@ArrowLLL
2017-05-14T16:25:03.000000Z
字数 6135
阅读 4215
信息内容安全考试大纲
Elon Lin
概论
产生背景
大数据时代的来临
网络信息内容特点
- 存储数字化
- 表现形式多样化,内容丰富
- 数量巨大,增长迅速
- 传播速度快、范围广、具有交互性
- 结构复杂,分布广泛
- 信息源复杂,无序
- 动态不稳定性
网络信息内容安全的定义
基于信息传播的互联网安全管理问题,反映的是网络用户公开发布的信息所带来的社会公共安全问题,这里面所涉及的技术主要包括 主题信息监控,舆情监控,社交网络社团挖掘等。
网络信息内容安全的特点
- 交叉。网络内容信息安全既是一门新兴的客体,又需要多个学科交叉研究。
- 互联。网络信息内容安全以互联网为研究载体。
- 海量。网络信息内容安全问题面对的是海量信息。
- 融合。传统信息安全是内容安全的保障,而这需要有利结合。
研究信息内容安全的“三分类”过程
- 句法分析。判断“信息是否为可读语句”,又称为语句分类。
- 主题分类。判断“由可读语句表达的信息是否属于所关注的安全领域”,又称领域分类或主题分类。
- 倾向分类。判断“落入某领域的信息是否符合所定义的安全准则”,又称安全分类。
网络信息内容安全研究的意义
- 提高网络用户及网站的使用效率。
- 净化网络空间
- 提高国家信息安全保障水平
未来发展需要关注的问题
- 网络信息内容的可信度
- 数据水印技术
- 基于大数据uuud网络信息真实性分析
- 移动互联网信息内容安全
网络信息的获取
互联网信息分类
主要分为 网络媒体信息 和 网络通信信息 两类。
网络媒体信息,指传统意义上的互联网网站的公开发布信息,网络用户通常可以基于通用网络浏览器获得互联网公开发布的信息。
通过以下划分方法继续细分 :
1. 网络媒体形态 : 广播式媒体 与 交互式媒体
2. 发布信息类型 : 文本信息、图像信息、音频信息和视频信息
3. 媒体发布方式 : 直接匿名浏览的公开发布信息, 需要身份认证访问的网络媒体信息;
4. 按网页具体形态分类 : 静态网页,动态网页
网络通信信息,指互联网用户使用除网络浏览器以外的专用客户端软件,实现与待定点的通信或进行点对点通信时所交互的信息。
网络媒体信息获取的一般流程
- 初始URL集合
- 信息获取
- 信息解析
- 信息判重
网络媒体信息获取的分类
- 全网信息获取
- 定点信息获取
- 基于主题的信息获取和元搜索
网络媒体信息获取的方法
带身份认证媒体发布信息获取
- 基于Cookie机制实现身份认证
- 基于网络加护重构实现媒体信息获取
内嵌脚本语言片段的动态网页信息获取
- 利用HTML DOM树提取动态网页内的脚本语言片段
- 基于Rhino实现Javascript动态网页信息获取
基于浏览器模拟实现网络媒体信息获取
- 身份认证表单自动填写
- 身份认证协商与发布信息一致
- 对网页内嵌URL逐一进行点击浏览与导出
网络通信信息获取的一般流程
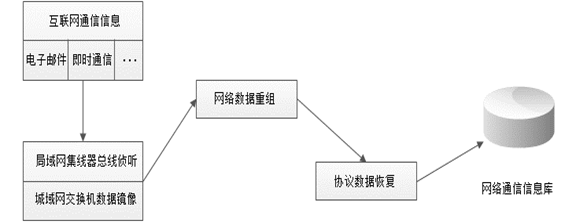
网络通信信息的获取方法
有线网络
- 端口镜像复制模式
- 攻击交换机以得到所有的数据包
- 攻击模式包括 MAC Flooding 和 ARP包欺骗
无线网络
- 设置成混杂模式
- 射频监听工作模式
基于Winpcap的数据包捕获设计流程
- 选择监听网络接口,
pcap_lookupdev()函数 - 建立监听会话,
pcap_oplive()函数 - 编辑过滤器,
pcap_compile()函数 - 设置过滤器,
pcap_setfilter()函数 - 捕获数据包,
pcap_loop()函数
网络信息内容预处理技术
中文分词
方法 : 基于字符串匹配, 基于统计方法, 基于理解方法。
常用分词系统 : BosonNLP中文分词系统、庖丁中文分词系统, jieba分词 等
去停用词
停用词是指与其他词相比,通常没有实际意义的词语。
计算机对其处理不但是没有价值的工作,还会增加运算复杂度,通常文本的停用词处理中可采用基于词频的方法将其除去。
语义特征提取
语义级别由低到高可分为 : 亚词级别,词级别,多词级别,语义级别和语用级别。其中应用最广泛的是词级别。
特征子集选择
常用的三种 特征选择方式 : 过滤(filter), 组合(wrappers) 和 嵌入(embedded)
重点: TF-IDF算法 —— 使用python做tf-ifd算法实践
网络信息内容过滤
概述
定义
根据用户的信息需求,运用一定的标准和工具,从大量的动态网络信息流中选取相关的信息或剔除不相关信息的过程。
特点
- 过滤系统是为无结构化和半结构化大数据而设计的信息系统
- 信息过滤系统主要用来处理大量的动态信息
- 过滤系统包含大量的数据
- 典型的过滤系统应用包含输入的数据流或是远程数据源的在线广播
- 过滤是基于对个体或群组的信息偏好的描述,也称为用户趣向
- 过滤是从动态的数据流中收集或去掉某些文本信息
意义
- 改善Internet信息查新技术的需要
- 个性化服务的基础
- 维护我国信息安全的迫切需要
- 信息中介(信息服务供应商)开展网络增值服务的手段
过滤技术的分类
根据过滤方法分类
基于内容的过滤, 基于网址的过滤,混合过滤
根据操作的主动性分类
主动过滤,被动过滤
根据过滤位置的分类
上游过滤, 下游过滤
- 根据过滤的不同应用分类
专门过滤软件、网络应用程序、其他过滤工具
网络过滤的一般流程
- 用户通过网络产生信息,用户需求模板将信息以计算机可识别的形式揭示出来,这就是用户需求模板
- 对动态的网络信息集不做预处理,只是当信息流经过系统时才运用一定的算法把信息揭示出来
- 通过反馈机制作用于用户和用户需求模板,使用户逐渐清晰自己的信息需求
- 反馈模块主要用于处理用户的反馈信息并依据反馈信息进一步精化用户模型,并保存
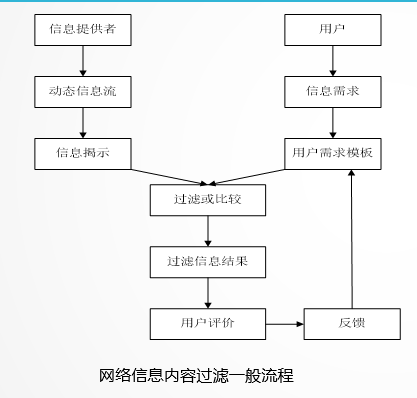
网络信息过滤模型
- 布尔模型
- 向量空间模型
- 神经网络模型
晚饭咯信息内容过滤主要方法
掌握朴素贝叶斯, 参考 贝叶斯推断应用:垃圾邮件过滤
话题检测与跟踪
话题检测与跟踪,Topic Detection and Tracking, 简称 TDT。
话题检测与跟踪定义
- 话题检测(Topic Detection) : 旨在发现新的事件并将谈论某一事件的报道归入相应的事件簇。
- 话题跟踪(Topic Tracking) : 通过监控新闻媒体流以发现与某一已知事件相关的后续新闻报道。
话题检测与跟踪特点
- 多数采用传统的文本分类、信息过滤和检测的方法,专门针对话题发现与跟踪自身特点的算法还未形成;
- 对某个用户感兴趣的特定话题,现有系统都无法保证取得满意效果;
- 综合使用多种相对成熟的方法,在实际应用中可能效果更佳。
话题检测与跟踪意义
传统的关键词检索技术,信息冗余度高,对信息简单罗列,难以全面把握。话题检测与跟踪技术能把分散的信息有效地汇聚并组织起来,从整体上了解一个话题的全部细节以及该话题中事件之间的相关性。
话题检测与跟踪的任务及研究现状
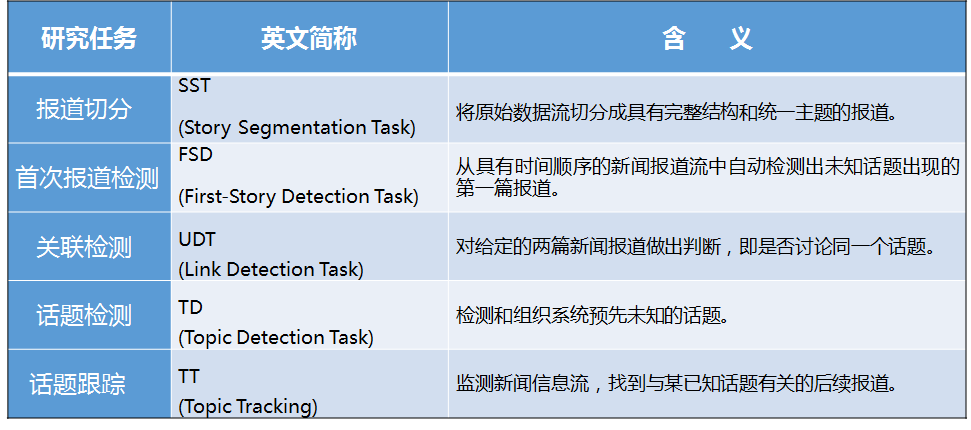
- 报道切分
- 基于语音识别系统的报道切分 : 根据语音信号的分布规律划分报道边界;
- 基于内容的报道边界识别 : 转录为文本形式,根据报道之间主题内容的差异估计报道边界;
- 话题检测, 主要任务有 :
- 首次报道检测(FSD) : 准确定位新话题出现的最初报道
- 在线话题检测(OTD) : 不仅要求识别最新话题,同时需要收集该话题的所有相关报道
其相关研究有 : 在线话题检测, 新事件检测, 事件回顾检测, 层次话题检测, 跨语言话题检测与跟踪
- 关联检测,检测随机选择的两篇报道是否论述同一话题,并分析它们之间的关联关系。主要方法有
- 向量空间模型(Vector Space Model, VSM) : 根据特征在文本中的概率分布估计权重,利用余弦夹角衡量报道之间的相似性;
- 语言模型(Language Model, LM) : 采用语言模型描述报道产生于某话题的概率,采用KLD算法综合得出。
- 话题跟踪
- 传统话题跟踪(TTT) :研究方向主要有 基于分类策略的话题跟踪研究,二元分类方法跟踪话题,Rocchio算法实施跟踪。其他面向TTT的的研究还有话题与报道的相似度匹配。
- 自适应话题跟踪(ATT) : 基于内容的ATT相关研究,采用文摘技术跟踪话题发展趋势;基于统计策略的ATT研究中,主要借鉴于自适应信息过滤。 未来研究重心主要在如何利用新闻语料的事件特征,并分析话题发展在时间轴上的分布。
- 话题跟踪
主要任务是跟踪已知话题的后续报道。
话题检测与跟踪的一般系统模型
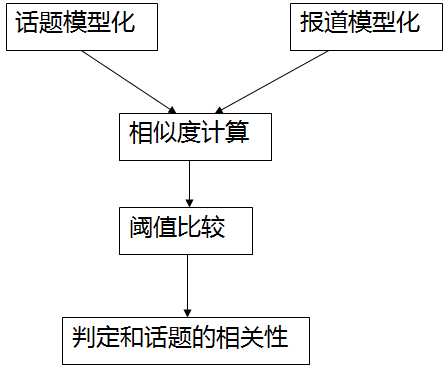
要实现话题发现与跟踪,需要解决以下问题 :
1. 话题/报道的模型化(常用模型有语言模型和向量空间模型)
2. 话题 - 报道相似度的计算;
3. 聚类策略(重点掌握K-Means算法)
4. 分类策略(阈值选择策略)。
话题检测与跟踪的效果评价
评测标准都是建立在检验系统漏检率和误检率的基础上 :
和 分别代表 漏检率和错检率;
和 分别是系统漏检和错检的条件概率;
和 是先验目标概率();
是综合了系统漏检率和错误率得到打性能损耗代价
规范化表示为
话题检测与跟踪的发展趋势
- 基于概率模型和自然语言处理技术(NLP)在话题检测与跟踪技术中的广泛应用
- 利用时序特征解决面向新闻报道的检测和跟踪任务
社会网络分析
概述
社会网络指的是社会行动者(Social Actor)及其关系的集合。社会网络强调每个行动者都与其他行动者有或多或少的关系,还关注行动者之间的“多元关系”,即联系。
社会网络分析主要研究社会实体的关系链接以及这些连接关系的模式,结构和功能。
社会网络分析的基本视角是 关系取向 和 位置取向
研究体系(分析角度)
- 中心性分析 : 研究个体处于网络中心的程度,反映该点在网络中的重要性程度。
- 凝聚子群分析 : 当网络中的某些行动者之间的关系特别紧密时,以至于结合成一个次级团体时,这样的团体在社会网络分析中被称为凝聚子群。分析网络中这样的子群的关系与特点就是凝聚子群分析。
- 核心-边缘结构分析 : 研究社会网络中哪些节点处于核心地位,哪些节点处于边缘地位。
分析模型
社会网络构建
1. 具有社团结构的无权网络模型,如 BA模型。
2. 基于分离者模型的社团结构模型。
社会网络的发现
1. 非重叠社团算法。是指识别出的社团之间互不重叠,每个节点有且仅属于一个社团;
2. 重叠社团算法。
常用方法
- 基于命名实体检索结果的社会网络构建
- 基于内容分析的社会网络构建
安全应用
- 社会挖掘和话题监控的互动模型研究
- 不同实体间关系倾向性分析
- 中文新闻文档自动文摘
网络舆情分析
概念
舆情指在一定的社会空间内,围绕中介性社会事项的发生、发展和变化,作为主题的民众对作为客体的国家管理者产生和持有的社会政治态度。如果把中间的一些定语省略,舆情就是民众的社会政治态度。
舆情的主要表现形态有 : 文本、图像和视频、网络行为等。
网络舆情的特点
- 直接性。通过网络直接发表意见,传播迅速
- 随意性和多元化。民众可匿名发表观点,健康观点和灰色言论并存
- 突发性。网络快速传播的特性使关注重点迅速成为舆论热点
- 隐蔽性。虚拟空间中网名可随意发言
- 偏差性。网络舆情不等于全名立场
网络舆情的功能
- 舆情分析引擎
- 自动采集功能
- 信息抽取功能
关键技术
信息采集技术
包括数据爬取,数据存储,数据清洗等
热点发现技术
主要算法有 : Single-pass聚类算法,K-means, KNN最近邻算法, SVM支持向量机,SOM神经网络聚类。
热点评估与跟踪
热点评估有词频统计和情感分类两个主要手段。
热点跟踪主要使用KNN最近邻法和朴素贝叶斯算法。舆情等级评估
综合评判方法实现舆情等级评估的构建步骤:
- 确定对象集和评估因素集
- 确定评估集
- 评估指标权重的确定
- 评估指标隶属度的确定
网络舆情分析系统框架
总体框架的关键
- 信息采集 : 从数据源进行网页抓取,经正文提取、内容去重等操作,然后将数据表示为便于处理的形式;
- 舆情分析 : 利用分类、聚类算法对信息进行分析处理,形成舆情简报传递给前台
关键技术分析
- 舆情搜索引擎。包括 网络抓取技术、网页处理技术和网页检索技术。
- 舆情分析引擎。包括 文本聚类、文本分类、文本倾向性分析。
分析常用方法
- 高仿网络信息深度抽取
- BBS/BLOG/聊天室内容提取模块
- 内容冗余性与完整性过滤模块
- 查询编辑接口模块
- 信息自动提取机器人技术
- 个性化可配置的信息自动提取技术
- 互动式信息的只能提取技术
- 网页编写语言的实时语义理解技术
- 多线程内容提取技术
- 基于语义的海量文本特征快速提取与分类
- 基于分词的文本特征提取模块
- 基于词频统计的文本特征提取模块
- 基于互联网网络媒体特征的多媒体特征提取模块
- 多媒体群件理解技术
- 综合字词i、标点和模式匹配的文本核心信息快速提取
- 图像核心信息快速提取技术
- 综合环境信息和相关媒体信息的多媒体群件理解技术
- 非结构信息自组织聚合表达
- 数据匪类模块
- 数据仓储模块
- 匪类数据库数据挖掘引擎模块
典型应用及发展趋势
典型应用
- 定点站点深入挖掘机制
- 异构数据归一化存储与目标站点热点查询
- 监控目标热点自动发现功能
发展趋势
- 针对信息源的深入信息采集
- 异构信息的融合分析
- 非结构信息的结构化表达
开源情报分析
概念价值
开源情报 : 指通过对公开信息或其他资源,包括报纸/刊物、电视、互联网等进行分析后所得到的情报。
开源情报的价值体现 :
- 情报收集成本小,风险低
- 开源情报内容更加丰富
- 开源起个包工作具有隐蔽性
开源情报分析的指标
信息源可靠性
信息源可靠度可参考如下指标 :
- 形式特征
- 组织特征
- 链接特征
- 价值特征
信息内容可靠度
评价信息内容可靠度有以下几点 :
- 明确公开源数据/公开源信息和公开源情报的区别。
- 要考察信息所表述的内容是否合情合理
- 从语言学角度考察,高可靠性的内容一般行文直接了当、清晰明确
- 从参考引用文献角度考察,高可靠性的内容会为数字、主要观点标引出处。
开源情报之数据分析
- 数据定量分析
定量分析方法有 :
- 聚类分析
- 关联规则挖掘
- 事件序列分析
- 社会网络分析
- 路径分析
- 预测分析
多源数据融合
把通过不同渠道、利用多种采集方式获取的具有不同数据结构的信息汇聚到一起,形成具有统一格式、面向多种应用的数据库及和,这一过程称为多元数据融合。
相关性分析
大数据时代数据处理理念的三大转变 :
- 要全体不要抽样
- 要效率不要绝对精确
- 要相关不要因果
开源情报具体框架
系统框架
- 系统采编报子系统 : 信息采集层依托开源情报数据采集体系,根据采集策略,实时准确采集来自不同数据源的数据,并对数据进行抽取结构化等清洗预处理。
- 情报感知分析子系统 : 情报感知分析子系统建立并更新原始素材库,为系统提供基础数据。实现数据的归类存储与数据更新。能够按数据来源分析存储原始数据,形成原始资料库,并对其做索引,供系统对原始信息的查找
- 大数据服务提供子系统 : 主要实现提供各种动态快讯、智能简报、热点分析报告、专题深度报告等功能
处理流程
- 信息采集业务 :将互联网、标准资源库、企业资源库、现有工程数据、内部资料和其他来源数据收集起来,形成原始数据。
- 开源情报加工和分析业务 : 对开源情报进行深度挖掘加工,自动提炼信息关键词、摘要,针对结构化后大数据做索引。
- 情报展示与服务业务 : 将平台的服务和产品采用多种方式发布、推送给不同的用户,包括订阅、热点周报、专题报告及年度汇总报告等。
应用趋势
引入大数据,应用大数据,探索大数据,利用大数据,研发大数据
余弦相似度分析
寻找与原文章相似的其他文章, 步骤 :
- 使用TF-IDF算法, 找出两篇文章的关键词;
- 每篇文章各取若个关键词,合并成一个特征集合,计算每篇文章对于该集合中的词的词频;
- 生成两篇文章的词频向量;
- 计算两个向量的余弦相似度,值越大越相似
以上です~
