@ArrowLLL
2017-04-18T04:28:57.000000Z
字数 5881
阅读 4869
K-Means 文本聚类
python Kmeans 机器学习
主页地址 :月光森林
引言
信息内容安全的一个作业, 要求用K-means聚类算法对一定量的新闻文本进行分类。为便于总结,同时交作业,以此记之。
参考
- jieba分词组件组件介绍
- Introduction to K-means Clustering
- 《Python机器学习及实践:从零开始通往Kaggle竞赛之路》中 K-means聚类部分
- Matplotlib 教程
轮廓系数的两个参考 : Silhouette (clustering) 和 轮廓系数-百度百科
准备
python版本 : 3.5.2
- 操作系统 : ubuntu 16.04
- 用到的python库 :
- jieba -- 用于中文分词, 可以通过
sudo pip3 install jieba3k直接安装 - numpy, 科学计算库,通过
sudo pip3 install numpy安装 - scikit-learn, 数据挖掘库, 可以通过
sudo pip3 install scikit-learn安装 - pylab, 绘图工具库。可以通过
sudo pip3 install matplotlib安装
- jieba -- 用于中文分词, 可以通过
- 33 份新闻文稿。以 的比例挑选训练集与测试集。即随机从33 份新闻文稿中挑选6份作为测试集。
文档树
.
├── findK.py
├── Kmeans.py
├── pycache
│ └── findK.cpython-35.pyc
├── test
│ ├── C4-Literature11.txt
│ ├── C4-Literature14.txt
│ ├── C4-Literature23.txt
│ ├── C4-Literature32.txt
│ ├── C4-Literature4.txt
│ └── C4-Literature7.txt
├── train
│ ├── C4-Literature1.txt
│ ├── ...
│ └── C4-Literature32.txt
└── tree.txt3 directories, 37 files
- findK.py 是从训练集中寻找K-means算法中合适的K值的python程序,后文中会介绍这种方法;
- Kmeans.py 是K-means算法的程序,包括训练与测试;
- pycache/ 文件夹是 K-means.py 调用 findK.py 中的函数生成的文件夹,其下的 findK.cpython-35.pyc 也是调用后生成的相应的.pyc文件, 方便下一次装载;
- test/ 文件夹下是测试集;
- train/ 文件夹下是训练集;
- tree.txt 是通过
~$ tree > tree.txt命令生成的文档树文件,就是上面引用中的内容,此处为了方便展示改变了一下树的姿势,将 train/ 文件夹下的文本用省略号代替了一部分;
关于测试集的产生,使用的是python的自带的随机函数random.choice() ,具体产生方式如下:
模型框架
整个聚类模型主要分为5个部分,分别是 : 提取特征,找k值,K-means聚类,结果评价,对测试集分类。
提取特征
提取文本特征的主要代码是 findK.py 文件内的 getTags() 函数和 getMatrix(wordDic, wordlist) 函数。
getTags()函数遍历 train/ 文件夹下的文本,使用jieba.analyse包里的函数extract_tags()函数提取文本的关键词,对每篇文本提取的关键字个数topK为10个。然后将其存入文本关键词列表 wordlist 和关键词位置字典 wordDic 并返回;getMatrix(wordDic, wordlist)显然其参数是getTags()的两个返回列表。这个函数的作用是将每个文本的关键字列表转化为一个01矩阵,每一行代表一个文本,每一列是一个关键词,如果第i个文本含有第j个关键词,则有 wordMartix[i, j] = 1 , 如果第i个文本不含有第k个关键词,则有 wordMatrix[i, k] = 0 , 对所有文本操作完毕后返回这个01矩阵。
找k值
找k值使用的 elbow point 方法。枚举聚类的 k 值,作出在每个 k 值下各个数据点到聚类中心的距离的折线图,图像中的拐点可以粗略地估计为聚类数量即k值。该方法主要参考Introduction to K-means Clustering,在《kaggle竞赛之路》中也提到过该方法。
这一部分会用到下一个会说到的K-means聚类,这里先按下不表,下一节说明。
找k值这一部分是通过 findK.py 的主函数部分完成的。枚举的聚类数量k值为 1 到 7,并且在每一个固定的k值下通过奔跑10次K-means算法防止随机取点造成只能取得局部最优解而不能得到全局最优解。
最后通过pylab下的plot函数作出图像如下:
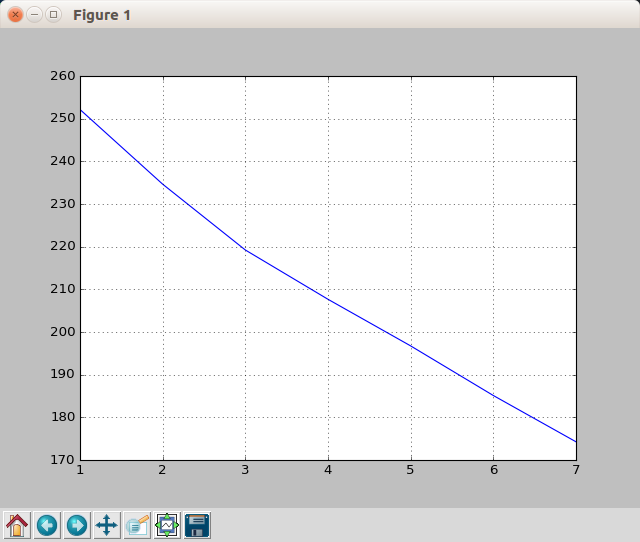
从图像中可以看到一个很明显的拐点是 k = 3 的点,故选取k值为3。
K-Means聚类
kmeans聚类使用的是sk-learn自带的KMeans类KMeans()。参数n_clusters表示聚类中心的个数。中使用到的属性和方法如下:
KMeans.fit(X)表示运用Kmeans算法计算X矩阵;KMeans.cluster_centers_表示聚类中心点;KMeans.lables_表示各个聚类样本的聚类结果标签;
关于K-Means算法的细节及数学基础可以参考第一部分提到的Introduction to K-means Clustering
结果评价
聚类结果评价使用的是轮廓系数(Silhouette Coefficient)。具体的内涵可参考 参考部分 给出的轮廓系数的相关链接,在《kaggle竞赛之路》中也提到过这种评价方法。
该评价方法结合了内聚度与分离度两种因素,将结果定性在-1到1之间。轮廓系数越接近1说明聚类结果越好,结果小于0说明聚类并不成功。
代码当中直接使用了sklearn.metrics包中的silhouette_score类silhouette_score(X, label, metrics) , X表示聚类对象矩阵,label表示聚类结果标签,metrics 表示聚类模型中计算距离的方法,默认为 'euclidean' 即欧几里得距离计算各个点到聚类中心的距离。
对测试集分类
对测试集分类使用的是 Kmeans.py 的主函数中还有一个对未知文本的分类预测函数 KMeans.predict(X), 它可以对矩阵X中的量做出预测。X的列数与Kmeans中样本的列数相同,行数为测试的样本数。返回一个矩阵表示预测的分类结果。
代码及其相应注释
findK.py
#!usr/bin/python3#coding: utf-8import osimport jiebaimport jieba.analyseimport numpy as npfrom sklearn.cluster import KMeansfrom pylab import *# 提取训练集中文本的关键字def getTags() :path = './train/'wordDic, wordslist = {}, []# os.listdir() 提取相应路径下的文件名for fileName in os.listdir(path) :# 以gbk格式打开文本with open(path + fileName, encoding = 'gbk') as f :# extract_tags() 函数提取关键字text = ' '.join(jieba.analyse.extract_tags(f.read(), topK = 10))words = text.split()# 将当前文本关键字放入总的关键字列表中wordslist.append(words)# 将当前文本关键字放入关键字字典中for word in words :wordDic[word] = 0# 遍历官架子字典,为每一个关键字取定一个字段值,即列号存入字典for (word, seqNo) in zip(wordDic, range(len(wordDic))) :wordDic[word] = seqNoreturn wordDic, wordslistdef getMatrix(wordDic, wordslist) :# 取定第一维为文本数,第二维为关键字数量的零矩阵wordMatrix = np.zeros([len(wordslist), len(wordDic)])# 第i个文本包含第j个词,则wordMatrix[i, j] = 1,构造01矩阵for (i, words) in zip(range(len(wordslist)), wordslist) :for word in words :wordMatrix[i, wordDic[word]] = 1# 返回01矩阵return wordMatrixif __name__ == '__main__' :# 提取文本关键字列表与关键词字典wordDic, wordslist = getTags()# 构造关键词01矩阵wordMatrix = getMatrix(wordDic, wordslist)# n 表示聚类数量K的封顶值n, distance = 8, []for i in range(1, n) :# 初始化最小距离为 -1minDis = -1# 跑10次Kmeans以保证取得的是全局最优解(10可以更大)for j in range(10) :# 调用sklearn的kmeans类kmeans = KMeans(n_clusters = i).fit(wordMatrix)# centers 表示每个样本对应的聚类中心点centers = np.array([kmeans.cluster_centers_[k] for k in kmeans.labels_])# 计算当前Kmeans结果的距离,取欧式距离但没有开方dis = ((wordMatrix - centers) ** 2).sum()# 更新最小值minDis = dis if minDis < 0 else min(minDis, dis)# 将相应的k值存入distance列表distance.append(minDis)# 绘图plot(range(1, n), distance)# 绘制网格grid()show()
Kmeans.py
#!usr/bin/python3#coding: utf-8import osimport numpy as npimport jieba.analyse as jbaysfrom sklearn.cluster import KMeansfrom sklearn.metrics import silhouette_scoreimport findK# 获取测试集的关键词01矩阵,与findK.py 中getMatrix()函数基本相同,不再做过多解释def getTestMatrix(wordDic, matrixshape1) :path = './test/'keyWordslist = []for fileName in os.listdir(path) :with open(path + fileName, encoding = 'gbk') as f :text = ' '.join(jbays.extract_tags(f.read(), topK = 10))words = text.split()keyWordslist.append(words)matrixshape0 = len(os.listdir(path))testMatrix = np.zeros((matrixshape0, matrixshape1))for (i, keywords) in zip(range(matrixshape0), keyWordslist) :for keyword in keywords :if keyword in wordDic :testMatrix[i, wordDic[keyword]] = 1return os.listdir(path), testMatrixif __name__ == '__main__' :# 获得训练集的关键词字典与列表worDic, wordslist = findK.getTags()# 获得训练集关键词的01矩阵minDis, wordMatrix = -1, findK.getMatrix(worDic, wordslist)# 获得测试集的文本标题与测试集关键词01矩阵fileName, testMatrix = getTestMatrix(worDic, wordMatrix.shape[1])# 奔跑10次KMeans防止取到局部最优解,与findK.py中类似,不过多解释for j in range(10) :# 取k值为3kmeans = KMeans(n_clusters = 3).fit(wordMatrix)centers = np.array([kmeans.cluster_centers_[k] for k in kmeans.labels_])dis = ((wordMatrix - centers) ** 2).sum()if minDis < 0 or dis < minDis :minDis,testKmeans = dis, kmeans# 使用轮廓系数评价聚类模型siCoScore = silhouette_score(wordMatrix, testKmeans.labels_, metric='euclidean')print ('轮廓系数为:', siCoScore)# 预测测试集的分类结果result = testKmeans.predict(testMatrix)for i in range(result.shape[0]) :print (fileName[i] + ' 类别为 :\t', result[i])
最终结果
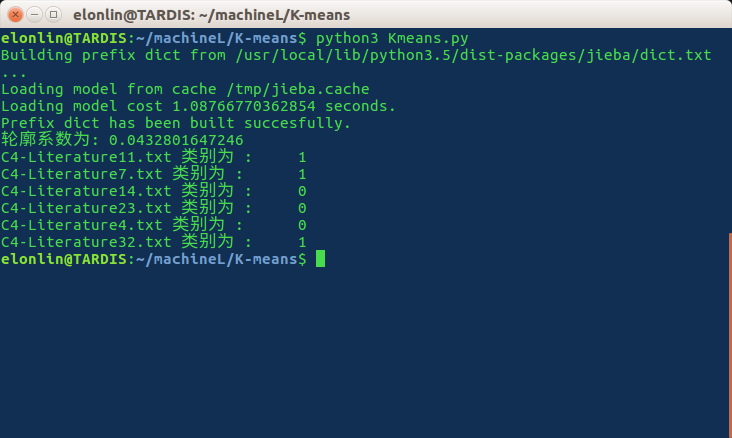
最终结果显示轮廓系数为0.043左右,聚类成功但是结果并不是很理想。推断应该有两个原因:
一是提取的关键词并不理想, 并且会有近义词的存在将原本意思相同的两个关键词作为完全不同的两个关键词,而近义词需要很大的语料库支撑。
二是01矩阵这个模型并不是很适合。做完以后想到可以用tf-idf值代替0和1作为矩阵中的值出现。但是后来写完tfidf的模型以后发现,使用tf-idf值会因为测试集中每个测试文本都会影响整体的idf值,每一次都要重新计算一遍,如果文本量巨大,计算时间成本相应地也会变得很大,就类似于实时的KNN算法一样,每一个测试样本又会作为训练样本加入原本的训练集。这种奔跑学习的方式虽然也算一种暴力美学,但是实在是有失优雅。所以放弃了使用tfidf的想法,改为使用jieba自带的extract_tags()函数提取关键词构建01矩阵作为特征。只是没想到结果会变得这么差。
最后只好以 结果至少没有小于0 来安慰自己了。
以上です~
