了wait()、notify()、notifyAll(),那程序可就彻底玩儿完了**。 - Condition实现了管程模型里面的条件变量。
- 管程中,Java 语言内置的管程里只有一个条件变量,Lock&Condition实现的管程是支持多个条件变量的,这是二者的一个重要区别。
- 例如,实现一个阻塞队列,就需要两个条件变量。
一个阻塞队列,需要两个条件变量,一个是队列不空(空队列不允许出队),另一个是队列不满(队列已满不允许入队)。相关的代码:
public class BlockedQueue<T>{final Lock lock = new ReentrantLock();// 条件变量:队列不满final Condition notFull = lock.newCondition();// 条件变量:队列不空final Condition notEmpty = lock.newCondition();// 入队void enq(T x) {lock.lock();try {while (队列已满){// 等待队列不满notFull.await();}// 省略入队操作...// 入队后, 通知可出队notEmpty.signal();}finally {lock.unlock();}}// 出队void deq(){lock.lock();try {while (队列已空){// 等待队列不空notEmpty.await();}// 省略出队操作...// 出队后,通知可入队notFull.signal();}finally {lock.unlock();}}}
- -- Lock 和 Condition实现的管程,线程等待和通知需要调用await()、signal()、signalAll(),语义和wait()、notify()、notifyAll()是相同的。
4-ReadWriteLock读写锁
基本知识:
- ReadWriteLock是一个接口,它的实现类是ReentrantReadWriteLock;
独占锁(写锁)、共享锁(读锁)、互斥锁?
- 是什么?
独占:该锁一次只能被一个线程持有,ReentrantLock和synchronized都是独占锁
共享:该锁可以被多个线程持有 - ReentrantReadWriteLock其读锁是共享锁,其写锁是独占锁。
syc -> lock -> ReentrantReadWriteLock(签名场景,一致性、并发性) - 读锁的共享锁可保证并发读是非常高效的,读写、写读、写写过程是互斥的
- 读写锁与互斥锁一个重要区别:
读写锁允许多个线程同时读共享变量,而互斥锁是不允许的,这是读写锁在读多写少场景下性能优于互斥锁的关键。但读写锁的写操作是互斥的,当一个线程在写共享变量的时候,是不允许其他线程执行写操作和读操作。
- 是什么?
读写锁咋实现的
- 可以多个读,只能一个写
// 线程在高内聚低耦合下操纵资源类class MyCache{ // 资源类private volatile Map<String,Object> map = new HashMap<>();//实现ReadWriteLock接口(不是Lock的实现类) Lock,只有一个线程// private Lock lock = new ReentrantLock();//要求写的时候一个线程进去,读的时候多个线程private ReentrantReadWriteLock rwLock = new ReentrantReadWriteLock();public void put(String key,Object value){rwLock.writeLock().lock();try {System.out.println(Thread.currentThread().getName() + "\t正在写入:" + key);//模拟网络延迟try {TimeUnit.MILLISECONDS.sleep(300);} catch (InterruptedException e) {e.printStackTrace();}map.put(key,value);System.out.println(Thread.currentThread().getName() + "\t写入完成!");}catch (Exception e){e.printStackTrace();}finally {rwLock.writeLock().unlock();}}public void get(String key){rwLock.readLock().lock();try {System.out.println(Thread.currentThread().getName() + "\t正在读取:");//模拟网络延迟try {TimeUnit.MILLISECONDS.sleep(300);} catch (InterruptedException e) {e.printStackTrace();}Object result = map.get(key);System.out.println(Thread.currentThread().getName() + "\t读取完成:" + result);} catch (Exception e) {e.printStackTrace();} finally {rwLock.readLock().unlock();}}}/*** 多个线程同时读一个资源类没有问题,所以为了满足并发量,读取共享资源应该可以同时进行。* 但是* 如果有一个线程想去写共享资源,就不能再有其他线程可以对该资源进行读或写* 小总结:* 读-读 能共存* 读-写 不能共存* 写-写 不能共存** 写操作:原子+独占,整个过程必须是一个完整的统一体,中间不允许被分割被打断。*/public class ReadWriteLockDemo {public static void main(String[] args) {MyCache myCache = new MyCache();for (int i = 1; i <= 5; i++) {System.out.println("W-"+i);final int tempInt = i;new Thread(()->{myCache.put(String.valueOf(tempInt),String.valueOf(tempInt));},"W-"+String.valueOf(i)).start();}for (int i = 1; i <= 5; i++) {final int tempInt = i;new Thread(()->{myCache.get(String.valueOf(tempInt));},"R-"+String.valueOf(i)).start();}}}
5-乐观锁
- 乐观锁,悲观锁
- 乐观锁与悲观锁的区别?
乐观锁 悲观锁 适用场景,实际应用场景 |2
+说说乐观锁悲观锁是什么,怎么实现,乐观锁和悲观锁的理解及如何实现,有哪些实现方式?
- 悲观锁:总是假设最坏的情况,每次去拿数据的时候都认为别人会修改,所以每次在拿数据的时候都会上锁,这样别人想拿这个数据就会阻塞直到它拿到锁。传统的关系型数据库里边就用到了很多这种锁机制,比如行锁,表锁等,读锁,写锁等,都是在做操作之前先上锁。再比如 Java 里面的同步原语 synchronized 关键字的实现也是悲观锁。
- 乐观锁:顾名思义,就是很乐观,每次去拿数据的时候都认为别人不会修改,所以不会上锁,但是在更新的时候会判断一下在此期间别人有没有去更新这个数据,可以使用版本号等机制。乐观锁适用于多读的应用类型,这样可以提高吞吐量,像数据库提供的类似于 write_condition 机制,其实都是提供的乐观锁。在 Java中 java.util.concurrent.atomic 包下面的原子变量类就是使用了乐观锁的一种实现方式 CAS 实现的。
- 乐观锁的实现方式:
① 使用版本标识来确定读到的数据与提交时的数据是否一致。提交后修改版本标识,不一致时可以采取丢弃和再次尝试的策略。
② java 中的 Compare and Swap 即 CAS ,当多个线程尝试使用 CAS 同时更新同一个变量时,只有其中一个线程能更新变量的值,而其它线程都失败,失败的线程并不会被挂起,而是被告知这次竞争中失败,并可以再次尝试。 CAS 操作中包含三个操作数 —— 需要读写的内存位置(V)、进行比较的预期原值(A)和拟写入的新值(B)。如果内存位置 V 的值与预期原值 A 相匹配,那么处理器会自动将该位置值更新为新值 B。否则处理器不做任何操作。
https://thinkwon.blog.csdn.net/article/details/104863992
5-Semaphore
Semaphore信号量?
- 只允许一个线程执行访问临界区,实现互斥锁功能;
- 用于控制资源能够被并发访问的线程数量/可以允许多个线程访问一个临界区;
怎么控制并发?
- 控制方法的并发量(Semaphore信号量方案)(优)
https://aalion.github.io/2019/12/28/concurrency82/ - 控制并发量(计数器方案)
- 控制并发量(阻塞队列方案)
https://blog.csdn.net/manzhizhen/article/details/81413014 √
https://blog.csdn.net/qq_36468243/article/details/86622942
- 控制方法的并发量(Semaphore信号量方案)(优)
其他的限流方式有什么,如何实现的-并发限流?
6-CountDownLatch|CyclicBarrier
并发工具类CountDownLatch、CyclicBarrier? |2
- CountDownLatch 和 CyclicBarrier 是Java并发包提供的两个非常易用的线程同步工具类
- 用法的区别:
① CountDownLatch主要用来解决一个线程等待多个线程的场景;CyclicBarrier是一组线程之间互相等待。
② CountDownLatch的计数器是不能循环利用的,也就是说一旦计数器减到 0,再有线程调用await(),该线程会直接通过。但CyclicBarrier 的计数器是可以循环利用的,而且具备自动重置的功能,一旦计数器减到 0 会自动重置到你设置的初始值。
③ CyclicBarrier 还可以设置回调函数,可以说是功能丰富。
说说倒计时器(CountDownLatch)和循环栅栏(CyclicBarrier)的区别
- CountDownLatch 强调一个线程等多个线程完成某件事情。一般用于某个线程 A 等待若干个其他线程执行完任务之后,它才执行;而 CyclicBarrier 是多个线程互等,等大家都完成,再携手共进。一般用于一组线程互相等待至某个状态,然后这一组线程再同时执行;
- 调用 CountDownLatch 的 countDown,当前线程并不会阻塞,会继续往下执行;而调用 CyclicBarrier 的 await 方法,会阻塞当前线程,直到 CyclicBarrier 指定的线程全部都到达了指定点的时候,才能继续往下执行;
- CountDownLatch 0时释放所有等待的线程,计数为0时,无法重置,不可重复利用。CyclicBarrier 是可以复用的,reset()方法重置屏障点,计数器会归零,重新开始计数。
https://aalion.github.io/2019/12/28/concurrency81/
7-Exchange
- 有没有用过java中的Exchange (多线程)
- Exchanger 是一个用于线程间协作的工具类,用于两个线程间能够交换。它提供了一个交换的同步点,在这个同步点两个线程能够交换数据。
https://aalion.github.io/2019/12/28/concurrency83/
- Exchanger 是一个用于线程间协作的工具类,用于两个线程间能够交换。它提供了一个交换的同步点,在这个同步点两个线程能够交换数据。
7-并发容器
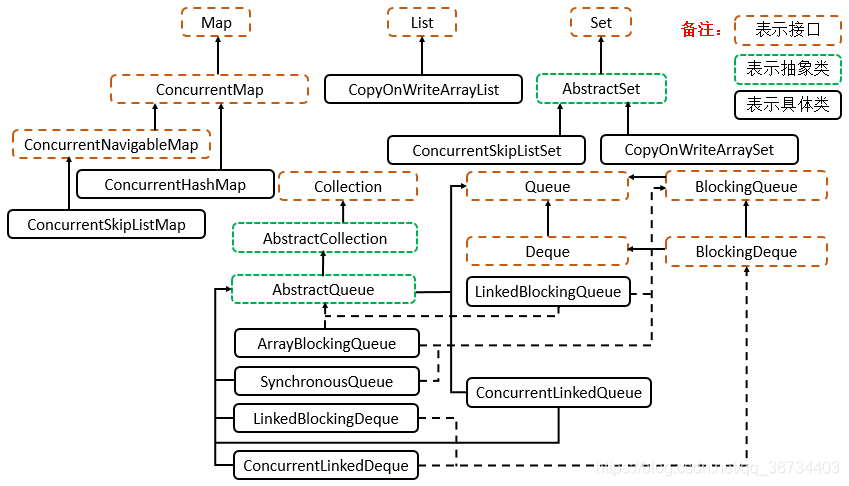
并发容器?
并发容器虽然数量非常多,四大类:List、Map、Set和Queue,下面的并发容器关系图,基本上把常用的容器都覆盖到了。
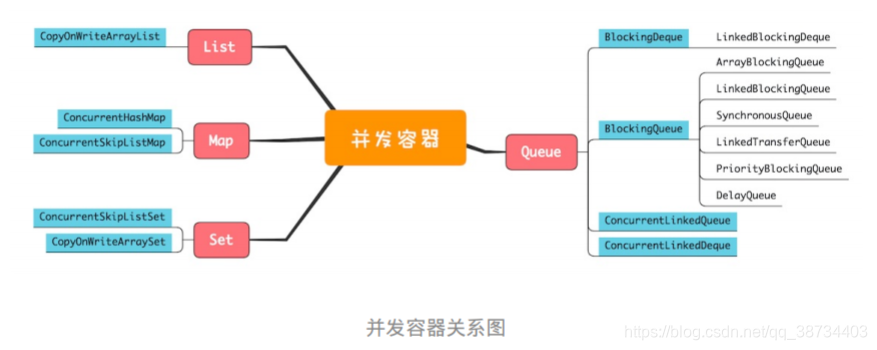
线程安全的List
- 线程安全的集合:
Vector | HashTable | StringBuffer - 非线程安全的:
ArrayList|LinkedList|HashMap|HashSet|TreeMap|TreeSet|StringBulider
- 线程安全的集合:
1-CopyOnWriteArrayList
ArrayList是线程不安全的,例子以及解决方案(sxt2)
- 1)非线程安全例子
psvm{List<String> list = new ArrayList<>();for(int i=1; i<30; i++){new Thread(() -> {list.aa(UUID.randomUUID().toString().substring(0,8));sout(list);},String.valueOf(i)).start();}}
① 故障现象:java.util.ConcurrentModificationException(并发修改异常)
② 导致原因:并发争抢修改导致,一个正在写,另一个线程过来抢夺,导致数据不一致异常。并发生修改异常。
③ 解决方案:
④ 优化建议(同样的错误不犯第2次)- eg:开启多个线程操作List集合,向ArrayList中增加元素,同时去除元素。
会出现以下几种情况:①Null②某些线程并未打印③数组下标越界异常 2)解决非线程安全
方案1:使用Vertor集合
缺点:Vertor加锁可以保证数据一致性,但并发性低new Vector<>();
方案2:使用Collections.synchronizedList
Collection:集合接口
Collections:集合接口辅助类
缺点:Collections.synchronizedList(new ArrayList<>());
方案3:使用JUC中的CopyOnWriteArrayList类替换。
new CopyOnWriteArraylist<>();
3)实现-Collections.synchronizedList实现
初始化
ArrayList arrayList = new ArrayList();List list2 = Collections.synchronizedList(arrayList);
add方法:通过关键字synchronized同步
public void add(int index, E element) {synchronized (mutex) {list.add(index, element);}}
get方法:synchronized
public V get(Object key) {synchronized (mutex) {return m.get(key);}}
实现-②CopyonwriteArrayList(写时复制,读写分离的思想)
- add:使用reentrantlock
Arrays.copyOf,扩容长度+1
/** The lock protecting all mutators */transient final ReentrantLock lock = new ReentrantLock();/** The array, accessed only via getArray/setArray. */private volatile transient Object[] array;//保证了线程的可见性public boolean add(E e) {final ReentrantLock lock = this.lock;//ReentrantLock 保证了线程的可见性和顺序性,即保证了多线程安全。// 获取独占锁lock.lock();try {Object[] elements = getArray();int len = elements.length;Object[] newElements = Arrays.copyOf(elements, len + 1);//在原先数组基础之上新建长度+1的数组,并将原先数组当中的内容拷贝到新数组当中。newElements[len] = e;//设值setArray(newElements);//对新数组进行赋值return true;} finally {lock.unlock();}}
get:无锁
public E get(int index) {return get(getArray(), index);}
- 1)非线程安全例子
CopyOnWriteArrayList,咋实现线程安全的?。
- 当向容器添加或删除元素的时候,不直接往当前容器添加删除,而是先将当前容器进行Copy,复制出一个新的容器,然后新的容器里添加删除元素,添加删除完元素之后,再将原容器的引用指向新的容器,整个过程加锁,保证了写的线程安全。
- 而因为写操作的时候不会对当前容器做任何处理,所以我们可以对容器进行并发的读,而不需要加锁,也就是读写分离。
- 一般来讲我们使用时,会用一个线程向容器中添加元素,一个线程来读取元素,而读取的操作往往更加频繁。写操作加锁保证了线程安全,读写分离保证了读操作的效率,简直完美。
- 补充(sxt2):
写时复制的概念:CopyOnWrite容器即写时复制的容器。往一个容器添加元素的时候,不直接往当前容器Object[]添加,而是先将当前容器Object[]进行复制,复制出一个新的容器Object[] newElements,然后向新的容器里添加元素,添加完元素之后,再将原容器的引用指向新的容器。这样做的好处是我们可以对CopyOnWrite容器进行并发的读,而不需要加锁,因为当前容器不会添加任何元素。所以CopyOnWrite容器也是一种读写分离的思想,读和写不同的容器。
Collections.synchronizedList和CopyOnWriteArrayList的异同点?
1)同: 实现线程安全的列表方式
2)异:- synchronizedList的add和get都是使用同步锁。
读写比较均匀的并发场景。
多线程下写性能比COWAL要好很多,而读采用了synchronized,读性能不如COWAL。 - CopyOnWriteArrayList 的add使用可重入锁,get数据无锁。
读多写少的并发场景。写性能较差,而多线程的读性能较好。发生修改时候做copy,新老版本分离,保证读的高性能,适用于以读为主,读远远大于写的场景中使用,比如缓存。比如白名单,黑名单,商品类目的访问和更新场景。
优点:可以进行并发的读,而不需要加锁,因为当前容器不会添加任何元素。
- synchronizedList的add和get都是使用同步锁。
CopyOnWriteArrayList的加锁时机?
写的时候CopyOnWriteArrayList写的时候读会读到空数据吗?
- 读取操作没有任何同步控制和锁操作,理由就是内部数组array不会发生修改,只会被另外一个 array 替换,因此可以保证数据安全。
- 添加集合的时候加了锁,保证了同步,避免了多线程写的时候会copy出多个副本出来。
2. Map--HashMap
3. Map--ConcurrentHashMap
|jg:集合|
ConcurrentHashMap原理? |3
https://www.cnblogs.com/lujiango/p/7580558.htmlConcurrentHashMap在jdk1.7/1.8里面的区别?
【ConcurrentHashmap和Hashtable都是支持并发的,这样会有一个问题,当你通过get(k)获取对应的value时,如果获取到的是null时,你无法判断,它是put(k,v)的时候value为null,还是这个key从来没有做过映射。HashMap是非并发的,可以通过contains(key)来做这个判断。而支持并发的Map在调用m.contains(key)和m.get(key),m可能已经不同了。】
并发了解过吗,ConcurrentHashMap 为什么能实现线程安全
- 使用了大量 synchronized,以及 CAS 无锁操作以保证 ConcurrentHashMap 操作的线程安全性。
- 底层数据结构改变为采用数组+链表+红黑树的数据形式。
https://juejin.im/post/5aeeaba8f265da0b9d781d16
CurrentHashMap和HashMap的区别?
1)区别
HashMap是线程不安全的?
原因:
1、方法不是同步的
2、resize()方法在高并发的情况下,可能会引起死循环。
场景:resize()进行扩容时,需要rehash(),就是重新计算已有结点存放的位置。这个过程是非常耗费时间和空间的
问题关键:resize()方法中的transfer()方法进行位置重排时,因为不同的线程是对同一个数据块进行重排,所以才导致的问题
https://blog.csdn.net/hh1sdfsf56456/article/details/81331521
2)CurrentHashMap
* 利用了锁分段的思想提高了并发度
3-ThreadLocal
ThreadLocal 实现原理
1)概述- ThreadLocal 线程的“本地变量”,即每个线程都拥有该变量副本,达到人手一份的效果,各用各的这样就可以避免共享资源的竞争。
2)实现 - 数据都放在了threadLocalMap中,threadLocal 的 get,set 和 remove 方法实际上具体是通过 threadLocalMap 的 getEntry,set 和 remove 方法实现的。
- ThreadLocalMap 是 threadLocal 一个静态内部类
① Entry - ThreadLocalMap 内部维护了一个 Entry 类型的 table 数组。
& table 数组的长度为 2 的幂次方。
& Entry 是一个以 ThreadLocal 为 key,Object 为 value 的键值对 - threadLocal 的内存泄漏问题
② set 方法:散列表实现 - 散列表就是一个包含关键字的固定大小的数组,通过使用散列函数,将关键字映射到数组的不同位置。
- 散列冲突:经常会出现多个关键字散列值相同的情况(被映射到数组的同一个位置),我们将这种情况称为散列冲突。
- 解决散列冲突的两种方式: 分离链表法(separate chaining)和开放定址法(open addressing)
- 分散链表法:使用链表解决冲突,将散列值相同的元素都保存到一个链表中。如 hashMap,concurrentHashMap 的拉链法。
- ThreadLocalMap 中使用开放地址法来处理散列冲突,而 HashMap 中使用的分离链表法。之所以采用不同的方式主要是因为:在 ThreadLocalMap 中的散列值分散的十分均匀,很少会出现冲突。并且 ThreadLocalMap 经常需要清除无用的对象,使用纯数组更加方便。
https://juejin.im/post/5aeeb22e6fb9a07aa213404a
③ getEntry 方法 - 若能当前定位的 entry 的 key 和查找的 key 相同的话就直接返回这个 entry,否则的话就是在 set 的时候存在 hash 冲突的情况,需要通过 getEntryAfterMiss 做进一步处理。
④ remove
通过往后环形查找到与指定 key 相同的 entry 后,先通过 clear 方法将 key 置为 null 后,使其转换为一个脏 entry,然后调用 expungeStaleEntry 方法将其 value 置为 null,以便垃圾回收时能够清理,同时将 table[i]置为 null。
3)应用场景
ThreadLocal 不是用来解决共享对象的多线程访问问题的,数据实质上是放在每个 thread 实例引用的 threadLocalMap,也就是说每个不同的线程都拥有专属于自己的数据容器(threadLocalMap),彼此不影响。因此 threadLocal 只适用于 共享对象会造成线程安全 的业务场景。比如hibernate 中通过 threadLocal 管理 Session就是一个典型的案例,不同的请求线程(用户)拥有自己的 session,若将 session 共享出去被多线程访问,必然会带来线程安全问题。
https://juejin.im/post/5aeeb22e6fb9a07aa213404a
4)问题
可能存在内存泄漏
- ThreadLocal 线程的“本地变量”,即每个线程都拥有该变量副本,达到人手一份的效果,各用各的这样就可以避免共享资源的竞争。
ThreadLocal如何使用,ThreadLocal会产生内存泄露的原因
ThreadLocal的作用和应用场景。
3-CopyOnWriteArraySet
Set非线程安全
1) 线程安全问题
故障现象:java.util.ConcurrentModificationException(并发修改异常)Collections.syschronizedSet(new hashSet<>());new CopyOnWriteArraySet<>(); //底层还是CopyOnWriteArrayList()方法实现的
4-Queue
- 分类:
- Java 提供的线程安全的 Queue可以分为阻塞队列和非阻塞队列;
- 阻塞队列的典型例子是BlockingQueue,非阻塞队列的典型例子是 ConcurrentLinkedQueue,在实际应用中要根据实际需要选用阻塞队列或者非阻塞队列。
- 阻塞队列可以通过加锁来实现,非阻塞队列可以通过 CAS 操作实现。
ConcurrentLinkedQueue
- ConcurrentLinkedQueue
- ConcurrentLinkedQueue这个队列使用链表作为其数据结构.ConcurrentLinkedQueue 应该算是在高并发环境中性能最好的队列了。它之所有能有很好的性能,是因为其内部复杂的实现。
- ConcurrentLinkedQueue 主要使用 CAS 非阻塞算法来实现线程安全。
- ConcurrentLinkedQueue 适合在对性能要求相对较高,同时对队列的读写存在多个线程同时进行的场景,即如果对队列加锁的成本较高则适合使用无锁的 ConcurrentLinkedQueue 来替代。
BlockingQueue
阻塞队列知道吗?
- 1> 队列+阻塞队列
- 阻塞队列,顾名思义,首先是一个队列,而一个阻塞队列在数据结构中所起的作用大致如下图所示:
- 试图从空的阻塞队列中获取元素的线程将会被阻塞,直到其他的线程往空的队列插入新的元素。
试图往已满的阻塞队列中添加新元素的线程同样也会被阻塞,直到其他的线程从列中移除一个或者多个元素或者完全清空队列后使队列重新变得空闲起来并后序新增。
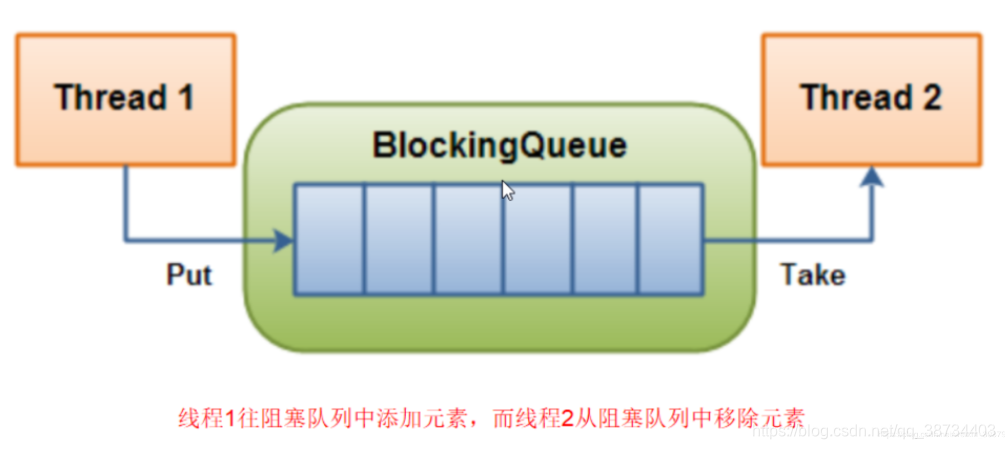
- 当阻塞队列为空时,从队列中获取元素的操作将会被阻塞。
- 当阻塞队列为满时,从队列里添加元素的操作将会被阻塞。
- 2> 为什么用?有什么好处?
- 在多线程领域:所谓阻塞,在某些情况下会挂起线程(阻塞),一旦条件满足,被挂起的线程又会自动被唤醒。
- 为什么需要BlockingQueue
好处是我们不需要关心什么时候需要阻塞线程,什么时候唤醒线程,因为这一切BlockingQueue都给你一手包办了。
- 3> BlockingQueue的核心方法
① ArrayBlockingQueue:是一个基于数组结构的有界阻塞队列,此队列按FIFO(先进先出)原则进行排序。
② LinkedBlockingQueue:一个基于链表结构的阻塞队列,此队列按FIFO(先进新出)排序元素,吞吐量通常要高于ArrayBlockingQueue。

③ SynchronousQueue:一个不存储元素的阻塞队列。每个插入操作必须等到另一个线程调用移除操作,否则插入操作一直处于阻塞状态,吞吐量通常要高于LinkedBlockingQueue。
-- SynchronousQueue没有容量
-- 与其他BlockingQueue不同,SynchronousQueue是一个不存储元素的BlockingQueue
-- 每一个put操作必须要等待一个take操作,否则不能继续添加元素,反之亦然。 - 4> 架构梳理+种类分析
1) 架构介绍
COllection-Queue-BlockingQueue
2) 种类分析
-- ArrayBlockingQueue: 由数组结构组成的有界阻塞队列。
-- LinkedBlockingQueue: 由链表结构组成的有界(但大小默认值为Integer.MAX_VALUE)阻塞队列。
-- PriorityBlockingQueue: 支持优先级排序的无界阻塞队列。
-- DelayQueue: 使用优先级队列实现的延迟无界阻塞队列。
-- SynchronousQueue: 不存储元素的阻塞队列,也即单个元素的队列。
-- LinkedTransferQueue: 由链表结构组成无界阻塞队列。
-- LinkedBlockingDque: 由链表结构组成的双向阻塞队列。 - 5> 用在哪里
① 生产者消费者模式
1)传统版 - 2.0版生产者消费者:sync、wait、notify => lock、await、singal
- 多线程创判断while
2)阻塞队列版
代码44:https://blog.csdn.net/weixin_39879073/article/details/93379162
② 线程池
③ 消息中间件
- 1> 队列+阻塞队列
如何设计一个消息队列
消息队列的作用
使用过哪些任务队列?
1)线程池-ArrayBlockingQueue
8-原子类
AtomicInterger
会问:CAS -> Unsafe > CAS底层 -> ABA -> 原子引用更新 -> 如何规避ABA
讲一讲AtomicInteger,为什么要用CAS而不是syschronized?
回答即可:① 底层原理:自旋锁;② Unsafe类(Unsafe类+CAS思想,即自旋)
syschronized一个时间段只允许一个线程访问,保证了一致性,并发性下降;CAS中的do-while没有加锁,可以反复的通过CAS比较,知道成功,既保证一致性,又提高了并发性。
1)CAS底层原理
① atomicInteger.getAndIncreament:解决i++线程安全问题- 方法调用的 unsafe.getAndAddInt(this,valueoffset,1)
this:当前对象
valueoffset:内存偏移量,即内存地址
getAndAddInt:在unsafe类,实现使用了先获取当前地址值getIntVolatile,再比较交换compareAndSwapInt,没得到正确值会一直CAS
2)UnSafe:JVM的原始类,native
- Unsafe 是 CAS 的核心类,由于 Java 方法无法直接访问底层系统,而需要通过本地(native)方法来访问, Unsafe 类相当一个后门,基于该类可以直接操作特定内存的数据。Unsafe 类存在于 sun.misc 包中,其内部方法操作可以像 C 指针一样直接操作内存,因为 Java 中 CAS 操作执行依赖于 Unsafe 类。
- 变量 vauleOffset,表示该变量值在内存中的偏移量,因为 Unsafe 就是根据内存偏移量来获取数据的。
- 变量 value 用 volatile 修饰,保证了多线程之间的内存可见性。
- Unsafe类中的compareAndSwaoInt,是一个本地方法,实现位于unsafe.cpp中。
3)CAS是什么
- CAS 的全称 Compare-And-Swap,它是一条 CPU 并发原语。
- 它的功能是判断内存某一个位置的值是否为预期,如果是则更改这个值,这个过程就是原子的。
- CAS 并发原体现在 JAVA 语言中就是 sun.misc.Unsafe 类中的各个方法。调用 UnSafe 类中的 CAS 方法,JVM 会帮我们实现出 CAS 汇编指令。这是一种完全依赖硬件的功能,通过它实现了原子操作。由于 CAS 是一种系统源语,源语属于操作系统用语范畴,是由若干条指令组成,用于完成某一个功能的过程,并且原语的执行必须是连续的,在执行的过程中不允许被中断,也就是说 CAS 是一条原子指令,不会造成所谓的数据不一致的问题。(即线程安全)
- 方法调用的 unsafe.getAndAddInt(this,valueoffset,1)
CAS的缺点
- 代码如下:
public final int getAndAddInt(Object var1, long var2, int var4) {int var5;do {var5 = this.getIntVolatile(var1, var2);} while(!this.compareAndSwapInt(var1, var2, var5, var5 + var4));return var5;}
1)循环时间长开销很大:
有个do-while,CAS失败会一直尝试,会给CPU带来很大开销,效率低于 synchronized
2)只能保证一个共享变量的原子操作
多共享变量,循环CAS会破坏原子性,只能加锁
3)ABA问题- 代码如下:
原子类AtomicInterger的ABA问题?原子更新引用知道吗?
1)CAS会导致ABA问题- CAS算法实现一个重要前提需要取出内存中某时刻的数据并在当下时刻比较并替换,那么在这个时间差类会导致数据的变化。
- 示例:(一个慢取出后挂起,快的已经更改了值,慢的再用原来的值更改)
有线程one,two两个线程,one线程较慢需要十秒钟,two线程较快尽需两秒,
一个线程one从内存位置中取出A,这时候另一个线程two也从内存中取出A,并且线程two进行了一些操作将值变成了B,然后线程内有一些其他操作two又将V位置的数据变成A,这时候线程one进行CAS操作发现内存中仍然是A,然后线程one操作成功。 - 尽管线程one的CAS操作成功,但是不代表这个过程就是没有问题的。因为one得到的这个内存中的值已经发生了许多问题.
2)原子引用:AotmicReference类
AotmicReference<User> aotmicReference = new AotmicReference<>();aotmicReference.set();aotmicReference.compareAndSet();
3)时间戳原子引用
- 新增一种修改版本号的机制(类似时间戳)
4)问题解决 - AtomicStampedReference类,boolean
atomicStampedReference=new AtomicStampedReference<>(值,时间戳-版本号)atomicStampedReference.compareAndSet(现值,期望值,期望版本号,新版本号)
自旋锁
是什么(sxt2)
- 自旋锁(spinlock):尝试获取锁的线程不会立即阻塞,而是采取循环的方式去获取锁,这样的好处是减少线程上下文切换的消耗,缺点是循环会消耗CPU。(阻塞的反义自旋)
手写一个自旋锁(sxt2)
import java.util.concurrent.TimeUnit;import java.util.concurrent.atomic.AtomicReference;/*** 题目:实现一个自旋锁* 自旋锁好处:循环比较获取直至成功为止,没有类似wait的阻塞。** 通过CAS操作完成自旋锁,A线程先进来调用myLock方法,自己持有5秒钟,* B随后进来后发现,当前线程持有锁,不是null,* 所以只能通过自旋等待,直到A释放锁后B随后抢到。*/public class SpinLockDemo {// 原子引用线程AtomicReference<Thread> atomicReference = new AtomicReference<>();public void myLock(){Thread thread = Thread.currentThread(); // 当前进来的线程System.out.println(thread.getName() + "\t come in!");while(!atomicReference.compareAndSet(null,thread)){//期望值,现值为null,当前线程进去}}// 解锁public void myUnlock(){Thread thread = Thread.currentThread();atomicReference.compareAndSet(thread,null); // 用完,设置为nullSystem.out.println(thread.getName() + "\t invoked myUnlock()");}public static void main(String[] args) {SpinLockDemo spinLockDemo = new SpinLockDemo();new Thread(()->{spinLockDemo.myLock();// 暂停一会线程try {TimeUnit.SECONDS.sleep(5);} catch (InterruptedException e) {e.printStackTrace();}spinLockDemo.myUnlock();},"AA").start();// 保证A先启动try {TimeUnit.SECONDS.sleep(1);} catch (InterruptedException e) {e.printStackTrace();}new Thread(()->{spinLockDemo.myLock();spinLockDemo.myUnlock();},"BB").start();}}
乐观锁
乐观锁 悲观锁 适用场景?
CAS原理及实现。
1) 概述- CAS 是 compare and swap 的缩写,即我们所说的比较交换。
- cas 是一种基于锁的操作,而且是乐观锁。在 java 中锁分为乐观锁和悲观锁。悲观锁是将资源锁住,等一个之前获得锁的线程释放锁之后,下一个线程才可以访问。而乐观锁采取了一种宽泛的态度,通过某种方式不加锁来处理资源,比如通过给记录加 version 来获取数据,性能较悲观锁有很大的提高。
- CAS 操作
包含三个操作数 —— 内存位置(V)、预期原值(A)和新值(B)。如果内存地址里面的值和 A 的值是一样的,那么就将内存里面的值更新成 B。CAS是通过无限循环来获取数据的,若果在第一轮循环中,a 线程获取地址里面的值被b 线程修改了,那么 a 线程需要自旋,到下次循环才有可能机会执行。 - java.util.concurrent.atomic 包下的类大多是使用 CAS 操作来实现的(AtomicInteger,AtomicBoolean,AtomicLong)。
2)CAS 的会产生什么问题?
- ABA 问题:
比如说一个线程 one 从内存位置 V 中取出 A,这时候另一个线程 two 也从内存中取出 A,并且 two 进行了一些操作变成了 B,然后 two 又将 V 位置的数据变成 A,这时候线程 one 进行 CAS 操作发现内存中仍然是 A,然后 one 操作成功。尽管线程 one 的 CAS 操作成功,但可能存在潜藏的问题。从 Java1.5 开始 JDK 的 atomic包里提供了一个类 AtomicStampedReference 来解决 ABA 问题。
说说自旋锁咋实现的
1)概念
自旋锁(spinlock):是指当一个线程在获取锁的时候,如果锁已经被其它线程获取,那么该线程将循环等待,然后不断的判断锁是否能够被成功获取,直到获取到锁才会退出循环。
2)存在的问题
① 如果某个线程持有锁的时间过长,就会导致其它等待获取锁的线程进入循环等待,消耗CPU。使用不当会造成CPU使用率极高。
② 上面Java实现的自旋锁不是公平的,即无法满足等待时间最长的线程优先获取锁。不公平的锁就会存在“线程饥饿”问题。
3)优点
① 自旋锁不会使线程状态发生切换,一直处于用户态,即线程一直都是active的;不会使线程进入阻塞状态,减少了不必要的上下文切换,执行速度快。
3)例子ublic class SpinLock {private AtomicReference cas = new AtomicReference();public void lock() {Thread current = Thread.currentThread();// 利用CASwhile (!cas.compareAndSet(null, current)) {// DO nothing}}public void unlock() {Thread current = Thread.currentThread();cas.compareAndSet(current, null);}}
lock()方法利用的CAS,当第一个线程A获取锁的时候,能够成功获取到,不会进入while循环,如果此时线程A没有释放锁,另一个线程B又来获取锁,此时由于不满足CAS,所以就会进入while循环,不断判断是否满足CAS,直到A线程调用unlock方法释放了该锁。
https://www.jianshu.com/p/9d3660ad4358乐观锁的了解,比如AtomicInteger?答:自增典型的实现了乐观锁,原理为CAS自旋,具体说了说CAS如何自旋
1) 概念:
乐观锁与之相反,它总是假设别的线程取数据的时候不会修改数据,所以不会上锁,但是会在更新的时候判断有没有更新过数据。
2) 乐观锁实现
乐视锁的实现之一就是CAS算法,CAS算法的过程大致是这样的:它包含三个参数CAS(V, E, N)。
V表示要更新的变量、E表示预期值、N表示新值
仅当V等于E的时候,才会把V的值设置成N,否则不会执行任何操作(比较和替换是一个原子操作)。如果V值和E值不相等,则说明有其他线程修改过V值,当前线程什么都不做,最后返回当前V的真实值。CAS操作是抱着乐观的态度进行的,它总是认为自己可以成功的完成操作。当多个线程同时使用CAS操作一个变量时,只有一个会成功更新,其余都会失败。失败的线程不会被挂起,仅是被告知失败,并且允许再次尝试,当然也允许失败的线程放弃操作。
https://juejin.im/post/5bfa85bbf265da613e21e9ac
https://www.jianshu.com/p/e674ee68fd3f
高并发的情况下,i++无法保证原子性,往往会出现问题,所以引入AtomicInteger类。
https://www.jianshu.com/p/4ed887664b13
https://blog.csdn.net/fanrenxiang/article/details/80623884说说CLH锁:CLH队列锁
- CLH是一种基于单向链表的高性能、公平的自旋锁。
https://blog.csdn.net/claram/article/details/83828768 - CLH(Craig,Landin,and Hagersten)队列是一个虚拟的双向队列(虚拟的双向队列即不存在队列实例,仅存在结点之间的关联关系)。AQS是将每条请求共享资源的线程封装成一个CLH锁队列的一个结点(Node)来实现锁的分配。
- CLH是一种基于单向链表的高性能、公平的自旋锁。
9. 线程池
JVM如何查看运行的线程数量?
怎么控制两个线程交替执行
交替执行银行转账多线程实现方法
谈谈你对多线程的理解?
为什么用线程池,优势 (sxt2)
- 预备知识
例子:原(一个cpu):一个小丑玩4个球;现(多个cpu):4个小丑每人一个
cpu核数:Runtime.getRuntime().avaliableProcessors()
省略了上下文的切换 - 为什么 & 优势
线程池做的工作主要是控制运行的线程的数量,处理过程中将任务放入队列,然后再线程创建后启动这些任务,如果线程数量超过了最大数量,超出数量的线程排队等候,等其它线程执行完毕,再从队列中取出任务来执行。
他的主要特点为:线程复用、控制最大并发数,管理线程。
第一:降低资源消耗。通过重复利用已创建的线程降低线程创建和销毁造成的消耗。
第二:提高响应速度。当任务到达时,任务可以不需要等到线程创建就能立即执行。
第三:提高线程的可管理性。线程是稀缺资源,如果无限制的创建,不仅会消耗系统资源,还会降低系统的稳定性,使用线程池可以进行统一的分配,调优和监控。
- 预备知识
1-Executor
Executor service?
🙋 Executor框架不仅包括了线程池的管理,还提供了线程工厂、队列以及拒绝策略等,Executor框架让并发编程变得更加简单。- Executor 框架结构(3大部分组成)
1) 任务(Runnable /Callable)
执行任务需要实现的Runnable接口或Callable接口。Runnable 接口或Callable接口实现类都可以被ThreadPoolExecutor或ScheduledThreadPoolExecutor 执行。
2) 任务的执行(Executor)
如下图所示,包括任务执行机制的核心接口 Executor ,以及继承自 Executor 接口的 ExecutorService 接口。ThreadPoolExecutor 和 ScheduledThreadPoolExecutor 这两个关键类实现了 ExecutorService 接口。

-- 这里提了很多底层的类关系,但是,实际上我们需要更多关注的是 ThreadPoolExecutor这个类,这个类在我们实际使用线程池的过程中,使用频率还是非常高的。
-- 注意: 通过查看 ScheduledThreadPoolExecutor 源代码我们发现 ScheduledThreadPoolExecutor 实际上是继承了 ThreadPoolExecutor 并实现了 ScheduledExecutorService ,而 ScheduledExecutorService 又实现了 ExecutorService,正如我们下面给出的类关系图显示的一样。
/** ① ThreadPoolExecutor 类描述: *///AbstractExecutorService实现了ExecutorService接口public class ThreadPoolExecutor extends AbstractExecutorService/** ② ScheduledThreadPoolExecutor 类描述: *///ScheduledExecutorService继承ExecutorService接口public class ScheduledThreadPoolExecutorextends ThreadPoolExecutorimplements ScheduledExecutorService
3) 异步计算的结果(Future)
Future 接口以及 Future 接口的实现类FutureTask类都可以代表异步计算的结果。
-- 当我们把 Runnable接口 或 Callable 接口 的实现类提交给 ThreadPoolExecutor 或 ScheduledThreadPoolExecutor 执行。(调用 submit() 方法时会返回一个 FutureTask 对象)- Executor框架的使用示意图
1> 主线程首先要创建实现 Runnable 或者 Callable 接口的任务对象。
2> 把创建完成的实现 Runnable/Callable接口的对象直接交给ExecutorService 执行: ExecutorService.execute(Runnable command))或者也可以把 Runnable 对象或Callable 对象提交给 ExecutorService 执行(ExecutorService.submit(Runnable task)或 ExecutorService.submit(Callable task))。
3> 如果执行 ExecutorService.submit(…),ExecutorService 将返回一个实现Future接口的对象(我们刚刚也提到过了执行execute()方法和 submit()方法的区别,submit()会返回一个FutureTask对象)。由于 FutureTask 实现了Runnable,我们也可以创建FutureTask,然后直接交给 ExecutorService 执行。
4> 最后,主线程可以执行FutureTask.get()方法来等待任务执行完成。主线程也可以执行 FutureTask.cancel(boolean mayInterruptIfRunning)来取消此任务的执行。

- Executor 框架结构(3大部分组成)
2-ThreadPoolExecutor的理解
参数
线程池的参数解释
- ThreadPoolExecutor类中提供的四个构造方法。
-- 其余三个如下构造方法的基础上产生(默认某些参数,如默认拒绝策略)
public ThreadPoolExecutor(int corePoolSize,int maximumPoolSize,long keepAliveTime,TimeUnit unit,BlockingQueue<Runnable> workQueue,ThreadFactory threadFactory,RejectedExecutionHandler handler) {if (corePoolSize < 0 ||maximumPoolSize <= 0 ||maximumPoolSize < corePoolSize ||keepAliveTime < 0)throw new IllegalArgumentException();if (workQueue == null || threadFactory == null || handler == null)throw new NullPointerException();this.acc = System.getSecurityManager() == null ?null :AccessController.getContext();this.corePoolSize = corePoolSize;this.maximumPoolSize = maximumPoolSize;this.workQueue = workQueue;this.keepAliveTime = unit.toNanos(keepAliveTime);this.threadFactory = threadFactory;this.handler = handler;}
- ThreadPoolExecutor类中提供的四个构造方法。
7大参数(sxt2)
1)corePoolSize:线程池中的常驻核心线程池数
2)maximumPoolSize:线程池能够容纳同时执行的最大线程数,此值必须大于等于1
3)keepAliveTime:多余的空闲线程的存活时间
当前线程池数量超过corePoolSize时,当空闲时间达到keepAliveTime值时,多余的空闲线程会被销毁直到只剩下corePoolSize个线程为止。
(注,只有当线程池中的线程数大于corePoolSize时才会起作用,直到线程池中的线程数不大于corePoolSize)
4)unit:keepAliveTime的单位。
5)workQueue:任务队列,被提交但尚未执行的任务。(相当于候客区)
用于保存任务的阻塞队列。可以使用ArrayBlockingQueue,LinkedBlockingQueue, SynchronousQueue, PriorityBlockingQueue。
6)threadFactory:表示生成线程池中工作线程的线程工厂,用于创建线程,一般默认的的即可。executor 创建新线程的时候会用到。
7)handler:拒绝策略,表示当队列满了并且工作线程大于等于线程池的最大线程数(maximumPoolSize)时如何来拒绝线程池的拒绝策略,以及默认?。
1) 是什么:等待队列也已经排满了,再也塞不下新任务了,同时,线程池中的max线程也达到了,无法继续为新任务服务。这时候就需要拒绝策略机制合理的处理这个问题。
2) 场景:线程池的任务缓存队列已满并且线程池中的线程数目达到maximumPoolSize时。
3) JDK内置的4种策略:
① ThreadPoolExecutor.AbortPolicy(默认):
丢弃所提交的任务并抛出RejectedExecutionException异常组织系统正常运行。
② ThreadPoolExecutor.DiscardPolicy:
丢弃任务,不做任何处理也不抛出异常。如果允许任务丢失,这是最好的一种方案。
③ ThreadPoolExecutor.DiscardOldestPolicy:
丢弃队列最前面的(即队列中等待最久的任务)任务,然后把当前被拒绝的任务加入队列重新提交。
④ ThreadPoolExecutor.CallerRunsPolicy:
由调用线程(提交任务的线程)处理该任务。"调用者运行"的一种调节机制,该策略既不会抛弃任务,也不会抛出异常,而是将某些任务回退到调用者,- 默认的拒绝策略从而降低新任务的流量。
4) 以上内置拒绝策略均实现了RejectedExecutionHanlder接口
- 默认的拒绝策略从而降低新任务的流量。
核心线程数与最大的线程数的区别/为什么存在? |2
说一下概念并分析一下整个线程流程
创建
多线程的实现方法/方式? |2
- 方式一:ThreadPoolExecutor构造函数实现

- 方式二:Executor框架的工具类Executors实现( 可以创建三种类型的 ThreadPoolExecutor):
FixedThreadPool
SingleThreadExecutor
CachedThreadPool

- 方式一:ThreadPoolExecutor构造函数实现
线程池用过吗?ThreadPoolExecutor谈谈你的理解? (sxt2)
1) 创建多线程的方式
① 通过继承Thread类,重写run方法;
② 通过实现runable接口;class MyThread implements Runnable{@Overridepublic void run(){...}}
③ 通过实现Callable接口; - 现在常用
class MyThread implements Callable<Integer>{@Overridepublic Interger call() throws Exception{sout("Callable 实现。。。");return null; // 如,return 1024;}}
Runnable、Callable区别
- Runnable没有返回值,Callable有返回值
- Runnable不会抛异常,Callable会抛异常
- Runnable生成run方法,Callable生成call方法
创建
public class CallableDemo{psvm{//FutureTask(Callable<V> callbel)FutureTask<Interger> futureTask = new FutureTask<>(new Mythread());Thread t1 = new Thread(futureTask,“线程名称”);t1.start();sout(futureTask.get()); // 获得 1024返回值}}
分支合并(forkjoin
public class CallableDemo{psvm{ //两个线程,一个main主线程,一个是AAfutureTask//FutureTask(Callable<V> callbel)FutureTask<Interger> futureTask = new FutureTask<>(new Mythread());Thread t1 = new Thread(futureTask,“线程名称”);t1.start(); // 可合并为:new Thread(futureTask,“AA”).start();// new Thread(futureTask,“AA”).start(); //共用一个futureTask只计算一次,可以再newint result01 = 100;//while(!futureTask.isDone()){ //如果没计算完,折中//}int result02 = futureTask.get(); // get()方法建议放在最后// 要求获得Callable线程的计算记过,如果没有计算完成就要去强求,会导致堵塞,直到计算完成。sout(result01 + result02); // 1124}}
④ 线程池
ThreadPoolExecutor创建线程池
- Runnable+ThreadPoolExecutor
代码中模拟了 10 个任务,我们配置的核心线程数为 5 、等待队列容量为 100 ,所以每次只可能存在 5 个任务同时执行,剩下的5个任务会被放到等待队列中去。当前的5个任务中如果有任务被执行完了,线程池就会去拿新的任务执行。
① 创建一个 Runnable 接口的实现类
/** 一个简单的Runnable类,需要大约5秒钟来执行其任务。*/public class MyRunnable implements Runnable {private String command;public MyRunnable(String s) {this.command = s;}@Overridepublic void run() {System.out.println(Thread.currentThread().getName() + " Start. Time = " + new Date());processCommand();System.out.println(Thread.currentThread().getName() + " End. Time = " + new Date());}private void processCommand() {try {Thread.sleep(5000);} catch (InterruptedException e) {e.printStackTrace();}}@Overridepublic String toString() {return this.command;}}
② 测试程序,ThreadPoolExecutor 构造函数自定义参数创建线程池。
public class ThreadPoolExecutorDemo {private static final int CORE_POOL_SIZE = 5;private static final int MAX_POOL_SIZE = 10;private static final int QUEUE_CAPACITY = 100;private static final Long KEEP_ALIVE_TIME = 1L;public static void main(String[] args) {//通过ThreadPoolExecutor构造函数自定义参数创建ThreadPoolExecutor executor = new ThreadPoolExecutor(CORE_POOL_SIZE,MAX_POOL_SIZE,KEEP_ALIVE_TIME,TimeUnit.SECONDS,new ArrayBlockingQueue<>(QUEUE_CAPACITY),new ThreadPoolExecutor.CallerRunsPolicy());// 创建10个for (int i = 0; i < 10; i++) {//创建WorkerThread对象(WorkerThread类实现了Runnable 接口)Runnable worker = new MyRunnable("" + i);//执行Runnableexecutor.execute(worker);}//终止线程池executor.shutdown();while (!executor.isTerminated()) {}System.out.println("Finished all threads");}}
- Runnable+ThreadPoolExecutor
/** ① MyCallable.java */public class MyCallable implements Callable<String> {@Overridepublic String call() throws Exception {Thread.sleep(1000);//返回执行当前 Callable 的线程名字return Thread.currentThread().getName();}}/** ② CallableDemo.java */public class CallableDemo {public static void main(String[] args) {//通过ThreadPoolExecutor构造函数自定义参数创建ThreadPoolExecutor executor = new ThreadPoolExecutor(5,10,1L,TimeUnit.SECONDS,new ArrayBlockingQueue<>(100),new ThreadPoolExecutor.CallerRunsPolicy());List<Future<String>> futureList = new ArrayList<>();Callable<String> callable = new MyCallable();for (int i = 0; i < 10; i++) {//提交任务到线程池Future<String> future = executor.submit(callable);//将返回值 future 添加到 list,我们可以通过 future 获得执行 Callable 得到的返回值futureList.add(future);}for (Future<String> fut : futureList) {try {System.out.println(new Date() + "::" + fut.get());} catch (InterruptedException | ExecutionException e) {e.printStackTrace();}}//关闭线程池executor.shutdown();}}
- Runnable+ThreadPoolExecutor
区别
- execute() vs submit()
execute()方法用于提交不需要返回值的任务,所以无法判断任务是否被线程池执行成功与否;
submit()方法用于提交需要返回值的任务。线程池会返回一个 Future类型的对象,通过这个 Future 对象可以判断任务是否执行成功 ,并且可以通过 Future 的 get()方法来获取返回值,get()方法会阻塞当前线程直到任务完成,而使用 get(long timeout,TimeUnit unit)方法则会阻塞当前线程一段时间后立即返回,这时候有可能任务没有执行完。
-- submit():
以AbstractExecutorService接口中的一个submit 方法为例子来看看源代码:
public Future<?> submit(Runnable task) {if (task == null) throw new NullPointerException();RunnableFuture<Void> ftask = newTaskFor(task, null);execute(ftask);return ftask;}// 上面方法调用的 newTaskFor 方法返回了一个 FutureTask 对象。protected <T> RunnableFuture<T> newTaskFor(Runnable runnable, T value) {return new FutureTask<T>(runnable, value);}
-- execute()方法:
public void execute(Runnable command) {...}
- isTerminated() VS isShutdown()
isShutDown 当调用 shutdown() 方法后返回为 true。
isTerminated 当调用 shutdown() 方法后,并且所有提交的任务完成后返回为 true
- execute() vs submit()
多线程相关:如何停止线程?
- 关闭线程池,可以通过shutdown和shutdownNow这两个方法。它们的原理都是遍历线程池中所有的线程,然后依次中断线程。shutdown和shutdownNow还是有不一样的地方:
-- shutdown只是将线程池的状态设置为SHUTDOWN状态,然后中断所有没有正在执行任务的线程,队列里的任务会执行完毕。
-- shutdownNow首先将线程池的状态设置为STOP,然后尝试停止所有的正在执行和未执行任务的线程,并返回等待执行任务的列表; - 看出 shutdown 方法会将正在执行的任务继续执行完,而 shutdownNow 会直接中断正在执行的任务。调用了这两个方法的任意一个,isShutdown方法都会返回 true,当所有的线程都关闭成功,才表示线程池成功关闭,这时调用isTerminated方法才会返回 true。
- 关闭线程池,可以通过shutdown和shutdownNow这两个方法。它们的原理都是遍历线程池中所有的线程,然后依次中断线程。shutdown和shutdownNow还是有不一样的地方:
原理
完整的线程池执行的流程/任务提交流程?
当一个并发任务提交给线程池,线程池分配线程去执行任务的过程:

1) 先判断线程池中核心线程池所有的线程是否都在执行任务。如果不是,则新创建一个线程执行刚提交的任务,否则,核心线程池中所有的线程都在执行任务,则进入第 2 步;
2) 判断当前阻塞队列是否已满,如果未满,则将提交的任务放置在阻塞队列中;否则,则进入第 3 步;
3) 判断线程池中所有的线程是否都在执行任务,如果没有,则创建一个新的线程来执行任务,否则,则交给饱和策略进行处理
https://juejin.im/post/5aeec0106fb9a07ab379574f说说线程池的底层工作原理?(sxt2)
- 图为ThreadPoolExecutor的execute方法的执行示意图:

1) 在创建了线程池后,等待提交过来的任务请求
2) 当调用execute()方法添加一个请求任务时,线程池会做如下判断
2.1 如果正在运行的线程数量小于corePoolSize,那么马上创建线程运行这个任务
2.2 如果正在运行的线程数量大于或等于corePoolSize,那么将这个任务放入队列
2.3 如果这时候队列满了且正在运行的线程数量还小于maximumPoolSize,那么还是要创建非核心线程立刻运行这个任务
2.4 如果队列满了且正在运行的线程数量大于或等于maximumPoolSize,那么线程池会启动饱和拒绝策略来执行
3) 当一个线程完成任务时,它会从队列中取下一个任务来执行
4) 当一个线程无事可做超过一定的时间(keepAliveTime)时,线程池会判断
4.1 如果当前运行的线程数大于corePoolSize,那么这个线程就被停掉
4.2 所以线程池的所有任务完成后它最终会收缩到corePoolSize的大小 execute方法源码
RunnableDemo中使用 executor.execute(worker)来提交一个任务到线程池中// 存放线程池的运行状态 (runState) 和线程池内有效线程的数量 (workerCount)private final AtomicInteger ctl = new AtomicInteger(ctlOf(RUNNING, 0));private static int workerCountOf(int c) {return c & CAPACITY;}//任务队列private final BlockingQueue<Runnable> workQueue;public void execute(Runnable command) {// 如果任务为null,则抛出异常。if (command == null)throw new NullPointerException();// ctl 中保存的线程池当前的一些状态信息int c = ctl.get();// 下面会涉及到 3 步 操作// 1.首先判断当前线程池中之行的任务数量是否小于 corePoolSize// 如果小于的话,通过addWorker(command, true)新建一个线程,并将任务(command)添加到该线程中;然后,启动该线程从而执行任务。if (workerCountOf(c) < corePoolSize) {if (addWorker(command, true))return;c = ctl.get();}// 2.如果当前之行的任务数量大于等于 corePoolSize 的时候就会走到这里// 通过 isRunning 方法判断线程池状态,线程池处于 RUNNING 状态才会被并且队列可以加入任务,该任务才会被加入进去if (isRunning(c) && workQueue.offer(command)) {int recheck = ctl.get();// 再次获取线程池状态,如果线程池状态不是 RUNNING 状态就需要从任务队列中移除任务,并尝试判断线程是否全部执行完毕。同时执行拒绝策略。if (!isRunning(recheck) && remove(command))reject(command);// 如果当前线程池为空就新创建一个线程并执行。else if (workerCountOf(recheck) == 0)addWorker(null, false);}//3. 通过addWorker(command, false)新建一个线程,并将任务(command)添加到该线程中;然后,启动该线程从而执行任务。//如果addWorker(command, false)执行失败,则通过reject()执行相应的拒绝策略的内容。else if (!addWorker(command, false))reject(command);}
addWorker方法源码 这个方法主要用来创建新的工作线程,如果返回true说明创建和启动工作线程成功,否则的话返回的就是false。
// 全局锁,并发操作必备private final ReentrantLock mainLock = new ReentrantLock();// 跟踪线程池的最大大小,只有在持有全局锁mainLock的前提下才能访问此集合private int largestPoolSize;// 工作线程集合,存放线程池中所有的(活跃的)工作线程,只有在持有全局锁mainLock的前提下才能访问此集合private final HashSet<Worker> workers = new HashSet<>();//获取线程池状态private static int runStateOf(int c) { return c & ~CAPACITY; }//判断线程池的状态是否为 Runningprivate static boolean isRunning(int c) {return c < SHUTDOWN;}/*** 添加新的工作线程到线程池* @param firstTask 要执行* @param core参数为true的话表示使用线程池的基本大小,为false使用线程池最大大小* @return 添加成功就返回true否则返回false*/private boolean addWorker(Runnable firstTask, boolean core) {retry:for (;;) {//这两句用来获取线程池的状态int c = ctl.get();int rs = runStateOf(c);// Check if queue empty only if necessary.if (rs >= SHUTDOWN &&! (rs == SHUTDOWN &&firstTask == null &&! workQueue.isEmpty()))return false;for (;;) {//获取线程池中线程的数量int wc = workerCountOf(c);// core参数为true的话表明队列也满了,线程池大小变为 maximumPoolSizeif (wc >= CAPACITY ||wc >= (core ? corePoolSize : maximumPoolSize))return false;//原子操作将workcount的数量加1if (compareAndIncrementWorkerCount(c))break retry;// 如果线程的状态改变了就再次执行上述操作c = ctl.get();if (runStateOf(c) != rs)continue retry;// else CAS failed due to workerCount change; retry inner loop}}// 标记工作线程是否启动成功boolean workerStarted = false;// 标记工作线程是否创建成功boolean workerAdded = false;Worker w = null;try {w = new Worker(firstTask);final Thread t = w.thread;if (t != null) {// 加锁final ReentrantLock mainLock = this.mainLock;mainLock.lock();try {//获取线程池状态int rs = runStateOf(ctl.get());//rs < SHUTDOWN 如果线程池状态依然为RUNNING,并且线程的状态是存活的话,就会将工作线程添加到工作线程集合中//(rs=SHUTDOWN && firstTask == null)如果线程池状态小于STOP,也就是RUNNING或者SHUTDOWN状态下,同时传入的任务实例firstTask为null,则需要添加到工作线程集合和启动新的Worker// firstTask == null证明只新建线程而不执行任务if (rs < SHUTDOWN ||(rs == SHUTDOWN && firstTask == null)) {if (t.isAlive()) // precheck that t is startablethrow new IllegalThreadStateException();workers.add(w);//更新当前工作线程的最大容量int s = workers.size();if (s > largestPoolSize)largestPoolSize = s;// 工作线程是否启动成功workerAdded = true;}} finally {// 释放锁mainLock.unlock();}//// 如果成功添加工作线程,则调用Worker内部的线程实例t的Thread#start()方法启动真实的线程实例if (workerAdded) {t.start();/// 标记线程启动成功workerStarted = true;}}} finally {// 线程启动失败,需要从工作线程中移除对应的Workerif (! workerStarted)addWorkerFailed(w);}return workerStarted;}
- 图为ThreadPoolExecutor的execute方法的执行示意图:
阻塞队列与拒绝策略的关系?
说一下这块流程- 阻塞队列最好是使用有界队列,如果采用无界队列的话,一旦任务积压在阻塞队列中的话就会占用过多的内存资源,甚至会使得系统崩溃。
多线程中,当线程数超过了阻塞队列的容量的情况?
说一下这块流程
当前 workQueue队列已满的话,则会创建新的线程来执行任务;如果线程个数已经超过了maximumPoolSize,则会使用饱和策略RejectedExecutionHandler来进行处理。线程池怎么保证线程一直运行的?
- 线程池当未调用 shutdown 方法时,是通过队列的 take 方法阻塞核心线程(Worker)的 run方法从而保证核心线程不被销毁的。
https://blog.csdn.net/smile_from_2015/article/details/105259789
- 线程池当未调用 shutdown 方法时,是通过队列的 take 方法阻塞核心线程(Worker)的 run方法从而保证核心线程不被销毁的。
种类
Execuors类实现的几种线程池类型,最后如何返回?
① newFixedThreadPool创建一个固定长线程池,可控制线程最大并发数,超出的线程会在队列中等待。
② newCachedThreadPool创建一个可缓存线程池,如果线程池长度超过处理需要,可灵活回收空闲线程,若无可回收,则新建线程。
③ newSingleThreadExecutor创建一个单线程化的线程池,它只会用唯一的工作线程来执行任务,保证所有任务按照指定顺序(FIFO, LIFO, 优先级)执行。
④ newScheduledThreadPool 创建一个固定长度线程池,支持定时及周期性任务执行。
线程池如何使用? (sxt2)
1) 架构说明
Java中的线程池是通过Executor框架实现的,该框架中用到了Executor,Executors(辅助工具类,如Arrays),ExecutorService,ThreadPoolExecutor(线程池的底层)这几个类。

2) 编码实现(共5种线程池)-第4中获得/使用Java多线程的方式,线程池
① 了解
-- Executors.newScheduledThreadPool()
池中任务每2'执行一次
-- Java8新出 Executors.newWorkStealingPool(int)
使用目前机器上可用的处理器作为它的并行级别(用的少,面试不怎么考)
② 重点public interface List<E> extends Collection<E> {public interface ExecutorService extends Executor {// 使用public class MyThreadPoolDemo{public static void main(String[] args) {ExecutorService threadPool = Executors.newFixedThreadPool(5);//一池5个处理线程// ExecutorService threadPool = Executors.newSingleThreadExecutor();//一池1个处理线程// ExecutorService threadPool = Executors.newCachedThreadPool();//一池N个处理线程// 模拟10个用户来办理业务,每个用户就是一个来自外部的请求线程try {for (int i = 0; i <10 ; i++) { //10个请求threadPool.execute(()->{ //LambdaSystem.out.println(Thread.currentThread().getName()+"\t 办理业务");});// TimeUnit.SECONDS.sleep(1);}}catch (Exception e){e.printStackTrace();}finally {threadPool.shutdown();//释放}}}
① Executors.newFixedThreadPool(int)
1)创建一个定长线程池,可控制线程最大并发数,超出的线程会在队列中等待。
2)newFixedThreadPool创建线程池CorePoolSize和maximumPoolSize值是相等的,使用的LinkedBlockingQueue。
适用:执行长期的任务,性能好很多。public static ExecutorService newFixedThreadPool(int nThreads) {return new ThreadPoolExecutor(nThreads, nThreads,0L, TimeUnit.MILLISECONDS,new LinkedBlockingQueue<Runnable>());}
- execute() 方法运行示意图(该图片来源:《Java 并发编程的艺术》):

1) 如果当前运行的线程数小于 corePoolSize, 2) 如果再来新任务的话,就创建新的线程来执行任务;
3) 当前运行的线程数等于 corePoolSize 后, 如果再来新任务的话,会将任务加入 LinkedBlockingQueue;
4)线程池中的线程执行完手头的任务后,会在循环中反复从 LinkedBlockingQueue 中获取任务来执行; - 为什么不推荐使用?
FixedThreadPool 使用无界队列 LinkedBlockingQueue(队列的容量为 Intger.MAX_VALUE)作为线程池的工作队列会对线程池带来如下影响 :
-- 当线程池中的线程数达到 corePoolSize 后,新任务将在无界队列中等待,因此线程池中的线程数不会超过 corePoolSize;
-- 由于使用无界队列时 maximumPoolSize 将是一个无效参数,因为不可能存在任务队列满的情况。所以,通过创建 FixedThreadPool的源码可以看出创建的 FixedThreadPool 的 corePoolSize 和 maximumPoolSize 被设置为同一个值。
-- 由于 1 和 2,使用无界队列时 keepAliveTime 将是一个无效参数;
-- 运行中的 FixedThreadPool(未执行 shutdown()或 shutdownNow())不会拒绝任务,在任务比较多的时候会导致 OOM(内存溢出)。
② Executors.newSingleThreadExecutor()
1> 创建一个单线程化的线程池,它只会用唯一的工作线程来执行任务,保证所有任务按照指定的顺序执行。
2> newSingleThreadExecutor将CorePoolSize和maximumPoolSize都设置为1,它使用的LinkedBlockingQueue。
适用:一个任务一个任务执行的场景。public static ExecutorService newSingleThreadExecutor() {return new FinalizableDelegatedExecutorService(new ThreadPoolExecutor(1, 1,0L, TimeUnit.MILLISECONDS,new LinkedBlockingQueue<Runnable>()));}
- 运行示意图(该图片来源:《Java 并发编程的艺术》):

1) 如果当前运行的线程数少于 corePoolSize,则创建一个新的线程执行任务;
2) 当前线程池中有一个运行的线程后,将任务加入 LinkedBlockingQueue
3) 线程执行完当前的任务后,会在循环中反复从LinkedBlockingQueue 中获取任务来执行; - 为什么不推荐使用?
无界队列LinkedBlockingQueue作为线程池的工作队列(队列的容量为Intger.MAX_VALUE)。SingleThreadExecutor 使用无界队列作为线程池的工作队列会对线程池带来的影响与FixedThreadPool相同。说简单点就是可能会导致 OOM,
单线程线程池newSingleThreadExecutor的应用场景
适用:一个任务一个任务执行的场景③ Executors.newCachedThreadPool()
1、创建一个可缓存线程池,如果线程池长度超过处理需求,可灵活回收线程池,若无可回收,则新建线程池。
2、将CorePoolSize设置为0,将maximumPoolSize设置为Interger.MAX_VALUE,即无界的,使用的SynchronousQueue,也就是说来了任务就创建线程运行,当线程空闲超过60秒,就销毁线程。
如果主线程提交任务的速度高于maximumPool中线程处理任务的速度时,CachedThreadPool 会不断创建新的线程。极端情况下,这样会导致耗尽 cpu 和内存资源。
适用:执行很多短期异步的小程序或者负载较轻的服务器。public static ExecutorService newCachedThreadPool() {return new ThreadPoolExecutor(0, Integer.MAX_VALUE,60L, TimeUnit.SECONDS,new SynchronousQueue<Runnable>());}

1> 首先执行 SynchronousQueue.offer(Runnable task) 提交任务到任务队列。如果当前 maximumPool中有闲线程正在执行SynchronousQueue.poll(keepAliveTime,TimeUnit.NANOSECONDS),那么主线程执行 offer 操作与空闲线程执行的 poll 操作配对成功,主线程把任务交给空闲线程执行,execute()方法执行完成,否则执行下面的步骤 2;
2> 当初始 maximumPool 为空,或者 maximumPool 中没有空闲线程时,将没有线程执行 SynchronousQueue.poll(keepAliveTime,TimeUnit.NANOSECONDS)。这种情况下,步骤 1 将失败,此时 CachedThreadPool 会创建新线程执行任务,execute 方法执行完成;- 为什么不推荐使用?
CachedThreadPool允许创建的线程数量为 Integer.MAX_VALUE,可能会创建大量线程,从而导致 OOM。
线程池 newCachedThreadPool线程池的缺点?配置参数?
如上④ Executors.ScheduledThreadPool()
- 主要用来在给定的延迟后运行任务,或者定期执行任务。
- 实际项目中基本不会被用到,因为有其他方案选择比如quartz。
备注: Quartz 是一个由 java 编写的任务调度库,由 OpenSymphony 组织开源出来。在实际项目开发中使用 Quartz 的还是居多,比较推荐使用 Quartz。因为 Quartz 理论上能够同时对上万个任务进行调度,拥有丰富的功能特性,包括任务调度、任务持久化、可集群化、插件等等。
3-生产使用
|设计线程池|
4. java线程你是怎么使用的?
4. 线程池用的多吗?让你设计一个线程池如何设计
5. 如何构造线程池,它的参数,饱和策略?
你如何设置合理参数
你再工作中单一的/固定的/可变的三种创建线程池的方法,你用的哪个多?超级大坑(sxt2)
1) 正确答案:一个都不用,我们生产上只使用自定义的。
2) Executors中JDK已经给你提供了,为什么不用?- 阿里巴巴开发手册-并发处理
【强制】线程资源必须通过线程池提供,不允许在应用中自行显式创建线程。
说明:使用线程池的好处是减少在创建和销毁线程上所消耗的时间以及系统资源的开销,解决资源不足的问题。如果不使用线程池,有可能造成系统创建大量同类线程而导致消耗完内存或者“过度切换”的问题。
【强制】线程池不允许使用 Executors去创建,而是通过 ThreadPoolExecutor的方式,这样的处理方式让写同学更加明确线程池运行规则,避资源耗尽风险。
说明: Executors返回的线程池对象返回的线程池对象的弊端 如下 : 1)FixedThreadPool和 SingleThread允许的请求队列长度为 Integer.MAX_VALUE,可 能会堆积大量的请求,从而导致 OOM。 2)CachedThreadPool和 ScheduledThreadPool允许的创建线程数量为Integer.MAX_VALUE,可能会创建大量的线程,从而导致 OOM。 - 无界队列,导致OOM
- 阿里巴巴开发手册-并发处理
工作中如何使用线程池的,是否子定义过线程池的使用?(sxt2)
public static void main(String[] args) {ExecutorService threadPool = new ThreadPoolExecutor(2, //corePoolSize5,//maximumPoolSize1L,//keepAliveTimeTimeUnit.SECONDS,new LinkedBlockingDeque<Runnable>(3),Executors.defaultThreadFactory(),new ThreadPoolExecutor.AbortPolicy());// 银行开启最大8个窗口try {for (int i = 0; i <10 ; i++) { //10个请求threadPool.execute(()->{ //LambdaSystem.out.println(Thread.currentThread().getName()+"\t 办理业务");});}}catch (Exception e){e.printStackTrace();}finally {threadPool.shutdown();}}
合理配置线程池你是如何考虑的(sxt2)
1) 决定核心线程数两个方面:CUP密集型、IO密集型//第一步:先获取运行服务器是几核的System.out.println(Runtime.getRuntime().availableProcessors());
2) CPU密集
- CPU密集指该任务需要大量的运算,而没有阻塞,CPU一直在全速运行
- CPU密集任务只有在真正的多核CPU上才能得到加速(通过线程)
- 而在单核CPU上(基本没了),无论你开几个模拟多线程该任务都不可能得到加速,因为CPU总的运算能力就这些
- CPU密集型任务配置金肯呢个少的线程数量:CPU核数+1个线程的线程池
3) IO密集型(2种,第1种常被讲,实际应用看效果)
- (1)由于IO密集型任务线程并不是一直在执行任务,则配置尽可能多的线程,如CPU核数*2
- (2)IO密集型,即该任务需要大量IO,即有大量的阻塞
- 在单线程上运行IO密集型的任务会导致浪费大量的CPU运算能力浪费在等待。
- 索引在IO密集型任务中使用多线程可以大大的加速程序运行,及时在单核CPU上,这种加速主要就是利用了被浪费带哦的阻塞时间。
- IO密集型时,大部分线程都阻塞,故需要多配置线程数:
- 公式参考:CPU核数/1-阻塞系数 阻塞系数在0.8-0.9之间 ,可取0.9
- 如8核CPU 8/1-0.9=80个线程数
corepoolsize和CPU有什么关系,为什么书上推荐是N+1,线程池适合计算密集型还是IO密集型
- 如果任务是IO密集型,一般线程数需要设置2倍CPU数以上,以此来尽量利用CPU资源。
- 如果任务是CPU密集型,一般线程数量只需要设置CPU数加1即可,更多的线程数也只能增加上下文切换,不能增加CPU利用率。
IO密集型的任务,因为IO操作并不占用CPU,可以加大线程池中的线程数目,让CPU处理更多的业务
CPU密集型任务,线程池中的线程数设置得少一些,减少线程上下文的切换。
https://www.cnblogs.com/weigy/p/12667425.html - N+1:N表示N个cpu处理器,当计算密集型的线程偶尔由于页缺失故障或者其他原因而暂停时,这个“额外”的线程也能确保CPU的时钟周期不会被浪费。-p141
任务性质不同的任务可以用不同规模的线程池分开处理。 - CPU 密集型任务配置尽可能少的线程数量,如配置Ncpu+1个线程的线程池。
- IO 密集型任务则由于需要等待 IO 操作,线程并不是一直在执行任务,则配置尽可能多的线程,如2xNcpu。
- 混合型的任务,如果可以拆分,则将其拆分成一个 CPU 密集型任务和一个 IO 密集型任务,只要这两个任务执行的时间相差不是太大,那么分解后执行的吞吐率要高于串行执行的吞吐率,如果这两个任务执行时间相差太大,则没必要进行分解。
- 可以通过Runtime.getRuntime().availableProcessors()方法获得当前设备的 CPU 个数。
https://juejin.im/post/5aeec0106fb9a07ab379574f
https://www.cnblogs.com/weigy/p/12667425.html
三、设计模式
1-生产者-消费者
//4.如何实现一个生产者和消费者模型。
//7.消费生产模型
3. 消费者重平衡(高可用性、伸缩性)
4. 那些情景下会造成消息漏消费?
5. 如何保证消息不被重复消费(幂等性)
8. 消费者与生产者的工作流程:
生产者-消费者模式实现批量执行SQL:
将原来直接INSERT数据到数据库的线程作为生产者线程,生产者线程只需将数据添加到任务队列,然后消费者线程负责将任务从任务队列中批量取出并批量执
行。- 示例:创建了5个消费者线程负责批量执行SQL,
5个消费者线程以 while(true){}循环方式批量地获取任务并批量地执行。
需要注意的是,从任务队列中获取批量任务的方法pollTasks()中,
首先是以阻塞方式获取任务队列中的一条任务,而后则是以非阻塞的方式获取任务;
之所以首先采用阻塞方式,是因为如果任务队列中没有任务,这样的方式能够避免无谓的循环。
//任务队列BlockingQueue<Task> bq=new LinkedBlockingQueue<>(2000);//启动5个消费者线程//执行批量任务void start() {ExecutorService es=xecutors.newFixedThreadPool(5);for (int i=0; i<5; i++) {es.execute(()->{try {while (true) {//获取批量任务List<Task> ts=pollTasks();//执行批量任务execTasks(ts);}}catch(Exception e){e.printStackTrace();}});}}//从任务队列中获取批量任务List<Task> pollTasks() throws InterruptedException{List<Task> ts=new LinkedList<>();//阻塞式获取一条任务Task t = bq.take();while(t != null){ts.add(t);//非阻塞式获取一条任务t = bq.poll();}return ts;}//批量执行任务execTasks(List<Task> ts) {//省略具体代码无数}
- 示例:创建了5个消费者线程负责批量执行SQL,
※ 4-mysql
资料:
为什么大家都说SELECT * 效率低 - 老刘的文章 - 知乎
https://zhuanlan.zhihu.com/p/149981715
资料:★
https://thinkwon.blog.csdn.net/article/details/104778621
https://thinkwon.blog.csdn.net/article/details/104778621?utm_medium=distribute.pc_relevant.none-task-blog-OPENSEARCH-7.control&depth_1-utm_source=distribute.pc_relevant.none-task-blog-OPENSEARCH-7.control
https://mp.weixin.qq.com/s/J3kCOJwyv2nzvI0_X0tlnAMysql逻辑架构:

- 最上层:
最上层的服务并不是MySQL所独有的,大多数基于网络的客户端/服务器的工具或者服务都有类似的架构。比如连接处理、授权认证、安全等等。 - 第二层:
第二层架构是MySQL比较有意思的部分。大多数MySQL的核心服务功能都在这一层,包括查询解析、分析、优化、缓存以及所有的内置函数(例如,日期、时间、数学和加密函数),所有跨存储引擎的功能都在这一层实现:存储过程、触发器、视图等。 - 第三层:
第三层包含了存储引擎。存储引擎负责MySQL中数据的存储和提取。和GNU/Linux下的各种文件系统一样,每个存储引擎都有它的优势和劣势。服务器通过API与存储引擎进行通信。这些接口屏蔽了不同存储引擎之间的差异,使得这些差异对上层的查询过程透明。存储引擎API包含几十个底层函数,用于执行诸如“开始一个事务”或者“根据主键提取一行记录”等操作。但存储引擎不会去解析SQL(1),不同存储引擎之间也不会相互通信,而只是简单地响应上层服务器的请求。
- 最上层:
1. 基础查询
1-写sql
- sql查询1?
- 课程名中包含‘计算机’的课程且成绩小于60分学生的学号、姓名
select number,name from
- 课程名中包含‘计算机’的课程且成绩小于60分学生的学号、姓名
sql查询2?
- 成绩表中按照科目取最大成绩
sql查询2?
- 主要考察成绩查询的sql,考察到的知识点主要包括 order by,sum,limit,group by ... having ...
2-关键字
常用的函数?
- 聚集函数:count,sum
- 合并字符串函数:concat(str1,str2,str3…)
https://www.cnblogs.com/progor/p/8832663.html
Mysql如何拼接字符串?
1)CONCAT(string1,string2,…)
说明 : string1,string2代表字符串,concat函数在连接字符串的时候,只要其中一个是NULL,那么将返回NULL
2)CONCAT_WS(separator,str1,str2,...)
说明 : string1,string2代表字符串,concat_ws 代表 concat with separator,第一个参数是其它参数的分隔符。分隔符的位置放在要连接的两个字符串之间。分隔符可以是一个字符串,也可以是其它参数。如果分隔符为 NULL,则结果为 NULL。函数会忽略任何分隔符参数后的 NULL 值。
3)group_concat函数
完整的语法如下:
group_concat([DISTINCT] 要连接的字段 [Order BY ASC/DESC 排序字段] [Separator '分隔符'])Mysql去重关键字?
- distinct
in如何实现的?
数据库中JOIN是怎么实现的?
mysql的几种连接?
左连接、内连接、右连接right join原理
左外连接和内连接的区别? |2
1)内连接,显示两个表中有联系的所有数据;
2)左链接,以左表为参照,显示所有数据;
3)右链接,以右表为参照显示数据;
https://www.cnblogs.com/cs071122/p/6753681.html
3-其他
为什么要使用数据库? [-]
- 数据保存在内存
优点: 存取速度快
缺点: 数据不能永久保存 - 数据保存在文件
优点: 数据永久保存
缺点:1)速度比内存操作慢,频繁的IO操作。2)查询数据不方便 - 数据保存在数据库
1)数据永久保存
2)使用SQL语句,查询方便效率高。
3)管理数据方便
- 数据保存在内存
为什么在技术选型时选择MySQL,而不是选择Oracle?
- mysql是免费的,oracle是收钱的。
- 阿里去IOE;√
- MySQL 允许数据丢包,而且可以大量部署在PC server上。符合互联网的特点。Oracle是严谨的企业数据库,讲究就是数据一致性,所以传统行业比较适合。
- 主要是免费,其次它是开源的,高级一点的你可以修改它的源码使其符合你的要求,方便扩展,代价是需要会修改的人来做这种工作,Linux也一样,免费开源,可以修改到适合公司的修改
数据库三范式?
- 第一范式:每个列都不可以再拆分。确保每列的原子性.
- 第二范式:在第一范式的基础上,非主键列完全依赖于主键,而不能是依赖于主键的一部分。
- 第三范式:在第二范式的基础上,非主键列只依赖于主键,不依赖于其他非主键。
- 在设计数据库结构的时候,要尽量遵守三范式,如果不遵守,必须有足够的理由。比如性能。事实上我们经常会为了性能而妥协数据库的设计。
mysql的三种驱动类型?
1)Class.forName("com.mysql.jdbc.Driver");//加载数据库驱动
2)new com.mysql.jdbc.Driver() ;//创建driver对象,加载数据库驱动
https://www.iteye.com/blog/862123204-qq-com-1566581写SQL的注意事项?
2. 存储引擎
mysql知道哪些存储引擎? |6
- 存储引擎(Storage engine)定义:
MySQL中的数据、索引以及其他对象是如何存储的,是一套文件系统的实现。
-- 数据库存储引擎:是数据库底层软件组织,数据库管理系统(DBMS)使用数据引擎进行创建、查询、更新和删除数据。不同的存储引擎提供不同的存储机制、索引技巧、锁定水平等功能,使用不同的存储引擎,还可以获得特定的功能。现在许多不同的数据库管理系统都支持多种不同的数据引擎。MySQL的核心就是插件式存储引擎。 - 常用的存储引擎:
① Innodb引擎:
-- MySQL默认事务型引擎。
在需要它不支持的特性时,才考虑使用其他存储引擎。
-- 提供了对数据库ACID事务的支持。并且还提供了行级锁和外键的约束。
设计的目标就是处理大数据容量的数据库系统。
-- MVCC 来支持高并发,并且实现了四个标准隔离级别(未提交读、提交读、可重复读、可串行化)。其默认级别时可重复读(REPEATABLE READ),在可重复读级别下,通过 MVCC + Next-Key Locking 防止幻读。
-- 主索引时聚簇索引,在索引中保存了数据,从而避免直接读取磁盘,因此对主键查询有很高的性能。
-- 内部做了很多优化,包括从磁盘读取数据时采用的可预测性读,能够自动在内存中创建hash索引以加速读操作的自适应哈希索引,以及能够加速插入操作的插入缓冲区等。
-- 支持真正的在线热备份。
MySQL 其他的存储引擎不支持在线热备份,要获取一致性视图需要停止对所有表的写入,而在读写混合的场景中,停止写入可能也意味着停止读取。
-- 提供了具有提交、回滚和崩溃恢复能力的事务安全。
-- 对比MyISAM引擎,写的处理效率会差一些,并且会占用更多的磁盘空间以保留数据和索引。
-- 特点:支持自动增长列,支持外键约束
② MyIASM引擎
-- mysql5.1及之前版本,为Mysql的默认引擎;
-- 不支持事务,也不支持行级锁和外键。
-- 优势:访问速度快,对事务完整性没有要求或者以select,insert为主的应用基本上可以用这个引擎来创建表;
-- 设计简单,数据以紧密格式存储。对于只读数据,或者表比较小、可以容忍修复操作,则依然可以使用它。
-- 提供了大量的特性,包括压缩表、空间数据索引等。
-- 不支持行级锁,只能对整张表加锁,读取时会对需要读到的所有表加共享锁,写入时则对表加排它锁。但在表有读取操作的同时,也可以往表中插入新的记录,这被称为并发插入(CONCURRENT INSERT)。
-- 可以手工或者自动执行检查和修复操作,但是和事务恢复以及崩溃恢复不同,可能导致一些数据丢失,而且修复操作是非常慢的。
-- 如果指定了 DELAY_KEY_WRITE 选项,在每次修改执行完成时,不会立即将修改的索引数据写入磁盘,而是会写到内存中的键缓冲区,只有在清理键缓冲区或者关闭表的时候才会将对应的索引块写入磁盘。这种方式可以极大的提升写入性能,但是在数据库或者主机崩溃时会造成索引损坏,需要执行修复操作。
-- 支持3种不同的存储格式,分别是:静态表;动态表;压缩表
③ MEMORY引擎:memory
-- 所有的数据都在内存中,数据的处理速度快,但是安全性不高。
-- Memory存储引擎使用存在于内存中的内容来创建表。每个memory表只实际对应一个磁盘文件,格式是.frm。memory类型的表访问非常的快,因为它的数据是放在内存中的,并且默认使用HASH索引,但是一旦服务关闭,表中的数据就会丢失掉。
-- MEMORY存储引擎的表可以选择使用BTREE索引或者HASH索引,两种不同类型的索引有其不同的使用范围
-- Memory类型的存储引擎主要用于哪些内容变化不频繁的代码表,或者作为统计操作的中间结果表,便于高效地对中间结果进行分析并得到最终的统计结果,。对存储引擎为memory的表进行更新操作要谨慎,因为数据并没有实际写入到磁盘中,所以一定要对下次重新启动服务后如何获得这些修改后的数据有所考虑。
④ MERGE存储引擎:merge
-- Merge存储引擎是一组MyISAM表的组合,这些MyISAM表必须结构完全相同,merge表本身并没有数据,对merge类型的表可以进行查询,更新,删除操作,这些操作实际上是对内部的MyISAM表进行的。
- 存储引擎(Storage engine)定义:
MySQL用的是什么引擎?
- MySQL常用的四种引擎:InnoDB、MyISAM、MEMORY、MERGE存储引擎
innodb和MyISAM区别? |2
- 区别:
- Innodb MyISAM 存储结构 所有的表都保存在同一个数据文件中(也可能是多个文件,或者是独立的表空间文件),InnoDB表的大小只受限于操作系统文件的大小,一般为2GB 每张表被存放在三个文件:.frm-表格定义、MYD(MYData)-数据文件、MYI(MYIndex)-索引文件 存储空间 InnoDB的表需要更多的内存和存储,它会在主内存中建立其专用的缓冲池用于高速缓冲数据和索引 MyISAM可被压缩,存储空间较小 可移植性、备份及恢复 免费的方案可以是拷贝数据文件、备份 binlog,或者用 mysqldump,在数据量达到几十G的时候就相对痛苦了 由于MyISAM的数据是以文件的形式存储,所以在跨平台的数据转移中会很方便。在备份和恢复时可单独针对某个表进行操作 文件格式 数据和索引是集中存储的,.ibd 数据和索引是分别存储的,数据.MYD,索引.MYI 记录存储顺序 按主键大小有序插入 按记录插入顺序保存 外键 支持 不支持 事务 支持 不支持 锁支持(锁是避免资源争用的一个机制,MySQL锁对用户几乎是透明的) 行级锁定、表级锁定,锁定力度小并发能力高 表级锁定 SELECT MyISAM更优 INSERT、UPDATE、DELETE InnoDB更优 select count(*) myisam更快,因为myisam内部维护了一个计数器,可以直接调取。 索引的实现方式 B+树索引,Innodb 是索引组织表 B+树索引,myisam 是堆表 哈希索引 支持 不支持 全文索引 不支持 支持 MyISAM索引与InnoDB索引的区别?[-]
- 1)InnoDB索引是聚簇索引,MyISAM索引是非聚簇索引。
2)InnoDB的主键索引的叶子节点存储着行数据,因此主键索引非常高效。
3)MyISAM索引的叶子节点存储的是行数据地址,需要再寻址一次才能得到数据。
4)InnoDB非主键索引的叶子节点存储的是主键和其他带索引的列数据,因此查询时做到覆盖索引会非常高效。
- 1)InnoDB索引是聚簇索引,MyISAM索引是非聚簇索引。
存储引擎选择?[-]
- 是否要支持事务,如果要请选择Innodb,如果不需要可以考虑 MyISAM。
- 如果表中绝大多数都是读查询(有人总结出读:写比率大于100:1),可以考虑MyISAM,如果既有读又有写,而且也挺频繁,请使用 InnoDB。
- 系统崩溃后,MyISAM 恢复起来更困难,能否接受。
- MySQL 5.5 开始 InnoDB 已经成为 MySQL 的默认引擎(之前是 MyISAM ),说明其优势是有目共睹的,如果你不知道用什么,那就用InnoDB吧,至少不会差。
- 如果没有特别的需求,使用默认的Innodb即可。
- MyISAM:以读写插入为主的应用程序,比如博客系统、新闻门户网站。
- Innodb:更新(删除)操作频率也高,或者要保证数据的完整性;并发量高,支持事务和外键。比如OA自动化办公系统。
感觉你的描述中innodb功能比myisam更强,你是这么觉得吗?
(两个特性和区别的角度阐述?)
6. 索引
1-树
- b、b+的插入删除过程:https://www.cnblogs.com/nullzx/p/8729425.html
页:
大小与操作系统有关,一般4k、8k,4的倍数,innodb默认16k(具体一页有多大数据跟操作系统有关);读取一页内的数据时候,实际上才发生了一次IO。二分查找的复杂度:O(log2n)
二叉树
- 二叉查找树的特点就是左子树的节点值比父亲节点小,而右子树的节点值比父亲节点大:
-- 在查找某个节点的时候,可以采取类似于二分查找的思想,快速找到某个节点。n个节点的二叉查找树,正常的情况下,查找的时间复杂度为 O(logn)。
-- 保证每次查找都可以这折半而减少IO次数;

- 极端情况:之所以说是正常情况下,是因为二叉查找树有可能出现一种极端的情况:
-- 此时的二叉查找树已经近似退化为一条链表,查找时间复杂度顿时变成了O(n)。由此必须防止这种情况发生,为了解决这个问题,于是引申出了平衡二叉树。
- 二叉查找树的特点就是左子树的节点值比父亲节点小,而右子树的节点值比父亲节点大:
平衡二叉树
- 1)概念
- 平衡二叉树是基于二分法的策略提高数据的查找速度的二叉树的数据结构。
-- 平衡二叉树是采用二分法思维,平衡二叉查找树除了具备二叉树的特点,最主要的特征是树的左右两个子树的层级最多相差1。在插入删除数据时通过左旋/右旋操作保持二叉树的平衡,不会出现左子树很高、右子树很矮的情况。
-- 平衡二叉查找树查询的性能接近于二分查找法,时间复杂度是 O(log2n)。 - 2)规则
平衡二叉树是采用二分法思维把数据按规则组装成一个树形结构的数据,用这个树形结构的数据减少无关数据的检索,大大的提升了数据检索的速度;平衡二叉树的数据结构组装过程有以下规则:
① 非叶子节点只能允许最多两个子节点存在。
② 每一个非叶子节点数据分布规则为左边的子节点小当前节点的值,右边的子节点大于当前节点的值(这里值是基于自己的算法规则而定的,比如hash值)。

- 平衡树的层级结构:
平衡二叉树的查询性能和树的层级(高度h)成反比,h值越小查询越快。为了保证树的结构左右两端数据大致平衡。降低二叉树的查询难度一般会采用一种算法机制实现节点数据结构的平衡,实现了这种算法的有比如Treap、红黑树。使用平衡二叉树能保证数据的左右两边的节点层级相差不会大于1,通过这样避免树形结构由于删除增加变成线性链表影响查询效率,保证数据平衡的情况下查找数据的速度近于二分法查找:

- 3)平衡二叉树特点:
① 非叶子节点最多拥有两个子节点。
② 非叶子节点值大于左边子节点、小于右边子节点。
③ 树的左右两边的层级数相差不会大于1。
④ 没有值相等重复的节点。 - 适用场景:
平衡二叉树,一般是用平衡因子差值决定并通过旋转来实现,左右子树树高差不超过1,那么和红黑树比较它是严格的平衡二叉树,平衡条件非常严格(树高差只有1),只要插入或删除不满足上面的条件就要通过旋转来保持平衡。由于旋转是非常耗费时间的。所以 AVL树适用于插入/删除次数比较少,但查找多的场景。 - 存在问题:
① 时间复杂度和树高相关。
树有多高就需要检索多少次,每个节点的读取,都对应一次磁盘 IO 操作。树的高度就等于每次查询数据时磁盘 IO 操作的次数。磁盘每次寻道时间为10ms,在表数据量大时,查询性能就会很差。(1百万的数据量,log2n约等于20次磁盘IO,时间20*10=0.2s)
② 平衡二叉树不支持范围查询快速查找,范围查询时需要从根节点多次遍历,查询效率不高。
红黑树
- 1)为什么有了平衡树还需要红黑树?
虽然平衡树解决了二叉查找树退化为近似链表的缺点,能够把查找时间控制在O(logn),不过却不是最佳的,因为平衡树要求每个节点的左子树和右子树的高度差至多等于1,这个要求实在是太严了,导致每次进行插入/删除节点的时候,几乎都会破坏平衡树的第二个规则,进而都需要通过左旋和右旋来进行调整,使之再次成为一颗符合要求的平衡树。 - 2)红黑树的特性
显然,如果在插入、删除很频繁的场景中,平衡树需要频繁调整,这会使平衡树的性能大打折扣,为了解决这个问题,于是有了红黑树,红黑树具有如下特点:
① 每个节点或者是黑色,或者是红色。
② 根节点是黑色。
③ 每个叶子节点(NIL)是黑色。 [注意:这里叶子节点,是指为空(NIL或NULL)的叶子节点]
④ 如果一个节点是红色的,则它的子节点必须是黑色的。
⑤ 从一个节点到该节点的子孙节点的所有路径上包含相同数目的黑节点。[这里指到叶子节点的路径]
-- 包含n个内部节点的红黑树的高度是 O(log(n))。如图:

- 3)红黑树的使用场景
-- java中使用到红黑树的有TreeSet和JDK1.8的HashMap。红黑树的插入和删除都要满足以上5个特性,操作非常复杂,为什么要使用红黑树?
原因:红黑树是一种平衡树,复杂的定义和规则都是为了保证树的平衡性。如果树不保证平衡性就是下图:很显然这就变成一个链表了。

-- 保证平衡性的最大的目的就是降低树的高度,因为树的查找性能取决于树的高度。所以树的高度越低搜索的效率越高! - 通过对从根节点到叶子节点路径上各个节点的颜色进行约束,确保没有一条路径会比其他路径长2倍,因而是近似平衡的。所以相对于严格要求平衡的AVL树来说,它的旋转保持平衡次数较少。适合,查找少,插入/删除次数多的场景。(现在部分场景使用跳表来替换红黑树,可搜索“为啥 redis 使用跳表(skiplist)而不是使用 red-black?”)
- 1)为什么有了平衡树还需要红黑树?
改造二叉树:为什么引入B树
- MySQL的数据是存储在磁盘文件中的,查询处理数据时,需要先把磁盘中的数据加载到内存中,磁盘IO操作非常耗时,所以优化的重点就是尽量减少磁盘IO操作。访问二叉树的每个节点就会发生一次IO,如果想要减少磁盘IO操作,就需要尽量降低树的高度。那如何降低树的高度呢?
- 假如key为bigint=8字节,每个节点有两个指针,每个指针为4个字节,一个节点占用的空间16个字节(8+4*2=16)。
- 因为在MySQL的InnoDB存储引擎一次IO会读取的一页(默认一页16K)的数据量,而二叉树一次IO有效数据量只有16字节,空间利用率极低。为了最大化利用一次IO空间,一个简单的想法是在每个节点存储多个元素,在每个节点尽可能多的存储数据。每个节点可以存储1000个索引(16k/16=1000),这样就将二叉树改造成了多叉树,通过增加树的叉树,将树从高瘦变为矮胖。构建1百万条数据,树的高度只需要2层就可以(1000*1000=1百万),也就是说只需要2次磁盘IO就可以查询到数据。磁盘IO次数变少了,查询数据的效率也就提高了。
- 这种数据结构我们称为B树,B树是一种多叉平衡查找树
B树(B-tree)
B树和B-tree,其实是同一种树。- B树的定义
B树(Balance Tree)也称B-树,它是一颗多路平衡查找树。我们描述一颗B树时需要指定它的阶数,阶数表示了一个结点最多有多少个孩子结点,一般用字母m表示阶数。当m取2时,就是我们常见的二叉搜索树。
一颗m阶的B树定义如下:
1)每个结点最多有m-1个关键字。
2)根结点最少可以只有1个关键字。
3)非根结点至少有Math.ceil(m/2)-1个关键字。
4)每个结点中的关键字都按照从小到大的顺序排列,每个关键字的左子树中的所有关键字都小于它,而右子树中的所有关键字都大于它。
5)所有叶子结点都位于同一层,或者说根结点到每个叶子结点的长度都相同。
-- 图示:一棵阶数为4的B树。
阶数m:在实际应用中的B树的阶数m都非常大(通常大于100),所以即使存储大量的数据,B树的高度仍然比较小。
节点:每个结点中存储了关键字(key)和关键字对应的数据(data),以及孩子结点的指针。将一个key和其对应的data称为一个记录。但为了方便描述,除非特别说明,后续文中就用key来代替(key,value)键值对这个整体。在数据库中我们将B树(和B+树)作为索引结构,可以加快查询速速,此时B树中的key就表示键,而data表示了这个键对应的条目在硬盘上的逻辑地址。

- 1)概念
-- 与平衡二叉树稍有不同的是,B树属于多叉树又名平衡多路查找树(查找路径不只两个),数据库索引技术里大量使用B树和B+树的数据结构。
-- 主要特点:
① B树的节点中存储着多个元素,每个内节点有多个分叉。
② 节点中的元素包含键值和数据,节点中的键值从大到小排列。也就是说,在所有的节点都储存数据。
③ 父节点当中的元素不会出现在子节点中。
④ 所有的叶子结点都位于同一层,叶节点具有相同的深度,叶节点之间没有指针连接。 - 2)规则
① 排序方式:所有节点关键字是按递增次序排列,并遵循左小右大原则。
② 子节点数:非叶子节点的子节点数>1,且<=M,且M>=2,空树除外(注:M阶代表一个树节点最多有多少个查找路径,M=M路,当M=2则是2叉树,M=3则是3叉)。
③ 关键字数:枝节点的关键字数量大于等于ceil(m/2)-1个且小于等于M-1个(注:ceil()是个朝正无穷方向取整的函数。如ceil(1.1)结果为2)。
④ 所有叶子节点均在同一层、叶子节点除了包含了关键字和关键字记录的指针外也有指向其子节点的指针只不过其指针地址都为null对应下图最后一层节点的空格子。 - 3)b树查询数据的流程:
-- 假如我们查询值等于10的数据。查询路径磁盘块1->磁盘块2->磁盘块5。
① 第一次磁盘IO:将磁盘块1加载到内存中,在内存中从头遍历比较,10<15,走左路,到磁盘寻址磁盘块2。
② 第二次磁盘IO:将磁盘块2加载到内存中,在内存中从头遍历比较,7<10,到磁盘中寻址定位到磁盘块5。
③ 第三次磁盘IO:将磁盘块5加载到内存中,在内存中从头遍历比较,10=10,找到10,取出data,如果data存储的行记录,取出data,查询结束。如果存储的是磁盘地址,还需要根据磁盘地址到磁盘中取出数据,查询终止。
-- 相比二叉平衡查找树:
在整个查找过程中,虽然数据的比较次数并没有明显减少,但是磁盘IO次数会大大减少。同时,由于我们的比较是在内存中进行的,比较的耗时可以忽略不计。B树的高度一般2至3层就能满足大部分的应用场景,所以使用B树构建索引可以很好的提升查询的效率。

-- B树索引查询过程:

- 4)️B树的插入节点流程
定义一个5阶树(平衡5路查找树),现在要把3、8、31、11、23、29、50、28这些数字构建出一个5阶树出来。遵循规则:
①节点拆分规则:当前是要组成一个5路查找树,那么此时m=5,关键字数必须<=5-1(这里关键字数>4就要进行节点拆分)。
②排序规则:满足节点本身比左边节点大,比右边节点小。

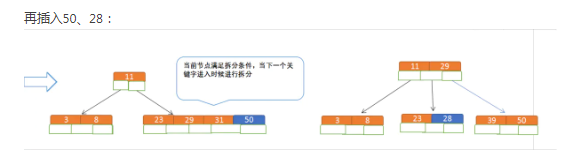
- 5)B树节点的删除
规则:
①节点合并规则:当前是要组成一个5路查找树,那么此时m=5,关键字数必须大于等于ceil(5/2)(这里关键字数<2就要进行节点合并)。
②满足节点本身比左边节点大,比右边节点小的排序规则。
③关键字数小于二时先从子节点取,子节点没有符合条件时就向父节点取,取中间值往父节点放。
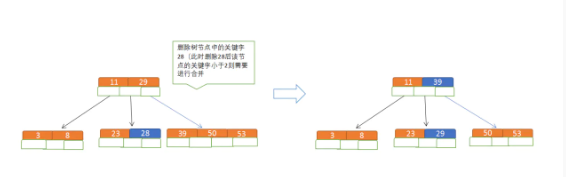
- 特点:
B树相对于平衡二叉树的不同是,每个节点包含的关键字增多了,特别是在B树应用到数据库中的时候,数据库充分利用了磁盘块的原理(磁盘数据存储是采用块的形式存储的,每个块的大小为4K,每次IO进行数据读取时,同一个磁盘块的数据可以一次性读取出来)把节点大小限制和充分使用在磁盘快大小范围;把树的节点关键字增多后树的层级比原来的二叉树少了,减少数据查找的次数和复杂度。 - b树的缺点:
1)B树不支持范围查询的快速查找,你想想这么一个情况如果我们想要查找10和35之间的数据,查找到15之后,需要回到根节点重新遍历查找,需要从根节点进行多次遍历,查询效率有待提高。
2)如果data存储的是行记录,行的大小随着列数的增多,所占空间会变大。这时,一个页中可存储的数据量就会变少,树相应就会变高,磁盘IO次数就会变大。
- B树的定义
B+树
- 1)概念
-- B+ Tree 是 B 树的一种变形、升级,它是基于 B Tree 和叶子节点顺序访问指针进行实现,通常用于数据库和操作系统的文件系统中。B+树更充分的利用了节点的空间,让查询速度更加稳定,其速度完全接近于二分法查找。
-- B+ 树有两种类型的节点:内部节点(也称索引节点)和叶子节点,内部节点就是非叶子节点,内部节点不存储数据,只存储索引,数据都存在叶子节点。
-- 内部节点中的 key 都按照从小到大的顺序排列,对于内部节点中的一个 key,左子树中的所有 key 都小于它,右子树中的 key 都大于等于它,叶子节点的记录也是按照从小到大排列的。
-- 每个叶子节点都存有相邻叶子节点的指针。
-- B+树和B树最主要的区别在于非叶子节点是否存储数据的问题:
B树:非叶子节点和叶子节点都会存储数据。
B+树:只有叶子节点才会存储数据,非叶子节点至存储键值。叶子节点之间使用双向指针连接,最底层的叶子节点形成了一个双向有序链表。

-- B+树的最底层叶子节点包含了所有的索引项。
B+树在查找数据的时候,由于数据都存放在最底层的叶子节点上,所以每次查找都需要检索到叶子节点才能查询到数据。
-- 所以在需要查询数据的情况下每次的磁盘的IO跟树高有直接的关系,但是从另一方面来说,由于数据都被放到了叶子节点,放索引的磁盘块锁存放的索引数量是会跟这增加的,相对于B树来说,B+树的树高理论上情况下是比B树要矮的。
-- 也存在索引覆盖查询的情况,
在索引中数据满足了当前查询语句所需要的全部数据,此时只需要找到索引即可立刻返回,不需要检索到最底层的叶子节点。 - 2)规则
① B+跟B树不同。
B+树的非叶子节点不保存关键字记录的指针,只进行数据索引,这样使得B+树每个非叶子节点所能保存的关键字大大增加。
② B+树叶子节点保存了父节点的所有关键字记录的指针,所有数据地址必须要到叶子节点才能获取到。所以每次数据查询的次数都一样。
③ B+树叶子节点的关键字从小到大有序排列,左边结尾数据都会保存右边节点开始数据的指针。
④ 非叶子节点的子节点数=关键字数(百度百科。根据各种资料,这里有两种算法的实现方式,另一种为非叶节点的关键字数=子节点数-1(维基百科),虽然数据排列结构不一样,但其原理还是一样的。Mysql 的 B+树是用第一种方式实现)。

- 3)特点
① B+树的层级更少:
相较于B树B+每个非叶子节点存储的关键字数更多,树的层级更少所以查询数据更快。
② B+树查询速度更稳定:
B+所有关键字数据地址都存在叶子节点上,所以每次查找的次数都相同所以查询速度要比B树更稳定。
③ B+树天然具备排序功能:
B+树所有的叶子节点数据构成了一个有序链表,在查询大小区间的数据时候更方便,数据紧密性很高,缓存的命中率也会比B树高。
④ B+树全节点遍历更快:
B+树遍历整棵树只需要遍历所有的叶子节点即可,而不需要像B树对每一层进行遍历,这有利于数据库做全表扫描。
⑤ B树相对于B+树的优点是,
如果经常访问的数据离根节点很近,而B树的非叶子节点本身存有关键字其数据的地址,所以这种数据检索的时候会要比B+树快。 - 等值查询:
假如我们查询值等于9的数据。查询路径磁盘块1->磁盘块2->磁盘块6。
① 第一次磁盘IO:将磁盘块1加载到内存中,在内存中从头遍历比较,9<15,走左路,到磁盘寻址磁盘块2。
② 第二次磁盘IO:将磁盘块2加载到内存中,在内存中从头遍历比较,7<9<12,到磁盘中寻址定位到磁盘块6。
③ 第三次磁盘IO:将磁盘块6加载到内存中,在内存中从头遍历比较,在第三个索引中找到9,取出data,如果data存储的行记录,取出data,查询结束。如果存储的是磁盘地址,还需要根据磁盘地址到磁盘中取出数据,查询终止。(这里需要区分的是在InnoDB中Data存储的为行数据,而MyIsam中存储的是磁盘地址。)

- 范围查询:
假如我们想要查找9和26之间的数据。查找路径是磁盘块1->磁盘块2->磁盘块6->磁盘块7。
① 首先查找值等于9的数据,将值等于9的数据缓存到结果集。这一步和前面等值查询流程一样,发生了三次磁盘IO。
② 查找到15之后,底层的叶子节点是一个有序列表,我们从磁盘块6,键值9开始向后遍历筛选所有符合筛选条件的数据。
③ 第四次磁盘IO:根据磁盘6后继指针到磁盘中寻址定位到磁盘块7,将磁盘7加载到内存中,在内存中从头遍历比较,9<25<26,9<26<=26,将data缓存到结果集。
④ 主键具备唯一性(后面不会有<=26的数据),不需再向后查找,查询终止。将结果集返回给用户。

- 可以看到B+树可以保证等值和范围查询的快速查找,MySQL的索引就采用了B+树的数据结构。
- 插入过程:5阶B树的插入
5阶B数的结点最少2个key,最多4个key。
a)空树中插入5

b)依次插入8,10,15

c)插入16

插入16后超过了关键字的个数限制,所以要进行分裂。在叶子结点分裂时,分裂出来的左结点2个记录,右边3个记录,中间key成为索引结点中的key,分裂后当前结点指向了父结点(根结点)。结果如下图所示。

当然我们还有另一种分裂方式,给左结点3个记录,右结点2个记录,此时索引结点中的key就变为15。
d)插入17

e)插入18,插入后如下图所示

当前结点的关键字个数大于5,进行分裂。分裂成两个结点,左结点2个记录,右结点3个记录,关键字16进位到父结点(索引类型)中,将当前结点的指针指向父结点。
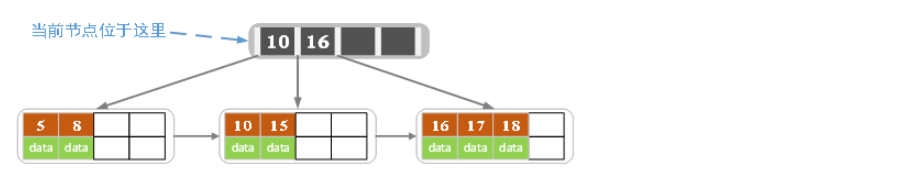
当前结点的关键字个数满足条件,插入结束。
f)插入若干数据后

g)在上图中插入7,结果如下图所示

当前结点的关键字个数超过4,需要分裂。左结点2个记录,右结点3个记录。分裂后关键字7进入到父结点中,将当前结点的指针指向父结点,结果如下图所示。

当前结点的关键字个数超过4,需要继续分裂。左结点2个关键字,右结点2个关键字,关键字16进入到父结点中,将当前结点指向父结点,结果如下图所示。

当前结点的关键字个数满足条件,插入结束。
- 1)概念
B*树
- 1)规则
B*树是B+树的变种,区别如下:
①首先是关键字个数限制问题,B+树初始化的关键字初始化个数是ceil(m/2),B*树的初始化个数为ceil(2/3*m)。
②B+树节点满时就会分裂,而B*树节点满时会检查兄弟节点是否满(因为每个节点都有指向兄弟的指针),如果兄弟节点未满则向兄弟节点转移关键字,如果兄弟节点已满,则从当前节点和兄弟节点各拿出1/3的数据创建一个新的节点出来。 - 2)特点
在B+树的基础上因其初始化的容量变大,使得节点空间使用率更高,而又存有兄弟节点的指针,可以向兄弟节点转移关键字的特性使得B*树额分解次数变得更少;
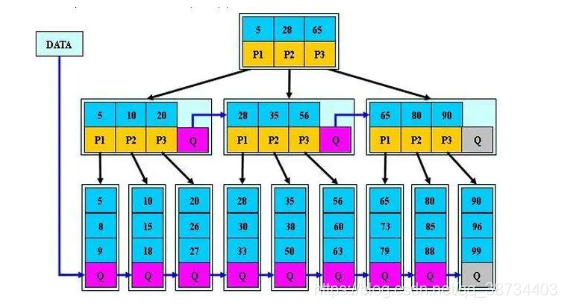
- 1)规则
总结
1)相同思想和策略
从平衡二叉树、B树、B+树、B*树总体来看它们的贯彻的思想是相同的,都是采用二分法和数据平衡策略来提升查找数据的速度。
2) 不同的方式的磁盘空间利用
不同点是它们一个一个在演变的过程中通过IO从磁盘读取数据的原理进行一步步的演变,每一次演变都是为了让节点的空间更合理的运用起来,从而使树的层级减少达到快速查找数据的目的。红黑树怎么实现的?
2-数据结构
b树定义?
- B树也称B-树,它是一颗多路平衡查找树。我们描述一颗B树时需要指定它的阶数,阶数表示了一个结点最多有多少个孩子结点,一般用字母m表示阶数。当m取2时,就是我们常见的二叉搜索树。
- 一颗m阶的B树定义如下:
1)每个结点最多有m-1个关键字。
2)根结点最少可以只有1个关键字。
3)非根结点至少有Math.ceil(m/2)-1个关键字。
4)每个结点中的关键字都按照从小到大的顺序排列,每个关键字的左子树中的所有关键字都小于它,而右子树中的所有关键字都大于它。
5)所有叶子结点都位于同一层,或者说根结点到每个叶子结点的长度都相同。
b+树怎么查找(如何插入的?)
- 1)查找
如上,1-树 - 2)插入
如上,1-树
- 1)查找
B+树数据太多了会怎么样
- InnoDB一棵B+树可以存放多少行数据?
约2千万。为什么是这么多呢?因为这是可以算出来的
https://www.cnblogs.com/wuneng/p/11455327.html
- InnoDB一棵B+树可以存放多少行数据?
B+树在磁盘存储?
B+树为什么节省内存?
b+树特点?
① B+树的层级更少:
相较于B树B+每个非叶子节点存储的关键字数更多,树的层级更少所以查询数据更快。
② B+树查询速度更稳定:
B+所有关键字数据地址都存在叶子节点上,所以每次查找的次数都相同所以查询速度要比B树更稳定。
③ B+树天然具备排序功能:
B+树所有的叶子节点数据构成了一个有序链表,在查询大小区间的数据时候更方便,数据紧密性很高,缓存的命中率也会比B树高。
④ B+树全节点遍历更快:
B+树遍历整棵树只需要遍历所有的叶子节点即可,而不需要像B树对每一层进行遍历,这有利于数据库做全表扫描。
⑤ B树相对于B+树的优点是,
如果经常访问的数据离根节点很近,而B树的非叶子节点本身存有关键字其数据的地址,所以这种数据检索的时候会要比B+树快。b+树为什么快/为什么b+树比b树查询效率高?
- B+树中,层数少,只在叶子节点存数据的特点就能极大的保证磁盘IO次数少,进而说,效率高~
b+优点?
- 使用B树的好处
B树可以在内部节点同时存储键和值,因此,把频繁访问的数据放在靠近根节点的地方将会大大提高热点数据的查询效率。这种特性使得B树在特定数据重复多次查询的场景中更加高效。 - 使用B+树的好处
由于B+树的内部节点只存放键,不存放值,因此,一次读取,可以在内存页中获取更多的键,有利于更快地缩小查找范围。 B+树的叶节点由一条链相连,因此,当需要进行一次全数据遍历的时候,B+树只需要使用O(logN)时间找到最小的一个节点,然后通过链进行O(N)的顺序遍历即可。而B树则需要对树的每一层进行遍历,这会需要更多的内存置换次数,因此也就需要花费更多的时间
- 使用B树的好处
b树和b+树区别? |3
- 1)结构上:
-- 在B树中,你可以将键和值存放在内部节点和叶子节点;但在B+树中,内部节点都是键,没有值,叶子节点同时存放键和值。
-- B+树的叶子节点有一条链相连,而B树的叶子节点各自独立 - 2)性能上:
① B+ 树的磁盘 IO 更低
B+ 树的内部节点并没有指向关键字具体信息的指针。因此其内部节点相对 B 树更小。如果把所有同一内部结点的关键字存放在同一盘块中,那么盘块所能容纳的关键字数量也越多。一次性读入内存中的需要查找的关键字也就越多。相对来说IO读写次数也就降低了。 - ② B+ 树的查询效率更加稳定
由于非叶子结点并不是最终指向文件内容的结点,而只是叶子结点中关键字的索引。所以任何关键字的查找必须走一条从根结点到叶子结点的路。所有关键字查询的路径长度相同,导致每一个数据的查询效率相当。 - ③ B+ 树元素遍历效率高
B 树在提高了磁盘IO性能的同时并没有解决元素遍历的效率低下的问题。正是为了解决这个问题,B+树应运而生。B+树只要遍历叶子节点就可以实现整棵树的遍历。而且在数据库中基于范围的查询是非常频繁的,而 B 树不支持这样的操作(或者说效率太低)。
- 1)结构上:
b+ 树的优势是什么?
(范围搜索方便,树矮胖,然后说如果一个叶子节点是一页16k,大概可以存储1000个索引,三层b+树就可以存储百万数据等等)- 为什么使用B+树作为索引(答了二叉树、B树、B+树的对比及其应用的优缺点)
mysql索引数据结构为什么是B+树?
为什么用B+树不用B或者二叉树或者哈希表?
- 核心原因是受限于磁盘i/o读取速度。
mysql一般用于存储比较大的数据,使用的都是机械硬盘。机械硬盘一次数据读取的时间是毫秒级的,和内存读取远远不在一个量级。
如果使用二叉树这种多层级结构,会导致磁盘的多次读取,每读取下一层数据,都是一次磁盘重新寻址。
所以B树,B+树 这种多叉树的优势有体现出来了。一个4层的B+树,基本能覆盖上亿数据的查找。
- 核心原因是受限于磁盘i/o读取速度。
b+树和二叉树的区别?
- 结构上:
-- 二叉树的每个结点至多有2个结点 或者只有1个左结点
-- B树 1。根结点至少有2个结点,2。除根结点和失败结点外的所有结点至少有m/2上取整个子结点,3。所有的失败结点均处在同一层上。左结点小于右结点。
-- B+树是B-树的变形,B+树的所有关键字都出现在叶结点上,上面各层结点中的关键码均是下一层相应结点中最大关键码的复写 - 为什么用b+不用二叉树
-- 查找效率(即比较次数):二叉树和b+树可能查询次数相同,但寻址次数不同;
-- 磁盘的寻址加载次数:
在把磁盘里的数据加载到内存中的时候,是以页为单位来加载的,而我们也知道,节点与节点之间的数据是不连续的,所以不同的节点,很有可能分布在不同的磁盘页中。由于 B 树的每一个节点,可以存放多个元素,所以磁盘寻址加载的次数会比较少
-- 在内存的运算速度是非常快的,至少比磁盘的寻址加载速度,快了几百倍,而我们进行数值比较的时候,是在内存中进行的,虽然 B 树的比较次数可能比二叉查找树多,但是磁盘操作次数少,所以总体来说,还是 B 树快的多,这也是为什么我们用使用 B 树来存储的原因。
-- Mysql如何衡量查询效率:主要是通过磁盘IO次数判断:
实际上磁盘的加载次数,基本上是和树的高度相关联的,高度越高,加载次数越多,越矮,加载次数越少。所以对于这种文件索引的存储,我们一般会选择矮胖的树形结构。例如有 1000 个元素,如果是二叉查找树的话,高度可能高达 10 层,而如果用 10 阶 B 树的话,只需要三四层即可。
- 结构上:
数据库为什么使用B+树而不是B树?[-]
- B树只适合随机检索,而B+树同时支持随机检索和顺序检索;
- B+树空间利用率更高,可减少I/O次数,磁盘读写代价更低。一般来说,索引本身也很大,不可能全部存储在内存中,因此索引往往以索引文件的形式存储的磁盘上。这样的话,索引查找过程中就要产生磁盘I/O消耗。B+树的内部结点并没有指向关键字具体信息的指针,只是作为索引使用,其内部结点比B树小,盘块能容纳的结点中关键字数量更多,一次性读入内存中可以查找的关键字也就越多,相对的,IO读写次数也就降低了。而IO读写次数是影响索引检索效率的最大因素;
- B+树的查询效率更加稳定。
B树搜索有可能会在非叶子结点结束,越靠近根节点的记录查找时间越短,只要找到关键字即可确定记录的存在,其性能等价于在关键字全集内做一次二分查找。而在B+树中,顺序检索比较明显,随机检索时,任何关键字的查找都必须走一条从根节点到叶节点的路,所有关键字的查找路径长度相同,导致每一个关键字的查询效率相当。 - B-树在提高了磁盘IO性能的同时并没有解决元素遍历的效率低下的问题。
B+树的叶子节点使用指针顺序连接在一起,只要遍历叶子节点就可以实现整棵树的遍历。而且在数据库中基于范围的查询是非常频繁的,而B树不支持这样的操作。 - 增删文件(节点)时,效率更高。
因为B+树的叶子节点包含所有关键字,并以有序的链表结构存储,这样可很好提高增删效率。
mysql索引,B+树,为什么不用红黑树? |2
- B + 树与红黑树的比较?[-]
红黑树等平衡树也可以用来实现索引,但是文件系统及数据库系统普遍采用 B+ Tree 作为索引结构,主要有以下两个原因:
(一)磁盘 IO 次数
B+ 树一个节点可以存储多个元素,相对于红黑树的树高更低,磁盘 IO 次数更少。
(二)磁盘预读特性
为了减少磁盘 I/O 操作,磁盘往往不是严格按需读取,而是每次都会预读。预读过程中,磁盘进行顺序读取,顺序读取不需要进行磁盘寻道。每次会读取页的整数倍。
操作系统一般将内存和磁盘分割成固定大小的块,每一块称为一页,内存与磁盘以页为单位交换数据。数据库系统将索引的一个节点的大小设置为页的大小,使得一次 I/O 就能完全载入一个节点。
- B + 树与红黑树的比较?[-]
Hash索引和B+树有什么区别或者说优劣呢?
- 首先要知道Hash索引和B+树索引的底层实现原理:
-- hash索引底层就是hash表,进行查找时,调用一次hash函数就可以获取到相应的键值,之后进行回表查询获得实际数据。B+树底层实现是多路平衡查找树。对于每一次的查询都是从根节点出发,查找到叶子节点方可以获得所查键值,然后根据查询判断是否需要回表查询数据。
-- Hash表,在Java中的HashMap,TreeMap就是Hash表结构,以键值对的方式存储数据。我们使用Hash表存储表数据Key可以存储索引列,Value可以存储行记录或者行磁盘地址。Hash表在等值查询时效率很高,时间复杂度为O(1);但是不支持范围快速查找,范围查找时还是只能通过扫描全表方式。
显然这种并不适合作为经常需要查找和范围查找的数据库索引使用。 - 那么可以看出他们有以下的不同:
① hash索引进行等值查询更快(一般情况下),但是却无法进行范围查询。
因为在hash索引中经过hash函数建立索引之后,索引的顺序与原顺序无法保持一致,不能支持范围查询。而B+树的的所有节点皆遵循(左节点小于父节点,右节点大于父节点,多叉树也类似),天然支持范围。
② hash索引不支持使用索引进行排序,原理同上。
hash索引不支持模糊查询以及多列索引的最左前缀匹配。原理也是因为hash函数的不可预测。AAAA和AAAAB的索引没有相关性。
③ hash索引任何时候都避免不了回表查询数据,而B+树在符合某些条件(聚簇索引,覆盖索引等)的时候可以只通过索引完成查询。
④ hash索引虽然在等值查询上较快,但是不稳定。性能不可预测,当某个键值存在大量重复的时候,发生hash碰撞,此时效率可能极差。而B+树的查询效率比较稳定,对于所有的查询都是从根节点到叶子节点,且树的高度较低。
-- 因此,在大多数情况下,直接选择B+树索引可以获得稳定且较好的查询速度。而不需要使用hash索引。
- 首先要知道Hash索引和B+树索引的底层实现原理:
b树和b+树适合什么查找 范围/顺序 ?
- b树:顺序,b+:范围/顺序
- B树非常适合读取和写入相对较大的数据块(如光盘)的存储系统。它通常用于数据库和文件系统。
索引是不是标准b+树,为什么 ?
mysql为什么用索引快
Innodb数据结构,B+树叶子节点存储的是什么数据?
- Mysql5.7之后默认的存储引擎是InnoDb,InnoDb的索引是聚簇索引
- B+树的叶子节点最终保存了数据的行信息,可以通过这个索引直接获取行数据,而不必再通过主键索引查找数据
3-索引
1-基础知识
- 如何看SQL的执行计划?
- explain关键字?
- 如果在select语句前放上关键词explain,mysql将解释它如何处理select,提供有关表如何联接和联接的次序。
- 表
| 关键字 | 功能 |
|---|---|
| select_type | 常用的有 SIMPLE 简单查询,UNION 联合查询,SUBQUERY 子查询等。 |
| table | 要查询的表 |
| possible_keys | 可选择的索引 |
| key | 实际使用的索引 |
| rows | 扫描的行数 |
| type | 索引查询类型,经常用到的索引查询类型:const:使用主键或者唯一索引进行查询的时候只有一行匹配 ref:使用非唯一索引 range:使用主键、单个字段的辅助索引、多个字段的辅助索引的最后一个字段进行范围查询 index:和all的区别是扫描的是索引树 all:扫描全表: |
explain的主要关键词
Explain关注哪里列?
数据库mysql索引? |6
- 索引概念
-- 官方介绍索引是帮助MySQL高效获取数据的数据结构。索引的功能相当于字典前面的拼音目录一样,能加快数据库的查询速度。(在数据之外,数据库系统还维护着满足特定查找算法的数据结构,这些数据结构以某种方式引用(指向)数据,这样就可以在这些数据结构上实现高级查找算法。这种数据结构,就是索引。)
-- 索引是一种特殊的文件(InnoDB数据表上的索引是表空间的一个组成部分),它们包含着对数据表里所有记录的引用指针。
-- 索引是一种数据结构。数据库索引,是数据库管理系统中一个排序的数据结构,以协助快速查询、更新数据库表中数据。索引的实现通常使用B树及其变种B+树。 - 存储:
一般来说索引本身也很大,不可能全部存储在内存中,因此索引往往是存储在磁盘上的文件中的(可能存储在单独的索引文件中,也可能和数据一起存储在数据文件中)。 - 分类:
我们通常所说的索引,包括聚集索引、覆盖索引、组合索引、前缀索引、唯一索引等,没有特别说明,默认都是使用B+树结构组织(多路搜索树,并不一定是二叉的)的索引。
- 索引概念
索引作用?
- 索引:对数据库中一列或多列的值进行排序的一种结构
- 作用:使用索引可以快速访问数据库表中特定信息(加速检索表中的数据)
- 索引的作用?
1)快速读取数据
2)保证数据记录的唯一性
3)实现表与表之间的参照完整性
4)在使用orderby ,group by子句进行检索时,索引可以减少排序和分组的时间。
数据库索引的优缺点?
索引的优势和劣势?
- 优势:
1)可以提高数据检索的效率,降低数据库的IO成本,类似于书的目录。
2)通过索引列对数据进行排序,降低数据排序的成本,降低了CPU的消耗。
-- 被索引的列会自动进行排序,包括【单列索引】和【组合索引】,只是组合索引的排序要复杂一些。
-- 如果按照索引列的顺序进行排序,对应order by语句来说,效率就会提高很多。 - 劣势:
1)创建索引和维护索引要耗费时间,并且随着数据量的增加所耗费的时间也会增加
2)索引会占据磁盘空间,数据表中的数据也会有最大上线设置的,如果我们有大量的索引,索引文件可能会比数据文件更快达到上线值
3)索引虽然会提高查询效率,但是会降低更新表的效率。比如每次对表进行增删改操作,MySQL不仅要保存数据,还有保存或者更新对应的索引文件。
- 优势:
索引的优点
- 大大减少了服务器需要扫描的数据行数。
- 帮助服务器避免进行排序和分组,以及避免创建临时表(B+Tree 索引是有序的,可以用于 ORDER BY 和 GROUP BY 操作。临时表主要是在排序和分组过程中创建,不需要排序和分组,也就不需要创建临时表)。
- 将随机 I/O 变为顺序 I/O(B+Tree索引是有序的,会将相邻的数据都存储在一起)。
索引优点
- 1)大大加快数据的检索速度
2)创建唯一性索引,保证数据库中的每一行数据的唯一性。
3)加速表与表之间的连接
4)在使用分组和排序进行检索时,可以显著的减少查询的时间。
- 1)大大加快数据的检索速度
Mysql索引的坏处是什么?
1)创建索引和维护索引要耗费时间,这种时间随着数据量的增加而增加。
2)索引需要占物理空间,除了数据表占数据空间之外,每一个索引还要占一定的物理空间,如果要建立聚簇索引,那么需要的空间就会更大。
3)当对表中的数据进行增加、删除和修改的时候,索引也要动态的维护,这样就降低了数据的维护速度。
https://blog.csdn.net/kennyrose/article/details/7532032InnoDB引擎的4大特性[-]
插入缓冲(insert buffer)
二次写(double write)
自适应哈希索引(ahi)
预读(read ahead)索引,为什么选择自增?
- InnoDB使用聚集索引,数据记录本身被存于主索引(一颗B+Tree)的叶子节点上。这就要求同一个叶子节点内(大小为一个内存页或磁盘页)的各条数据记录按主键顺序存放,因此每当有一条新的记录插入时,MySQL会根据其主键将其插入适当的节点和位置,如果页面达到装载因子(InnoDB默认为15/16),则开辟一个新的页(节点)。
- 如果表使用自增主键,那么每次插入新的记录,记录就会顺序添加到当前索引节点的后续位置,当一页写满,就会自动开辟一个新的页。
这样就会形成一个紧凑的索引结构,近似顺序填满。由于每次插入时也不需要移动已有数据,因此效率很高,也不会增加很多开销在维护索引上。 - 如果使用非自增主键(如果身份证号或学号等),由于每次插入主键的值近似于随机,因此每次新纪录都要被插到现有索引页得中间某个位置,此时MySQL不得不为了将新记录插到合适位置而移动数据,甚至目标页面可能已经被回写到磁盘上而从缓存中清掉,此时又要从磁盘上读回来,这增加了很多开销,同时频繁的移动、分页操作造成了大量的碎片,得到了不够紧凑的索引结构,后续不得不通过OPTIMIZETABLE来重建表并优化填充页面。
2-原理
索引模型是什么?
- 常见的索引模型有哈希表、有序数组、B+树。
https://www.cnblogs.com/fly-bryant/p/13195465.html
- 常见的索引模型有哈希表、有序数组、B+树。
索引的底层/mysql索引数据结构? |3
- 准确说,mysql默认的存储引擎 InnoDB使用的是B+树
索引原理?
- 索引用来快速地寻找那些具有特定值的记录。如果没有索引,一般来说执行查询时遍历整张表。
- 索引的原理很简单,就是把无序的数据变成有序的查询
1)把创建了索引的列的内容进行排序
2)对排序结果生成倒排表
3)在倒排表内容上拼上数据地址链
4)在查询的时候,先拿到倒排表内容,再取出数据地址链,从而拿到具体数据
https://www.cnblogs.com/klb561/p/10666296.html
https://blog.csdn.net/weixin_42181824/article/details/82261988
数据库的索引原理 ???
通常是「平衡树」(非二叉),也就是b tree及其变种B+树。
https://blog.csdn.net/kennyrose/article/details/7532032
https://blog.csdn.net/z_ryan/article/details/79685072 √
https://www.cnblogs.com/harderman-mapleleaves/p/4528212.html
https://www.cnblogs.com/makai/p/10861296.html
https://www.cnblogs.com/aspwebchh/p/6652855.htmlMySQL索引数据结构? |4
- (b树,hash)
-- 索引的数据结构和具体存储引擎的实现有关,在MySQL中使用较多的索引有Hash索引,B+树索引等;常用的InnoDB存储引擎的默认索引实现为:B+树索引。对于哈希索引来说,底层的数据结构就是哈希表,因此在绝大多数需求为单条记录查询的时候,可以选择哈希索引,查询性能最快;其余大部分场景,建议选择BTree索引。
-- 索引是在存储引擎层实现的,而不是在服务器层实现的,所以不同存储引擎具有不同的索引类型和实现。 - B+ Tree 索引
• 是大多数 MySQL 存储引擎的默认索引类型。
-- 因为不再需要进行全表扫描,只需要对树进行搜索即可,所以查找速度快很多。
-- 因为 B+ Tree 的有序性,所以除了用于查找,还可以用于排序和分组。
-- 可以指定多个列作为索引列,多个索引列共同组成键。
-- 适用于全键值、键值范围和键前缀查找,其中键前缀查找只适用于最左前缀查找。如果不是按照索引列的顺序进行查找,则无法使用索引。
• InnoDB 的 B+Tree 索引分为主索引和辅助索引。主索引的叶子节点 data 域记录着完整的数据记录,这种索引方式被称为聚簇索引。因为无法把数据行存放在两个不同的地方,所以一个表只能有一个聚簇索引。

• 辅助索引的叶子节点的data域记录着主键的值,因此在使用辅助索引进行查找时,需要先查找到主键值,然后再到主索引中进行查找,这个过程也被称作回表。
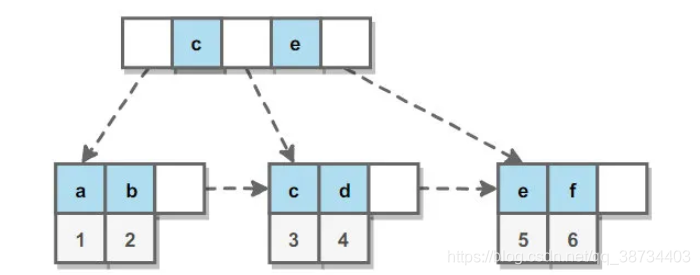
- 哈希索引
• 哈希索引能以 O(1) 时间进行查找,但是失去了有序性:
-- 无法用于排序与分组;
-- 只支持精确查找,无法用于部分查找和范围查找。
• InnoDB 存储引擎有一个特殊的功能叫“自适应哈希索引”,当某个索引值被使用的非常频繁时,会在 B+Tree 索引之上再创建一个哈希索引,这样就让 B+Tree 索引具有哈希索引的一些优点,比如快速的哈希查找。
• 类似于数据结构中简单实现的HASH表(散列表)一样,当我们在mysql中用哈希索引时,主要就是通过Hash算法(常见的Hash算法有直接定址法、平方取中法、折叠法、除数取余法、随机数法),将数据库字段数据转换成定长的Hash值,与这条数据的行指针一并存入Hash表的对应位置;如果发生Hash碰撞(两个不同关键字的Hash值相同),则在对应Hash键下以链表形式存储。当然这只是简略模拟图。
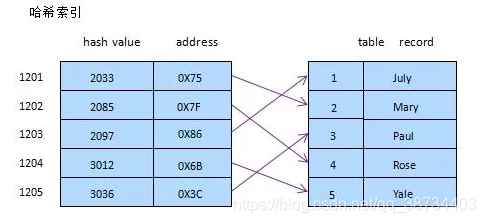
- (b树,hash)
索引算法有哪些? [-]
- 索引算法有 BTree算法和Hash算法
BTree算法
BTree是最常用的mysql数据库索引算法,也是mysql默认的算法。因为它不仅可以被用在=,>,>=,<,<=和between这些比较操作符上,而且还可以用于like操作符,只要它的查询条件是一个不以通配符开头的常量, 例如:-- 只要它的查询条件是一个不以通配符开头的常量select * from user where name like 'jack%';-- 如果一通配符开头,或者没有使用常量,则不会使用索引,例如:select * from user where name like '%jack';
Hash算法
Hash Hash索引只能用于对等比较,例如=,<=>(相当于=)操作符。由于是一次定位数据,不像BTree索引需要从根节点到枝节点,最后才能访问到页节点这样多次IO访问,所以检索效率远高于BTree索引。
??
索引是在存储引擎中实现的,而不是在服务器层中实现的。所以,每种存储引擎的索引都不一定完全相同,并不是所有的存储引擎都支持所有的索引类型。- 1 B-Tree索引
- 2 Hash索引
如果多个值有相同的hash code,索引把它们的行指针用链表保存到同一个hash表项中。 - 3 空间(R-Tree)索引
MyISAM支持空间索引,主要用于地理空间数据类型。 - 4 全文(Full-text)索引
全文索引是MyISAM的一个特殊索引类型,主要用于全文检索。 - 全文索引
-- MyISAM 存储引擎支持全文索引,用于查找文本中的关键词,而不是直接比较是否相等。
-- 查找条件使用 MATCH AGAINST,而不是普通的 WHERE。
-- 全文索引使用倒排索引实现,它记录着关键词到其所在文档的映射。
-- InnoDB 存储引擎在 MySQL 5.6.4 版本中也开始支持全文索引。 - 空间数据索引
-- MyISAM 存储引擎支持空间数据索引(R-Tree),可以用于地理数据存储。空间数据索引会从所有维度来索引数据,可以有效地使用任意维度来进行组合查询。
-- 必须使用 GIS 相关的函数来维护数据。
2-索引分类
MyISAM索引和InnoDB索引?
- https://mp.weixin.qq.com/s/faOaXRQM8p0kwseSHaMCbg
- Mysql的索引实现
介绍完了索引数据结构,那肯定是要带入到Mysql里面看看真实的使用场景的,所以这里分析Mysql的两种存储引擎的索引实现:MyISAM索引和InnoDB索引 - MyIsam索引
-- 以一个简单的user表为例。user表存在两个索引,id列为主键索引,age列为普通索引
-- MyISAM的数据文件和索引文件是分开存储的。MyISAM使用B+树构建索引树时,叶子节点中存储的键值为索引列的值,数据为索引所在行的磁盘地址。

1)主键索引
注:以下分析仅供参考,MyISAM在查询时,会将索引节点缓存在MySQL缓存中,而数据缓存依赖于操作系统自身的缓存,所以并不是每次都是走的磁盘,这里只是为了分析索引的使用过程。

◆ 表user的索引存储在索引文件user.MYI中,数据文件存储在数据文件 user.MYD中。
◆ 简单分析下查询时的磁盘IO情况:根据主键等值查询数据:
select * from user where id = 28;
① 先在主键树中从根节点开始检索,将根节点加载到内存,比较28<75,走左路。(1次磁盘IO)
② 将左子树节点加载到内存中,比较16<28<47,向下检索。(1次磁盘IO)
③ 检索到叶节点,将节点加载到内存中遍历,比较16<28,18<28,28=28。查找到值等于30的索引项。(1次磁盘IO)
④ 从索引项中获取磁盘地址,然后到数据文件user.MYD中获取对应整行记录。(1次磁盘IO)
⑤ 将记录返给客户端。
◆ 磁盘IO次数:3次索引检索+记录数据检索。

◆ 根据主键范围查询数据:
select * from user where id between 28 and 47;
① 先在主键树中从根节点开始检索,将根节点加载到内存,比较28<75,走左路。(1次磁盘IO)
② 将左子树节点加载到内存中,比较16<28<47,向下检索。(1次磁盘IO)
③ 检索到叶节点,将节点加载到内存中遍历比较16<28,18<28,28=28<47。查找到值等于28的索引项。
根据磁盘地址从数据文件中获取行记录缓存到结果集中。(1次磁盘IO)
我们的查询语句时范围查找,需要向后遍历底层叶子链表,直至到达最后一个不满足筛选条件。
④ 向后遍历底层叶子链表,将下一个节点加载到内存中,遍历比较,28<47=47,根据磁盘地址从数据文件中获取行记录缓存到结果集中。(1次磁盘IO)
⑤ 最后得到两条符合筛选条件,将查询结果集返给客户端。
◆ 磁盘IO次数:4次索引检索+记录数据检索。

2)辅助索引
◆ 在 MyISAM 中,辅助索引和主键索引的结构是一样的,没有任何区别,叶子节点的数据存储的都是行记录的磁盘地址。只是主键索引的键值是唯一的,而辅助索引的键值可以重复。
◆ 查询数据时,由于辅助索引的键值不唯一,可能存在多个拥有相同的记录,所以即使是等值查询,也需要按照范围查询的方式在辅助索引树中检索数据。 - InnoDB索引
1)主键索引(聚簇索引)
◆ 每个InnoDB表都有一个聚簇索引,聚簇索引使用B+树构建,叶子节点存储的数据是整行记录。一般情况下,聚簇索引等同于主键索引,当一个表没有创建主键索引时,InnoDB会自动创建一个ROWID字段来构建聚簇索引。InnoDB创建索引的具体规则如下:
① 在表上定义主键PRIMARY KEY,InnoDB将主键索引用作聚簇索引。
② 如果表没有定义主键,InnoDB会选择第一个不为NULL的唯一索引列用作聚簇索引。
③ 如果以上两个都没有,InnoDB 会使用一个6 字节长整型的隐式字段 ROWID字段构建聚簇索引。该ROWID字段会在插入新行时自动递增。
◆ 除聚簇索引之外的所有索引都称为辅助索引。在中InnoDB,辅助索引中的叶子节点存储的数据是该行的主键值都。在检索时,InnoDB使用此主键值在聚簇索引中搜索行记录。
◆ 这里以user_innodb为例,user_innodb的id列为主键,age列为普通索引。

◆ InnoDB的数据和索引存储在一个文件t_user_innodb.ibd中。InnoDB的数据组织方式,是聚簇索引。
◆ 主键索引的叶子节点会存储数据行,辅助索引只会存储主键值。
InnoDB主键索引,如图:

◆ 等值查询数据:
** select * from user_innodb where id = 28;**
① 先在主键树中从根节点开始检索,将根节点加载到内存,比较28<75,走左路。(1次磁盘IO)
② 将左子树节点加载到内存中,比较16<28<47,向下检索。(1次磁盘IO)
③ 检索到叶节点,将节点加载到内存中遍历,比较16<28,18<28,28=28。查找到值等于28的索引项,直接可以获取整行数据。将改记录返回给客户端。(1次磁盘IO)
◆ 磁盘IO数量:3次。

2)辅助索引
◆ 除聚簇索引之外的所有索引都称为辅助索引,InnoDB的辅助索引只会存储主键值而非磁盘地址。
◆ 以表user_innodb的age列为例,age索引的索引结果如下图(InnoDB辅助索引)。
◆ 底层叶子节点的按照(age,id)的顺序排序,先按照age列从小到大排序,age列相同时按照id列从小到大排序。
◆ 使用辅助索引需要检索两遍索引:首先检索辅助索引获得主键,然后使用主键到主索引中检索获得记录。

◆ 画图分析等值查询的情况:
** select * from t_user_innodb where age=19; **
◆ 根据在辅助索引树中获取的主键id,到主键索引树检索数据的过程称为回表查询。
◆ 磁盘IO数:辅助索引3次+获取记录回表3次

3)组合索引
◆ 还是以自己创建的一个表为例:表 abc_innodb,id为主键索引,创建了一个联合索引idx_abc(a,b,c)。

◆ 组合索引的数据结构:

◆ 组合索引的查询过程:
select * from abc_innodb where a = 13 and b = 16 and c = 4;

4)最左匹配原则:
◆ 最左前缀匹配原则和联合索引的索引存储结构和检索方式是有关系的。
◆ 在组合索引树中,最底层的叶子节点按照第一列a列从左到右递增排列,但是b列和c列是无序的,b列只有在a列值相等的情况下小范围内递增有序,而c列只能在a,b两列相等的情况下小范围内递增有序。
◆ 就像上面的查询,B+树会先比较a列来确定下一步应该搜索的方向,往左还是往右。如果a列相同再比较b列。但是如果查询条件没有a列,B+树就不知道第一步应该从哪个节点查起。
◆ 可以说创建的idx_abc(a,b,c)索引,相当于创建了(a)、(a,b)(a,b,c)三个索引。◆ 组合索引的最左前缀匹配原则:使用组合索引查询时,mysql会一直向右匹配直至遇到范围查询(>、<、between、like)就停止匹配。
5)覆盖索引
◆ 覆盖索引并不是说是索引结构,覆盖索引是一种很常用的优化手段。因为在使用辅助索引的时候,我们只可以拿到主键值,相当于获取数据还需要再根据主键查询主键索引再获取到数据。但是试想下这么一种情况,在上面abc_innodb表中的组合索引查询时,如果我只需要abc字段的,那是不是意味着我们查询到组合索引的叶子节点就可以直接返回了,而不需要回表。这种情况就是覆盖索引。
可以看一下执行计划:
- 总结:对sql语句里面的索引的优化
1)避免回表
◆ 在InnoDB的存储引擎中,使用辅助索引查询的时候,因为辅助索引叶子节点保存的数据不是当前记录的数据而是当前记录的主键索引,索引如果需要获取当前记录完整数据就必然需要根据主键值从主键索引继续查询。这个过程我们成位回表。想想回表必然是会消耗性能影响性能。那如何避免呢?
◆ 使用索引覆盖,举个例子:现有User表(id(PK),name(key),sex,address,hobby...)
◆ 如果在一个场景下,select id,name,sex from user where name ='zhangsan';这个语句在业务上频繁使用到,而user表的其他字段使用频率远低于它,在这种情况下,如果我们在建立 name 字段的索引的时候,不是使用单一索引,而是使用联合索引(name,sex)这样的话再执行这个查询语句是不是根据辅助索引查询到的结果就可以获取当前语句的完整数据。
◆ 这样就可以有效地避免了回表再获取sex的数据。
◆ 这里就是一个典型的使用覆盖索引的优化策略减少回表的情况。
2)联合索引的使用
◆ 联合索引,在建立索引的时候,尽量在多个单列索引上判断下是否可以使用联合索引。联合索引的使用不仅可以节省空间,还可以更容易的使用到索引覆盖。
◆ 试想一下,索引的字段越多,是不是更容易满足查询需要返回的数据呢。比如联合索引(a_b_c),是不是等于有了索引:a,a_b,a_b_c三个索引,这样是不是节省了空间,当然节省的空间并不是三倍于(a,a_b,a_b_c)三个索引,因为索引树的数据没变,但是索引data字段的数据确实真实的节省了。
◆ 联合索引的创建原则,在创建联合索引的时候因该把频繁使用的列、区分度高的列放在前面,频繁使用代表索引利用率高,区分度高代表筛选粒度大,这些都是在索引创建的需要考虑到的优化场景,也可以在常需要作为查询返回的字段上增加到联合索引中,如果在联合索引上增加一个字段而使用到了覆盖索引,那我建议这种情况下使用联合索引。
◆ 联合索引的使用
① 考虑当前是否已经存在多个可以合并的单列索引,如果有,那么将当前多个单列索引创建为一个联合索引。
② 当前索引存在频繁使用作为返回字段的列,这个时候就可以考虑当前列是否可以加入到当前已经存在索引上,使其查询语句可以使用到覆盖索引。
InnoDB和MyISAM
1)InnoDB- InnoDB也使用B+Tree作为索引结构
- InnoDB中,表数据文件本身就是按B+Tree组织的一个索引结构,这棵树的叶节点data域保存了完整的数据记录。这个索引的key是数据表的主键,因此InnoDB表数据文件本身就是主索引。
- InnoDB的辅助索引:InnoDB的所有辅助索引都引用主键作为data域。
- InnoDB 表是基于聚簇索引建立的。
2)MyISAM - MyISAM索引文件和数据文件是分离的,索引文件仅保存数据记录的地址
- MyISAM引擎使用B+Tree作为索引结构,叶节点的data域存放的是数据记录的地址。
- 在MyISAM中,主索引和辅助索引(Secondary key)在结构上没有任何区别,只是主索引要求key是唯一的,而辅助索引的key可以重复
- 同样也是一颗B+Tree,data域保存数据记录的地址。
- MyISM使用的是非聚簇索引,
3)问题:主键索引是聚集索引还是非聚集索引?
在Innodb下主键索引是聚集索引,在Myisam下主键索引是非聚集索引
https://www.cnblogs.com/jiawen010/p/11805241.html ★
主键索引与非主键索引有什么区别 ?
- 主键索引和非主键索引的区别是:非主键索引的叶子节点存放的是主键的值,而主键索引的叶子节点存放的是整行数据,其中非主键索引也被称为二级索引,而主键索引也被称为聚簇索引。
什么是聚簇索引?何时使用聚簇索引与非聚簇索引 [-]
- 聚簇索引:将数据存储与索引放到了一块,找到索引也就找到了数据
- 非聚簇索引:将数据存储于索引分开结构,索引结构的叶子节点指向了数据的对应行,myisam通过key_buffer把索引先缓存到内存中,当需要访问数据时(通过索引访问数据),在内存中直接搜索索引,然后通过索引找到磁盘相应数据,这也就是为什么索引不在key buffer命中时,速度慢的原因
- 澄清一个概念:innodb中,在聚簇索引之上创建的索引称之为辅助索引,辅助索引访问数据总是需要二次查找,非聚簇索引都是辅助索引,像复合索引、前缀索引、唯一索引,辅助索引叶子节点存储的不再是行的物理位置,而是主键值何时使用聚簇索引与非聚簇索引
聚簇索引和非聚簇索引?
高性能的索引策略
1 聚簇索引(Clustered Indexes)
https://www.cnblogs.com/whgk/p/6179612.html
https://www.cnblogs.com/likeju/p/5409102.html
2 聚簇索引和非聚簇索引- 聚簇索引并不是一种单独的索引类型,而是一种数据存储方式。都是b+树
- 场景
平时,我们使用Mysql数据库,会为主键建立一个B+树索引,当我们基于主键搜索的时候,比如“where id = 666”,这时候,就会用到索引,将文件最终的存放地址找出来并加载,而当我们使用没有建立索引的字段进行搜索的时候,比如“where parm = ’笑笑笑笑‘”,这样子的,就不会用到索引。 - 聚簇索引
就是为这个不是主键的字段建立了索引,并且B+树的叶子节点最终保存了数据的行信息,可以通过这个索引直接获取行数据,而不必再通过主键索引查找数据 - 非聚簇索引
就是当我们为不是主键的字段建立索引的时候,在这个索引B+树结构的叶子结点中,并不会想主键索引那样存储行数据,而是存储了主键的信息,找到主键之后,在通过主键索引查找出数据来 - Mysql5.7之后默认的存储引擎是InnoDb,InnoDb的索引是聚簇索引。
- 优缺点
聚簇索引的优点就是数据发生变化的时候,不用再去维护非主键索引了,因为存储的知识主键的信息,由于行数据和叶子节点存储在一起,主键和行数据是一起被载入内存的,找到叶子节点就可以立刻返回数据。https://blog.csdn.net/weixin_37641413/article/details/97823120 - 区别 在《数据库原理》一书中是这么解释聚簇索引和非聚簇索引的区别的:
聚簇索引的叶子节点就是数据节点,而非聚簇索引的叶子节点仍然是索引节点,只不过有指向对应数据块的指针。
https://www.cnblogs.com/jiawen010/p/11805241.html ★
https://www.cnblogs.com/qlqwjy/p/8592684.html
聚簇索引和非聚簇索引的区别?
答了聚簇索引:结构、建立(主键上建立、无主键则选择第一个唯一索引,若都没有主键和唯一索引则隐藏有一个字段实现聚簇索引)
非聚簇结构、非聚簇索引一定会回表查询吗?[-]
- 不一定,这涉及到查询语句所要求的字段是否全部命中了索引,如果全部命中了索引,那么就不必再进行回表查询。
- 举个简单的例子,假设我们在员工表的年龄上建立了索引,那么当进行select age from employee where age<20的查询时,在索引的叶子节点上,已经包含了age信息,不会再次进行回表查询。
B+树在满足聚簇索引和覆盖索引的时候不需要回表查询数据,[-]
-- 在B+树的索引中,叶子节点可能存储了当前的key值,也可能存储了当前的key值以及整行的数据,这就是聚簇索引和非聚簇索引。 在InnoDB中,只有主键索引是聚簇索引,如果没有主键,则挑选一个唯一键建立聚簇索引。如果没有唯一键,则隐式的生成一个键来建立聚簇索引。
-- 当查询使用聚簇索引时,在对应的叶子节点,可以获取到整行数据,因此不用再次进行回表查询。Mysql回表?回表问题?
- 回表概念:
-- 回表就是先通过数据库索引扫描出数据所在的行,再通过行主键id取出索引中未提供的数据,即基于非主键索引的查询需要多扫描一棵索引树。
-- 因此,可以通过索引先查询出id字段,再通过主键id字段,查询行中的字段数据,即通过再次查询提供MySQL查询速度。
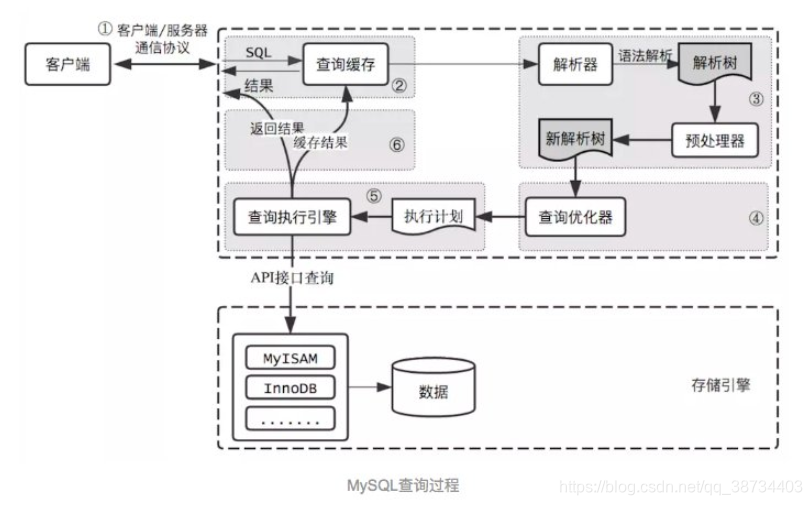
- 回表概念:
回表的过程,磁盘读几次,跟数据在内存中比哪个快?
- 非聚簇索引所要求的字段如果全部命中了索引,不需要会表
- 回表:再重新遍历索引树,双倍io
联合索引是什么?为什么需要注意联合索引中的顺序?[-]
- MySQL可以使用多个字段同时建立一个索引,叫做联合索引。在联合索引中,如果想要命中索引,需要按照建立索引时的字段顺序挨个使用,否则无法命中索引。
- 具体原因为:
- MySQL使用索引时需要索引有序,假设现在建立了"name,age,school"的联合索引,那么索引的排序为: 先按照name排序,如果name相同,则按照age排序,如果age的值也相等,则按照school进行排序。
- 当进行查询时,此时索引仅仅按照name严格有序,因此必须首先使用name字段进行等值查询,之后对于匹配到的列而言,其按照age字段严格有序,此时可以使用age字段用做索引查找,以此类推。因此在建立联合索引的时候应该注意索引列的顺序,一般情况下,将查询需求频繁或者字段选择性高的列放在前面。此外可以根据特例的查询或者表结构进行单独的调整。
Mysql对联合索引有优化么?会自动调整顺序么?哪个版本开始优化?
前缀索引 [-]
- 语法:index(field(10)),使用字段值的前10个字符建立索引,默认是使用字段的全部内容建立索引。
- 前提:前缀的标识度高。比如密码就适合建立前缀索引,因为密码几乎各不相同。
- 实操的难度:在于前缀截取的长度。
- 可以利用select count(*)/count(distinct left(password,prefixLen));,通过从调整prefixLen的值(从1自增)查看不同前缀长度的一个平均匹配度,接近1时就可以了(表示一个密码的前prefixLen个字符几乎能确定唯一一条记录)
什么是最左前缀原则?什么是最左匹配原则 [-]
- 顾名思义,就是最左优先,在创建多列索引时,要根据业务需求,where子句中使用最频繁的一列放在最左边。
- 最左前缀匹配原则,非常重要的原则,mysql会一直向右匹配直到遇到范围查询(>、<、between、like)就停止匹配,比如a = 1 and b = 2 and c > 3 and d = 4 如果建立(a,b,c,d)顺序的索引,d是用不到索引的,如果建立(a,b,d,c)的索引则都可以用到,a,b,d的顺序可以任意调整。
- =和in可以乱序,比如a = 1 and b = 2 and c = 3 建立(a,b,c)索引可以任意顺序,mysql的查询优化器会帮你优化成索引可以识别的形式
联合索引的最左匹配原则? |2
(答了:建立多列索引、多列索引顺序性和索引下推)从底层解释最左匹配原则?
mysql存储引擎索引优化?
- 避免回表
- 使用联合索引
mysql索引有哪些,都有什么特点?
- 数据库索引类型有哪些? |5
索引的分类/索引有哪几种类型?
- 主键索引: 数据列不允许重复,不允许为NULL,一个表只能有一个主键。
- 唯一索引: 数据列不允许重复,允许为NULL值,一个表允许多个列创建唯一索引。
• 可以通过 ALTER TABLE table_name ADD UNIQUE (column); 创建唯一索引
• 可以通过 ALTER TABLE table_name ADD UNIQUE (column1,column2); 创建唯一组合索引 - 普通索引: 基本的索引类型,没有唯一性的限制,允许为NULL值。
• 可以通过ALTER TABLE table_name ADD INDEX index_name (column);创建普通索引
• 可以通过ALTER TABLE table_name ADD INDEX index_name(column1, column2, column3);创建组合索引 - 全文索引: 是目前搜索引擎使用的一种关键技术。
• 可以通过ALTER TABLE table_name ADD FULLTEXT (column);创建全文索引
索引的分类?
mytable表:
CREATE TABLE mytable(ID INT NOT NULL,username VARCHAR(16) NOT NULL,city VARCHAR(50) NOT NULL,age INT NOT NULL);
1)单例索引
一个索引只包含单个列,但一个表中可以有多个单列索引。
① 普通索引
没有什么限制,允许在定义索引的列中插入重复值和空值。◆ 创建1:创建索引CREATE INDEX indexName ON mytable(username(length));-- 如果是CHAR,VARCHAR类型,length可以小于字段实际长度;如果是BLOB和TEXT类型,必须指定 length,下同。◆ 创建2:修改表结构ALTER mytable ADD INDEX [indexName] ON (username(length))◆ 创建3:创建表的时候直接指定CREATE TABLE mytable(:ID INT NOT NULL,username VARCHAR(16) NOT NULL,INDEX [indexName] (username(length)));◆ 删除索引的语法:DROP INDEX [indexName] ON mytable;
② 唯一索引
索引列中的值必须是唯一的,但是允许为空值。◆ 创建索引CREATE UNIQUE INDEX indexName ON mytable(username(length))◆ 修改表结构ALTER mytable ADD UNIQUE [indexName] ON (username(length))◆ 创建表的时候直接指定CREATE TABLE mytable(ID INT NOT NULL,username VARCHAR(16) NOT NULL,UNIQUE [indexName] (username(length)));
③ 主键索引
是一种特殊的唯一索引,不允许有空值。◆ 创建:一般是在建表的时候同时创建主键索引:CREATE TABLE mytable(ID INT NOT NULL,username VARCHAR(16) NOT NULL,PRIMARY KEY(ID));
当然也可以用 ALTER 命令。记住:一个表只能有一个主键。
2) 组合索引
在表中的多个字段组合上创建的索引,只有在查询条件中使用了这些字段的左边字段时,索引才会被使用,使用组合索引时遵循最左前缀集合。◆ 创建:将 name, city, age建到一个索引里:ALTER TABLE mytable ADD INDEX name_city_age (name(10),city,age);◆ 使用:“最左前缀”都会用到usernname,city,age | usernname,city | usernnameSELECT * FROM mytable WHREE username="admin" AND city="郑州"SELECT * FROM mytable WHREE username="admin"
3) 全文索引
在一堆文字中,通过其中的某个关键字等,就能找到该字段所属的记录行,比如有"你是个大煞笔,二货 ..." 通过大煞笔,可能就可以找到该条记录。
只有在MyISAM引擎上才能使用,只能在CHAR,VARCHAR,TEXT类型字段上使用全文索引。
FULLTEXT- 4) 空间索引
空间索引是对空间数据类型的字段建立的索引,MySQL中的空间数据类型有四种,GEOMETRY、POINT、LINESTRING、POLYGON。
在创建空间索引时,使用SPATIAL关键字。
要求,引擎为MyISAM,创建空间索引的列,必须将其声明为NOT NULL。
SPATIAL
mysql索引类型?
单列索引(普通索引,唯一索引,主键索引)、组合索引、全文索引、空间索引索引之间的区别
1) 单列索引:一个索引只包含单个列,但一个表中可以有多个单列索引。- 普通索引:没有什么限制,允许在定义索引的列中插入重复值和空值;
- 唯一索引:索引列中的值必须是唯一的,允许为null
- 主键索引:一种特殊的唯一索引,不允许有null。
2)组合索引
在表中的多个字段组合上创建的索引,只有在查询条件中使用了这些字段的左边字段时,索引才会被使用,使用组合索引时遵循最左前缀集合;
3)全文索引:只有在MyISAM引擎上才能使用,只能在CHAR,VARCHAR,TEXT类型字段上使用全文索引,在一堆文字中,通过其中的某个关键字等,就能找到该字段所属的记录行;
4)空间索引:空间索引是对空间数据类型的字段建立的索引,MySQL中的空间数据类型有四种,GEOMETRY、POINT、LINESTRING、POLYGON。
在创建空间索引时,使用SPATIAL关键字。
要求,引擎为MyISAM,创建空间索引的列,必须将其声明为NOT NULL。
3-创建索引|使用
怎么建立索引1?
select * from t where b=1;
Select * from t where a=1 and b=1;
先说需要建两个索引,后来反应过来了,建一个联合索引。怎么建索引2?
select * from a=1 and b>2 or c in(1,2,3)场景题:音乐界面和评论,如何建立表和索引
Select * from t where c=1;
C是非主键索引,问几次磁盘io,b+索引树高度3。mysql给性别建立索引 和 直接查询 有区别吗?
- 重复性较强的字段,不适合添加索引,列的离散度太低,索引查询效率很低的
- 建了索引数据库也不一定会用到,只会白白增加索引维护的额外开销,因为索引也是需要存储的,所以插入和更新的写入操作,同时需要插入和更新你这个字段的索引的.
所以说,唯一性太差的字段不需要创建索引,即便用于where条件.
https://www.cnblogs.com/mkl34367803/p/13096564.html
只有一个字段,字段值都是汉字,建立索引后是如何排序的 ?
索引:A>0 B =3 C=1 会不会走索引?
一列只有8中情况的数据,另一列不确认,哪一列适合建索引?
索引语句
CREATE TABLE table_name[col_name data type][unique|fulltext][index|key][index_name](col_name[length])[asc|desc]
- col_name:需要创建索引的字段列
- unique|fulltext:可选参数,唯一索引|全文索引
- index和key:两者作用相同,用来指定创建索引
- index_name:指定索引的名称,可选参数,默认col_name为索引值
- length:可选参数,索引的长度,只有字符串类型的字段才能指定索引长度
- asc或desc指定升序或降序的索引值存储
https://www.cnblogs.com/luyucheng/p/6289714.html
怎么建索引? |2
https://www.cnblogs.com/whgk/p/6179612.html
创建索引的三种方式,删除索引? [-]第一种方式:在执行CREATE TABLE时创建索引
CREATE TABLE user_index2 (id INT auto_increment PRIMARY KEY,first_name VARCHAR (16),last_name VARCHAR (16),id_card VARCHAR (18),information text,KEY name (first_name, last_name),FULLTEXT KEY (information),UNIQUE KEY (id_card));
第二种方式:使用ALTER TABLE命令去增加索引
ALTER TABLE table_name ADD INDEX index_name (column_list);
-- ALTER TABLE用来创建普通索引、UNIQUE索引或PRIMARY KEY索引。
-- 其中,table_name是要增加索引的表名,column_list指出对哪些列进行索引,多列时各列之间用逗号分隔。
-- 索引名index_name可自己命名,缺省时,MySQL将根据第一个索引列赋一个名称。另外,ALTER TABLE允许在单个语句中更改多个表,因此可以在同时创建多个索引。- 第三种方式:使用CREATE INDEX命令创建
CREATE INDEX index_name ON table_name (column_list);
-- CREATE INDEX可对表增加普通索引或UNIQUE索引。(但是,不能创建PRIMARY KEY索引)
- 删除索引
-- 根据索引名删除普通索引、唯一索引、全文索引:alter table 表名 drop KEY 索引名
alter table user_index drop KEY name;alter table user_index drop KEY id_card;alter table user_index drop KEY information;
-- 删除主键索引:alter table 表名 drop primary key(因为主键只有一个)。这里值得注意的是,如果主键自增长,那么不能直接执行此操作(自增长依赖于主键索引):
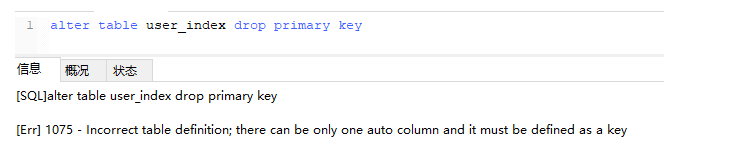
-- 需要取消自增长再行删除:
-- 但通常不会删除主键,因为设计主键一定与业务逻辑无关。alter table user_index-- 重新定义字段MODIFY id int,drop PRIMARY KEY
百万级别或以上的数据如何删除 [-]
- 关于索引:由于索引需要额外的维护成本,因为索引文件是单独存在的文件,所以当我们对数据的增加,修改,删除,都会产生额外的对索引文件的操作,这些操作需要消耗额外的IO,会降低增/改/删的执行效率。所以,在我们删除数据库百万级别数据的时候,查询MySQL官方手册得知删除数据的速度和创建的索引数量是成正比的。
1) 所以我们想要删除百万数据的时候可以先删除索引(此时大概耗时三分多钟)
2) 然后删除其中无用数据(此过程需要不到两分钟)
3) 删除完成后重新创建索引(此时数据较少了)创建索引也非常快,约十分钟左右。
4) 与之前的直接删除绝对是要快速很多,更别说万一删除中断,一切删除会回滚。那更是坑了。
- 关于索引:由于索引需要额外的维护成本,因为索引文件是单独存在的文件,所以当我们对数据的增加,修改,删除,都会产生额外的对索引文件的操作,这些操作需要消耗额外的IO,会降低增/改/删的执行效率。所以,在我们删除数据库百万级别数据的时候,查询MySQL官方手册得知删除数据的速度和创建的索引数量是成正比的。
索引使用场景(重点)[-]
- 1)where
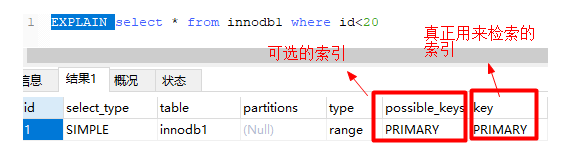
上图中,根据id查询记录,因为id字段仅建立了主键索引,因此此SQL执行可选的索引只有主键索引,如果有多个,最终会选一个较优的作为检索的依据。
-- 增加一个没有建立索引的字段-- (alter table 表名 add index(字段名))alter table innodb1 add sex char(1);-- 按sex检索时可选的索引为nullEXPLAIN SELECT * from innodb1 where sex='男';
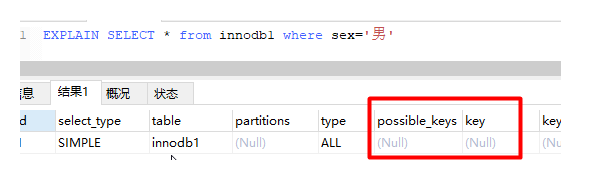
- 2) order by
-- 当我们使用order by将查询结果按照某个字段排序时,如果该字段没有建立索引,那么执行计划会将查询出的所有数据使用外部排序(将数据从硬盘分批读取到内存使用内部排序,最后合并排序结果),这个操作是很影响性能的,因为需要将查询涉及到的所有数据从磁盘中读到内存(如果单条数据过大或者数据量过多都会降低效率),更无论读到内存之后的排序了。
-- 但是如果我们对该字段建立索引alter table 表名 add index(字段名),那么由于索引本身是有序的,因此直接按照索引的顺序和映射关系逐条取出数据即可。而且如果分页的,那么只用取出索引表某个范围内的索引对应的数据,而不用像上述那取出所有数据进行排序再返回某个范围内的数据。(从磁盘取数据是最影响性能的) - 3) join
对join语句匹配关系(on)涉及的字段建立索引能够提高效率 - 4) 索引覆盖
如果要查询的字段都建立过索引,那么引擎会直接在索引表中查询而不会访问原始数据(否则只要有一个字段没有建立索引就会做全表扫描),这叫索引覆盖。因此我们需要尽可能的在select后只写必要的查询字段,以增加索引覆盖的几率。 - 这里值得注意的是不要想着为每个字段建立索引,因为优先使用索引的优势就在于其体积小。
- 1)where
创建索引的原则(重中之重)
- 索引虽好,但也不是无限制的使用,最好符合一下几个原则
1) 最左前缀匹配原则,组合索引非常重要的原则,mysql会一直向右匹配直到遇到范围查询(>、<、between、like)就停止匹配,比如a = 1 and b = 2 and c > 3 and d = 4 如果建立(a,b,c,d)顺序的索引,d是用不到索引的,如果建立(a,b,d,c)的索引则都可以用到,a,b,d的顺序可以任意调整。
2)较频繁作为查询条件的字段才去创建索引
3)更新频繁字段不适合创建索引
4)若是不能有效区分数据的列不适合做索引列(如性别,男女未知,最多也就三种,区分度实在太低)
5)尽量的扩展索引,不要新建索引。比如表中已经有a的索引,现在要加(a,b)的索引,那么只需要修改原来的索引即可。
6)定义有外键的数据列一定要建立索引。
7)对于那些查询中很少涉及的列,重复值比较多的列不要建立索引。
8)对于定义为text、image和bit的数据类型的列不要建立索引。
- 索引虽好,但也不是无限制的使用,最好符合一下几个原则
建索引时需要注意什么? [-]
- 非空字段:应该指定列为NOT NULL,除非你想存储NULL。在mysql中,含有空值的列很难进行查询优化,因为它们使得索引、索引的统计信息以及比较运算更加复杂。你应该用0、一个特殊的值或者一个空串代替空值;
- 取值离散大的字段:(变量各个取值之间的差异程度)的列放到联合索引的前面,可以通过count()函数查看字段的差异值,返回值越大说明字段的唯一值越多字段的离散程度高;
- 索引字段越小越好:数据库的数据存储以页为单位一页存储的数据越多一次IO操作获取的数据越大效率越高。
MySQL建立索引有什么规则 ?
索引的使用注意事项
1)哪些情况下不需要使用索引
2)索引不可用的情况
3)索引不会被使用的几种情况
https://www.cnblogs.com/xyhero/p/b0ad525c6a6a5ed2bd7f40918c5dbd98.html使用原则:
1、对经常更新的表就避免对其进行过多的索引,对经常用于查询的字段应该创建索引,
2、数据量小的表最好不要使用索引,因为由于数据较少,可能查询全部数据花费的时间比遍历索引的时间还要短,索引就可能不会产生优化效果。
3、在一同值少的列上(字段上)不要建立索引,比如在学生表的"性别"字段上只有男,女两个不同值。相反的,在一个字段上不同值较多可是建立索引索引的使用条件? [-]
- 对于非常小的表、大部分情况下简单的全表扫描比建立索引更高效;
- 对于中到大型的表,索引就非常有效;
- 但是对于特大型的表,建立和维护索引的代价将会随之增长。这种情况下,需要用到一种技术可以直接区分出需要查询的一组数据,而不是一条记录一条记录地匹配,例如可以使用分区技术。
为什么对于非常小的表,大部分情况下简单的全表扫描比建立索引更高效?
- 如果一个表比较小,那么显然直接遍历表比走索引要快(因为需要回表)。
- 注:首先,要注意这个答案隐含的条件是查询的数据不是索引的构成部分,否也不需要回表操作。其次,查询条件也不是主键,否则可以直接从聚簇索引中拿到数据。
索引设计的原则?[-]
适合索引的列是出现在where子句中的列,或者连接子句中指定的列
基数较小的类,索引效果较差,没有必要在此列建立索引
使用短索引,如果对长字符串列进行索引,应该指定一个前缀长度,这样能够节省大量索引空间
不要过度索引。索引需要额外的磁盘空间,并降低写操作的性能。在修改表内容的时候,索引会进行更新甚至重构,索引列越多,这个时间就会越长。所以只保持需要的索引有利于查询即可。哪些建立索引比较适合(比如性别建立索引合适吗)
索引是建立在数据库表中的某些列的上面。在创建索引的时候,应该考虑在哪些列上可以创建索引,在哪些列上不能创建索引。一般来说,应该在这些列上创建索引:在经常需要搜索的列上,可以加快搜索的速度;在作为主键的列上,强制该列的唯一性和组织表中数据的排列结构;在经常用在连接的列上,这些列主要是一些外键,可以加快连接的速度;在经常需要根据范围进行搜索的列上创建索引,因为索引已经排序,其指定的范围是连续的;在经常需要排序的列上创建索引,因为索引已经排序,这样查询可以利用索引的排序,加快排序查询时间;在经常使用在WHERE子句中的列上面创建索引,加快条件的判断速度。
https://blog.csdn.net/kennyrose/article/details/7532032
4-优化
使用索引查询一定能提高查询的性能吗?为什么 [-]
- 通常,通过索引查询数据比全表扫描要快。但是我们也必须注意到它的代价。
• 索引需要空间来存储,也需要定期维护, 每当有记录在表中增减或索引列被修改时,索引本身也会被修改。 这意味着每条记录的INSERT,DELETE,UPDATE将为此多付出4,5 次的磁盘I/O。 因为索引需要额外的存储空间和处理,那些不必要的索引反而会使查询反应时间变慢。使用索引查询不一定能提高查询性能,索引范围查询(INDEX RANGE SCAN)适用于两种情况:
• 基于一个范围的检索,一般查询返回结果集小于表中记录数的30%
• 基于非唯一性索引的检索
- 通常,通过索引查询数据比全表扫描要快。但是我们也必须注意到它的代价。
优化数据库,创建索引?
- 目的:数据库索引其实就是为了使查询数据效率快。
SELECT * FROM award WHERE nickname = 'css'
https://www.cnblogs.com/chenshishuo/p/5030029.html
- 目的:数据库索引其实就是为了使查询数据效率快。
索引失效/什么时候数据库索引失效?|2
3. 事务
数据库并发问题及其对应解决? |2
innoDB事务?
- 解释一下事务?
数据库事务的特性? |3
1)事务
事务(Transaction)是并发控制的基本单位。
所谓事务,它是一个操作序列,这些操作要么都执行,要么都不执行,它是一个不可分割的工作单位。例如,银行转帐工作:从一个帐号扣款并使另一个帐号增款,这两个操作要么都执行,要么都不执行。
2)四大特性- 原子性:原子性是指事务包含的所有操作要么全部成功,要么全部失败回滚。
- 一致性:一个事务执行之前和执行之后都必须处于一致性状态。
AB用户总共5000,如何转账还是5000. - 隔离性:多个并发事务之间要相互隔离。
- 持久性:一个事务一旦被提交了,那么对数据库中的数据的改变就是永久性的,即便是在数据库系统遇到故障的情况下也不会丢失提交事务的操作。
数据的ACID
- ACID,是指在可靠数据库管理系统(DBMS)中,事务(transaction)所应该具有的四个特性:原子性(Atomicity)、一致性(Consistency)、隔离性(Isolation)、持久性(Durability)
- ACID 之间的关系
事务的 ACID 特性概念很简单,但不好理解,主要是因为这几个特性不是一种平级关系:
◆ 只有满足一致性,事务的结果才是正确的。
◆ 在无并发的情况下,事务串行执行,隔离性一定能够满足。此时只要能满足原子性,就一定能满足一致性。在并发的情况下,多个事务并行执行,事务不仅要满足原子性,还需要满足隔离性,才能满足一致性。
◆ 事务满足持久化是为了能应对数据库崩溃的情况。
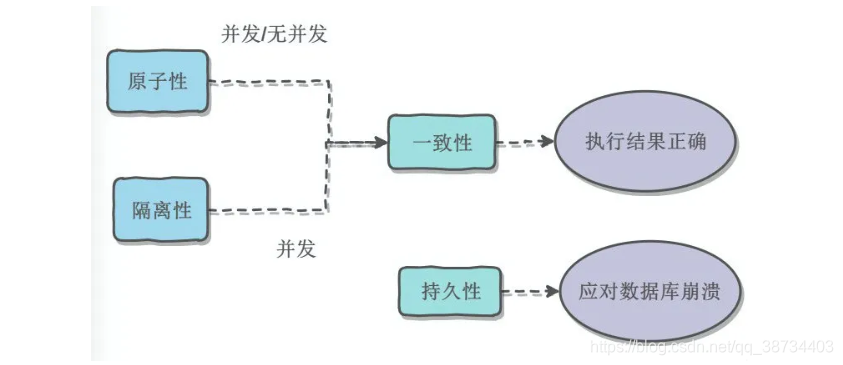
开启事务办法
基本操作
1、connection.setAutCommit(false):关闭事务自动提交(开启事务)
2、connection.commit():手动提交事务
3、connection.rollback():事务回滚
补:撤销事务中的部分操作
SavePoint sp = connection.setSavepoint();:设置事务回滚点
connection.rollback(sp);
connection.commit();:最后不要忘了提交事务,否则前面需要提交保存的操作也将不会保存到数据库中
4种具体实现:https://blog.csdn.net/qq_33976820/article/details/71203281数据库的脏读,不可重复读,幻读/不考虑隔离性导致的问题?
- 1)脏读
◆ 指在一个事务处理过程里读取了另一个未提交的事务中的数据。
◆ A事务在修改数据未提交,B访问并使用了还未提交的数据 - 2)不可重复读
◆ 指在对于数据库中的某个数据,一个事务范围内多次查询却返回了不同的数据值,这是由于在查询间隔,被另一个事务修改并提交了。
◆ 不可重复读和脏读的区别是,脏读是某一事务读取了另一个事务未提交的脏数据,而不可重复读则是读取了前一事务提交的数据。
◆ A正多次读取同一行数据,B修改了行数据,导致A多次读取的数据不一致 - 3)幻读
◆ 幻读是事务非独立执行时发生的一种现象。
◆ 如事务A改变了表某字段的值1—>2,事务B新插入一条某字段仍为1的记录 - 4)丢失更新
◆ A事务和B事务同时修改同一行数据,出现A事务修改内容丢失,修改内容变成B事务修改内容;
◆ 解决:进行行加锁,只允许并发一个更新事务
- 1)脏读
mysql事务的隔离级别?分别解决了什么? |9
- SQL 标准定义了四个隔离级别:
4个级别,由低到高,级别越高,执行效率就越低
◆ 1)READ-UNCOMMITTED(读取未提交): 最低的隔离级别,允许读取尚未提交的数据变更,任何情况都无法保证,可能会导致脏读、不可重复读或幻读。
◆ 2)READ-COMMITTED(读取已提交): 允许读取并发事务已经提交的数据,可以阻止脏读,但是幻读或不可重复读仍有可能发生。
◆ 3)REPEATABLE-READ(可重复读): 对同一字段的多次读取结果都是一致的,除非数据是被本身事务自己所修改,可以阻止脏读和不可重复读,但幻读仍有可能发生。
◆ 4)SERIALIZABLE(可串行化): 最高的隔离级别,完全服从ACID的隔离级别。所有的事务依次逐个执行,这样事务之间就完全不可能产生干扰,也就是说,该级别可以防止脏读、不可重复读以及幻读。 - 事务隔离机制的实现基于锁机制和并发调度。其中并发调度使用的是MVVC(多版本并发控制),通过保存修改的旧版本信息来支持并发一致性读和回滚等特性。
◆ 因为隔离级别越低,事务请求的锁越少,所以大部分数据库系统的隔离级别都是READ-COMMITTED(读取提交内容):,但是你要知道的是InnoDB 存储引擎默认使用 REPEATABLE-READ(可重读)并不会有任何性能损失。
◆ InnoDB 存储引擎在分布式事务的情况下一般会用到SERIALIZABLE(可串行化)隔离级别。
- SQL 标准定义了四个隔离级别:
默认隔离级别?
- Mysql 默认采用的 REPEATABLE_READ隔离级别 Oracle 默认采用的 READ_COMMITTED隔离级别
每个隔离级别是如何解决
https://blog.csdn.net/weixin_43934104/article/details/105847463 √
https://www.cnblogs.com/nightOfStreet/p/12977291.html数据库隔离级别,哪个更好,性能比较?
- 隔离级别高的数据库的可靠性高,但并发量低,而隔离级别低的数据库可靠性低,但并发量高,系统开销小
- 未提交读与序列化读不常用。
未提交读危险性太高,会读到很多脏数据。
而可串行化读是通过将读取的每一行数据加锁,以耗费性能为代价换取的,所以使用也很少, - 大部分数据库的隔离级别是提交读,比如oracle、sqlserver。而mysql默认的数据隔离级别是可重复读。
- 比较读提交,重复读性能
https://www.cnblogs.com/hainange/p/6153632.html
读已提交的原理?
多版本并发控制
MVCC其实就是行级锁的一个升级版。我们都知道数据库中有表锁和行锁,在表锁中读写操作是阻塞的,而MVCC的读写一般是不会阻塞的,这样避免了很多加锁过程。
1)隐藏列
Innodb引擎中数据表会有两个隐藏列,客户端不可见,分别是trx_id,创建版本号;和roll_pointer,回滚指针。
其中创建版本号其实就是创建该行数据的事务id。
2)undo log
事务对数据更新操作,会把旧数据行记录在undo log的记录中,在undo log记录数据行、生成这行数据的事务id。
在undo log中和之前的数据行形成一条链表,链表头就是最新的数据,这条链表就叫做版本链.
事务的可见性都是基于这个undo log来实现的
3)ReadView
查询操作时,事务会生成一个ReadView,ReadView是一个事务快照,准确来说是当前时间点系统内活跃的事务列表,也就是说系统内所有未提交的事务,都会记录在这个Readview内,事务就根据它来判断哪些数据是可见的,哪些是不可见的。
查询一条数据时,事务会拿到这个ReadView,去到undo log中进行判断。若查询到某一条数据:
先去查看undo log中的最新数据行,如果数据行的版本号小于ReadView记录的事务id最小值,就说明这条数据对当前数据库是可见的,可以直接作为结果集返回
若数据行版本号大于ReadView记录最大值,说明这条数据是由一个新的事务修改的,对当前事务不可见,那么就顺着版本链继续往下寻找第一条满足条件的
若数据行版本号在ReadView最小值和最大值之间,那么就需要进行遍历了整个ReadView了,如果数据行版本号等于ReadView的某个值,说说明该行数据仍然处于活跃状态,那么对当前事务不可见
读已提交和可重复读的实现
ReadView就是这样来判断数据可见性的。
那又是如何实现读已提交和可重复读呢?其实很简单,就是生成ReadView的时机不同。
对读已提交来说,事务中的每次读操作都会生成一个新的ReadView,也就是说,如果这期间某个事务提交了,那么它就会从ReadView中移除。这样确保事务每次读操作都能读到相对比较新的数据
而对可重复读来说,事务只有在第一次进行读操作时才会生成一个ReadView,后续的读操作都会重复使用这个ReadView。也就是说,如果在此期间有其他事务提交了,那么对于可重复读来说也是不可见的,因为对它来说,事务活跃状态在第一次进行读操作时就已经确定下来,后面不会修改了。
https://blog.csdn.net/SCUTJAY/article/details/104653599可重复读解决不了什么问题,怎么实现的可重复读?
- 可以阻止脏读和不可重复读,但幻读仍有可能发生。
4. 多版本并发控制
RC和RR级别事务的实现:一致性视图、MVCC
MVCC(gxn)
- MySQL的大多数事务型存储引擎实现的都不是简单的行级锁。基于提升并发性能的考虑,它们一般都同时实现了多版本并发控制(MVCC)。
- MVCC是行级锁的一个变种,但是它在很多情况下避免了加锁操作,因此开销更低。虽然实现机制有所不同,但大都实现了非阻塞的读操作,写操作也只锁定必要的行。
- MVCC的实现,是通过保存数据在某个时间点的快照来实现的。也就是说,不管需要执行多长时间,每个事务看到的数据都是一致的。根据事务开始的时间不同,每个事务对同一张表,同一时刻看到的数据可能是不一样的。
- 前面说到不同存储引擎的MVCC实现是不同的,典型的有乐观(optimistic)并发控制和悲观(pessimistic)并发控制。下面我们通过InnoDB的简化版行为来说明MVCC是如何工作的。
- InnoDB的MVCC,是通过在每行记录后面保存两个隐藏的列来实现的。这两个列,一个保存了行的创建时间,一个保存行的过期时间(或删除时间)。当然存储的并不是实际的时间值,而是系统版本号(system version number)。每开始一个新的事务,系统版本号都会自动递增。事务开始时刻的系统版本号会作为事务的版本号,用来和查询到的每行记录的版本号进行比较。下面看一下在REPEATABLE READ隔离级别下,MVCC具体是如何操作的。
1)SELECT
InnoDB会根据以下两个条件检查每行记录:
◆ InnoDB只查找版本早于当前事务版本的数据行(也就是,行的系统版本号小于或等于事务的系统版本号),这样可以确保事务读取的行,要么是在事务开始前已经存在的,要么是事务自身插入或者修改过的。
◆ 行的删除版本要么未定义,要么大于当前事务版本号。这可以确保事务读取到的行,在事务开始之前未被删除。
只有符合上述两个条件的记录,才能返回作为查询结果。
2)INSERT
InnoDB为新插入的每一行保存当前系统版本号作为行版本号。
3)DELETE
InnoDB为删除的每一行保存当前系统版本号作为行删除标识。
4)UPDATE
InnoDB为插入一行新记录,保存当前系统版本号作为行版本号,同时保存当前系统版本号到原来的行作为行删除标识。 - 保存这两个额外系统版本号,使大多数读操作都可以不用加锁。这样设计使得读数据操作很简单,性能很好,并且也能保证只会读取到符合标准的行。不足之处是每行记录都需要额外的存储空间,需要做更多的行检查工作,以及一些额外的维护工作。
- MVCC只在REPEATABLE READ和READ COMMITTED两个隔离级别下工作。其他两个隔离级别都和MVCC不兼容(4),因为READ UNCOMMITTED总是读取最新的数据行,而不是符合当前事务版本的数据行。而SERIALIZABLE则会对所有读取的行都加锁。
MVCC
- 多版本并发控制(Multi-Version Concurrency Control, MVCC)是 MySQL 的 InnoDB 存储引擎实现隔离级别的一种具体方式,用于实现提交读和可重复读这两种隔离级别。而未提交读隔离级别总是读取最新的数据行,无需使用MVCC。可串行化隔离级别需要对所有读取的行都加锁,单纯使用 MVCC 无法实现。
- 基础概念
1)版本号
◆ 系统版本号:是一个递增的数字,每开始一个新的事务,系统版本号就会自动递增。
◆ 事务版本号:事务开始时的系统版本号。
2)隐藏的列
MVCC 在每行记录后面都保存着两个隐藏的列,用来存储两个版本号:
◆ 创建版本号:指示创建一个数据行的快照时的系统版本号;
◆ 删除版本号:如果该快照的删除版本号大于当前事务版本号表示该快照有效,否则表示该快照已经被删除了。
3)Undo 日志
MVCC 使用到的快照存储在Undo日志中,该日志通过回滚指针把一个数据行(Record)的所有快照连接起来。
- 实现过程
◆ 以下实现过程针对可重复读隔离级别。
◆ 当开始一个事务时,该事务的版本号肯定大于当前所有数据行快照的创建版本号,理解这一点很关键。数据行快照的创建版本号是创建数据行快照时的系统版本号,系统版本号随着创建事务而递增,因此新创建一个事务时,这个事务的系统版本号比之前的系统版本号都大,也就是比所有数据行快照的创建版本号都大。
1)SELECT
◆ 多个事务必须读取到同一个数据行的快照,并且这个快照是距离现在最近的一个有效快照。但是也有例外,如果有一个事务正在修改该数据行,那么它可以读取事务本身所做的修改,而不用和其它事务的读取结果一致。
◆ 把没有对一个数据行做修改的事务称为T,T所要读取的数据行快照的创建版本号必须小于等于T的版本号,因为如果大于T的版本号,那么表示该数据行快照是其它事务的最新修改,因此不能去读取它。除此之外,T所要读取的数据行快照的删除版本号必须是未定义或者大于T的版本号,因为如果小于等于T的版本号,那么表示该数据行快照是已经被删除的,不应该去读取它。
2)INSERT
将当前系统版本号作为数据行快照的创建版本号。
3)DELETE
将当前系统版本号作为数据行快照的删除版本号。
4)UPDATE
将当前系统版本号作为更新前的数据行快照的删除版本号,并将当前系统版本号作为更新后的数据行快照的创建版本号。可以理解为先执行 DELETE 后执行 INSERT。 - 快照读与当前读
◆ 在可重复读级别中,通过MVCC机制,虽然让数据变得可重复读,但我们读到的数据可能是历史数据,是不及时的数据,不是数据库当前的数据!这在一些对于数据的时效特别敏感的业务中,就很可能出问题。
◆ 对于这种读取历史数据的方式,我们叫它快照读 (snapshot read),而读取数据库当前版本数据的方式,叫当前读 (current read)。很显然,在MVCC中:
① 快照读
MVCC 的 SELECT 操作是快照中的数据,不需要进行加锁操作。
select * from table ….;
② 当前读
MVCC 其它会对数据库进行修改的操作(INSERT、UPDATE、DELETE)需要进行加锁操作,从而读取最新的数据。可以看到 MVCC 并不是完全不用加锁,而只是避免了 SELECT 的加锁操作。
INSERT;UPDATE;DELETE;
在进行 SELECT 操作时,可以强制指定进行加锁操作。以下第一个语句需要加 S 锁,第二个需要加 X 锁。
- select * from table where ? lock in share mode;- select * from table where ? for update;
◆ 事务的隔离级别实际上都是定义的当前读的级别,MySQL为了减少锁处理(包括等待其它锁)的时间,提升并发能力,引入了快照读的概念,使得select不用加锁。而update、insert这些“当前读”的隔离性,就需要通过加锁来实现了。
2. 锁
mysql锁?
锁的类型&按照锁的粒度分数据库锁有哪些?锁机制与InnoDB锁算法
- 在关系型数据库中,可以按照锁的粒度把数据库锁分为行级锁(INNODB引擎)、表级锁(MYISAM引擎)和页级锁(BDB引擎 )。
- MyISAM和InnoDB存储引擎使用的锁:
◆ MyISAM采用表级锁(table-level locking)。
◆ InnoDB支持行级锁(row-level locking)和表级锁,默认为行级锁 - 行级锁,表级锁和页级锁对比
1)行级锁
◆ 行级锁是Mysql中锁定粒度最细的一种锁,表示只针对当前操作的行进行加锁。行级锁能大大减少数据库操作的冲突。其加锁粒度最小,但加锁的开销也最大。行级锁分为共享锁 和 排他锁。
◆ 特点:开销大,加锁慢;会出现死锁;锁定粒度最小,发生锁冲突的概率最低,并发度也最高。
2)表级锁
◆ 表级锁是MySQL中锁定粒度最大的一种锁,表示对当前操作的整张表加锁,它实现简单,资源消耗较少,被大部分MySQL引擎支持。最常使用的MYISAM与INNODB都支持表级锁定。表级锁定分为表共享读锁(共享锁)与表独占写锁(排他锁)。
◆ 特点:开销小,加锁快;不会出现死锁;锁定粒度大,发出锁冲突的概率最高,并发度最低。
3)页级锁
页级锁是MySQL中锁定粒度介于行级锁和表级锁中间的一种锁。表级锁速度快,但冲突多,行级冲突少,但速度慢。所以取了折衷的页级,一次锁定相邻的一组记录。
◆ 特点:开销和加锁时间界于表锁和行锁之间;会出现死锁;锁定粒度界于表锁和行锁之间,并发度一般
从锁的类别上分MySQL都有哪些锁呢?像上面那样子进行锁定岂不是有点阻碍并发效率了
- 从锁的类别上来讲,有共享锁和排他锁。
- 共享锁: 又叫做读锁。 当用户要进行数据的读取时,对数据加上共享锁。共享锁可以同时加上多个。
- 排他锁: 又叫做写锁。 当用户要进行数据的写入时,对数据加上排他锁。排他锁只可以加一个,他和其他的排他锁,共享锁都相斥。
- 用上面的例子来说就是用户的行为有两种,一种是来看房,多个用户一起看房是可以接受的。 一种是真正的入住一晚,在这期间,无论是想入住的还是想看房的都不可以。
- 锁的粒度取决于具体的存储引擎,InnoDB实现了行级锁,页级锁,表级锁。
- 他们的加锁开销从大到小,并发能力也是从大到小。
行锁?
- 概念
- 实现:MySQL中InnoDB引擎的行锁是怎么实现的?
-- 答:InnoDB是基于索引来完成行锁
-- 例: select * from tab_with_index where id = 1 for update;
for update 可以根据条件来完成行锁锁定,并且 id 是有索引键的列,如果 id 不是索引键那么InnoDB将完成表锁,并发将无从谈起
innodb什么情况下使用行锁和表锁?
InnoDB存储引擎的三种锁算法 [-]
- 锁算法
◆ Record lock:单个行记录上的锁
-- 锁定一个记录上的索引,而不是记录本身。
-- 如果表没有设置索引,InnoDB 会自动在主键上创建隐藏的聚簇索引,因此 Record Locks 依然可以使用。
◆ Gap lock:间隙锁,锁定一个范围,不包括记录本身
-- 锁定索引之间的间隙,但是不包含索引本身。例如当一个事务执行以下语句,其它事务就不能在 t.c 中插入 15。
-- SELECT c FROM t WHERE c BETWEEN 10 and 20 FOR UPDATE;
◆ Next-key lock:record+gap 锁定一个范围,包含记录本身
-- 它是 Record Locks 和 Gap Locks 的结合,不仅锁定一个记录上的索引,也锁定索引之间的间隙。
-- next-key锁其实包含了记录锁和间隙锁,即锁定一个范围,并且锁定记录本身,InnoDB默认加锁方式是next-key 锁。
-- 例如一个索引包含以下值:10, 11, 13, and 20,那么就需要锁定以下区间:
(-∞, 10]
(10, 11]
(11, 13]
(13, 20]
(20, +∞) - 相关知识点:
① innodb对于行的查询使用next-key lock
② Next-locking keying为了解决Phantom Problem幻读问题
③ 当查询的索引含有唯一属性时,将next-key lock降级为record key
④ Gap锁设计的目的是为了阻止多个事务将记录插入到同一范围内,而这会导致幻读问题的产生
⑤ 有两种方式显式关闭gap锁:(除了外键约束和唯一性检查外,其余情况仅使用record lock)
A. 将事务隔离级别设置为RC B.将参数innodb_locks_unsafe_for_binlog设置为1 - 在 InnoDB 存储引擎中,SELECT 操作的不可重复读问题通过 MVCC 得到了解决,而 UPDATE、DELETE 的不可重复读问题通过 Record Lock 解决,INSERT的不可重复读问题是通过 Next-Key Lock(Record Lock + Gap Lock)解决的。
- 锁算法
了解mysql的间隙锁?
next key锁
Mysql要加上nextkey锁,语句该怎么写
- next-key锁的作用是为了防止幻读,导致主从复制的不一致。当我们具体where条件指定某一个值时,它也会锁住这个值的前后范围。
- 比如有一个表child,id列上有90,100,102,
-- 当我们执行select * from chlid where id=100 for update 时,mysql会锁住90到102这个区间,一开始有点疑惑就是其实mysql只需要去锁定id=100这个值就可以防止幻读了,为什么还要去锁定相邻的区间范围呢?
这是为了预防另一种情况的发生。
-- 比如当我们执行 select * from chlid where id>100 for update时,这时next-key锁就派上用场了。
索引扫描到了100和102这两个值,但是仅仅锁住这两个值是不够的,因为当我们在另一个会话插入id=101的时候,就有可能产生幻读了。
所以mysql必须锁住[100,102)和[102,无穷大)这个范围,才能保证不会出现幻读。
对MySQL的锁了解吗
- 当数据库有并发事务的时候,可能会产生数据的不一致,这时候需要一些机制来保证访问的次序,锁机制就是这样的一个机制。
- 就像酒店的房间,如果大家随意进出,就会出现多人抢夺同一个房间的情况,而在房间上装上锁,申请到钥匙的人才可以入住并且将房间锁起来,其他人只有等他使用完毕才可以再次使用。
隔离级别与锁的关系 [-]
- 在Read Uncommitted级别下,读取数据不需要加共享锁,这样就不会跟被修改的数据上的排他锁冲突
- 在Read Committed级别下,读操作需要加共享锁,但是在语句执行完以后释放共享锁;
- 在Repeatable Read级别下,读操作需要加共享锁,但是在事务提交之前并不释放共享锁,也就是必须等待事务执行完毕以后才释放共享锁。
- SERIALIZABLE 是限制性最强的隔离级别,因为该级别锁定整个范围的键,并一直持有锁,直到事务完成。
什么是死锁?怎么解决?[-]
- 死锁是指两个或多个事务在同一资源上相互占用,并请求锁定对方的资源,从而导致恶性循环的现象。
- 常见的解决死锁的方法
1)如果不同程序会并发存取多个表,尽量约定以相同的顺序访问表,可以大大降低死锁机会。
2)在同一个事务中,尽可能做到一次锁定所需要的所有资源,减少死锁产生概率;
3)对于非常容易产生死锁的业务部分,可以尝试使用升级锁定颗粒度,通过表级锁定来减少死锁产生的概率;
如果业务处理不好可以用分布式事务锁或者使用乐观锁
数据库的乐观锁和悲观锁是什么?怎么实现的?[-]
- 数据库管理系统(DBMS)中的并发控制的任务是确保在多个事务同时存取数据库中同一数据时不破坏事务的隔离性和统一性以及数据库的统一性。乐观并发控制(乐观锁)和悲观并发控制(悲观锁)是并发控制主要采用的技术手段。
◆ 悲观锁:假定会发生并发冲突,屏蔽一切可能违反数据完整性的操作。在查询完数据的时候就把事务锁起来,直到提交事务。实现方式:使用数据库中的锁机制
◆ 乐观锁:假设不会发生并发冲突,只在提交操作时检查是否违反数据完整性。在修改数据的时候把事务锁起来,通过version的方式来进行锁定。实现方式:乐一般会使用版本号机制或CAS算法实现。 - 两种锁的使用场景
◆ 从上面对两种锁的介绍,我们知道两种锁各有优缺点,不可认为一种好于另一种,像乐观锁适用于写比较少的情况下(多读场景),即冲突真的很少发生的时候,这样可以省去了锁的开销,加大了系统的整个吞吐量。
◆ 但如果是多写的情况,一般会经常产生冲突,这就会导致上层应用会不断的进行retry,这样反倒是降低了性能,所以一般多写的场景下用悲观锁就比较合适。
- 数据库管理系统(DBMS)中的并发控制的任务是确保在多个事务同时存取数据库中同一数据时不破坏事务的隔离性和统一性以及数据库的统一性。乐观并发控制(乐观锁)和悲观并发控制(悲观锁)是并发控制主要采用的技术手段。
7. 查询优化
https://thinkwon.blog.csdn.net/article/details/104778621
1. 慢查询如何分析排查和优化? |3
mysql如何优化(回答索引、拆分等) |5
mysql查询优化?
索引、关联子查询等,最常见的就是给表加上合适的索引mysql在项目中的优化场景?
分库分表的理解,好处
https://blog.csdn.net/u010817136/article/details/51037845数据库垂直与水平拆分怎么做?
分库分表数据切分- 水平切分
◆ 水平切分又称为 Sharding,它是将同一个表中的记录拆分到多个结构相同的表中。
◆ 当一个表的数据不断增多时,Sharding 是必然的选择,它可以将数据分布到集群的不同节点上,从而缓存单个数据库的压力。
- 垂直切分
◆ 垂直切分是将一张表按列分成多个表,通常是按照列的关系密集程度进行切分,也可以利用垂直气氛将经常被使用的列喝不经常被使用的列切分到不同的表中。
◆ 在数据库的层面使用垂直切分将按数据库中表的密集程度部署到不通的库中,例如将原来电商数据部署库垂直切分称商品数据库、用户数据库等。
- Sharding 策略
◆ 哈希取模:hash(key)%N
◆ 范围:可以是 ID 范围也可以是时间范围
◆ 映射表:使用单独的一个数据库来存储映射关系 - Sharding 存在的问题
1)事务问题
使用分布式事务来解决,比如 XA 接口
2)连接
可以将原来的连接分解成多个单表查询,然后在用户程序中进行连接。
3)唯一性
◆ 使用全局唯一 ID (GUID)
◆ 为每个分片指定一个 ID 范围
◆ 分布式 ID 生成器(如 Twitter 的 Snowflake 算法)
- 水平切分
9. 复制
主从复制
- 主从复制:将主数据库中的DDL和DML操作通过二进制日志(BINLOG)传输到从数据库上,然后将这些日志重新执行(重做);从而使得从数据库的数据与主数据库保持一致。
- 主从复制的作用
◆ 主数据库出现问题,可以切换到从数据库。
◆ 可以进行数据库层面的读写分离。
◆ 可以在从数据库上进行日常备份。 - MySQL主从复制解决的问题
◆ 数据分布:随意开始或停止复制,并在不同地理位置分布数据备份
◆ 负载均衡:降低单个服务器的压力
◆ 高可用和故障切换:帮助应用程序避免单点失败
◆ 升级测试:可以用更高版本的MySQL作为从库 - MySQL主从复制工作原理
◆ 在主库上把数据更高记录到二进制日志
◆ 从库将主库的日志复制到自己的中继日志
◆ 从库读取中继日志的事件,将其重放到从库数据中 - 主要涉及三个线程:binlog 线程、I/O 线程和 SQL 线程。
◆ 主--binlog 线程 :负责将主服务器上的数据更改写入二进制日志(Binary log)中。
◆ 从--I/O 线程 :负责从主服务器上读取- 二进制日志,并写入从服务器的中继日志(Relay log)。
◆ 从--SQL 线程 :负责读取中继日志,解析出主服务器已经执行的数据更改并在从服务器中重放(Replay)。
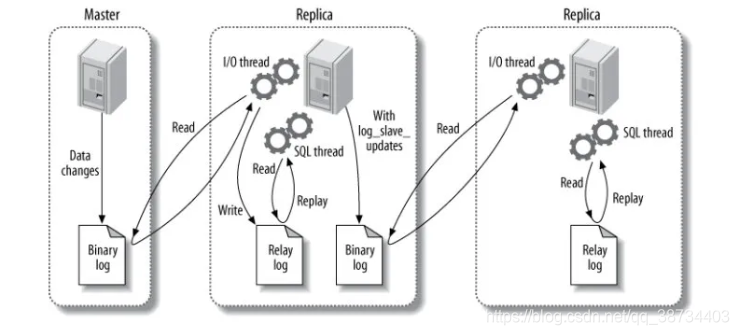
- 复制过程

Binary log:主数据库的二进制日志
Relay log:从服务器的中继日志
第一步:master在每个事务更新数据完成之前,将该操作记录串行地写入到binlog文件中。
第二步:salve开启一个I/O Thread,该线程在master打开一个普通连接,主要工作是binlog dump process。如果读取的进度已经跟上了master,就进入睡眠状态并等待master产生新的事件。I/O线程最终的目的是将这些事件写入到中继日志中。
第三步:SQL Thread会读取中继日志,并顺序执行该日志中的SQL事件,从而与主数据库中的数据保持一致。
mysql主从复制主要有哪几种模式?
mysql主从同步怎么做?
mysql是集群还是单节点?最大连接数,最大的表中数据量大约是多少?
读写分离
- 主服务器处理写操作以及实时性要求比较高的读操作,而从服务器处理读操作。
- 读写分离能提高性能的原因在于:
◆ 主从服务器负责各自的读和写,极大程度缓解了锁的争用;
◆ 从服务器可以使用 MyISAM,提升查询性能以及节约系统开销;
◆ 增加冗余,提高可用性。 - 读写分离常用代理方式来实现,代理服务器接收应用层传来的读写请求,然后决定转发到哪个服务器。
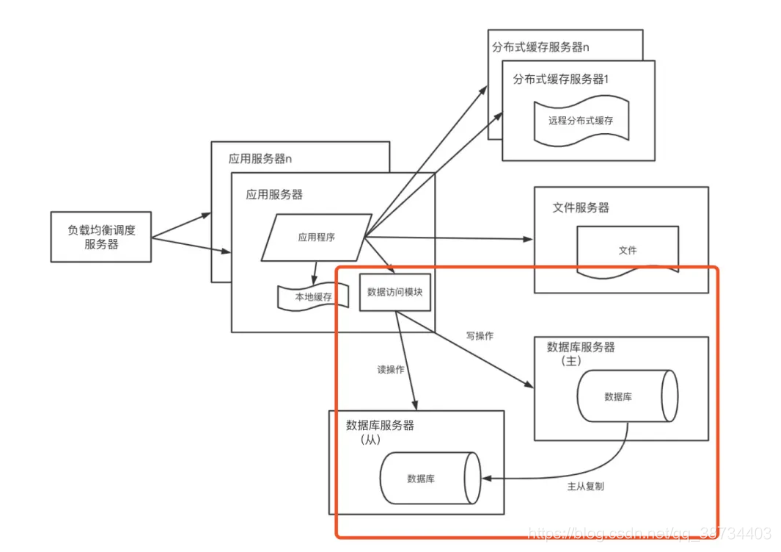
数据库的读写分离的作用?
因为数据库的“写”(写10000条数据到oracle可能要3分钟)操作是比较耗时的。
但是数据库的“读”(从oracle读10000条数据可能只要5秒钟)。
所以读写分离,解决的是,数据库的写入,影响了查询的效率sql注入原理及解决方案?
https://www.cnblogs.com/jiaoxiaohui/p/10760763.html
※ 5-Redis
- 总结:
https://www.zybuluo.com/mdeditor#1714102 - 资料
https://juejin.im/post/6844904142310211597
https://thinkwon.blog.csdn.net/article/details/103522351
一、基础知识
1-redis简介
- redis介绍一下?rky
是什么?可以做什么?基本结构?特性?弊端?
1. 概述
|是什么?|做什么?|特性?|
redis概念?(+)
- Redis(Remote Dictionary Server)
- 由C编写,开源的(BSD许可)高性能非关系型(NoSQL)的键值对数据库。
- 一种基于键值对(key-value)的NoSQL数据库,
- 其值可以是由多种数据结构和算法组成,因此Redis可以满足很多的应用场景,
- Redis会将所有数据都存放在内存中,使它的读写性能非常惊人。
- 还可以将内存的数据利用快照和日志的形式保存到硬盘上,这样在发生类似断电或者机器故障的时候,内存中的数据不会“丢失”。
- 除了上述功能以外,还提供了键过期、发布订阅、事务、流水线、Lua脚本等附加功能。
Redis的8个重要特性(rsy)
1)速度快:快的原因;
2)基于键值对的数据结构服务器:类似词典的功能;
3)丰富的功能:5种数据结构、键过期、发布订阅、Lua脚本、简单的事务、流水线(Pipeline);
4)简单稳定:源码很少、单线程模型、不需要依赖于操作系统中的类库,实现事件处理;
5)客户端语言多:提供了简单的TCP通信协议,很多编程语言可以很方便地接入到
Redis,几乎涵盖了主流的编程语言;
6)持久化:RDB和AOF;
7)主从复制
8)高可用和分布式:高可用实现Redis Sentinel,它能够保证Redis节点的故障发现和故障自动转移、分布式实现Redis Cluster,提供了高可用、读写和容量的
扩展性。redis是单线程还是多线程?
- 为什么说redis是单线程的?
Redis基于Reactor模式开发了网络事件处理器,这个处理器被称为文件事件处理器。它的组成结构为4部分:多个套接字、IO多路复用程序、文件事件分派器、事件处理器。因为文件事件分派器队列的消费是单线程的,所以Redis才叫单线程模型。

但是我们也知道,一般来说 Redis 的瓶颈并不在CPU,而在内存和网络。如果要使用 CPU多核,可以搭建多个 Redis 实例来解决。
https://www.cnblogs.com/innocenter/p/12963979.html
- 为什么说redis是单线程的?
redis的单线程?
- redis核心就是,如果我的数据全都在内存里,我单线程的去操作 就是效率最高的,为什么呢,因为多线程的本质就是CPU模拟出来多个线程的情况,这种模拟出来的情况就有一个代价,就是上下文的切换,对于一个内存的系统来说,它没有上下文的切换就是效率最高的。redis 用 单个CPU绑定一块内存的数据,然后针对这块内存的数据进行多次读写的时候,都是在一个CPU上完成的,所以它是单线程处理这个事。在内存的情况下,这个方案就是最佳方案 —— 阿里 沈询
- redis作为单进程模型的程序,为了充分利用多核CPU,常常在一台server上会启动多个实例。而为了减少切换的开销,有必要为每个实例指定其所运行的CPU。
redis为什么那么快?-1)速度快
(为什么Redis的性能十分的高?)- 正常情况下,Redis执行命令的速度非常快,官方给出的数字是读写性 能可以达到10万/秒,不考虑机器性能的差异,大致归纳为以下四点造就了Redis除此之快的速度:
① Redis的所有数据都是存放在内存中的,内存执行速度快。
-- 据谷歌给出的各层级硬件执行速度,看出把数据放在内存中是Redis速度快的最主要原因。
-- 数据储存在内存里面,读写数据的时候都不会受到硬盘I/O速度的限制,所以速度极快。
② Redis是用C语言实现的,执行速度相对会更快。
-- 一般来说C语言实现的程序“距离”操作系统更近,执行速度相对会更快
③ Redis使用了单线程架构,预防了多线程可能产生的竞争问题。
④ 开源代码优雅并性能高。
-- 作者对于Redis源代码可以说是精打细磨,曾经有人评价Redis是少有的集性能和优雅于一身的开源代码。
- 正常情况下,Redis执行命令的速度非常快,官方给出的数字是读写性 能可以达到10万/秒,不考虑机器性能的差异,大致归纳为以下四点造就了Redis除此之快的速度:
为什么单线程还能这么快?-4)简单 |2
(/redis单线程为什么快?)- 简单体现:源码少、单线程、不依赖os中的类库,内部实现
1)纯内存访问
-- Redis将所有数据放在内存中,内存的响应时长大约为100纳秒,这是Redis达到每秒万级别访问的重要基础。
-- 查找和操作的时间复杂度都是O(1)
2)非阻塞I/O
Redis使用epoll作为I/O多路复用技术的实现,再加上Redis自身的事件处理模型将epoll中的连接、读写、关闭都转换为事件,不在网络I/O上浪费过多的时间。(使用多路I/O复用模型,多路I/O复用模型是利用 select、poll、epoll 可以同时监察多个流的 I/O事件的能力,在空闲的时候,会把当前线程阻塞掉,当有一个或多个流有 I/O 事件时,就从阻塞态中唤醒,于是程序就会轮询一遍所有的流(epoll 是只轮询那些真正发出了事件的流),并且只依次顺序的处理就绪的流,这种做法就避免了大量的无用操作)
3)单线程避免了线程切换和竞态产生的消耗
-- 避免了不必要的上下文切换和竞争条件,也不存在多进程或者多线程导致的切换而消耗CPU,不用去考虑各种锁的问题,不存在加锁释放锁操作,没有因为可能出现死锁而导致的性能消耗;
-)参考其他,还有
① 数据结构简单,对数据操作也简单,Redis中的数据结构是专门进行设计的;
② 使用底层模型不同,它们之间底层实现方式以及与客户端之间通信的应用协议不一样,Redis直接自己构建了VM机制,因为一般的系统调用系统函数的话,会浪费一定的时间去移动和请求;
https://www.cnblogs.com/hzSummer/p/9551848.html
- 简单体现:源码少、单线程、不依赖os中的类库,内部实现
redis的作用?
(/rky:Redis使用场景/可以做什么 )
1)缓存
缓存机制几乎在所有的大型网站都有使用,合理地使用缓存不仅可以加 快数据的访问速度,而且能够有效地降低后端数据源的压力。Redis提供了键值过期时间设置,并且也提供了灵活控制最大内存和内存溢出后的淘汰策略。
2)排行榜系统
排行榜系统几乎存在于所有的网站,例如按照热度排名的排行榜,按照 发布时间的排行榜,按照各种复杂维度计算出的排行榜,Redis提供了列表和有序集合数据结构,合理地使用这些数据结构可以很方便地构建各种排行榜系统。
3)计数器应用
计数器在网站中的作用至关重要,例如视频网站有播放数、电商网站有 浏览数,为了保证数据的实时性,每一次播放和浏览都要做加1的操作,如 果并发量很大对于传统关系型数据的性能是一种挑战。Redis天然支持计数功能而且计数的性能也非常好,可以说是计数器系统的重要选择。
4)社交网络
赞/踩、粉丝、共同好友/喜好、推送、下拉刷新等是社交网站的必备功能,由于社交网站访问量通常比较大,而且传统的关系型数据不太适合保存这种类型的数据,Redis提供的数据结构可以相对比较容易地实现这些功能。
5)消息队列系统
消息队列系统可以说是一个大型网站的必备基础组件,因为其具有业务 解耦、非实时业务削峰等特性。Redis提供了发布订阅功能和阻塞队列的功能,虽然和专业的消息队列比还不够足够强大,但是对于一般的消息队列功能基本可以满足。redis常用命令?
- 全局
keys * //查看所有键dbsize //键总数exists key //检查键是否存在,返回1,0del key [key ...] //删除键 del javaexpire key seconds // 键过期 set java 10type key //键的数据结构类型object encoding //命令查询内部编码
- 全局
更新redis怎么实现?
- 1)键空间
-- Redis是一个键值对(key-value pair)数据库服务器,服务器中的每个数据库都由一个redis.h/redisDb结构表示,其中,redisDb结构的dict字典保存了数据库中的所有键值对,我们将这个字典称为键空间(key space):
typedef struct redisDb {// ...// 数据库键空间,保存着数据库中的所有键值对dict *dict;// ...} redisDb;
-- 键空间和用户所见的数据库是直接对应的:
·键空间的键也就是数据库的键,每个键都是一个字符串对象。
·键空间的值也就是数据库的值,每个值可以是字符串对象、列表对象、哈希表对象、集合对象和有序集合对象中的任意一种Redis对象。
-- 因为数据库的键空间是一个字典,所以所有针对数据库的操作,比如添加一个键值对到数据库,或者从数据库中删除一个键值对,又或者在数据库中获取某个键值对等,实际上都是通过对键空间字典进行操作来实现的。- 2)键更新
对一个数据库键进行更新,实际上就是对键空间里面键所对应的值对象进行更新,根据值对象的类型不同,更新的具体方法也会有所不同。
-- 例子:
redis> SET message "blah blah"

- 1)键空间
2. 为什么用
为什么要用 Redis /为什么要用缓存
- 读多,减轻数据压力,使用缓存保证效率
- 高性能
将用户访问的数据存在数缓存中,下一次再访问可以直接从缓存中获取。操作缓存就是直接操作内存,所以速度相当快。数据更改,同步改变缓存中相应的数据即可! - 高并发
直接操作缓存能够承受的请求是远远大于直接访问数据库的,用户的一部分请求会直接到缓存这里而不用经过数据库。
为什么要用 Redis 而不用 map/guava 做缓存?
- 缓存分为本地缓存和分布式缓存。
- Java使用自带的map或者guava实现的是本地缓存,最主要的特点是轻量以及快速,生命周期随着jvm的销毁而结束,并且在多实例的情况下,每个实例都需要各自保存一份缓存,缓存不具有一致性。
- redis 或 memcached这类称为分布式缓存,在多实例的情况下,各实例共用一份缓存数据,缓存具有一致性。
-- 缺点:需要保持redis或memcached服务的高可用,整个程序架构上较为复杂。
redis与memcached有什么区别,为什么选择Redis,而不是memcached?
redis单进程单线程
单进程多线程的同样基于内存的 KV 数据库 Memcached
Memcache需要依赖libevent这样的系统类库redis优缺点?
- 优点
-- 读写性能优异 (读 11万次/s,写 81000次/s)
-- 支持数据持久化 (AOF、RDB)
-- 支持事务,所有操作都是原子性的,同时对几个操作合并后的原子性执行。
-- 数据类型丰富
-- 支持主从复制,主机会自动将数据同步到从机,可以进行读写分离 - 缺点
-- 数据库容量受到物理内存的限制,不能用作海量数据的高性能读写,因此Redis适合的场景主要局限在较小数据量的高性能操作和运算上。
-- Redis 不具备自动容错和恢复功能,主机从机的宕机都会导致前端部分读写请求失败,需要等待机器重启或者手动切换前端的IP才能恢复。
-- 主机宕机,宕机前有部分数据未能及时同步到从机,切换IP后还会引入数据不一致的问题,降低了系统的可用性。
-- Redis较难支持在线扩容,在集群容量达到上限时在线扩容会变得很复杂。为避免这一问题,运维人员在系统上线时必须确保有足够的空间,这对资源造成了很大的浪费。
- 优点
说一下单进程、单线程的Redis和你平时写的多线程程序的对比?
线程切换
2-数据结构
redis的五种数据结构/数据类型? |8
- 支持多种类型的数据结构,如字符串(String),散列/哈希(Hash),列表(List),集合(Set),有序集合(Sorted Set或者是ZSet)与范围查询,位图(Bitmaps),Hyperloglogs、GEO(地理信息定位)。
- 其中常见的数据结构类型有:String、List、Set、Hash、ZSet这5种。
插入数据时间复杂度?
数据结构 时间复杂度 string set O(1) mset:O(n) get:O(1) list lpush/rpush:O(n) lpop/rpop:O(1)n为插入数量 hash hset/hget:O(1) hmset/hmget:O(n) set sadd/spop:O(n)
1-应用场景
- 数据类型的应用场景?
string类型应用场景?
1)缓存功能
比较典型的缓存使用场景,如图

-- 其中,Redis作为缓存层,MySQL作为存储层,绝大部分请求的数据都是从Redis中获取。由于Redis具有支撑高并发的特性,所以缓存通常能起到加速读写和降低后端压力的作用。//1)该函数用于获取用户的基础信息:UserInfo getUserInfo(long id){//2)首先从Redis获取用户信息:// 定义键userRedisKey = "user:info:" + id;// 从Redis获取值value = redis.get(userRedisKey);if (value != null) {// 将值进行反序列化为UserInfo并返回结果userInfo = deserialize(value);return userInfo;}//3)如果没有从Redis获取到用户信息,需要从MySQL中进行获取,并将结果回写到Redis,添加1小时(3600秒)过期时间:// 从MySQL获取用户信息userInfo = mysql.get(id);// 将userInfo序列化,并存入Redisredis.setex(userRedisKey, 3600, serialize(userInfo));// 返回结果return userInfo}
2)计数
-- Redis作为计数的基础工具,可以实现快速计数、查询缓存的功能,同时数据可以异步落地到其他数据源。
-- 例如笔者所在团队的视频播放数系统就是使用Redis作为视频播放数计数的基础组件,用户每播放一次视频,相应的视频播放数就会自增1:
(应用:实际上一个真实的计数系统要考虑的问题会很多:防作弊、按照不同维度计数,数据持久化到底层数据源等。)long incrVideoCounter(long id) {key = "video:playCount:" + id;return redis.incr(key);}
3)共享Session
现象:
一个分布式Web服务将用户的Session信息(例如用户登录信息)保存在各自服务器中,这样会造成一个问题,出于负载均衡的考虑,分布式服务会将用户的访问均衡到不同服务器上,用户刷新一次访问可能会发现需要重新登录,这个问题是用户无法容忍的。
解决:
为了解决这个问题,可以使用Redis将用户的Session进行集中管理,如
图,在这种模式下只要保证Redis是高可用和扩展性的,每次用户更新或者查询登录信息都直接从Redis中集中获取。- 4)限速
很多应用出于安全的考虑,会在每次进行登录时,让用户输入手机验证
码,从而确定是否是用户本人。但是为了短信接口不被频繁访问,会限制用户每分钟获取验证码的频率,例如一分钟不能超过5次
(例如一些网站限制一个IP地址不能在一秒钟之内访问超过n次也可以采用类似的思路。)
//伪代码给出了基本实现思路:phoneNum = "138xxxxxxxx";key = "shortMsg:limit:" + phoneNum;// SET key value EX 60 NXisExists = redis.set(key,1,"EX 60","NX");if(isExists != null || redis.incr(key) <=5){// 通过}else{// 限速}
哈希应用场景?
- 关系型数据表记录的两条用户信息,用户的属性作为表的列,每条用户信息作为行。
id name age city 1 tom 23 beijng 2 mike 30 tianjin - 将其用哈希类型存储

相比于使用字符串序列化缓存用户信息,哈希类型变得更加直观,并且在更新操作上会更加便捷。可以将每个用户的id定义为键后缀,多对fieldvalue对应每个用户的属性,类似如下伪代码:
UserInfo getUserInfo(long id){// 用户id作为key后缀userRedisKey = "user:info:" + id;// 使用hgetall获取所有用户信息映射关系userInfoMap = redis.hgetAll(userRedisKey);UserInfo userInfo;if (userInfoMap != null) {// 将映射关系转换为UserInfouserInfo = transferMapToUserInfo(userInfoMap);} else {// 从MySQL中获取用户信息userInfo = mysql.get(id);// 将userInfo变为映射关系使用hmset保存到Redis中redis.hmset(userRedisKey, transferUserInfoToMap(userInfo));// 添加过期时间redis.expire(userRedisKey, 3600);}return userInfo;}
不同,哈希类型和关系型数据库有两点不同之处:
-- 哈希类型是稀疏的,而关系型数据库是完全结构化的,例如哈希类型
每个键可以有不同的field,而关系型数据库一旦添加新的列,所有行都要为其设置值(即使为NULL)。
-- 关系型数据库可以做复杂的关系查询,而Redis去模拟关系型复杂查询开发困难,维护成本高。
list列表的使用场景?
1)消息队列
lpush+brpop命令组合即可实现阻塞队列,生产者客户端使用lrpush从列表左侧插入元素,多个消费者客户端使用brpop命令阻塞式的“抢”列表尾部的元素,多个客户端保证了消费的负载均衡和高可用性。
2)文章列表
每个用户有属于自己的文章列表,现需要分页展示文章列表。此时可以考虑使用列表,因为列表不但是有序的,同时支持按照索引范围获取元素。1|每篇文章使用哈希结构存储,例如每篇文章有3个属性title、timestamp、content:
hmset acticle:1 title xx timestamp 1476536196 content xxxx...hmset acticle:k title yy timestamp 1476512536 content yyyy...
2|向用户文章列表添加文章,user:{id}:articles作为用户文章列表的键(key):
lpush user:1:acticles article:1 article3...lpush user:k:acticles article:5...
3|分页获取用户文章列表,例如下面伪代码获取用户id=1的前10篇文
章:articles = lrange user:1:articles 0 9for article in {articles}hgetall {article}
列表类型保存和获取文章列表的两个问题。
-- 当每次分页获取的文章个数较多,需多次hgetall操作,
可以考虑使用Pipeline批量获取,或者考虑将文章数据序列化为字符串类型,使用mget批量获取。
-- 分页获取文章列表时,lrange命令在列表两端性能较好,但是如果列表较大,获取列表中间范围的元素性能会变差,
可以考虑将列表做二级拆分,或者使用Redis3.2的quicklist内部编码实现,它结合ziplist和linkedlist的特点,获取列表中间范围的元素时也可以高效完成。- 其他扩展?
实际上列表的使用场景很多,在选择时可以参考以下口诀:
-- lpush+lpop=Stack(栈)
-- lpush+rpop=Queue(队列)
-- lpsh+ltrim=Capped Collection(有限集合)
-- lpush+brpop=Message Queue(消息队列)
set应用场景?
- 集合类型比较典型的使用场景是标签(tag)。
- 例如一个用户可能对娱乐、体育比较感兴趣,另一个用户可能对历史、新闻比较感兴趣,这些兴趣点就是标签。有了这些数据就可以得到喜欢同一个标签的人,以及用户的共同喜好的标签,这些数据对于用户体验以及增强用户黏度比较重要。
- 例如一个电子商务的网站会对不同标签的用户做不同类型的推荐,比如对数码产品比较感兴趣的人,在各个页面或者通过邮件的形式给他们推荐最新的数码产品,通常会为网站带来更多的利益。
- 实现:下面使用集合类型实现标签功能的若干功能。
1|给用户添加标签
sadd user:1:tags tag1 tag2 tag5sadd user:2:tags tag2 tag3 tag5...sadd user:k:tags tag1 tag2 tag4...
2|给标签添加用户
sadd tag1:users user:1 user:3sadd tag2:users user:1 user:2 user:3...sadd tagk:users user:1 user:2...
实际开发需要注意问题:开发提示1:
用户和标签的关系维护应该在一个事务内执行,防止部分命令失败造成的数据不一致,有关如何将两个命令放在一个事务,参考事务以及Lua的使用方法。3|删除用户下的标签
srem user:1:tags tag1 tag5...
4|删除标签下的用户
srem tag1:users user:1srem tag5:users user:1...
3|和4|也是尽量放在一个事务执行。
5|计算用户共同感兴趣的标签可以使用sinter命令,来计算用户共同感兴趣的标签,如下代码所示:
sinter user:1:tags user:2:tags
开发注意问题:开发提示2:
前面只是给出了使用Redis集合类型实现标签的基本思路,实际上一个
标签系统远比这个要复杂得多,不过集合类型的应用场景通常为以下几种:
-- sadd=Tagging(标签)
-- spop/srandmember=Random item(生成随机数,比如抽奖)
-- sadd+sinter=Social Graph(社交需求)
zset应用场景?
- 排行榜系统。
-- 例如视频网站需要对用户上传的视频做排行榜,榜单的维度可能是多个方面的:按照时间、按照播放数量、按照获得的赞数。 - 实现:使用赞数这个维度,记录每天用户上传视频的排行榜。
主要需要实现以下4个功能: (1)添加用户赞数
例如用户mike上传了一个视频,并获得了3个赞// 可以使用有序集合的zadd和zincrby功能:zadd user:ranking:2016_03_15 mike 3// 如果之后再获得一个赞,可以使用zincrby:zincrby user:ranking:2016_03_15 mike 1
(2)取消用户赞数
由于各种原因(例如用户注销、用户作弊)需要将用户删除,此时需要
将用户从榜单中删除掉,可以使用zrem。
例如删除成员tom:zrem user:ranking:2016_03_15 mike
(3)展示获取赞数最多的十个用户
此功能使用zrevrange命令实现:zrevrangebyrank user:ranking:2016_03_15 0 9
(4)展示用户信息以及用户分数
此功能将用户名作为键后缀,将用户信息保存在哈希类型中,至于用户
的分数和排名可以使用zscore和zrank两个功能:hgetall user:info:tomzscore user:ranking:2016_03_15 mikezrank user:ranking:2016_03_15 mike
- 排行榜系统。
项目中的应用?
- redis有哪些数据结构你在项目中使用到了,redis在项目中是如何使用的?
2-内部编码
需参考《rsx》
1. 每种数据结构都有两种以上的内部编码实现,例如list数据结构包含了linkedlist和ziplist两种内部编码

redis的5种类型,及其实现原理(redis设计与实现这本书我倒背如流,面试官夸我很不错)
- 如下
Redis底层数据结构?
- Redis用到的所有主要数据结构,如简单动态字符串(SDS)、双端链表(linkedlist)、字典(hashtable)、压缩列表(ziplist)、整数集合(intset)、跳跃表(skiplist)等等。
- Redis并没有直接使用这些数据结构来实现键值对数据库,而是基于这些数据结构创建了一个对象系统,这个系统包含字符串对象、列表对象、哈希对象、集合对象和有序集合对象这五种类型的对象;
1.hash对象
- redis的Hash类型讲解?
- 哈希对象的编码?
- 哈希对象的编码可以是ziplist或者hashtable。
1)ziplist编码
ziplist编码的哈希对象使用压缩列表作为底层实现,每当有新的键值对要加入到哈希对象时,程序会先将保存了键的压缩列表节点推入到压缩列表表尾,然后再将保存了值的压缩列表节点推入到压缩列表表尾,因此:
·保存了同一键值对的两个节点总是紧挨在一起,保存键的节点在前,保存值的节点在后;
·先添加到哈希对象中的键值对会被放在压缩列表的表头方向,而后来添加到哈希对象中的键值对会被放在压缩列表的表尾方向。

2)hashtable编码
hashtable编码的哈希对象使用字典作为底层实现,哈希对象中的每个键值对都使用一个字典键值对来保存:
·字典的每个键都是一个字符串对象,对象中保存了键值对的键;
·字典的每个值都是一个字符串对象,对象中保存了键值对的值。

- 编码转换?
1)当哈希对象可以同时满足以下两个条件时,哈希对象使用ziplist编码:
·哈希对象保存的所有键值对的键和值的字符串长度都小于64字节;
·哈希对象保存的键值对数量小于512个;不能满足这两个条件的哈希对象需要使用hashtable编码。
2)对于使用ziplist编码的列表对象来说,当使用ziplist编码所需的两个条件的任意一个不能被满足时,对象的编码转换操作就会被执行,原本保存在压缩列表里的所有键值对都会被转移并保存到字典里面,对象的编码也会从ziplist变为hashtable。
- 哈希对象的编码可以是ziplist或者hashtable。
2.哈希编码
2.1 字典-hashtable
渐进式rehash?
reids的hash是怎么实现的-hashtable? |2
2.2 压缩列表-ziplist
- reids的hash是怎么实现的-ziplist? |2
3.zset编码
3.1 zset对象
redis的Zset怎么实现的? |3
- 有序集合的编码可以是ziplist或者skiplist。
- ziplist编码
-- ziplist编码的压缩列表对象使用压缩列表作为底层实现,每个集合元素使用两个紧挨在一起的压缩列表节点来保存,第一个节点保存元素的成员(member),而第二个元素则保存元素的分值(score)。
-- 压缩列表内的集合元素按分值从小到大进行排序,分值较小的元素被放置在靠近表头的方向,而分值较大的元素则被放置在靠近表尾的方向。


- skiplist编码
skiplist编码的有序集合对象使用zset结构作为底层实现,一个zset结构同时包含一个字典和一个跳跃表:
typedef struct zset {zskiplist *zsl;dict *dict;} zset;


有序集合元素同时被保存在字典和跳跃表中(上图)
为了展示方便,图在字典和跳跃表中重复展示了各个元素的成员和分值,但在实际中,字典和跳跃表会共享元素的成员和分值,所以并不会造成任何数据重复,也不会因此而浪费任何内存。- zset结构中的zsl跳跃表按分值从小到大保存了所有集合元素,每个跳跃表节点都保存了一个集合元素:跳跃表节点的object属性保存了元素的成员,而跳跃表节点的score属性则保存了元素的分值。通过这个跳跃表,程序可以对有序集合进行范围型操作,比如ZRANK、ZRANGE等命令就是基于跳跃表API来实现的。
-- 除此之外,zset结构中的dict字典为有序集合创建了一个从成员到分值的映射,字典中的每个键值对都保存了一个集合元素:字典的键保存了元素的成员,而字典的值则保存了元素的分值。通过这个字典,程序可以用O(1)复杂度查找给定成员的分值,ZSCORE命令就是根据这一特性实现的,而很多其他有序集合命令都在实现的内部用到了这一特性。
-- 有序集合每个元素的成员都是一个字符串对象,而每个元素的分值都是一个double类型的浮点数。值得一提的是,虽然zset结构同时使用跳跃表和字典来保存有序集合元素,但这两种数据结构都会通过指针来共享相同元素的成员和分值,所以同时使用跳跃表和字典来保存集合元素不会产生任何重复成员或者分值,也不会因此而浪费额外的内存。 - 编码转换?
1)不能满足以上两个条件的有序集合对象将使用skiplist编码。(可修改条件上限)
·有序集合保存的元素数量小于128个;
·有序集合保存的所有元素成员的长度都小于64字节;
2)对于使用ziplist编码的有序集合对象来说,当使用ziplist编码所需的两个条件中的任意一个不能被满足时,就会执行对象的编码转换操作,原本保存在压缩列表里的所有集合元素都会被转移并保存到zset结构里面,对象的编码也会从ziplist变为skiplist。
Zset数据结构,怎么排序的?
- 上述中找答案↑
zset实现是跳表,否可以用平衡树实现
- 范围查找:平衡树比skiplist操作要复杂。
平衡树,找到指定范围的小值后,还需中序遍历继续查找。
skiplist,找到小值之后,对第1层链表进行若干步的遍历即可。 - 插入和删除:平衡树可能引发子树的调整,操作复杂,而skiplist只需要修改相邻节点的指针,简单速度。
- 内存占用:skiplist比平衡树更灵活一些。
- 算法实现:skiplist比平衡树要简单得多。
- 范围查找:平衡树比skiplist操作要复杂。
为什么有序集合需要同时使用跳跃表和字典来实现?
- 在理论上,有序集合可以单独使用字典或者跳跃表的其中一种数据结构来实现,但无论单独使用字典还是跳跃表,在性能上对比起同时使用字典和跳跃表都会有所降低。举个例子,如果我们只使用字典来实现有序集合,那么虽然以O(1)复杂度查找成员的分值这一特性会被保留,但是,因为字典以无序的方式来保存集合元素,所以每次在执行范围型操作——比如ZRANK、ZRANGE等命令时,程序都需要对字典保存的所有元素进行排序,完成这种排序需要至少O(NlogN)时间复杂度,以及额外的O(N)内存空间(因为要创建一个数组来保存排序后的元素)。
- 另一方面,如果我们只使用跳跃表来实现有序集合,那么跳跃表执行范围型操作的所有优点都会被保留,但因为没有了字典,所以根据成员查找分值这一操作的复杂度将从O(1)上升为O(logN)。因为以上原因,为了让有序集合的查找和范围型操作都尽可能快地执行,Redis选择了同时使用字典和跳跃表两种数据结构来实现有序集合。
3.2 zset-skiplist
问skiplist。
Z-Set基于什么?介绍一下跳表?jdk中的跳表?
跳表怎么实现的?
- skiplist数据结构
skiplist作为zset的存储结构,整体存储结构如下图,核心点主要是包括一个dict对象和一个skiplist对象。dict保存key/value,key为元素,value为分值;skiplist保存的有序的元素列表,每个元素包括元素和分值。两种数据结构下的元素指向相同的位置。 - skiplist的源码格式
zset包括dict和zskiplist两个数据结构,其中dict的保存key/value,便于通过key(元素)获取score(分值)。zskiplist保存有序的元素列表,便于执行range之类的命令。
/** 有序集合*/typedef struct zset {// 字典,键为成员,值为分值// 用于支持 O(1) 复杂度的按成员取分值操作dict *dict;// 跳跃表,按分值排序成员// 用于支持平均复杂度为 O(log N) 的按分值定位成员操作// 以及范围操作zskiplist *zsl;} zset;
zskiplist作为skiplist的数据结构,包括指向头尾的header和tail指针,其中level保存的是skiplist的最大的层数。
/** 跳跃表*/typedef struct zskiplist {// 表头节点和表尾节点struct zskiplistNode *header, *tail;// 表中节点的数量unsigned long length;// 表中层数最大的节点的层数int level;} zskiplist;
skiplist跳跃列表中每个节点的数据格式,每个节点有保存数据的robj指针,分值score字段,后退指针backward便于回溯,zskiplistLevel的数组保存跳跃列表每层的指针。
/** 跳跃表节点*/typedef struct zskiplistNode {// 成员对象robj *obj;// 分值double score;// 后退指针struct zskiplistNode *backward;// 层struct zskiplistLevel {// 前进指针struct zskiplistNode *forward;// 跨度unsigned int span;} level[];} zskiplistNode;
- skiplist数据结构
3.3 应用
- 如何使用redis的Zset实现延时队列?
https://shirenchuang.blog.csdn.net/article/details/98864764
二、单机
3-持久化
- 相关配置(rky):
- RDB相关配置

- AOF相关配置

- RDB相关配置
1-原因
- redis中的数据会丢失吗?
会丢失,一般原因:
- 程序bug或人为误操作。
- 因客户端缓冲区内存使用过大,导致大量键被LRU淘汰。
- 主库故障后自动重启,可能导致数据丢失。
- 网络分区的问题,可能导致短时间的写入数据丢失。
- 主从复制数据不一致,发生故障切换后,出现数据丢失。
- 大量过期键,同时被淘汰清理。
https://blog.csdn.net/shangyuanlang/article/details/81297970
2-机制|RDB|AOF
RDB复制副本的时候,还会提供服务吗?如果此时有其他更改数据指令,快照会有什么变化?
redis持久化默认是哪一种? | 3
- Redis 默认的持久化方式是 RDB ,并且默认是打开的。
redis持久化有哪些方式/两种持久化机制? |3
- RDB持久化(Redis DataBase)
把当前进程数据生成快照保存到硬盘的过程。 - AOF(Append Only File)
将每一个收到的写命令都通过write函数追加到文件中。通俗就是日志记录。
- RDB持久化(Redis DataBase)
Redis的持久化原理? 解释一下RDB、AOF
- RDB原理

1)执行bgsave命令,Redis父进程判断当前是否存在正在执行的子进程,如RDB/AOF子进程,如果存在bgsave命令直接返回。
2)父进程执行fork操作创建子进程,fork操作过程中父进程会阻塞,通过info stats命令查看latest_fork_usec选项,可以获取最近一个fork操作的耗时,单位为微秒。
3)父进程fork完成后,bgsave命令返回“Background saving started”信息并不再阻塞父进程,可以继续响应其他命令。
4)子进程创建RDB文件,根据父进程内存生成临时快照文件,完成后对原有文件进行原子替换。执行lastsave命令可以获取最后一次生成RDB的时间,对应info统计的rdb_last_save_time选项。
5)进程发送信号给父进程表示完成,父进程更新统计信息,具体见info Persistence下的rdb_*相关选项。 - AOF原理
AOF的工作流程操作:命令写入(append)、文件同步(sync)、文件重写(rewrite)、重启加载(load)。

流程如下:
1)所有的写入命令会追加到aof_buf(缓冲区)中。
2)AOF缓冲区根据对应的策略向硬盘做同步操作。
3)随着AOF文件越来越大,需要定期对AOF文件进行重写,达到压缩的目的。
4)当Redis服务器重启时,可以加载AOF文件进行数据恢复。
- RDB原理
3-应用--
项目中用的哪一种redis持久化,默认是哪一种?
redis 持久化有哪几种方式,怎么选?
4-内存
基础知识点:
- 内存相关配置
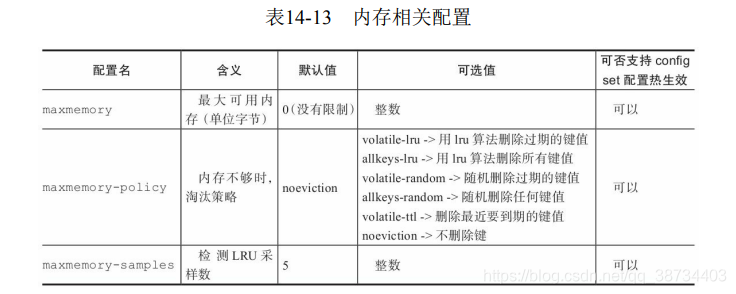
- Redis内存管理:
主要通过控制内存上限和回收策略实现;
1)Redis使用maxmemory参数限制最大可用内存。限制内存的目的主要有:
·用于缓存场景,当超出内存上限maxmemory时使用LRU等删除策略释放空间。
·防止所用内存超过服务器物理内存。
2)Redis的内存回收机制主要体现在以下两个方面:
·删除到达过期时间的键对象。
·内存使用达到maxmemory上限时触发内存溢出控制策略。
- 内存相关配置
redis缓存回收机制?
因为C语言并不具备自动内存回收功能,所以Redis在自己的对象系统中构建了一个引用计数(reference counting)技术实现的内存回收机制,通过这一机制,程序可以通过跟踪对象的引用计数信息,在适当的时候自动释放对象并进行内存回收。
每个对象的引用计数信息由redisObject结构的refcount属性记录:typedef struct redisObject {// ...// 引用计数int refcount;// ...} robj;
对象的引用计数信息会随着对象的使用状态而不断变化:
·在创建一个新对象时,引用计数的值会被初始化为1;
·当对象被一个新程序使用时,它的引用计数值会被增一;
·当对象不再被一个程序使用时,它的引用计数值会被减一;
·当对象的引用计数值变为0时,对象所占用的内存会被释放。生命周期
对象的整个生命周期可以划分为创建对象、操作对象、释放对象三个阶段。作为例子,以下代码展示了一个字符串对象从创建到释放的整个过程(其他不同类型的对象也会经历类似的过程):// 创建一个字符串对象s,对象的引用计数为1robj *s = createStringObject(...)//对象s执行各种操作...// 将对象s 的引用计数减一,使得对象的引用计数变为0// 导致对象s 被释放decrRefCount(s)
API
修改对象引用计数的API,这些API分别用于增加、减少、重置对象的引用计数。

什么是内存碎片,产生的原因?
- 内存分配器为了更好地管理和重复利用内存,分配内存策略一般采用固定范围的内存块进行分配。
-- 例如jemalloc在64位系统中将内存空间划分为:小、大、巨大三个范围。每个范围内又划分为多个小的内存块单位。比如当保存5KB对象时jemalloc可能会采用8KB的块存储,而剩下的3KB空间变为了内存碎片不能再分配给其他对象存储。是jemalloc针对碎片化问题专门做了优化,一般不会存在过度碎片化的问题; - 原因:以下场景容易出现高内存碎片问题:
-- 频繁做更新操作,例如频繁对已存在的键执行append、setrange等更新操作。
-- 大量过期键删除,键对象过期删除后,释放的空间无法得到充分利用,导致碎片率上升。 - 常见的解决:
1)数据对齐:在条件允许的情况下尽量做数据对齐,比如数据尽量采用数字类型或者固定长度字符串等,但是这要视具体的业务而定,有些场景无法做到。
2)安全重启:重启节点可以做到内存碎片重新整理,因此可以利用高可用架构,如Sentinel或Cluster,将碎片率过高的主节点转换为从节点,进行安全重启。
- 内存分配器为了更好地管理和重复利用内存,分配内存策略一般采用固定范围的内存块进行分配。
redis数据达到多少是阈值?
- Redis使用maxmemory参数限制最大可用内存。
- 注意:
maxmemory限制的是Redis实际使用的内存量,也就是used_memory统计项对应的内存。由于内存碎片率的存在,实际消耗的内存可能会比maxmemory设置的更大,实际使用时要小心这部分内存溢出。
redis最大内存设置了多少?
- 一般推荐Redis设置内存为最大物理内存的四分之三
http://linux.zhizuobiao.com/linux-19051400034/
- 一般推荐Redis设置内存为最大物理内存的四分之三
redis为什么要设置过期时间?
过期时间是怎么设置的?
- 通过EXPIRE key seconds命令来设置数据的过期时间
- Redis有四个不同的命令可以用于设置键的生存时间(键可以存在多久)或过期时间(键什么时候会被删除):
·EXPIRE命令用于将键key的生存时间设置为ttl秒。
·PEXPIRE命令用于将键key的生存时间设置为ttl毫秒。
·EXPIREAT命令用于将键key的过期时间设置为timestamp所指定的秒数时间戳。
·PEXPIREAT命令用于将键key的过期时间设置为timestamp所指定的毫秒数时间戳。 - 虽然有多种不同单位和不同形式的设置命令,但实际上EXPIRE、PEXPIRE、EXPIREAT三个命令都是使用PEXPIREAT命令来实现的:无论客户端执行的是以上四个命令中的哪一个,经过转换之后,最终的执行效果都和执行PEXPIREAT命令一样。
redis key 的过期键删除策略?
- Redis所有的键都可以设置过期属性,内部保存在过期字典中。由于进程内保存大量的键,维护每个键精准的过期删除机制会导致消耗大量的CPU,对于单线程的Redis来说成本过高,实现过期键的内存回收。
- 三种不同的删除策略:
·定时删除:在设置键的过期时间的同时,创建一个定时器(timer),让定时器在键的过期时间来临时,立即执行对键的删除操作。
·惰性删除:放任键过期不管,但是每次从键空间中获取键时,都检查取得的键是否过期,如果过期的话,就删除该键;如果没有过期,就返回该键。
·定期删除:每隔一段时间,程序就对数据库进行一次检查,删除里面的过期键。至于要删除多少过期键,以及要检查多少个数据库,则由算法决定。 - 在这三种策略中,第一种和第三种为主动删除策略,而第二种则为被动删除策略。
定期删除怎么实现的,是开启一个新进程还是停止工作去删除?
- 定期删除策略的实现
过期键的定期删除策略由redis.c/activeExpireCycle函数实现,每当Redis的服务器周期性操作redis.c/serverCron函数执行时,activeExpireCycle函数就会被调用,它在规定的时间内,分多次遍历服务器中的各个数据库,从数据库的expires字典中随机检查一部分键的过期时间,并删除其中的过期键。 整个过程可以用伪代码描述如下:
# 默认每次检查的数据库数量DEFAULT_DB_NUMBERS = 16# 默认每个数据库检查的键数量DEFAULT_KEY_NUMBERS = 20# 全局变量,记录检查进度current_db = 0def activeExpireCycle():# 初始化要检查的数据库数量# 如果服务器的数据库数量比DEFAULT_DB_NUMBERS要小,那么以服务器的数据库数量为准if server.dbnum < DEFAULT_DB_NUMBERS:db_numbers = server.dbnumelse:db_numbers = DEFAULT_DB_NUMBERS# 遍历各个数据库for i in range(db_numbers):# 如果current_db的值等于服务器的数据库数量,这表示检查程序已经遍历了服务器的所有数据库一次# 将current_db重置为0,开始新的一轮遍历if current_db == server.dbnum:current_db = 0# 获取当前要处理的数据库redisDb = server.db[current_db]# 将数据库索引增1,指向下一个要处理的数据库current_db += 1# 检查数据库键for j in range(DEFAULT_KEY_NUMBERS):# 如果数据库中没有一个键带有过期时间,那么跳过这个数据库if redisDb.expires.size() == 0: break# 随机获取一个带有过期时间的键key_with_ttl = redisDb.expires.get_random_key()# 检查键是否过期,如果过期就删除它if is_expired(key_with_ttl):delete_key(key_with_ttl)# 已达到时间上限,停止处理if reach_time_limit(): return
activeExpireCycle函数的工作模式可以总结如下:
· 函数每次运行时,都从一定数量的数据库中取出一定数量的随机键进行检查,并删除其中的过期键。
· 全局变量current_db会记录当前activeExpireCycle函数检查的进度,并在下一次activeExpireCycle函数调用时,接着上一次的进度进行处理。比如说,如果当前activeExpireCycle函数在遍历10号数据库时返回了,那么下次activeExpireCycle函数执行时,将从11号数据库开始查找并删除过期键。
· 随着activeExpireCycle函数的不断执行,服务器中的所有数据库都会被检查一遍,这时函数将current_db变量重置为0,然后再次开始新一轮的检查工作。
- 定期删除策略的实现
redis内存满了会怎么样
- 当Redis所用内存达到maxmemory上限时会触发相应的溢出控制策略/淘汰策略。具体策略受maxmemory-policy参数控制,Redis支持6种策略;默认值noeviction。
redis使用哪种淘汰策略?
- noeviction
Redis缓存(内存)淘汰策略 |2
- Redis的内存淘汰策略是指在Redis的用于缓存的内存不足时,怎么处理需要新写入且需要申请额外空间的数据。
1)全局的键空间选择性移除
noeviction:当内存不足以容纳新写入数据时,新写入操作会报错。
allkeys-lru:当内存不足以容纳新写入数据时,在键空间中,移除最近最少使用的key。(这个是最常用的)
allkeys-random:当内存不足以容纳新写入数据时,在键空间中,随机移除某个key。
2)设置过期时间的键空间选择性移除
volatile-lru:当内存不足以容纳新写入数据时,在设置了过期时间的键空间中,移除最近最少使用的key。
volatile-random:当内存不足以容纳新写入数据时,在设置了过期时间的键空间中,随机移除某个key。
volatile-ttl:当内存不足以容纳新写入数据时,在设置了过期时间的键空间中,有更早过期时间的key优先移除。 - 总结
Redis的内存淘汰策略的选取并不会影响过期的key的处理。内存淘汰策略用于处理内存不足时的需要申请额外空间的数据;过期策略用于处理过期的缓存数据。
规则名称 规则说明 volatile-lru 使用LRU算法删除一个键(只对设置了生存时间的键) allkeys-lru 使用LRU算法删除一个键 volatile-random 随机删除一个键(只对设置了生存时间的键) allkeys-random 随机删除一个键 volatile-ttl 删除生存时间最近的一个键 noeviction 不删除键,只返回错误 - LRU算法,least RecentlyUsed,最近最少使用算法。
- Redis的内存淘汰策略是指在Redis的用于缓存的内存不足时,怎么处理需要新写入且需要申请额外空间的数据。
Java语言,实现一下LRU缓存?
redis中lru咋实现的?
- 实现思路:首先实现一个双向链表,每次有一个key被访问之后,就把被访问的key放到链表的头部。当缓存不够时,直接从尾部逐个摘除。
- redis中LRU的思路:即如果一个key经常被访问,那么该key的idle time应该是最小的
- lfu的思路:如果能够记录一个key被访问的次数,那么经常被访问的key最有可能再次被访问到。
https://segmentfault.com/a/1190000017555834
5-客户端
- Redis删除一个记录怎么实现的
1)启动
- redis-cli:连接本地的 redis 服务
- PING:用于检测 redis 服务是否启动
2)创建(string) - SET runoobkey redis:SET key value 设置指定 key 的值
3)删除 - DEL runoobkey:键被删除成功,命令执行后输出 (integer) 1,否则将输出 (integer) 0
三、多机
13.有没有了解过伪缓存(这是什么鬼😑)
项目中用redis限流,是如何做到的
准备同步
String;业务监控的周期监控,会查找最近时间段缓存记录,避免从头开始监控查表;然后说说特性,说说为什么那么快~~
3.1 复制
基础知识:
- 只读:
默认情况下,从节点使用slave-read-only=yes配置为只读模式。由于复制只能从主节点到从节点,对于从节点的任何修改主节点都无法感知,修改从节点会造成主从数据不一致。 - 拓扑结构:
Redis的复制拓扑结构可以支持单层或多层复制关系,由拓扑复杂性
分为3种:一主一从、一主多从(可以实现读写分离)、树状主从结构。 - 复制过程
1)开始:在从节点执行slaveof命令后,复制过程便开始运作。
2)复制过程大致分为6个过程:
① 保存主节点(master)信息。
执行slaveof后从节点只保存主节点的地址信息便直接返回,这时建立复制流程还没有开始;主节点的ip和port被保存下来,但是主节点的连接状态(master_link_status)是下线状态。
② 从节点(slave)内部通过每秒运行的定时任务维护复制相关逻辑,当定时任务发现存在新的主节点后,会尝试与该节点建立网络连接。
从节点会建立一个socket套接字,专门用于接受主节点发送的复制命令。
如果从节点无法建立连接,定时任务会无限重试直到连接成功或者执行slaveof no one取消复制;
③ 发送ping命令。
连接建立成功后从节点发送ping请求进行首次通信,ping请求主要目的如下:
·检测主从之间网络套接字是否可用。
·检测主节点当前是否可接受处理命令。
如果发送ping命令后,从节点没有收到主节点的pong回复或者超时,比如网络超时或者主节点正在阻塞无法响应命令,从节点会断开复制连接,下次定时任务会发起重连;
④ 权限验证。
如果主节点设置了requirepass参数,则需要密码验证,从节点必须配置masterauth参数保证与主节点相同的密码才能通过验证;如果验证失败复制将终止,从节点重新发起复制流程。
⑤ 同步数据集。
主从复制连接正常通信后,对于首次建立复制的场景,主节点会把持有的数据全部发送给从节点,这部分操作是耗时最长的步;
⑥ 命令持续复制。
当主节点把当前的数据同步给从节点后,便完成了复制的建立流程。接下来主节点会持续地把写命令发送给从节点,保证主从数据一致性。 - 数据同步
➽ psync命令运行需要以下组件支持?
·主从节点各自复制偏移量。
·主节点复制积压缓冲区。
·主节点运行id。
➽ 复制偏移量?
► 参与复制的主从节点都会维护自身复制偏移量。
► 主节点(master)在处理完写入命令后,会把命令的字节长度做累加记录;
► 从节点(slave)每秒钟上报自身的复制偏移量给主节点,因此主节点也会保存从节点的复制偏移量;
► 从节点在接收到主节点发送的命令后,也会累加记录自身的偏移量。
► 通过对比主从节点的复制偏移量,可以判断主从节点数据是否一致。
► 问题分析:
通过主节点的统计信息,计算出master_repl_offset-slave_offset字节量,判断主从节点复制相差的数据量,根据这个差值判定当前复制的健康度。如果主从之间复制偏移量相差较大,则可能是网络延迟或命令阻塞等原因引起。
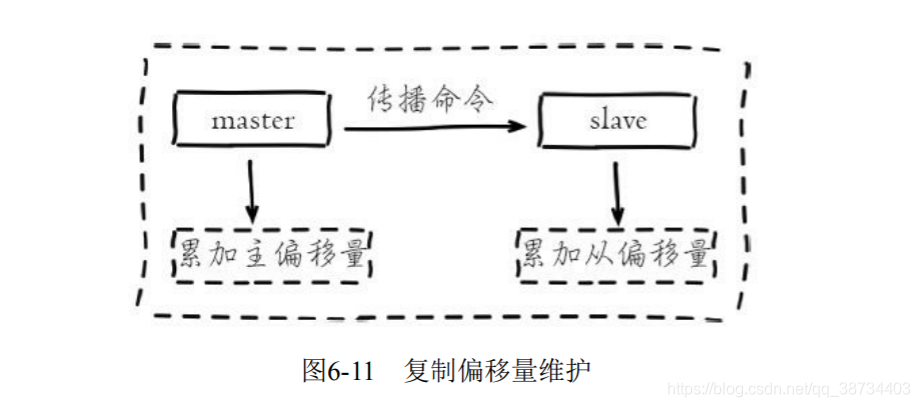
➽ 复制积压缓冲区?
► 复制积压缓冲区是保存在主节点上的一个固定长度的队列,默认大小为1MB,当主节点有连接的从节点(slave)时被创建,这时主节点(master)响应写命令时,不但会把命令发送给从节点,还会写入复制积压缓冲区;
► 由于缓冲区本质上是先进先出的定长队列,所以能实现保存最近已复制数据的功能,用于部分复制和复制命令丢失的数据补救。
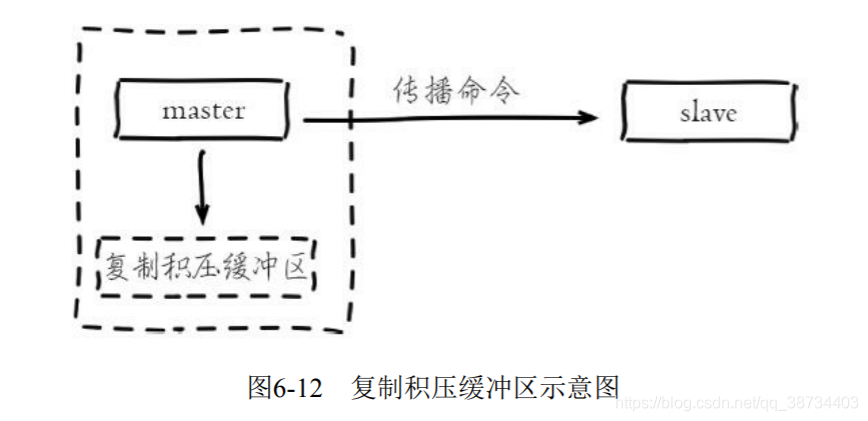
➽ 主节点运行ID?
► 每个Redis节点启动后都会动态分配一个40位的十六进制字符串作为运行ID。
► 运行ID的主要作用是用来唯一识别Redis节点,比如从节点保存主节点的运行ID识别自己正在复制的是哪个主节点。
► 如果只使用ip+port的方式识别主节点,那么主节点重启变更了整体数据集(如替换RDB/AOF文件),从节点再基于偏移量复制数据将是不安全的,因此当运行ID变化后从节点将做全量复制。
► 可以运行info server命令查看当前节点的运行ID;
► 需要注意的是Redis关闭再启动后,运行ID会随之改变;
➽ 如何在不改变运行ID的情况下重启呢?
► 当需要调优一些内存相关配置,例如:hash-max-ziplist-value等,这些配置需要Redis重新加载才能优化已存在的数据,这时可以使用debug reload命令重新加载RDB并保持运行ID不变,从而有效避免不必要的全量复制。
► debug reload命令会阻塞当前Redis节点主线程,阻塞期间会生成本地RDB快照并清空数据之后再加载RDB文件。因此对于大数据量的主节点和无法容忍阻塞的应用场景,谨慎使用。
➽ psync命令?
从节点使用psync命令完成部分复制和全量复制功能,命令格式:psync{runId}{offset},参数含义如下:
·runId:从节点所复制主节点的运行id。
·offset:当前从节点已复制的数据偏移量。
➽ psync命令运行流程?

流程说明:
1)从节点(slave)发送psync命令给主节点,参数runId是当前从节点保存的主节点运行ID,如果没有则默认值为,参数offset是当前从节点保存的复制偏移量,如果是第一次参与复制则默认值为-1。
2)主节点(master)根据psync参数和自身数据情况决定响应结果:
·如果回复+FULLRESYNC{runId}{offset},那么从节点将触发全量复制流程。
·如果回复+CONTINUE,从节点将触发部分复制流程。
·如果回复+ERR,说明主节点版本低于Redis2.8,无法识别psync命令,从节点将发送旧版的sync命令触发全量复制流程。 - 作用:
Redis的主从复制模式可以将主节点的数据改变同步给从节点,这样从节点就可以起到两个作用:
第一,作为主节点的一个备份,一旦主节点出了故障不可达的情况,从节点可以作为后备“顶”上来,并且保证数据尽量不丢失(主从复制是最终一致性)。
第二,从节点可以扩展主节点的读能力,一旦主节点不能支撑住大并发量的读操作,从节点可以在一定程度上帮助主节点分担读压力。
- 只读:
redis同步机制?
全量复制和部分复制redis主从同步是怎样的过程?
Redis在2.8及以上版本使用psync命令完成主从数据同步,同步过程分为:全量复制和部分复制。全量复制? (rky)
- 触发全量复制的命令是sync(redis<2.8)和psync(redis>2.8);
- 此处psync全量复制流程,与2.8以前的sync全量复制机制基本一致。
- 流程说明:

1)发送psync命令进行数据同步,由于是第一次进行复制,从节点没有复制偏移量和主节点的运行ID,所以发送psync-1。
2)主节点根据psync-1解析出当前为全量复制,回复+FULLRESYNC响应。
3)从节点接收主节点的响应数据保存运行ID和偏移量offset。
4)主节点执行bgsave保存RDB文件到本地。
5)主节点发送RDB文件给从节点,从节点把接收的RDB文件保存在本地并直接作为从节点的数据文件。
▍超时问题:数据量较大的主节点,比如生成的RDB文件较大,超时后从节点将放弃接受RDB文件并清理已经下载的临时文件,导致全量复制失败。
-> 调大repl-timeout参数防止出现全量同步数据超时。
6)对于从节点开始接收RDB快照到接收完成期间,主节点仍然响应读写命令,因此主节点会把这期间写命令数据保存在复制客户端缓冲区内,当从节点加载完RDB文件后,主节点再把缓冲区内的数据发送给从节点,保证主从之间数据一致性。
▍主节点创建和传输RDB的时间过长,对于高流量写入场景非常容易造成主节点复制客户端缓冲区溢出。
-)对于主节点,当发送完所有的数据后就认为全量复制完成,但是对于从节点全量复制依然没有完成,还有后续步骤需要处理。
7)从节点接收完主节点传送来的全部数据后会清空自身旧数据。
8)从节点清空数据后开始加载RDB文件,对于较大的RDB文件,这一步操作依然比较耗时。
▍读写分离的场景,从节点也负责响应读命令。如果此时从节点正出于全量复制阶段或者复制中断,那么从节点在响应读命令可能拿到过期或错误的数据。对于这种场景,Redis复制提供了slave-serve-stale-data参数,默认开启状态。如果开启则从节点依然响应所有命令,对于无法容忍不一致的应用场景可以设置no来关闭命令执行。
9)从节点成功加载完RDB后,如果当前节点开启了AOF持久化功能,它会立刻做bgrewriteaof操作,为了保证全量复制后AOF持久化文件立刻可用。 - 显然,全量复制的开销弊端。时间开销主要包括:
·主节点bgsave时间。
·RDB文件网络传输时间。
·从节点清空数据时间。
·从节点加载RDB的时间。
·可能的AOF重写时间。
当数据量达到一定规模之后,由于全量复制过程中将进行多次持久化相关操作和网络数据传输,这期间会大量消耗主从节点所在服务器的CPU、内存和网络资源。
部分复制?
- 部分复制主要是Redis针对全量复制的过高开销做出的一种优化措施,
- 使用psync{runId}{offset}命令实现。
- 当从节点(slave)正在复制主节点(master)时,如果出现网络闪断或者命令丢失等异常情况时,从节点会向主节点要求补发丢失的命令数据,如果主节点的复制积压缓冲区内存在这部分数据则直接发送给从节点,这样就可以保持主从节点复制的一致性。
- 补发的这部分数据一般远远小于全量数据,所以开销很小。
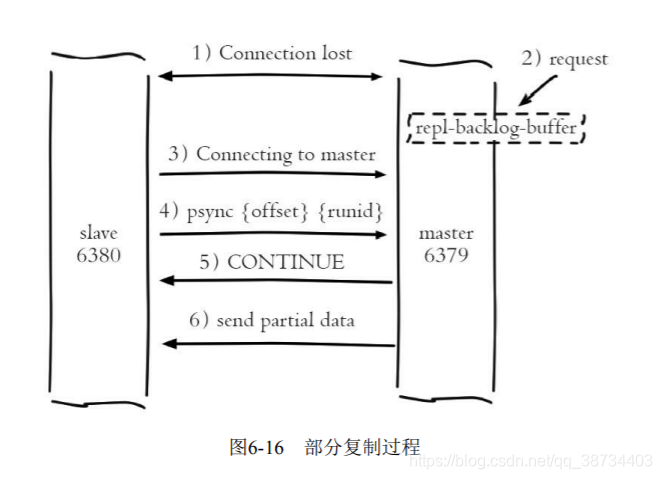
- 流程说明:
1)当主从节点之间网络出现中断时,如果超过repl-timeout(RDB文件从创建到传输完毕消耗的总时间)时间,主节点会认为从节点故障并中断复制连接;
2)主从连接中断期间主节点依然响应命令,但因复制连接中断命令无法发送给从节点,不过主节点内部存在的复制积压缓冲区,依然可以保存最近一段时间的写命令数据,默认最大缓存1MB。
3)当主从节点网络恢复后,从节点会再次连上主节点;
4)当主从连接恢复后,由于从节点之前保存了自身已复制的偏移量和主节点的运行ID。因此会把它们当作psync参数发送给主节点,要求进行部分复制操作
5)主节点接到psync命令后首先核对参数runId是否与自身一致,如果一致,说明之前复制的是当前主节点;之后根据参数offset在自身复制积压缓冲区查找,如果偏移量之后的数据存在缓冲区中,则对从节点发送+CONTINUE响应,表示可以进行部分复制。
6)主节点根据偏移量把复制积压缓冲区里的数据发送给从节点,保证主从复制进入正常状态;发送的数据量可以在主节点的日志获取;
开发与运维中的问题?
- 基于复制的应用场景。
通过复制机制,数据集可以存在多个副本(从节点)。这些副本可以应用于读写分离、故障转移(failover)、实时备份等场景。 - 应用中的一些问题:
1)读写分离
对于读占比较高的场景,可以通过把一部分读流量分摊到从节点(slave)来减轻主节点(master)压力,同时需要注意永远只对主节点执行写操作当使用从节点响应读请求时,业务端可能会遇到如下问题:
·复制数据延迟。
·读到过期数据。
·从节点故障。
2)主从配置不一致
3)规避全量复制
- 基于复制的应用场景。
3.2 哨兵
Sentinel的基本知识点:
- 名词:

- 名词:
redis高可用是怎么保证的? /redis如何实现高可用? |5
(哨兵、持久化策略RDB、AOF)- 高可用(High Availability),是当一台服务器停止服务后,对于业务及用户毫无影响。
- Redis的高可用策略(主从&哨兵架构)
- 主从方式、主从拓扑、哨兵机制
https://www.jianshu.com/p/c2abf726acc7
解释一下哨兵?
- 1)主从复制的问题:
① 一旦主节点出现故障,需要手动将一个从节点晋升为主节点,同时需要修改应用方的主节点地址,还需要命令其他从节点去复制新的主节点,整个过程都需要人工干预。
② 主节点的写能力受到单机的限制。
③ 主节点的存储能力受到单机的限制。 - 2)解决:
-- 问题①,就是Redis的高可用问题,Redis从2.8开始正式提供了Redis Sentinel(哨兵)架构来解决这个问题;
-- 问题②、③属于Redis的分布式问题,在集群中介绍; - 3)高可用
-- 概念:
当主节点出现故障时,Redis Sentinel能自动完成故障发现和故障转移,并通知应用方,从而实现真正的高可用。
-- 方案:
Redis Sentinel是一个分布式架构,其中包含若干个Sentinel节点和Redis数据节点,每个Sentinel节点会对数据节点和其余Sentinel节点进行监控,当它发现节点不可达时,会对节点做下线标识。如果被标识的是主节点,它还会和其他Sentinel节点进行“协商”,当大多数Sentinel节点都认为主节点不可达时,它们会选举出一个Sentinel节点来完成自动故障转移的工作,同时会将这个变化实时通知给Redis应用方。整个过程完全是自动的,不需要人工来介入,所以这套方案很有效地解决了Redis的高可用问题。 - 区别:
Redis Sentinel与Redis主从复制模式只是多了若干Sentinel节点,所以Redis Sentinel并没有针对Redis节点做了特殊处理;从逻辑架构上看,Sentinel节点集合会定期对所有节点进行监控,特别是对主节点的故障实现自动转移。

- 下面以1个主节点、2个从节点、3个Sentinel节点组成的Redis Sentinel为例子进行说明,拓扑结构如下。

- 整个故障转移的处理逻辑有下面4个步骤:
1)如图,主节点出现故障,此时两个从节点与主节点失去连接,主从复制失败。

2)如图,每个Sentinel节点通过定期监控发现主节点出现了故障。

3)如图,多个Sentinel节点对主节点的故障达成一致,选举出sentinel-3节点作为领导者负责故障转移。

4)如图,Sentinel领导者节点执行了故障转移,整个过程自动化完成的。

5)故障转移后整个Redis Sentinel的拓扑结构如图所示。

- 功能:
通过上面介绍的Redis Sentinel逻辑架构以及故障转移的处理,可以看出Redis Sentinel具有以下几个功能:
1)监控:Sentinel节点会定期检测Redis数据节点、其余Sentinel节点是否可达。
2)通知:Sentinel节点会将故障转移的结果通知给应用方。
3)主节点故障转移:实现从节点晋升为主节点并维护后续正确的主从关系。
4)配置提供者:在Redis Sentinel结构中,客户端在初始化的时候连接的是Sentinel节点集合,从中获取主节点信息。 - 好处:
同时看到,Redis Sentinel包含了若个Sentinel节点,这样做也带来了两个好处:
1)对于节点的故障判断是由多个Sentinel节点共同完成,这样可以有效地防止误判。
2)Sentinel节点集合是由若干个Sentinel节点组成的,这样即使个别Sentinel节点不可用,整个Sentinel节点集合依然是健壮的。
但是Sentinel节点本身就是独立的Redis节点,只不过它们有一些特殊,它们不存储数据,只支持部分命令。 - 实现原理
详见总结
- 1)主从复制的问题:
sentinel适用场景-读写分离?
- 很多从节点或者确实需要读写分离的场景,如何实现从节点的高可用是非常有必要的。
- Redis Sentinel读写分离设计思路
-- Redis Sentinel在对各个节点的监控中,如果有对应事件的发生,都会发出相应的事件消息,其中和从节点变动的事件有以下几个:
·+switch-master:切换主节点(原来的从节点晋升为主节点),说明减少了某个从节点。
·+convert-to-slave:切换从节点(原来的主节点降级为从节点),说明添加了某个从节点。
·+sdown:主观下线,说明可能某个从节点可能不可用(因为对从节点不会做客观下线),所以在实现客户端时可以采用自身策略来实现类似主观下线的功能。
·+reboot:重新启动了某个节点,如果它的角色是slave,那么说明添加了某个从节点。 - 所以在设计Redis Sentinel的从节点高可用时,只要能够实时掌握所有从节点的状态,把所有从节点看做一个资源池,无论是上线还是下线从节点,客户端都能及时感知到(将其从资源池中添加或者删除),这样从节点的高可用目标就达到了。

Redisson的看门狗机制?
3.3 集群
基础知识点:
- Redis Cluster是Redis的分布式解决方案,在3.0版本正式推出,有效地解决了Redis分布式方面的需求。当遇到单机内存、并发、流量等瓶颈时,可以采用Cluster架构方案达到负载均衡的目的。
分布式缓存读写不一致问题
一致性Hash算法,及其应用。
hash和一致性hash的区别,为什么要用一致性hash
说说redis集群?。
1)至少部署两台Redis服务器构成一个小的集群,主要有2个目的:- 高可用性:在主机挂掉后,自动故障转移,使前端服务对用户无影响。
- 读写分离:将主机读压力分流到从机上。
2)Redis有三种集群模式,分别是: - 主从模式、Sentinel模式、Cluster模式
https://blog.csdn.net/miss1181248983/article/details/90056960
redis cluster集群同步过程?
3.4 总结
数据一致
- 复制功能对过期键的处理:
-- 当服务器运行在复制模式下时,从服务器的过期键删除动作由主服务器控制:
·主服务器在删除一个过期键之后,会显式地向所有从服务器发送一个DEL命令,告知从服务器删除这个过期键。
·从服务器在执行客户端发送的读命令时,即使碰到过期键也不会将过期键删除,而是继续像处理未过期的键一样来处理过期键。
·从服务器只有在接到主服务器发来的DEL命令之后,才会删除过期键。
-- 通过由主服务器来控制从服务器统一地删除过期键,可以保证主从服务器数据的一致性,也正是因为这个原因,当一个过期键仍然存在于主服务器的数据库时,这个过期键在从服务器里的复制品也会继续存在。
- 复制功能对过期键的处理:
主从一致性?
大概答了在哨兵中RDB和AOF是怎么配合使用来保证主从一致
几个方面
从刚启动
主从同步
主掉线切换项目里redis怎么保持一致性?
Redis一致性如何处理。(讲了主从,集群,哈希槽等)
sentinel和cluster区别和各自适用场景?
四、独立功能
4.0 事件
Redis如何实现单线程IO多路复用?
- 1)文件事件处理器:
-- Redis基于Reactor模式开发了自己的网络事件处理器:这个处理器被称为文件事件处理器(file event handler):
-- 虽然文件事件处理器以单线程方式运行,但通过使用I/O多路复用程序来监听多个套接字,文件事件处理器既实现了高性能的网络通信模型,又可以很好地与Redis服务器中其他同样以单线程方式运行的模块进行对接,这保持了Redis内部单线程设计的简单性。 - 2)文件事件处理器的构成
文件事件处理器的四个组成部分,它们分别是套接字、I/O多路复用程序、文件事件分派器(dispatcher),以及事件处理器。

-- 文件事件是对套接字操作的抽象,每当一个套接字准备好执行连接应答(accept)、写入、读取、关闭等操作时,就会产生一个文件事件。因为一个服务器通常会连接多个套接字,所以多个文件事件有可能会并发地出现。
-- I/O多路复用程序负责监听多个套接字,并向文件事件分派器传送那些产生了事件的套接字。
-- 尽管多个文件事件可能会并发地出现,但I/O多路复用程序总是会将所有产生事件的套接字都放到一个队列里面,然后通过这个队列,以有序(sequentially)、同步(synchronously)、每次一个套接字的方式向文件事件分派器传送套接字。当上一个套接字产生的事件被处理完毕之后(该套接字为事件所关联的事件处理器执行完毕),I/O多路复用程序才会继续向文件事件分派器传送下一个套接字,如图。

-- 文件事件分派器接收I/O多路复用程序传来的套接字,并根据套接字产生的事件的类型,调用相应的事件处理器。
-- 服务器会为执行不同任务的套接字关联不同的事件处理器,这些处理器是一个个函数,它们定义了某个事件发生时,服务器应该执行的动作。 - 3)I/O多路复用程序的实现
-- Redis的I/O多路复用程序的所有功能都是通过包装常见的select、epoll、evport和kqueue这些I/O多路复用函数库来实现的,每个I/O多路复用函数库在Redis源码中都对应一个单独的文件,比如ae_select.c、ae_epoll.c、ae_kqueue.c,诸如此类。
-- 因为Redis为每个I/O多路复用函数库都实现了相同的API,所以I/O多路复用程序的底层实现是可以互换的;
-- Redis在I/O多路复用程序的实现源码中用#include宏定义了相应的规则,程序会在编译时自动选择系统中性能最高的I/O多路复用函数库来作为Redis的I/O多路复用程序的底层实现:
/* Include the best multiplexing layer supported by this system.* The following should be ordered by performances, descending. */# ifdef HAVE_EVPORT# include "ae_evport.c"# else# ifdef HAVE_EPOLL# include "ae_epoll.c"# else# ifdef HAVE_KQUEUE# include "ae_kqueue.c"# else# include "ae_select.c"# endif# endif# endif
- 1)文件事件处理器:
4.1 发布与订阅
4.2 事务
setnx是事务吗?
答了不是(不知道对不对),然后又说了一下Redis本身自带的事务(部分事务,非原子性)分布式事务?
说一下分布式事务吗?
不太了解,所以大概答了思路:通过事务实现Mysql和Redis的同步修改,异常回滚啥的
lua脚本
bitmap
Bitmap介绍一下?
因为说到 bitmap,问了一下布隆过滤器如何实现
布隆过滤器的实现。
9. 缓存
- 讲讲redis缓存?
- 缓存能够有效地加速应用的读写速度,同时也可以降低后端负载。
- 缓存的收益和成本?
-- 左侧为客户端直接调用存储层的架构,右侧为比较典型的缓存层+存储层架构;

-- 收益:
① 加速读写:因为缓存通常都是全内存的(例如Redis、Memcache),而存储层通常读写性能不够强悍(例如MySQL),通过缓存的使用可以有效地加速读写,优化用户体验。
② 降低后端负载:帮助后端减少访问量和复杂计算(例如很复杂的SQL语句),在很大程度降低了后端的负载。
-- 成本:
① 数据不一致性:缓存层和存储层的数据存在着一定时间窗口的不一致性,时间窗口跟更新策略有关。
② 代码维护成本:加入缓存后,需要同时处理缓存层和存储层的逻辑,增大了开发者维护代码的成本。
③ 运维成本:以Redis Cluster为例,加入后无形中增加了运维成本。 - 缓存的使用场景基本包含如下两种?:
① 开销大的复杂计算:以MySQL为例子,一些复杂的操作或者计算(例如大量联表操作、一些分组计算),如果不加缓存,不但无法满足高并发量,同时也会给MySQL带来巨大的负担。
② 加速请求响应:即使查询单条后端数据足够快(例如select*from table where id=),那么依然可以使用缓存,以Redis为例子,每秒可以完成数万次读写,并且提供的批量操作可以优化整个IO链的响应时间。 - 缓存的缓存更新策略的选择和使用场景?
-- 缓存中的数据通常都是有生命周期的,需要在指定时间后被删除或更新,以保证缓存空间在一个可控的范围。
1)LRU/LFU/FIFO算法剔除
► 使用场景:用于缓存使用量超过了预设的最大值时候,如何对现有的数据进行剔除。例如Redis使用maxmemory-policy这个配置作为内存最大值后对于数据的剔除策略。
► 一致性:要清理哪些数据是由具体算法决定,开发人员只能决定使用哪种算法,所以数据的一致性是最差的。
► 维护成本:算法不需要开发人员自己来实现,通常只需要配置最大maxmemory和对应的策略即可。开发人员只需要知道每种算法的含义,选择适合自己的算法即可。
2)超时剔除
► 使用场景:超时剔除通过给缓存数据设置过期时间,让其在过期时间后自动删除,例如Redis提供的expire命令。如果业务可以容忍一段时间内,缓存层数据和存储层数据不一致,那么可以为其设置过期时间。在数据过期后,再从真实数据源获取数据,重新放到缓存并设置过期时间。例如一个视频的描述信息,可以容忍几分钟内数据不一致,但是涉及交易方面的业务,后果可想而知。
► 一致性:一段时间窗口内(取决于过期时间长短)存在一致性问题,即缓存数据和真实数据源的数据不一致。
► 维护成本:维护成本不是很高,只需设置expire过期时间即可,当然前提是应用方允许这段时间可能发生的数据不一致。
3)主动更新
► 使用场景:应用方对于数据的一致性要求高,需要在真实数据更新后,立即更新缓存数据。例如可以利用消息系统或者其他方式通知缓存更新。
► 一致性:一致性最高,但如果主动更新发生了问题,那么这条数据很可能很长时间不会更新,所以建议结合超时剔除一起使用效果会更好。
► 维护成本:维护成本会比较高,开发者需要自己来完成更新,并保证更新操作的正确性。
-- 应用建议
► 低一致性业务建议配置最大内存和淘汰策略的方式使用。
► 高一致性业务可以结合使用超时剔除和主动更新,这样即使主动更新出了问题,也能保证数据过期时间后删除脏数据。

- 缓存粒度控制方法。
-- 缓存全部数据和部分数据;

- 穿透问题优化。
- 无底洞问题优化。
- 雪崩问题优化。
- 热点key重建优化。
1-穿透|击穿|雪崩
|aobing|
redis的缓存穿透、缓存击穿、缓存雪崩原因现象和解决措施? |3
redis缓存穿透与解决措施? |3 (rky
- 是什么?
指查询一个根本不存在的数据,缓存层和存储层都不会命中,通常出于容错的考虑,如果从存储层查不到数据则不写入缓存层,如图整个过程分为如下3步:
1)缓存层不命中。
2)存储层不命中,不将空结果写回缓存。
3)返回空结果。
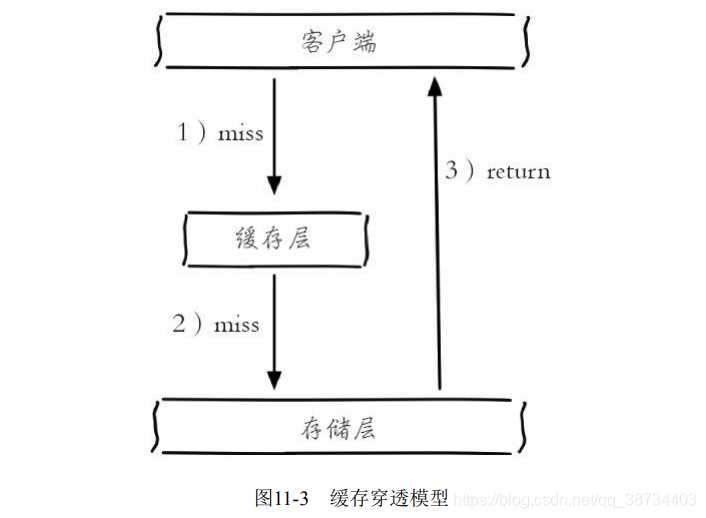
- 后果:
► 导致不存在的数据每次请求都要到存储层去查询,失去了缓存保护后端存储的意义。
► 缓存穿透问题可能会使后端存储负载加大,由于很多后端存储不具备高并发性,甚至可能造成后端存储宕掉。通常可以在程序中分别统计总调用数、缓存层命中数、存储层命中数,如果发现大量存储层空命中,可能就是出现了缓存穿透问题。 - 基本原因有两个:
► 第一,自身业务代码或者数据出现问题;
► 第二,一些恶意攻击、爬虫等造成大量空命中。 - 解决缓存穿透问题:
1)缓存空对象
如图,当第2步存储层不命中后,仍然将空对象保留到缓存层中,之后再访问这个数据将会从缓存中获取,这样就保护了后端数据源。

▷ 缓存空对象会有两个问题:
① 空值做了缓存,意味着缓存层中存了更多的键,需要更多的内存空间(如果是攻击,问题更严重),比较有效的方法是针对这类数据设置一个较短的过期时间,让其自动剔除。
② 缓存层和存储层的数据会有一段时间窗口的不一致,可能会对业务有一定影响。
例如过期时间设置为5分钟,如果此时存储层添加了这个数据,那此段时间就会出现缓存层和存储层数据的不一致,此时可以利用消息系统或者其他方式清除掉缓存层中的空对象。
▷ 缓存空对象的实现代码:
String get(String key) {// 从缓存中获取数据String cacheValue = cache.get(key);// 缓存为空if (StringUtils.isBlank(cacheValue)) {// 从存储中获取String storageValue = storage.get(key);cache.set(key, storageValue);// 如果存储数据为空,需要设置一个过期时间(300秒)if (storageValue == null) {cache.expire(key, 60 * 5);}return storageValue;} else {// 缓存非空return cacheValue;}}
2)布隆过滤器拦截
► 如图,在访问缓存层和存储层之前,将存在的key用布隆过滤器提前保存起来,做第一层拦截。

► 场景:
例如:一个推荐系统有4亿个用户id,每个小时算法工程师会根据每个用户之前历史行为计算出推荐数据放到存储层中,但是最新的用户由于没有历史行为,就会发生缓存穿透的行为,为此可以将所有推荐数据的用户做成布隆过滤器。如果布隆过滤器认为该用户id不存在,那么就不会访问存储层,在一定程度保护了存储层。
► 实现:
有关布隆过滤器的相关知识,可以参考:https://en.wikipedia.org/wiki/Bloom_filter可以利用Redis的Bitmaps实现布隆过滤器,GitHub上已经开源了类似的方案,读者可以进行参考:https://github.com/erikdubbelboer/redis-lua-scaling-bloom-filter。
► 应用场景:
适用于数据命中不高、数据相对固定、实时性低(通常是数据集较大)的应用场景,代码维护较为复杂,但是缓存空间占用少。
► 两种解决方法的对比(实际上这个问题是一个开放问题,有很多解决方法)
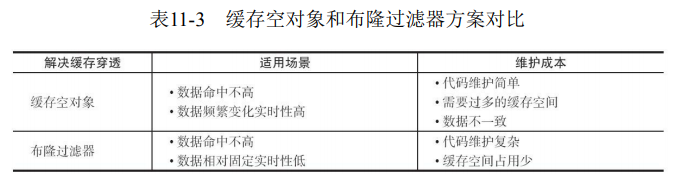
- 是什么?
redis缓存雪崩与解决措施? |3 (rky
- 是什么?
由于缓存层承载着大量请求,有效地保护了存储层,但是如果缓存层由于某些原因不能提供服务,于是所有的请求都会达到存储层,存储层的调用量会暴增,造成存储层也会级联宕机的情况。缓存雪崩的英文原意是stampeding herd(奔逃的野牛),指的是缓存层宕掉后,流量会像奔逃的野牛一样,打向后端存储。
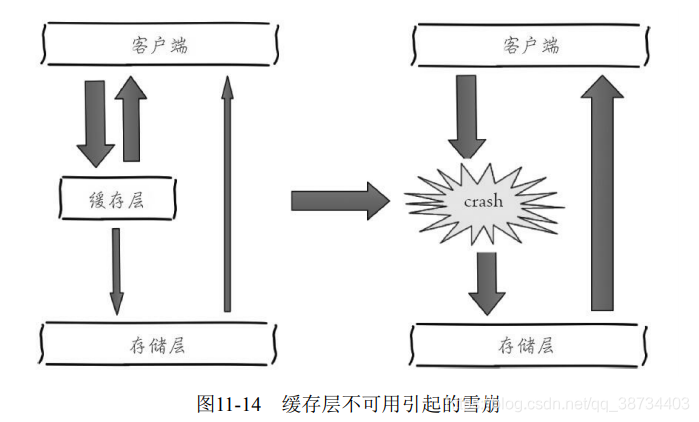
- 三个方面预防和解决缓存雪崩问题:
1)保证缓存层服务高可用性。
和飞机都有多个引擎一样,如果缓存层设计成高可用的,即使个别节点、个别机器、甚至是机房宕掉,依然可以提供服务,例如前面介绍过的Redis Sentinel和Redis Cluster都实现了高可用。
2)依赖隔离组件为后端限流并降级。
无论是缓存层还是存储层都会有出错的概率,可以将它们视同为资源。作为并发量较大的系统,假如有一个资源不可用,可能会造成线程全部阻塞(hang)在这个资源上,造成整个系统不可用。
▷ 降级机制在高并发系统中是非常普遍的:比如推荐服务中,如果个性化推荐服务不可用,可以降级补充热点数据,不至于造成前端页面是开天窗。在实际项目中,我们需要对重要的资源(例如Redis、MySQL、HBase、外部接口)都进行隔离,让每种资源都单独运行在自己的线程池中,即使个别资源出现了问题,对其他服务没有影响。但是线程池如何管理,比如如何关闭资源池、开启资源池、资源池阀值管理,这些做起来还是相当复杂的。
3)提前演练。
在项目上线前,演练缓存层宕掉后,应用以及后端的负载情况以及可能出现的问题,在此基础上做一些预案设定。
- 是什么?
见你写了个加随机数预防缓存雪崩,解释一下?
- 这里分享一个简单方案就时讲缓存失效时间分散开,比如我们可以在原有的失效时间基础上增加一个随机值,比如1-5分钟随机,这样每一个缓存的过期时间的重复率就会降低,就很难引发集体失效的事件。
https://blog.csdn.net/zeb_perfect/article/details/54135506 - 其他方案:
https://blog.csdn.net/kongtiao5/article/details/82771694
- 这里分享一个简单方案就时讲缓存失效时间分散开,比如我们可以在原有的失效时间基础上增加一个随机值,比如1-5分钟随机,这样每一个缓存的过期时间的重复率就会降低,就很难引发集体失效的事件。
redis缓存击穿(热点数据集中失效/热点key重建优化)与解决措施? |3 (rky
- 缓存+过期时间-策略:
► 优:加速数据读写、保证数据的定期更新,基本能够满足绝大部分需求。 - 问题:
如下两个问题如果同时出现,在缓存失效的瞬间,有大量线程来重建缓存,造成后端负载加大,甚至可能会让应用崩溃。
① 当前key是一个热点key(例如一个热门的娱乐新闻),并发量非常大。
② 重建缓存不能在短时间完成,可能是一个复杂计算,例如复杂的SQL、多次IO、多个依赖等。
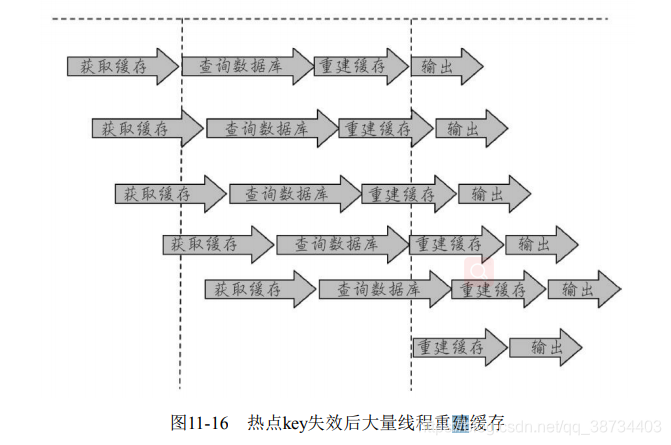
- 解决:
1)互斥锁(mutex key)
► 此方法只允许一个线程重建缓存,其他线程等待重建缓存的线程执行完,重新从缓存获取数据即可,整个过程如图。
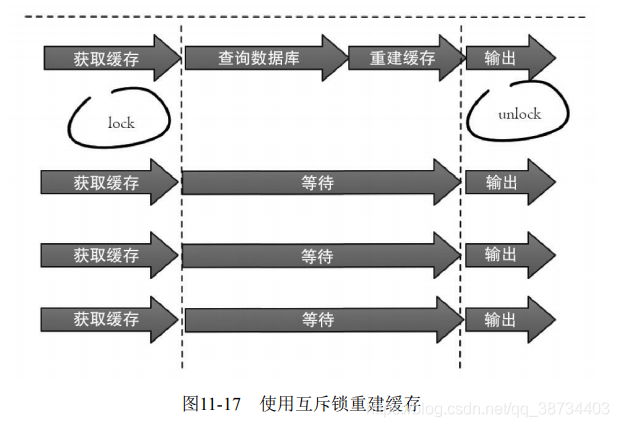
► 下面代码使用Redis的setnx命令实现上述功能:
String get(String key) {// 从Redis中获取数据String value = redis.get(key);// 如果value为空,则开始重构缓存if (value == null) {// 只允许一个线程重构缓存,使用nx,并设置过期时间exString mutexKey = "mutext:key:" + key;if (redis.set(mutexKey, "1", "ex 180", "nx")) {// 从数据源获取数据value = db.get(key);// 回写Redis,并设置过期时间redis.setex(key, timeout, value);// 删除key_mutexredis.delete(mutexKey);}// 其他线程休息50毫秒后重试else {Thread.sleep(50);get(key);}}return value;}
1)从Redis获取数据,如果值不为空,则直接返回值;否则执行下面的2.1)和2.2)步骤。
2.1)如果set(nx和ex)结果为true,说明此时没有其他线程重建缓存,那么当前线程执行缓存构建逻辑。
2.2)如果set(nx和ex)结果为false,说明此时已经有其他线程正在执行构建缓存的工作,那么当前线程将休息指定时间(例如这里是50毫秒,取决于构建缓存的速度)后,重新执行函数,直到获取到数据。
2)永远不过期
► “永远不过期”包含两层意思:
-- 从缓存层面来看,确实没有设置过期时间,所以不会出现热点key过期后产生的问题,也就是“物理”不过期。
-- 从功能层面来看,为每个value设置一个逻辑过期时间,当发现超过逻辑过期时间后,会使用单独的线程去构建缓存。
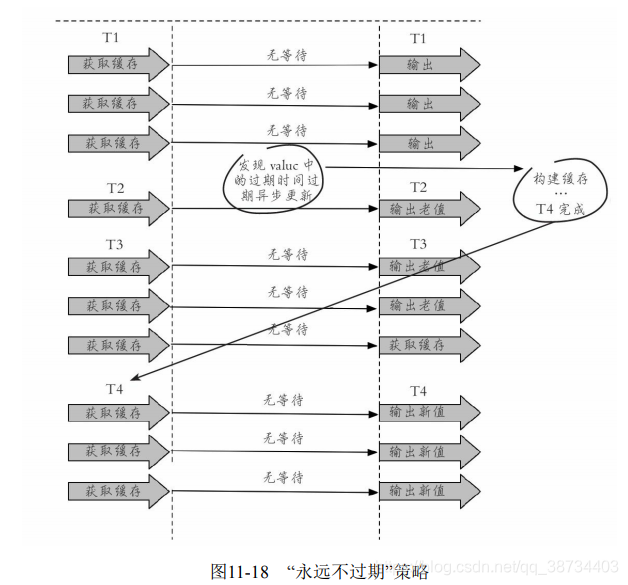
► 从实战看,此方法有效杜绝了热点key产生的问题,但唯一不足的就是重构缓存期间,会出现数据不一致的情况,这取决于应用方是否容忍这种不一致。
► 代码实现:String get(final String key) {V v = redis.get(key);String value = v.getValue();// 逻辑过期时间long logicTimeout = v.getLogicTimeout();// 如果逻辑过期时间小于当前时间,开始后台构建if (v.logicTimeout <= System.currentTimeMillis()) {String mutexKey = "mutex:key:" + key;if (redis.set(mutexKey, "1", "ex 180", "nx")) {// 重构缓存threadPool.execute(new Runnable() {public void run() {String dbValue = db.get(key);redis.set(key, (dbvalue,newLogicTimeout));redis.delete(mutexKey);}});}}return value;}
- 缓存指标对比解决方案?
► 作为一个并发量较大的应用,在使用缓存时有三个目标:
第一,加快用户访问速度,提高用户体验。
第二,降低后端负载,减少潜在的风险,保证系统平稳。
第三,保证数据“尽可能”及时更新。下面将按照这三个维度对上述两种解决方案进行分析。
► 互斥锁(mutex key):这种方案思路比较简单,但是存在一定的隐患,如果构建缓存过程出现问题或者时间较长,可能会存在死锁和线程池阻塞的风险,但是这种方法能够较好地降低后端存储负载,并在一致性上做得比较好。 - “永远不过期”:这种方案由于没有设置真正的过期时间,实际上已经不存在热点key产生的一系列危害,但是会存在数据不一致的情况,同时代码复杂度会增大。

- 缓存+过期时间-策略:
为什么选择Redis作为缓存?
-- 收益:
① 加速读写:因为缓存通常都是全内存的(例如Redis、Memcache),而存储层通常读写性能不够强悍(例如MySQL),通过缓存的使用可以有效地加速读写,优化用户体验。
② 降低后端负载:帮助后端减少访问量和复杂计算(例如很复杂的SQL语句),在很大程度降低了后端的负载。缓存一致性相关问题?
- 问题:
1)如何保证mysql与redis的双写一致性。
(最终一致性和强一致性)
如果对数据有强一致性要求,不能放缓存。
2)怎么保证redis与Mysql的数据一致性(秒杀预热数据的一致性,就解释了不需要一致性,只保证Mysql库存正确即可之类的)
3)怎么实现redis,mysql数据一致性,为什么不采取更新数据库,再更新缓存?这样做有什么不好?怎么改进呢?等等
4)项目中的缓存不一致怎么解决的
-- 不一致原因:先操作缓存,在写数据库成功之前,如果有读请求发生,可能导致旧数据入缓存,引发数据不一致。
-- 解决:串行化 - 解决:
https://www.jianshu.com/p/c72ba33ea49e
- 问题:
1- 分布式锁
- redis分布式锁以及实现?
2-项目和场景题
2.1 场景题
设计一个缓存商品的方案,什么时候保存商品到缓存,什么时候删除缓存的商品?
如何设计一个秒杀系统?
① 怎么测试秒杀
② Redis怎么库存预热,RabbitMQ怎么进行队列削峰如何解决一个高并发场景呢?
(答数据库主从复制读写分离,分库分表,服务器划分不通服务或者负载均衡,加消息队列和缓存)
2.2 项目
Redis项目中用来做什么 ?
你项目如果用redis改进,怎么改?
※ 6-网络
http状态码 |3
常见:状态码 含义 200 请求成功 301 资源(网页等)被永久转移到其它URL 404 请求的资源(网页等)不存在 500 内部服务器错误 分类:
分类 含义 1** 信息,服务器收到请求,需要请求者继续执行操作 2** 成功,操作被成功接收并处理 3** 重定向,需要进一步的操作以完成请求 4** 客户端错误,请求包含语法错误或无法完成请求 5** 服务器错误,服务器在处理请求的过程中发生了错误 301,302区别?
- 301适合永久重定向
• 301比较常用的场景是使用域名跳转。
• 比如,我们访问 http://www.baidu.com 会跳转到https://www.baidu.com,发送请求之后,就会返回301状态码,然后返回一个location,提示新的地址,浏览器就会拿着这个新的地址去访问。
• 注意: 301请求是可以缓存的, 即通过看status code,可以发现后面写着from cache。
• 或者你把你的网页的名称从php修改为了html,这个过程中,也会发生永久重定向。 - 302用来做临时跳转
• 比如未登陆的用户访问用户中心重定向到登录页面。
• 访问404页面会重新定向到首页。 - 301重定向和302重定向的区别
• 302重定向只是暂时的重定向,搜索引擎会抓取新的内容而保留旧的地址,因为服务器返回302,所以,搜索搜索引擎认为新的网址是暂时的。
• 而301重定向是永久的重定向,搜索引擎在抓取新的内容的同时也将旧的网址替换为了重定向之后的网址。
• 301重定向的使用对搜索引擎更加友好,因此建议尽量使用301进行跳转。
- 301适合永久重定向
为什么会产生202,404这种页面错误
写出常用端口
- 1521: Oracle
- 3306: MySQL
- 8080: tomcat默认端口
- 8000-9090 web
https://www.jianshu.com/p/048963e312bc
七层网络模型,及每层作用 |4
- 必读:
https://blog.csdn.net/liuchengzimozigreat/article/details/100169829
https://www.cnblogs.com/sunsky303/p/10647255.html - OSI模型:
自下向上:物理层、数据链路层、网络层、传输层、会话层、表示层、应用层

- 物理层:
物理层负责最后将信息编码成电流脉冲或其它信号用于网上传输;
• eg:RJ45等将数据转化成0和1; - 数据链路层:
数据链路层通过物理网络链路提供数据传输。不同的数据链路层定义了不同的网络和协议特征,其中包括物理编址、网络拓扑结构、错误校验、数据帧序列以及流控;
• 可以简单的理解为:规定了0和1的分包形式,确定了网络数据包的形式; - 网络层
网络层负责在源和终点之间建立连接;
• 可以理解为,此处需要确定计算机的位置,怎么确定?IPv4,IPv6! - 传输层
传输层向高层提供可靠的端到端的网络数据流服务。
• 可以理解为:每一个应用程序都会在网卡注册一个端口号,该层就是端口与端口的通信!常用的(TCP/IP)协议; - 会话层
会话层建立、管理和终止表示层与实体之间的通信会话;
• 建立一个连接(自动的手机信息、自动的网络寻址); - 表示层:
表示层提供多种功能用于应用层数据编码和转化,以确保以一个系统应用层发送的信息可以被另一个系统应用层识别;
• 可以理解为:解决不同系统之间的通信,eg:Linux下的QQ和Windows下的QQ可以通信; - 应用层:
OSI 的应用层协议包括文件的传输、访问及管理协议(FTAM),以及文件虚拟终端协议(VIP)和公用管理系统信息(CMIP)等;
• 规定数据的传输协议;
- 必读:
计算机网络五层模型,每层的作用?

七层网络模型以及某几个协议在哪一层?
网络层和传输层分别解决了什么问题?
- 网络层
网络层负责在源和终点之间建立连接; - 传输层
传输层向高层提供可靠的端到端的网络数据流服务。
- 网络层
网络七层模型,http是哪一层?
(本人研究生方向网络相关,http扯了好久,各个版本演进、报文头,各种方法)- 应用层
计网TCP/IP?TCP/IP协议
1.UDP|TCP
UDP是什么?
- 是什么:
• UDP(User Datagram Protocol用户数据报协议)
• 传输层协议
• 无连接的数据报协议
• 不能提供数据报分组,组装和不能对数据报进行排序
• 主要用于不要求分组顺序到达的传输中,分组传输顺序的检查和排序有应用层完成。
• 提供面向事务的简单不可靠传递服务。
• UDP协议使用端口分别运行在同一台设备上的多个应用程序
• 功能:为了在给定的主句上能识别多个目的的地址,同时允许多个应用程序在同一台主句上工作并能够独立地进行数据包的发送和接受,设计用户数据报协议UDP - 应用场景:
UDP当对网络通讯质量要求不高的时候,要求网络通讯速度能尽量的快,这时就可以使用UDP。比如,日常生活中,常见使用UDP协议的应用如下:
-- QQ语音、QQ视频、TFTP……
- 是什么:
UDP怎么实现可靠传输? |2
1)添加seq/ack机制,确保数据发送到对端
2)添加发送和接收缓冲区,主要是用户超时重传。
3)添加超时重传机制。
https://www.jianshu.com/p/6c73a4585ebatcp参考:
https://blog.csdn.net/qq_38950316/article/details/81087809
https://blog.csdn.net/qzcsu/article/details/72861891
https://www.cnblogs.com/jainszhang/p/10641728.htmlTCP是什么?应用场景,udp怎么实现tcp功能
- 是什么?
• 传输控制协议(TCP)是一种面向连接的,可靠的,基于字节流的传输通信协议。
• 传输层协议
• 原因:应用层需要可靠的连接,但是IP层没有这样的流机制
• 面向连接,即在客户端和服务器之间发送数据之间,必须先建立连接
• 位于应用层和IP层之间
• 连接需要建立三次握手、四次挥手断开连接
• 传输数据时可靠的 - 应用场景
TCP当对网络通讯质量有要求的时候,比如:整个数据要准确无误的传递给对方,这往往用于一些要求可靠的应用,比如HTTP、HTTPS、FTP等传输文件的协议,POP、SMTP等邮件传输的协议。
在日常生活中,常见使用TCP协议的应用如下:
-- 浏览器,用的HTTP
-- FlashFXP,用的FTP
-- Outlook,用的POP、SMTP
-- Putty,用的Telnet、SSH
-- QQ文件传输…………
- 是什么?
tcp三次握手? |5
- 必读:https://blog.csdn.net/qq_38950316/article/details/81087809
- 三次握手过程理解:
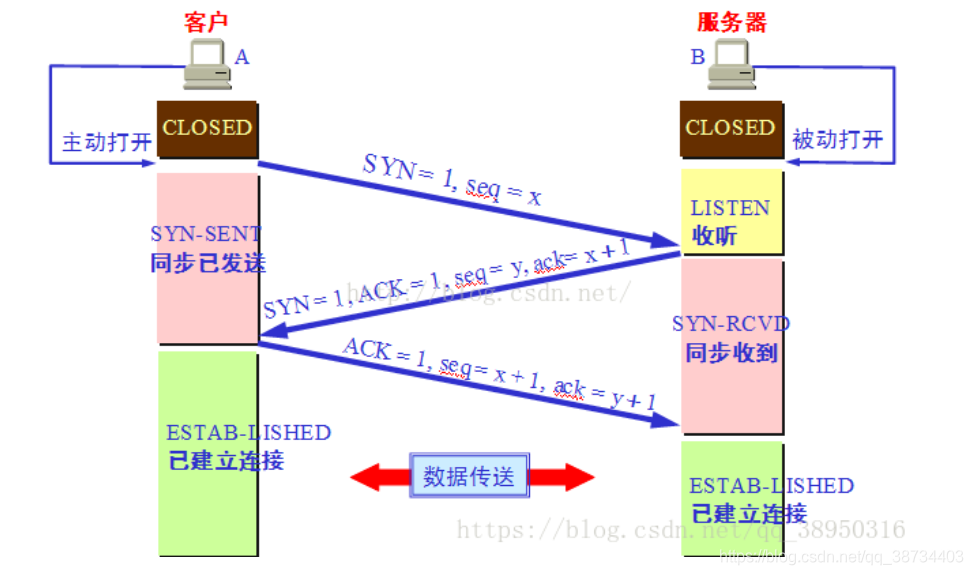
- 第一次握手:建立连接时,客户端发送syn包(syn=x)到服务器,并进入SYN_SENT状态,等待服务器确认;SYN:同步序列编号(Synchronize Sequence Numbers)。
- 第二次握手:服务器收到syn包,必须确认客户的SYN(ack=x+1),同时自己也发送一个SYN包(syn=y),即SYN+ACK包,此时服务器进入SYN_RECV状态;
- 第三次握手:客户端收到服务器的SYN+ACK包,向服务器发送确认包ACK(ack=y+1),此包发送完毕,客户端和服务器进入ESTABLISHED(TCP连接成功)状态,完成三次握手。
tcp四次挥手?以及客户端/服务端分别发送消息后的状态? |4
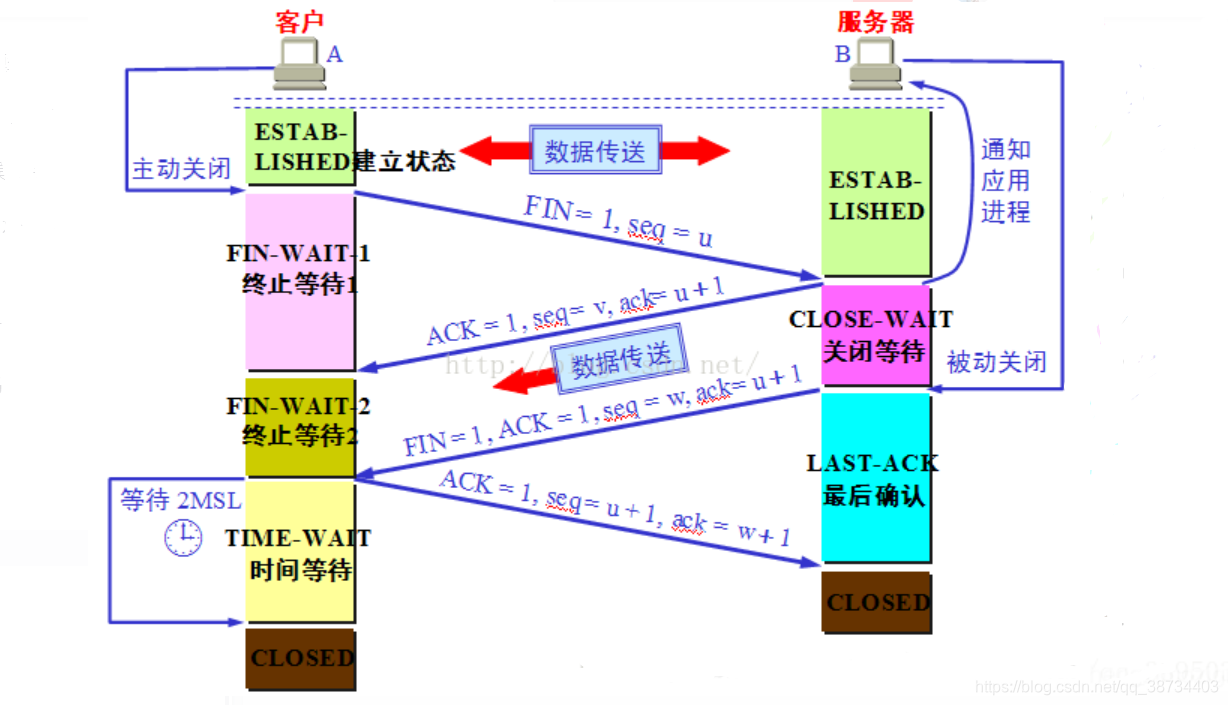
- 四次挥手过程
第一次挥手:客户端发出释放FIN=1,自己序列号seq=u,进入FIN-WAIT-1状态
第二次挥手:服务器收到客户端的后,发出ACK=1确认标志和客户端的确认号ack=u+1,自己的序列号seq=v,进入CLOSE-WAIT状态
第三次挥手:客户端收到服务器确认结果后,进入FIN-WAIT-2状态。此时服务器发送释放FIN=1信号,确认标志ACK=1,确认序号ack=u+1,自己序号seq=w,服务器进入LAST-ACK(最后确认态)
第四次挥手:客户端收到回复后,发送确认ACK=1,ack=w+1,自己的seq=u+1,客户端进入TIME-WAIT(时间等待)。客户端经过2个最长报文段寿命后,客户端CLOSE;服务器收到确认后,立刻进入CLOSE状态。
- 四次挥手过程
三次握手都会发送电报,目的是什么?
三次握手在TCP中是以什么形式进行的
为什么要三次握手,四次挥手,两次不行么
- 三次握手的原因 :第三次握手是为了防止失效的连接请求到达服务器,让服务器错误打开连接。
- 四次挥手:客户端发送了 FIN连接释放报文之后,服务器收到了这个报文,就进入了 CLOSE-WAIT 状态。这个状态是为了让服务器端发送还未传送完毕的数据,传送完毕之后,服务器会发送 FIN 连接释放报文。。
为什么客户端最后还要等待2MSL tcp的timewait
客户端接收到服务器端的 FIN 报文后进入此状态,此时并不是直接进入 CLOSED 状态,还需要等待一个时间计时器设置的时间 2MSL。这么做有两个理由:- 确保最后一个确认报文能够到达。如果 B 没收到 A 发送来的确认报文,那么就会重新发送连接释放请求报文,A 等待一段时间就是为了处理这种情况的发生。
- 等待一段时间是为了让本连接持续时间内所产生的所有报文都从网络中消失,使得下一个新的连接不会出现旧的连接请求报文。
https://blog.csdn.net/TJtulong/article/details/89858678
TCP 如何保证可靠传输,讲了一下拥塞控制、滑动窗口/tcp可靠性/为什么是可靠的
1)可靠传输:通过序列号、检验和、确认应答信号、重发控制、连接管理、窗口控制、流量控制、拥塞控制实现可靠性。(重传机制?)
2)TCP 滑动窗口
窗口允许发送方在收到ACK之前连续发送多个分组,窗口的大小就是指无需等待确认应答而可以继续发送数据的最大值。
https://blog.csdn.net/TJtulong/article/details/89858678TCP协议怎么保证传输可靠性,如果收到了重复数据怎么办?
TCP流量控制?
tcp拥塞控制? |3
tcp拥塞控制怎么实现
- 如果网络出现拥塞,分组将会丢失,此时发送方会继续重传,从而导致网络拥塞程度更高。因此当出现拥塞时,应当控制发送方的速率。
- TCP 主要通过四个算法来进行拥塞控制:慢开始、拥塞避免、快重传、快恢复。
https://blog.csdn.net/TJtulong/article/details/89858678
TCP用的是ipoc还是什么?
TCP头有什么信息?
TCP往IP层的包添加了哪些东西
弱网情况下TCP性能较差,为什么。
讲一下TCP和UDP区别? |3
为什么选用TCP而不用UDP
查找出目前正在运行的TCP/UDP服务?
netstat -atunlp网络拥塞,最快方式下载一个视频文件的方法
DNS
问DNS怎么查询二级域名。
有用过短域名服务吗,能说一下吗?
- 域名与ip的对应关系
为什么一ip多端口
问计算机网络的知识:网关、子网掩码
DNS解析过程。|4
DNS 的过程?
- 例如,要查询www.baidu.com的IP地址(DNS解析url):
① 浏览器搜索自己的DNS缓存(维护一张域名与IP地址的对应表)
② 若没有,则搜索操作系统中的DNS缓存(维护一张域名与IP地址的对应表)
③ 若没有,则搜索操作系统的hosts文件(Windows环境下,维护一张域名与IP地址的对应表,位置一般在C:\Windows\System32\drivers\etc\hosts)
④ 若没有,则操作系统将域名 送至 本地域名服务器--(递归查询方式),本地域名服务器 查询自己的DNS缓存,查找成功则返回结果,否则,(以下是迭代查询方式)
.1 本地域名 务器 向根域名服务器(其虽然没有每个域名的具体信息,但存储了负责每个域,如com、net、org等的解析的顶级域名服务器的地址)发起请求,此处,根域名服务器返回com域的顶级域名服务器的地址
.2 本地域名 务器 向com域的顶级域名服务器发起请求,返回baidu.com权限域名服务器(权限域名服务器,用来保存该区中的所有主机域名到IP地址的映射)地址
.3 本地域名 务器 向baidu.com权限域名服务器发起请求,得到www.baidu.com的IP地址
⑤ 本地域名 务器 将得到的IP地址返回给操作系统,同时自己也将IP地址缓存起来
⑥ 操作系统将 IP 地址返回给浏览器,同时自己也将IP地址缓存起来
⑦ 至此,浏览器已经得到了域名对应的IP地址
https://blog.csdn.net/qq_21993785/article/details/81188253
- 例如,要查询www.baidu.com的IP地址(DNS解析url):
多台服务器,一个域名,客户端请求到具体某一台服务器的全过程,尽可能的细
- DNS解析的过程/浏览器输入一个url,敲下回车后网络的全过程 |3
在浏览器中输入一个网址到最后响应的全过程?
- 域名解析 —> 与服务器建立连接 —> 发起HTTP请求 —> 服务器响应HTTP请求,浏览器得到html代码 —> 浏览器解析html代码,并请求html代码中的资源(如js、css、图片) —> 浏览器对页面进行渲染呈现给用户
https://blog.csdn.net/u013777975/article/details/80496121
https://blog.csdn.net/qq_21993785/article/details/81188253
- 域名解析 —> 与服务器建立连接 —> 发起HTTP请求 —> 服务器响应HTTP请求,浏览器得到html代码 —> 浏览器解析html代码,并请求html代码中的资源(如js、css、图片) —> 浏览器对页面进行渲染呈现给用户
输入 www.baidu.com 时的内部流程,dns基于udp还是tcp
web页面 html解析:如何提取新闻页面title和content
问了不了解DNS劫持。
http
http协议 、http的结构
http完整请求(客户端和服务端):url和SpringMVC
http协议,假设有个http下载链接,在网络很差的情况下怎么保证下载成功(request请求头,断点续传)
HTTP1.0、HTTP1.1、HTTP2.0的区别
介绍下https,是如何加密的,加密算法
HTTP和HTTPS的区别 |2
https原理
计算机网络的http头部。
http端口可以改吗
http状态码 方式
http请求头中的信息(基本都说出来)
HTTP?
超文本传输协议:是一个你来我往的过程,客户端(浏览器)发起请求(我要访问www.wangsu.com),请求到达服务端,服务端响应一个结果(网宿首页的内容),发起HTTP请求之前,需要建立连接。聊聊http2.0
① 多路复用 ② 数据压缩 ③ 服务器推送
https://blog.csdn.net/weixin_34258782/article/details/88772230http1.0、http1.1、http2.0区别
- http1.0、http1.1主要区别
① 长连接
1.0使用keep-alive参数来告知服务器端要建立一个长链接;
1.1默认支持长连接,保持链接设置Connection:Keep-Alive
(注:http用个长连接来发多个请求。http基于TCP/IP协议的,创建一个TCP连接是需要经过三次握手的,有一定的开销,如果每次通讯都要重新建立连接的话,对性能有影响。)
② 节约带宽
1.1支持只发送header信息,服务端返回401,客户端可以不用请求body,节约带宽。另外HTTP还支持传送内容的一部分。
[注:如果服务器认为客户端有权限请求服务器,则返回100,否则返回401。客户端如果接受到100,才开始把请求body发送到服务器。客户端已经有一部分的资源时,只需要跟服务器请求另外的部分资源即可。这是支持文件断点续传的基础。]
③ HOST域
1.0是没有host域的;
1.1才支持这个参数。
[ 注:现在可以web server例如tomat,设置虚拟站点是非常常见的,也即是说,web server上的多个虚拟站点可以共享同一个ip和端口。] - http1.1和http2.0主要区别
① 多路复用
HTTP2.0使用了多路复用的技术,做到同一个连接并发处理多个请求,而且并发请求的数量比HTTP1.1大了好几个数量级。
HTTP1.1也可以多建立几个TCP连接,来支持处理更多并发的请求,但是创建TCP连接本身也是有开销的。
② 数据压缩
HTTP1.1不支持header数据的压缩
HTTP2.0使用HPACK算法对header的数据进行压缩,数据体积小,网络传输更快。
③ 服务器推送
对支持HTTP2.0的web server请求数据的时候,服务器会顺便把一些客户端需要的资源一起推送到客户端,客户端无需再次创建连接发送请求到服务器端获取。
合适加载静态资源。
[注:资源存在客户端的某处地方,客户端直接从本地加载这些资源就可以了,不用走网络,速度自然是快很多的。]
https://blog.csdn.net/linsongbin1/article/details/54980801
- http1.0、http1.1主要区别
web优化有哪些方法?缓存出错怎么办?
问http缓存
1) web缓存- Web 缓存大致可以分为:数据库缓存、服务器端缓存、浏览器缓存。
- 浏览器缓存包含: HTTP 缓存、indexDB、cookie、localstorage 等等。
2) HTTP 缓存 - 概念:http缓存指的是: 当客户端向服务器请求资源时,会先抵达浏览器缓存,如果浏览器有“要请求资源”的副本,就可以直接从浏览器缓存中提取而不是从原始服务器中提取这个资源。
- 分类:强制缓存、协商缓存、私有缓存、共享缓存
- 好处:
① 减少了冗余的数据传输,节省了网费。
② 缓解了服务器的压力, 大大提高了网站的性能
③ 加快了客户端加载网页的速度 - 如何使用&注意事项等
阅读 https://www.jianshu.com/p/227cee9c8d15
https://www.cnblogs.com/ranyonsue/p/8918908.html
session
- 分布式session设置/分布式session怎么实现的?
- cookie与session的区别
- session的机制!!
如何实现cookie跨域?非子域名
怎么实现跨域单点登录?
(答:,说了说jwt具体怎么实现,这里不知道对不对,感觉可能不对)
分布式session(介绍背景,流程,操作),session,cookie区别javaweb项目中怎么实现用户登录功能?
(答:使用session和cookies)cookie session区别
- 会话(Session):跟踪是Web程序中常用的技术,用来跟踪用户的整个会话。常用的会话跟踪技术是Cookie与Session。Cookie通过在客户端记录信息确定用户身份,Session通过在服务器端记录信息确定用户身份。
- 两者最大的区别在于生存周期,一个是预先设置的生存周期,或永久的保存于本地的文件(cookie)。一个是IE启动到IE关闭.(浏览器页面一关 ,session就消失了)
用户登陆后,用户信息存放在哪里,服务器如何识别当前用户
- 当用户登陆后 服务器会产生一个session,该session保存有用户的信息
- 识别步
1) 用户密码登录时,在后台的req中记住sessio
2) 如果用户保存登录密码,则记住cookie,否则把当前用户的cookie设置为
3) 每次用户需要向后台进行请求时,进行状态检验:session是否存在?
若存在,则继续进行请求操作,并将session的有效时间重新设置一次;
若不存在,则判断cookie是否存在?
若存在,使用该cookie完成自动登录,即完成了一次1);
若不存在,则页面重定向到登录页面。
https://blog.csdn.net/xixi880928/article/details/69389337
https://blog.csdn.net/itguangit/article/details/78330761
https://blog.csdn.net/danshenxiaobang/article/details/72902280
session如何保证用户唯一对应
https://www.iteye.com/problems/85769有关Session,以及Cookide被禁用时Session如何使用
如果指定的方法为POST请求,怎么处理。
get和post区别?
- 1)最直观的区别就是GET把参数包含在URL中,POST通过request body传递参数。
GET 和 POST 到底有什么区别? - 大宽宽的回答 - 知乎
https://www.zhihu.com/question/28586791/answer/767316172
- 1)最直观的区别就是GET把参数包含在URL中,POST通过request body传递参数。
SOAP、UDDI等有什么作用
- SOAP,作为传输层,是Web services 的通信协议。用来在消费者和服务提供者之间传送消息。
- UDDI用来注册和查找服务。它就是一个目录,只不过在这个目录中存放的是一些关于 Web 服务的信息而已,用户可以在这个目录中查找服务,取得服务的WSDL描述,然后通过SOAP来调用服务
https://blog.csdn.net/shuaishuai3409/article/details/51602437
socket

※ 7-Linux|os
os
linuxIO select,epoll的区别
//多路复用:select 和 epoll的区别
操作系统换页算法,当时内心想到了FIFO,LRU
零拷贝
- 什么是零拷贝
零拷贝描述的是CPU不执行拷贝数据从一个存储区域到另一个存储区域的任务,这通常用于通过网络传输一个文件时以减少CPU周期和内存带宽。 - 好处
① 减少甚至完全避免不必要的CPU拷贝,从而让CPU解脱出来去执行其他的任务
② 减少内存带宽的占用
③ 通常零拷贝技术还能够减少用户空间和操作系统内核空间之间的上下文切换 - 实现
零拷贝实际的实现并没有真正的标准,取决于操作系统如何实现这一点。零拷贝完全依赖于操作系统。操作系统支持,就有;不支持,就没有。不依赖Java本身。
https://www.jianshu.com/p/e76e3580e356
- 什么是零拷贝
说了多路复用的阻塞方式?(BIO,NIO,AIO然后问异步是啥)
- 概念:很多个网络I/O复用一个或少量的线程来处理多个TCP连接(或多个Channel)连接。
- 阻塞(read为例):
1)进程发起read,进行recvfrom系统调用;
2)内核开始第一阶段,准备数据(从磁盘拷贝到缓冲区),进程请求的数据并不是一下就能准备好;准备数据是要消耗时间的;
3)与此同时,进程阻塞(进程是自己选择阻塞与否),等待数据ing;
4)直到数据从内核拷贝到了用户空间,内核返回结果,进程解除阻塞。
也就是说,内核准备数据和数据从内核拷贝到进程内存地址这两个过程都是阻塞的。
图示:https://blog.csdn.net/ligupeng7929/article/details/93672312
BIO、NIO、AIO的定义和区别
1) I/O:输入(Input)和输出(Output)- 只要具有输入输出类型的交互系统都可以认为是 I/O 系统,也可以说 I/O 是整个操作系统数据交换与人机交互的通道
2)区别
- BIO (Blocking I/O):同步阻塞I/O模式,数据的读取写入必须阻塞在一个线程内等待其完成。
① 特性:会阻塞每一个线程
② 如,当朋友聚餐,叫一个线程停留在一个人那,直到这个人吃好,然后去处理下一个。在线程在等待一个人吃饭的时间段什么都没有做。 - NIO (New I/O):同时支持阻塞与非阻塞模式
① 只阻塞一个线程
② 如同步非阻塞:用一个线程不断的轮询每个人吃饭的状态,看看是否有人吃饭的状态发生了改变,再进行下一步的操作。 - AIO ( Asynchronous I/O):异步非阻塞I/O模型。
① 不阻塞任何线程
② 异步非阻塞与同步非阻塞的区别:异步非阻塞无需一个线程去轮询所有IO操作的状态改变,在相应的状态改变后,系统会通知对应的线程来处理。③ 例子:每个人手机编辑信息,吃完之后,每个人会自动通知线程吃完了
Nio和IO有什么区别
- NIO:面向缓冲、同步无阻塞、选择器(多路复用)
- IO: 面向流、 同步阻塞、无
https://baijiahao.baidu.com/s?id=1632673729522644150&wfr=spider&for=pc
https://www.cnblogs.com/panxuejun/p/8631423.html
Nio和aio的区别
- NIO (New I/O):同时支持阻塞与非阻塞模式
- AIO ( Asynchronous I/O):异步非阻塞I/O模型。
https://blog.csdn.net/u010541670/article/details/91890649?utm_medium=distribute.pc_relevant.none-task-blog-BlogCommendFromMachineLearnPai2-2.nonecase&depth_1-utm_source=distribute.pc_relevant.none-task-blog-BlogCommendFromMachineLearnPai2-2.nonecase
cache和buffer区别(OS中cache是内存和CPU之间的高速缓存区,buffer基本都是IO缓存区)
https://www.zhihu.com/question/26190832本地缓存和远端缓存的选择问题,各自好坏。。
https://www.cnblogs.com/yougewe/p/9142732.html
linux
linux怎么查看日志中前十条记录
- head -n 10 filename.log
讲一下常用的Linux命令,linux的命令,你自己使用过的有哪些(做在笔记上)
- tail -f
- netstat
- top,ps -aux
查看进程命令
- ps -aux 查看所有的进程(不是动态的)
- top 查看所有的进程(是动态的)
- 查找所有名称含 'tomcat' 的进程的命令: ps -aux | grep tomcat
查看端口:netstat -nplt |grep 8775
查看cpu:cat /proc/cpuinfo
查找磁盘上最大的文件:du -Sh | sort -rh | head -n 10
查看系统日志文件:实时查看 tail -f /var/log/messages
- 默认配置下,日志文件通常都保存在“/var/log”目录下。
- /var/log/message 系统启动后的信息和错误日志,是Red Hat Linux中最常用的日志之一
linux crontab有没有用过
作用:定时备份,实时备份看所有磁盘空间的命令
查大数据文件的最后几行
- tail -n 20 filename
查看系统负载
- $uptime
- 结果:15:24:14 up 2 days, 18:54, 1 user, load average:0.04, 0.03, 0.05
- 注解:up 2 days, 18:54 :系统开机到现在经过了2天
1 users:当前1用户在线
load average:0.04, 0.03, 0.05:系统1分钟、5分钟、15分钟的CPU负载信息.
备注:load average后面三个数值的含义是最近1分钟、最近5分钟、最近15分钟系统的负载值。这个值的意义是,单位时间段内CPU活动进程数。如果你的机器为单核,那么只要这几个值均<1,代表系统就没有负载压力,如果你的机器为N核,那么必须是这几个值均<N才可认为系统没有负载压力。
- 内核态和用户态区别
文件从服务器到硬盘,要拷贝几次数据,从哪到哪。
服务器先发送序列化后的二进制文件到网卡(数据现在在内核态) -> 从网卡拷贝到内存(内核态数据拷贝到用户态,再拷贝回内核态)->内存拷贝到硬盘(内核态->用户态->内核态) 一共经历4次数据拷贝 。
软件层面的优化措施可以把中间拷贝到内存这一步骤省略(DPDK优化)Cpu load的参数如果为4,描述一下现在系统处于什么情况
※ 8-mybatis
mybatis缓存,有了mabatis缓存为啥还有redis?,sql注入,mybatis怎么防止sql注入的(#{}),用了这个为什么能防止注入?底层怎么实现的?
Mybatis的一级、二级缓存
1)一级缓存: 基于 PerpetualCache 的 HashMap本地缓存,其存储作用域为 Session,当 Session flush 或 close 之后,该 Session 中的所有 Cache 就将清空,默认打开一级缓存。
2)二级缓存与一级缓存其机制相同,默认也是采用 PerpetualCache,HashMap 存储,不同在于其存储作用域为 Mapper(Namespace),并且可自定义存储源,如 Ehcache。默认不打开二级缓存,要开启二级缓存,使用二级缓存属性类需要实现Serializable序列化接口(可用来保存对象的状态),可在它的映射文件中配置 ;
3)对于缓存数据更新机制,当某一个作用域(一级缓存 Session/二级缓存Namespaces)的进行了C/U/D 操作后,默认该作用域下所有 select 中的缓存将被 clear。
一级二级缓存
mybatis的的一级缓存是SqlSession级别的缓存,一级缓存缓存的是对象,当SqlSession提交、关闭以及其他的更新数据库的操作发生后,一级缓存就会清空。二级缓存是SqlSessionFactory级别的缓存,同一个SqlSessionFactory产生的SqlSession都共享一个二级缓存,二级缓存中存储的是数据,当命中二级缓存时,通过存储的数据构造对象返回。查询数据的时候,查询的流程是二级缓存>一级缓存>数据库。
※ 9-Spring
你说你看过spring讲一下(好慌,我就只懂个ioc和aop。然后对ioc中的单例模式说了半天,实现的方式枚举,静态内部类,双重锁,然后说了下这样为啥是线程安全的)
https://blog.csdn.net/lishuangzhe7047/article/details/20740209
https://blog.csdn.net/qq_22583741/article/details/79589910熟悉Spring了……web容器?
Spring的启动过程
https://blog.csdn.net/moshenglv/article/details/53517343
AOP|IoC
Spring两大特性/特点
控制反转(IoC)和面向切面编程(AOP)。
https://blog.csdn.net/dkbnull/article/details/87219562IOC怎么实现的,底层什么数据结构
工厂+反射+配置文件实现spring事务在项目里怎么用的
(1)编程式事务管理对基于 POJO 的应用来说是唯一选择。我们需要在代码中调用beginTransaction()、commit()、rollback()等事务管理相关的方法,这就是编程式事务管理。
(2)基于 TransactionProxyFactoryBean的声明式事务管理
(3)基于 @Transactional 的声明式事务管理
(4)基于Aspectj AOP配置事务
https://blog.csdn.net/CHINACR07/article/details/78817449
https://blog.csdn.net/daijin888888/article/details/51822257SpringAOP如何实现事务
AOP原理,代理事务之间可以嵌套吗?
AOP机制的原理
springaop原理
Spring:用到哪些技术?AOP用到什么设计模式?
面向切面编程,说一说那些场景
说说面向切面编程
Spring的aop有哪些实现方式
AOP主要在项目中做了什么
动态代理的实现方式和区别
动态代理的原理
Spring的AOP,以及代理模式下几种常见的代理
如果A调用B,而B被AOP拦截了,是否能走aop
Spring日志事务怎么实现业务做完才开始写日志呢
aop,ioc及实现原理,aop及实现,cglib,jdk动态代理实现原理,aop场景题
1) aop基本概念- AOP(Aspect-Oriented Programming):面向切面的编程。
- 作用:可以进行日志记录,可以进行事务管理,可以进行安全控制,可以进行异常处理,可以进行性能统计
2) aop实现原理
- aop的底层实现是代理模式加反射.
- aop:反射(略),代理模式分为多种,静态代理和动态代理,动态代理面又分为jdk动态代理和cglib动态代理
- 代理模式的好处
可以防止对方得到我们真实的方法;
3)Java动态代理(JDK和cglib)
a.JDK动态代理
① JDK动态代理包含:一个类和一个接口
** InvocationHandler接口
** Proxy类:
Proxy类是专门完成代理的操作类,可以通过此类为一个或多个接口动态地生成实现类,此类提供了如下的操作方法:
③ 弊端
JDK的动态代理依靠接口实现,如果有些类并没有实现接口,则不能使用JDK代理,这就要使用cglib动态代理了。
b.Cglib动态代理
① 介绍
JDK的动态代理机制只能代理实现了接口的类,而不能实现接口的类就不能实现JDK的动态代理,cglib是针对类来实现代理的,他的原理是对指定的目标类生成一个子类,并覆盖其中方法实现增强,但因为采用的是继承,所以不能对final修饰的类进行代理。4)cglib动态代理与JDK动态区别
java动态代理是利用反射机制生成一个实现代理接口的匿名类,在调用具体方法前调用InvokeHandler来处理。
而cglib动态代理是利用asm开源包,对代理对象类的class文件加载进来,通过修改其字节码生成子类来处理。note:https://blog.csdn.net/qq_38734403/article/details/105715064
Cglib和jdk的动态代理哪个快
在1.6和1.7的时候,JDK动态代理商的速度要比CGLib动态代理商的速度要慢,但是并没有教科书上的10倍差距,在JDK1.8的时候,JDK动态代理商的速度已经比CGLib动态代理商的速度快很多了
https://www.songma.com/news/txtlist_i22903v.html
Bean
springboot的自动配置能讲讲吗
详细:https://blog.csdn.net/u014745069/article/details/83820511spring的@autowired的作用
- 就是spring可以自动帮你把bean里面引用的对象的setter/getter方法省略,它会自动帮你set/get
https://blog.csdn.net/weixin_38410177/article/details/80513029
- 就是spring可以自动帮你把bean里面引用的对象的setter/getter方法省略,它会自动帮你set/get
Bean的自动装配,AutoWeird和Resource两个注释的区别以及哪个更好
- Resource是JDK提供的,而Autowired是Spring提供的
- Resource不允许找不到bean的情况,而Autowired允许(@Autowired(required = false))
- 指定name的方式不一样,@Resource(name = "baseDao"),@Autowired()@Qualifier("baseDao")
- Resource默认通过name查找,而Autowired默认通过type查找
https://blog.csdn.net/balsamspear/article/details/87936936
https://blog.csdn.net/magi1201/article/details/82590106
Bean的初始化方式
① 通过实现 InitializingBean/DisposableBean 接口来定制初始化之后/销毁之前的操作方法;
② 通过 元素的 init-method/destroy-method属性指定初始化之后 /销毁之前调用的操作方法;
③ 在指定方法上加上@PostConstruct 或@PreDestroy注解来制定该方法是在初始化之后还是销毁之前调用。
https://blog.csdn.net/HEYUTAO007/article/details/50326793Bean的作用域?
- 作用:用于确定哪种类型的bean实例应该从Spring容器中返回给调用者
- 五种作用域
① singleton单例模式、② prototype原型模式、③ request、④ session、⑤application(global session:全局的web域,类似于servlet中的application)
https://blog.csdn.net/kongmin_123/article/details/82048392
Controller是哪种作用域
- 单例
- 原因:为了性能、不需要多例。
https://blog.51cto.com/lavasoft/1394669
Bean的生命周期是什么
- 实例化bean对象(通过构造方法或者工厂方法)
- 设置对象属性(setter等)(依赖注入)
- 如果Bean实现了BeanNameAware接口,工厂调用Bean的setBeanName()方法传递Bean的ID。(和下面的一条均属于检查Aware接口)
- 如果Bean实现了BeanFactoryAware接口,工厂调用setBeanFactory()方法传入工厂自身
- 将Bean实例传递给Bean的前置处理器的postProcessBeforeInitialization(Object bean, String beanname)方法
- 调用Bean的初始化方法
- 将Bean实例传递给Bean的后置处理器的postProcessAfterInitialization(Object bean, String beanname)方法
- 使用Bean
- 容器关闭之前,调用Bean的销毁方法
图示:https://blog.csdn.net/w_linux/article/details/80086950
BeanFactory与FactoryBean
- BeanFactory是Spring容器的顶层接口,FactoryBean更类似于用户自定义的工厂接口。
- 他们两个都是个工厂,但FactoryBean本质上还是一个Bean,也归BeanFactory管理
- BeanFactory是提供了OC容器最基本的形式,给具体的IOC容器的实现提供了规范,FactoryBean可以说为IOC容器中Bean的实现提供了更加灵活的方式,FactoryBean在IOC容器的基础上给Bean的实现加上了一个简单工厂模式和装饰模式,我们可以在getObject()方法中灵活配置。
https://zhuanlan.zhihu.com/p/87382038
https://blog.csdn.net/wangbiao007/article/details/53183764
spring定时调度怎么用的
(一)在xml里加入task的命名空间
(二)启用注解驱动的定时任务
(三)注解写在实现类的方法上,实现类上要有组件的注解@Component
(四)写我们的定时任务
https://blog.csdn.net/qq_33556185/article/details/51852537springboot的starter有了解过吗
- SpringBoot中的starter是一种非常重要的机制,能够抛弃以前繁杂的配置,将其统一集成进starter,应用者只需要在maven中引入starter依赖,SpringBoot就能自动扫描到要加载的信息并启动相应的默认配置。
- starter让我们摆脱了各种依赖库的处理,需要配置各种信息的困扰。
https://www.cnblogs.com/hello-shf/p/10864977.html
认为微服务的概念
- 微服务架构风格是一种使用一套小服务来开发单个应用的方式途径,每个服务运行在自己的进程中,并使用轻量级机制通信,通常是HTTP API,这些服务基于业务能力构建,并能够通过自动化部署机制来独立部署,这些服务使用不同的编程语言实现,以及不同数据存储技术,并保持最低限度的集中式管理。
https://blog.csdn.net/wuxiaobingandbob/article/details/78642020
- 微服务架构风格是一种使用一套小服务来开发单个应用的方式途径,每个服务运行在自己的进程中,并使用轻量级机制通信,通常是HTTP API,这些服务基于业务能力构建,并能够通过自动化部署机制来独立部署,这些服务使用不同的编程语言实现,以及不同数据存储技术,并保持最低限度的集中式管理。
SpringMVC的接口,从请求到响应,一共做了什么?dispatchservelet是怎么工作的?
①请求发送到DispatcherServlet
②通过HandleMapping,解析获取到请求对应的Handler
③HandlerAdapter适配器,根据Handler调用真正的处理器处理请求,并开始真正业务逻辑
④上一步处理完后返回一个ViewAndModel对象,Model是返回的数据对象,View是个逻辑上的View
⑤ViewResolver会根据逻辑View查找实际的View
⑥将Model传给实际的View,然后将View返回给请求者
※ 0-data structure
md: https://www.zybuluo.com/songhanshi/note/1729602
jf: https://blog.csdn.net/qq_38734403/article/details/106562052
lc: https://blog.csdn.net/qq_38734403/article/details/107995530
※ 项目 ※
md: https://www.zybuluo.com/songhanshi/note/1769095
※ 场景 ※
- 业务场景(秒杀防止超卖)
- 业务场景:电脑微信扫码,然后手机点验证,电脑就进入微信。怎么实现
17.场景题,模拟微信消息用什么数据结构,说了List和SortedSet,具体用一个用哪个,选了 List(想着当作消息队列使用),问了下具体(说了 消息来了就 lpush,rpop),pop 以后如果还想看呢,说了 range
1.微博热搜如何设计,选用哪种数据结构比较合适,为什么
1.设计题:如何设计一个抢红包,有哪些要注意的点,怎么解决
4、发散性问题:假如有100万个玩家,需要对这100W个玩家的积分中前100名的积分,按照顺序显示在网站中,要求是实时更新的。积分可能由做的任务和获得的金钱决定。问如何对着100万个玩家前100名的积分进行实时更新?
(我说了分治和Hash,但他说我的方法都是从全局的数据进行考虑的,这样空间和时间要求太多,并且不现实。最后他给出了解决方法,就是利用缓存机制,缓存---tomcat---DB,层级计算,能不用到DB层就别用,因为每进一层,实现起来都会更复杂和更慢。解决的思路就是,考虑出了前100名的后100W-100名玩家的积分,让变化的积分跟第100名比较,如果比第100名高,那就替换的原则。)
•要统计10分钟内订单的亏损,你会怎么设计(strom窗口模式)
要统计10分钟内订单的亏损,你会怎么设计(strom窗口模式)
6.设计抽奖系统,四种奖品,A10%,B20%,C30%,D40%,我回答的Random
•查找出文件test中的所有含"apa"的单词,并保存到文件testc中
8. 某项目中的支付用的哪个支付中心?与淘宝对账了没,怎么处理的?
xm
- 收获
- 项目1:需求迭代,需求不明确,推翻重做,与前端联调,可扩展,复用性&可配置,与产品经理反复确认,demo,数据样例,沟通文档
- 项目2:老服务,相关人员离职,缺失文档,接手服务,在这种情况,看服务代码,搭建测试环境测试,熟悉,维护支持
- 项目3:不会,学习tensorflow,找了一个模型,做迁移学习,成长,,面对新的知识,积极去学习
1、简单介绍一下自己。
2、介绍一下你的项目经历。
3、讲一下你在这个项目中用到的技术,负责哪个模块?
4、在项目过程中有没有遇到什么困难,怎么去解决的?
16、还有什么想问我的么?
1.Java怎么学习的,学习路径,做过什么项目,用过哪些中间件。
3.做过最难的业务场景
•项目:你做了什么,为什么要这么做,用了什么技术要解决什么问题
2.说一个能体现你学习能力的项目或实习经历或者学习经历
- 反问:先夸一波面试官,您问的问题真的很棒,很多我在学习时忽略到的,虽然基础但是很深入,学习到了很多,没人能经受的了拍马屁吧!!!然后问了一些学技术的建议,企业希望大学生可以处于什么样的水平?
资料引用
- (带+为参考此链接)https://blog.csdn.net/ThinkWon/article/details/104390612
- sxt2:尚学堂2季
- jvm3:《深入理解Java虚拟机:JVM高级特性与最佳实践(第3版)》
- jvms:《实战JAVA虚拟机》
- redis
- rky:《redis开发与运维》【1】
- rss:《redis设计与实现》【2】
27、31\32\33\34
https://blog.csdn.net/weixin_40778497/article/details/104110272
