@ArrowLLL
2017-08-14T14:20:53.000000Z
字数 6046
阅读 2860
感知机学习算法实践
Elon Lin
概述
李航《统计学习方法》学习的第二篇博文。内容为书籍第二章感知机的算法实践。感知机的学习笔记 —— 感知机学习笔记。
本篇使用kaggle网站提供的关于“数字识别”的数据。经过随机选取获得训练集和测试集,使用训练集训练感知机,对测试集测试,然后通过计算误判率来验证算法的有效性和正确性。。
- 系统 : ubuntu 16.04
- python版本: 3.5.1
- 为了理解原理自己造轮子,不使用拓展包
初始时文件结构为 :
.
├── data.py
├── main.py
├── oldTrain.csv
├── perceptron.py
├── test.py
└── tree.txt0 directories, 6 files
运行main.py后会新增文件,改变项目结构为如下:
.
├── ans.csv
├── data.py
├── main.py
├── oldTrain.csv
├── perceptron.py
├── pycache
│ ├── data.cpython-35.pyc
│ ├── perceptron.cpython-35.pyc
│ └── test.cpython-35.pyc
├── test.csv
├── test.py
├── train.csv
└── tree.txt1 directory, 12 files
热如何产生这些文件的在后面的部分会讲到。
数据来源与处理
数据为kaggle网站提供的“数字识别”,可在 下载地址 中看到如下图所示的链接文件:
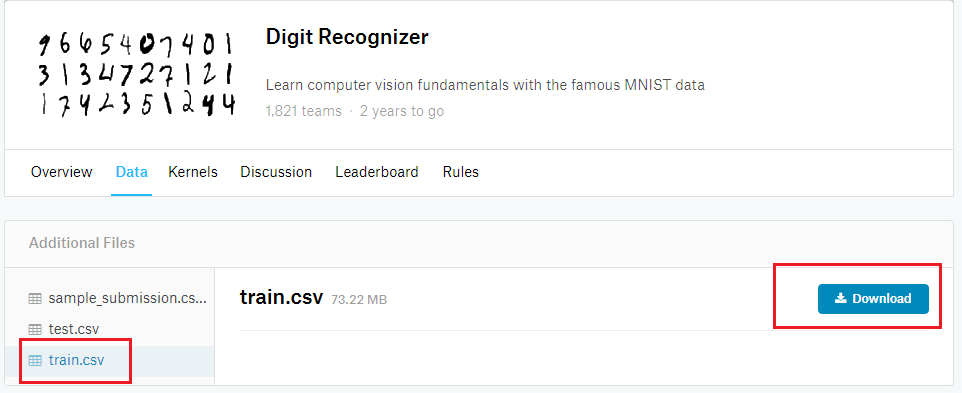
由于于感知机的限制性,该次实践只需要train.csv,不需要test.csv,原因下面会讲到。因此点击train.csv 然后 Download 即可。
因为感知机用于解决二分类问题,不能用于将10个数字分类。所以我们要做的,是将train.csv 中不必要的数据去除掉。我选择只留下 0 和 1 的数据,将 2~9 的数据全部删除,当然读者们可以选择留下任意两个数字,可以用于二分类即可。
另外,因为我们只选取其中 0 和 1 两类数据,而kaggle提供的test.csv 是包含所有 0~9 数据的10个数据的,并且没有说明类别。这也是为什么我们不需要test.csv的原因。由于没有测试数据,因此,我们需要将处理后的 train.csv 分解为两部分,分别作为训练集和测试集,按照惯例,是8:2的比例,80%作为训练集,20%作为测试集。
以下为处理数据的python代码 data.py :
#!usr/bin/env python3# -*- coding:utf-8 -*-import sysimport randomdef get01(fileName) :'''fileName中含有的是带有标签0-9的数据,该函数用于将fileName中的2-9的数据去除,只留下0和1的数据'''data = []with open(fileName) as f:lines = f.read().split()tag = lines[0]for line in lines[1:] :if line[0] in ('1', '0') :data.append(line)return tag, datadef getData(args) :'''用于获取args文件中的0和1的数据,并将数据按照2:8分为数据集和测试集,以及测试集对应的答案放入相应的文件 "train.csv", "test.csv", "ans.csv"'''# 获取只包含0和1的数据集tags, lines = get01(args)lineNum = len(lines)# 随机取8:2的数据testDataSet = set(random.sample(range(lineNum), (int)(lineNum / 5)))# 创建相应的文件train = open('train.csv', 'w+')train.write(tags + '\n')test = open('test.csv', 'w+')tags.replace('label', 'case')test.write(tags + '\n')answer = open('ans.csv', 'w+')answer.write("case,label\n")# 写入文件c = 0for i, line in zip(range(lineNum), lines) :label = '+1' if line[0] == '1' else '-1'if i in testDataSet :answer.write("%s,%s\n" % (c, label))test.write(str(c) + line[1:] + '\n')c += 1else :line = label + line[1:]train.write(line + '\n')# 在终端输出分配结果print ('data num : ' + str(lineNum))print ('train data : ' + str(lineNum - len(testDataSet)))print ('test data : ' + str(len(testDataSet)))train.close()test.close()return 'train.csv', 'test.csv', 'ans.csv'if __name__ == '__main__' :if len(sys.argv) == 2 :oldFile = sys.argv[1]else :oldFile = 'oldTrain.csv'print (getData(oldFile))
首先需要将下载的 train.csv 更名为 oldTrain.csv. 从python代码中可以看出,生成的训练数据文件也叫 train.csv, 更改源文件名字可以防止原数据被覆盖,从而保护原本的数据,多次利用。
data.py 的作用就是将原本的 oldTrain.csv 中的数据按照 8:2 的比例分为 train.csv 和 test.csv,以及 test.csv 对应的label的答案 ans.csv 。由于是随机取数据,故该代码可以重用。每运行一次可以由原来的数据生成不同的训练集和测试集。
这个代码很好理解,如果有兴趣的话,可以0和1的二分类改为任何两个数字的二分类问题。例如3和4, 2和8, 9和7等等的。
感知机模型训练
感知机模型的训练代码保存为 perceptron.py. 这里采用的是原始形式的感知机模型。学习率为 (eta),在代码中可以自行调整,默认值为1。
#!usr/bin/env python3# -*- coding:utf-8 -*-w, b, eta = [], 0, 1def L(x) :'''函数 L(x) = w .* x + b'''return sum(wv * xv for (wv, xv) in zip(w, x)) + bdef findWrong(dataSet) :'''找到数据集中的误分类点,如果没有找到返回 None,找到则返回一个元组 (误分类结果 y, 该误分类点的特征向量 x)'''t = 0for (y,x) in dataSet :t += 1if L(x) * y <= 0 :return (y, x)return Nonedef sgd(data) :'''利用传入的误分类点使用梯度下降法极小化目标函数 :w = w + (eta * y) .* xb = b + eta * y'''global w, b, etay, x = dataw = [dw + eta * y * dx for (dw, dx) in zip(w, x)]b = b + eta * ydef train(fileName, _eta = 1) :'''训练过程函数,感知机要求训练数据保证线性可分,采用的是原始形式的感知机学习算法'''# 取出对应csv按文件中的数据,并存入列表dataSet# 列表中的单个数据以二元组形式存储,(标签, 特征向量)f = open(fileName)data = f.read().split()column_names = data[0].split(',')f.close()dataSet = []for singleData in data[1:] :singleData = list(map(int, singleData.split(',')))dataSet.append((singleData[0], singleData[1:]))# 初始化全局变量 :权值向量w, 偏置b, 学习率etaglobal w, b, etaeta = _etaw = [0 for i in range(len(dataSet[0][4]))]trainTime = 0# 训练过程,先找到一个误分类点,然后用sgd函数进行修正,while True :selectData = findWrong(dataSet)if selectData == None : breaksgd(selectData)trainTime += 1if trainTime % 10 == 0 :print ("----- train Time :", trainTime, " -----")# 输出训练次数,即误分类次数print ("----- total train time :", trainTime, " -----")return w, bif __name__ == '__main__' :w, b = train('train.csv')print ("w :", w)print ("b = ", b)
perceptron.py 即为训练模型的代码实现。采用的是感知机学习算法的原始形式,为了查看训练过程,每误分类10次就输出一次训练次数。
在 train() 函数中使用 findWrong() 函数找到误分类点,然后用 sgd() 函数利用梯度下降法极小化目标函数;findWrong() 函数中又调用 L(data) 函数得到目标函数值。
代码并不复杂,加上注释中给出的过程以及参考《统计学习方法》对应的模型很容易理解。
对测试集进行测试
测试代码 test.py,用于对 test.csv 文件内的数据进行分类 :
#!usr/bin/env python3# -*- coding:utf-8 -*-w, b = [], 0def test(x) :'''按照模型 y = w .* x + b 计算对应数据的类别y值非负返回为 +1y值为负则返回 -1'''global w, bL = sum(wv * xv for (wv, xv) in zip(w, x)) + breturn 1 if L >= 0 else -1def testFile(fileName, dw, db) :'''从测试文件fileName中读取测试集的特征,利用dw和db构成的感知机模型对fileName中的测试数据进行分类'''global w, bw, b = dw, db# 读取数据with open(fileName) as f :testData = f.read().split()# 使用 test()函数对数据进行分类,并将结果存入testResult列表testResult, column_names = {}, testData[0]for data in testData[1:] :data = data.split(',')label = data[0]result = test(map(int, data[1:]))testResult[label] = result# 返回结果,为字典类型{label : result}return testResultif __name__ == '__main__' :dw = [0 for i in range(28 * 28)]testResult = testFile('test.csv', dw, 0)for label, result in testResult.items() :if(result == -1) :print (label, ":", result)
需要注意的是, 在 '__main__' 中将 dw 和 db 分别标记为零向量和零值,单独运行时并不能对测试文件正确分类。需要利用 main.py 将上面三个代码结合起来才能得到正确的分类结果。
过程就是读取,然后分类,根据代码注释,也并不难理解。
主函数main
main.py 文件将上述3份代码结合起来,将原来的 oldTrain.csv 进行剔除选择测试集和训练集,然后训练,然后测试,最终输出结果。
#!usr/bin/env python3# -*- coding:utf-8 -*-import dataimport perceptronimport testimport os, sysdef dealAns(ansFile) :'''读取csv文件ansFile,并进行处理获得结果字典{case : resultLabel}'''with open(ansFile) as f :ansSet = f.read().split()answer, column_names = {}, ansSet[0].split(',')for ans in ansSet[1:] :ans = ans.split(',')answer[ans[0]] = int(ans[1])return answerdef main(dataFileName, eta) :'''传入参数包括原本包含0-9这10个数字的文件集合dataFileName, 以及预先传入的学习率eta值在终端输出最终的测试结果,包括正确分类和错误分类的数量以及分类的正确率'''# 调用 data.getData 对数据集清洗并按照8 :2分集trainFile, testFile, ansFile = data.getData(dataFileName)# 使用perceptron.train利用训练集训练感知机模型w, b = perceptron.train(trainFile, eta)# 调用 test.testFile 对测试文件中的数据进行测试,传入相应的w值和b值testResult = test.testFile(testFile, w, b)# 读取ans.csv文件返回一个字典 {case : label}answer = dealAns(ansFile)# 输出测试结果positive, negative = 0, 0for label, result in testResult.items() :if answer[label] == result :positive += 1else :negative += 1print ("PN = ", positive, negative)print ("accurity =", positive / (positive + negative))if __name__ == '__main__' :argv = sys.argvif(len(argv) == 3) :main(argv[1], int(argv[2]))else :'parame error !!'
代码如上,过程也已在代码中注释标明, 不做过多的解释。
调用的命令需要加入两个参数,分别是原始文件的名字和学习率eta值。例如本人将原始数据文件保存为 oldTrain.csv,学习率选定为 1,因此在终端输入的命令为 python3 main.py oldTrain.csv 1
运行过程与结果
如下图 :
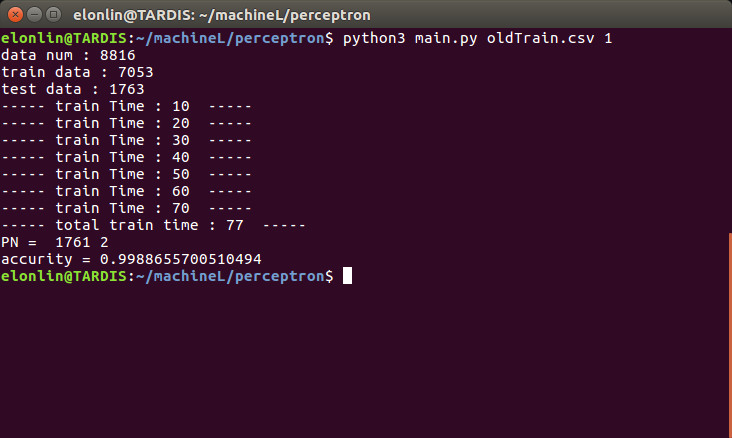
因为每一次挑选的测试集和训练集胡有所差别,所以测试结果也会有不同,但总体的分类正确率均在0.99以上。
